Neural networks try to overcome the shortcomings of logistic regression in which we have to choose a non-linear hypothesis. Logistic regression requires that we choose an appropriate combination of polynomial terms and the order of the equation. The problem with this is sometimes we either tend to overfit or underfit. Neural networks allow the ability to learns new model parameters from the basis raw parameters.
The neural network is modeled on the neural networking ability of the human brain. The brain is made of trillions of neurons. Each neuron is a processing unit which has several inputs in the dendrites and an output the axon. The neurons communicate thro a combination of electro chemical signal at the synapses or the spaces between the neuron.
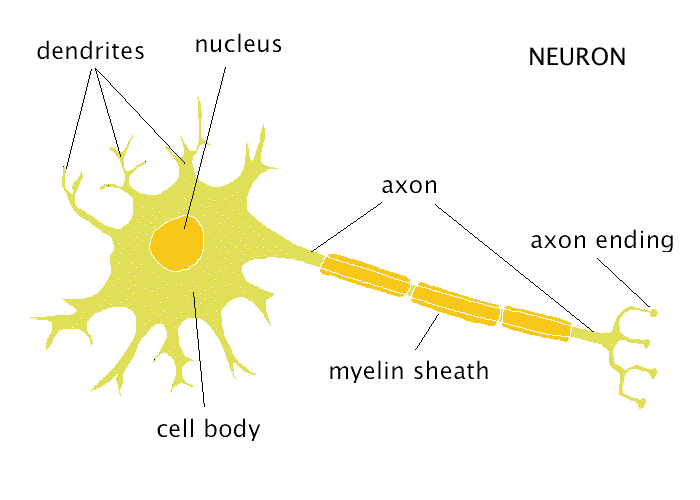
A neural network mimics the working of the neuron.
So in a neural network the features of the problem serve as input. For e.g in the case of being able to determine if a mail is spam or not the features could be the words in the subject line, the from address, the contents etc. Based on a combination of these features we need to classify whether the mail is spam or not.

The above diagram shows a simple neural network with features x1, x2, x3 and a bias unit x0
With a hypothesis function hƟ(x) = 1/(1 + e-x)
The edges from the features xi are the model parameters Ɵ. In other words the edges represent weights.
A typical neural network is a network of many logistic units organized in layers. The output of each layer forms the input to the next subsequent layer. This is shown below

As can be seen in a multi-layer neural network at the left we have the features x1,x2, .. xn.
This at the layer becomes the activation unit. The key advantage of neural networks over regular logistic regression that learns the models parameters is that learned model parameters are input to the next subsequent layers which learn the model parameters more finely. Hence this gives a better fit for the combination of parameters.
The activation parameters at the next layer are
a12 = g(Ɵ101x0+ Ɵ111x1+ Ɵ121x2 + Ɵ131x3) where g is the logistic function or the sigmoid function discussed in my previous post Simplifying ML: Logistic regression – Part 2

Here a12 is the activation parameter at layer 1
Ɵ10 is the model parameter at layer 1 and is the 0th parameter. Similarly Ɵ11 is the model parameter at layer 1 and is the 1st parameter and so on.
Similarly the other activation parameters can be written as
a22 = g(Ɵ201x0+ Ɵ211x1+ Ɵ221x2 + Ɵ231x3)
a32 = g(Ɵ301x0+ Ɵ311x1+ Ɵ321x2 + Ɵ331x3)
hƟ(x) = a13 = g(Ɵ102a0+ Ɵ112a1+ Ɵ122a2 + Ɵ132a3 – (A)
The crux of neural networks is that instead of creating a hypothesis based on the set of raw features, the neural network with multiple hidden layers can learn its own features. In the equation (A) we can see that the hypothesis is not a function of the input raw features x1,x2,… xn but on a new set of features or the activation units a1,a2, … an . In other words the network has ‘learned’ its own features.
As mentioned above the output of each layer is the logistic function or the sigmoid function
The beauty of neural networks based on logistic functions is that we can easily realize the equivalent of logic gates like AND, OR, NOT, NOR etc.
The hypothesis for the above network would be

hƟ(x) = g(-30 + 20 * x1 + 20 * x2)
So for x1= 0 and x2 = 0 we would have
hƟ(x) = g(-30 + 0 + 0) = g(-30)
Since g(-30) < g(0) < 0.5 = 0

Similarly a NOT gate can be constructed with a neural network as follows


Neural networks can also be used for multi class classification.

Hence there are multiple advantages to neural networks. Neural networks are amenable to a) creating complex logic models of combinations of AND, NOT, OR gates
b) The model parameters are learned from the raw parameters and can be more flexible.
It appears that the interest in neural networks surged in the 1980s and then waned, The neural networks were similar to the above and were based on forward propagation. However it appears that in recent time’s backward propagation has been used successfully in areas of research known as ‘deep learning’
This is based on the Coursera course on Machine Learning by Professor Andrew Ng. A highy enjoyable and classic course!!!
Find me on Google+





