
“Take up one idea. Make that one idea your life — think of it, dream of it, live on that idea. Let the brain, muscles, nerves, every part of your body, be full of that idea, and just leave every other idea alone. This is the way to success.”
– Swami Vivekananda
“Be the change you want to see in the world”
– Mahatma Gandhi
“If you want to shine like the sun, first burn like the sun”
-Shri A.P.J Abdul Kalam
Reinforcement Learning
Reinforcement Learning (RL) involves decision making under uncertainty which tries to maximize return over successive states.There are four main elements of a Reinforcement Learning system: a policy, a reward signal, a value function. The policy is a mapping from the states to actions or a probability distribution of actions. Every action the agent takes results in a numerical reward. The agent’s sole purpose is to maximize the reward in the long run.
Reinforcement Learning is very different from Supervised, Unsupervised and Semi-supervised learning where the data is either labeled, unlabeled or partially labeled and the learning algorithm tries to learn the target values from the input features which is then used either for inference or prediction. In unsupervised the intention is to extract patterns from the data. In Reinforcement Learning the agent/robot takes action in each state based on the reward it would get for a particular action in a specific state with the goal of maximizing the reward. In many ways Reinforcement Learning is similar to how human beings and animals learn. Every action we take is with the goal of increasing our overall happiness, contentment, money,fame, power over the opposite!
RL has been used very effectively in many situations, the most famous is AlphaGo from Deep Mind, the first computer program to defeat a professional Go player in the Go game, which is supposed to be extremely complex. Also AlphaZero, from DeepMind has a higher ELO rating than that of Stockfish and was able to beat Stockfish 800+ times in 1000 chess matches. Take a look at DeepMind
In this post, I use some of the basic concepts of Reinforcment Learning to solve Grids (mazes). With this we can solve mazes, with arbitrary size, shape and complexity fairly easily. The RL algorithm can find the optimal path through the maze. Incidentally, I recollect recursive algorithms in Data Structures book which take a much more complex route with a lot of back tracking to solve maze problems
Reinforcement Learning involves decision making under uncertainty which tries to maximize return over successive states.There are four main elements of a Reinforcement Learning system: a policy, a reward signal, a value function. The policy is a mapping from the states to actions or a probability distribution of actions. Every action the agent takes results in a numerical reward. The agent’s sole purpose is to maximize the reward in the long run.
The reward indicates the immediate return, a value function specifies the return in the long run. Value of a state is the expected reward that an agent can accrue.
The agent/robot takes an action in At in state St and moves to state S’t anf gets a reward Rt+1 as shown

An agent will seek to maximize the overall return as it transition across states
The expected return can be expressed as



A policy is a mapping from states to probabilities of selecting each possible action. If the agent is following policy 


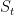
The value function of a state s under a policy 
This can be written as
![v_{\pi}(s) = E_{\pi}[G_{t} |S_{t}=s] = E_{\pi}[\sum_{k=0}^{k=Inf} \gamma^{k}R_{t+k+1}|S_{t}=s]](https://s0.wp.com/latex.php?latex=v_%7B%5Cpi%7D%28s%29+%3D+E_%7B%5Cpi%7D%5BG_%7Bt%7D+%7CS_%7Bt%7D%3Ds%5D+%3D+E_%7B%5Cpi%7D%5B%5Csum_%7Bk%3D0%7D%5E%7Bk%3DInf%7D+%5Cgamma%5E%7Bk%7DR_%7Bt%2Bk%2B1%7D%7CS_%7Bt%7D%3Ds%5D&bg=ffffff&fg=000000&s=0&c=20201002)
=
![E_{\pi}[R_{t+1} + \gamma G_{t+1} |S_{t}=s]](https://s0.wp.com/latex.php?latex=E_%7B%5Cpi%7D%5BR_%7Bt%2B1%7D+%2B+%5Cgamma+G_%7Bt%2B1%7D+%7CS_%7Bt%7D%3Ds%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![v_{\pi}(s)=\sum_{a} \pi(a|s) \sum_{s',r} p(s',r|s,a)[r+\gamma*v_{\pi}(s')]](https://s0.wp.com/latex.php?latex=v_%7B%5Cpi%7D%28s%29%3D%5Csum_%7Ba%7D+%5Cpi%28a%7Cs%29+%5Csum_%7Bs%27%2Cr%7D+p%28s%27%2Cr%7Cs%2Ca%29%5Br%2B%5Cgamma%2Av_%7B%5Cpi%7D%28s%27%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
Similarly the action value function gives the expected return when taking an action ‘a’ in state ‘s’
![q_{\pi}(s,a)= \sum_{s',r} p(s',r|s,a)[r+\gamma*\pi(a|s)q_{\pi}(s',a')]](https://s0.wp.com/latex.php?latex=q_%7B%5Cpi%7D%28s%2Ca%29%3D+%5Csum_%7Bs%27%2Cr%7D+p%28s%27%2Cr%7Cs%2Ca%29%5Br%2B%5Cgamma%2A%5Cpi%28a%7Cs%29q_%7B%5Cpi%7D%28s%27%2Ca%27%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
These are Bellman’s equation for the state value function
The Bellman equations give the equation for each of the state
The Bellman optimality equations give the optimal policy of choosing specific actions in specific states to achieve the maximum reward and reach the goal efficiently. They are given as
![v_{*}(s)=max_{a}\sum_{s',r} p(s',r|s,a)[r+\gamma*v_{*}(s')]](https://s0.wp.com/latex.php?latex=v_%7B%2A%7D%28s%29%3Dmax_%7Ba%7D%5Csum_%7Bs%27%2Cr%7D+p%28s%27%2Cr%7Cs%2Ca%29%5Br%2B%5Cgamma%2Av_%7B%2A%7D%28s%27%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![q_{*}(s,a)=\sum_{s',r} p(s',r|s,a)[r+\gamma*max_{a}q_{*}(s',a')]](https://s0.wp.com/latex.php?latex=q_%7B%2A%7D%28s%2Ca%29%3D%5Csum_%7Bs%27%2Cr%7D+p%28s%27%2Cr%7Cs%2Ca%29%5Br%2B%5Cgamma%2Amax_%7Ba%7Dq_%7B%2A%7D%28s%27%2Ca%27%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
The Bellman equations cannot be used directly in goal directed problems and dynamic programming is used instead where the value functions are computed iteratively
n this post I solve Grids using Reinforcement Learning. In the problem below the Maze has 2 end states as shown in the corner. There are four possible actions in each state up, down, right and left. If an action in a state takes it out of the grid then the agent remains in the same state. All actions have a reward of -1 while the end states have a reward of 0
This is shown as

where the reward for any transition is Rt=−1Rt=−1 except the transition to the end states at the corner which have a reward of 0. The policy is a uniform policy with all actions being equi-probable with a probability of 1/4 or 0.25
1. Gridworld-1
import numpy as np
import random
gamma = 1 # discounting rate
gridSize = 4
rewardValue = -1
terminationStates = [[0,0], [gridSize-1, gridSize-1]]
actions = [[-1, 0], [1, 0], [0, 1], [0, -1]]
numIterations = 1000
The action value provides the next state for a given action in a state and the accrued reward
def actionValue(initialPosition,action):
if initialPosition in terminationStates:
finalPosition = initialPosition
reward=0
else:
#Compute final position
finalPosition = np.array(initialPosition) + np.array(action)
reward= rewardValue
# If the action moves the finalPosition out of the grid, stay in same cell
if -1 in finalPosition or gridSize in finalPosition:
finalPosition = initialPosition
reward= rewardValue
#print(finalPosition)
return finalPosition, reward
1a. Bellman Update
# Initialize valueMap and valueMap1
valueMap = np.zeros((gridSize, gridSize))
valueMap1 = np.zeros((gridSize, gridSize))
states = [[i, j] for i in range(gridSize) for j in range(gridSize)]
def policy_evaluation(numIterations,gamma,theta,valueMap):
for i in range(numIterations):
delta=0
for state in states:
weightedRewards=0
for action in actions:
finalPosition,reward = actionValue(state,action)
weightedRewards += 1/4* (reward + gamma * valueMap[finalPosition[0],finalPosition][1])
valueMap1[state[0],state[1]]=weightedRewards
delta =max(delta,abs(weightedRewards-valueMap[state[0],state[1]]))
valueMap = np.copy(valueMap1)
if(delta < 0.01):
print(valueMap)
break
valueMap = np.zeros((gridSize, gridSize))
valueMap1 = np.zeros((gridSize, gridSize))
states = [[i, j] for i in range(gridSize) for j in range(gridSize)]
policy_evaluation(1000,1,0.001,valueMap)
Findings
The valueMap is the result of several sweeps through all the states. It can be seen that the cells in the corner state have a higher value. We can start on any cell in the grid and move in the direction which is greater than the current state and we will reach the end state
1b. Greedify
The previous alogirthm while it works is somewhat inefficient as we have to sweep over the states to compute the state value function. The approach below works on the same problem but after each computation of the value function, a greedifications takes place to ensure that the action with the highest return is selected after which the policy ππ is followed
To make the transitions clearer I also create another grid which shows the path from any cell to the end states as
‘u’ – up
‘d’ – down
‘r’ – right
‘l’ – left
Important note: If there are several alternative actions with equal value then the algorithm will break the tie randomly
valueMap = np.zeros((gridSize, gridSize))
valueMap1 = np.zeros((gridSize, gridSize))
states = [[i, j] for i in range(gridSize) for j in range(gridSize)]
pi = np.ones((gridSize,gridSize))/4
pi1 = np.chararray((gridSize, gridSize))
pi1[:] = 'a'
# Compute the value state function for the Grid
def policy_evaluate(states,actions,gamma,valueMap):
#print("iterations=",i)
for state in states:
weightedRewards=0
for action in actions:
finalPosition,reward = actionValue(state,action)
weightedRewards += 1/4* (reward + gamma * valueMap[finalPosition[0],finalPosition][1])
# Set the computed weighted rewards to valueMap1
valueMap1[state[0],state[1]]=weightedRewards
# Copy to original valueMap
valueMap = np.copy(valueMap1)
return(valueMap)
def argmax(q_values):
idx=np.argmax(q_values)
return(np.random.choice(np.where(a==a[idx])[0].tolist()))
# Compute the best action in each state
def greedify_policy(state,pi,pi1,gamma,valueMap):
q_values=np.zeros(len(actions))
for idx,action in enumerate(actions):
finalPosition,reward = actionValue(state,action)
q_values[idx] += 1/4* (reward + gamma * valueMap[finalPosition[0],finalPosition][1])
# Find the index of the action for which the q_value is
idx=q_values.argmax()
pi[state[0],state[1]]=idx
if(idx == 0):
pi1[state[0],state[1]]='u'
elif(idx == 1):
pi1[state[0],state[1]]='d'
elif(idx == 2):
pi1[state[0],state[1]]='r'
elif(idx == 3):
pi1[state[0],state[1]]='l'
def improve_policy(pi, pi1,gamma,valueMap):
policy_stable = True
for state in states:
old = pi[state].copy()
# Greedify policy for state
greedify_policy(state,pi,pi1,gamma,valueMap)
if not np.array_equal(pi[state], old):
policy_stable = False
print(pi)
print(pi1)
return pi, pi1, policy_stable
def policy_iteration(gamma, theta):
valueMap = np.zeros((gridSize, gridSize))
pi = np.ones((gridSize,gridSize))/4
pi1 = np.chararray((gridSize, gridSize))
pi1[:] = 'a'
policy_stable = False
print("here")
while not policy_stable:
valueMap = policy_evaluate(states,actions,gamma,valueMap)
pi,pi1, policy_stable = improve_policy(pi,pi1, gamma,valueMap)
return valueMap, pi,pi1
theta=0.1
valueMap, pi,pi1 = policy_iteration(gamma, theta)
Findings
From the above valueMap we can see that greedification solves this much faster as below

1c. Bellman Optimality update
The Bellman optimality update directly updates the value state function for the action that results in the maximum return in a state
gamma = 1 # discounting rate
rewardValue = -1
gridSize = 4
terminationStates = [[0,0], [gridSize-1, gridSize-1]]
actions = [[-1, 0], [1, 0], [0, 1], [0, -1]]
numIterations = 1000
valueMap = np.zeros((gridSize, gridSize))
valueMap1 = np.zeros((gridSize, gridSize))
states = [[i, j] for i in range(gridSize) for j in range(gridSize)]
pi = np.ones((gridSize,gridSize))/4
pi1 = np.chararray((gridSize, gridSize))
pi1[:] = 'a'
def bellman_optimality_update(valueMap, state, gamma):
q_values=np.zeros(len(actions))
for idx,action in enumerate(actions):
finalPosition,reward = actionValue(state,action)
q_values[idx] += 1/4* (reward + gamma * valueMap[finalPosition[0],finalPosition][1])
# Find the index of the action for which the q_value is
idx=q_values.argmax()
max = np.argmax(q_values)
valueMap[state[0],state[1]] = q_values[max]
#print(q_values[max])
def value_iteration(gamma, theta):
valueMap = np.zeros((gridSize, gridSize))
while True:
delta = 0
for state in states:
v_old=valueMap[state[0],state[1]]
bellman_optimality_update(valueMap, state, gamma)
delta = max(delta, abs(v_old - valueMap[state[0],state[1]]))
if delta < theta:
break
pi = np.ones((gridSize,gridSize))/4
for state in states:
greedify_policy(state,pi,pi1,gamma,valueMap)
print(pi)
print(pi1)
return valueMap, pi,pi1
gamma = 1
theta = 0.01
valueMap,pi,pi1=value_iteration(gamma, theta)
pi
pi1
Findings
The above valueMap shows the optimal path from any state

2.Gridworld 2
To make the problem more interesting, I created a 2nd grid which has more interesting structure as shown below <img src=”fig5.png”
The end state is the grey cell. Transitions to the black cells have a negative reward of -10. All other transitions have a reward of -1, while the end state has a reward of 0
##2a. Bellman Update
gamma = 1 # discounting rate
gridSize = 4
terminationStates = [[0,0]]
#terminationStates = [[0,0]]
actions = [[-1, 0], [1, 0], [0, 1], [0, -1]]
numIterations = 1000
rewardValue = np.zeros((gridSize,gridSize)) -1
rewardValue[0]=np.array([-1,-10,-10,-10])
rewardValue[2]=np.array([-10,-10,-10,-1])
rewardValue
def actionValue(initialPosition,action):
if initialPosition in terminationStates:
finalPosition = initialPosition
reward=0
else:
#Compute final position
finalPosition = np.array(initialPosition) + np.array(action)
# If the action moves the finalPosition out of the grid, stay in same cell
if -1 in finalPosition or gridSize in finalPosition:
finalPosition = initialPosition
reward= rewardValue[finalPosition[0],finalPosition[1]]
else:
reward= rewardValue[finalPosition[0],finalPosition[1]]
#print(finalPosition)
return finalPosition, reward
valueMap = np.zeros((gridSize, gridSize))
valueMap1 = np.zeros((gridSize, gridSize))
states = [[i, j] for i in range(gridSize) for j in range(gridSize)]
def policy_evaluation(numIterations,gamma,theta,valueMap):
for i in range(numIterations):
delta=0
#print("iterations=",i)
for state in states:
weightedRewards=0
for action in actions:
finalPosition,reward = actionValue(state,action)
#print("reward=",reward,"valueMap=",valueMap[finalPosition[0],finalPosition][1])
weightedRewards += 1/4* (reward + gamma * valueMap[finalPosition[0],finalPosition][1])
#print(weightedRewards)
valueMap1[state[0],state[1]]=weightedRewards
#print("wr=",weightedRewards,"va=",valueMap[state[0],state[1]])
delta =max(delta,abs(weightedRewards-valueMap[state[0],state[1]]))
valueMap = np.copy(valueMap1)
#print(valueMap1)
if(delta < 0.01):
print(delta)
print(valueMap)
break
valueMap = np.zeros((gridSize, gridSize))
valueMap1 = np.zeros((gridSize, gridSize))
states = [[i, j] for i in range(gridSize) for j in range(gridSize)]
policy_evaluation(1000,1,0.0001,valueMap)
2b. Greedify
valueMap = np.zeros((gridSize, gridSize))
valueMap1 = np.zeros((gridSize, gridSize))
states = [[i, j] for i in range(gridSize) for j in range(gridSize)]
pi = np.ones((gridSize,gridSize))/4
pi1 = np.chararray((gridSize, gridSize))
pi1[:] = 'a'
# Compute the value state function for the Grid
def policy_evaluate(states,actions,gamma,valueMap):
#print("iterations=",i)
for state in states:
weightedRewards=0
for action in actions:
finalPosition,reward = actionValue(state,action)
weightedRewards += 1/4* (reward + gamma * valueMap[finalPosition[0],finalPosition][1])
# Set the computed weighted rewards to valueMap1
valueMap1[state[0],state[1]]=weightedRewards
# Copy to original valueMap
valueMap = np.copy(valueMap1)
return(valueMap)
def argmax(q_values):
idx=np.argmax(q_values)
return(np.random.choice(np.where(a==a[idx])[0].tolist()))
# Compute the best action in each state
def greedify_policy(state,pi,pi1,gamma,valueMap):
q_values=np.zeros(len(actions))
for idx,action in enumerate(actions):
finalPosition,reward = actionValue(state,action)
q_values[idx] += 1/4* (reward + gamma * valueMap[finalPosition[0],finalPosition][1])
# Find the index of the action for which the q_value is
idx=q_values.argmax()
pi[state[0],state[1]]=idx
if(idx == 0):
pi1[state[0],state[1]]='u'
elif(idx == 1):
pi1[state[0],state[1]]='d'
elif(idx == 2):
pi1[state[0],state[1]]='r'
elif(idx == 3):
pi1[state[0],state[1]]='l'
def improve_policy(pi, pi1,gamma,valueMap):
policy_stable = True
for state in states:
old = pi[state].copy()
# Greedify policy for state
greedify_policy(state,pi,pi1,gamma,valueMap)
if not np.array_equal(pi[state], old):
policy_stable = False
print(pi)
print(pi1)
return pi, pi1, policy_stable
def policy_iteration(gamma, theta):
valueMap = np.zeros((gridSize, gridSize))
pi = np.ones((gridSize,gridSize))/4
pi1 = np.chararray((gridSize, gridSize))
pi1[:] = 'a'
policy_stable = False
print("here")
while not policy_stable:
valueMap = policy_evaluate(states,actions,gamma,valueMap)
pi,pi1, policy_stable = improve_policy(pi,pi1, gamma,valueMap)
return valueMap, pi,pi1
theta=0.1
valueMap, pi,pi1 = policy_iteration(gamma, theta)
## 2c. Bellman Optimality update
gamma = 1 # discounting rate
rewardValue = np.zeros((gridSize,gridSize)) -1
rewardValue[0]=np.array([-1,-10,-10,-10])
rewardValue[2]=np.array([-10,-10,-10,-1])
rewardValue
gridSize = 4
terminationStates = [[0,0]]
actions = [[-1, 0], [1, 0], [0, 1], [0, -1]]
numIterations = 1000
valueMap = np.zeros((gridSize, gridSize))
valueMap1 = np.zeros((gridSize, gridSize))
states = [[i, j] for i in range(gridSize) for j in range(gridSize)]
pi = np.ones((gridSize,gridSize))/4
pi1 = np.chararray((gridSize, gridSize))
pi1[:] = 'a'
2c. Bellman Optimality Update
def bellman_optimality_update(valueMap, state, gamma):
q_values=np.zeros(len(actions))
for idx,action in enumerate(actions):
finalPosition,reward = actionValue(state,action)
q_values[idx] += 1/4* (reward + gamma * valueMap[finalPosition[0],finalPosition][1])
# Find the index of the action for which the q_value is
idx=q_values.argmax()
max = np.argmax(q_values)
valueMap[state[0],state[1]] = q_values[max]
#print(q_values[max])
def value_iteration(gamma, theta):
valueMap = np.zeros((gridSize, gridSize))
while True:
delta = 0
for state in states:
v_old=valueMap[state[0],state[1]]
bellman_optimality_update(valueMap, state, gamma)
delta = max(delta, abs(v_old - valueMap[state[0],state[1]]))
if delta < theta:
break
pi = np.ones((gridSize,gridSize))/4
for state in states:
greedify_policy(state,pi,pi1,gamma,valueMap)
print(pi)
print(pi1)
return valueMap, pi,pi1
gamma = 1
theta = 0.000001
valueMap,pi,pi1=value_iteration(gamma, theta)
pi
pi1
chararray([[b'u', b'l', b'd', b'd'],
[b'u', b'l', b'l', b'l'],
[b'u', b'u', b'u', b'u'],
[b'r', b'r', b'r', b'u']], dtype='|S1')
Findings
The above shows the path from any cell to the stop cell as

3. Another maze
This is the third grid world which I create where the green cell is the end state and has a reward of 0. Transitions to the black cell will receive a reward of -10 and all other transitions will receive a reward of -1

gamma = 1 # discounting rate
gridSize = 5
terminationStates = [[2,2]]
actions = [[-1, 0], [1, 0], [0, 1], [0, -1]]
numIterations = 1000
rewardValue = np.zeros((gridSize,gridSize)) -1
rewardValue[1]=np.array([-1,-10,-1,-10,-1])
rewardValue[3]=np.array([-1,-10,-1,-10,-1])
rewardValue
3a. Bellman Update
def actionValue(initialPosition,action):
if initialPosition in terminationStates:
finalPosition = initialPosition
reward=0
else:
#Compute final position
finalPosition = np.array(initialPosition) + np.array(action)
# If the action moves the finalPosition out of the grid, stay in same cell
if -1 in finalPosition or gridSize in finalPosition:
finalPosition = initialPosition
reward= rewardValue[finalPosition[0],finalPosition[1]]
else:
reward= rewardValue[finalPosition[0],finalPosition[1]]
#print(finalPosition)
return finalPosition, reward
valueMap = np.zeros((gridSize, gridSize))
valueMap1 = np.zeros((gridSize, gridSize))
states = [[i, j] for i in range(gridSize) for j in range(gridSize)]
def policy_evaluation(numIterations,gamma,theta,valueMap):
for i in range(numIterations):
delta=0
#print("iterations=",i)
for state in states:
weightedRewards=0
for action in actions:
finalPosition,reward = actionValue(state,action)
#print("reward=",reward,"valueMap=",valueMap[finalPosition[0],finalPosition][1])
weightedRewards += 1/4* (reward + gamma * valueMap[finalPosition[0],finalPosition][1])
#print(weightedRewards)
valueMap1[state[0],state[1]]=weightedRewards
#print("wr=",weightedRewards,"va=",valueMap[state[0],state[1]])
delta =max(delta,abs(weightedRewards-valueMap[state[0],state[1]]))
valueMap = np.copy(valueMap1)
#print(valueMap1)
if(delta < 0.01):
print(delta)
print(valueMap)
break
valueMap = np.zeros((gridSize, gridSize))
valueMap1 = np.zeros((gridSize, gridSize))
states = [[i, j] for i in range(gridSize) for j in range(gridSize)]
policy_evaluation(1000,1,0.0001,valueMap)
3b. Greedify
valueMap = np.zeros((gridSize, gridSize))
valueMap1 = np.zeros((gridSize, gridSize))
states = [[i, j] for i in range(gridSize) for j in range(gridSize)]
pi = np.ones((gridSize,gridSize))/4
pi1 = np.chararray((gridSize, gridSize))
pi1[:] = 'a'
# Compute the value state function for the Grid
def policy_evaluate(states,actions,gamma,valueMap):
#print("iterations=",i)
for state in states:
weightedRewards=0
for action in actions:
finalPosition,reward = actionValue(state,action)
weightedRewards += 1/4* (reward + gamma * valueMap[finalPosition[0],finalPosition][1])
# Set the computed weighted rewards to valueMap1
valueMap1[state[0],state[1]]=weightedRewards
# Copy to original valueMap
valueMap = np.copy(valueMap1)
return(valueMap)
def argmax(q_values):
idx=np.argmax(q_values)
return(np.random.choice(np.where(a==a[idx])[0].tolist()))
# Compute the best action in each state
def greedify_policy(state,pi,pi1,gamma,valueMap):
q_values=np.zeros(len(actions))
for idx,action in enumerate(actions):
finalPosition,reward = actionValue(state,action)
q_values[idx] += 1/4* (reward + gamma * valueMap[finalPosition[0],finalPosition][1])
# Find the index of the action for which the q_value is
idx=q_values.argmax()
pi[state[0],state[1]]=idx
if(idx == 0):
pi1[state[0],state[1]]='u'
elif(idx == 1):
pi1[state[0],state[1]]='d'
elif(idx == 2):
pi1[state[0],state[1]]='r'
elif(idx == 3):
pi1[state[0],state[1]]='l'
def improve_policy(pi, pi1,gamma,valueMap):
policy_stable = True
for state in states:
old = pi[state].copy()
# Greedify policy for state
greedify_policy(state,pi,pi1,gamma,valueMap)
if not np.array_equal(pi[state], old):
policy_stable = False
print(pi)
print(pi1)
return pi, pi1, policy_stable
def policy_iteration(gamma, theta):
valueMap = np.zeros((gridSize, gridSize))
pi = np.ones((gridSize,gridSize))/4
pi1 = np.chararray((gridSize, gridSize))
pi1[:] = 'a'
policy_stable = False
print("here")
while not policy_stable:
valueMap = policy_evaluate(states,actions,gamma,valueMap)
pi,pi1, policy_stable = improve_policy(pi,pi1, gamma,valueMap)
return valueMap, pi,pi1
theta=0.1
valueMap, pi,pi1 = policy_iteration(gamma, theta)
gamma = 1 # discounting rate
gridSize=5
rewardValue = np.zeros((gridSize,gridSize)) -1
rewardValue = np.zeros((gridSize,gridSize)) -1
rewardValue[1]=np.array([-1,-10,-1,-10,-1])
rewardValue[3]=np.array([-1,-10,-1,-10,-1])
print(rewardValue)
terminationStates = [[2,2]]
actions = [[-1, 0], [1, 0], [0, 1], [0, -1]]
numIterations = 1000
3c. Bellman Optimality Update
valueMap = np.zeros((gridSize, gridSize))
valueMap1 = np.zeros((gridSize, gridSize))
states = [[i, j] for i in range(gridSize) for j in range(gridSize)]
pi = np.ones((gridSize,gridSize))/4
pi1 = np.chararray((gridSize, gridSize))
pi1[:] = 'a'
def bellman_optimality_update(valueMap, state, gamma):
q_values=np.zeros(len(actions))
for idx,action in enumerate(actions):
finalPosition,reward = actionValue(state,action)
q_values[idx] += 1/4* (reward + gamma * valueMap[finalPosition[0],finalPosition][1])
# Find the index of the action for which the q_value is
idx=q_values.argmax()
max = np.argmax(q_values)
valueMap[state[0],state[1]] = q_values[max]
#print(q_values[max])
def value_iteration(gamma, theta):
valueMap = np.zeros((gridSize, gridSize))
while True:
delta = 0
for state in states:
v_old=valueMap[state[0],state[1]]
bellman_optimality_update(valueMap, state, gamma)
delta = max(delta, abs(v_old - valueMap[state[0],state[1]]))
if delta < theta:
break
pi = np.ones((gridSize,gridSize))/4
for state in states:
greedify_policy(state,pi,pi1,gamma,valueMap)
print(pi)
print(pi1)
return valueMap, pi,pi1
gamma = 1
theta = 0.000001
valueMap,pi,pi1=value_iteration(gamma, theta)
pi
pi1
chararray([[b'd', b'r', b'd', b'l', b'd'],
[b'd', b'd', b'd', b'd', b'd'],
[b'r', b'r', b'u', b'l', b'l'],
[b'u', b'u', b'u', b'u', b'u'],
[b'u', b'r', b'u', b'l', b'u']], dtype='|S1')
Findings
We can see that the Bellman Optimality Update correctly finds the path the to end node which we can see from the valueMap1 above which is

Conclusion:
We can see how with the Bellman equations implemented iteratively with dynamic programming we can solve mazes of arbitrary shapes and complexities as long as we correctly choose the reward for the transitions
References
1. Reinforcement learning – An introduction by Richard S. Sutton and Andrew G Barto
2. Reinforcement learning (RL) 101 with Python Blog by Gerard Martinez
3. Reinforcement Learning Demystified: Solving MDPs with Dynamic Programming Blog by Mohammed Ashraf
You may also like
1. My book ‘Deep Learning from first principles:Second Edition’ now on Amazon
2. Big Data-4: Webserver log analysis with RDDs, Pyspark, SparkR and SparklyR
3. Practical Machine Learning with R and Python – Part 3
3. Pitching yorkpy…on the middle and outside off-stump to IPL – Part 2
4. Sixer – R package cricketr’s new Shiny avatar
5. Natural language processing: What would Shakespeare say?
6. Getting started with Tensorflow, Keras in Python and R
To see all posts click Index of posts
