It is carnival time again as IPL 2023 is underway!! The new GooglyPlusPlus now includes AI/ML models for computing ball-by-ball Win Probability of matches and each individual player’s Win Probability Contribution (WPC). GooglyPlusPlus uses 2 ML models
Deep Learning (Tensorflow) – accuracy : 0.8584
Logistic Regression (glmnet-tidymodels) : 0.728
Besides, as before, GooglyPlusPlus will also include the usual near real-time analytics with the Shiny app being automatically updated with the previous day’s match data.
Note: The Win Probability Computation can also be done on a live feed of streaming data. Since, I don’t have access to live feeds, the app will show how Win Probability changed during the course of completed matches. For more details on Win Probability and Win Probability Contribution see my posts
GooglyPlusPlus has been also updated with all the latest T20 league’s match data. It includes data from BBL 2022, NTB 2022, CPL 2022, PSL 2023, ICC T20 2022 and now IPL 2023.
GooglyPlusPlus has the following functionality
Batsman tab: For detailed analysis of batsmen
Bowler tab: For detailed analysis of bowlers
Match tab: Analysis of individual matches, plot of Runs vs SR, Wickets vs ER in power play, middle and death overs, Win Probability Analysis of teams and Win Probability Contribution of players
Head-to-head tab: Detailed analysis of team-vs-team batting/bowling scorecard, batting, bowling performances, performances in power play, middle and death overs
Team performance tab: Analysis of team-vs-all other teams with batting /bowling scorecard, batting, bowling performances, performances in power play, middle and death overs
Optimisation tab: Allows one to pit batsmen vs bowlers and vice-versa. This tab also uses integer programming to optimise batting and bowling lineup
Batting analysis tab: Ranks batsmen using Runs or SR. Also plots performances of batsmen in power play, middle and death overs and plots them in a 4×4 grid
Bowling analysis tab: Ranks bowlers based on Wickets or ER. Also plots performances of bowlers in power play, middle and death overs and plots them in a 4×4 grid
Also note all these tabs and features are available for all T20 formats namely IPL, Intl. T20 (men, women), BBL, NTB, PSL, CPL, SSM.
Important note: It is possible, that at times, the Win Probability (Deep Learning) for some recent IPL matches will give an error. This is because I need to rebuild the models on a daily basis as the matches use player embeddings and there are new players. While I will definitely rebuild the models on weekends and whenever I find time, you may have to bear with this error occasionally.
Note: All charts are interactive, which means that you can hover, zoom-in, zoom-out, pan etc on the charts
The latest avatar of GooglyPlusPlus2023 is based on my R package yorkr with data from Cricsheet.
Follow me on twitter for daily highlights @tvganesh_85
GooglyPlusPlus can analyse players, matches, teams, rank, compute win probability and much more.
Included below are some random analyses of IPL 2023 matches so far
A) Chennai Super Kings vs Gujarat Titans – 31 Mar 2023
GT won by 5 wickets ( 4 balls remaining)
a) Worm Wicket Chart
b) Ball-by-ball Win Probability (Logistic Regression) (side-by-side)
This model shows that CSK had the upper hand in the 2nd last over, before it changed to GT. More details on Win Probability and Win Probability Contribution in the posts given by the links above.
c) b) Ball-by-ball Win Probability (Logistic Regression) (overlapping)
Here the ball-by-ball win probability is overlapped. CSK and GT both had nearly the same probability of winning in the 2nd last over before GT edges CSK out
B) Punjab Kings vs Rajasthan Royals – 05 Apr 2023
This was a another closely fought match. PBKS won by 5 runs
a) Worm wicket chart
b) Batting partnerships
Shikhar Dhawan scored 86 runs
c) Ball-by-ball Win Probability using Deep Learning (overlapping)
PBKS was generally ahead in the win probability race
d) Batsman Win Probability Contribution
This plot shows how the different batsmen contributed to the Win Probability. We can see that Shikhar Dhawan has a highest win probability. He played a very sensible innings. Also it appears that there is no difference between Prabhsimran Singh and others, though he score 60 runs. This computation is based on when they come to bat and how the win probability changes when they get dismissed, as seen in the 2nd chart
C) Delhi Capitals vs Gujarat Titans – 4 Apr 2023
GT won by 6 wickets (11 balls remaining)
a) Worm wicket chart
b) Runs scored across 20 overs
c) Runs vs SR plot
d) Batting scorecard (Gujarat Titans)
e) Batsman Win Probability Contribution (Gujarat Titans)
Miller has a higher percentage in the Win Contribution than Sai Sudershan who held the innings together.Strange are the ways of the ML models!!
D) Sunrisers Hyderabad vs Lucknow Supergiants ( 7 Apr 2023)
LSG won by 5 wickets (24 balls left). SRH were bamboozled by the pitch while LSG was able to cruise along
a) Worm wicket chart
b) Wickets vs ER plot
c) Wickets across 20 overs
d) Ball-by-ball win probability using Deep Learning (overlapping)
e) Bowler Win Probability Contribution (LSG)
Bishnoi has a higher win probability contribution than Krunal, though he just took 1 wicket to Krunal’s 3 wickets. This is based on how the Win Probability changed at that point in the game.
The above set of plots are just a random sample.
Note: There are 8 tabs each for 9 T20 leagues (BBL, CPL, T20 (men), T20 (women), IPL, PSL, NTB, SSM, WBB). So there are a lot more detailed charts/analses.
In this post, I compute each batsman’s or bowler’s Win Probability Contribution (WPC) in a T20 match. This metric captures by how much the player (batsman or bowler) changed/impacted the Win Probability of the T20 match. For this computation I use my machine learning models, I had created earlier, which predicts the ball-by-ball win probability as the T20 match progresses through the 2 innings of the match.
In the picture snippet below, you can see how the win probability changes ball-by-ball for each batsman for a T20 match between CSK vs LSG- 31 Mar 2022
In my previous posts I had created several Machine Learning models. In order to compute the player’s Win Probability contribution in this post, I have used the following ML models
The batsman’s or bowler’s win probability contribution changes ball-by=ball. The player’s contribution is calculated as the difference in win probability when the batsman faces the 1st ball in his innings and the last ball either when is out or the innings comes to an end. If the difference is +ve the the player has had a positive impact, and likewise for negative contribution. Similarly, for a bowler, it is the win probability when he/she comes into bowl till, the last delivery he/she bowls
Note: The Win Probability Contribution does not have any relation to the how much runs or at what strike rate the batsman scored the runs. Rather the model computes different win probability for each player, based on his/her embedding, the ball in the innings and six other feature vectors like runs, run rate, runsMomentum etc. These values change for every ball as seen in the table above. Also, this is not continuous. The 2 ML models determine the Win Probability for a specific player, ball and the context in the match.
This metric is similar to Win Probability Added (WPA) used in Sabermetrics for baseball. Here is the definition of WPA from Fangraphs “Win Probability Added (WPA) captures the change in Win Expectancy from one plate appearance to the next and credits or debits the player based on how much their action increased their team’s odds of winning.” This article in Fangraphs explains in detail how this computation is done.
In this post I have added 4 new function to my R package yorkr.
batsmanWinProbLR – batsman’s win probability contribution based on glmnet (Logistic Regression)
bowlerWinProbLR – bowler’s win probability contribution based on glmnet (Logistic Regression)
batsmanWinProbDL – batsman’s win probability contribution based on Deep Learning Model
bowlerWinProbDL – bowlerWinProbLR – bowler’s win probability contribution based on Deep Learning
Hence there are 4 additional features in GooglyPlusPlus based on the above 4 functions. In addition I have also updated
-winProbLR (overLap) function to include the names of batsman when they come to bat and when they get out or the innings comes to an end, based on Logistic Regression
-winProbDL(overLap) function to include the names of batsman when they come to bat and when they get out based on Deep Learning
Hence there are 6 new features in this version of GooglyPlusPlus.
Note: All these new 6 features are available for all 9 formats of T20 in GooglyPlusPlus namely
a) IPL b) BBL c) NTB d) PSL e) Intl, T20 (men) f) Intl. T20 (women) g) WBB h) CSL i) SSM
Check out the latest version of GooglyPlusPlus at gpp2023-2
Note: The data for GooglyPlusPlus comes from Cricsheet and the Shiny app is based on my R package yorkr
A) Chennai SuperKings vs Delhi Capitals – 04 Oct 2021
To understand Win Probability Contribution better let us look at Chennai Super Kings vs Delhi Capitals match on 04 Oct 2021
This was closely fought match with fortunes swinging wildly. If we take a look at the Worm wicket chart of this match
a) Worm Wicket chart – CSK vs DC – 04 Oct 2021
Delhi Capitals finally win the match
b) Win Probability Logistic Regression (side-by-side) – CSK vs DC – 4 Oct 2021
Plotting how win probability changes over the course of the match using Logistic Regression Model
In this match Delhi Capitals won. The batting scorecard of Delhi Capitals
c) Batting Scorecard of Delhi Capitals – CSK vs DC – 4 Oct 2021
d) Win Probability Logistic Regression (Overlapping) – CSK vs DC – 4 Oct 2021
The Win Probability LR (overlapping) shows the probability function of both teams superimposed over one another. The plot includes when a batsman came into to play and when he got out. This is for both teams. This looks a little noisy, but there is a way to selectively display the change in Win Probability for each team. This can be done , by clicking the 3 arrows (orange or blue) from top to bottom. First double-click the team CSK or DC, then click the next 2 items (blue,red or black,grey) Sorry the legends don’t match the colors! 😦
Below we can see how the win probability changed for Delhi Capitals during their innings, as batsmen came into to play. See below
e)Batsman Win Probability contribution:DC – CSK vs DC – 4 Oct 2021
Computing the individual batsman’s Win Contribution and plotting we have. Hetmeyer has a higher Win Probability contribution than Shikhar Dhawan depsite scoring fewer runs
f) Bowler’s Win Probability contribution :CSK – CSK vs DC – 4 Oct 2021
We can also check the Win Probability of the bowlers. So for e.g the CSK bowlers and which bowlers had the most impact. Moeen Ali has the least impact in this match
B) Intl. T20 (men) Australia vs India – 25 Sep 2022
a) Worm wicket chart – Australia vs India – 25 Sep 2022
This was another close match in which India won with the penultimate ball
b) Win Probability based on Deep Learning model (side-by-side) –Australia vs India – 25 Sep 2022
c) Win Probability based on Deep Learning model (overlapping) –Australia vs India – 25 Sep 2022
The plot below shows how the Win Probability of the teams varied across the 20 overs. The 2 Win Probability distributions are superimposed over each other
d) Batsman Win Probability Contribution : India – Australia vs India – 25 Sep 2022
Selectively choosing the India Win Probability plot by double-clicking legend ‘India’ on the right , followed by single click of black, grey legend we have
We see that Kohli, Suryakumar Yadav have good contribution to the Win Probability
e) Plotting the Runs vs Strike Rate:India – Australia vs India – 25 Sep 2022
f) Batsman’s Win Probability Contribution-Australia vs India – 25 Sep 2022
Finally plotting the Batsman’s Win Probability Contribution
Interestingly, Kohli has a greater Win Probability Contribution than SKY, though SKY scored more runs at a better strike rate. As mentioned above, the Win Probability is context dependent and also depends on past performances of the player (batsman, bowler)
Finally let us look at
C) India vs England Intll T20 Women (11 July 2021)
a) Worm wicket chart – India vs England Intl. T20 Women (11 July 2021)
India won this T20 match by 8 runs
b) Win Probability using the Logistic Regression Model –India vs England Intl. T20 Women (11 July 2021)
c) Win Probability with the DL model –India vs England Intl. T20 Women (11 July 2021)
d) Bowler Win Probability Contribution with the LR model–India vs England Intl. T20 Women (11 July 2021)
e) Bowler Win Contribution with the DL model–India vs England Intl. T20 Women (11 July 2021)
Go ahead and try out the latest version of GooglyPlusPlus
In my previous post Computing Win Probability of T20 matches I had discussed various approaches on computing Win Probability of T20 matches. I had created ML models with glmnet and random forest using TidyModels. This was what I had achieved
glmnet : accuracy – 0.67 and sensitivity/specificity – 0.68/0.65
random forest : accuracy – 0.737 and roc_auc- 0.834
DL model with Keras in Python : accuracy – 0.73
I wanted to see if the performance of the models could be further improved. I got a suggestion from a AI/DL whizkid, who is close to me, to include embeddings for batsmen and bowlers. He felt that win percentage is influenced by which batsman faces which bowler.
So, I started to explore this idea. Embeddings can be used to convert categorical variables to a vector of continuous floating point numbers.Fortunately R’s Tidymodels, has a convenient functionality to create embeddings. By including embeddings for batsman, bowler the performance of my ML models improved vastly. Now the performance is
glmnet : accuracy – 0.728 and roc_auc – 0.81
random forest : accuracy – 0.927 and roc_auc – 0.98
mlp-dnn :accuracy – 0.762 and roc_auc – 0.854
As can be seem there is almost a 20% increase in accuracy with random forests with embeddings over the model without embeddings. Moreover, the feature importance which is plotted below shows that the bowler and batsman embeddings have a significant influence on the Win Probability
Note: The data for this analysis is taken from Cricsheet and has been processed with my R package yorkr.
A. Win Probability using GLM with penalty and player embeddings
Here Generalised Linear Model (GLMNET) for Logistic Regression is used. In the GLMNET the regularisation path is computed for the lasso or elastic net penalty at a grid of values for the regularisation parameter lambda. glmnet is extremely fast and gave an accuracy of 0.72 for an roc_auc of 0.81 with batsman, bowler embeddings. This was good improvement over my earlier implementation with glmnet without the batsman & bowler embeddings which had a
Read the data
a) Read the data from 9 T20 leagues (BBL, CPL, IPL, NTB, PSL, SSM, T20 Men, T20 Women, WBB) and create a single data frame of ball-by-ball data. Display the data frame
b) Split to training, validation and test sets. The dataset is initially split into training and test in the ratio 80%:20%. The training data is again split into training and validation in the ratio 80:20
4) Create a Logistic Regression Workflow by adding the GLM model and the recipe
5) Create grid of elastic penalty values for regularisation
6) Train all 30 models
7) Plot the ROC of the model against the penalty
# Use all 12 cores
cores <- parallel::detectCores()
cores
# Create a Logistic Regression model with penalty
lr_mod <-
logistic_reg(penalty = tune(), mixture = 1) %>%
set_engine("glmnet",num.threads = cores)
# Create pre-processing recipe
lr_recipe <-
recipe(isWinner ~ ., data = df_other) %>%
step_embed(batsman,bowler, outcome = vars(isWinner)) %>% step_normalize(ballNum,ballsRemaining,runs,runRate,numWickets,runsMomentum,perfIndex)
# Set the workflow by adding the GLM model with the recipe
lr_workflow <-
workflow() %>%
add_model(lr_mod) %>%
add_recipe(lr_recipe)
# Create a grid for the elastic net penalty
lr_reg_grid <- tibble(penalty = 10^seq(-4, -1, length.out = 30))
lr_reg_grid %>% top_n(-5)
# A tibble: 5 × 1
penalty
<dbl>
1 0.0001
2 0.000127
3 0.000161
4 0.000204
5 0.000259
lr_reg_grid %>% top_n(5) # highest penalty values
# A tibble: 5 × 1
penalty
<dbl>
1 0.0386
2 0.0489
3 0.0621
4 0.0788
5 0.1
# Train 30 penalized models
lr_res <-
lr_workflow %>%
tune_grid(val_set,
grid = lr_reg_grid,
control = control_grid(save_pred = TRUE),
metrics = metric_set(accuracy,roc_auc))
# Plot the penalty versus ROC
lr_plot <-
lr_res %>%
collect_metrics() %>%
ggplot(aes(x = penalty, y = mean)) +
geom_point() +
geom_line() +
ylab("Area under the ROC Curve") +
scale_x_log10(labels = scales::label_number())
lr_plot
The Penalty vs ROC plot is shown below
8) Display the ROC_AUC of the top models with the penalty
9) Select the model with the best ROC_AUC and the associated penalty. It can be seen the best mean ROC_AUC is 0.81 and the associated penalty is 0.000530
top_models <-
lr_res %>%
show_best("roc_auc", n = 15) %>%
arrange(penalty)
top_models
# A tibble: 15 × 7
penalty .metric .estimator mean n std_err .config
<dbl> <chr> <chr> <dbl> <int> <dbl> <chr>
1 0.0001 roc_auc binary 0.810 1 NA Preprocessor1_Model01
2 0.000127 roc_auc binary 0.810 1 NA Preprocessor1_Model02
3 0.000161 roc_auc binary 0.810 1 NA Preprocessor1_Model03
4 0.000204 roc_auc binary 0.810 1 NA Preprocessor1_Model04
5 0.000259 roc_auc binary 0.810 1 NA Preprocessor1_Model05
6 0.000329 roc_auc binary 0.810 1 NA Preprocessor1_Model06
7 0.000418 roc_auc binary 0.810 1 NA Preprocessor1_Model07
8 0.000530 roc_auc binary 0.810 1 NA Preprocessor1_Model08
9 0.000672 roc_auc binary 0.810 1 NA Preprocessor1_Model09
10 0.000853 roc_auc binary 0.810 1 NA Preprocessor1_Model10
11 0.00108 roc_auc binary 0.810 1 NA Preprocessor1_Model11
12 0.00137 roc_auc binary 0.810 1 NA Preprocessor1_Model12
13 0.00174 roc_auc binary 0.809 1 NA Preprocessor1_Model13
14 0.00221 roc_auc binary 0.809 1 NA Preprocessor1_Model14
15 0.00281 roc_auc binary 0.809 1 NA Preprocessor1_Model15
#Picking the best model and the corresponding penalty
lr_best <-
lr_res %>%
collect_metrics() %>%
arrange(penalty) %>%
slice(8)
lr_best
# A tibble: 1 × 7
penalty .metric .estimator mean n std_err .config
<dbl> <chr> <chr> <dbl> <int> <dbl> <chr>
1 0.000530 roc_auc binary 0.810 1 NA Preprocessor1_Model08
# Collect predictions and generate the AUC curve
lr_auc <-
lr_res %>%
collect_predictions(parameters = lr_best) %>%
roc_curve(isWinner, .pred_0) %>%
mutate(model = "Logistic Regression")
autoplot(lr_auc)
7) Plot the Area under the Curve (AUC).
10) Build the final model with the best LR parameters value as found in lr_best
a) The best performance was for a penalty of 0.000530
b) The accuracy achieved is 0.72. Clearly using the embeddings for batsman, bowlers improves on the performance of the GLM model without the embeddings. The accuracy achieved was 0.72 whereas previously it was 0.67 see (Computing Win Probability of T20 Matches)
c) Create a fit with the best parameters
d) The accuracy is 72.8% and the ROC_AUC is 0.813
# Create a model with the penalty for best ROC_AUC
last_lr_mod <-
logistic_reg(penalty = 0.000530, mixture = 1) %>%
set_engine("glmnet",num.threads = cores,importance = "impurity")
#Update the workflow with this model
last_lr_workflow <-
lr_workflow %>%
update_model(last_lr_mod)
#Create a fit
set.seed(345)
last_lr_fit <-
last_lr_workflow %>%
last_fit(splits)
#Generate accuracy, roc_auc
last_lr_fit %>%
collect_metrics()
# A tibble: 2 × 4
.metric .estimator .estimate .config
<chr> <chr> <dbl> <chr>
1 accuracy binary 0.728 Preprocessor1_Model1
2 roc_auc binary 0.813 Preprocessor1_Model1
11) Plot the feature importance
It can be seen that bowler and batsman embeddings are the most significant for the prediction followed by runRate.
Chennai Super Kings-Lucknow Super Giants-2022-03-31
16a) The corresponding Worm-wicket graph for this match is as below
Chennai Super Kings-Lucknow Super Giants-2022-03-31
B) Win Probability using Random Forest with player embeddings
In the 2nd approach I use Random Forest with batsman and bowler embeddings. The performance of the model with embeddings is quantum jump from the earlier performance without embeddings. However, the random forest is also computationally intensive.
1) Read the data
a) Read the data from 9 T20 leagues (BBL, CPL, IPL, NTB, PSL, SSM, T20 Men, T20 Women, WBB) and create a single data frame of ball-by-ball data. Display the data frame
2) Create training.validation and test sets
b) Split to training, validation and test sets. The dataset is initially split into training and test in the ratio 80%:20%. The training data is again split into training and validation in the ratio 80:20
library(dplyr)
library(caret)
library(e1071)
library(ggplot2)
library(tidymodels)
library(tidymodels)
library(embed)
# Helper packages
library(readr) # for importing data
library(vip)
library(ranger)
# Read all the 9 T20 leagues
df1=read.csv("output3/matchesBBL3.csv")
df2=read.csv("output3/matchesCPL3.csv")
df3=read.csv("output3/matchesIPL3.csv")
df4=read.csv("output3/matchesNTB3.csv")
df5=read.csv("output3/matchesPSL3.csv")
df6=read.csv("output3/matchesSSM3.csv")
df7=read.csv("output3/matchesT20M3.csv")
df8=read.csv("output3/matchesT20W3.csv")
df9=read.csv("output3/matchesWBB3.csv")
# Bind into a single dataframe
df=rbind(df1,df2,df3,df4,df5,df6,df7,df8,df9)
set.seed(123)
df$isWinner = as.factor(df$isWinner)
#Split data into training, validation and test sets
splits <- initial_split(df,prop = 0.80)
df_other <- training(splits)
df_test <- testing(splits)
set.seed(234)
val_set <- validation_split(df_other, prop = 0.80)
val_set
2) Create a Random Forest model tuning for number of predictor nodes at each decision node (mtry) and minimum number of predictor nodes (min_n)
3) Use the ranger engine and set up for classification
4) Set up the recipe and include batsman and bowler embeddings
5) Create a workflow and add the recipe and the random forest model with the tuning parameters
# Use all 12 cores parallely
cores <- parallel::detectCores()
cores
[1] 12
# Create the random forest model with mtry and min as tuning parameters
rf_mod <-
rand_forest(mtry = tune(), min_n = tune(), trees = 1000) %>%
set_engine("ranger", num.threads = cores) %>%
set_mode("classification")
# Setup the recipe with batsman and bowler embeddings
rf_recipe <-
recipe(isWinner ~ ., data = df_other) %>%
step_embed(batsman,bowler, outcome = vars(isWinner))
# Create the random forest workflow
rf_workflow <-
workflow() %>%
add_model(rf_mod) %>%
add_recipe(rf_recipe)
rf_mod
# show what will be tuned
extract_parameter_set_dials(rf_mod)
set.seed(345)
# specify which values meant to tune
# Build the model
rf_res <-
rf_workflow %>%
tune_grid(val_set,
grid = 10,
control = control_grid(save_pred = TRUE),
metrics = metric_set(accuracy,roc_auc))
# Pick the best roc_auc and the associated tuning parameters
rf_res %>%
show_best(metric = "roc_auc")
# A tibble: 5 × 8
mtry min_n .metric .estimator mean n std_err .config
<int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
1 4 4 roc_auc binary 0.980 1 NA Preprocessor1_Model08
2 9 8 roc_auc binary 0.979 1 NA Preprocessor1_Model03
3 8 16 roc_auc binary 0.974 1 NA Preprocessor1_Model10
4 7 22 roc_auc binary 0.969 1 NA Preprocessor1_Model09
5 5 19 roc_auc binary 0.969 1 NA Preprocessor1_Model06
rf_res %>%
show_best(metric = "accuracy")
# A tibble: 5 × 8
mtry min_n .metric .estimator mean n std_err .config
<int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
1 4 4 accuracy binary 0.927 1 NA Preprocessor1_Model08
2 9 8 accuracy binary 0.926 1 NA Preprocessor1_Model03
3 8 16 accuracy binary 0.915 1 NA Preprocessor1_Model10
4 7 22 accuracy binary 0.906 1 NA Preprocessor1_Model09
5 5 19 accuracy binary 0.904 1 NA Preprocessor1_Model0
6) Select all models with the best roc_auc. It can be seen that the best roc_auc is 0.980 for mtry=4 and min_n=4
7) Get the model with the highest accuracy. The highest accuracy achieved is 0.927 or 92.7. This accuracy is also for mtry=4 and min_n=4
# Pick the best roc_auc and the associated tuning parameters
rf_res %>%
show_best(metric = "roc_auc")
# A tibble: 5 × 8
mtry min_n .metric .estimator mean n std_err .config
<int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
1 4 4 roc_auc binary 0.980 1 NA Preprocessor1_Model08
2 9 8 roc_auc binary 0.979 1 NA Preprocessor1_Model03
3 8 16 roc_auc binary 0.974 1 NA Preprocessor1_Model10
4 7 22 roc_auc binary 0.969 1 NA Preprocessor1_Model09
5 5 19 roc_auc binary 0.969 1 NA Preprocessor1_Model06
# Display the accuracy of the models in descending order and the parameters
rf_res %>%
show_best(metric = "accuracy")
# A tibble: 5 × 8
mtry min_n .metric .estimator mean n std_err .config
<int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
1 4 4 accuracy binary 0.927 1 NA Preprocessor1_Model08
2 9 8 accuracy binary 0.926 1 NA Preprocessor1_Model03
3 8 16 accuracy binary 0.915 1 NA Preprocessor1_Model10
4 7 22 accuracy binary 0.906 1 NA Preprocessor1_Model09
5 5 19 accuracy binary 0.904 1 NA Preprocessor1_Model0
8) Select the model with the best parameters for accuracy mtry=4 and min_n=4. For this the accuracy is 0.927. For this configuration the roc_auc is also the best at 0.980
9) Plot the Area Under the Curve (AUC). It can be seen that this model performs really well and it hugs the top left.
# Pick the best model
rf_best <-
rf_res %>%
select_best(metric = "accuracy")
# The best model has mtry=4 and min=4
rf_best
mtry min_n .config
<int> <int> <chr>
1 4 4 Preprocessor1_Model08
#Plot AUC
rf_auc <-
rf_res %>%
collect_predictions(parameters = rf_best) %>%
roc_curve(isWinner, .pred_0) %>%
mutate(model = "Random Forest")
autoplot(rf_auc)
10) Create the final model with the best parameters
11) Execute the final fit
12) Plot feature importance, The bowler and batsman embedding followed by perfIndex and runRate are features that contribute the most to the Win Probability
16) Computing Win Probability with Random Forest Model for match
Pakistan-India-2022-10-23
17) Worm -wicket graph of match
Pakistan-India-2022-10-23
C) Win Probability using MLP – Deep Neural Network (DNN) with player embeddings
In this approach the MLP package of Tidymodels was used. Multi-layer perceptron (MLP) with Deep Neural Network (DNN) was used to compute the Win Probability using player embeddings. An accuracy of 0.76 was obtained
1) Read the data
a) Read the data from 9 T20 leagues (BBL, CPL, IPL, NTB, PSL, SSM, T20 Men, T20 Women, WBB) and create a single data frame of ball-by-ball data. Display the data frame
2) Create training.validation and test sets
b) Split to training, validation and test sets. The dataset is initially split into training and test in the ratio 80%:20%. The training data is again split into training and validation in the ratio 80:20
Of the 3 ML models, glmnet, random forest and Multi-layer Perceptron DNN, random forest had the best performance
Random Forest ML model with batsman, bowler embeddings was able to achieve an accuracy of 92.4% and a ROC_AUC of 0.98 with very low false positives, negatives. This was a quantum jump from my earlier random forest model without embeddings which had an accuracy of 73.7% and an ROC_AUC of 0.834
The glmnet and NN models are fairly light weight. Random Forest is computationally very intensive.
It is that time of the year when there is “a song in the air, the lark’s on the wing, and the snail’s on the the thorn“. Yes, it is the that time of year when the grand gala event of IPL 2022 is underway. So, I managed to wake myself from my Covid-induced slumber, worked up my ‘creaking bones‘ and cranked up the GooglyPlusPlus machinery.
So now, every morning, a scheduled CRON tab entry will automatically download the previous night’s match data from Cricsheet, unzip, process and transform it into the necessary format required by my R package yorkr, and make it available to my Shiny app GooglyPlusPlus. Hence the data is current and you have access to ‘analytics-in-the-now’!.
As you know in 2021, I added a lot of new features to GooglyPlusPlus, new tabs to do even more. analytics – or in other words there is “more GooglyPlusPlus per click!!”. So now, you have the following
Batsman tab: For detailed analysis of batsmen
Bowler tab: For detailed analysis of bowlers
Match tab: Analysis of individual matches, plot of Runs vs SR, Wickets vs ER in power play, middle and death overs
Head-to-head tab: Detailed analysis of team-vs-team batting/bowling scorecard, batting, bowling performances, performances in power play, middle and death overs
Team performance tab: Analysis of team-vs-all other teams with batting /bowling scorecard, batting, bowling performances, performances in power play, middle and death overs
Optimisation tab: Allows one to pit batsmen vs bowlers and vice-versa. This tab also uses integer programming to optimise batting and bowling lineup
Batting analysis tab: Ranks batsmen using Runs or SR. Also plots performances of batsmen in power play, middle and death overs and plots them in a 4×4 grid
Bowling analysis tab: Ranks bowlers based on Wickets or ER. Also plots performances of bowlers in power play, middle and death overs and plots them in a 4×4 grid
Also note all these tabs and features are available for all T20 formats namely IPL, Intl. T20 (men, women), BBL, NTB, PSL, CPL, SSM.
Note: All charts are interactive, which means that you can hover, zoom-in, zoom-out, pan etc on the charts
The latest avatar of GooglyPlusPlus2022 is based on my R package yorkr with data from Cricsheet.
Here are some random analysis that can be done by GooglyPlusPlus across the tabs. Note the app will be updated daily and the analytics will be current throughout the season of IPL 2022
A) Match tab
a) GT vs DC – 2 Apr 2022
Runs vs SR – Gujarat Titans
b) CSK vs LSG – 31 Mar 2022
Runs across 20 overs
c) KKR vs PBKS -Match wicket worm chart – 1 Apr 2022
B) Batsmen tab
a) Faf Du Plessis – Runs vs Deliveries
b) Sanju Samson – Runs against opposition
C) Bowler’s tab
a) D J Bravo – No of deliveries to wicket
b) Trent Boult – Wickets at Venues
D) Head-to-head tab
a) DC vs MI – Mar -2019 till date : Batting scorecard
b) CSK vs KKR – Jan 2019 till date : Runs vs SR
E) Team vs All Teams tab
a) Punjab Kings vs all Teams – Wickets vs ER in Power play
b) Rajasthan Royals vs all Teams : Jan 2019 till date : Runs vs SR in Power play
F) Optimisation tab
a) Batsmen vs Bowlers
b) Bowlers vs batsmen
G) Batting analysis
This tab is for ranking batsmen
a) Batsmen rank from 2019 till date (Runs over SR)
GooglyPlusPlus2022 is the new avatar of last year’s GooglyPlusPlus2021. Roughly, about 5 years back I had written a post on Using linear programming to optimize T20 batting and bowling line up. This post has been on the back of my mind for a long time and I decided to pay this post a revisit. This requires computing performance of individual batsmen vs bowlers and vice-versa for performing the optimization. So in this latest incarnation, there are 4 new functions
batsmanVsBowlerPerf – Performance of batsmen against chosen bowlers
bowlerVsBatsmanPerf – Performance of bowlers versus specific batsmen
battingOptimization – Optimizing batting line up based on strike rates ad remaining overs
bowlingOptimization – Optimizing bowling line up based on economy rates and remaining overs
These 4 functions have been incorporated in all the supported 9 T20 formats namely a. IPL b. Intl. T20(men) c. Intl. T20 (women) d. BBL e. NTB f. PSL g. WBB h. CPL i. SSM
You can clone/fork the code for GooglyPlusPlus2022 from Github from gpp2022-1
With this latest update you can do a myriad of analyses of batsmen, bowlers, teams, matches. This is just-in-time for the IPL Mega-auction!! Do check out these other posts of GooglyPlusPlus for other detailed analysis
A) Batsman Vs Bowlers – This option computes the performance of individual batsman against individual bowlers
a) IPL Batsmen vs Bowlers
Included below are the performances of Dhoni, Raina and Kohli against Malinga, Ashwin and Bumrah. Note: The last 2 text box input are not required for this.
b) Intl. T20 (men) Batsmen vs Bowlers
Note: You can type the name and choose from the drop down list
B) Bowler vs Batsmen – You can check the performance of specific bowlers against specific batsmen
a) Intl. T20 (women) India vs Australia
b) PSL Bowlers vs Batsmen
C) Strategy for optimizing batting and bowling line up
From the above 2 tabs, it is obvious, that different bowlers have different ER and wicket rate against different batsmen. In other words, the effectiveness of the bowlers varies by batsmen. Conversely, batsmen are more comfortable with certain bowlers versus others and this shows up in different strike rates.
Hence during the death overs, when trying to restrict batsmen to a certain score or on the flip side when the batting side needs to score a target within certain overs, we need to take advantage of the relative effectiveness of bowlers vs batsmen for optimising bowling and aggressiveness of batsmen versus bowlers to quickly reach the target.
This is the approach that is used for bowling and batting optimisation. For optimising bowling, we need to formulate a minimisation problem based on ER rates and for optimising batting, a maximisation strategy is chosen based on SR. ‘Integer programming’ is used to compute during the last set of overs
This latest version includes optimization using “integer programming” based on R package lpSolve.
Here are the 2 formulations
Assume there are 3 bowlers – and there are 3 batsmen –
I) LP Formulation for bowling order
Let the economy rate be the Economy Rate of the jth bowler to the ith batsman. Also if remaining overs for the bowlers are and the total number of overs left to be bowled are
Let the economy rate be the Economy Rate of the jth bowler to the ith batsman. Objective function : Minimize – i.e. Constraints Where is the number of overs remaining for the jth bowler against ‘k’ batsmen and if the total number of overs remaining to be bowled is N then or The overs that any bowler can bowl is
II) LP Formulation for batting lineup
Let the strike rate be the Strike Rate of the ith batsman to the jth bowler Objective function : Maximize – i.e. Constraints Where is the number of overs remaining for the jth bowler against ‘k’ batsmen and the total number of overs remaining to be bowled is N then or The overs that any bowler can bowl is
C) Optimized bowling lineup
a) IPL – Optimizing bowling line up
Note: For computing the Optimal bowling lineup, the total number of overs remaining and the number of overs for each bowler have to be entered.
b) PSL – Optimizing batting line up
d) Optimized batting lineup
a) Intl. T20 (men) India vs England
b) Carribean Premier League – Optimizing batting line up
Analytics for e.g. sports analytics, business analytics or analytics in e-commerce or in other domain has 2 main requirements namely a) What kind of analytics (set of parameters,function) will squeeze out the most intelligence from the data b) How to represent the analytics so that an expert can garner maximum insight?
While it may appear that the former is more important, the latter is also equally, if not, more vital to the problem. Indeed, a picture is worth a thousand words, and often times is more insightful than a large table of numbers. However, in the case of sports analytics, for e.g. in cricket a batting or bowling scorecard captures more information and can never be represented in chart.
So, my Shiny app GooglyPlusPlus includes both charts and tables for different aspects of the analysis. In this post, a newer type of chart, popular among senior management experts, namely the 4 quadrant graph is introduced, which helps in categorising batsmen and bowlers into 4 categories as shown below
a) Batting Performances – Top right quadrant (High runs, High Strike rate)
b) Bowling Performances – Bottom right quadrant( High wickets, Low Economy Rate)
I have added the following 32 functions in this latest version of GooglyPlusPlus
A. Match Tab
All the functions below are at match level
Team Runs vs SR Plot
Team Wickets vs ER Plot
Team Runs vs SR Power play plot
Team Runs vs SR Middle overs plot
Team Runs vs SR Death overs plot
Team Wickets vs ER Power Play
Team Wickets vs ER Middle overs
Team Wickets vs ER Death overs
B. Head-to-head Tab
The below functions are based on all matches between 2 teams’
Team Runs vs SR Plot all Matches
Team Wickets vs ER Plot all Matches
Team Runs vs SR Power play plot all Matches
Team Runs vs SR Middle overs plot all Matches
Team Runs vs SR Death overs plot all Matches
Team Wickets vs ER Power Play plot all Matches
Team Wickets vs ER Middle overs plot all Matches
Team Wickets vs ER Death overs plot all Matches
C. Team Performance tab
The below functions are based on a team’s performance against all other teams
Team Runs vs SR Plot overall
Team Wickets vs ER Plot overall
Team Runs vs SR Power play plot overall
Team Runs vs SR Middle overs plot overall
Team Runs vs SR Death overs plot overall
Team Wickets vs ER Power Play overall
Team Wickets vs ER Middle overs overall
Team Wickets vs ER Death overs overall
D. T20 format Batting Analysis
This analysis is at T20 format level (IPL, Intl. T20(men), Intl. T20 (women), PSL, CPL etc.)
Overall Runs vs SR plot
Overall Runs vs SR Power play plot
Overall Runs vs SR Middle overs plot
Overall Runs vs SR Death overs plot
E. T20 Bowling Analysis
This analysis is at T20 format level (IPL, Intl. T20(men), Intl. T20 (women), PSL, CPL etc.)
Overall Wickets vs ER plot
Team Wickets vs ER Power Play
Team Wickets vs ER Middle overs
Team Wickets vs ER Death overs
These 32 functions have been added to my yorkr package and so all these functions become plug-n-play in my Shiny app GooglyPlusPlus2021 which means that the 32 functions apply across all the nine T20 formats that the app supports i.e. IPL, Intl. T20 (men), Intl. T20 (women), BBL, NTB, PSL, CPL, SSM, WBB.
Hence the multiplicative factor of the new addition is 32 x 9 = 288 additional ways of exploring match, team and player data
You can clone/fork GooglyPlusPlus from Github at gpp2021-10
Check out my app GooglyPlusPlus2021 and analyze batsmen, bowlers, teams, overall performance. The data for all the nine T20 formats have been updated to include the latest data.
Hence, the app is just in time for the IPL mega auction. You should be able to analyse players in IPL, Intl. T20 or in any of the other formats from where they could be drawn and check out their relative standings
I am including some random plots to demonstrate the newly minted functions
Note 1: All plots are interactive. The controls are on the top right. You can hover over data, zoom-in, zoom-out, compare data etc by choosing the appropriate control. To know more about how to use the interactive charts see GooglyPlusPlus2021 is now fully interactive!!!
New Zealand batting, except K Williamson, the rest did not fire as much
For Australia, Warner, Maxwell and Marsh played good knocks to wrest control
II) Head-to-head
a) Wickets vs ER during Power play of Mumbai Indians in all matches against Chennai Super Kings (IPL)
b) Karachi Kings Runs vs SR during middle overs against Multan Sultans (PSL)
c) Wickets vs ER during death overs of Barbados Tridents in all matches against Jamaica Tallawahs (CPL)
III) Teams overall batting performance
India’s best T20 performers in Power play since 2018 (Intl. T20)
e) Australia’s best performers in Death overs since Mar 2017 (Intl. T20)
f) India’s Intl. T20 (women) best Runs vs SR since 2018
g) England’s Intl. T20 (women) best bowlers in Death overs
IV) Overall Batting Performanceacross T20
This tab gives the batsmen’s rank and overall batting performance across the T20 format.
a) Why was Hardik Pandya chosen, and why this was in error?
Of course, it provides an insight into why Hardik Pandya was chosen in India’s World cup team despite poor performances recently. Here are the best Intl. T20 death over batsmen
Of course, we can zoom in to get a better look
This is further substantiated when we performances in IPL
However, if you move the needle forward a year at a time, you see Hardik Pandya’s performance drops significantly
and further down
Rather, Dinesh Karthik, Sanju Samson or Ruturaj Gaikwad would have been better options
b) Best batsmen Intl. T20 (women) in Power play since 2018
V) Overall bowling performance
This tab gives the bowler’s rank and overall bowling performance in Power play, middle and death overs across all T20 formats
a) Intl. T20 (men) best bowlers in Power Play from 2019 (zoomed in)
b) Intl. T20(men) best bowlers in Death overs since 2019
c) Was B. Kumar a good choice for India team in World cup?
Bhuvi was one of India’s best bowler in Power play only if we go back to the beginning of time
i) From 2008
But if we move forward to 2020 onwards we see Arshdeep Singh or D Chahar would have been a better choice
ii) From 2020 onwards
iii) 2021 onwards
Hence D Chahar & Arshdeep Singh are the natural choice moving forwards for India
iv) T20 Best batsman
If we look at Intl. T20 performances since 2017, Babar Azam leads the pack, however his Strike rate needs to move up.
This latest edition of GooglyPlusPlus2021 now includes detailed analysis of teams, batsmen and bowlers in power play, middle and death overs. The T20 format is based on 3 phases as each side faces 20 overs.
Power play: Overs: 0 – 6 – No more than 2 players can be outside the 30 yard circle
Middle overs: Overs: 7- 16 – During these overs the batting side tries to consolidate their innings
Death overs: Overs: 16 -20 – During these 5 overs the batting side tries to accelerate the scoring rate, while the bowling side will try to restrict the batsmen against going for big hits
This is shown below
This latest update of GooglyPlusPlus2021 includes the following functions
a) Match tab
teamRunsAcrossOvers
teamSRAcrossOvers
teamWicketsAcrossOvers
teamERAcrossOvers
matchWormWickets
b) Head-to-head tab
teamRunsAcrossOversOppnAllMatches
teamSRAcrossOversOppnAllMatches
teamWicketsAcrossOversOppnAllMatches
teamERAcrossOversOppnAllMatches
topRunsBatsmenAcrossOversOppnAllMatches
topSRBatsmenAcrossOversOppnAllMatches
topWicketsBowlersAcrossOversOppnAllMatches
topERBowlerAcrossOverOppnAllMatches
c) Overall performance tab
teamRunsAcrossOversAllOppnAllMatches
teamSRAcrossOversAllOppnAllMatches
teamWicketsAcrossOversAllOppnAllMatches
teamERAcrossOversAllOppnAllMatches
topRunsBatsmenAcrossOversAllOppnAllMatches
topSRBatsmenAcrossOversAllOppnAllMatches
topWicketsBowlersAcrossOversAllOppnAllMatches
topERBowlerAcrossOverAllOppnAllMatches
Hence a total of 8 + 8 + 5 = 21 functions have been added. These functions can be utilized across all the 9 T20 formats that are supported in GooglyPlusPlus2021 namely
You can clone/fork the code for the Shiny app from Github – gpp2021-9
Included below is a random selection of options from the 189 possibilities mentioned above. Feel free to try out for yourself
A) IPL – CSK vs KKR 2018-04-10
a) Team Runs in power play, middle and death overs
b) Team Strike rate in power play, middle and death overs
B) Intl. T20 (men) – India vs Afghanistan (2021-11-03)
a) Team wickets in power play, middle and death overs
b) Team Economy rate in power play, middle and death overs
C) Intl. T20 (women) Head-to-head : India vs Australia since 2018
a) Team Runs in all matches in power play, middle and death overs
D) PSL Head-to-head strike rate since 2019
a) Team vs team Strike rate : Karachi Kings vs Lahore Qalanders since 2019 in power play, middle and death overs
E) Team overall performance in all matches against all opposition
a) BBL : Brisbane Heats : Team Wickets between 2015 – 2018 in power play, middle and death overs
F) Top Runs and Strike rate Batsman of Mumbai Indians vs Royal Challengers Bangalore since 2018
a) Top runs scorers for Mumbai Indians (MI) in power play, middle and death overs
b) Top strike rate for RCB in power play, middle and death overs
F) Intl. T20 (women) India vs England since 2018
a) Top wicket takers for England in power play, middle and death overs since 2018
b) Top wicket takers for India in power play, middle and death overs since 2018
G) Intl. T20 (men) All time best batsmen and bowlers for India
a) Most runs in power play, middle and death overs
b) Highest strike rate in power play, middle and death overs
H) Match worm wicket chart
In addition to the usual Match worm chart, I have also added a Match Wicket worm chart in the latest version
Note: You can zoom to the area where you would like to focus more
The option of looking at the Match worm chart (without wickets) also exists.
Go ahead take GooglyPlusPlus2021 for a test drive and check out how your favourite players perform in power play, middle and death overs. Click GooglyPlusPlus2021
You can fork/download the app code from Github at gpp2021-9
This year 2021, we are witnessing a rare spectacle in the cricketing universe, where IPL playoffs are immediately followed by ICC World Cup T20. Cricket pundits have claimed such a phenomenon occurs once in 127 years! Jokes apart, the World cup T20 is underway and as usual GooglyPlusPlus is ready for the action.
GooglyPlusPlus will provide near-real time analytics, by automatically downloading the latest match data daily, processing and organising the match data into appropriate folders so that my R package yorkr can slice and dice the data to provide the pavilion-view analytics.
The charts capture all the breathless, heart-pounding, and nail-biting action in great details in the many tables and plots. Every table and chart tell a story. You just have to ‘read between the lines!’
GooglyPlusPlus2021 will update itself automatically every day, so the data will be current and you can analyse all matches upto the previous day, along with the historical performances of the teams. So make sure you check it everyday.
The are 5 tabs for each of the formats supported by GooglyPlusPlus2021 which now supports IPL, Intl. T20(men), Intl. T20(women), BBL, NTB, PSL, CPL, SSM, WBB. Besides, it also supports ODI (men) and ODI (women)
Each of the formats have 5 tabs – Batsman, Bowler, Match, Head-to-head and Overall Performace.
All T20 formats also include a ranking functionality for the batsmen and bowlers
You can now perform drill-down analytics for batsmen, bowlers, head-to-head and overall performance based on date-range selector functionality. The ranking tabs also include date range selector granular analysis. For more details see GooglyPlusPlus2021 enhanced with drill-down batsman, bowler analytics
This latest update to GooglyPlusPlus2021 includes the following changes
a) All the functions in the ‘Batsman’ and ‘Bowler ‘tabs now include a date range, which allows you specify a period of interest.
b) The ‘Rank Batsman’ and ‘Rank Bowler’ tabs also include a date range selector, against the earlier version which had a ‘Since year’ slider see GooglyPlusPlus2021 bubbles up top T20 players in all formats!. The earlier ‘Since year’ slider option could only rank for the latest year or for all years up to the current year. Now with the new ‘date range’ picker we can check the batsman and bowler ranks in any IPL season or (any T20 format) or for a range of years.
c) Note: The Head-to-head and Overall performance tabs already include a date range selector.
There are 10 batsman functions and 9 bowler function that have changed for the following T20 and ODI formats and Rank batsman and bowler includes the ‘date range’ and has changed for all T20 formats.
GooglyPlusPlus2021 supports all the following T20 formats
I have included some random screen shots of some of using these tabs and options in GooglyPlusPlus2021.
A) KL Rahul’s Cumulative average in IPL 2021 vs IPL 2020
a) KL Rahul in IPL 2021
b) KL Rahul in IPL 2020
B) Performance of Babar Azam in Intl. T20 (men)
a) Babar Azam’s cumulative average from 2019
b) Babar Azam’s Runs against opposition since 2019
Note: Intl. T20 (women) data available upto Mar 2020 from Cricsheet
a) A J Healy performance between 2010 – 2015
b) A J Healy performance between 2015 – 2020
D) M S Dhoni’s performance with the bat pre-2020 and post 2020
There has been a significant decline in Dhoni’s performance in the last couple of years
I) Dhoni’s performance from Jan 2010 to Dec 2019
a) Moving average at 25+(Dhoni before)
The moving average actually moves up…
b) Cumulative average at 25+(Dhoni before)
c) Cumulative Strike rate 140+ (Dhoni before)
d) Dhoni’s moving average is ~10-12 (post 2020)
e) Dhoni’s cumulative average (post 2020)
f) Dhoni’s strike rate ~80 (post 2020)
E) Bumrah’s performance in IPL
a) Bumrah’s performance in IPL 2020
b) Bumrah’s performance in IPL 2021
F) Moving average wickets for A. Shrubsole in ODI (women)
G) Chris Jordan’s cumulative economy rate
We can see that Jordan has become more expensive over the years
G) Ranking players
In this latest version the ‘Since year slider’ has been replaced with a Date Range selector. With this we can identify the player ranks in any IPL, CPL, PSL or BBL season. We can also check the performance over the last couple of years. Note: The matches played and Runs over Strike rate or Strike rate over runs can be computed. Similarly for bowlers we have Wickets over Economy rate and Economy rate over wickets options.
a) Ranking IPL batsman in IPL season 2020
b) Ranking Intl. T20 (batsmen) from Jan 2019 to Jul 2021
c) Ranking Intl. T20 bowlers (women) from Jan 2019 – Jul 2021
d) Best IPL bowlers over the last 3 seasons (Wickets over Economy rate)
e) Best IPL bowlers over the last 3 seasons (Economy rate over wickets)
You can clone/download this latest version of GooglyPlusPlus2021 from Github at gpp2021-7
The IPL 2021 extravaganza has restarted again, now in Dubai, and it was time for me to crank up good ol’ GooglyPlusPlus2021. As in my earlier post, GooglyPlus2021 with IPL 2021 as it happens, during the initial set of IPL 2021 games,, a command script will execute automatically every day, download the latest data files, unzip, sort, process and put them in appropriate directories so that GooglyPlusPlus can work its magic on the data, with my R package yorkr. You can do analysis of IPL 2021 matches, batsmen, bowlers, historical performance analysis of head-to-head clashes and performances of teams.
Note: Since the earlier instalment of IPL 2021, there are 2 key changes that have taken place in GooglyPlusPlus.
Now,
a) All charts are interactive. You can hover over charts, click, double-click to get more details. To see more details on how to use the interactive charts, see my post GooglyPlusPlus2021 is now fully interactive!
You can try out my app GooglyPlusPlus2021 by clicking GooglyPlusPlus2021
The code for my R package yorkr is available at Github at yorkr
You can clone/fork GooglyPlusPlus2021 from github at gpp2021-6
IPL 2021 is already underway.
Some key analysis and highlights of the 2 recently concluded IPL matches
CSK vs MI
KKR vs RCB
a) CSK vs MI (19 Sep 2021) – Batting Partnerships (CSK)
b) CSK vs MI (19 Sep 2021) – Bowling scorecard (MI)
c) CSK vs MI (19 Sep 2021) –Match worm chart
Even though MI had a much better start and were cruising along to a victory, they lost the plot around the 18.1 th over as seen below (hover on the chart)
d
d) KKR vs RCB ( 20 Sep 2021)– Bowling wicket match
This chart gives the wickets taken by the bowler and the total runs conceded
e) KKR vs RCB ( 20 Sep 2021)– Match worm chart
This was a no contest. RCB batting was pathetic and KKR blasted their way to victory as seen in this worm chart
Note: You can also do historical analysis of teams with GooglyPlusPlus2021
For the match to occur today PBKS vs RR (21 Sep 2021) we can perform head-to-head historical analysis. Here Kings XI Punjab has been chosen instead of Punjab Kings as that was its name.
f) Head-to-head (PBKS vs RR) today’s match 21 Sep 2021
For the Rajasthan Royals Sanjy Samson and Jos Buttler have the best performance from 2018 -2021 as seen below
For Punjab Kings KL Rahul and Chris Gayle are the leading scorers for the period 2018-2021
g) Current ranking of batsmen IPL 2021
h) Current ranking of bowlers IPL 2021
Also you analyse individual batsman and bowlers
i) Batsman analysis
To see Rituraj Gaikwad performance checkout the batsman tab
j) Bowler analysis
Performance of Varun Chakaravarty
Remember to check out GooglyPlusPlus2021 for your daily analysis of matches, teams, batsmen and bowlers. Your ride will be waiting for you!!!
You can clone/fork GooglyPlusPlus2021 from github at gpp2021-6
GooglyPlusPlus2021 has been updated with all completed 31 matches











































































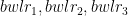
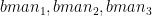
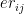 be the Economy Rate of the jth bowler to the ith batsman. Also if remaining overs for the bowlers are
be the Economy Rate of the jth bowler to the ith batsman. Also if remaining overs for the bowlers are 

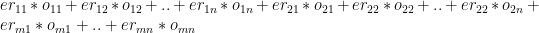

 is the number of overs remaining for the jth bowler against ‘k’ batsmen
is the number of overs remaining for the jth bowler against ‘k’ batsmen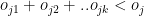
 or
or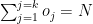
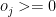
 be the Strike Rate of the ith batsman to the jth bowler
be the Strike Rate of the ith batsman to the jth bowler






































































































