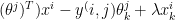In my last post ‘GooglyPlusPlus now with Win Probability Analysis for all T20 matches‘ I had discussed the performance of my ML models, created with and without player embeddings, in computing the Win Probability of T20 matches. With batsman & bowler embeddings I got much better performance than without the embeddings
glmnet – Accuracy – 0.73
Random Forest (RF) – Accuracy – 0.92
While the Random Forest gave excellent accuracy, it was bulky and also took an unusually long time to predict the Win Probability of a single T20 match. The above 2 ML models were built using R’s Tidymodels. glmnet was fast, but I wanted to see if I could create a ML model that was better, lighter and faster. I had initially tried to use Tensorflow, Keras in Python but then abandoned it, since I did not know how to port the Deep Learning model to R and use in my app GooglyPlusPlus.
But later, since I was stuck with a bulky Random Forest model, I decided to again explore options for saving the Keras Deep Learning model and loading it in R. I found out that saving the model as .h5, we can load it in R and use it for predictions. Hence, I rebuilt a Deep Learning model using Keras, Python with player embeddings and I got excellent performance. The DL model was light and had an accuracy 0.8639 with an ROC_AUC of 0.964 which was great!
GooglyPlusPlus uses data from Cricsheet and is based on my R package yorkr
You can try out this latest version of GooglyPlusPlus at gpp2023-1
Here are the steps
A. Build a Keras Deep Learning model
a. Import necessary packages
import pandas as pd
import numpy as np
from zipfile import ZipFile
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import regularizers
from pathlib import Path
import matplotlib.pyplot as plt
b, Upload the data of all 9 T20 leagues (BBL, CPL, IPL, T20 (men) , T20(women), NTB, CPL, SSM, WBB)
# Read all T20 leagues
df1=pd.read_csv('t20.csv')
print("Shape of dataframe=",df1.shape)
# Create training and test data set
train_dataset = df1.sample(frac=0.8,random_state=0)
test_dataset = df1.drop(train_dataset.index)
train_dataset1 = train_dataset[['batsmanIdx','bowlerIdx','ballNum','ballsRemaining','runs','runRate','numWickets','runsMomentum','perfIndex']]
test_dataset1 = test_dataset[['batsmanIdx','bowlerIdx','ballNum','ballsRemaining','runs','runRate','numWickets','runsMomentum','perfIndex']]
train_dataset1
# Set the target data
train_labels = train_dataset.pop('isWinner')
test_labels = test_dataset.pop('isWinner')
train_dataset1
a=train_dataset1.describe()
stats=a.transpose
a
c. Create a Deep Learning ML model using batsman & bowler embeddings
This was a huge success for me to be able to create the Deep Learning model in Python and use it in my Shiny app GooglyPlusPlus. The Deep Learning Keras model is light-weight and extremely fast.
The Deep Learning model has now been integrated into GooglyPlusPlus. Now you can check the Win Probability using both a) glmnet (Logistic Regression with lasso regularisation) b) Keras Deep Learning model with dropouts as regularisation
In addition I have created 2 features based on Win Probability (WP)
i) Win Probability (Side-by-side– Plot(interactive) : With this functionality the 1st and 2nd innings will be side-by-side. When the 1st innings is played by team 1, the Win Probability of team 2 = 100 – WP (team1). Similarly, when the 2nd innings is being played by team 2, the Win Probability of team1 = 100 – WP (team 2)
ii) Win Probability (Overlapping) – Plot (static): With this functionality the Win Probabilities of both team1(1st innings) & team 2 (2nd innings) are displayed overlapping, so that we can see how the probabilities vary ball-by-ball.
Note: Since the same UI is used for all match functions I had to re-use the Plot(interactive) and Plot(static) radio buttons for Win Probability (Side-by-side) and Win Probability(Overlapping) respectively
Here are screenshots using both ML models with both functionality for some random matches
B) ICC T20 Men World Cup – Netherland-South Africa- 2022-11-06
i) Match Worm wicket chart
ii) Win Probability with LR (Side-by-Side- Plot(interactive))
iii) Win Probability LR (Overlapping- Plot(static))
iv) Win Probability Deep Learning (Side-by-side – Plot(interactive)
In the 213th ball of the innings South Africa was slightly ahead of Netherlands. After that they crashed and burned!
v) Win Probability Deep Learning (Overlapping – Plot (static)
It can be seen that in the 94th ball of both innings South Africa was ahead of Netherlands before the eventual slump.
C) Intl. T20 (Women) India – New Zealand – 2020 – 02 – 27
Here is an interesting match between India and New Zealand T20 Women’s teams. NZ successfully chased the India’s total in a wildly swinging fortunes. See the charts below
i) Match Worm Wicket chart
ii) Win Probability with LR (Side-by-side – Plot (interactive)
iii) Win Probability with LR (Overlapping – Plot (static)
iv) Win Probability with DL model (Side-by-side – Plot (interactive))
v) Win Probability with DL model (Overlapping – Plot (static))
The above functionality in plotting the Win Probability using LR or DL with both options (Side-by-side or Overlapping) is available for all 9 T20 leagues currently supported by GooglyPlusPlus.
In my previous post Computing Win Probability of T20 matches I had discussed various approaches on computing Win Probability of T20 matches. I had created ML models with glmnet and random forest using TidyModels. This was what I had achieved
glmnet : accuracy – 0.67 and sensitivity/specificity – 0.68/0.65
random forest : accuracy – 0.737 and roc_auc- 0.834
DL model with Keras in Python : accuracy – 0.73
I wanted to see if the performance of the models could be further improved. I got a suggestion from a AI/DL whizkid, who is close to me, to include embeddings for batsmen and bowlers. He felt that win percentage is influenced by which batsman faces which bowler.
So, I started to explore this idea. Embeddings can be used to convert categorical variables to a vector of continuous floating point numbers.Fortunately R’s Tidymodels, has a convenient functionality to create embeddings. By including embeddings for batsman, bowler the performance of my ML models improved vastly. Now the performance is
glmnet : accuracy – 0.728 and roc_auc – 0.81
random forest : accuracy – 0.927 and roc_auc – 0.98
mlp-dnn :accuracy – 0.762 and roc_auc – 0.854
As can be seem there is almost a 20% increase in accuracy with random forests with embeddings over the model without embeddings. Moreover, the feature importance which is plotted below shows that the bowler and batsman embeddings have a significant influence on the Win Probability
Note: The data for this analysis is taken from Cricsheet and has been processed with my R package yorkr.
A. Win Probability using GLM with penalty and player embeddings
Here Generalised Linear Model (GLMNET) for Logistic Regression is used. In the GLMNET the regularisation path is computed for the lasso or elastic net penalty at a grid of values for the regularisation parameter lambda. glmnet is extremely fast and gave an accuracy of 0.72 for an roc_auc of 0.81 with batsman, bowler embeddings. This was good improvement over my earlier implementation with glmnet without the batsman & bowler embeddings which had a
Read the data
a) Read the data from 9 T20 leagues (BBL, CPL, IPL, NTB, PSL, SSM, T20 Men, T20 Women, WBB) and create a single data frame of ball-by-ball data. Display the data frame
b) Split to training, validation and test sets. The dataset is initially split into training and test in the ratio 80%:20%. The training data is again split into training and validation in the ratio 80:20
4) Create a Logistic Regression Workflow by adding the GLM model and the recipe
5) Create grid of elastic penalty values for regularisation
6) Train all 30 models
7) Plot the ROC of the model against the penalty
# Use all 12 cores
cores <- parallel::detectCores()
cores
# Create a Logistic Regression model with penalty
lr_mod <-
logistic_reg(penalty = tune(), mixture = 1) %>%
set_engine("glmnet",num.threads = cores)
# Create pre-processing recipe
lr_recipe <-
recipe(isWinner ~ ., data = df_other) %>%
step_embed(batsman,bowler, outcome = vars(isWinner)) %>% step_normalize(ballNum,ballsRemaining,runs,runRate,numWickets,runsMomentum,perfIndex)
# Set the workflow by adding the GLM model with the recipe
lr_workflow <-
workflow() %>%
add_model(lr_mod) %>%
add_recipe(lr_recipe)
# Create a grid for the elastic net penalty
lr_reg_grid <- tibble(penalty = 10^seq(-4, -1, length.out = 30))
lr_reg_grid %>% top_n(-5)
# A tibble: 5 × 1
penalty
<dbl>
1 0.0001
2 0.000127
3 0.000161
4 0.000204
5 0.000259
lr_reg_grid %>% top_n(5) # highest penalty values
# A tibble: 5 × 1
penalty
<dbl>
1 0.0386
2 0.0489
3 0.0621
4 0.0788
5 0.1
# Train 30 penalized models
lr_res <-
lr_workflow %>%
tune_grid(val_set,
grid = lr_reg_grid,
control = control_grid(save_pred = TRUE),
metrics = metric_set(accuracy,roc_auc))
# Plot the penalty versus ROC
lr_plot <-
lr_res %>%
collect_metrics() %>%
ggplot(aes(x = penalty, y = mean)) +
geom_point() +
geom_line() +
ylab("Area under the ROC Curve") +
scale_x_log10(labels = scales::label_number())
lr_plot
The Penalty vs ROC plot is shown below
8) Display the ROC_AUC of the top models with the penalty
9) Select the model with the best ROC_AUC and the associated penalty. It can be seen the best mean ROC_AUC is 0.81 and the associated penalty is 0.000530
top_models <-
lr_res %>%
show_best("roc_auc", n = 15) %>%
arrange(penalty)
top_models
# A tibble: 15 × 7
penalty .metric .estimator mean n std_err .config
<dbl> <chr> <chr> <dbl> <int> <dbl> <chr>
1 0.0001 roc_auc binary 0.810 1 NA Preprocessor1_Model01
2 0.000127 roc_auc binary 0.810 1 NA Preprocessor1_Model02
3 0.000161 roc_auc binary 0.810 1 NA Preprocessor1_Model03
4 0.000204 roc_auc binary 0.810 1 NA Preprocessor1_Model04
5 0.000259 roc_auc binary 0.810 1 NA Preprocessor1_Model05
6 0.000329 roc_auc binary 0.810 1 NA Preprocessor1_Model06
7 0.000418 roc_auc binary 0.810 1 NA Preprocessor1_Model07
8 0.000530 roc_auc binary 0.810 1 NA Preprocessor1_Model08
9 0.000672 roc_auc binary 0.810 1 NA Preprocessor1_Model09
10 0.000853 roc_auc binary 0.810 1 NA Preprocessor1_Model10
11 0.00108 roc_auc binary 0.810 1 NA Preprocessor1_Model11
12 0.00137 roc_auc binary 0.810 1 NA Preprocessor1_Model12
13 0.00174 roc_auc binary 0.809 1 NA Preprocessor1_Model13
14 0.00221 roc_auc binary 0.809 1 NA Preprocessor1_Model14
15 0.00281 roc_auc binary 0.809 1 NA Preprocessor1_Model15
#Picking the best model and the corresponding penalty
lr_best <-
lr_res %>%
collect_metrics() %>%
arrange(penalty) %>%
slice(8)
lr_best
# A tibble: 1 × 7
penalty .metric .estimator mean n std_err .config
<dbl> <chr> <chr> <dbl> <int> <dbl> <chr>
1 0.000530 roc_auc binary 0.810 1 NA Preprocessor1_Model08
# Collect predictions and generate the AUC curve
lr_auc <-
lr_res %>%
collect_predictions(parameters = lr_best) %>%
roc_curve(isWinner, .pred_0) %>%
mutate(model = "Logistic Regression")
autoplot(lr_auc)
7) Plot the Area under the Curve (AUC).
10) Build the final model with the best LR parameters value as found in lr_best
a) The best performance was for a penalty of 0.000530
b) The accuracy achieved is 0.72. Clearly using the embeddings for batsman, bowlers improves on the performance of the GLM model without the embeddings. The accuracy achieved was 0.72 whereas previously it was 0.67 see (Computing Win Probability of T20 Matches)
c) Create a fit with the best parameters
d) The accuracy is 72.8% and the ROC_AUC is 0.813
# Create a model with the penalty for best ROC_AUC
last_lr_mod <-
logistic_reg(penalty = 0.000530, mixture = 1) %>%
set_engine("glmnet",num.threads = cores,importance = "impurity")
#Update the workflow with this model
last_lr_workflow <-
lr_workflow %>%
update_model(last_lr_mod)
#Create a fit
set.seed(345)
last_lr_fit <-
last_lr_workflow %>%
last_fit(splits)
#Generate accuracy, roc_auc
last_lr_fit %>%
collect_metrics()
# A tibble: 2 × 4
.metric .estimator .estimate .config
<chr> <chr> <dbl> <chr>
1 accuracy binary 0.728 Preprocessor1_Model1
2 roc_auc binary 0.813 Preprocessor1_Model1
11) Plot the feature importance
It can be seen that bowler and batsman embeddings are the most significant for the prediction followed by runRate.
Chennai Super Kings-Lucknow Super Giants-2022-03-31
16a) The corresponding Worm-wicket graph for this match is as below
Chennai Super Kings-Lucknow Super Giants-2022-03-31
B) Win Probability using Random Forest with player embeddings
In the 2nd approach I use Random Forest with batsman and bowler embeddings. The performance of the model with embeddings is quantum jump from the earlier performance without embeddings. However, the random forest is also computationally intensive.
1) Read the data
a) Read the data from 9 T20 leagues (BBL, CPL, IPL, NTB, PSL, SSM, T20 Men, T20 Women, WBB) and create a single data frame of ball-by-ball data. Display the data frame
2) Create training.validation and test sets
b) Split to training, validation and test sets. The dataset is initially split into training and test in the ratio 80%:20%. The training data is again split into training and validation in the ratio 80:20
library(dplyr)
library(caret)
library(e1071)
library(ggplot2)
library(tidymodels)
library(tidymodels)
library(embed)
# Helper packages
library(readr) # for importing data
library(vip)
library(ranger)
# Read all the 9 T20 leagues
df1=read.csv("output3/matchesBBL3.csv")
df2=read.csv("output3/matchesCPL3.csv")
df3=read.csv("output3/matchesIPL3.csv")
df4=read.csv("output3/matchesNTB3.csv")
df5=read.csv("output3/matchesPSL3.csv")
df6=read.csv("output3/matchesSSM3.csv")
df7=read.csv("output3/matchesT20M3.csv")
df8=read.csv("output3/matchesT20W3.csv")
df9=read.csv("output3/matchesWBB3.csv")
# Bind into a single dataframe
df=rbind(df1,df2,df3,df4,df5,df6,df7,df8,df9)
set.seed(123)
df$isWinner = as.factor(df$isWinner)
#Split data into training, validation and test sets
splits <- initial_split(df,prop = 0.80)
df_other <- training(splits)
df_test <- testing(splits)
set.seed(234)
val_set <- validation_split(df_other, prop = 0.80)
val_set
2) Create a Random Forest model tuning for number of predictor nodes at each decision node (mtry) and minimum number of predictor nodes (min_n)
3) Use the ranger engine and set up for classification
4) Set up the recipe and include batsman and bowler embeddings
5) Create a workflow and add the recipe and the random forest model with the tuning parameters
# Use all 12 cores parallely
cores <- parallel::detectCores()
cores
[1] 12
# Create the random forest model with mtry and min as tuning parameters
rf_mod <-
rand_forest(mtry = tune(), min_n = tune(), trees = 1000) %>%
set_engine("ranger", num.threads = cores) %>%
set_mode("classification")
# Setup the recipe with batsman and bowler embeddings
rf_recipe <-
recipe(isWinner ~ ., data = df_other) %>%
step_embed(batsman,bowler, outcome = vars(isWinner))
# Create the random forest workflow
rf_workflow <-
workflow() %>%
add_model(rf_mod) %>%
add_recipe(rf_recipe)
rf_mod
# show what will be tuned
extract_parameter_set_dials(rf_mod)
set.seed(345)
# specify which values meant to tune
# Build the model
rf_res <-
rf_workflow %>%
tune_grid(val_set,
grid = 10,
control = control_grid(save_pred = TRUE),
metrics = metric_set(accuracy,roc_auc))
# Pick the best roc_auc and the associated tuning parameters
rf_res %>%
show_best(metric = "roc_auc")
# A tibble: 5 × 8
mtry min_n .metric .estimator mean n std_err .config
<int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
1 4 4 roc_auc binary 0.980 1 NA Preprocessor1_Model08
2 9 8 roc_auc binary 0.979 1 NA Preprocessor1_Model03
3 8 16 roc_auc binary 0.974 1 NA Preprocessor1_Model10
4 7 22 roc_auc binary 0.969 1 NA Preprocessor1_Model09
5 5 19 roc_auc binary 0.969 1 NA Preprocessor1_Model06
rf_res %>%
show_best(metric = "accuracy")
# A tibble: 5 × 8
mtry min_n .metric .estimator mean n std_err .config
<int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
1 4 4 accuracy binary 0.927 1 NA Preprocessor1_Model08
2 9 8 accuracy binary 0.926 1 NA Preprocessor1_Model03
3 8 16 accuracy binary 0.915 1 NA Preprocessor1_Model10
4 7 22 accuracy binary 0.906 1 NA Preprocessor1_Model09
5 5 19 accuracy binary 0.904 1 NA Preprocessor1_Model0
6) Select all models with the best roc_auc. It can be seen that the best roc_auc is 0.980 for mtry=4 and min_n=4
7) Get the model with the highest accuracy. The highest accuracy achieved is 0.927 or 92.7. This accuracy is also for mtry=4 and min_n=4
# Pick the best roc_auc and the associated tuning parameters
rf_res %>%
show_best(metric = "roc_auc")
# A tibble: 5 × 8
mtry min_n .metric .estimator mean n std_err .config
<int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
1 4 4 roc_auc binary 0.980 1 NA Preprocessor1_Model08
2 9 8 roc_auc binary 0.979 1 NA Preprocessor1_Model03
3 8 16 roc_auc binary 0.974 1 NA Preprocessor1_Model10
4 7 22 roc_auc binary 0.969 1 NA Preprocessor1_Model09
5 5 19 roc_auc binary 0.969 1 NA Preprocessor1_Model06
# Display the accuracy of the models in descending order and the parameters
rf_res %>%
show_best(metric = "accuracy")
# A tibble: 5 × 8
mtry min_n .metric .estimator mean n std_err .config
<int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
1 4 4 accuracy binary 0.927 1 NA Preprocessor1_Model08
2 9 8 accuracy binary 0.926 1 NA Preprocessor1_Model03
3 8 16 accuracy binary 0.915 1 NA Preprocessor1_Model10
4 7 22 accuracy binary 0.906 1 NA Preprocessor1_Model09
5 5 19 accuracy binary 0.904 1 NA Preprocessor1_Model0
8) Select the model with the best parameters for accuracy mtry=4 and min_n=4. For this the accuracy is 0.927. For this configuration the roc_auc is also the best at 0.980
9) Plot the Area Under the Curve (AUC). It can be seen that this model performs really well and it hugs the top left.
# Pick the best model
rf_best <-
rf_res %>%
select_best(metric = "accuracy")
# The best model has mtry=4 and min=4
rf_best
mtry min_n .config
<int> <int> <chr>
1 4 4 Preprocessor1_Model08
#Plot AUC
rf_auc <-
rf_res %>%
collect_predictions(parameters = rf_best) %>%
roc_curve(isWinner, .pred_0) %>%
mutate(model = "Random Forest")
autoplot(rf_auc)
10) Create the final model with the best parameters
11) Execute the final fit
12) Plot feature importance, The bowler and batsman embedding followed by perfIndex and runRate are features that contribute the most to the Win Probability
16) Computing Win Probability with Random Forest Model for match
Pakistan-India-2022-10-23
17) Worm -wicket graph of match
Pakistan-India-2022-10-23
C) Win Probability using MLP – Deep Neural Network (DNN) with player embeddings
In this approach the MLP package of Tidymodels was used. Multi-layer perceptron (MLP) with Deep Neural Network (DNN) was used to compute the Win Probability using player embeddings. An accuracy of 0.76 was obtained
1) Read the data
a) Read the data from 9 T20 leagues (BBL, CPL, IPL, NTB, PSL, SSM, T20 Men, T20 Women, WBB) and create a single data frame of ball-by-ball data. Display the data frame
2) Create training.validation and test sets
b) Split to training, validation and test sets. The dataset is initially split into training and test in the ratio 80%:20%. The training data is again split into training and validation in the ratio 80:20
Of the 3 ML models, glmnet, random forest and Multi-layer Perceptron DNN, random forest had the best performance
Random Forest ML model with batsman, bowler embeddings was able to achieve an accuracy of 92.4% and a ROC_AUC of 0.98 with very low false positives, negatives. This was a quantum jump from my earlier random forest model without embeddings which had an accuracy of 73.7% and an ROC_AUC of 0.834
The glmnet and NN models are fairly light weight. Random Forest is computationally very intensive.
It is time!! So last weekend, I turned the wheels, moved the levers and listened to the hiss of steam, as I cranked up my Shiny app GooglyPlusPlus. The ICC Men’s T20 World Cup is just around the corner, and it was time to prepare for this event. This latest GooglyPlusPlus is current with the latest Intl. men’s T20 match data, give or take a few. GooglyPlusPlus can analyze batsmen, bowlers, matches, team-vs-team, team-vs-all teams, besides also ranking batsmen, bowlers and plot performances in Powerplay, middle and death overs.
In this post, I include a quick refresher of some of features of my app GooglyPlusPlus. Note: This is a random sampling of the functions available. There are more than 120+ features available in the app.
Check out your favourite players and your country’s team with GooglyPlusPlus
Note 1: All charts are interactive
Note 2: You can choose a date range for your analysis
Note 3: The data for this app is taken from Cricsheet
T20Batsman tab
This tab includes functions pertaining to individual batsmen. Functions include Runs vs Deliveries, moving average runs, cumulative average run, cumulative average strike rate, runs against opposition, runs at venue etc.
For e.g.
a) Suryakumar Yadav’s (India) cumulative strike rate
b) Mohammed Rizwan’s (Pakistan) performance against opposition
2. T20 Bowler’s Tab
The bowlers tab has functions for computing mean economy rate, moving average wickets, cumulative average wicks, cumulative economy rate, bowlers performance against opposition, bowlers performance in venue, predict wickets and others
A random function is shown below
a) Predict wickets for Wanindu Hasaranga of Sri Lanka
3. T20 Match tab
The match tab has functions that can compute match batting & bowling scorecard, batting partnerships, batsmen performance vs bowlers, bowler’s wicket kind, bowler’s wicket match, match worm graph, match worm wicket graph, team runs across 20 overs, team wickets in 20 overs, teams runs or wickets in powerplay, middle and death overs
Here are a couple of functions from this tab
a) Afghanistan vs Ireland – 2022-08-15
b) Australia vs Sri Lanka – 2019-11-01 – Runs across 20 overs
4. T20 Head-to-head tab
This tab provides the analysis of all combination of T20 teams (countries) in different aspects. This tab can compute the overall batting, bowling scorecard in all matches between 2 countries, batsmen partnerships, performances against bowlers, bowlers vs batsmen, runs, strike rate, wickets, economy rate across 20 overs, runs vs SR plot and wicket vs ER plot in all matches between team and so on. Here are a couple of examples from this tab
a) Bangladesh vs West Indies – Batting scorecard from 2019-01-01 to 2022-07-07
b) Wickets vs ER plot – England vs New Zealand – 2019-01-01 to 2021-11-10
5. T20 Team performance overalltab
This tab provides detailed analysis of the team’s performance against all other teams. As in the previous tab there are functions to compute the overall batting, bowling scorecard of a team against all other teams for any specific interval of time. This can help in picking out the most consistent batsmen, bowlers. Besides there are functions to compute overall batting partnerships, bowler vs batsmen, runs, wickets across 20 overs, run vs SR and wickets vs ER etc.
a) Batsmen vs Bowlers (Rank 1- V Kohli 2019-01-01 to 2022-09-25)
b) team Runs vs SR in Death overs (India) (2019-01-01 to 2022-09-25)
6) Optimisation tab
In the optimisation tab we can check the performance of a specific batsmen against specific bowlers or bowlers against batsmen
a) Batsmen vs Bowlers
b) Bowlers vs batsmen
7) T20 Batting Performancetab
This tab performs various analytics like ranking batsmen based on Run over SR and SR over Runs. Also you can plot overall Runs vs SR, and more specifically Runs vs SR in Powerplay, Middle and Death overs. All of this can be done for a specific date range. Here are some examples. The data includes all of T20 (all countries all matches)
a) Rank batsmen (Runs over SR, minimum matches played=33, date range=2019-01-01 to 2022-09-27)
The top 3 batsmen are Mohamen Rizwan, V Kohli and Babar Azam
b) Overall runs vs SR plot (2019-01-01 to 2022-09-27)
c) Overall Runs vs SR in Powerplay (all teams- 2019-01-01-2022-09-27)
This plot will be crowded. However, we can zoom into an area of interest. The controls for interacting with the plot are in the top of the plot as shown
Zooming in and panning to the area we can see the best performers in powerplay are as below
8) T20 Bowling Performancetab
This tab computes and ranks bowlers on Wickets over Economy and Economy rate over wickets. We can also compute and plot the Wickets vs ER in all matches , besides the Wickets vs ER in powerplay, middle and death overs with data from all countries
a) Rank Bowlers (Wickets over ER, minimum matches=28, 2019-01-01 to 2022-09-27)
b) Wickets vs ER plot
S Lamichhane (NEP), Hasaranga (SL) and Shamsi (SA) are excellent bowlers with high wickets and low ER as seen in the plot below
c) Wickets vs ER in death overs (2019-01-01 to 2022-09-27, min matches=24)
Zooming in and panning we see the best performers in death overs are MR Adair (IRE), Haris Rauf(PAK) and Chris Jordan (ENG)
With the excitement building up, it is time you checked out how your country will perform and the players who will do well.
IPL 2022 has just concluded and yet again, it is has thrown a lot of promising and potential youngsters in its wake, while established players have fallen! With IPL 2022, we realise that “Sceptre and Crownmusttumble down” and that ‘theglories‘ of form and class like everything else are “shadows not substantial things” (Death the Leveller by James Shirley).
So King Kohli had to kneel, and hitman’ himself got hit. Rishabh Pant, Jadeja also had a poor season. On the contrary there were several youngsters who shone like Abhishek Sharma, Tilak Verma, Umran Malik or a Mohsin Khan
This post is about my potential T20 Indian players for the World Cup 2022 and beyond.
The post below includes my own analysis and thoughts. Feel free to try out my Shiny app GooglyPlusPlus and draw your own conclusions.
How often we hear that data by itself is useless, unless we can draw insights from it? This is a prevailing theme in the corporate world and everybody uses all sorts of tools to analyse and subsequently draw insights. Data analysis can be done in many ways as data can be sliced, diced, chopped in a zillion ways. There are many facets and perspectives to analysing data. Creating insights is easy, but arriving at actionable insights is anything but. So, the problem of selecting the best 11 is difficult as there are so many ways to look at the analysis. My Shiny app GooglyPlusPlus based on my R package yorkr can analyse data in several ways namely
Batsman analysis
Bowler analysis
Match analysis
Team vs team analysis
Team vs all teams analysis
Batsman vs bowler and vice versa
Analysis of in 3,4,5 in power play, middle and death overs
GooglyPlusPlus uses my R package yorkr which has ~ 160 functions some which have several options. So, we can say roughly there are ~500 different ways that analysis can be done or in other words we can gather almost roughly 500+ different insights, not to mention that there are so many combinations of head-on matches and one-vs-all matches.
So generating insights or different ways of analysis data alone is not enough. The question is whether we can get a consolidated view from the different insights. In this post, I try to identify the best contenders for the Indian T20 team. This is far more difficult than it looks. Do you select players on past historical performance or do you choose from the newer crop of players, who have excelled in the recent IPL season. I think this boils down the typical situation in any domain. In engineering, we have tradeoffs – processing power vs memory tradeoff, throughput vs latency tradeoff or in the financial domain it is cost vs benefit or risk vs reward tradeoff. For team selection, the quandary is, whether to choose seasoned players with good historical performance but a poor performances in recent times or go with youngsters who have played with great courage and flair in this latest episode of IPL 2022. Hence there is a tradeoff between reliable but below average performance or risky but superlative performances of new players.
For this I base my potential list from
Then (past history of batsmen & bowlers) – I have chosen the performance of batsmen and bowlers in the last 3 years. With we can arrive at those who have had reasonably reliable performance for the last 3 years
Now (IPL 2022) – Performance in the current season IPL 2022
A. Then (Jan 2020 – May 2022) – Batsmen analysis
In this section I analyse the performances of batsmen and bowlers from Jan 2022 – May 2022. This is done based on ranking, and plots of Runs vs Strike Rate in Power Play, Middle and Death overs
Also I analyse bowlers based on the overall rank from Jan 2022- May 2022. Further more analysis is done on Wickets vs Economy Rate overall and in Power Play, Middle and Death overs
a. Ranks of batsmen (Runs over Strike Rate) : Jan 2020 – May 2022
IPL 2022 just finished and clearly brings out the batsmen who are in great nick. It is always going to be a judgment call of whether to go for ‘old reliable’ or ‘new and awesome’.
a. Ranks of batsmen (Runs over Strike Rate) : IPL 2022
The best batsmen this season in Runs over Strike rate are
f. Best batsmen Runs vs SR in Death overs:IPL 2022
Top batsmen in death overs in IPL 2022
[Dinesh Karthik, Rahul Tewatia, MS Dhoni, KL Rahul, Azar Patel, Washington Sundar, R Ashwin, Hardik Pandya, Ayush Badoni, Shivam Dube, Suryakumar Yadav, Ravindra Jadeja, Sanju Samson]
OverallBattingPerformance in season
Kohli peaked in 2016 and from then on it has been a downward slide (see below)
Taking a look at Kohli’s moving average it is clear that he is past his prime and it will take a herculean effort to regain his lost glory
Similarly, Rohit Sharma’s moving average is constantly around ~30 as seen below
The cumulative average of Rohit Sharma is shown below
Comparing KL Rahul, Shikhar Dhawan, Rohit Sharma and V Kohli we see that KL Rahul and Shikhar Dhawan have had a much superior performance in the last 2-3 years. Rohit has averaged about ~25 runs every season.
Comparing the 4 wicket-keeper batsmen Sanju Samson, Rishabh Pant, Ishan Kishan and Dinesh Karthik from 2016
i) Runs over Strike Rate
We see that Pant peaked in 2018 but has not performed as well since. In the last 2 years Sanju Samson and Ishan Kishan have done well
ii) Strike Rate over Runs
For the last couple of seasons Rishabh Pant and Dinesh Kartik top the strike rate over the other 2
Similar analysis can be done other combinations of batsmen
Choosing the best batsmen from the above, my top 5 batsmen would be
Personally, I feel Ishan Kishan and Shreyas Iyer are a little tardy while playing express speeds, as compared to Sanju Samson or Rishabh Pant.
If you notice, I have not included both Virat Kohli or Rohit Sharma who have been below par for some time
C.Then (Jan 2020 – May 2022) – Bowler analysis
This section I analyse the performances of bowlers from Jan 2022 – May 2022. This is done based on ranking, and plots of Wickets vs Economy Rate in Power Play, Middle and Death overs
a. Ranks of bowlers (Wickets over Economy Rate) : Jan 2020 – May 2022
The most consistent bowlers Wickets over Economy Rate for the last 3 years are
[YS Chahal, Jasprit Bumrah, Mohammed Dhami, Harshal Patel, Shardul Thakur, Arshdeep Singh, Rahul Chahar, Varun Chakravarthy, Ravi Bishnoi, Prasidh Krishna, R Ashwon, Axar Patel, Mohammed Siraj, Ravindra Jadeja, Krunal Pandya, Rahul Tewatia]
b. Ranks of bowlers (Economy Rate over Wickets) : Jan 2020 – May 2022
The most economical bowlers since 2020 are
[Axar Patel, Krunal Pandya, Jasprit Bumrah, CV Varun, R Ashwin, Ravi Bishnoi, Rahul Chahar, YS Chahal, Ravindra Jadeja, Harshal Patel, Mohammed Shami, Mohammed Siraj, Rahul Tewatia, Arshdeep Singh, Prasidh Krishna, Shardul Thakur]
c.BestBowlers Wickets vs ER :Jan 2020 – May 2022
The best bowlers Wickets vs ER will be in the bottom right quadrant. The most consistent and reliable bowlers are
[YS Chahal, Jasprit Bumrah, Mohammed Shami, Harshal Patel, CV Arun, Ravi Bishnoi, Rahul Chahar, R Ashwin, Axar Patel]
d. Best bowlers Wickets vs ER in Powerplay:Jan 2020 – May 2022
The best bowlers in Powerplay are
[Mohammed Shami, Deepak Chahar, Mohammed Siraj, Arshdeep Singh, Jasprit Bumrah, Avesh Khan, Mukesh Choudhary, Shardul Thakur, T Natarajan, Bhuvaneshwar Kumar, WashingtonSundar, Shivam Mavi]
e. Best bowlers Wickets vs ER in Middle overs : Jan 2020 – May 2022
The most reliable performers in middle overs from 2020-2022 are
[YS Chahal, Rahul Chahr, Ravi Bishnoi, Harshal Patel, Axar Patel, Jasprit Bumrah, Umran Malik, R Ashwin, Avesh Khan, Shardul Thakur, Kuldeep Yadav]
f. Best bowlers Wickets vs ER in Death overs : Jan 2020 – May 2022
The most reliable bowlers are
[Harshal Patel, Mohammed Shami, Jasprit Bumrah, Arshdeep Singh, T Natarajan, Avesh Khan, Shardul Thakur, Bhuvaneshwar Kumar, Shivam Mavi, YS Chahal, Prasidh Krishna, Mohammed Siraj, Chetan Sakariya]
B) Now (IPL 2022)– Bowler analysis
a. Ranks of bowlers (Wickets over Economy Rate) : IPL 2022
The best bowlers in IPL 2022 when considering Wickets over Economy Rate
[YS Chahal, Umran Malik, Prasidh Krishna, Mohammed Shami, Kuldeep Yadav, Harshal Patel, T Natarajan, Avesh Khan, Shardul Thakur, Mukesh Choudhary, Jasprit Bumrah, Ravi Bishnoi]
a. Ranks of bowlers (Economy Rate over Wickets) : IPL 2022
The most economical bowlers in IPL 2022 are
[Axar Patel, Jasprit Bumrah, Krunal Pandya, Umesh Yadav, Bhuvaneshwar Kumar, Rahul Chahr, Harshal Patel, Arshdeep Singh, R Ashwion, Umran Malik, Kuldeep Yadav, YS Chahal, Mohammed Shami, Avesh Khan, Prasidh Krishna]
c.BestBowlers Wickets vs ER :IPL 2022
The overall best bowlers in IPL 2022 are
[YS Chahal, Umran Malik, Harshal Patel, Prasidh Krishna, Mohammed Shami, Kuldeep Yadav, Avesh Khan, Jasprit Bumrah, Umesh Yadav, Bhuvaneshwar Kumar, Arshdeep Singh, R Ashwin, Rahul Chahar, Krunal Pandya]
d. Best bowlers Wickets vs ER in Powerplay: IPL 2022
The best bowlers in IPL 2022 in Power play are
[Mukesh Choudhary, Mohammed Shami, Prasidh Krishna, Umesh Yadav, Avesh Khan, Mohsin Khan, T Natarajan, Jasprit Bumrah, Yash Dayal, Mohammed Siraj]
d. Best bowlers Wickets vs ER in Middle overs: IPL 2022
The best bowlers in IPL 2022 during middle overs
The best bowlers are
[YS Chahal, Umran Malik, Kuldeep Yadav, Harshal Patel, Ravi Bishnoi, R Ashwin]
e. Best bowlers Wickets vs ER in Death overs: IPL 2022
The best bowlers in death overs in IPL 2022 are
[T Natarajan, Harshal Patel, Bhuvaneshwar Kumar, Mohammed Shami, Jasprit Bumrah, Shardul Thakur, YS Chahal, Prasidh Krishna, Avesh Khan, Mohsin Khan, Yash Dayal, Umran Malik, Arshdeep Singh]
Typically in a team we would need a combination of 4 bowlers (2 fast & 2 spinner or 3 fast and 1 spinner) with an additional player who is all rounder.
For 4 bowlers we could have
JJ Bumrah
Mohammed Shami, Umran Malik, Bhuvaneshwar Kumar, Umesh Yadav
Arshdeep Singh, Avesh Khan, Mohsin Khan, Harshal Patel
YS Chahal, Ravi Bishnoi, Rahul Chahar, Axar Patel
Ravindra Jadeja, Hardik Pandya, Rahul Tewathia, R Ashwin
i) Performance comparison (Wickets over Economy Rate)
Bumrah had the best season in 2020. He has been doing quite well and has been among the wickets
ii) Performance comparison (Economy Rate over Wickets)
Bumrah has the best Economy Rate
We can do a wicket prediction of bowlers. So for example for Bumrah it is
iii) Performance evaluation(Wickets over Economy Rate)
Harshal Patel followed by Avesh Khan had a good season last year, but Umran Malik pipped them this year (see below)
iv) Performance analysis of spinners
a. Wickets over Economy Rate: 2022
Chahal has the best season followed by Bishnoi and Chahar this season
b) Economy Rate over WIckets
Axar Patel has the best economy rate followed by Rahul Chahar
Conclusion
The above post identified the best candidates for the Indian team in the future and beyond. In my T20 list, I have neither included Virat Kohli or Rohit Sharma. The data in T20 clearly indicates that they have had their days. There is a lot more talent around. The tradeoff is a little risk for a greater potential performance. My list would be
Often times before crucial matches, or in general, we would like to know the performance of a batsman against a bowler or vice-versa, but we may not have the data. We generally have data where different batsmen would have faced different sets of bowlers with certain performance data like ballsFaced, totalRuns, fours, sixes, strike rate and timesOut. Similarly different bowlers would have performance figures(deliveries, runsConceded, economyRate and wicketTaken) against different sets of batsmen. We will never have the data for all batsmen against all bowlers. However, it would be good estimate the performance of batsmen against a bowler, even though we do not have the performance data. This could be done using collaborative filtering which identifies and computes based on the similarity between batsmen vs bowlers & bowlers vs batsmen.
This post shows an approach whereby we can estimate a batsman’s performance against bowlers even though the batsman may not have faced those bowlers, based on his/her performance against other bowlers. It also estimates the performance of bowlers against batsmen using the same approach. This is based on the recommender algorithm which is used to recommend products to customers based on their rating on other products.
This idea came to me while generating the performance of batsmen vs bowlers & vice-versa for 2 IPL teams in this IPL 2022 with my Shiny app GooglyPlusPlus in the optimization tab, I found that there were some batsmen for which there was no data against certain bowlers, probably because they are playing for the first time in their team or because they were new (see picture below)
In the picture above there is no data for Dewald Brevis against Jasprit Bumrah and YS Chahal. Wouldn’t be great to estimate the performance of Brevis against Bumrah or vice-versa? Can we estimate this performance?
While pondering on this problem, I realized that this problem formulation is similar to the problem formulation for the famous Netflix movie recommendation problem, in which user’s ratings for certain movies are known and based on these ratings, the recommender engine can generate ratings for movies not yet seen.
This post estimates a player’s (batsman/bowler) using the recommender engine This post is based on R package recommenderlab
You can download this R Markdown file and the associated data and perform the analysis yourself using any other recommender engine from Github at playerPerformanceEstimation
Problem statement
In the table below we see a set of bowlers vs a set of batsmen and the number of times the bowlers got these batsmen out. By knowing the performance of the bowlers against some of the batsmen we can use collaborative filter to determine the missing values. This is done using the recommender engine.
The Recommender Engine works as follows. Let us say that there are feature vectors , and for the 3 bowlers which identify the characteristics of these bowlers (“fast”, “lateral drift through the air”, “movement off the pitch”). Let each batsman be identified by parameter vectors , and so on
For e.g. consider the following table
Then by assuming an initial estimate for the parameter vector and the feature vector xx we can formulate this as an optimization problem which tries to minimize the error for This can work very well as the algorithm can determine features which cannot be captured. So for e.g. some particular bowler may have very impressive figures. This could be due to some aspect of the bowling which cannot be captured by the data for e.g. let’s say the bowler uses the ‘scrambled seam’ when he is most effective, with a slightly different arc to the flight. Though the algorithm cannot identify the feature as we know it, but the ML algorithm should pick up intricacies which cannot be captured in data.
Hence the algorithm can be quite effective.
Note: The recommender lab performance is not very good and the Mean Square Error is quite high. Also, the ROC and AUC curves show that not in aLL cases the algorithm is doing a clean job of separating the True positives (TPR) from the False Positives (FPR)
Note: This is similar to the recommendation problem
The collaborative optimization object can be considered as a minimization of both and the features x and can be written as
J(, }= 1/2
The collaborative filtering algorithm can be summarized as follows
Initialize , … and the set of features be ,, … , to small random values
Minimize J(, … ,, , … ,) using gradient descent. For every j=1,2, …, i= 1,2,..,
:= – ( ) –
&
:= – (
Hence for a batsman with parameters and a bowler with (learned) features x, predict the “times out” for the player where the value is not known using
The above derivation for the recommender problem is taken from Machine Learning by Prof Andrew Ng at Coursera from the lecture Collaborative filtering
There are 2 main types of Collaborative Filtering(CF) approaches
User based Collaborative Filtering User-based CF is a memory-based algorithm which tries to mimics word-of-mouth by analyzing rating data from many individuals. The assumption is that users with similar preferences will rate items similarly.
Item based Collaborative Filtering Item-based CF is a model-based approach which produces recommendations based on the relationship between items inferred from the rating matrix. The assumption behind this approach is that users will prefer items that are similar to other items they like.
1a. A note on ROC and Precision-Recall curves
A small note on interpreting ROC & Precision-Recall curves in the post below
ROC Curve: The ROC curve plots the True Positive Rate (TPR) against the False Positive Rate (FPR). Ideally the TPR should increase faster than the FPR and the AUC (area under the curve) should be close to 1
Precision-Recall: The precision-recall curve shows the tradeoff between precision and recall for different threshold. A high area under the curve represents both high recall and high precision, where high precision relates to a low false positive rate, and high recall relates to a low false negative rate
Helper functions for the RMarkdown notebook are created
eval – Gives details of RMSE, MSE and MAE of ML algorithm
evalRecomMethods – Evaluates different recommender methods and plot the ROC and Precision-Recall curves
# This function returns the error for the chosen algorithm and also predicts the estimates
# for the given data
eval <- function(data, train1, k1,given1,goodRating1,recomType1="UBCF"){
set.seed(2022)
e<- evaluationScheme(data,
method = "split",
train = train1,
k = k1,
given = given1,
goodRating = goodRating1)
r1 <- Recommender(getData(e, "train"), recomType1)
print(r1)
p1 <- predict(r1, getData(e, "known"), type="ratings")
print(p1)
error = calcPredictionAccuracy(p1, getData(e, "unknown"))
print(error)
p2 <- predict(r1, data, type="ratingMatrix")
p2
}
# This function will evaluate the different recommender algorithms and plot the AUC and ROC curves
evalRecomMethods <- function(data,k1,given1,goodRating1){
set.seed(2022)
e<- evaluationScheme(data,
method = "cross",
k = k1,
given = given1,
goodRating = goodRating1)
models_to_evaluate <- list(
`IBCF Cosinus` = list(name = "IBCF",
param = list(method = "cosine")),
`IBCF Pearson` = list(name = "IBCF",
param = list(method = "pearson")),
`UBCF Cosinus` = list(name = "UBCF",
param = list(method = "cosine")),
`UBCF Pearson` = list(name = "UBCF",
param = list(method = "pearson")),
`Zufälliger Vorschlag` = list(name = "RANDOM", param=NULL)
)
n_recommendations <- c(1, 5, seq(10, 100, 10))
list_results <- evaluate(x = e,
method = models_to_evaluate,
n = n_recommendations)
plot(list_results, annotate=c(1,3), legend="bottomright")
plot(list_results, "prec/rec", annotate=3, legend="topleft")
}
3. Batsman performance estimation
The section below regenerates the performance for batsmen based on incomplete data for the different fields in the data frame namely balls faced, fours, sixes, strike rate, times out. The recommender lab allows one to test several different algorithms all at once namely
User based – Cosine similarity method, Pearson similarity
Item based – Cosine similarity method, Pearson similarity
Popular
Random
SVD and a few others
3a. Batting dataframe
head(df)
## batsman1 bowler1 ballsFaced totalRuns fours sixes SR timesOut
## 1 A Badoni A Mishra 0 0 0 0 NaN 0
## 2 A Badoni A Nortje 0 0 0 0 NaN 0
## 3 A Badoni A Zampa 0 0 0 0 NaN 0
## 4 A Badoni Abdul Samad 0 0 0 0 NaN 0
## 5 A Badoni Abhishek Sharma 0 0 0 0 NaN 0
## 6 A Badoni AD Russell 0 0 0 0 NaN 0
3b Data set and data preparation
For this analysis the data from Cricsheet has been processed using my R package yorkr to obtain the following 2 data sets – batsmenVsBowler – This dataset will contain the performance of the batsmen against the bowler and will capture a) ballsFaced b) totalRuns c) Fours d) Sixes e) SR f) timesOut – bowlerVsBatsmen – This data set will contain the performance of the bowler against the difference batsmen and will include a) deliveries b) runsConceded c) EconomyRate d) wicketsTaken
Obviously many rows/columns will be empty
This is a large data set and hence I have filtered for the period > Jan 2020 and < Dec 2022 which gives 2 datasets a) batsmanVsBowler20_22.rdata b) bowlerVsBatsman20_22.rdata
I also have 2 other datasets of all batsmen and bowlers in these 2 dataset in the files c) all-batsmen20_22.rds d) all-bowlers20_22.rds
## A Mishra A Nortje A Zampa Abdul Samad Abhishek Sharma
## A Badoni NA NA NA NA NA
## A Manohar NA NA NA NA NA
## A Nortje NA NA NA NA NA
## AB de Villiers NA 4 3 NA NA
## Abdul Samad NA NA NA NA NA
## Abhishek Sharma NA NA NA NA NA
## AD Russell 1 NA NA NA NA
## AF Milne NA NA NA NA NA
## AJ Finch NA NA NA NA 3
## AJ Tye NA NA NA NA NA
## AD Russell AF Milne AJ Tye AK Markram Akash Deep
## A Badoni NA NA NA NA NA
## A Manohar NA NA NA NA NA
## A Nortje NA NA NA NA NA
## AB de Villiers 3 NA 3 NA NA
## Abdul Samad NA NA NA NA NA
## Abhishek Sharma NA NA NA NA NA
## AD Russell NA NA 6 NA NA
## AF Milne NA NA NA NA NA
## AJ Finch NA NA NA NA NA
## AJ Tye NA NA NA NA NA
The dots below represent data for which there is no performance data. These cells need to be estimated by the algorithm
set.seed(2022)
r <- as(df8,"realRatingMatrix")
getRatingMatrix(r)[1:15,1:15]
## 15 x 15 sparse Matrix of class "dgCMatrix"
## [[ suppressing 15 column names 'A Mishra', 'A Nortje', 'A Zampa' ... ]]
The data frame of the batsman vs bowlers from the period 2020 -2022 is read as a dataframe. To remove rows with very low number of ratings(timesOut, SR, Fours, Sixes etc), the rows are filtered so that there are at least more 10 values in the row. For the player estimation the dataframe is converted into a wide-format as a matrix (m x n) of batsman x bowler with each of the columns of the dataframe i.e. timesOut, SR, fours or sixes. These different matrices can be considered as a rating matrix for estimation.
A similar approach is taken for estimating bowler performance. Here a wide form matrix (m x n) of bowler x batsman is created for each of the columns of deliveries, runsConceded, ER, wicketsTaken
5. Batsman’s times Out
The code below estimates the number of times the batsmen would lose his/her wicket to the bowler. As discussed in the algorithm above, the recommendation engine will make an initial estimate features for the bowler and an initial estimate for the parameter vector for the batsmen. Then using gradient descent the recommender engine will determine the feature and parameter values such that the over Mean Squared Error is minimum
From the plot for the different algorithms it can be seen that UBCF performs the best. However the AUC & ROC curves are not optimal and the AUC> 0.5
df3 <- select(df, batsman1,bowler1,timesOut)
df6 <- xtabs(timesOut ~ ., df3)
df7 <- as.data.frame.matrix(df6)
df8 <- data.matrix(df7)
df8[df8 == 0] <- NA
r <- as(df8,"realRatingMatrix")
# Filter only rows where the row count is > 10
r0=r[(rowCounts(r) > 10),]
getRatingMatrix(r0)[1:10,1:10]
## 10 x 10 sparse Matrix of class "dgCMatrix"
## [[ suppressing 10 column names 'A Mishra', 'A Nortje', 'A Zampa' ... ]]
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.000 3.000 3.000 3.463 4.000 21.000
# Evaluate the different plotting methods
evalRecomMethods(r0[1:dim(r0)[1]],k1=5,given=7,goodRating1=median(getRatings(r0)))
#Evaluate the error
a=eval(r0[1:dim(r0)[1]],0.8,k1=5,given1=7,goodRating1=median(getRatings(r0)),"UBCF")
## Recommender of type 'UBCF' for 'realRatingMatrix'
## learned using 70 users.
## 18 x 145 rating matrix of class 'realRatingMatrix' with 1755 ratings.
## RMSE MSE MAE
## 2.069027 4.280872 1.496388
b=round(as(a,"matrix")[1:10,1:10])
c <- as(b,"realRatingMatrix")
m=as(c,"data.frame")
names(m) =c("batsman","bowler","TimesOut")
6. Batsman’s Strike rate
This section deals with the Strike rate of batsmen versus bowlers and estimates the values for those where the data is incomplete using UBCF method.
Even here all the algorithms do not perform too efficiently. I did try out a few variations but could not lower the error (suggestions welcome!!)
## Recommender of type 'UBCF' for 'realRatingMatrix'
## learned using 105 users.
## 27 x 145 rating matrix of class 'realRatingMatrix' with 3220 ratings.
## RMSE MSE MAE
## 77.71979 6040.36508 58.58484
b=round(as(a,"matrix")[1:10,1:10])
c <- as(b,"realRatingMatrix")
n=as(c,"data.frame")
names(n) =c("batsman","bowler","SR")
7. Batsman’s Sixes
The snippet of code estimes the sixes of the batsman against bowlers. The ROC and AUC curve for UBCF looks a lot better here, as it significantly greater than 0.5
## Recommender of type 'UBCF' for 'realRatingMatrix'
## learned using 52 users.
## 14 x 145 rating matrix of class 'realRatingMatrix' with 1634 ratings.
## RMSE MSE MAE
## 3.529922 12.460350 2.532122
b=round(as(a,"matrix")[1:10,1:10])
c <- as(b,"realRatingMatrix")
o=as(c,"data.frame")
names(o) =c("batsman","bowler","Sixes")
## Recommender of type 'UBCF' for 'realRatingMatrix'
## learned using 67 users.
## 17 x 145 rating matrix of class 'realRatingMatrix' with 2083 ratings.
## RMSE MSE MAE
## 5.486661 30.103447 4.060990
b=round(as(a,"matrix")[1:10,1:10])
c <- as(b,"realRatingMatrix")
p=as(c,"data.frame")
names(p) =c("batsman","bowler","Fours")
9. Batsman’s Total Runs
The code below estimates the total runs that would have scored by the batsman against different bowlers
## Recommender of type 'UBCF' for 'realRatingMatrix'
## learned using 105 users.
## 27 x 145 rating matrix of class 'realRatingMatrix' with 3256 ratings.
## RMSE MSE MAE
## 41.50985 1723.06788 29.52958
b=round(as(a,"matrix")[1:10,1:10])
c <- as(b,"realRatingMatrix")
q=as(c,"data.frame")
names(q) =c("batsman","bowler","TotalRuns")
10. Batsman’s Balls Faced
The snippet estimates the balls faced by batsmen versus bowlers
## Recommender of type 'UBCF' for 'realRatingMatrix'
## learned using 112 users.
## 28 x 145 rating matrix of class 'realRatingMatrix' with 3378 ratings.
## RMSE MSE MAE
## 33.91251 1150.05835 23.39439
b=round(as(a,"matrix")[1:10,1:10])
c <- as(b,"realRatingMatrix")
r=as(c,"data.frame")
names(r) =c("batsman","bowler","BallsFaced")
11. Generate the Batsmen Performance Estimate
This code generates the estimated dataframe with known and ‘predicted’ values
## batsman bowler BallsFaced TotalRuns Fours Sixes SR TimesOut
## 1 AB de Villiers A Mishra 94 124 7 5 144 5
## 2 AB de Villiers A Nortje 26 42 4 3 148 3
## 3 AB de Villiers A Zampa 28 42 5 7 106 4
## 4 AB de Villiers Abhishek Sharma 22 28 0 10 136 5
## 5 AB de Villiers AD Russell 70 135 14 12 207 4
## 6 AB de Villiers AF Milne 31 45 6 6 130 3
12. Bowler analysis
Just like the batsman performance estimation we can consider the bowler’s performances also for estimation. Consider the following table
As in the batsman analysis, for every batsman a set of features like (“strong backfoot player”, “360 degree player”,“Power hitter”) can be estimated with a set of initial values. Also every bowler will have an associated parameter vector θθ. Different bowlers will have performance data for different set of batsmen. Based on the initial estimate of the features and the parameters, gradient descent can be used to minimize actual values {for e.g. wicketsTaken(ratings)}.
load("recom_data/bowlerVsBatsman20_22.rdata")
12a. Bowler dataframe
Inspecting the bowler dataframe
head(df2)
## bowler1 batsman1 balls runsConceded ER wicketTaken
## 1 A Mishra A Badoni 0 0 0.000000 0
## 2 A Mishra A Manohar 0 0 0.000000 0
## 3 A Mishra A Nortje 0 0 0.000000 0
## 4 A Mishra AB de Villiers 63 61 5.809524 0
## 5 A Mishra Abdul Samad 0 0 0.000000 0
## 6 A Mishra Abhishek Sharma 2 3 9.000000 0
## Recommender of type 'UBCF' for 'realRatingMatrix'
## learned using 96 users.
## 24 x 195 rating matrix of class 'realRatingMatrix' with 3954 ratings.
## RMSE MSE MAE
## 30.72284 943.89294 19.89204
b=round(as(a,"matrix")[1:10,1:10])
c <- as(b,"realRatingMatrix")
s=as(c,"data.frame")
names(s) =c("bowler","batsman","BallsBowled")
14. Runs conceded by bowler
This section estimates the runs conceded by the bowler. The UBCF Cosinus algorithm performs the best with TPR increasing fastewr than FPR
## Recommender of type 'UBCF' for 'realRatingMatrix'
## learned using 95 users.
## 24 x 195 rating matrix of class 'realRatingMatrix' with 3820 ratings.
## RMSE MSE MAE
## 43.16674 1863.36749 30.32709
b=round(as(a,"matrix")[1:10,1:10])
c <- as(b,"realRatingMatrix")
t=as(c,"data.frame")
names(t) =c("bowler","batsman","RunsConceded")
15. Economy Rate of the bowler
This section computes the economy rate of the bowler. The performance is not all that good
## Recommender of type 'UBCF' for 'realRatingMatrix'
## learned using 95 users.
## 24 x 195 rating matrix of class 'realRatingMatrix' with 3839 ratings.
## RMSE MSE MAE
## 4.380680 19.190356 3.316556
b=round(as(a,"matrix")[1:10,1:10])
c <- as(b,"realRatingMatrix")
u=as(c,"data.frame")
names(u) =c("bowler","batsman","EconomyRate")
16. Wickets Taken by bowler
The code below computes the wickets taken by the bowler versus different batsmen
## Recommender of type 'UBCF' for 'realRatingMatrix'
## learned using 64 users.
## 16 x 195 rating matrix of class 'realRatingMatrix' with 1908 ratings.
## RMSE MSE MAE
## 2.672677 7.143203 1.956934
b=round(as(a,"matrix")[1:10,1:10])
c <- as(b,"realRatingMatrix")
v=as(c,"data.frame")
names(v) =c("bowler","batsman","WicketTaken")
17. Generate the Bowler Performance estmiate
The entire dataframe is regenerated with known and ‘predicted’ values
## bowler batsman BallsBowled RunsConceded EconomyRate WicketTaken
## 1 A Mishra AB de Villiers 102 144 8 4
## 2 A Mishra Abdul Samad 13 20 7 4
## 3 A Mishra Abhishek Sharma 14 26 8 2
## 4 A Mishra AD Russell 47 85 9 3
## 5 A Mishra AJ Finch 45 61 11 4
## 6 A Mishra AJ Tye 14 20 5 4
18. Conclusion
This post showed an approach for performing the Batsmen Performance Estimate & Bowler Performance Estimate. The performance of the recommender engine could have been better. In any case, I think this approach will work for player estimation provided the recommender algorithm is able to achieve a high degree of accuracy. This will be a good way to estimate as the algorithm will be able to determine features and nuances of batsmen and bowlers which cannot be captured by data.
It is that time of the year when there is “a song in the air, the lark’s on the wing, and the snail’s on the the thorn“. Yes, it is the that time of year when the grand gala event of IPL 2022 is underway. So, I managed to wake myself from my Covid-induced slumber, worked up my ‘creaking bones‘ and cranked up the GooglyPlusPlus machinery.
So now, every morning, a scheduled CRON tab entry will automatically download the previous night’s match data from Cricsheet, unzip, process and transform it into the necessary format required by my R package yorkr, and make it available to my Shiny app GooglyPlusPlus. Hence the data is current and you have access to ‘analytics-in-the-now’!.
As you know in 2021, I added a lot of new features to GooglyPlusPlus, new tabs to do even more. analytics – or in other words there is “more GooglyPlusPlus per click!!”. So now, you have the following
Batsman tab: For detailed analysis of batsmen
Bowler tab: For detailed analysis of bowlers
Match tab: Analysis of individual matches, plot of Runs vs SR, Wickets vs ER in power play, middle and death overs
Head-to-head tab: Detailed analysis of team-vs-team batting/bowling scorecard, batting, bowling performances, performances in power play, middle and death overs
Team performance tab: Analysis of team-vs-all other teams with batting /bowling scorecard, batting, bowling performances, performances in power play, middle and death overs
Optimisation tab: Allows one to pit batsmen vs bowlers and vice-versa. This tab also uses integer programming to optimise batting and bowling lineup
Batting analysis tab: Ranks batsmen using Runs or SR. Also plots performances of batsmen in power play, middle and death overs and plots them in a 4×4 grid
Bowling analysis tab: Ranks bowlers based on Wickets or ER. Also plots performances of bowlers in power play, middle and death overs and plots them in a 4×4 grid
Also note all these tabs and features are available for all T20 formats namely IPL, Intl. T20 (men, women), BBL, NTB, PSL, CPL, SSM.
Note: All charts are interactive, which means that you can hover, zoom-in, zoom-out, pan etc on the charts
The latest avatar of GooglyPlusPlus2022 is based on my R package yorkr with data from Cricsheet.
Here are some random analysis that can be done by GooglyPlusPlus across the tabs. Note the app will be updated daily and the analytics will be current throughout the season of IPL 2022
A) Match tab
a) GT vs DC – 2 Apr 2022
Runs vs SR – Gujarat Titans
b) CSK vs LSG – 31 Mar 2022
Runs across 20 overs
c) KKR vs PBKS -Match wicket worm chart – 1 Apr 2022
B) Batsmen tab
a) Faf Du Plessis – Runs vs Deliveries
b) Sanju Samson – Runs against opposition
C) Bowler’s tab
a) D J Bravo – No of deliveries to wicket
b) Trent Boult – Wickets at Venues
D) Head-to-head tab
a) DC vs MI – Mar -2019 till date : Batting scorecard
b) CSK vs KKR – Jan 2019 till date : Runs vs SR
E) Team vs All Teams tab
a) Punjab Kings vs all Teams – Wickets vs ER in Power play
b) Rajasthan Royals vs all Teams : Jan 2019 till date : Runs vs SR in Power play
F) Optimisation tab
a) Batsmen vs Bowlers
b) Bowlers vs batsmen
G) Batting analysis
This tab is for ranking batsmen
a) Batsmen rank from 2019 till date (Runs over SR)
Analytics is by definition, the science (& art) of identifying, discovering and interpreting patterns in data. There are different ways of capturing these patterns through charts (bar, pie, cumulative data, moving average etc.). One such way is the motion or animated chart which captures the changes in data across different time periods. This was made famous by Hans Rosling in his Gapminder charts.
In this post, I use animated charts, based on gganimate(), to display the rise and fall of batsmen and bowlers in IPL and Intl. T20 (men). I only did this for these 2 formats as they have sufficient data over at least 10+ years.
To construct these animated charts, I use a ‘sliding window’ of 3 years, so that we get a clearer view of batsman and bowler consistency. The animated charts show the performance of players for this moving window for e.g. Jan 2008- Dec 2010, Jan 2009-Dec 2011, Jan 2010- Dec 2012 and so on till Jan 2019- Dec 2021. This is done for both batting( total runs) and bowling (total wickets). If you would like to analyse the performance of particular batsmen, bowler during specific periods or for a team vs another team or in the overall T20 format, check out my post GooglyPlusPlus2021: Towards more picturesque analytics!
You clone/fork the code from Github here animation.
Important note: The year which is displayed on the side actually represents the last 3 years, for e.g. 2015 (2013, 2014, 2015) or 2019 (2017, 2018, 2019)
IPL Batting performance
We can see that Kohli stays in the top 3 from 2015-2019
2. IPL Bowling performance
Malinga ruled from 2010- 2015. Bumrah is in top 3 from 2019-2021
3. IPL Batting in Power play
Adam Gilchrist, Tendulkar, Warner, KL Rahul, Shikhar Dhawan have a stay at the top
4. IPL Batting in Middle overs
Rohit Sharma, Kohli, Pant have their stay at the top
5. IPL Batting Death overs
MS Dhoni is lord and master of the death overs in IPL for a rolling period of 10 years from 2011-2020. No wonder, he is the best finisher of T20 cricket
6. IPL Bowling Power Play
Bhuvanesh Kumar is in top 3 from 2014-2018 and then Deepak Chahar
7. IPL Bowling Middle overs
Toppers Harbhajan Singh, YS Chahal, Rashid Khan
8. IPL Bowling Death overs
SL Malinga, B. Kumar, JJ Bumrah and Rabada top the list across the years
9. T20 (men) Batting performance
Kohli, Babar Azam, P R Stirling are best performers
10. T20 (men) bowling performance
Saaed Ajmal tops from 2010-2014 and Rashid Khan 2018-2020
11. T20 (men) batting Power play
Shahzad, D Warner, Rohit Sharma, PR Stirling best performers
12. T20 (men) batting middle overs
Babar Azam is the best middle overs player from 2018-2021
13. T20(men) batting death overs
MS Dhoni, Shoaib Malik, V Kohli, David Miller are the best death over players
14. T20 (men) bowling Power play
Mohammad Nabi, Mujeeb ur Rahman, TG Southee are the best bowlers in power play
15. T20 (men) bowling middle overs
Imran Tahir from 2015-2017, Shadab Khan from 2018-2020, T Shamsi in 2021 top the tables
16. T20 (men) bowling death overs
Saaed Ajmal, A J Tye, Bumrah, Haris Rauf occupy the top slot in different periods
Analytics for e.g. sports analytics, business analytics or analytics in e-commerce or in other domain has 2 main requirements namely a) What kind of analytics (set of parameters,function) will squeeze out the most intelligence from the data b) How to represent the analytics so that an expert can garner maximum insight?
While it may appear that the former is more important, the latter is also equally, if not, more vital to the problem. Indeed, a picture is worth a thousand words, and often times is more insightful than a large table of numbers. However, in the case of sports analytics, for e.g. in cricket a batting or bowling scorecard captures more information and can never be represented in chart.
So, my Shiny app GooglyPlusPlus includes both charts and tables for different aspects of the analysis. In this post, a newer type of chart, popular among senior management experts, namely the 4 quadrant graph is introduced, which helps in categorising batsmen and bowlers into 4 categories as shown below
a) Batting Performances – Top right quadrant (High runs, High Strike rate)
b) Bowling Performances – Bottom right quadrant( High wickets, Low Economy Rate)
I have added the following 32 functions in this latest version of GooglyPlusPlus
A. Match Tab
All the functions below are at match level
Team Runs vs SR Plot
Team Wickets vs ER Plot
Team Runs vs SR Power play plot
Team Runs vs SR Middle overs plot
Team Runs vs SR Death overs plot
Team Wickets vs ER Power Play
Team Wickets vs ER Middle overs
Team Wickets vs ER Death overs
B. Head-to-head Tab
The below functions are based on all matches between 2 teams’
Team Runs vs SR Plot all Matches
Team Wickets vs ER Plot all Matches
Team Runs vs SR Power play plot all Matches
Team Runs vs SR Middle overs plot all Matches
Team Runs vs SR Death overs plot all Matches
Team Wickets vs ER Power Play plot all Matches
Team Wickets vs ER Middle overs plot all Matches
Team Wickets vs ER Death overs plot all Matches
C. Team Performance tab
The below functions are based on a team’s performance against all other teams
Team Runs vs SR Plot overall
Team Wickets vs ER Plot overall
Team Runs vs SR Power play plot overall
Team Runs vs SR Middle overs plot overall
Team Runs vs SR Death overs plot overall
Team Wickets vs ER Power Play overall
Team Wickets vs ER Middle overs overall
Team Wickets vs ER Death overs overall
D. T20 format Batting Analysis
This analysis is at T20 format level (IPL, Intl. T20(men), Intl. T20 (women), PSL, CPL etc.)
Overall Runs vs SR plot
Overall Runs vs SR Power play plot
Overall Runs vs SR Middle overs plot
Overall Runs vs SR Death overs plot
E. T20 Bowling Analysis
This analysis is at T20 format level (IPL, Intl. T20(men), Intl. T20 (women), PSL, CPL etc.)
Overall Wickets vs ER plot
Team Wickets vs ER Power Play
Team Wickets vs ER Middle overs
Team Wickets vs ER Death overs
These 32 functions have been added to my yorkr package and so all these functions become plug-n-play in my Shiny app GooglyPlusPlus2021 which means that the 32 functions apply across all the nine T20 formats that the app supports i.e. IPL, Intl. T20 (men), Intl. T20 (women), BBL, NTB, PSL, CPL, SSM, WBB.
Hence the multiplicative factor of the new addition is 32 x 9 = 288 additional ways of exploring match, team and player data
You can clone/fork GooglyPlusPlus from Github at gpp2021-10
Check out my app GooglyPlusPlus2021 and analyze batsmen, bowlers, teams, overall performance. The data for all the nine T20 formats have been updated to include the latest data.
Hence, the app is just in time for the IPL mega auction. You should be able to analyse players in IPL, Intl. T20 or in any of the other formats from where they could be drawn and check out their relative standings
I am including some random plots to demonstrate the newly minted functions
Note 1: All plots are interactive. The controls are on the top right. You can hover over data, zoom-in, zoom-out, compare data etc by choosing the appropriate control. To know more about how to use the interactive charts see GooglyPlusPlus2021 is now fully interactive!!!
New Zealand batting, except K Williamson, the rest did not fire as much
For Australia, Warner, Maxwell and Marsh played good knocks to wrest control
II) Head-to-head
a) Wickets vs ER during Power play of Mumbai Indians in all matches against Chennai Super Kings (IPL)
b) Karachi Kings Runs vs SR during middle overs against Multan Sultans (PSL)
c) Wickets vs ER during death overs of Barbados Tridents in all matches against Jamaica Tallawahs (CPL)
III) Teams overall batting performance
India’s best T20 performers in Power play since 2018 (Intl. T20)
e) Australia’s best performers in Death overs since Mar 2017 (Intl. T20)
f) India’s Intl. T20 (women) best Runs vs SR since 2018
g) England’s Intl. T20 (women) best bowlers in Death overs
IV) Overall Batting Performanceacross T20
This tab gives the batsmen’s rank and overall batting performance across the T20 format.
a) Why was Hardik Pandya chosen, and why this was in error?
Of course, it provides an insight into why Hardik Pandya was chosen in India’s World cup team despite poor performances recently. Here are the best Intl. T20 death over batsmen
Of course, we can zoom in to get a better look
This is further substantiated when we performances in IPL
However, if you move the needle forward a year at a time, you see Hardik Pandya’s performance drops significantly
and further down
Rather, Dinesh Karthik, Sanju Samson or Ruturaj Gaikwad would have been better options
b) Best batsmen Intl. T20 (women) in Power play since 2018
V) Overall bowling performance
This tab gives the bowler’s rank and overall bowling performance in Power play, middle and death overs across all T20 formats
a) Intl. T20 (men) best bowlers in Power Play from 2019 (zoomed in)
b) Intl. T20(men) best bowlers in Death overs since 2019
c) Was B. Kumar a good choice for India team in World cup?
Bhuvi was one of India’s best bowler in Power play only if we go back to the beginning of time
i) From 2008
But if we move forward to 2020 onwards we see Arshdeep Singh or D Chahar would have been a better choice
ii) From 2020 onwards
iii) 2021 onwards
Hence D Chahar & Arshdeep Singh are the natural choice moving forwards for India
iv) T20 Best batsman
If we look at Intl. T20 performances since 2017, Babar Azam leads the pack, however his Strike rate needs to move up.
This latest edition of GooglyPlusPlus2021 now includes detailed analysis of teams, batsmen and bowlers in power play, middle and death overs. The T20 format is based on 3 phases as each side faces 20 overs.
Power play: Overs: 0 – 6 – No more than 2 players can be outside the 30 yard circle
Middle overs: Overs: 7- 16 – During these overs the batting side tries to consolidate their innings
Death overs: Overs: 16 -20 – During these 5 overs the batting side tries to accelerate the scoring rate, while the bowling side will try to restrict the batsmen against going for big hits
This is shown below
This latest update of GooglyPlusPlus2021 includes the following functions
a) Match tab
teamRunsAcrossOvers
teamSRAcrossOvers
teamWicketsAcrossOvers
teamERAcrossOvers
matchWormWickets
b) Head-to-head tab
teamRunsAcrossOversOppnAllMatches
teamSRAcrossOversOppnAllMatches
teamWicketsAcrossOversOppnAllMatches
teamERAcrossOversOppnAllMatches
topRunsBatsmenAcrossOversOppnAllMatches
topSRBatsmenAcrossOversOppnAllMatches
topWicketsBowlersAcrossOversOppnAllMatches
topERBowlerAcrossOverOppnAllMatches
c) Overall performance tab
teamRunsAcrossOversAllOppnAllMatches
teamSRAcrossOversAllOppnAllMatches
teamWicketsAcrossOversAllOppnAllMatches
teamERAcrossOversAllOppnAllMatches
topRunsBatsmenAcrossOversAllOppnAllMatches
topSRBatsmenAcrossOversAllOppnAllMatches
topWicketsBowlersAcrossOversAllOppnAllMatches
topERBowlerAcrossOverAllOppnAllMatches
Hence a total of 8 + 8 + 5 = 21 functions have been added. These functions can be utilized across all the 9 T20 formats that are supported in GooglyPlusPlus2021 namely
You can clone/fork the code for the Shiny app from Github – gpp2021-9
Included below is a random selection of options from the 189 possibilities mentioned above. Feel free to try out for yourself
A) IPL – CSK vs KKR 2018-04-10
a) Team Runs in power play, middle and death overs
b) Team Strike rate in power play, middle and death overs
B) Intl. T20 (men) – India vs Afghanistan (2021-11-03)
a) Team wickets in power play, middle and death overs
b) Team Economy rate in power play, middle and death overs
C) Intl. T20 (women) Head-to-head : India vs Australia since 2018
a) Team Runs in all matches in power play, middle and death overs
D) PSL Head-to-head strike rate since 2019
a) Team vs team Strike rate : Karachi Kings vs Lahore Qalanders since 2019 in power play, middle and death overs
E) Team overall performance in all matches against all opposition
a) BBL : Brisbane Heats : Team Wickets between 2015 – 2018 in power play, middle and death overs
F) Top Runs and Strike rate Batsman of Mumbai Indians vs Royal Challengers Bangalore since 2018
a) Top runs scorers for Mumbai Indians (MI) in power play, middle and death overs
b) Top strike rate for RCB in power play, middle and death overs
F) Intl. T20 (women) India vs England since 2018
a) Top wicket takers for England in power play, middle and death overs since 2018
b) Top wicket takers for India in power play, middle and death overs since 2018
G) Intl. T20 (men) All time best batsmen and bowlers for India
a) Most runs in power play, middle and death overs
b) Highest strike rate in power play, middle and death overs
H) Match worm wicket chart
In addition to the usual Match worm chart, I have also added a Match Wicket worm chart in the latest version
Note: You can zoom to the area where you would like to focus more
The option of looking at the Match worm chart (without wickets) also exists.
Go ahead take GooglyPlusPlus2021 for a test drive and check out how your favourite players perform in power play, middle and death overs. Click GooglyPlusPlus2021
You can fork/download the app code from Github at gpp2021-9
This year 2021, we are witnessing a rare spectacle in the cricketing universe, where IPL playoffs are immediately followed by ICC World Cup T20. Cricket pundits have claimed such a phenomenon occurs once in 127 years! Jokes apart, the World cup T20 is underway and as usual GooglyPlusPlus is ready for the action.
GooglyPlusPlus will provide near-real time analytics, by automatically downloading the latest match data daily, processing and organising the match data into appropriate folders so that my R package yorkr can slice and dice the data to provide the pavilion-view analytics.
The charts capture all the breathless, heart-pounding, and nail-biting action in great details in the many tables and plots. Every table and chart tell a story. You just have to ‘read between the lines!’
GooglyPlusPlus2021 will update itself automatically every day, so the data will be current and you can analyse all matches upto the previous day, along with the historical performances of the teams. So make sure you check it everyday.
The are 5 tabs for each of the formats supported by GooglyPlusPlus2021 which now supports IPL, Intl. T20(men), Intl. T20(women), BBL, NTB, PSL, CPL, SSM, WBB. Besides, it also supports ODI (men) and ODI (women)
Each of the formats have 5 tabs – Batsman, Bowler, Match, Head-to-head and Overall Performace.
All T20 formats also include a ranking functionality for the batsmen and bowlers
You can now perform drill-down analytics for batsmen, bowlers, head-to-head and overall performance based on date-range selector functionality. The ranking tabs also include date range selector granular analysis. For more details see GooglyPlusPlus2021 enhanced with drill-down batsman, bowler analytics
























































































 ,
, 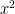 and
and  for the 3 bowlers which identify the characteristics of these bowlers (“fast”, “lateral drift through the air”, “movement off the pitch”). Let each batsman be identified by parameter vectors
for the 3 bowlers which identify the characteristics of these bowlers (“fast”, “lateral drift through the air”, “movement off the pitch”). Let each batsman be identified by parameter vectors  ,
,  and so on
and so on
 and the feature vector xx we can formulate this as an optimization problem which tries to minimize the error for
and the feature vector xx we can formulate this as an optimization problem which tries to minimize the error for  This can work very well as the algorithm can determine features which cannot be captured. So for e.g. some particular bowler may have very impressive figures. This could be due to some aspect of the bowling which cannot be captured by the data for e.g. let’s say the bowler uses the ‘scrambled seam’ when he is most effective, with a slightly different arc to the flight. Though the algorithm cannot identify the feature as we know it, but the ML algorithm should pick up intricacies which cannot be captured in data.
This can work very well as the algorithm can determine features which cannot be captured. So for e.g. some particular bowler may have very impressive figures. This could be due to some aspect of the bowling which cannot be captured by the data for e.g. let’s say the bowler uses the ‘scrambled seam’ when he is most effective, with a slightly different arc to the flight. Though the algorithm cannot identify the feature as we know it, but the ML algorithm should pick up intricacies which cannot be captured in data.
 ,
,  }= 1/2
}= 1/2
 and the set of features be
and the set of features be 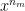 to small random values
to small random values , i= 1,2,..,
, i= 1,2,.., 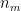
 :=
:=  (
( 
 )
)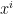 –
– 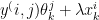
 :=
:=