“The Cloud brings it with it the promise of utility-style computing and the ability to pay according to usage.
Cloud Computing provides elasticity or the ability to grow and shrink based on traffic patterns.
Cloud Computing does away with CAPEX and the need to buy infrastructure upfront and replaces it with OPEX model and so on”.
All this old news and has been repeated many times. But what exactly constitutes cloud computing? What brings about the above features? What are its building blocks of the cloud that enable one to realize the above?
This post tries to look deeper into the innards of the Cloud to determine what the cloud really is.
Before we get to this I would like to dwell on an analogy to understand the Cloud better.
Let us assume, Mr. A owns a large building of about 15,000 sq feet and about 100 feet tall. Let us assume that Mr. A wants to rent this building.
Now, assume that the door of this building opens to single, large room on the inside!
Mr. X comes to rent this building. If this was the case then poor Mr. X would have to pay through his nose, presumably, for the entire building even though his requirement would have been for a small room of about 600 x 600 feet. Imagine the waste of space. Moreover this would also have resulted in an enormous waste of electricity. Imagine the lighting needed. Also an inordinate amount of water would have to be utilized if this single, large room needed to be cleaned. The cost for all of this would have to be borne by Mr. X.
This is clearly not a pleasant state of affairs for either Mr. X or for the owner Mr. A of the building.
The solution to this is easy. What Mr. A needs to do, is to partition the building into self-contained rooms (600 x 600 sq feet) with all the amenities. Each self-contained unit would need to have its own electricity and water meter.
Now Mr. A can rent rooms to different tenants on their need basis. This is a win-win situation both for Mr, A and Mr. X. The tenants only need to pay for the rooms they occupy and the electricity and water they consume.
This is exactly the principle behind cloud computing and is known as ‘virtualization’
There are 3 computing components that one must consider. CPU, Network and Storage. The below picture shows the virtualization of CPU,RAM, NIC (network card), Disk (storage)
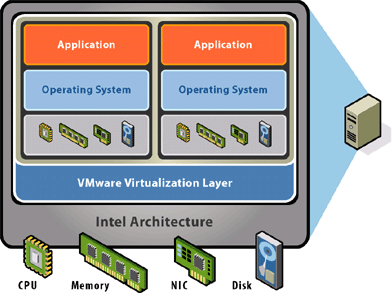
The Cloud is essentially made up of anywhere between 100 servers to 100,000 servers. The servers are akin to the large building. Running a single OS and application(s) on the entire server is a waste of computing, storage and network resources.
Virtualization abstracts the hardware, storage and network through the use of software known as the ‘hypervisor’. On top of the hypervisor several ‘guest OSes’ can run. Applications can then run on these guest OSes.
Hence over the CPU (single, dual or multi-core) of the server, multiple guest OS’es can run each with its own set of applications
This is similar to partitioning the large CPU resource of the server into smaller units.
There are 3 main Virtualization technologies namely VMware, Citrix and MS Hyper-V
Here is a diagram showing the 3 main the virtualization technologies

To be continued …
Find me on Google+




")

