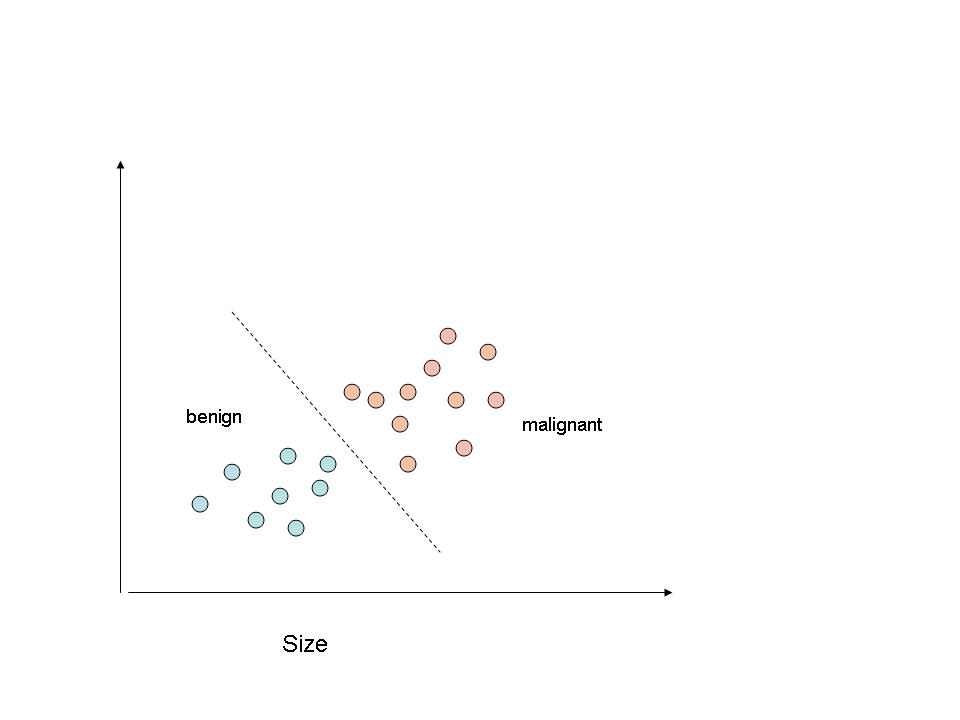
Logistic regression is another class of Machine Learning algorithms which comes under supervised learning. In this regression technique we need to classify data. Take a look at my earlier post Simplifying Machine Learning algorithms – Part 1 I had discussed linear regression. For e.g if we had data on tumor sizes versus the fact that the tumor was benign or malignant, the question is whether given a tumor size we can predict whether this tumor would be benign or cancerous. So we need to have the ability to classify this data.
This is shown below

It is obvious that a line with a certain slope could easily separate the two.
As another example we could have an algorithm that is able to automatically classify mail as either spam or not spam based on the subject line. So for e.g if the subject line had words like medicine, prize, lottery etc we could with a fair degree of probability classify this as spam.
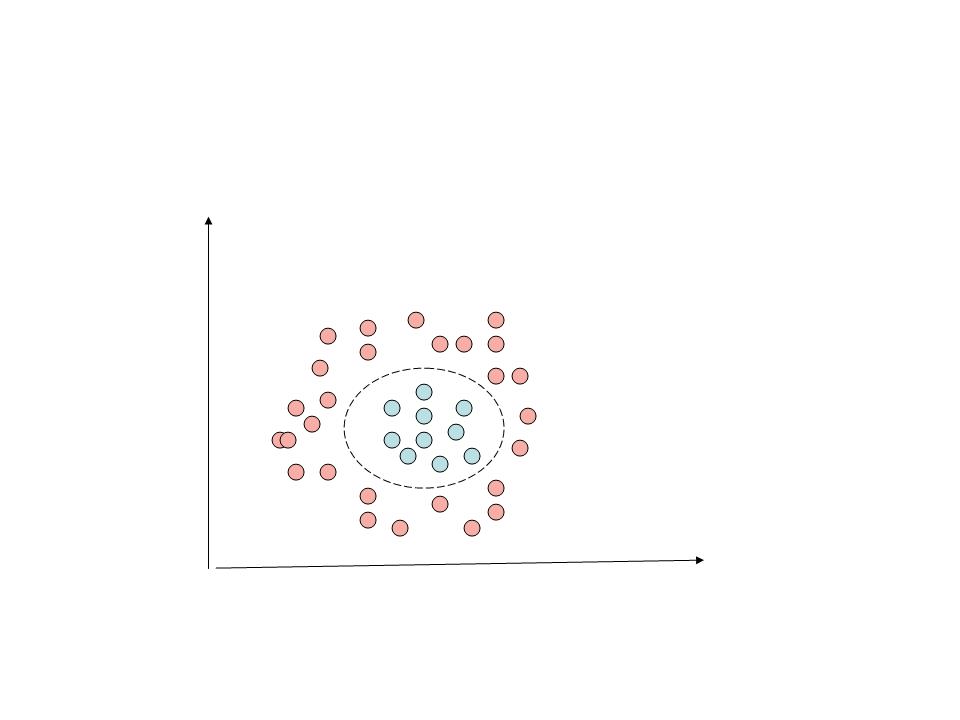
However some classification problems could be far more complex. We may need to classify another problem as shown below.

From the above it can be seen that hypothesis function is second order equation which is either a circle or an ellipse.
In the case of logistic regression the hypothesis function should be able to switch between 2 values 0 or 1 almost like a transistor either being in cutoff or in saturation state.
In the case of logistic regression 0 <= hƟ <= 1
The hypothesis function uses function of the following form
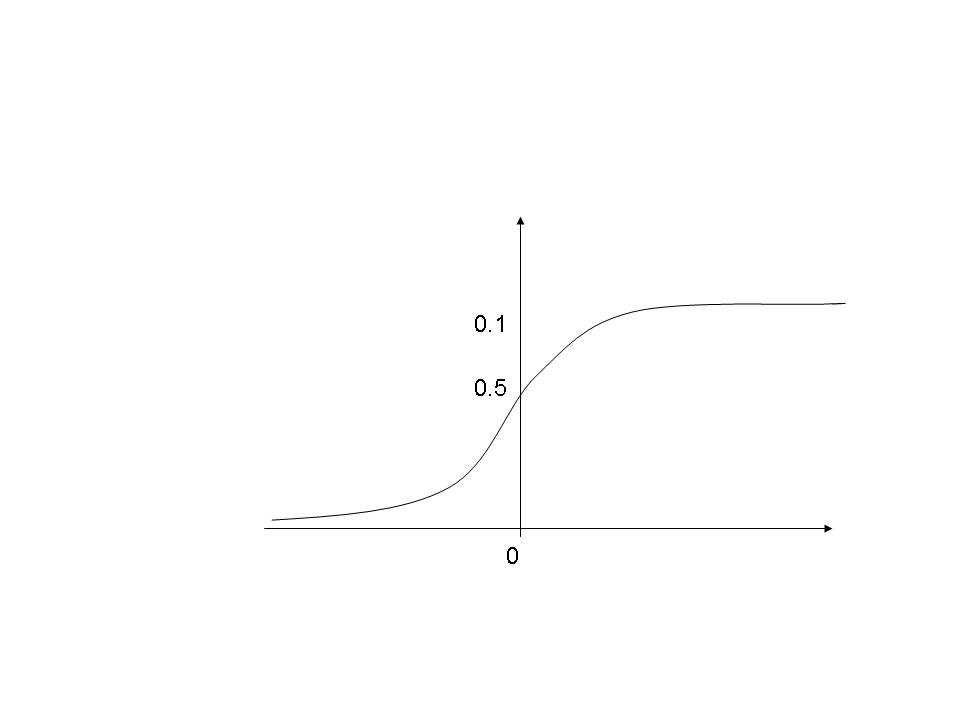
g(z) = 1/(1 + e‑z)
and hƟ (x) = g(ƟTX)

The function g(z) shown above has the characteristic required for logistic regression as it has the following shape
The function rapidly asymptotes at 1 when hƟ (x) >= 0.5 and hƟ (x) asymptotes to 0 when hƟ (x) < 0.5
As in linear regression we can have hypothesis function be of an appropriate order. So for e.g. in the ellipse figure above one could choose a hypothesis function as follows
hƟ (x) = Ɵ0 + Ɵ1x12 + Ɵ2x22 + Ɵ3x1 + Ɵ4x2
or
hƟ (x) = 1/(1 + e –(Ɵ0 + Ɵ1×12 + Ɵ2×22 + Ɵ3×1 + Ɵ4×2))
We could choose the general form of a circle which is
f(x) = ax2 + by2 +2gx + 2hy + d
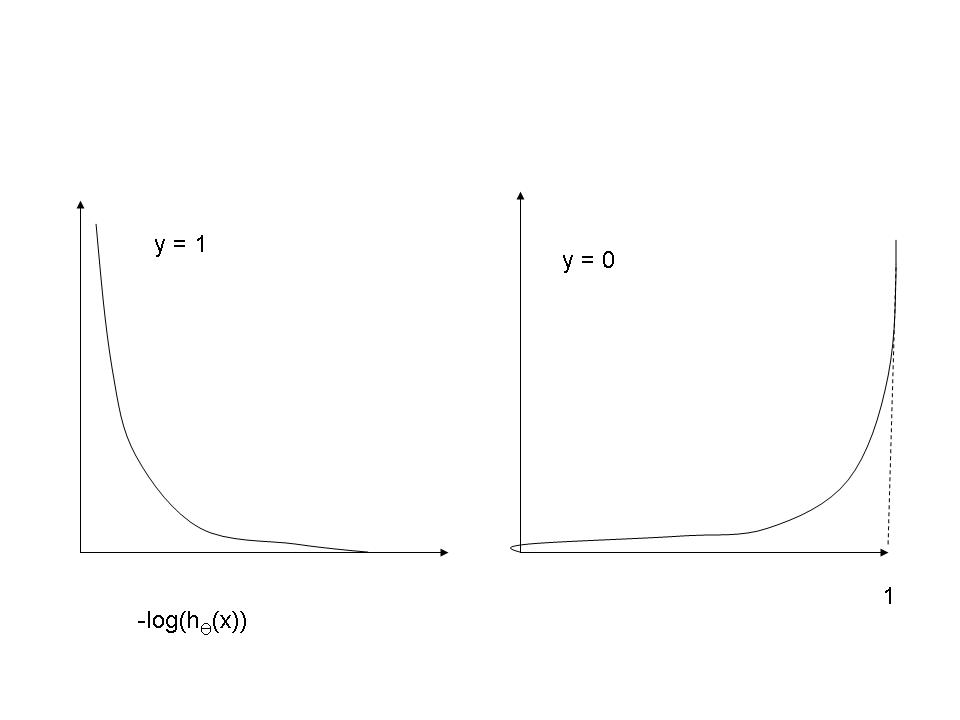
The cost function for logistic regression is given below
Cost(hƟ (x),y) = { -log(hƟ (x)) if y = 1
-log(1 – hƟ (x))) if y = 0
In the case of regression there was a single cost function which could determine the error of the data against the predicted value.
The cost in the event of logistic regression is given as above as a set of 2 equations one for the case where the data is 1 and another for the case where the data is 0.
The reason for this is as follows. If we consider y =1 as a positive value, then when our hypothesis correctly predicts 1 then we have a ‘true positive’ however if we predict 0 when it should be 1 then we have a false negative. Similarly when the data is 0 and we predict a 1 then this is the case of a false positive and if we correctly predict 0 when it is 0 it is true negative.
Here is the reason as how the cost function
Cost(hƟ (x),y) = { -log(hƟ (x)) if y = 1
-log(1 – hƟ (x))) if y = 0
Was arrived at. By definition the cost function gives the error between the predicted value and the data value.
The logic for determining the appropriate function is as follows
For y = 1
y=1 & hypothesis = 1 then cost = 0
y= 1 & hypothesis = 0 then cost = Infinity
Similarly for y = 0
y = 0 & hypotheses = 0 then cost = 0
y = 0 & hypothesis = 1 then cost = Infinity
and the the functions above serve exactly this purpose as can be seen

Hence the cost can be written as
J(Ɵ) = Cost(hƟ (x),y) = -y * log(hƟ (x)) – (1-y) * (log(1 – hƟ (x))
This is the same as the equation above
The same gradient descent algorithm can now be used to minimize the cost function
So we can iterate througj
Ɵj = Ɵj – α δ/δ Ɵj J(Ɵ0, Ɵ1,… Ɵn)
This works out to a function that is similar to linear regression
Ɵj = Ɵj – α 1/m { Σ hƟ (xi) – yi} xj i
This will enable the machine to fairly accurately determine the parameters Ɵj for the features x and provide the hypothesis function.
This is based on the Coursera course on Machine Learning by Professor Andrew Ng. Highly recommended!!!
Find me on Google+
 The future of technology will bring big changes, including advances in AI, brain-to-brain interfaces, and the ability to halt death
The future of technology will bring big changes, including advances in AI, brain-to-brain interfaces, and the ability to halt death