
In physics there are 4 types of forces – gravitational forces among celestial bodies, electro-magnetic forces and strong and weak forces at the sub-atomic level. The equations that seem to work among large bodies don’t seem to apply at the sub-atomic level though there have been several attempts at grand unification theories
Similarly in computing we have: – computing at personal level, enterprise level, data-center level and a web scale level. The problems and paradigms at each level are very different and unique. The sequential processing, relational database accesses or network speeds at the local area network level are very different to the parallel processing requirements, NoSQL based storage accesses and WAN latencies.
Here is the first of my posts on paradigms at the Web Scale.
The internet now contains in excess of 1 billion hosts. This is based on a report in the World Fact Book published in 2012.
In these 1 billion and odd hosts there are at least ~1.5 billion pages that have been indexed. There must be several hundred million that are not indexed by the major search engines.
Search engines like Google, Bing or Yahoo have to work on several hundred million pages. Similarly social web sites like Facebook, Twitter or LinkedIn have to deal with several hundred million users who constantly perform status updates, upload images, tweet etc. To handle large quantities of data efficiently and quickly there is a need for web scale algorithms.
One such algorithm is the map-reduce, that had its origins in Google. The map reduce essentially consists of a set of mappers which take as input a key-value pair and outputs 0 or more key value pairs. The reducer takes all tuples with the same key and combines them based on some function and emits a key value pair
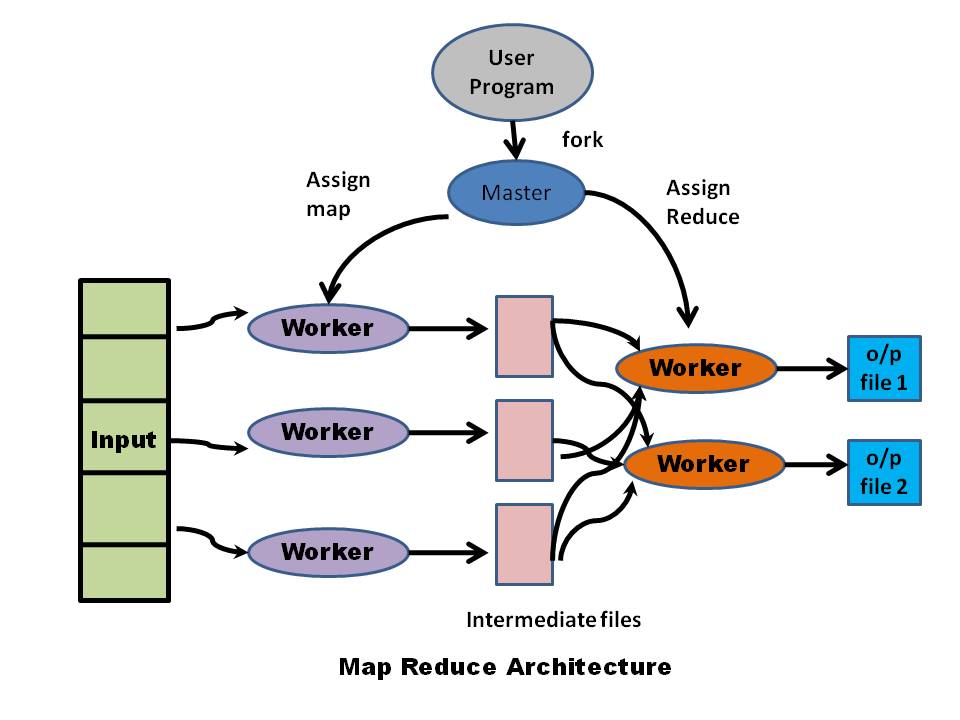
Map-reduce, and its open source avatar, Hadoop, are now used routinely to solve several large scale problems. To be honest, I was and still am, puzzled whether the 2 simple tasks types of mapping & reducing can be used for a large variety of problems. However, it appears so.
I would have assumed that there would have been other flavors, maybe an ‘identify-update’, ‘determine-solve’ or some such equivalent, unless a large set of problems can be expressed as some combination of the map reduce paradigm.
Anyway here a few examples for which the map reduce algorithm is useful.
Word Counting: The standard example for map-reduce is the word counting program. In this the map reduce algorithm generates a list of words with their corresponding word count from a set of input files. The Map task reads each document and breaks it into a sequence of words (w1, w2, w3 …). It then emits a key value pair as follows
(w1,1),(w2,1),(w3,1),(w1,1) and so on. If a word is repeated in the document it occurs multiple times in the output. Now the entire key, value pairs are grouped by keys and sent to one of the reducer tasks. Each reducer will then sum all the values thus giving the total for each word.

Matrix multiplication: Big Data is a typical challenge in the web where there is a need to determine patterns and trends in mountains of data. Machine learning algorithms are utilized to determine structure in data that has 3 characteristics of volume, variety and velocity. Machine learning algorithms typically depend on matrix operations. Map-reduce is ideally suited for this and one of the original purposes of Google for map-reduce was with matrix multiplication.
Let us assume that we have a n x n matrix M whose element in row i and column j is mij
Also let us assume that there is a vector ‘v’ whose jth element is vj . Then the matrix vector product can be is the vector x of the length n whose ith element is given as
xi = ∑ mijvj
Map function: The map function applies to each single element of the matrix M. For each element mij the map task outputs a key-value pair as follows (i, mijvj). Hence we will have a key-value pairs for all ‘i’ from 1 to n.
Reduce function: The reduce function takes all pairs with the same key ‘i’ and sum it up.
Hence each reducer will generate
xi = ∑ mijvj
(Reference: Mining of Massive Datasets– Anand Rajaraman, Jure Leskovec, Jeffrey D Ullman)
This link gives a good write-up on a matrix x matrix multiplication,
Map-reduce for Relational Operations: Map-reduce can be used to perform a number of operations on large scale data that are used in database operations. Multiple database operations can be performed on large scale data like selection, projection, union, intersection, difference, natural join, grouping etc.
Here is a an example taken from ‘Web Intelligence & Big Data’ course from Coursera any Gautam Shroff.
Let us assume that there are 2 tables ‘Sales by address’ and “City by address’ and the need is to find the total ‘Sales by City’. The SQL query for this
SELECT SUM(Sale),City FROM Sales, City WHERE Sales.Addr_id = Cities.Addr_id GROUP BY City
This can be done by 2 map-reduce tasks.
The first map-reduce task GROUPs BY Sales as follows
Map1: The first map task will emit (Address, rest of record (SALE/City))
Reduce1: The first reduce task will SUM (Sales) by Address for every City. Clearly this will have multiple occurrences of City.
At this point we will have the sum of the sales for every city. However each city can occur multiple times. Now we have to GROUP BY City
Map2: Now the mapper emits the (City, rest of record (SALES)
Reduce2: The 2nd reduce now SUMS all the sales for each city.
Clearly the map-reduce algorithm does solve some major areas. It is extremely useful when there is a need to perform the same operation on multiple documents. It would definitely be useful in building the inverted index or in Page rank. Also, map-reduce is very powerful in handling matrix operations. Large class of problems like machine learning, computer vision all use matrices extensively and map-reduce is extremely critical when it has done in large volumes of data. Besides, the ability of map-reduce to perform a large set of database operations is something that can be used in many situations in the web.
However it is no silver bullet for all types of problems.
