
This presentation includes the 3 part and touches upon Apache Edgent, NLP and Big Data with Spark.
Category: map-reduce

Thinking Web Scale (TWS-3): Map-Reduce – Bring compute to data
In the last decade and a half, there has arisen a class of problem that are becoming very critical in the computing domain. These problems deal with computing in a highly distributed environments. A key characteristic of this domain is the need to grow elastically with increasing workloads while tolerating failures without missing a beat. In short I would like to refer to this as ‘Web Scale Computing’ where the number of servers exceeds several 100’s and the data size is of the order of few hundred terabytes to several Exabytes.
There are several features that are unique to large scale distributed systems
- The servers used are not specialized machines but regular commodity, off-the-shelf servers
- Failures are not the exception but the norm. The design must be resilient to failures
- There is no global clock. Each individual server has its own internal clock with its own skew and drift rates. Algorithms exist that can create a notion of a global clock
- Operations happen at these machines concurrently. The order of the operations, things like causality and concurrency, can be evaluated through special algorithms like Lamport or Vector clocks
- The distributed system must be able to handle failures where servers crash, disk fails or there is a network problem. For this reason data is replicated across servers, so that if one server fails the data can still be obtained from copies residing on other servers.
- Since data is replicated there are associated issues of consistency. Algorithms exist that ensure that the replicated data is either ‘strongly’ consistent or ‘eventually’ consistent. Trade-offs are often considered when choosing one of the consistency mechanisms
- Leaders are elected democratically. Then there are dictators who get elected through ‘bully’ing.
In some ways distributed systems behave like a murmuration of starlings (or a school of fish), where a leader is elected on the fly (pun unintended) and the starlings or fishes change direction based on a few (typically 6) closest neighbors.
This series of posts, Thinking Web Scale (TWS) , will be about Web Scale problems and the algorithms designed to address this. I would like to keep these posts more essay-like and less pedantic.
In the early days, computing used to be done in a single monolithic machines with its own CPU, RAM and a disk., This situation was fine for a long time, as technology promptly kept its date with Moore’s Law which stated that the “ computing power and memory capacity’ will double every 18 months. However this situation changed drastically as the data generated from machines grew exponentially – whether it was the call detail records, records from retail stores, click streams, tweets, and status updates of social networks of today
These massive amounts of data cannot be handled by a single machine. We need to ‘divide’ and ‘conquer this data for processing. Hence there is a need for a hundreds of servers each handling a slice of the data.
The first post is about the fairly recent computing paradigm “Map-Reduce”. Map- Reduce is a product of Google Research and was developed to solve their need to calculate create an Inverted Index of Web pages, to compute the Page Rank etc. The algorithm was initially described in a white paper published by Google on the Map-Reduce algorithm. The Page Rank algorithm now powers Google’s search which now almost indispensable in our daily lives.
The Map-Reduce assumes that these servers are not perfect, failure-proof machines. Rather Map-Reduce folds into its design the assumption that the servers are regular, commodity servers performing a part of the task. The hundreds of terabytes of data is split into 16MB to 64MB chunks and distributed into a file system known as ‘Distributed File System (DFS)’. There are several implementations of the Distributed File System. Each chunk is replicated across servers. One of the servers is designated as the “Master’. This “Master’ allocates tasks to ‘worker’ nodes. A Master Node also keeps track of the location of the chunks and their replicas.
When the Map or Reduce has to process data, the process is started on the server in which the chunk of data resides.
The data is not transferred to the application from another server. The Compute is brought to the data and not the other way around. In other words the process is started on the server where the data, intermediate results reside
The reason for this is that it is more expensive to transmit data. Besides the latencies associated with data transfer can become significant with increasing distances
Map-Reduce had its genesis from a Lisp Construct of the same name
Where one could apply a common operation over a list of elements and then reduce the resulting list of elements with a reduce operation
The Map-Reduce was originally created by Google solve Page Rank problem Now Map-Reduce is used across a wide variety of problems.
The main components of Map-Reduce are the following
- Mapper: Convert all d ∈ D to (key (d), value (d))
- Shuffle: Moves all (k, v) and (k’, v’) with k = k’ to same machine.
- Reducer: Transforms {(k, v1), (k, v2) . . .} to an output D’ k = f(v1, v2, . . .). …
- Combiner: If one machine has multiple (k, v1), (k, v2) with same k then it can perform part of Reduce before Shuffle
A schematic of the Map-Reduce is included below\

Map Reduce is usually a perfect fit for problems that have an inherent property of parallelism. To these class of problems the map-reduce paradigm can be applied in simultaneously to a large sets of data. The “Hello World” equivalent of Map-Reduce is the Word count problem. Here we simultaneously count the occurrences of words in millions of documents
The map operation scans the documents in parallel and outputs a key-value pair. The key is the word and the value is the number of occurrences of the word. E.g. In this case ‘map’ will scan each word and emit the word and the value 1 for the key-value pair
So, if the document contained
“All men are equal. Some men are more equal than others”
Map would output
(all,1), (men,1), (are,1), (equal,1), (some,1), (men,1), (are,1), (equal,1), (than,1), (others,1)
The Reduce phase will take the above output and give sum all key value pairs with the same key
(all,1), (men,2), (are,2),(equal,2), (than,1), (others,1)
So we get to count all the words in the document
In the Map-Reduce the Master node assigns tasks to Worker nodes which process the data on the individual chunks

Map-Reduce also makes short work of dealing with large matrices and can crunch matrix operations like matrix addition, subtraction, multiplication etc.
Matrix-Vector multiplication
As an example if we consider a Matrix-Vector multiplication (taken from the book Mining Massive Data Sets by Jure Leskovec, Anand Rajaraman et al
For a n x n matrix if we have M with the value mij in the ith row and jth column. If we need to multiply this with a vector vj, then the matrix-vector product of M x vj is given by xi

Here the product of mij x vj can be performed by the map function and the summation can be performed by a reduce operation. The obvious question is, what if the vector vj or the matrix mij did not fit into memory. In such a situation the vector and matrix are divided into equal sized slices and performed acorss machines. The application would have to work on the data to consolidate the partial results.
Fortunately, several problems in Machine Learning, Computer Vision, Regression and Analytics which require large matrix operations. Map-Reduce can be used very effectively in matrix manipulation operations. Computation of Page Rank itself involves such matrix operations which was one of the triggers for the Map-Reduce paradigm.
Handling failures: As mentioned earlier the Map-Reduce implementation must be resilient to failures where failures are the norm and not the exception. To handle this the ‘master’ node periodically checks the health of the ‘worker’ nodes by pinging them. If the ping response does not arrive, the master marks the worker as ‘failed’ and restarts the task allocated to worker to generate the output on a server that is accessible.
Stragglers: Executing a job in parallel brings forth the famous saying ‘A chain is as strong as the weakest link’. So if there is one node which is straggler and is delayed in computation due to disk errors, the Master Node starts a backup worker and monitors the progress. When either the straggler or the backup complete, the master kills the other process.
Mining Social Networks, Sentiment Analysis of Twitterverse also utilize Map-Reduce.
However, Map-Reduce is not a panacea for all of the industry’s computing problems (see To Hadoop, or not to Hadoop)
But the Map-Reduce is a very critical paradigm in the distributed computing domain as it is able to handle mountains of data, can handle multiple simultaneous failures, and is blazingly fast.
Also see
1. A crime map of India in R: Crimes against women
2. What’s up Watson? Using IBM Watson’s QAAPI with Bluemix, NodeExpress – Part 1
3. Bend it like Bluemix, MongoDB with autoscaling – Part 2
4. Informed choices through Machine Learning : Analyzing Kohli, Tendulkar and Dravid
To see all posts click ‘Index of Posts”
Share:

Reducing to the Map-Reduce paradigm- Thinking Web Scale – Part 1
In physics there are 4 types of forces – gravitational forces among celestial bodies, electro-magnetic forces and strong and weak forces at the sub-atomic level. The equations that seem to work among large bodies don’t seem to apply at the sub-atomic level though there have been several attempts at grand unification theories
Similarly in computing we have: – computing at personal level, enterprise level, data-center level and a web scale level. The problems and paradigms at each level are very different and unique. The sequential processing, relational database accesses or network speeds at the local area network level are very different to the parallel processing requirements, NoSQL based storage accesses and WAN latencies.
Here is the first of my posts on paradigms at the Web Scale.
The internet now contains in excess of 1 billion hosts. This is based on a report in the World Fact Book published in 2012.
In these 1 billion and odd hosts there are at least ~1.5 billion pages that have been indexed. There must be several hundred million that are not indexed by the major search engines.
Search engines like Google, Bing or Yahoo have to work on several hundred million pages. Similarly social web sites like Facebook, Twitter or LinkedIn have to deal with several hundred million users who constantly perform status updates, upload images, tweet etc. To handle large quantities of data efficiently and quickly there is a need for web scale algorithms.
One such algorithm is the map-reduce, that had its origins in Google. The map reduce essentially consists of a set of mappers which take as input a key-value pair and outputs 0 or more key value pairs. The reducer takes all tuples with the same key and combines them based on some function and emits a key value pair
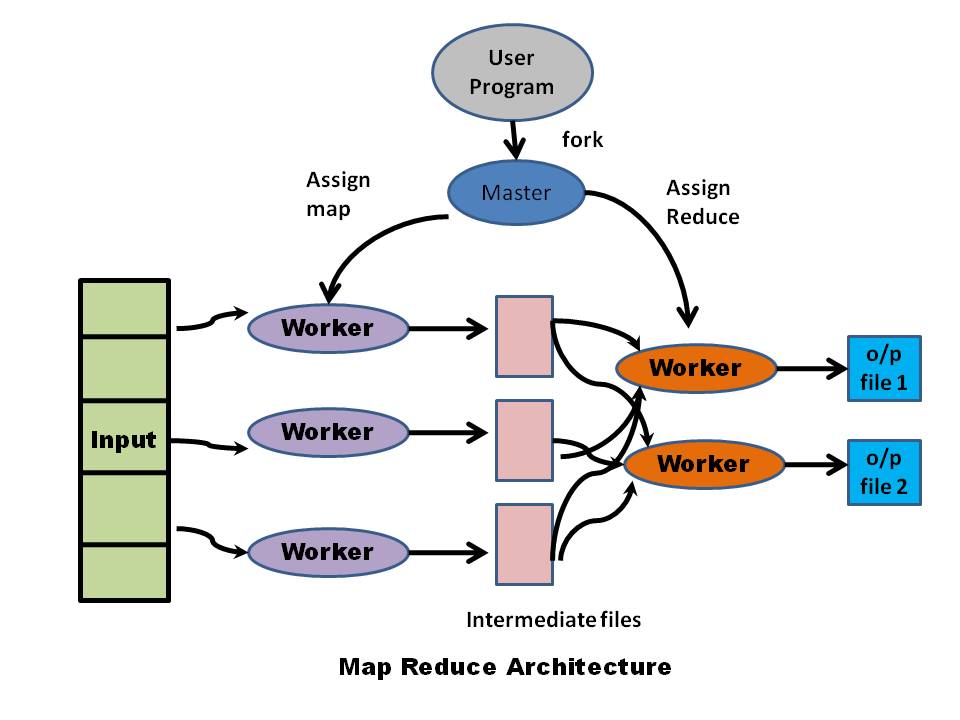
Map-reduce, and its open source avatar, Hadoop, are now used routinely to solve several large scale problems. To be honest, I was and still am, puzzled whether the 2 simple tasks types of mapping & reducing can be used for a large variety of problems. However, it appears so.
I would have assumed that there would have been other flavors, maybe an ‘identify-update’, ‘determine-solve’ or some such equivalent, unless a large set of problems can be expressed as some combination of the map reduce paradigm.
Anyway here a few examples for which the map reduce algorithm is useful.
Word Counting: The standard example for map-reduce is the word counting program. In this the map reduce algorithm generates a list of words with their corresponding word count from a set of input files. The Map task reads each document and breaks it into a sequence of words (w1, w2, w3 …). It then emits a key value pair as follows
(w1,1),(w2,1),(w3,1),(w1,1) and so on. If a word is repeated in the document it occurs multiple times in the output. Now the entire key, value pairs are grouped by keys and sent to one of the reducer tasks. Each reducer will then sum all the values thus giving the total for each word.

Matrix multiplication: Big Data is a typical challenge in the web where there is a need to determine patterns and trends in mountains of data. Machine learning algorithms are utilized to determine structure in data that has 3 characteristics of volume, variety and velocity. Machine learning algorithms typically depend on matrix operations. Map-reduce is ideally suited for this and one of the original purposes of Google for map-reduce was with matrix multiplication.
Let us assume that we have a n x n matrix M whose element in row i and column j is mij
Also let us assume that there is a vector ‘v’ whose jth element is vj . Then the matrix vector product can be is the vector x of the length n whose ith element is given as
xi = ∑ mijvj
Map function: The map function applies to each single element of the matrix M. For each element mij the map task outputs a key-value pair as follows (i, mijvj). Hence we will have a key-value pairs for all ‘i’ from 1 to n.
Reduce function: The reduce function takes all pairs with the same key ‘i’ and sum it up.
Hence each reducer will generate
xi = ∑ mijvj
(Reference: Mining of Massive Datasets– Anand Rajaraman, Jure Leskovec, Jeffrey D Ullman)
This link gives a good write-up on a matrix x matrix multiplication,
Map-reduce for Relational Operations: Map-reduce can be used to perform a number of operations on large scale data that are used in database operations. Multiple database operations can be performed on large scale data like selection, projection, union, intersection, difference, natural join, grouping etc.
Here is a an example taken from ‘Web Intelligence & Big Data’ course from Coursera any Gautam Shroff.
Let us assume that there are 2 tables ‘Sales by address’ and “City by address’ and the need is to find the total ‘Sales by City’. The SQL query for this
SELECT SUM(Sale),City FROM Sales, City WHERE Sales.Addr_id = Cities.Addr_id GROUP BY City
This can be done by 2 map-reduce tasks.
The first map-reduce task GROUPs BY Sales as follows
Map1: The first map task will emit (Address, rest of record (SALE/City))
Reduce1: The first reduce task will SUM (Sales) by Address for every City. Clearly this will have multiple occurrences of City.
At this point we will have the sum of the sales for every city. However each city can occur multiple times. Now we have to GROUP BY City
Map2: Now the mapper emits the (City, rest of record (SALES)
Reduce2: The 2nd reduce now SUMS all the sales for each city.
Clearly the map-reduce algorithm does solve some major areas. It is extremely useful when there is a need to perform the same operation on multiple documents. It would definitely be useful in building the inverted index or in Page rank. Also, map-reduce is very powerful in handling matrix operations. Large class of problems like machine learning, computer vision all use matrices extensively and map-reduce is extremely critical when it has done in large volumes of data. Besides, the ability of map-reduce to perform a large set of database operations is something that can be used in many situations in the web.
However it is no silver bullet for all types of problems.
Share:

Test driving Apache Hadoop: Standalone & pseudo-distributed mode
The Hadoop paradigm originated from Google and is used in crunching large data sets. It is ideally suited for applications like Big Data, creating an inverted index used by search engines and other problems which require terabytes of data to processed in parallel. One key aspect of Hadoop is that it is made up of commodity servers. Hence server, disk crashes or network issues are assumed to be norm rather than an exception.
The Hadoop paradigm is made of the Map-Reduce & the HDFS parts. The Map-Reduce has 2 major components to it. The Map part takes as input key- value pairs and emits a transformed key-value pair. For e.g Map could count the number of occurrences of words or created an inverted index of a word and its location in a document. The Reduce part takes as input the emitted key-value pairs of the Map output and performs another operation on the inputs from the Map part for.e.g summing up the counts of words. A great tutorial on Map-Reduce can be found at http://developer.yahoo.com/hadoop/tutorial/module4.html
The HDFS (Hadoop Distributed File System) is the special storage that is used in tandem with the Map-Reduce algorithm. The HDFS distributes data among Datanodes. A Namenode maintains the meta data of where individual pieces of data are stored.
To get started with Apache Hadoop download a stable release of Hadoop from (e.g. hadoop-1.0.4.tar.gz)
http://hadoop.apache.org/common/releases.html#Download
a) Install Hadoop on your system preferably in /usr/local/
tar xzf ./Downloads/hadoop-1.0.4.tar.gz
sudo mv hadoop-1.0.4 hadoop (rename hadoop-1.0.4 to hadoop for convenience) sudo chown -R hduser:hadoop hadoop Apache Hadoop requires Java to be installed. Download and install Java on your machine from
http://www.oracle.com/technetwork/java/javase/downloads/jdk-7u4-downloads-1591156.html
b) After you have installed java set $JAVA_HOME in
usr/local/hadoop/conf/hadoop-env.sh
export JAVA_HOME=/usr/bin/java (uncomment and set the correct path)
c) Create a user hduser in group hadoop
For this click Applications->Other->User & Groups
Choose Add User – hduser & Add Group – hadoop
Choose properties and add hduser to the hadoop group.
Standalone Operation
Under root do
/usr/sbin/sshd
then
$ssh localhost
If you cannot do a ssh to localhost with passphrase then do the following
$ ssh-keygen -t rsa -P “”
You will get the following
Generating public/private rsa key pair. Enter file in which to save the key (/home/hduser/.ssh/id_rsa): Created directory '/home/hduser/.ssh'. Your identification has been saved in /home/hduser/.ssh/id_rsa.
…
$ cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
Now re-run
$ssh localhost – This time it should go fine
Create a directory input and copy *.xml files from conf/
$mkdir input
$cp /usr/local/hadoop/share/hadoop/templates/conf/*.xml input
Then execute the following. This searches for the string “dfs*” in all the XML files under the input directory
$/usr/local/hadoop/bin/hadoop jar /usr/share/hadoop/hadoop-examples-1.0.3.jar grep input output ‘dfs[a-z.]+’
You should see
[root@localhost hadoop]# /usr/local/hadoop/bin/hadoop jar /usr/share/hadoop/hadoop-examples-1.0.3.jar grep input output ‘dfs[a-z.]+’
12/06/10 13:00:51 INFO util.NativeCodeLoader: Loaded the native-hadoop library
..
…
12/06/10 13:01:45 INFO mapred.JobClient: Reduce output records=38
12/06/10 13:01:45 INFO mapred.JobClient: Virtual memory (bytes) snapshot=0
12/06/10 13:01:45 INFO mapred.JobClient: Map output records=38
Where it indicates that there are 38 such record strings with dfs* in it.
If you get an error
java.lang.OutOfMemoryError: Java heap space
then increase the heap size from 128 to 1024 as below
…
<property>
<name>mapred.child.java.opts</name>
<value>-server -Xmx1024m -Djava.net.preferIPv4Stack=true</value>
</property>
….
Pseudo distributed mode
In the pseudo distributed mode separate Java processes are started for the Job Tracker which schedules tasks, the Task tracker which executes tasks and the Namenode which contains the data
A good post on Hadoop standalone mode is given in Michael Nolls post – Running Hadoop on Ubuntu Linux (single node cluster)
a) Execute the following commands
. ./.bashrc
$mkdir -p /home/hduser/hadoop/tmp
$chown hduser:hadoop /home/hduser/hadoop/tmp
$chmod 750 /home/hduser/hadoop/tmp
b) Do the following
Note:Files core-site.xml, mapred-site,xml & hdfs-site.xml exist under
/usr/local/hadoop/share/hadoop/templates/conf& usr/local/hadoop/conf
It appears that Apache hadoop gives precedence to /usr/local/hadoop/conf. So add the following between <configuration and </configuration>
In file /usr/local//hadoop/conf/core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hduser/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:54310</value>
<description>The name of the default file system. Either the
literal string “local” or a host:port for NDFS.
</description>
<final>true</final>
</property>
In /usr/local//hadoop/conf//mapred-site.xml
<property>
<name>mapred.job.tracker</name>
<value>localhost:54311</value>
<final>true</final
</property>
In /usr/local//hadoop/conf//hdfs-site.xml add
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
Now perform
$sudo /usr/sbin/ssh
$ssh localhost (Note you may have to generate key as above if you get an error)
c) Since the pseudo distributed mode will use the HDFS file system we need to format this.So run the following command
$$HADOOP_HOME/bin/hadoop namenode -format
[root@localhost hduser]# /usr/local/hadoop/bin/hadoop namenode -format
12/06/10 15:48:16 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost.localdomain/127.0.0.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 1.0.3
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.0 -r 1335192; compiled by ‘hortonfo’ on Tue May 8 20:16:59 UTC 2012
************************************************************/
…
12/06/10 15:48:17 INFO common.Storage: Image file of size 110 saved in 0 seconds.
12/06/10 15:48:18 INFO common.Storage: Storage directory /home/hduser/hadoop/tmp/dfs/name has been successfully formatted.
12/06/10 15:48:18 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost.localdomain/127.0.0.1
d) Now start all the Hadoop processes
$/usr/local/hadoop/bin/start-all.sh
starting namenode, logging to /var/log/hadoop/root/hadoop-root-namenode-localhost.localdomain.out
localhost: starting datanode, logging to /var/log/hadoop/root/hadoop-root-datanode-localhost.localdomain.out
localhost: starting secondarynamenode, logging to /var/log/hadoop/root/hadoop-root-secondarynamenode-localhost.localdomain.out
starting jobtracker, logging to /var/log/hadoop/root/hadoop-root-jobtracker-localhost.localdomain.out ocalhost: starting tasktracker, logging to /var/log/hadoop/root/hadoop-root-tasktracker-localhost.localdomain.out
Verify that all processes have started by executing /usr/java/jdk1.7.0_04/bin/jps
[root@localhost hduser]# /usr/java/jdk1.7.0_04/bin/jps
10971 DataNode
10866 NameNode
11077 SecondaryNameNode
11147 JobTracker
11264 TaskTracker
11376 Jps
You will see JobTracker,taskTracker,NameNode,DataNode and SecondaryNameNode
You can also do netstat -plten | grep java
tcp 0 0 0.0.0.0:50090 0.0.0.0:* LISTEN 0 166832 11077/java
tcp 0 0 0.0.0.0:50060 0.0.0.0:* LISTEN 0 167407 11264/java
tcp 0 0 0.0.0.0:50030 0.0.0.0:* LISTEN 0 166747 11147/java
tcp 0 0 0.0.0.0:50070 0.0.0.0:* LISTEN 0 165669 10866/java
tcp 0 0 0.0.0.0:50010 0.0.0.0:* LISTEN 0 166951 10971/java
tcp 0 0 0.0.0.0:50075 0.0.0.0:* LISTEN 0 166955 10971/java
tcp 0 0 127.0.0.1:55839 0.0.0.0:* LISTEN 0 166816 11264/java
tcp 0 0 0.0.0.0:50020 0.0.0.0:* LISTEN 0 165843 10971/java
tcp 0 0 127.0.0.1:54310 0.0.0.0:* LISTEN 0 165535 10866/java
tcp 0 0 127.0.0.1:54311 0.0.0.0:* LISTEN 0 166733 11147/java
e) Now copy files from your local directory /home/hduser/input to the HDFS file system
Now you can check the web interface for JobTracker & NameNode
This is as per mapred-site.xml & hdfs-site.xml in /conf directory. They are at
ñJobTracker – http://localhost:50030/

ñNameNode – http://localhost:50070/

f) Copy files from your local directory to HDFS
$/usr/local/hadoop/bin/hadoop dfs -copyFromLocal /home/hduser/input /user/hduser/input
Ensure that the files have been copies by listing the contents of HDFS
g) Check that files have been copied
$/usr/local/hadoop/bin/hadoop dfs -ls /user/hduser/input
Found 9 items
-rw-r–r– 1 root supergroup 7457 2012-06-10 10:31 /user/hduser/input/capacity-scheduler.xml
-rw-r–r– 1 root supergroup 2447 2012-06-10 10:31 /user/hduser/input/core-site.xml
-rw-r–r– 1 root supergroup 2300 2012-06-10 10:31 /user/hduser/input/core-site_old.xml
-rw-r–r– 1 root supergroup 5044 2012-06-10 10:31 /user/hduser/input/hadoop-policy.xml
-rw-r–r– 1 root supergroup 7595 2012-06-10 10:31 /user/hduser/input/hdfs-site.xml
h) Now execute the grep functionality
[root@localhost hduser]# /usr/local/hadoop/bin/hadoop jar /usr/local/hadoop/hadoop-examples-1.0.4.jar grep /user/hduser/input /user/hduser/output ‘dfs[a-z.]+’
12/06/10 10:34:22 INFO util.NativeCodeLoader: Loaded the native-hadoop library
….
12/06/10 10:34:23 INFO mapred.JobClient: Running job: job_201206101010_0003
12/06/10 10:34:24 INFO mapred.JobClient: map 0% reduce 0%
12/06/10 10:34:48 INFO mapred.JobClient: map 11% reduce 0%
…
…
12/06/10 10:35:21 INFO mapred.JobClient: map 88% reduce 22%
12/06/10 10:35:24 INFO mapred.JobClient: map 100% reduce 22%
12/06/10 10:35:27 INFO mapred.JobClient: map 100% reduce 29%
12/06/10 10:35:36 INFO mapred.JobClient: map 100% reduce 100%
12/06/10 10:35:42 INFO mapred.JobClient: Job complete: job_201206101010_0003
….
12/06/10 10:36:16 INFO mapred.JobClient: Reduce input groups=3
12/06/10 10:36:16 INFO mapred.JobClient: Combine output records=0
12/06/10 10:36:16 INFO mapred.JobClient: Physical memory (bytes) snapshot=180502528
12/06/10 10:36:16 INFO mapred.JobClient: Reduce output records=36
12/06/10 10:36:16 INFO mapred.JobClient: Virtual memory (bytes) snapshot=695119872
12/06/10 10:36:16 INFO mapred.JobClient: Map output records=36
i) Check the result
[root@localhost hduser]# /usr/local/hadoop/bin/hadoop dfs -cat /user/hduser/output/*
6 dfs.data.dir
2 dfs.
2 dfs.block.access.token.enable
2 dfs.cluster.administrators
2 dfs.datanode.address
2 dfs.datanode.data.dir.perm
2 dfs.datanode.http.address
2 dfs.datanode.kerberos.principal
2 dfs.datanode.keytab.file
2 dfs.exclude
…..
j)/usr/local/hadoop/bin/stop-all.sh
Have fun with hadoop…
Share:

Big Data – Getting bigger!
 Published in Telecom Asia – Big Data is getting bigger
Published in Telecom Asia – Big Data is getting bigger
There are two very significant ways that our world has changed in the past decade. Firstly, we are more “connected”. Secondly we are “awash with data.” In a planet with 7 billion people there are now 2 billion PCs and upward of 6 billion mobile connections. Besides the connection which we as human beings have there are now numerous connections to the internet from devices, sensors and actuators. In other words the world is getting more and more instrumented. There are in excess of 30 billion RFID tags which enable tracking of goods as they move from warehouse, to retail store, sensors on cars and bridges besides cardiac implants in the human body that are constantly sending a stream of data to the network (do look at my post The Internet of Things” . In addition we have the emergence of the Smart Grid with its millions and millions of smart meters that are capable of sensing power loads and appropriately redistributing power and drawing less power during peak hours.
All these devices be it laptops, cell phones, sensors, RFIDs or smart meters are sending enormous amounts of data to the network. In other words there is an enormous data overload happening in the networks of today. According to a Cisco report the projected increase in data traffic between 2014 and 2015 is of the order of 200 exabytes (10^18)). In addition the report states that the total number of connected to the network will be twice the world population or around 15 billion).
Fortunately the explosion in data has been accompanied by falling prices in storage and extraordinary increases in processing capacity. The data that is generated by the devices by the devices, cell phones, PC etc by themselves are useless. However if processed they can provide insights into trends and patterns which can be used to make key decisions. For e.g. the data exhaust that comes from a user’s browsing trail, click stream provide important insight into user behavior which can be mined to make important decisions. Similarly inputs from social media like Twitter, Facebook provide businesses with key inputs which can be used for making business decisions. Call Detail records that are created for mobile calls can also be a source of user behavior. Data from retail store provide insights into consumer choices. For all these to happen the enormous amounts of data has to be analyzed using algorithms to determine statistical trends, patterns and tendencies in the data.
It is here that Big Data enters the picture. Big Data enables the management of the 3 V’s of data , namely volume, velocity and variety. As mentioned above the volume of data is growing at an exponential rate and should exceed 200 exabytes by 2015. The rate at which the data is generated, or the velocity, is also growing phenomenally given the variety and the number of devices that are connected to the network. Besides there is a tremendous variety to the data. Data is both structured, semi-structured and unstructured. Logs could be in plain text, CSV,XML, JSON and so on. The issue of 3 V’s of data makes Big Data most suited for crunching this enormous proliferation of data at the velocity at which it is generated.
Big Data : Big Data or Analytics (see my post “The Rise of Analytics” ) deals with the algorithms that analyze petabytes (10^15)of data and identify key patterns in them. The patterns that are so identified can be used to make important predictions in the future. For example Big Data has been used by energy companies in identifying key locations for positioning their wind turbines. To identify the precise location requires that petabytes of data be crunched rapidly and appropriate patterns be identified. There are several applications of Big Data including identifying brand sentiment from social media, to customer behavior from click exhaust to identifying optimal power usage by consumers.
The key difference between Big Data and traditional processing methods are that the volume of data that has be processed and the speed with which it has to be processed. As mentioned before the 3 V’s of volume, velocity and variety make traditional methods unsuitable for handling this data. In this context, besides the key algorithms of analytics another player is extremely important in Big Data – that is Hadoop. Hadoop is a processing technique that involves tremendous parallelization of the task (for details look at To Hadoop, or not to Hadoop)
The Hadoop Ecosystem – Hadoop had its origins at Google during its work with the Google’s File System (GFS) and the Map Reduce programming paradigm.
HDFS and Map-Reduce : Hadoop in essence is the Hadoop Distributed File System (HDFS) and the Map Reduce paradigm. The Hadoop System is made up of thousands of distributed commodity servers. The data is stored in the HDFS in blocks of 64 MB or 128 MB. The data is replicated among two or more servers to maintain redundancy. Since Hadoop is made of regular commodity servers which are prone to failures, fault tolerance is included by design. The Map Reduce Paradigm essentially breaks a job into multiple tasks which are executed in parallel. Initially the “Map” part processes the input data and outputs a pair of tuples. The “Reduce” part then scans the pair of tuples and generates a consolidated output. For e.g. The “map” part could count the number of occurrences of different words in different sets of files and output the words and their count as pairs. The “reduce” would then sum up the counts of the word from the individual ‘map’ parts and provide the total occurrences of the words in multiple files.
Pig and PigLatin : This is a programming language developed at Yahoo to relieve programmers of the intricacies of programming the Map-Reduce and assigning tasks to individual parts. Pig is made up of two parts namely PigLatin, the language and the environment in which it will execute.
Hive: Hive is a Hadoop run-time support structure that was developed by Facebook. Hive has a distinct SQL flavor to it and also simplifies the task of Hadoop programming.
JAQL : JAQL is a declarative query language developed by IBM for handling JSON objects. JAQL is another programming paradigm that is used to programming Hadoop.
Conclusion: It is a foregone conclusion that Big Data and Hadoop will take center stage in the not too distant future given the explosion of data and the dire need of being able to glean useful business insights from them. Big Data and its algorithms provide the way for identifying useful pearls of wisdom from otherwise useless data. Big Data is bound to become mission critical in the enterprises of the future.
Share:

Cloud Computing – Design Considerations
 Cloud Computing is definitely turning out to be the proverbial carrot for enterprises to host their applications on the public cloud. The cloud promises many benefits to users of the cloud. Cloud Computing obviates the need for upfront capital expenses for computing infrastructure, real estate and maintenance personnel. This technology allows for scaling up or scaling down as demand on the application fluctuates.
Cloud Computing is definitely turning out to be the proverbial carrot for enterprises to host their applications on the public cloud. The cloud promises many benefits to users of the cloud. Cloud Computing obviates the need for upfront capital expenses for computing infrastructure, real estate and maintenance personnel. This technology allows for scaling up or scaling down as demand on the application fluctuates.
While the advantages are many, migrating application onto the cloud is no trivial task. The cloud is essentially composed of commodity servers. The cloud creates multiple instances of the application and runs it on the same or on different servers. The benefit of executing in parallel is that the same task can be completed faster. The cloud offers enterprises the ability to quickly scale to handle increasing demands,
But the process of deploying applications on to the cloud requires that the application be re architected to take advantage of this parallelism that the cloud provides. But the ability to handle parallelization is no simple task. The key attributes that need to be handled by distributed systems is the need for consistency and availability. If there are variables that need to be shared across the parallel instances then the application must make special provisions to handle this and ensure consistency. Similarly the application must be designed to handle failures.
Applications that are intended to be deployed on the cloud must be designed to scale-out rather than having the ability to scale-up. Scaling up refers to the process of adding more horse power by way of faster CPUs, more RAM and faster throughput. But applications that need to be deployed on the cloud need to have the ability to scale out or scale horizontally where more servers are added without any change in processing horsepower. The design for horizontal scalability is the key to cloud computing architectures.
Some of the key principles to keep in mind while designing for the cloud is to ensure that the application is composed of loosely coupled processes preferably based on SOA principles. While a multi-threaded architecture where resource sharing through mutexes works in monolithic applications such a architecture is of no help when there are multiple instances of the same application running on different servers. How does one maintain consistency of the shared resource across instances? This is a tough problem to solve. Ideally the application should be thread safe and should be based on a shared – nothing kind of architecture. One such technique is to use queues that the cloud provides as a means of sharing across instances. However this may impact the performance of the system. Other methods include using ‘memcached’ which has been used successfully by Facebook, Twitter, Livejournal, Zynga etc deployed on the cloud. Still another method is to use the Map-Reduce algorithm where the variables across instances are handled by ‘map’ and the ‘reduce’ part handles the consistency across instances.
Another key consideration is the need to support availability requirements. Since the cloud is made up of commodity hardware there is every possibility of servers failing. The application must be designed with inbuilt resilience to handle such failures. This could by designing active-standby architecture or by providing for checkpointing so that application can restart from some known previous point.
Hence while cloud computing is the way to go in the future there is a need to be able to carefully design the application so that full advantage of the cloud can be taken.
