Here is the 1st part of my video presentation on “Machine Learning, Data Science, NLP and Big Data – Part 2”
Author: Tinniam V Ganesh
Visionary, thought leader and pioneer with 27+ years of experience in the software industry.

Video presentation on Machine Learning, Data Science, NLP and Big Data – Part 1
Here is the 1st part of my video presentation on “Machine Learning, Data Science, NLP and Big Data – Part 1”
Share:
Analyzing World Bank data with WDI, googleVis Motion Charts
Recently I was surfing the web, when I came across a real cool post New R package to access World Bank data, by Markus Gesmann on using googleVis and motion charts with World Bank Data. The post also introduced me to Hans Rosling, Professor of Sweden’s Karolinska Institute. Hans Rosling, the creator of the famous Gapminder chart, the “Heath and Wealth of Nations” displays global trends through animated charts (A must see!!!). As they say, in Hans Rosling’s hands, data dances and sings. Take a look at some of his Ted talks for e.g. Hans Rosling:New insights on poverty. Prof Rosling developed the breakthrough software behind the visualizations, in the Gapminder. The free software, which can be loaded with any data – was purchased by Google in March 2007.
In this post, I recreate some of the Gapminder charts with the help of R packages WDI and googleVis. The WDI package of Vincent Arel-Bundock, provides a set of really useful functions to get to data based on the World Bank Data indicators. googleVis provides motion charts with which you can animate the data.. Incidentally Datacamp has a very nice, short course on googleVis “Having fun with googleVis”
See an updated version of this post Revisiting World Bank data analysis with WDI and gVisMotionChart
You can clone/download the code from Github at worldBankAnalysis which is in the form of an Rmd file.
library(WDI)
library(ggplot2)
library(googleVis)
library(plyr)1.Get the data from 1960 to 2016 for the following
- Population – SP.POP.TOTL
- GDP in US $ – NY.GDP.MKTP.CD
- Life Expectancy at birth (Years) – SP.DYN.LE00.IN
- GDP Per capita income – NY.GDP.PCAP.PP.CD
- Fertility rate (Births per woman) – SP.DYN.TFRT.IN
- Poverty headcount ratio – SI.POV.2DAY
# World population total
population = WDI(indicator='SP.POP.TOTL', country="all",start=1960, end=2016)
# GDP in US $
gdp= WDI(indicator='NY.GDP.MKTP.CD', country="all",start=1960, end=2016)
# Life expectancy at birth (Years)
lifeExpectancy= WDI(indicator='SP.DYN.LE00.IN', country="all",start=1960, end=2016)
# GDP Per capita
income = WDI(indicator='NY.GDP.PCAP.PP.CD', country="all",start=1960, end=2016)
# Fertility rate (births per woman)
fertility = WDI(indicator='SP.DYN.TFRT.IN', country="all",start=1960, end=2016)
# Poverty head count
poverty= WDI(indicator='SI.POV.2DAY', country="all",start=1960, end=2016)2.Rename the columns
names(population)[3]="Total population"
names(lifeExpectancy)[3]="Life Expectancy (Years)"
names(gdp)[3]="GDP (US$)"
names(income)[3]="GDP per capita income"
names(fertility)[3]="Fertility (Births per woman)"
names(poverty)[3]="Poverty headcount ratio"3.Join the data frames
Join the individual data frames to one large wide data frame with all the indicators for the countries
j1 <- join(population, gdp)
j2 <- join(j1,lifeExpectancy)
j3 <- join(j2,income)
j4 <- join(j3,poverty)
wbData <- join(j4,fertility)
4.Use WDI_data
Use WDI_data to get the list of indicators and the countries. Join the countries and region
#This returns list of 2 matrixes
wdi_data =WDI_data
# The 1st matrix is the list is the set of all World Bank Indicators
indicators=wdi_data[[1]]
# The 2nd matrix gives the set of countries and regions
countries=wdi_data[[2]]
df = as.data.frame(countries)
aa <- df$region != "Aggregates"
# Remove the aggregates
countries_df <- df[aa,]
# Subset from the development data only those corresponding to the countries
bb = subset(wbData, country %in% countries_df$country)
cc = join(bb,countries_df)dd = complete.cases(cc)
developmentDF = cc[dd,]5.Create and display the motion chart
gg<- gvisMotionChart(cc,
idvar = "country",
timevar = "year",
xvar = "GDP",
yvar = "Life Expectancy",
sizevar ="Population",
colorvar = "region")
plot(gg)
cat(gg$html$chart, file="chart1.html")
Note: Unfortunately it is not possible to embed the motion chart in WordPress. It is has to hosted on a server as a Webpage. After exploring several possibilities I came up with the following process to display the animation graph. The plot is saved as a html file using ‘cat’ as shown above. The chart1.html page is then hosted as a Github page (gh-page) on Github.
Here is the ggvisMotionChart
Do give World Bank Motion Chart1 a spin. Here is how the Motion Chart has to be used
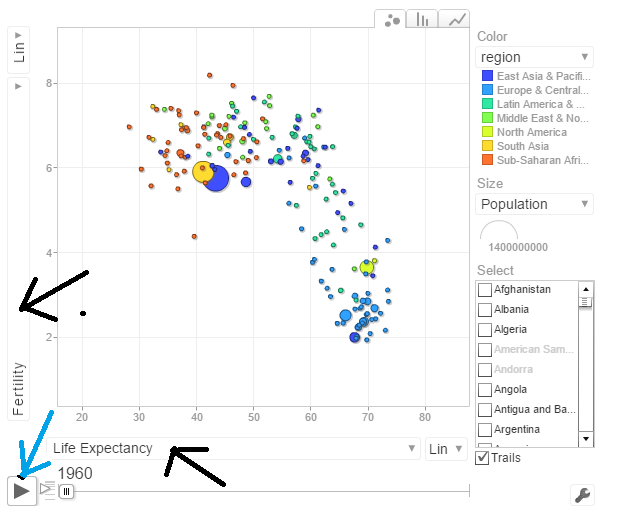
You can select Life Expectancy, Population, Fertility etc by clicking the black arrows. The blue arrow shows the ‘play’ button to set animate the motion chart. You can also select the countries and change the size of the circles. Do give it a try. Here are some quick analysis by playing around with the motion charts with different parameters chosen
The set of charts below are screenshots captured by running the motion chart World Bank Motion Chart1
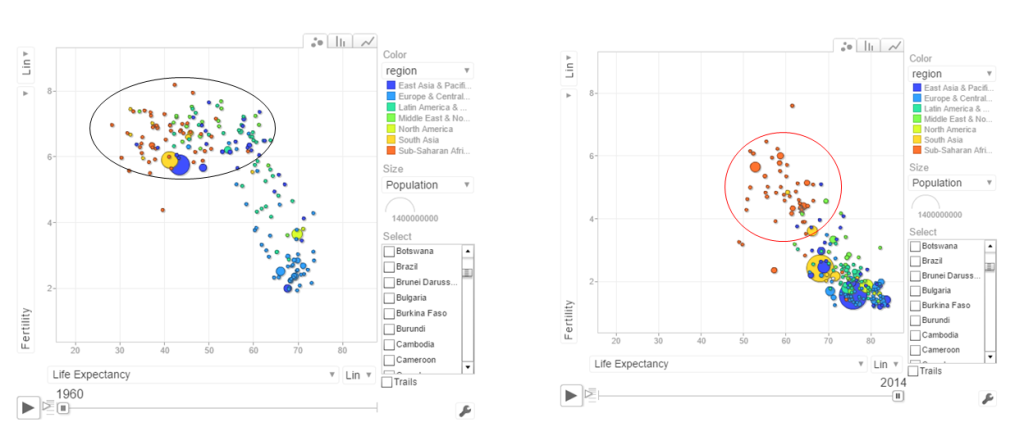
a. Life Expectancy vs Fertility chart
This chart is used by Hans Rosling in his Ted talk. The left chart shows low life expectancy and high fertility rate for several sub Saharan and East Asia Pacific countries in the early 1960’s. Today the fertility has dropped and the life expectancy has increased overall. However the sub Saharan countries still have a high fertility rate
b. Population vs GDP
The chart below shows that GDP of India and China have the same GDP from 1973-1994 with US and Japan well ahead.
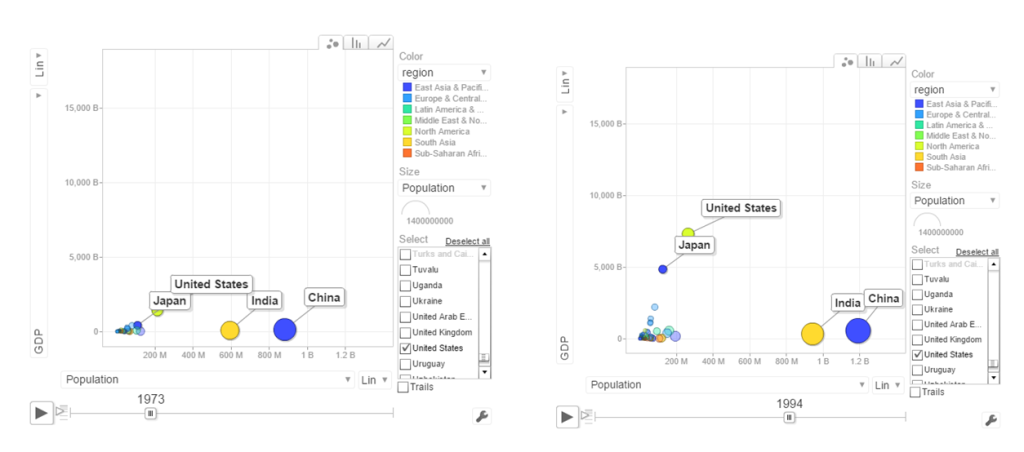
From 1998- 2014 China really pulls away from India and Japan as seen below
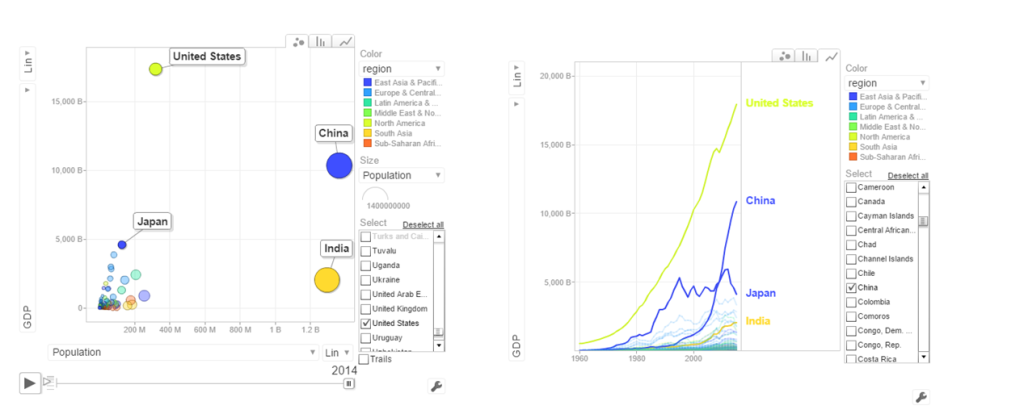
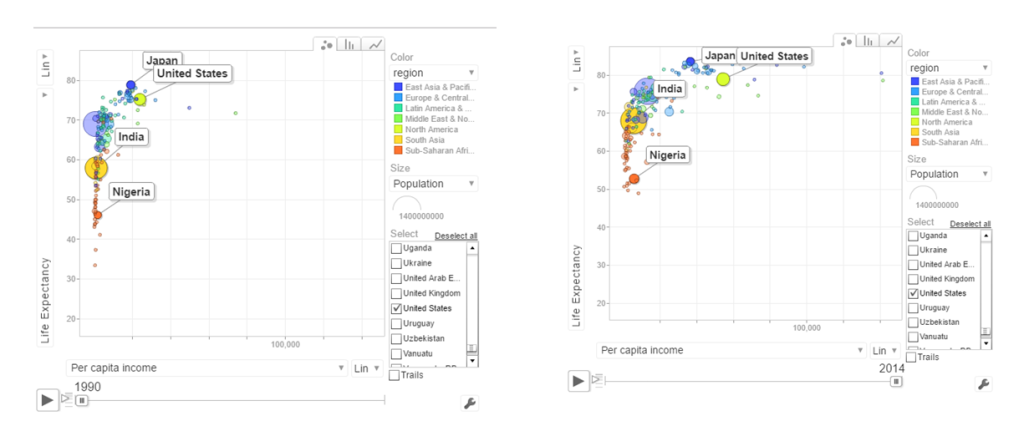
c. Per capita income vs Life Expectancy
In the 1990’s the per capita income and life expectancy of the sub -saharan countries are low (42-50). Japan and US have a good life expectancy in 1990’s. In 2014 the per capita income of the sub-saharan countries are still low though the life expectancy has marginally improved.
d. Population vs Poverty headcount
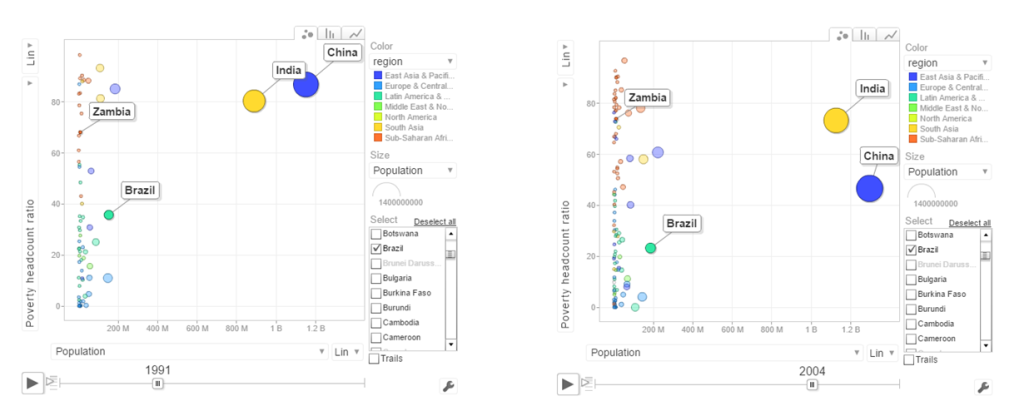
In the early 1990’s China had a higher poverty head count ratio than India. By 2004 China had this all figured out and the poverty head count ratio drops significantly. This can also be seen in the chart below.
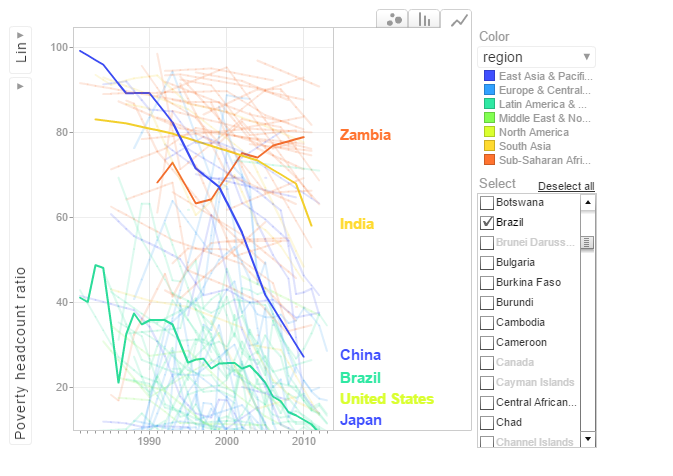
In the chart above China shows a drastic reduction in poverty headcount ratio vs India. Strangely Zambia shows an increase in the poverty head count ratio.
6.Get the data for the 2nd set of indicators
- Total population – SP.POP.TOTL
- GDP in US$ – NY.GDP.MKTP.CD
- Access to electricity (% population) – EG.ELC.ACCS.ZS
- Electricity consumption KWh per capita -EG.USE.ELEC.KH.PC
- CO2 emissions -EN.ATM.CO2E.KT
- Sanitation Access – SH.STA.ACSN
# World population
population = WDI(indicator='SP.POP.TOTL', country="all",start=1960, end=2016)
# GDP in US $
gdp= WDI(indicator='NY.GDP.MKTP.CD', country="all",start=1960, end=2016)
# Access to electricity (% population)
elecAccess= WDI(indicator='EG.ELC.ACCS.ZS', country="all",start=1960, end=2016)
# Electric power consumption Kwh per capita
elecConsumption= WDI(indicator='EG.USE.ELEC.KH.PC', country="all",start=1960, end=2016)
#CO2 emissions
co2Emissions= WDI(indicator='EN.ATM.CO2E.KT', country="all",start=1960, end=2016)
# Access to sanitation (% population)
sanitationAccess= WDI(indicator='SH.STA.ACSN', country="all",start=1960, end=2016)7.Rename the columns
names(population)[3]="Total population"
names(gdp)[3]="GDP US($)"
names(elecAccess)[3]="Access to Electricity (% popn)"
names(elecConsumption)[3]="Electric power consumption (KWH per capita)"
names(co2Emissions)[3]="CO2 emisions"
names(sanitationAccess)[3]="Access to sanitation(% popn)"8.Join the individual data frames
Join the individual data frames to one large wide data frame with all the indicators for the countries
j1 <- join(population, gdp)
j2 <- join(j1,elecAccess)
j3 <- join(j2,elecConsumption)
j4 <- join(j3,co2Emissions)
wbData1 <- join(j3,sanitationAccess)
9.Use WDI_data
Use WDI_data to get the list of indicators and the countries. Join the countries and region
#This returns list of 2 matrixes
wdi_data =WDI_data
# The 1st matrix is the list is the set of all World Bank Indicators
indicators=wdi_data[[1]]
# The 2nd matrix gives the set of countries and regions
countries=wdi_data[[2]]
df = as.data.frame(countries)
aa <- df$region != "Aggregates"
# Remove the aggregates
countries_df <- df[aa,]
# Subset from the development data only those corresponding to the countries
ee = subset(wbData1, country %in% countries_df$country)
ff = join(ee,countries_df)## Joining by: iso2c, country10.Create and display the motion chart
gg1<- gvisMotionChart(ff,
idvar = "country",
timevar = "year",
xvar = "GDP",
yvar = "Access to Electricity",
sizevar ="Population",
colorvar = "region")
plot(gg1)
cat(gg1$html$chart, file="chart2.html")
This is World Bank Motion Chart2 which has a different set of parameters like Access to Energy, CO2 emissions etc
The set of charts below are screenshots of the motion chart World Bank Motion Chart 2
a. Access to Electricity vs Population
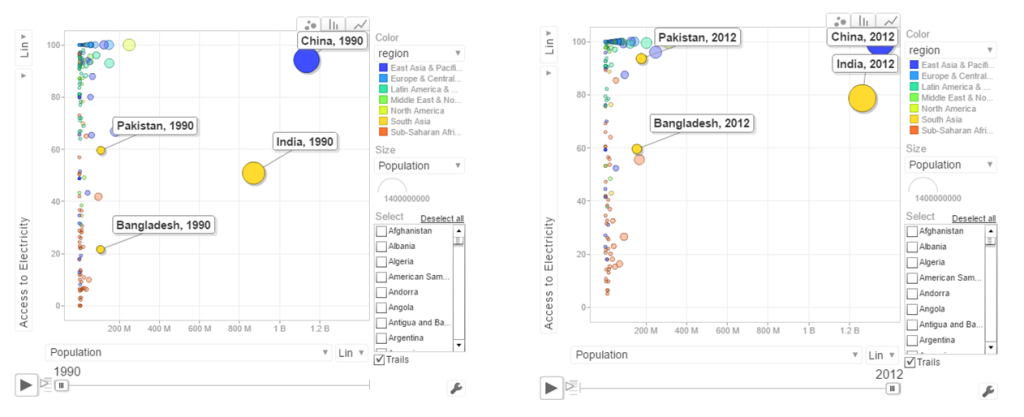 The above chart shows that in China 100% population have access to electricity. India has made decent progress from 50% in 1990 to 79% in 2012. However Pakistan seems to have been much better in providing access to electricity. Pakistan moved from 59% to close 98% access to electricity
The above chart shows that in China 100% population have access to electricity. India has made decent progress from 50% in 1990 to 79% in 2012. However Pakistan seems to have been much better in providing access to electricity. Pakistan moved from 59% to close 98% access to electricity
b. Power consumption vs population
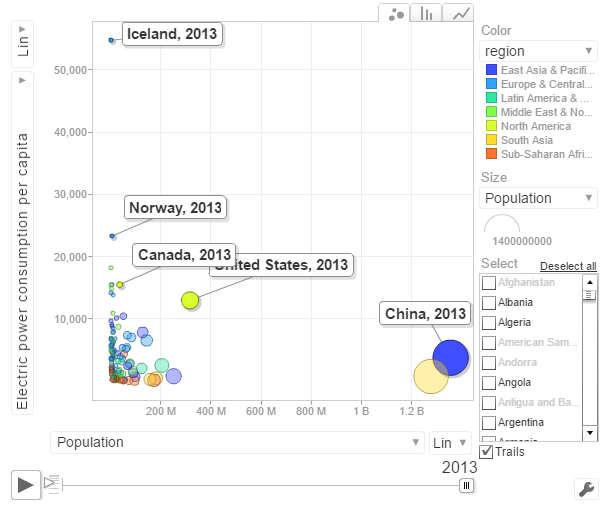
The above chart shows the Power consumption vs Population. China and India have proportionally much lower consumption that Norway, US, Canada
c. CO2 emissions vs Population
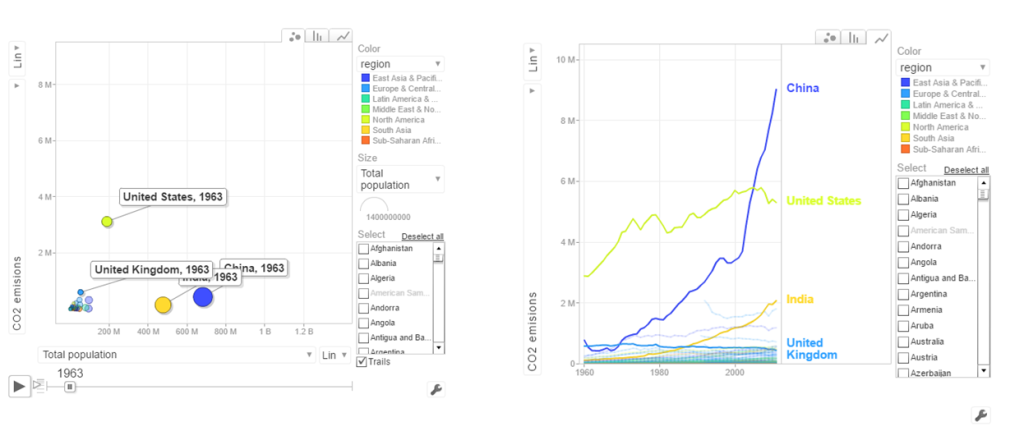
In 1963 the CO2 emissions were fairly low and about comparable for all countries. US, India have shown a steady increase while China shows a steep increase. Interestingly UK shows a drop in CO2 emissions
d. Access to sanitation
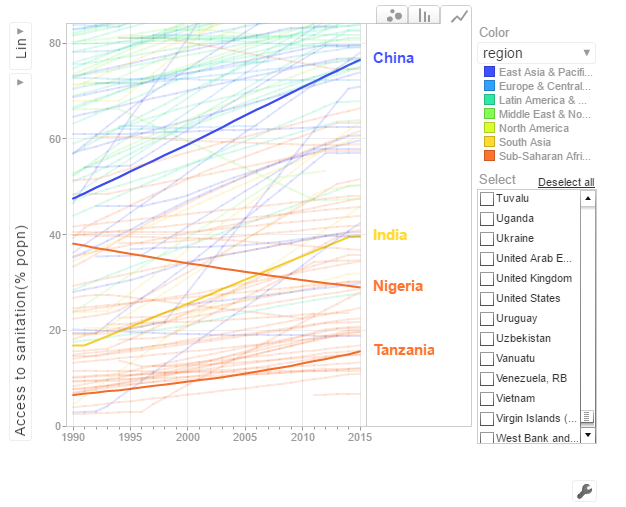
India shows an improvement but it has a long way to go with only 40% of population with access to sanitation. China has made much better strides with 80% having access to sanitation in 2015. Strangely Nigeria shows a drop in sanitation by almost about 20% of population.
The code is available at Github at worldBankAnalysys
Conclusion: So there you have it. I have shown some screenshots of some sample parameters of the World indicators. Please try to play around with World Bank Motion Chart1 & World Bank Motion Chart 2 with your own set of parameters and countries. You can also create your own motion chart from the 100s of WDI indicators avaialable at World Bank Data indicator.
Finally, I would really like to thank Prof Hans Rosling, googleVis and WDI (Vincent Arel-Bundock) for making this visualization possible!
Also see
1. Introducing QCSimulator: A 5-qubit quantum computing simulator in R
2. Dabbling with Wiener filter using OpenCV
3. Designing a Social Web Portal
4. Design Principles of Scalable, Distributed Systems
5. Re-introducing cricketr! : An R package to analyze performances of cricketers
6. Natural language processing: What would Shakespeare say?
To see all posts Index of posts
Share:

cricketr sizes up legendary All-rounders of yesteryear
Introduction
This is a post I have been wanting to write for several months, but had to put it off for one reason or another. In this post I use my R package cricketr to analyze the performance of All-rounder greats namely Kapil Dev, Ian Botham, Imran Khan and Richard Hadlee. All these players had talent that was natural and raw. They were good strikers of the ball and extremely lethal with their bowling. The ODI data for these players have been taken from ESPN Cricinfo.
Please be mindful of the ESPN Cricinfo Terms of Use
If you are passionate about cricket, and love analyzing cricket performances, then check out my racy book on cricket ‘Cricket analytics with cricketr and cricpy – Analytics harmony with R & Python’! This book discusses and shows how to use my R package ‘cricketr’ and my Python package ‘cricpy’ to analyze batsmen and bowlers in all formats of the game (Test, ODI and T20). The paperback is available on Amazon at $21.99 and the kindle version at $9.99/Rs 449/-. A must read for any cricket lover! Check it out!!
You can download the latest PDF version of the book at ‘Cricket analytics with cricketr and cricpy: Analytics harmony with R and Python-6th edition‘

You can also read this post at Rpubs as cricketr-AR. Dowload this report as a PDF file from cricketr-AR
Important note 1: The latest release of ‘cricketr’ now includes the ability to analyze performances of teams now!! See Cricketr adds team analytics to its repertoire!!!
Important note 2 : Cricketr can now do a more fine-grained analysis of players, see Cricketr learns new tricks : Performs fine-grained analysis of players
Important note 3: Do check out the python avatar of cricketr, ‘cricpy’ in my post ‘Introducing cricpy:A python package to analyze performances of cricketers”
Note: If you would like to do a similar analysis for a different set of batsman and bowlers, you can clone/download my skeleton cricketr template from Github (which is the R Markdown file I have used for the analysis below). You will only need to make appropriate changes for the players you are interested in. Just a familiarity with R and R Markdown only is needed.
Important note: Do check out my other posts using cricketr at cricketr-posts
All Rounders
- Kapil Dev (Ind)
- Ian Botham (Eng)
- Imran Khan (Pak)
- Richard Hadlee (NZ)
I have sprinkled the plots with a few of my comments. Feel free to draw your conclusions! The analysis is included below
if (!require("cricketr")){
install.packages("cricketr",)
}
library(cricketr)The data for any particular ODI player can be obtained with the getPlayerDataOD() function. To do you will need to go to ESPN CricInfo Playerand type in the name of the player for e.g Kapil Dev, etc. This will bring up a page which have the profile number for the player e.g. for Kapil Dev this would be http://www.espncricinfo.com/india/content/player/30028.html. Hence, Kapils’s profile is 30028. This can be used to get the data for Kapil Dev’s data as shown below. I have already executed the below 4 commands and I will use the files to run further commands
#kapil1
#botham11
#imran1
#hadlee1 Analyses of batting performances of the All Rounders
The following plots gives the analysis of the 4 ODI batsmen
- Kapil Dev (Ind) – Innings – 225, Runs = 3783, Average=23.79, Strike Rate= 95.07
- Ian Botham (Eng) – Innings – 116, Runs= 2113, Average=23.21, Strike Rate= 79.10
- Imran Khan (Pak) – Innings – 175, Runs= 3709, Average=33.41, Strike Rate= 72.65
- Richard Hadlee (NZ) – Innings – 115, Runs= 1751, Average=21.61, Strike Rate= 75.50
Plot of 4s, 6s and the scoring rate in ODIs
The 3 charts below give the number of
- 4s vs Runs scored
- 6s vs Runs scored
- Balls faced vs Runs scored
A regression line is fitted in each of these plots for each of the ODI batsmen
A. Kapil Dev
It can be seen that Kapil scores four 4’s when he scores 50. Also after facing 50 deliveries he scores around 43
par(mfrow=c(1,3))
par(mar=c(4,4,2,2))
batsman4s("./kapil1.csv","Kapil")
batsman6s("./kapil1.csv","Kapil")
batsmanScoringRateODTT("./kapil1.csv","Kapil")
dev.off()## null device
## 1B. Ian Botham
Botham scores around 39 runs after 50 deliveries
par(mfrow=c(1,3))
par(mar=c(4,4,2,2))
batsman4s("./botham1.csv","Botham")
batsman6s("./botham1.csv","Botham")
batsmanScoringRateODTT("./botham1.csv","Botham")
dev.off()## null device
## 1C. Imran Khan
Imran scores around 36 runs for 50 deliveries
par(mfrow=c(1,3))
par(mar=c(4,4,2,2))
batsman4s("./imran1.csv","Imran")
batsman6s("./imran1.csv","Imran")
batsmanScoringRateODTT("./imran1.csv","Imran")
dev.off()## null device
## 1D. Richard Hadlee
Hadlee also scores around 30 runs facing 50 deliveries
par(mfrow=c(1,3))
par(mar=c(4,4,2,2))
batsman4s("./hadlee1.csv","Hadlee")
batsman6s("./hadlee1.csv","Hadlee")
batsmanScoringRateODTT("./hadlee1.csv","Hadlee")
dev.off()## null device
## 1Cumulative Average runs of batsman in career
Kapils cumulative avrerage runs drops towards the last 15 innings wheres Botham had a good run towards the end of his career. Imran performance as a batsman really peaks towards the end with a cumulative average of almost 25 runs. Hadlee has a stead performance
par(mfrow=c(2,2))
par(mar=c(4,4,2,2))
batsmanCumulativeAverageRuns("./kapil1.csv","Kapil")
batsmanCumulativeAverageRuns("./botham1.csv","Botham")
batsmanCumulativeAverageRuns("./imran1.csv","Imran")
batsmanCumulativeAverageRuns("./hadlee1.csv","Hadlee")
dev.off()## null device
## 1Cumulative Average strike rate of batsman in career
Kapil’s strike rate is superlative touching the 90’s steadily. Botham’s strike drops dramatically towards the latter part of his career. Imran average at a steady 75 and Hadlee averages around 85.
par(mfrow=c(2,2))
par(mar=c(4,4,2,2))
batsmanCumulativeStrikeRate("./kapil1.csv","Kapil")
batsmanCumulativeStrikeRate("./botham1.csv","Botham")
batsmanCumulativeStrikeRate("./imran1.csv","Imran")
batsmanCumulativeStrikeRate("./hadlee1.csv","Hadlee")
dev.off()## null device
## 1Relative Mean Strike Rate
Kapil tops the strike rate among all the all-rounders. This is really a revelation to me. This can also be seen in the original data in Kapil’s strike rate is at a whopping 95.07 in comparison to Botham, Inran and Hadlee who are at 79.1,72.65 and 75.50 respectively
par(mar=c(4,4,2,2))
frames <- list("./kapil1.csv","./botham1.csv","imran1.csv","hadlee1.csv")
names <- list("Kapil","Botham","Imran","Hadlee")
relativeBatsmanSRODTT(frames,names)
Relative Runs Frequency Percentage
This plot shows that Imran has a much better average runs scored over the other all rounders followed by Kapil
frames <- list("./kapil1.csv","./botham1.csv","imran1.csv","hadlee1.csv")
names <- list("Kapil","Botham","Imran","Hadlee")
relativeRunsFreqPerfODTT(frames,names)
Relative cumulative average runs in career
It can be seen clearly that Imran Khan leads the pack in cumulative average runs followed by Kapil Dev and then Botham
frames <- list("./kapil1.csv","./botham1.csv","imran1.csv","hadlee1.csv")
names <- list("Kapil","Botham","Imran","Hadlee")
relativeBatsmanCumulativeAvgRuns(frames,names)
Relative cumulative average strike rate in career
In the cumulative strike rate Hadlee and Kapil run a close race.
frames <- list("./kapil1.csv","./botham1.csv","imran1.csv","hadlee1.csv")
names <- list("Kapil","Botham","Imran","Hadlee")
relativeBatsmanCumulativeStrikeRate(frames,names)
Percent 4’s,6’s in total runs scored
The plot below shows the contrib
frames <- list("./kapil1.csv","./botham1.csv","imran1.csv","hadlee1.csv")
names <- list("Kapil","Botham","Imran","Hadlee")
runs4s6s <-batsman4s6s(frames,names)
print(runs4s6s)## Kapil Botham Imran Hadlee
## Runs(1s,2s,3s) 72.08 66.53 77.53 73.27
## 4s 21.98 25.78 17.61 21.08
## 6s 5.94 7.68 4.86 5.65Runs forecast
The forecast for the batsman is shown below.
par(mfrow=c(2,2))
par(mar=c(4,4,2,2))
batsmanPerfForecast("./kapil1.csv","Kapil")
batsmanPerfForecast("./botham1.csv","Botham")
batsmanPerfForecast("./imran1.csv","Imran")batsmanPerfForecast("./hadlee1.csv","Hadlee")
dev.off()## null device
## 13D plot of Runs vs Balls Faced and Minutes at Crease
The plot is a scatter plot of Runs vs Balls faced and Minutes at Crease. A prediction plane is fitted
par(mfrow=c(1,2))
par(mar=c(4,4,2,2))
battingPerf3d("./kapil1.csv","Kapil")
battingPerf3d("./botham1.csv","Botham")
dev.off()## null device
## 1par(mfrow=c(1,2))
par(mar=c(4,4,2,2))
battingPerf3d("./imran1.csv","Imran")
battingPerf3d("./hadlee1.csv","Hadlee")
dev.off()## null device
## 1Predicting Runs given Balls Faced and Minutes at Crease
A multi-variate regression plane is fitted between Runs and Balls faced +Minutes at crease.
BF <- seq( 10, 200,length=10)
Mins <- seq(30,220,length=10)
newDF <- data.frame(BF,Mins)
kapil <- batsmanRunsPredict("./kapil1.csv","Kapil",newdataframe=newDF)
botham <- batsmanRunsPredict("./botham1.csv","Botham",newdataframe=newDF)
imran <- batsmanRunsPredict("./imran1.csv","Imran",newdataframe=newDF)
hadlee <- batsmanRunsPredict("./hadlee1.csv","Hadlee",newdataframe=newDF)The fitted model is then used to predict the runs that the batsmen will score for a hypotheticial Balls faced and Minutes at crease. It can be seen that Kapil is the best bet for a balls faced and minutes at crease followed by Botham.
batsmen <-cbind(round(kapil$Runs),round(botham$Runs),round(imran$Runs),round(hadlee$Runs))
colnames(batsmen) <- c("Kapil","Botham","Imran","Hadlee")
newDF <- data.frame(round(newDF$BF),round(newDF$Mins))
colnames(newDF) <- c("BallsFaced","MinsAtCrease")
predictedRuns <- cbind(newDF,batsmen)
predictedRuns## BallsFaced MinsAtCrease Kapil Botham Imran Hadlee
## 1 10 30 16 6 10 15
## 2 31 51 33 22 22 28
## 3 52 72 49 38 33 42
## 4 73 93 65 54 45 56
## 5 94 114 81 70 56 70
## 6 116 136 97 86 67 84
## 7 137 157 113 102 79 97
## 8 158 178 130 117 90 111
## 9 179 199 146 133 102 125
## 10 200 220 162 149 113 139Highest runs likelihood
The plots below the runs likelihood of batsman. This uses K-Means . A. Kapil Dev
batsmanRunsLikelihood("./kapil1.csv","Kapil")
## Summary of Kapil 's runs scoring likelihood
## **************************************************
##
## There is a 34.57 % likelihood that Kapil will make 22 Runs in 24 balls over 34 Minutes
## There is a 17.28 % likelihood that Kapil will make 46 Runs in 46 balls over 65 Minutes
## There is a 48.15 % likelihood that Kapil will make 5 Runs in 7 balls over 9 MinutesB. Ian Botham
batsmanRunsLikelihood("./botham1.csv","Botham")
## Summary of Botham 's runs scoring likelihood
## **************************************************
##
## There is a 47.95 % likelihood that Botham will make 9 Runs in 12 balls over 15 Minutes
## There is a 39.73 % likelihood that Botham will make 23 Runs in 32 balls over 44 Minutes
## There is a 12.33 % likelihood that Botham will make 59 Runs in 74 balls over 101 MinutesC. Imran Khan
batsmanRunsLikelihood("./imran1.csv","Imran")
## Summary of Imran 's runs scoring likelihood
## **************************************************
##
## There is a 23.33 % likelihood that Imran will make 36 Runs in 54 balls over 74 Minutes
## There is a 60 % likelihood that Imran will make 14 Runs in 18 balls over 23 Minutes
## There is a 16.67 % likelihood that Imran will make 53 Runs in 90 balls over 115 MinutesD. Richard Hadlee
batsmanRunsLikelihood("./hadlee1.csv","Hadlee")
## Summary of Hadlee 's runs scoring likelihood
## **************************************************
##
## There is a 6.1 % likelihood that Hadlee will make 64 Runs in 79 balls over 90 Minutes
## There is a 42.68 % likelihood that Hadlee will make 25 Runs in 33 balls over 44 Minutes
## There is a 51.22 % likelihood that Hadlee will make 9 Runs in 11 balls over 15 MinutesAverage runs at ground and against opposition
A. Kapil Dev
par(mfrow=c(1,2))
par(mar=c(4,4,2,2))
batsmanAvgRunsGround("./kapil1.csv","Kapil")
batsmanAvgRunsOpposition("./kapil1.csv","Kapil")
dev.off()## null device
## 1B. Ian Botham
par(mfrow=c(1,2))
par(mar=c(4,4,2,2))
batsmanAvgRunsGround("./botham1.csv","Botham")
batsmanAvgRunsOpposition("./botham1.csv","Botham")
dev.off()## null device
## 1C. Imran Khan
par(mfrow=c(1,2))
par(mar=c(4,4,2,2))
batsmanAvgRunsGround("./imran1.csv","Imran")
batsmanAvgRunsOpposition("./imran1.csv","Imran")
dev.off()## null device
## 1D. Richard Hadlee
par(mfrow=c(1,2))
par(mar=c(4,4,2,2))
batsmanAvgRunsGround("./hadlee1.csv","Hadlee")
batsmanAvgRunsOpposition("./hadlee1.csv","Hadlee")
dev.off()## null device
## 1Moving Average of runs over career
The moving average for the 4 batsmen indicate the following
Kapil’s performance drops significantly while there is a slump in Botham’s performance. On the other hand Imran and Hadlee’s performance were on the upswing.
par(mfrow=c(2,2))
par(mar=c(4,4,2,2))
batsmanMovingAverage("./kapil1.csv","Kapil")
batsmanMovingAverage("./botham1.csv","Botham")
batsmanMovingAverage("./imran1.csv","Imran")
batsmanMovingAverage("./hadlee1.csv","Hadlee")
dev.off()## null device
## 1Check batsmen in-form, out-of-form
[1] “**************************** Form status of Kapil ****************************\n\n
Population size: 72
Mean of population: 19.38 \n
Sample size: 9 Mean of sample: 6.78 SD of sample: 6.14 \n\n
Null hypothesis H0 : Kapil ‘s sample average is within 95% confidence interval of population average\n
Alternative hypothesis Ha : Kapil ‘s sample average is below the 95% confidence interval of population average\n\n
Kapil ‘s Form Status: Out-of-Form because the p value: 8.4e-05 is less than alpha= 0.05
“**************************** Form status of Botham ****************************\n\n
Population size: 65
Mean of population: 21.29 \n
Sample size: 8 Mean of sample: 15.38 SD of sample: 13.19 \n\n
Null hypothesis H0 : Botham ‘s sample average is within 95% confidence interval of population average\n
Alternative hypothesis Ha : Botham ‘s sample average is below the 95% confidence interval of population average\n\n
Botham ‘s Form Status: In-Form because the p value: 0.120342 is greater than alpha= 0.05 \n
“**************************** Form status of Imran ****************************\n\n
Population size: 54
Mean of population: 24.94 \n
Sample size: 6 Mean of sample: 30.83 SD of sample: 25.4 \n\n
Null hypothesis H0 : Imran ‘s sample average is within 95% confidence interval of population average\n
Alternative hypothesis Ha : Imran ‘s sample average is below the 95% confidence interval of population average\n\n
Imran ‘s Form Status: In-Form because the p value: 0.704683 is greater than alpha= 0.05 \n
“**************************** Form status of Hadlee ****************************\n\n
Population size: 73
Mean of population: 18 \n
Sample size: 9 Mean of sample: 27 SD of sample: 24.27 \n\n
Null hypothesis H0 : Hadlee ‘s sample average is within 95% confidence interval of population average\n
Alternative hypothesis Ha : Hadlee ‘s sample average is below the 95% confidence interval of population average\n\n
Hadlee ‘s Form Status: In-Form because the p value: 0.85262 is greater than alpha= 0.05 \n *******************************************************************************************\n\n”
Analyses of bowling performances of the All Rounders
The following plots gives the analysis of the 4 ODI batsmen
- Kapil Dev (Ind) – Innings – 225, Wickets = 253, Average=27.45, Economy Rate= 3.71
- Ian Botham (Eng) – Innings – 116, Wickets = 145, Average=28.54, Economy Rate= 3.96
- Imran Khan (Pak) – Innings – 175, Wickets = 182, Average=26.61, Economy Rate= 3.89
- Richard Hadlee (NZ) – Innings – 115, Wickets = 158, Average=21.56, Economy Rate= 3.30
Botham has the highest number of innings and wickets followed closely by Mitchell. Imran and Hadlee have relatively fewer innings.
To get the bowler’s data use
#kapil2
#botham2
#imran2
#hadlee2 “`
Wicket Frequency percentage
This plot gives the percentage of wickets for each wickets (1,2,3…etc).
par(mfrow=c(1,4))
par(mar=c(4,4,2,2))
bowlerWktsFreqPercent("./kapil2.csv","Kapil")
bowlerWktsFreqPercent("./botham2.csv","Botham")
bowlerWktsFreqPercent("./imran2.csv","Imran")
bowlerWktsFreqPercent("./hadlee2.csv","Hadlee")
dev.off()## null device
## 1Wickets Runs plot
The plot below gives a boxplot of the runs ranges for each of the wickets taken by the bowlers.
par(mfrow=c(1,4))
par(mar=c(4,4,2,2))
bowlerWktsRunsPlot("./kapil2.csv","Kapil")
bowlerWktsRunsPlot("./botham2.csv","Botham")
bowlerWktsRunsPlot("./imran2.csv","Imran")
bowlerWktsRunsPlot("./hadlee2.csv","Hadlee")
dev.off()## null device
## 1Cumulative average wicket plot
Botham has the best cumulative average wicket touching almost 1.6 wickets followed by Hadlee
par(mfrow=c(1,3))
par(mar=c(4,4,2,2))
bowlerCumulativeAvgWickets("./kapil2.csv","Kapil")
bowlerCumulativeAvgWickets("./botham2.csv","Botham")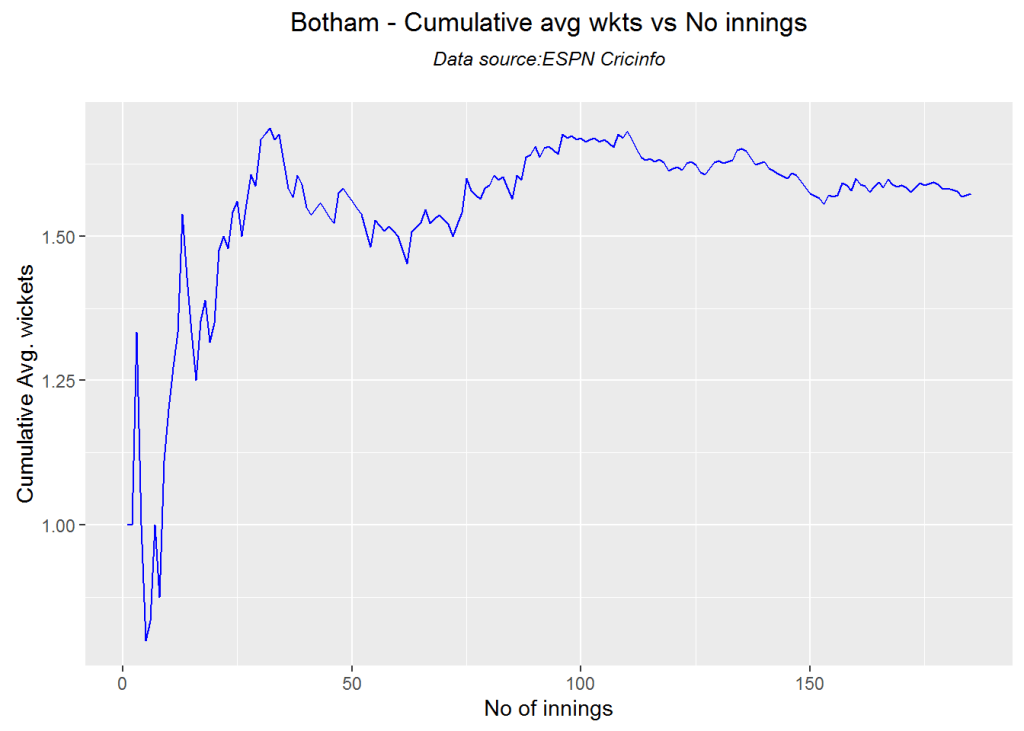
bowlerCumulativeAvgWickets("./imran2.csv","Imran")
bowlerCumulativeAvgWickets("./hadlee2.csv","Hadlee")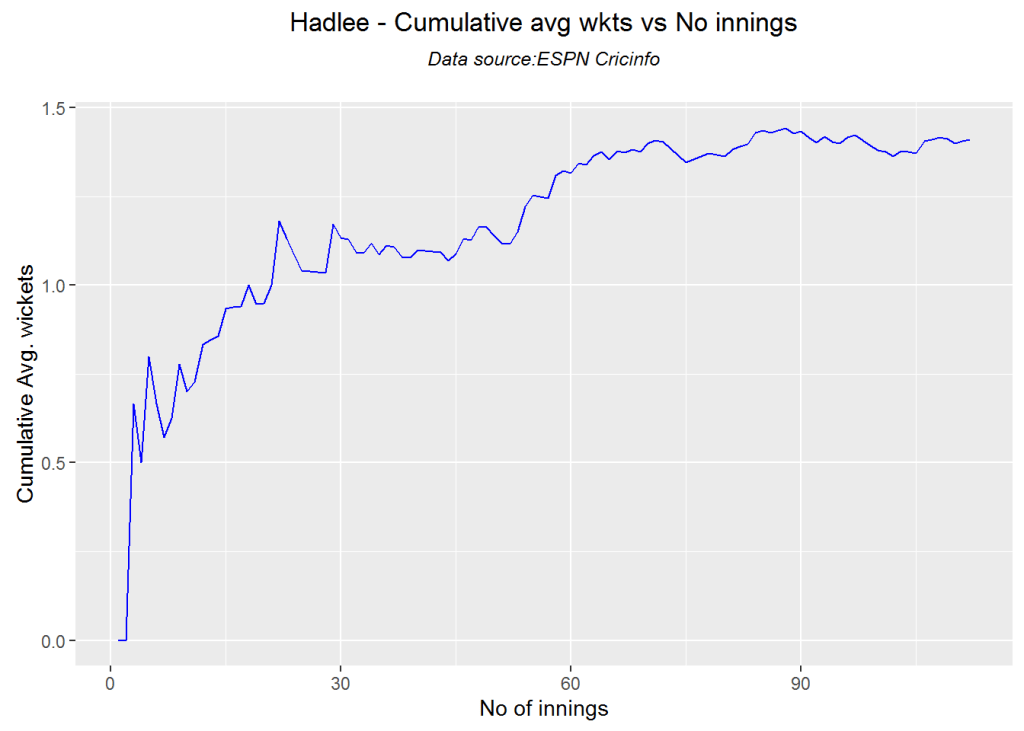
dev.off()## null device
## 1par(mfrow=c(1,3))
par(mar=c(4,4,2,2))
bowlerCumulativeAvgEconRate("./kapil2.csv","Kapil")
bowlerCumulativeAvgEconRate("./botham2.csv","Botham")
bowlerCumulativeAvgEconRate("./imran2.csv","Imran")
bowlerCumulativeAvgEconRate("./hadlee2.csv","Hadlee")
dev.off()## null device
## 1Average wickets in different grounds and opposition
A. Kapil Dev
par(mfrow=c(1,2))
par(mar=c(4,4,2,2))
bowlerAvgWktsGround("./kapil2.csv","Kapil")
bowlerAvgWktsOpposition("./kapil2.csv","Kapil")
dev.off()## null device
## 1B. Ian Botham
par(mfrow=c(1,2))
par(mar=c(4,4,2,2))
bowlerAvgWktsGround("./botham2.csv","Botham")
bowlerAvgWktsOpposition("./botham2.csv","Botham")
dev.off()## null device
## 1C. Imran Khan
par(mfrow=c(1,2))
par(mar=c(4,4,2,2))
bowlerAvgWktsGround("./imran2.csv","Imran")
bowlerAvgWktsOpposition("./imran2.csv","Imran")
dev.off()## null device
## 1D. Richard Hadlee
par(mfrow=c(1,2))
par(mar=c(4,4,2,2))
bowlerAvgWktsGround("./hadlee2.csv","Hadlee")
bowlerAvgWktsOpposition("./hadlee2.csv","Hadlee")
dev.off()## null device
## 1Relative bowling performance
It can be seen that Botham is the most effective wicket taker of the lot
frames <- list("./kapil2.csv","./botham2.csv","imran2.csv","hadlee2.csv")
names <- list("Kapil","Botham","Imran","Hadlee")
relativeBowlingPerf(frames,names)
Relative Economy Rate against wickets taken
Hadlee has the best overall economy rate followed by Kapil Dev
frames <- list("./kapil2.csv","./botham2.csv","imran2.csv","hadlee2.csv")
names <- list("Kapil","Botham","Imran","Hadlee")
relativeBowlingERODTT(frames,names)
Relative cumulative average wickets of bowlers in career
This plot confirms the wicket taking ability of Botham followed by Hadlee
frames <- list("./kapil2.csv","./botham2.csv","imran2.csv","hadlee2.csv")
names <- list("Kapil","Botham","Imran","Hadlee")
relativeBowlerCumulativeAvgWickets(frames,names)
Relative cumulative average economy rate of bowlers
frames <- list("./kapil2.csv","./botham2.csv","imran2.csv","hadlee2.csv")
names <- list("Kapil","Botham","Imran","Hadlee")
relativeBowlerCumulativeAvgEconRate(frames,names)
Moving average of wickets over career
This plot shows that Hadlee has the best economy rate followed by Kapil
par(mfrow=c(2,2))
par(mar=c(4,4,2,2))
bowlerMovingAverage("./kapil2.csv","Kapil")
bowlerMovingAverage("./botham2.csv","Botham")
bowlerMovingAverage("./imran2.csv","Imran")
bowlerMovingAverage("./hadlee2.csv","Hadlee")
dev.off()## null device
## 1Wickets forecast
par(mfrow=c(2,2))
par(mar=c(4,4,2,2))
bowlerPerfForecast("./kapil2.csv","Kapil")
bowlerPerfForecast("./botham2.csv","Botham")
bowlerPerfForecast("./imran2.csv","Imran")
bowlerPerfForecast("./hadlee2.csv","Hadlee")
dev.off()## null device
## 1Check bowler in-form, out-of-form
“**************************** Form status of Kapil ****************************\n\n
Population size: 198
Mean of population: 1.2 \n Sample size: 23 Mean of sample: 0.65 SD of sample: 0.83 \n\n
Null hypothesis H0 : Kapil ‘s sample average is within 95% confidence interval \n of population average\n
Alternative hypothesis Ha : Kapil ‘s sample average is below the 95% confidence\n interval of population average\n\n
Kapil ‘s Form Status: Out-of-Form because the p value: 0.002097 is less than alpha= 0.05 \n
“**************************** Form status of Botham ****************************\n\n
Population size: 166
Mean of population: 1.58 \n Sample size: 19 Mean of sample: 1.47 SD of sample: 1.12 \n\n
Null hypothesis H0 : Botham ‘s sample average is within 95% confidence interval \n of population average\n
Alternative hypothesis Ha : Botham ‘s sample average is below the 95% confidence\n interval of population average\n\n
Botham ‘s Form Status: In-Form because the p value: 0.336694 is greater than alpha= 0.05 \n
“**************************** Form status of Imran ****************************\n\n
Population size: 137
Mean of population: 1.23 \n Sample size: 16 Mean of sample: 0.81 SD of sample: 0.91 \n\n
Null hypothesis H0 : Imran ‘s sample average is within 95% confidence interval \n of population average\n
Alternative hypothesis Ha : Imran ‘s sample average is below the 95% confidence\n interval of population average\n\n
Imran ‘s Form Status: Out-of-Form because the p value: 0.041727 is less than alpha= 0.05 \n
“**************************** Form status of Hadlee ****************************\n\n
Population size: 100
Mean of population: 1.38 \n Sample size: 12 Mean of sample: 1.67 SD of sample: 1.37 \n\n
Null hypothesis H0 : Hadlee ‘s sample average is within 95% confidence interval \n of population average\n
Alternative hypothesis Ha : Hadlee ‘s sample average is below the 95% confidence\n interval of population average\n\n
Hadlee ‘s Form Status: In-Form because the p value: 0.761265 is greater than alpha= 0.05 \n *******************************************************************************************\n\n”
Key findings
Here are some key conclusions ODI batsmen
- Kapil Dev’s strike rate stands high above the other 3
- Imran Khan has the best cumulative average runs followed by Kapil
- Botham is the most effective wicket taker followed by Hadlee
- Hadlee is the most economical bowler and is followed by Kapil Dev
- For a hypothetical Balls Faced and Minutes at creases Kapil will score the most runs followed by Botham
- The moving average of indicates that the best is yet to come for Imran and Hadlee. Kapil and Botham were on the decline
Also see my other posts in R
- A primer on Qubits, Quantum gates abd Quantum operations
- Deblurring with OpenCV:Weiner filter reloaded
- Designing a Social Web Portal
- A crime map of India in R – Crimes against women
- Bend it like Bluemix, MongoDB with autoscaling – Part 2
- Mirror, mirror . the best batsman of them all?
For a full list of posts see Index of posts
Share:

IBM Data Science Experience: First steps with yorkr
Fresh, and slightly dizzy, from my foray into Quantum Computing with IBM’s Quantum Experience, I now turn my attention to IBM’s Data Science Experience (DSE).
I am on the verge of completing a really great 3 module ‘Data Science and Engineering with Spark XSeries’ from the University of California, Berkeley and I have been thinking of trying out some form of integrated delivery platform for performing analytics, for quite some time. Coincidentally, IBM comes out with its Data Science Experience. a month back. There are a couple of other collaborative platforms available for playing around with Apache Spark or Data Analytics namely Jupyter notebooks, Databricks, Data.world.
I decided to go ahead with IBM’s Data Science Experience as the GUI is a lot cooler, includes shared data sets and integrates with Object Storage, Cloudant DB etc, which seemed a lot closer to the cloud, literally! IBM’s DSE is an interactive, collaborative, cloud-based environment for performing data analysis with Apache Spark. DSE is hosted on IBM’s PaaS environment, Bluemix. It should be possible to access in DSE the plethora of cloud services available on Bluemix. IBM’s DSE uses Jupyter notebooks for creating and analyzing data which can be easily shared and has access to a few hundred publicly available datasets
Disclaimer: This article represents the author’s viewpoint only and doesn’t necessarily represent IBM’s positions, strategies or opinions
In this post, I use IBM’s DSE and my R package yorkr, for analyzing the performance of 1 ODI match (Aus-Ind, 2 Feb 2012) and the batting performance of Virat Kohli in IPL matches. These are my ‘first’ steps in DSE so, I use plain old “R language” for analysis together with my R package ‘yorkr’. I intend to do more interesting stuff on Machine learning with SparkR, Sparklyr and PySpark in the weeks and months to come.
You can checkout the Jupyter notebooks created with IBM’s DSE Y at Github – “Using R package yorkr – A quick overview’ and on NBviewer at “Using R package yorkr – A quick overview”
Working with Jupyter notebooks are fairly straight forward which can handle code in R, Python and Scala. Each cell can either contain code (Python or Scala), Markdown text, NBConvert or Heading. The code is written into the cells and can be executed sequentially. Here is a screen shot of the notebook.
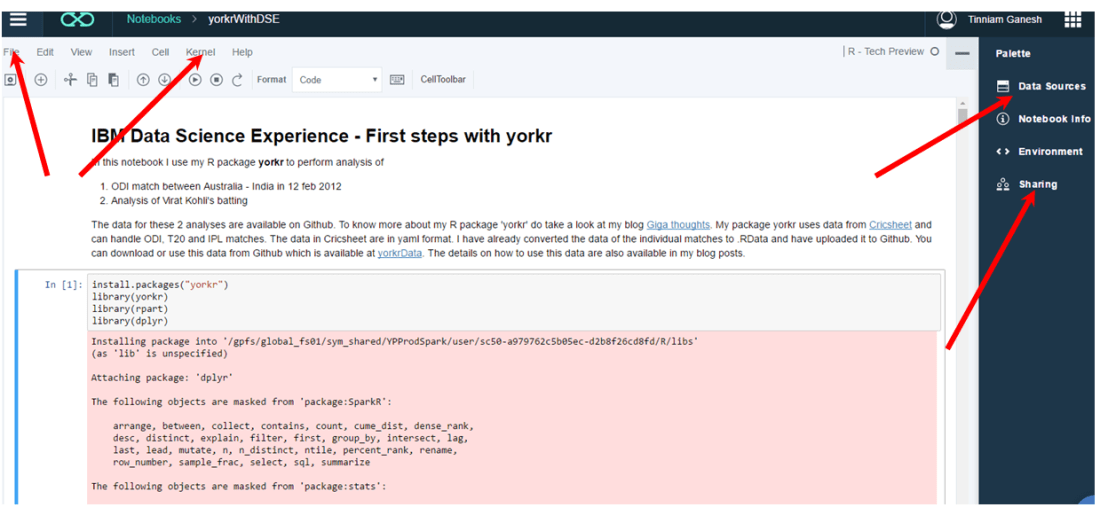
The ‘File’ menu can be used for ‘saving and checkpointing’ or ‘reverting’ to a checkpoint. The ‘kernel’ menu can be used to start, interrupt, restart and run all cells etc. Data Sources icon can be used to load data sources to your code. The data is uploaded to Object Storage with appropriate credentials. You will have to import this data from Object Storage using the credentials. In my notebook with yorkr I directly load the data from Github. You can use the sharing to share the notebook. The shared notebook has an extension ‘ipynb’. You can use the ‘Sharing’ icon to share the notebook. The shared notebook has an extension ‘ipynb’. You an import this notebook directly into your environment and can get started with the code available in the notebook.
You can import existing R, Python or Scala notebooks as shown below. My notebook ‘Using R package yorkr – A quick overview’ can be downloaded using the link ‘yorkrWithDSE’ and clicking the green download icon on top right corner.
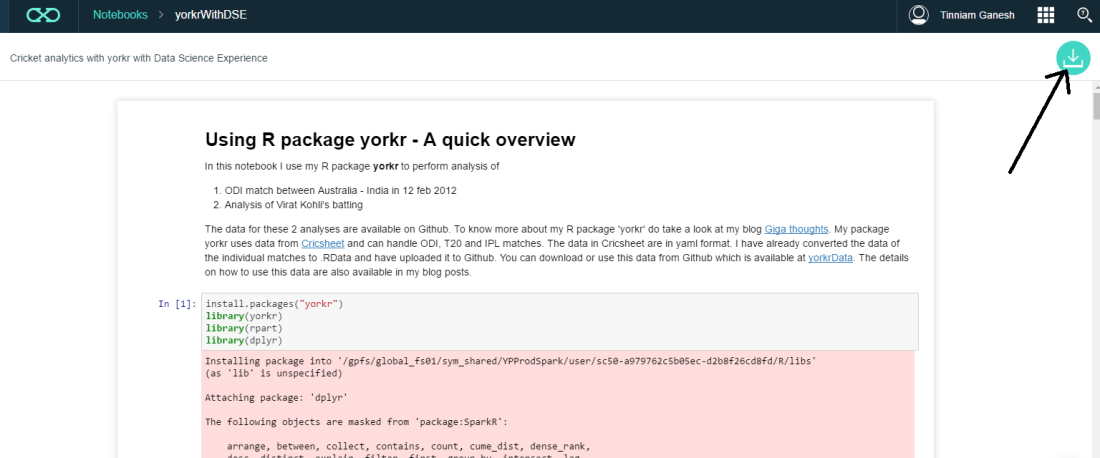
I have also uploaded the file to Github and you can download from here too ‘yorkrWithDSE’. This notebook can be imported into your DSE as shown below
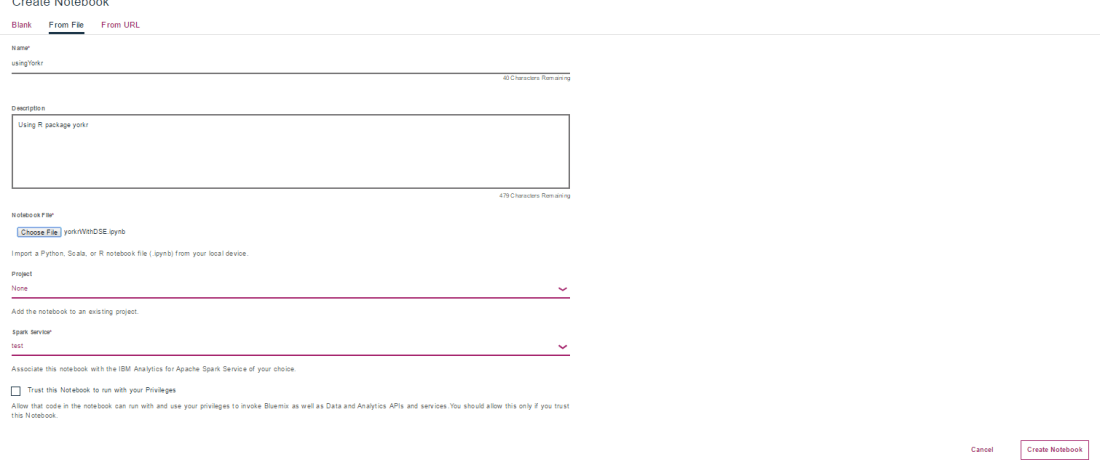
Jupyter notebooks have been integrated with Github and are rendered directly from Github. You can view my Jupyter notebook here – “Using R package yorkr – A quick overview’. You can also view it on NBviewer at “Using R package yorkr – A quick overview”
So there it is. You can download my notebook, import it into IBM’s Data Science Experience and then use data from ‘yorkrData” as shown. As already mentioned yorkrData contains converted data for ODIs, T20 and IPL. For details on how to use my R package yorkr please my posts on yorkr at “Index of posts”
Hope you have fun playing wit IBM’s Data Science Experience and my package yorkr.
I will be exploring IBM’s DSE in weeks and months to come in the areas of Machine Learning with SparkR,SparklyR or pySpark.
Watch this space!!!
Disclaimer: This article represents the author’s viewpoint only and doesn’t necessarily represent IBM’s positions, strategies or opinions
Also see
1. Introducing QCSimulator: A 5-qubit quantum computing simulator in R
2. Natural Processing Language : What would Shakespeare say?
3. Introducing cricket package yorkr:Part 1- Beaten by sheer pace!
4. A closer look at “Robot horse on a Trot! in Android”
5. Re-introducing cricketr! : An R package to analyze performances of cricketers
6. What’s up Watson? Using IBM Watson’s QAAPI with Bluemix, NodeExpress – Part 1
7. Deblurring with OpenCV: Wiener filter reloaded
To see all my posts check
Index of posts
Share:

Introducing QCSimulator: A 5-qubit quantum computing simulator in R
Introduction
My 5-qubit Quantum Computing Simulator,QCSimulator, is finally ready, and here it is! I have been able to successfully complete this simulator by working through a fair amount of material. To a large extent, the simulator is easy, if one understands how to solve the quantum circuit. However the theory behind quantum computing itself, is quite formidable, and I hope to scale this mountain over a period of time.
QCSimulator is now on CRAN!!!
The code for the QCSimulator package is also available at Github QCSimulator. This post has also been published at Rpubs as QCSimulator and can be downloaded as a PDF document at QCSimulator.pdf
Disclaimer: This article represents the author’s viewpoint only and doesn’t necessarily represent IBM’s positions, strategies or opinions
install.packages("QCSimulator")
library(QCSimulator)
library(ggplot2)1. Initialize the environment and set global variables
Here I initialize the environment with global variables and then display a few of them.
rm(list=ls())
#Call the init function to initialize the environment and create global variables
init()
# Display some of global variables in environment
ls()## [1] "I16" "I2" "I4" "I8" "q0_" "q00_" "q000_"
## [8] "q0000_" "q00000_" "q00001_" "q0001_" "q00010_" "q00011_" "q001_"
## [15] "q0010_" "q00100_" "q00101_" "q0011_" "q00110_" "q00111_" "q01_"
## [22] "q010_" "q0100_" "q01000_" "q01001_" "q0101_" "q01010_" "q01011_"
## [29] "q011_" "q0110_" "q01100_" "q01101_" "q0111_" "q01111_" "q1_"
## [36] "q10_" "q100_" "q1000_" "q10000_" "q10001_" "q1001_" "q10010_"
## [43] "q10011_" "q101_" "q1010_" "q10100_" "q10101_" "q1011_" "q10110_"
## [50] "q10111_" "q11_" "q110_" "q1100_" "q11000_" "q11001_" "q1101_"
## [57] "q11010_" "q11011_" "q111_" "q1110_" "q11100_" "q11101_" "q1111_"
## [64] "q11110_" "q11111_"#1. 2 x 2 Identity matrix
I2## [,1] [,2]
## [1,] 1 0
## [2,] 0 1#2. 8 x 8 Identity matrix
I8## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8]
## [1,] 1 0 0 0 0 0 0 0
## [2,] 0 1 0 0 0 0 0 0
## [3,] 0 0 1 0 0 0 0 0
## [4,] 0 0 0 1 0 0 0 0
## [5,] 0 0 0 0 1 0 0 0
## [6,] 0 0 0 0 0 1 0 0
## [7,] 0 0 0 0 0 0 1 0
## [8,] 0 0 0 0 0 0 0 1#3. Qubit |00>
q00_## [,1]
## [1,] 1
## [2,] 0
## [3,] 0
## [4,] 0#4. Qubit |010>
q010_## [,1]
## [1,] 0
## [2,] 0
## [3,] 1
## [4,] 0
## [5,] 0
## [6,] 0
## [7,] 0
## [8,] 0#5. Qubit |0100>
q0100_## [,1]
## [1,] 0
## [2,] 0
## [3,] 0
## [4,] 0
## [5,] 1
## [6,] 0
## [7,] 0
## [8,] 0
## [9,] 0
## [10,] 0
## [11,] 0
## [12,] 0
## [13,] 0
## [14,] 0
## [15,] 0
## [16,] 0#6. Qubit 10010
q10010_## [,1]
## [1,] 0
## [2,] 0
## [3,] 0
## [4,] 0
## [5,] 0
## [6,] 0
## [7,] 0
## [8,] 0
## [9,] 0
## [10,] 0
## [11,] 0
## [12,] 0
## [13,] 0
## [14,] 0
## [15,] 0
## [16,] 0
## [17,] 0
## [18,] 0
## [19,] 1
## [20,] 0
## [21,] 0
## [22,] 0
## [23,] 0
## [24,] 0
## [25,] 0
## [26,] 0
## [27,] 0
## [28,] 0
## [29,] 0
## [30,] 0
## [31,] 0
## [32,] 0The QCSimulator implements the following gates
- Pauli X,Y,Z, S,S’, T, T’ gates
- Rotation , Hadamard,CSWAP,Toffoli gates
- 2,3,4,5 qubit CNOT gates e.g CNOT2_01,CNOT3_20,CNOT4_13 etc
- Toffoli State,SWAPQ0Q1
2. To display the unitary matrix of gates
To check the unitary matrix of gates, we need to pass the appropriate identity matrix as an argument. Hence below the qubit gates require a 2 x 2 unitary matrix and the 2 & 3 qubit CNOT gates require a 4 x 4 and 8 x 8 identity matrix respectively
PauliX(I2)## [,1] [,2]
## [1,] 0 1
## [2,] 1 0Hadamard(I2)## [,1] [,2]
## [1,] 0.7071068 0.7071068
## [2,] 0.7071068 -0.7071068S1Gate(I2)## [,1] [,2]
## [1,] 1+0i 0+0i
## [2,] 0+0i 0-1iCNOT2_10(I4)## [,1] [,2] [,3] [,4]
## [1,] 1 0 0 0
## [2,] 0 0 0 1
## [3,] 0 0 1 0
## [4,] 0 1 0 0CNOT3_20(I8)## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8]
## [1,] 1 0 0 0 0 0 0 0
## [2,] 0 0 0 0 0 1 0 0
## [3,] 0 0 1 0 0 0 0 0
## [4,] 0 0 0 0 0 0 0 1
## [5,] 0 0 0 0 1 0 0 0
## [6,] 0 1 0 0 0 0 0 0
## [7,] 0 0 0 0 0 0 1 0
## [8,] 0 0 0 1 0 0 0 03. Compute the inner product of vectors
For example of phi = 1/2|0> + sqrt(3)/2|1> and si= 1/sqrt(2)(10> + |1>) then the inner product is the dot product of the vectors
phi = matrix(c(1/2,sqrt(3)/2),nrow=2,ncol=1)
si = matrix(c(1/sqrt(2),1/sqrt(2)),nrow=2,ncol=1)
angle= innerProduct(phi,si)
cat("Angle between vectors is:",angle)## Angle between vectors is: 154. Compute the dagger function for a gate
The gate dagger computes and displays the transpose of the complex conjugate of the matrix
TGate(I2)## [,1] [,2]
## [1,] 1+0i 0.0000000+0.0000000i
## [2,] 0+0i 0.7071068+0.7071068iGateDagger(TGate(I2))## [,1] [,2]
## [1,] 1+0i 0.0000000+0.0000000i
## [2,] 0+0i 0.7071068-0.7071068i5. Invoking gates in series
The Quantum gates can be chained by passing each preceding Quantum gate as the argument. The final gate in the chain will have the qubit or the identity matrix passed to it.
# Call in reverse order
# Superposition states
# |+> state
Hadamard(q0_)## [,1]
## [1,] 0.7071068
## [2,] 0.7071068# |-> ==> H x Z
PauliZ(Hadamard(q0_))## [,1]
## [1,] 0.7071068
## [2,] -0.7071068# (+i) Y ==> H x S
SGate(Hadamard(q0_))## [,1]
## [1,] 0.7071068+0.0000000i
## [2,] 0.0000000+0.7071068i# (-i)Y ==> H x S1
S1Gate(Hadamard(q0_))## [,1]
## [1,] 0.7071068+0.0000000i
## [2,] 0.0000000-0.7071068i# Q1 -- TGate- Hadamard
Q1 = Hadamard(TGate(I2))6. More gates in series
TGate of depth 2
The Quantum circuit for a TGate of Depth 2 is
Q0 — Hadamard-TGate-Hadamard-TGate-SGate-Measurement as shown in IBM’s Quantum Experience Composer
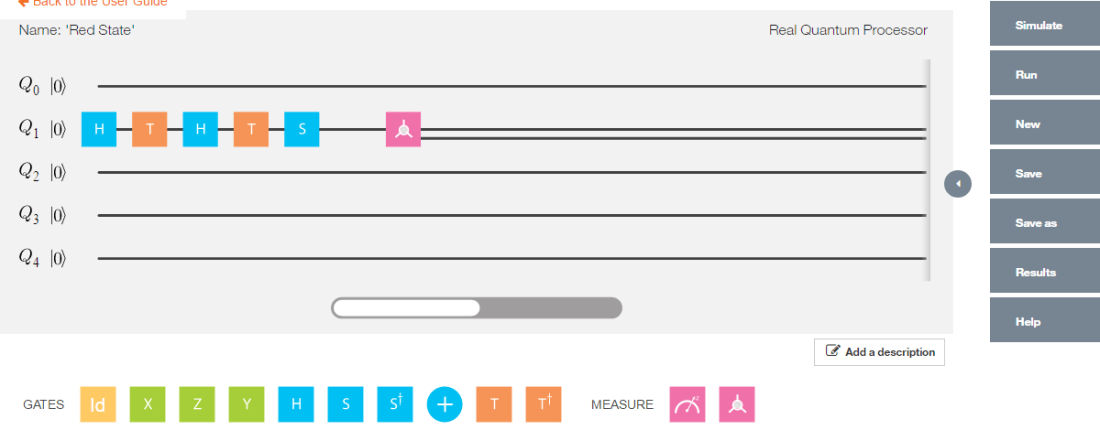
Implementing the quantum gates in series in reverse order we have
# Invoking this in reverse order we get
a = SGate(TGate(Hadamard(TGate(Hadamard(q0_)))))
result=measurement(a)
plotMeasurement(result)
7. Invoking gates in parallel
To obtain the results of gates in parallel we have to take the Tensor Product Note:In the TensorProduct invocation the Identity matrix is passed as an argument to get the unitary matrix of the gate. Q0 – Hadamard-Measurement Q1 – Identity- Measurement
#
a = TensorProd(Hadamard(I2),I2)
b = DotProduct(a,q00_)
plotMeasurement(measurement(b))
a = TensorProd(PauliZ(I2),Hadamard(I2))
b = DotProduct(a,q00_)
plotMeasurement(measurement(b))
8. Measurement
The measurement of a Quantum circuit can be obtained using the measurement function. Consider the following Quantum circuit
Q0 – H-T-H-T-S-H-T-H-T-H-T-H-S-Measurement where H – Hadamard gate, T – T Gate and S- S Gate
a = SGate(Hadamard(TGate(Hadamard(TGate(Hadamard(TGate(Hadamard(SGate(TGate(Hadamard(TGate(Hadamard(I2)))))))))))))
measurement(a)## 0 1
## v 0.890165 0.1098359. Plot measurement
Using the same example as above Q0 – H-T-H-T-S-H-T-H-T-H-T-H-S-Measurement where H – Hadamard gate, T – T Gate and S- S Gate we can plot the measurement
a = SGate(Hadamard(TGate(Hadamard(TGate(Hadamard(TGate(Hadamard(SGate(TGate(Hadamard(TGate(Hadamard(I2)))))))))))))
result = measurement(a)
plotMeasurement(result)
10. Evaluating a Quantum Circuit
The above procedures for evaluating a quantum gates in series and parallel can be used to evalute more complex quantum circuits where the quantum gates are in series and in parallel.
Here is an evaluation of one such circuit, the Bell ZQ state using the QCSimulator (from IBM’s Quantum Experience)

# 1st composite
a = TensorProd(Hadamard(I2),I2)
# Output of CNOT
b = CNOT2_01(a)
# 2nd series
c=Hadamard(TGate(Hadamard(SGate(I2))))
#3rd composite
d= TensorProd(I2,c)
# Output of 2nd composite
e = DotProduct(b,d)
#Action of quantum circuit on |00>
f = DotProduct(e,q00_)
result= measurement(f)
plotMeasurement(result)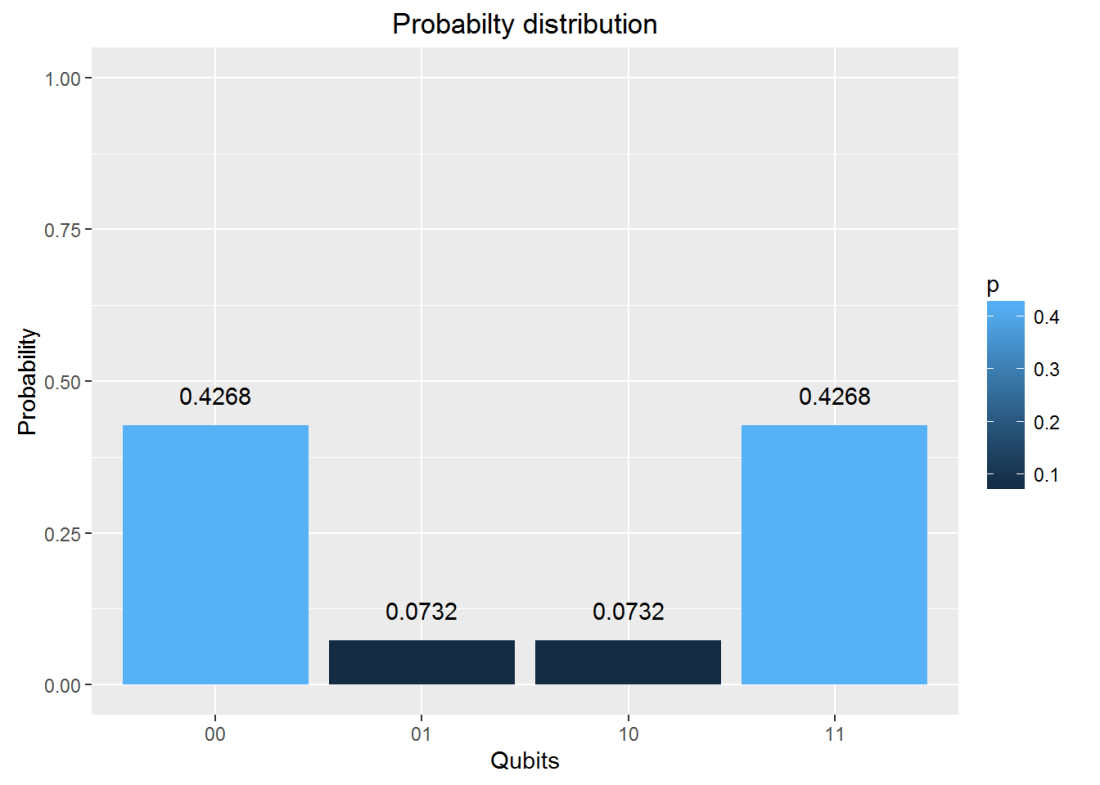
11. Toffoli State
This circuit for this comes from IBM’s Quantum Experience. This circuit is available in the package. This is how the state was constructed. This circuit is shown below

The implementation of the above circuit in QCSimulator is as below
# Computation of the Toffoli State
H=1/sqrt(2) * matrix(c(1,1,1,-1),nrow=2,ncol=2)
I=matrix(c(1,0,0,1),nrow=2,ncol=2)
# 1st composite
# H x H x H
a = TensorProd(TensorProd(H,H),H)
# 1st CNOT
a1= CNOT3_12(a)
# 2nd composite
# I x I x T1Gate
b = TensorProd(TensorProd(I,I),T1Gate(I))
b1 = DotProduct(b,a1)
c = CNOT3_02(b1)
# 3rd composite
# I x I x TGate
d = TensorProd(TensorProd(I,I),TGate(I))
d1 = DotProduct(d,c)
e = CNOT3_12(d1)
# 4th composite
# I x I x T1Gate
f = TensorProd(TensorProd(I,I),T1Gate(I))
f1 = DotProduct(f,e)
g = CNOT3_02(f1)
#5th composite
# I x T x T
h = TensorProd(TensorProd(I,TGate(I)),TGate(I))
h1 = DotProduct(h,g)
i = CNOT3_12(h1)
#6th composite
# I x H x H
j = TensorProd(TensorProd(I,Hadamard(I)),Hadamard(I))
j1 = DotProduct(j,i)
k = CNOT3_12(j1)
# 7th composite
# I x H x H
l = TensorProd(TensorProd(I,Hadamard(I)),Hadamard(I))
l1 = DotProduct(l,k)
m = CNOT3_12(l1)
n = CNOT3_02(m)
#8th composite
# T x H x T1
o = TensorProd(TensorProd(TGate(I),Hadamard(I)),T1Gate(I))
o1 = DotProduct(o,n)
p = CNOT3_02(o1)
result = measurement(p)
plotMeasurement(result)
12. GHZ YYX measurement
Here is another Quantum circuit, namely the entangled GHZ YYX state. This is

and is implemented in QCSimulator as
# Composite 1
a = TensorProd(TensorProd(Hadamard(I2),Hadamard(I2)),PauliX(I2))
b= CNOT3_12(a)
c= CNOT3_02(b)
# Composite 2
d= TensorProd(TensorProd(Hadamard(I2),Hadamard(I2)),Hadamard(I2))
e= DotProduct(d,c)
#Composite 3
f= TensorProd(TensorProd(S1Gate(I2),S1Gate(I2)),Hadamard(I2))
g= DotProduct(f,e)
#Composite 4
i= TensorProd(TensorProd(Hadamard(I2),Hadamard(I2)),I2)
j = DotProduct(i,g)
result=measurement(j)
plotMeasurement(result)
Conclusion
The 5 qubit Quantum Computing Simulator is now fully functional. I hope to add more gates and functionality in the months to come.
Feel free to install the package from Github and give it a try.
Disclaimer: This article represents the author’s viewpoint only and doesn’t necessarily represent IBM’s positions, strategies or opinions
References
- IBM’s Quantum Experience
- Quantum Computing in Python by Dr. Christine Corbett Moran
- Lecture notes-1
- Lecture notes-2
- Quantum Mechanics and Quantum Computationat edX- UC, Berkeley
My other posts on Quantum Computing
- Venturing into IBM’s Quantum Experience 2.Going deeper into IBM’s Quantum Experience!
- A primer on Qubits, Quantum gates and Quantum Operations
- Exploring Quantum Gate operations with QCSimulator
- Taking a closer look at Quantum gates and their operations
You may also like
For more posts on other topics like Cloud Computing, IBM Bluemix, Distributed Computing, OpenCV, R, cricket please check my Index of posts
Share:

Taking a closer look at Quantum gates and their operations
This post is a continuation of my earlier post ‘Exploring Quantum gate operations with QCSimulator’. Here I take a closer look at more quantum gates and their operations, besides implementing these new gates in my Quantum Computing simulator, the QCSimulator in R.
Disclaimer: This article represents the author’s viewpoint only and doesn’t necessarily represent IBM’s positions, strategies or opinions
In quantum circuits, gates are unitary matrices which operate on 1,2 or 3 qubit systems which are represented as below
1 qubit
|0> = 
2 qubits
|0> 
|0>
|1>
|1>
3 qubits
|0>
|0>
|0>
…
…
|1>
Hence single qubit is represented as 2 x 1 matrix, 2 qubit as 4 x 1 matrix and 3 qubit as 8 x 1 matrix




1) Composing Quantum gates in series
When quantum gates are connected in a series. The overall effect of the these quantum gates in series is obtained my taking the dot product of the unitary gates in reverse. For e.g.
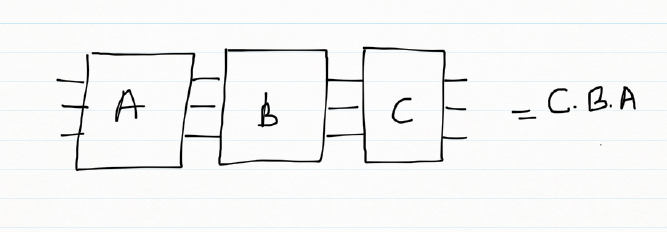
In the following picture the effect of the quantum gates A,B,C is the dot product of the gates taken reverse order
result = C . B . A
This overall action of the 3 quantum gates can be represented by a single ‘transfer’ matrix which is the dot product of the gates
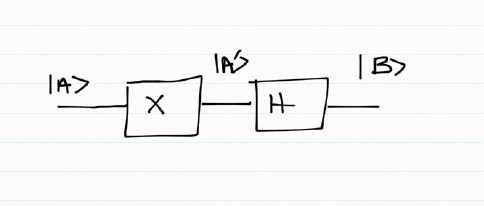
If we had a Pauli X followed by a Hadamard gate the combined effect of these gates on the inputs can be deduced by constructing a truth table
| Input | Pauli X – Output A’ | Hadamard – Output B |
| |0> | |1> | 1/√2(|0> – |1>) |
| |1> | |0> | 1/√2(|0> + |1>) |
Or
|0> -> 1/√2(|0> – |1>)
|1> -> 1/√2(|0> + |1>)
which is
Therefore the ‘transfer’ matrix can be written as
T = 1/√2



2)Quantum gates in parallel
When quantum gates are in parallel then the composite effect of the gates can be obtained by taking the tensor product of the quantum gates.
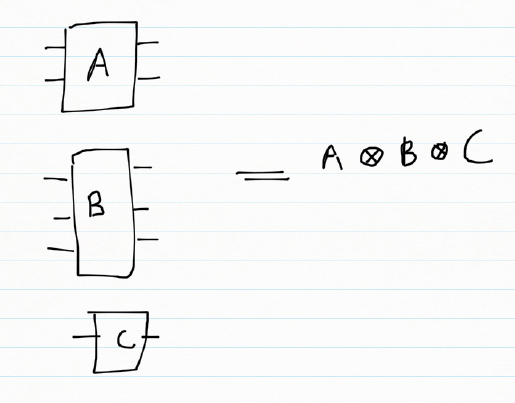
If we consider the combined action of a Pauli X gate and a Hadamard gate in parallel
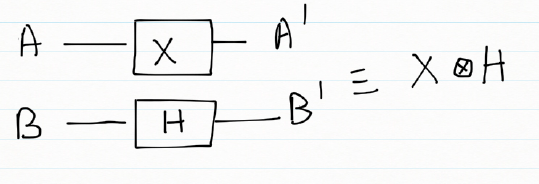
| A | B | A’ | B’ |
| |0> | |0> | |1> | 1/√2(|0> + |1>) |
| |0> | |1> | |1> | 1/√2(|0> – |1>) |
| |1> | |0> | |0> | 1/√2(|0> + |1>) |
| |1> | |1> | |0> | 1/√2(|0> – |1>) |
Or
|00> => |1>
|01> => |1>
|10> => |0>
|11> => |0>
|00> = 
|01> = 
|10> = 
|11> = 




Here are more Quantum gates
a) Rotation gate
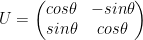
b) Toffoli gate
The Toffoli gate flips the 3rd qubit if the 1st and 2nd qubit are |1>
| Toffoli gate | |
| Input | Output |
| |000> | |000> |
| |001> | |001> |
| |010> | |010> |
| |011> | |011> |
| |100> | |100> |
| |101> | |101> |
| |110> | |111> |
| |111> | |110> |
c) Fredkin gate
The Fredkin gate swaps the 2nd and 3rd qubits if the 1st qubit is |1>
| Fredkin gate | |
| Input | Output |
| |000> | |000> |
| |001> | |001> |
| |010> | |010> |
| |011> | |011> |
| |100> | |100> |
| |101> | |110> |
| |110> | |101> |
| |111> | |111> |
d) Controlled U gate
A controlled U gate can be represented as
controlled U = 
where U =

e) Controlled Pauli gates
Controlled Pauli gates are created based on the following identities. The CNOT gate is a controlled Pauli X gate where controlled U is a Pauli X gate and matches the CNOT unitary matrix. Pauli gates can be constructed using
a) H x X x H = Z &
H x H = I
b) S x X x S1
S x S1 = I
the controlled Pauli X, Y , Z are contructed using the CNOT for the controlled X in the above identities
In general a controlled Pauli gate can be created as below
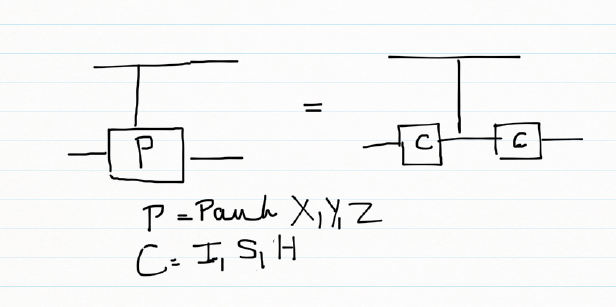
f) CPauliX
Here C is the 2 x2 Identity matrix. Simulating this in my QCSimulator
CPauliX I=matrix(c(1,0,0,1),nrow=2,ncol=2)
# Compute 1st composite
a = TensorProd(I,I)
b = CNOT2_01(a)
# Compute 1st composite
c = TensorProd(I,I)
#Take dot product
d = DotProduct(c,b)
#Take dot product with qubit
e = DotProduct(d,q)
e
}
Implementing the above with I, S, H gives Pauli X, Y and Z as seen below
library(QCSimulator)
I4=matrix(c(1,0,0,0,
0,1,0,0,
0,0,1,0,
0,0,0,1),nrow=4,ncol=4)
#Controlled Pauli X
CPauliX(I4)## [,1] [,2] [,3] [,4]
## [1,] 1 0 0 0
## [2,] 0 1 0 0
## [3,] 0 0 0 1
## [4,] 0 0 1 0#Controlled Pauli Y
CPauliY(I4)## [,1] [,2] [,3] [,4]
## [1,] 1+0i 0+0i 0+0i 0+0i
## [2,] 0+0i 1+0i 0+0i 0+0i
## [3,] 0+0i 0+0i 0+0i 0-1i
## [4,] 0+0i 0+0i 0+1i 0+0i#Controlled Pauli Z
CPauliZ(I4)## [,1] [,2] [,3] [,4]
## [1,] 1 0 0 0
## [2,] 0 1 0 0
## [3,] 0 0 1 0
## [4,] 0 0 0 -1g) CSWAP gate

q00=matrix(c(1,0,0,0),nrow=4,ncol=1)
q01=matrix(c(0,1,0,0),nrow=4,ncol=1)
q10=matrix(c(0,0,1,0),nrow=4,ncol=1)
q11=matrix(c(0,0,0,1),nrow=4,ncol=1)
CSWAP(q00)## [,1]
## [1,] 1
## [2,] 0
## [3,] 0
## [4,] 0#Swap qubits
CSWAP(q01)## [,1]
## [1,] 0
## [2,] 0
## [3,] 1
## [4,] 0#Swap qubits
CSWAP(q10)## [,1]
## [1,] 0
## [2,] 1
## [3,] 0
## [4,] 0CSWAP(q11)## [,1]
## [1,] 0
## [2,] 0
## [3,] 0
## [4,] 1h) Toffoli state
The Toffoli state creates a 3 qubit entangled state 1/2(|000> + |001> + |100> + |111>)
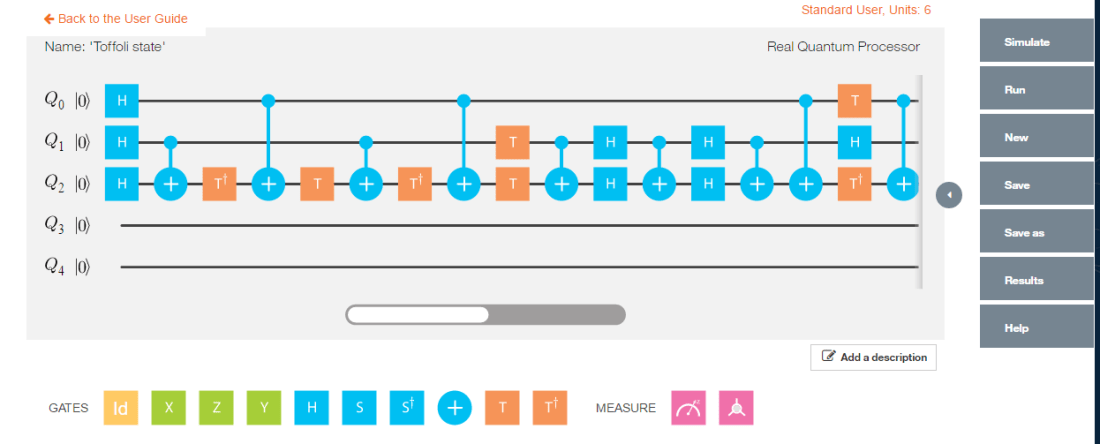
Simulating the Toffoli state in IBM Quantum Experience we get

h) Implementation of Toffoli state in QCSimulator
#ToffoliState
# Computation of the Toffoli State
H=1/sqrt(2) * matrix(c(1,1,1,-1),nrow=2,ncol=2)
I=matrix(c(1,0,0,1),nrow=2,ncol=2)
# 1st composite
# H x H x H
a = TensorProd(TensorProd(H,H),H)
# 1st CNOT
a1= CNOT3_12(a)
# 2nd composite
# I x I x T1Gate
b = TensorProd(TensorProd(I,I),T1Gate(I))
b1 = DotProduct(b,a1)
c = CNOT3_02(b1)
# 3rd composite
# I x I x TGate
d = TensorProd(TensorProd(I,I),TGate(I))
d1 = DotProduct(d,c)
e = CNOT3_12(d1)
# 4th composite
# I x I x T1Gate
f = TensorProd(TensorProd(I,I),T1Gate(I))
f1 = DotProduct(f,e)
g = CNOT3_02(f1)
#5th composite
# I x T x T
h = TensorProd(TensorProd(I,TGate(I)),TGate(I))
h1 = DotProduct(h,g)
i = CNOT3_12(h1)
#6th composite
# I x H x H
j = TensorProd(TensorProd(I,Hadamard(I)),Hadamard(I))
j1 = DotProduct(j,i)
k = CNOT3_12(j1)
# 7th composite
# I x H x H
l = TensorProd(TensorProd(I,Hadamard(I)),Hadamard(I))
l1 = DotProduct(l,k)
m = CNOT3_12(l1)
n = CNOT3_02(m)
#8th composite
# T x H x T1
o = TensorProd(TensorProd(TGate(I),Hadamard(I)),T1Gate(I))
o1 = DotProduct(o,n)
p = CNOT3_02(o1)
result = measurement(p)
plotMeasurement(result)
The measurement is identical to the that of IBM Quantum Experience
Conclusion: This post looked at more Quantum gates. I have implemented all the gates in my QCSimulator which I hope to release in a couple of months.
Disclaimer: This article represents the author’s viewpoint only and doesn’t necessarily represent IBM’s positions, strategies or opinions
References
1. http://www1.gantep.edu.tr/~koc/qc/chapter4.pdf
2. http://iontrap.umd.edu/wp-content/uploads/2016/01/Quantum-Gates-c2.pdf
3. https://quantumexperience.ng.bluemix.net/
Also see
1. Venturing into IBM’s Quantum Experience
2. Going deeper into IBM’s Quantum Experience!
3. A primer on Qubits, Quantum gates and Quantum Operations
4. Exploring Quantum gate operations with QCSimulator
Take a look at my other posts at
1. Index of posts
Share:

Exploring Quantum Gate operations with QCSimulator
Introduction: Ever since I was initiated into Quantum Computing, through IBM’s Quantum Experience I have been hooked. My initial encounter with domain made me very excited and all wound up. The reason behind this, I think, is because there is an air of mystery around ‘Quantum’ anything. After my early rush with the Quantum Experience, I have deliberately slowed down to digest the heady stuff.
This post also includes my early prototype of a Quantum Computing Simulator( QCSimulator) which I am creating in R. I hope to have a decent Quantum Computing simulator available, in the next couple of months. The ideas for this simulator are based on IBM’s Quantum Experience and the lectures on Quantum Mechanics and Quantum Computation by Prof Umesh Vazirani from University of California at Berkeley at edX. This calls to this simulator have been included in R Markdown file and has been published at RPubs as Quantum Computing Simulator
Disclaimer: This article represents the author’s viewpoint only and doesn’t necessarily represent IBM’s positions, strategies or opinions
In this post I explore quantum gate operations
A) Quantum Gates
Quantum gates are represented as a n x n unitary matrix. In mathematics, a complex square matrix U is unitary if its conjugate transpose Uǂ is also its inverse – that is, if
U ǂU =U U ǂ=I
a) Clifford Gates
The following gates are known as Clifford Gates and are represented as the unitary matrix below
1. Pauli X

2.Pauli Y
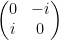
3. Pauli Z

4. Hadamard
1/√2
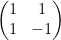
5. S Gate
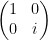
6. S1 Gate

7. CNOT

b) Non-Clifford Gate
The following are the non-Clifford gates
1. Toffoli Gate
T =
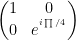
2. Toffoli1 Gate
T1 =
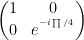
B) Evolution of a 1 qubit Quantum System
The diagram below shows how a 1 qubit system evolves on the application of Quantum Gates.

C) Evolution of a 2 Qubit System
The following diagram depicts the evolution of a 2 qubit system. The 4 different maximally entangled states can be obtained by using a Hadamard and a CNOT gate to |00>, |01>, |10> & |11> resulting in the entangled states Φ+, Ψ+, Φ–, Ψ– respectively

D) Verifying Unitary’ness
XXǂ = XǂX= I
TTǂ = TǂT=I
SSǂ = SǂS=I
The Uǂ function in the simulator is
Uǂ = GateDagger(U)
E) A look at some Simulator functions
The unitary functions for the Clifford and non-Clifford gates have been implemented functions. The unitary functions can be chained together by invoking each successive Gate as argument to the function.
1. Creating the dagger function
HDagger = GateDagger(Hadamard)
HDagger x Hadamard
TDagger = GateDagger(TGate)
TDagger x TGate
H## [,1] [,2]
## [1,] 0.7071068 0.7071068
## [2,] 0.7071068 -0.7071068HDagger = GateDagger(H)
HDagger## [,1] [,2]
## [1,] 0.7071068 0.7071068
## [2,] 0.7071068 -0.7071068HDagger %*% H## [,1] [,2]
## [1,] 1 0
## [2,] 0 1T## [,1] [,2]
## [1,] 1+0i 0.0000000+0.0000000i
## [2,] 0+0i 0.7071068+0.7071068iTDagger = GateDagger(T)
TDagger## [,1] [,2]
## [1,] 1+0i 0.0000000+0.0000000i
## [2,] 0+0i 0.7071068-0.7071068iTDagger %*% T## [,1] [,2]
## [1,] 1+0i 0+0i
## [2,] 0+0i 1+0i2. Angle between 2 vectors – Inner product
The angle between 2 vectors can be obtained by taking the inner product between the vectors
#1. a is the diagonal vector 1/2 |0> + 1/2 |1> and b = q0 = |0>
diagonal <- matrix(c(1/sqrt(2),1/sqrt(2)),nrow=2,ncol=1)
q0=matrix(c(1,0),nrow=2,ncol=1)
innerProduct(diagonal,q0)## [,1]
## [1,] 45#2. a = 1/2|0> + sqrt(3)/2|1> and b= 1/sqrt(2) |0> + 1/sqrt(2) |1>
a = matrix(c(1/2,sqrt(3)/2),nrow=2,ncol=1)
b = matrix(c(1/sqrt(2),1/sqrt(2)),nrow=2,ncol=1)
innerProduct(a,b)## [,1]
## [1,] 153. Chaining Quantum Gates
For e.g.
H x q0
S x H x q0 == > SGate(Hadamard(q0))
Or
H x S x S x H x q0 == > Hadamard(SGate(SGate(Hadamard))))
# H x q0
Hadamard(q0)## [,1]
## [1,] 0.7071068
## [2,] 0.7071068# S x H x q0
SGate(Hadamard(q0))## [,1]
## [1,] 0.7071068+0.0000000i
## [2,] 0.0000000+0.7071068i# H x S x S x H x q0
Hadamard(SGate(SGate(Hadamard(q0))))## [,1]
## [1,] 0+0i
## [2,] 1+0i# S x T x H x T x H x q0
SGate(TGate(Hadamard(TGate(Hadamard(q0)))))## [,1]
## [1,] 0.8535534+0.3535534i
## [2,] 0.1464466+0.3535534i4. Measurement
The output of Quantum Gate operations can be measured with
measurement(a)
measurement(q0)
measurement(Hadamard(q0))
a=SGate(TGate(Hadamard(TGate(Hadamard(I)))))
measurement(a)
measurement(SGate(TGate(Hadamard(TGate(Hadamard(I))))))
measurement(q0)## 0 1
## v 1 0measurement(Hadamard(q0))## 0 1
## v 0.5 0.5a <- SGate(TGate(Hadamard(TGate(Hadamard(q0)))))
measurement(a)## 0 1
## v 0.8535534 0.14644665. Plot the measurements
plotMeasurement(q1)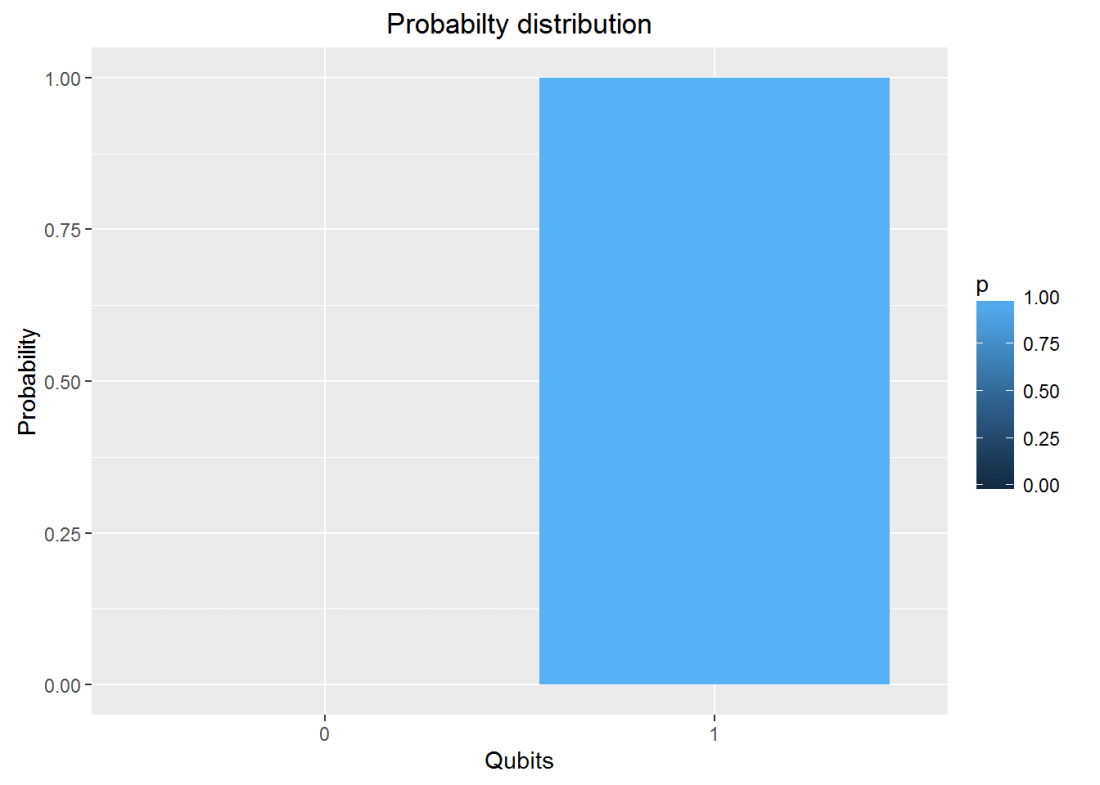
plotMeasurement(Hadamard(q0))
a = measurement(SGate(TGate(Hadamard(TGate(Hadamard(q0))))))
plotMeasurement(a)
6. Using the QCSimulator for one of the Bell tests
Here I compute the following measurement of Bell state ZW with the QCSimulator

When this is simulated on IBM’s Quantum Experience the result is

Below I simulate the same on my R based QCSimulator
# Compute the effect of the Composite H gate with the Identity matrix (I)
a=kronecker(H,I,"*")
a## [,1] [,2] [,3] [,4]
## [1,] 0.7071068 0.0000000 0.7071068 0.0000000
## [2,] 0.0000000 0.7071068 0.0000000 0.7071068
## [3,] 0.7071068 0.0000000 -0.7071068 0.0000000
## [4,] 0.0000000 0.7071068 0.0000000 -0.7071068# Compute the applcation of CNOT on this result
b = CNOT(a)
b## [,1] [,2] [,3] [,4]
## [1,] 0.7071068 0.0000000 0.7071068 0.0000000
## [2,] 0.0000000 0.7071068 0.0000000 0.7071068
## [3,] 0.0000000 0.7071068 0.0000000 -0.7071068
## [4,] 0.7071068 0.0000000 -0.7071068 0.0000000# Obtain the result of CNOT on q00
c = b %*% q00
c## [,1]
## [1,] 0.7071068
## [2,] 0.0000000
## [3,] 0.0000000
## [4,] 0.7071068# Compute the effect of the composite HxTxHxS gates and the Identity matrix(I) for measurement
d=Hadamard(TGate(Hadamard(SGate(I))))
e=kronecker(I, d,"*")
# Applying the composite gate on the output 'c'
f = e %*% c
# Measure the output
g <- measurement(f)
g## 00 01 10 11
## v 0.4267767 0.0732233 0.0732233 0.4267767#Plot the measurement
plotMeasurement(g)
aa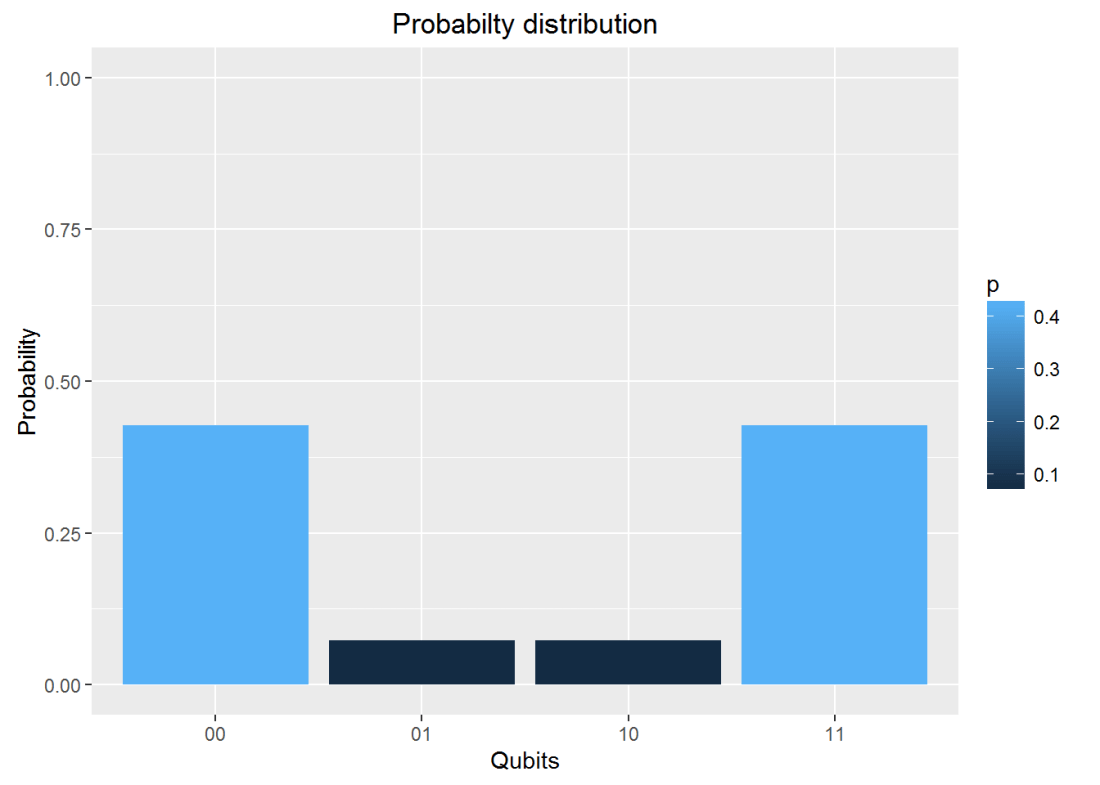
which is exactly the result obtained with IBM’s Quantum Experience!
Conclusion : In this post I dwell on 1 and 2-qubit quantum gates and explore their operation. I have started to construct a R based Quantum Computing Simulator. I hope to have a reasonable simulator in the next couple of months. Let’s see.
Watch this space!
Disclaimer: This article represents the author’s viewpoint only and doesn’t necessarily represent IBM’s positions, strategies or opinions
References
1. IBM Quantum Experience – User Guide
2. Quantum Mechanics and Quantum Conputing, UC Berkeley
Also see
1. Venturing into IBM’s Quantum Experience
2. Going deeper into IBM’s Quantum Experience!
3. A primer on Qubits, Quantum gates and Quantum Operations
You may also like
1. My TEDx talk on the “Internet of Things”
2. Experiments with deblurring using OpenCV
3. TWS-5: Google’s Page Rank: Predicting the movements of a random web walker
For more posts see
Index of posts
Share:

A primer on Qubits, Quantum gates and Quantum Operations
Introduction: After my initial encounter with IBM’s Quantum Experience, and my playing around with qubits, quantum gates and trying out the Bell experiment I can now say that I am fairly hooked to quantum computing.
So, I decided that before going any further, that I needed to spend a little time more, getting to know more about the basics of Dirac’s bra-ket notation, qubits and ensuring that my knowledge is properly “chunked” ( See Learning to Learn: Powerful mental tools to master tough subjects, a really good course!!)
So, I started to look around for material on Quantum Computing, and finally landed on the classic course “Quantum Mechanics and Quantum Computing”, from University of California, Berkeley by Prof Umesh V Vazirani at edX. I have started to audit the course (listen in, without doing the assignments). The Prof is unbelievably good, and makes the topic both interesting and absorbing. This post is based on my notes of week 1 & 2 lectures. I have tried to articulate as best as I can, what I have understood of the lectures, though I would strongly recommend you to, at least audit the archived course. By the way, I also had to refresh my knowledge of basic trigonometry and linear algebra. My knowledge of the basics of matrix manipulation, vectors etc. were buried deep within the sands of time. Luckily for me, they were reasonably intact.
A) Quantum states
A hydrogen atom has 1 electron in orbit. The electron can be either in the idle state or in the excited state. We can represent the idle state with |0> and the excited state with |1>, which is Dirac’s ‘ket’ notation.

This electron will be in a superposition state which is represented by
Ψ = α |0> + β |1> where α & β are complex numbers and obey | α|2 + | β|2 = 1
For e.g. we could have the superposition state
It can be seen that | α|2 = 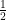
For a complex number α = a+ bi == > | α| =

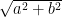
B) Measurement
However, when the electron or the qubit is measured, the state of superposition collapses to either |0> or |1> with the following probability’s
The resulting state is
|0> with probability | α|2
|1> with probability | β |2
And | α|2 + | β|2 = 1 because the sum of the probabilities must add up to 1 i.e.

C) Geometric interpretation
Let us consider a qubit that is in a superposition state
Ψ = α |0> + β |1> where α & β are complex numbers and obey | α|2 + | β|2 = 1
We can write this as a vector 
It can be seen that if
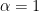

and
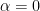

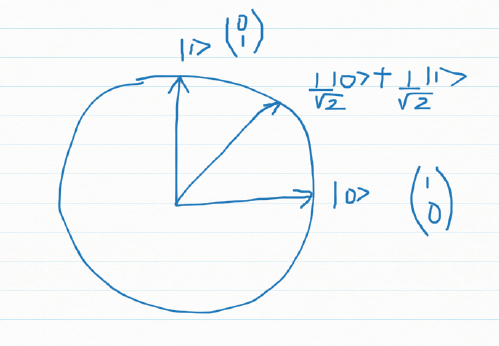


Measuring a qubit in standard basis
If we represent the qubit geometrically then the superposition can be represented as a vector which makes an angle 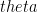
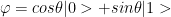
Measuring this 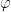
The output is is |0> with probability 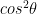
|1> with probability

D) Measuring a qubit in any basis
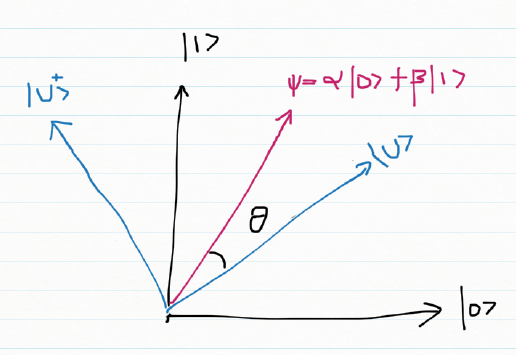
The qubit can be measured in any arbitrary basis. For e.g. if
Ψ = α |0> + β |1> and we have the diagonal basis
|u>| and |u’> as shown and Ψ makes an angle 
|u> with probability cos2Θ
And |u’> with probability sin2Θ
E) K Qubit system
Let us assume that we have a Quantum System with k qubits
|0>, |1>, |2>… |k-1>
The qubit will be in a superimposed state
Ψ = α0 |0>+ α1 |1> + α2|2> + … + αk-1 |k-1>
Where αj is a complex vector with the property ∑ αj = 1
Here Ψ is a unit vector in a K dimensional complex vector space, known as Hilbert Space
For e.g. a 3 qubit quantum system
Then P(0) = ½ P(1) = ¼ and P(2) = ¼ ∑Pj = 1

We could also write
Or
Ψ = α0 |0>+ α1 |1> + α2|2> + … + αk-1 |k-1>
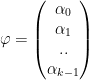
F) Measuring the angle between 2 complex vectors
To measure the angle between 2 complex vectors
And
we need to take the inner product of the complex conjugate of the 1st vector and the 2nd
cosΘ = inner product =>



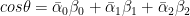
For e.g.
If 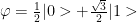
And

Then the angle between these 2 vectors are obtained by taking the inner product
cosΘ = ½ * 1/√2 + √3/2 * ½
G) Measuring Ψ in |+> or |-> basis
For e.g. if
Then we can specify/measure Ψ in |+> or |-> basis as follow
|+> = 1/√2(|0> + |1>) and |-> = 1/√2(|0> – |1>)
Or |0> = 1/√2(|+> + |->) and |1> = 1/√2(|+> – |->)
We can write
Ψ= α|+> + β|->
Substituting for |0> and |1> in (A) we get

H) Quantum gates
I) Clifford gates
Pauli gates
a) Pauli X
The Pauli X gate does a bit flip
|0> ==> X|0> ==> |1>
|1> ==> X|1> ==> |0>
and is represented
b) Pauli Z
This gates does a phase flip and is represented as the 2 x 2 unitary matrix
c) Pauli Y
The Pauli operator Y does both a bit and a phase flip. The Y operator is represented as
K) Superposition gates
Superposition is the concept that adding quantum states together results in a new quantum state. There are 3 gates that perform superposition of qubits the H, S and S’ gate.
a) H gate (Hadamard gate)
The H gate, also known as the Hadamard Gate when applied |0> state results in the qubit being half the time in |0> and the other half in |1>
The H gate can be represented as
1/√2
b) S gate
The S gate can be represented as
c) S’ gate
And the S’ gate is
L) Non-Clifford Gates
The quantum gates discussed in my earlier post Pauli X, Y, Z, H, S and S1 are members of a special group of gates known as the ‘Clifford group’.
The non-Clifford gates, discussed are the T and Tǂ gates
These are given by
T =
Tǂ =

M) 2 qubit system
A 2 qubit system
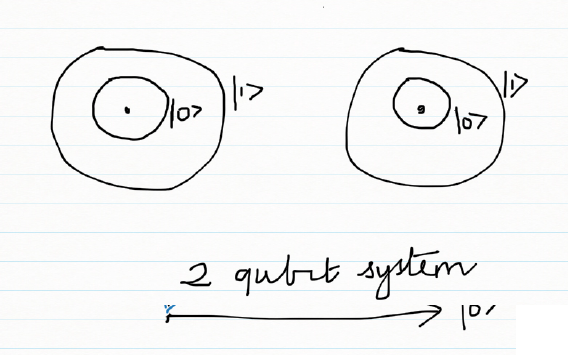
A 2 qubit system is a superposition of all possible 2 qubit states. A 2 qubit system and can be represented as
Ψ = α00 |00> + α01 |01> + α10 |10> + α11 |11>
Measuring the 2 qubit system, as earlier, results in the collapse of the superposition and the result is one of 4 qubit states. The probability of the measure state is the square of the amplitude | αij|2
N) Entanglement
A 2 qubit system in which we have
Ψ = α0 |0> + α1 |1> and Φ= β0 |0> + β1 |1> the superimposed state is obtained by taking the tensor product of the 2 qubits
Where 

The state
Ψ = 1/√2|00> + 1/√2|11>
Is called an ‘entangled’ state because it cannot be reduced to a product of 2 vectors
N) 2 qubit gates
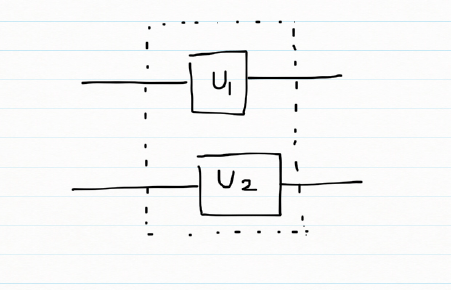
A 2 qubit system is a superposition of all possible 2 qubit states. A 2 qubit system and can be represented as
Ψ = α00 |00> + α01 |01> + α10 |10> + α11 |11>
Measuring the 2 qubit system, as earlier, results in the collapse of the superposition and the result is one of 4 qubit states. The probability of the measure state is the square of the amplitude | αij|2
More specifically a 2 qubit system in which we have
Ψ = α0 |0> + α1 |1> and Φ= β0 |0> + β1 |1> the superimposed state is obtained by taking the tensor product of the 2 qubits
Where
The state
Ψ = 1/√2|00> + 1/√2|11>
Is called an ‘entangled’ state because it cannot be reduced to a product of 2 vectors
A quantum gate is a 2 x 2 unitary matrix U such that
α0 |0> + α1 |1> == > Quantum Gate == > β0|0> + β1 |1>
Unitary functions: In mathematics, a complex square matrix U is unitary if its conjugate transpose U* is also its inverse
If
U=
And U* =
Then
UU* = I where I is the Identity matrix
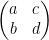

2 qubit gates is 4 x 4 unitary matrix
For a 2 qubit that is in the superposition state
Ψ = α00 |00> + α01 |01> + α10 |10> + α11 |11>
A 2 qubit gate’s operation on Ψ is


One important 2 qubit gate is the CNOT gate which is shown below
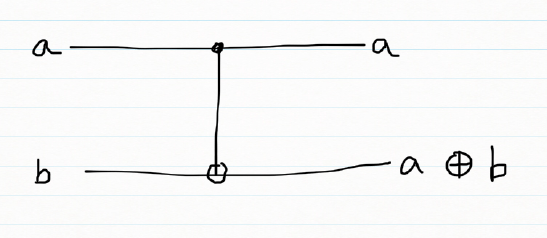
The CNOT gate is represented by the following unitary matrix

If 2 2×2 qubit gates were applied to 2 qubits the composite gate would be Tensor product of the 2 matrices
u1 =
u2 =
then
U=
U =
The above product is also known as the Kronecker product
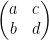



O) Tensor product of 2 qubits
Ψ = α0 |0> + α1 |1> and Φ= β0 |0> + β1 |1>
$latex \varphi \otimes \phi= α0 β0|0>|0> + α0 β1|0>|1> + α1 β0|1>|0> + α1 β1|1>|1>
= α0 β0|00> + α0 β1|01> + α1 β0|10> + α1 β1|11>
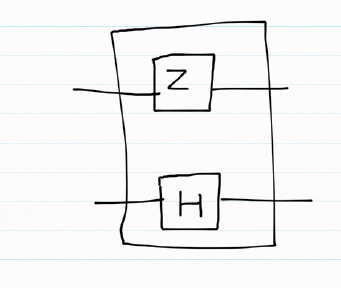
If a Z gate and a Hadamard gate H were applied on 2 qubits, it is interest to know what the resulting composite gate would be.
Z = 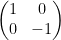
The composite gate is obtained by the tensor product of
Hence the result of the composite gate is
=
=
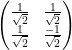
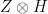


which is the entangled state.
Conclusion: This post includes most of the required basics to get started on Quantum Computing. I will probably add another post detailing the operations of the Quantum Gates on qubits.
Note:
1.The equations and matrices have been created using LaTeX notation using the online LaTex equation creator
2. The figures have been created using the app Bamboo Paper, which I think is cooler than creating in Powerpoint
Also see
1.Venturing into IBM’s Quantum Experience
2. Going deeper into IBM’s Quantum Experience!
You may also like
1. Sixer – R package cricketr’s new Shiny avatar
2. Natural language processing: What would Shakespeare say?
3. Sea shells on the seashore
4. How to program – Some essential tips
5. Rock N’ Roll with Bluemix, Cloudant & NodeExpress
6. The Many Faces of Latency
Share:

Going deeper into IBM’s Quantum Experience!
Introduction
In this post I delve deeper into IBM’s Quantum Experience. As mentioned in my earlier post “Venturing into IBM’s Quantum Experience”, IBM, has opened up its Quantum computing environment, to the general public, as the Quantum Experience. The access to Quantum Experience is through IBM’s Platform as a Service (PaaS) offering, Bluemix™. Clearly this is a great engineering feat, which integrates the highly precise environment of Quantum Computing, where the qubits are maintained at 5 milliKelvin, and the IBM Bluemix PaaS environment on Softlayer. The Quantum Experience, is in fact Quantum Computing as a Service (QCaaS). In my opinion, the Quantum Experience, provides a glimpse of tomorrow, today,
Disclaimer: This article represents the author’s viewpoint only and doesn’t necessarily represent IBM’s positions, strategies or opinions
Note: Also by the way, feel free to holler if you find anything incorrect or off the mark in my post. I am just getting started on quantum computing so there may be slip ups.
A) Bloch sphere
 In my earlier post the operations of the X, Y, Z, H, S, and S1 were measured using the standard or diagonal basis and the results were in probabilities of the qubit(s). However, the probabilities alone, in the standard basis, are not enough to specify a quantum state because it does not capture the phase of the superposition. A convenient representation for a qubit is the Bloch sphere.
In my earlier post the operations of the X, Y, Z, H, S, and S1 were measured using the standard or diagonal basis and the results were in probabilities of the qubit(s). However, the probabilities alone, in the standard basis, are not enough to specify a quantum state because it does not capture the phase of the superposition. A convenient representation for a qubit is the Bloch sphere.
The general state of a quantum two-level system can be written in the form
|ψ⟩=α|0⟩+β|1⟩,
Where α and β are complex numbers with |α|2+|β|2=1. This leads to the “canonical” parameterized form
|ψ⟩= cos Θ/2 |0> + eiΦ sin Θ/2 |1> (A)
in terms of only two real numbers θ and φ, with natural ranges 0 ≤ θ ≤ π and 0 ≤ φ ≤ 2π. These are the same as the polar angles in 3-dimensional spherical coordinates, and this leads to the representation of the state (1) as a point on a unit sphere called the Bloch sphere.
In the notation of (A), the state |0> is represented by the North pole, and the state |1> by the South pole. Note: The states |0> and |1> , n the Bloch sphere are not orthogonal to each other. The states on the equator of the Bloch sphere, correspond to superpositions of |0> and |1> with equal weights (θ = π∕2), and different phases, parameterized by the azimuthal angle φ (the “longitude”)
In the picture below Bloch measurements are performed on the operations on the qubits

The results of the Bloch measurements for the combination of quantum gates are shown below
i) Quantum gate operations and Bloch measurements
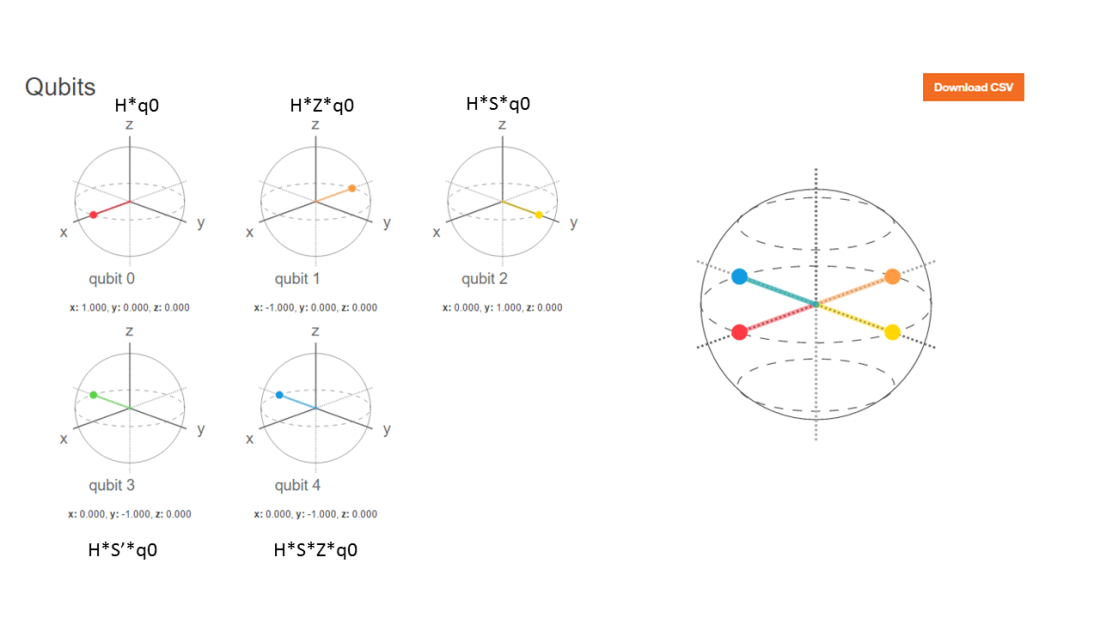
ii) Quantum gate operations as Superposition operations
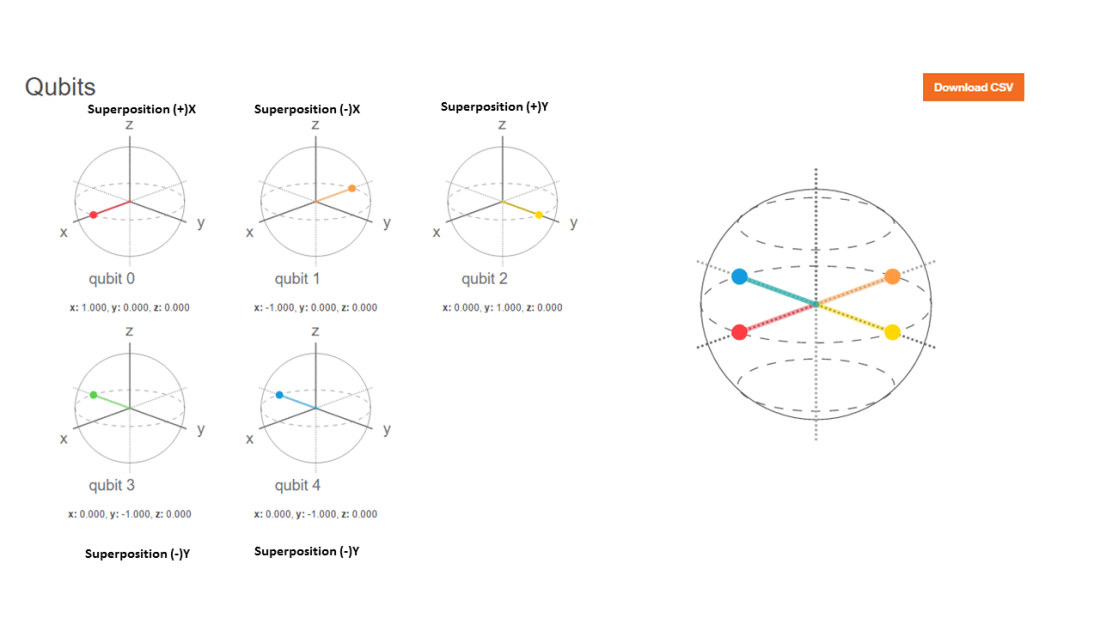
B) Classical vs Quantum computing
A classical computer that has N-bits has 
one point in time, it can be in one, and only one of 2N configurations. Interestingly, the quantum computer also takes in a n -bit number and outputs a n -bit number; but because of the superposition principle and the possibility of entanglement, the intermediate state is very different.
A system which had N different mutually exclusive states can be represented as |1>, |2>. . . |N> using the Dirac’s bra-ket notation
A pure quantum state is a superposition of all these states
Φ = α1 1> + α2 2> + …. + αN N>
To describe it requires complex numbers, giving a lot more room for maneuvering.
C) The CNOT gate
The CNOT gate or the Controlled-Not gate is an example of a two-qubit quantum gate. The CNOT gate’s action is to flip (apply a NOT or X gate to) the target qubit if the control qubit is 1; otherwise it does nothing. The CNOT plays the role of the classical XOR gate, but unlike the XOR, The CNOT gate is a two-output gate and is reversible It is represented by the matrix by the following 4 x 4 matrix
The CNOT gate flips the target bit if the control bit is 1, otherwise it does nothing if it’s 0:
More specifically
CNOT|0>|b> = |0>|b>
CNOT|1>|b>= |1>|1 – b>
The operation of the CNOT gate can be elaborated as below
The 2-qubit basis states can be represented as four-dimensional vectors
|00> =
|01> =
|10> =
|11> =




For example, a quantum state may be expanded as a linear combination of this basis:
|ψ⟩=a|00⟩+b|01⟩+c|10⟩+d|11⟩
The CNOT matrix can be applied as below
CNOT*|ψ⟩=CNOT*(a|00⟩+b|01⟩+c|10⟩+d|11⟩)
= a*CNOT*|00⟩+…+d*CNOT*|11⟩
where you perform standard matrix multiplication on the basis vectors to get:
CNOT*|ψ⟩=a|00⟩+b|01⟩+c|11⟩+d|10⟩
In other words, the CNOT gate has transformed
|10⟩↦|11⟩ and |11⟩↦|10⟩
i) CNOT operations in R code
# CNOT gate
cnot= matrix(c(1,0,0,0,0,1,0,0,0,0,0,1,0,0,1,0),nrow=4,ncol=4)
cnot## [,1] [,2] [,3] [,4]
## [1,] 1 0 0 0
## [2,] 0 1 0 0
## [3,] 0 0 0 1
## [4,] 0 0 1 0#a. Qubit |00>
q00=matrix(c(1,0,0,0),nrow=4,ncol=1)
q00## [,1]
## [1,] 1
## [2,] 0
## [3,] 0
## [4,] 0# CNOT *q00 ==> q00
a <- cnot %*% q00
a## [,1]
## [1,] 1
## [2,] 0
## [3,] 0
## [4,] 0#b.Qubit |01>
q01=matrix(c(0,1,0,0),nrow=4,ncol=1)
q01## [,1]
## [1,] 0
## [2,] 1
## [3,] 0
## [4,] 0# CNOT *q01 ==> q01
a <- cnot %*% q01
a## [,1]
## [1,] 0
## [2,] 1
## [3,] 0
## [4,] 0#c. Qubit |10>
q10=matrix(c(0,0,1,0),nrow=4,ncol=1)
q10## [,1]
## [1,] 0
## [2,] 0
## [3,] 1
## [4,] 0# CNOT *q10 ==> q11
a <- cnot %*% q10
a## [,1]
## [1,] 0
## [2,] 0
## [3,] 0
## [4,] 1#d. Qubit |11>
q11=matrix(c(0,0,0,1),nrow=4,ncol=1)
q11## [,1]
## [1,] 0
## [2,] 0
## [3,] 0
## [4,] 1# CNOT *q11 ==> q10
a <- cnot %*% q11
a## [,1]
## [1,] 0
## [2,] 0
## [3,] 1
## [4,] 0D) Non Clifford gates
The quantum gates discussed in my earlier post (Pauli X, Y, Z, H, S and S1) and the CNOT are members of a special group of gates known as the ‘Clifford group’. These gates can be simulated efficiently on a classical computer. Therefore, the Clifford group is not universal. A finite set of gates that can approximate any arbitrary unitary matrix is known as a universal gate set. This is similar, to how certain sets of classical logic gates, such as {AND, NOT}, are functionally complete and can be used to build any Boolean function ( I remember this axiom/fact from my Digital Electronics -101 class about 3 decades back!).
Adding almost any non-Clifford gate to single-qubit Clifford gates and CNOT gates makes the group universal which I presume can simulate any arbitrary unitary matrix. The non-Clifford gates, discussed are the T and Tǂ gates
These are given by
T =
Tǂ =
i) T gate operations
The T gate makes it possible to reach different points of the Bloch sphere. By increasing the number of T-gates in the quantum circuit ( we start to cover the Bloch sphere more densely with states that can be reached
ii) T Gates of depth 2 – Computational Measurement
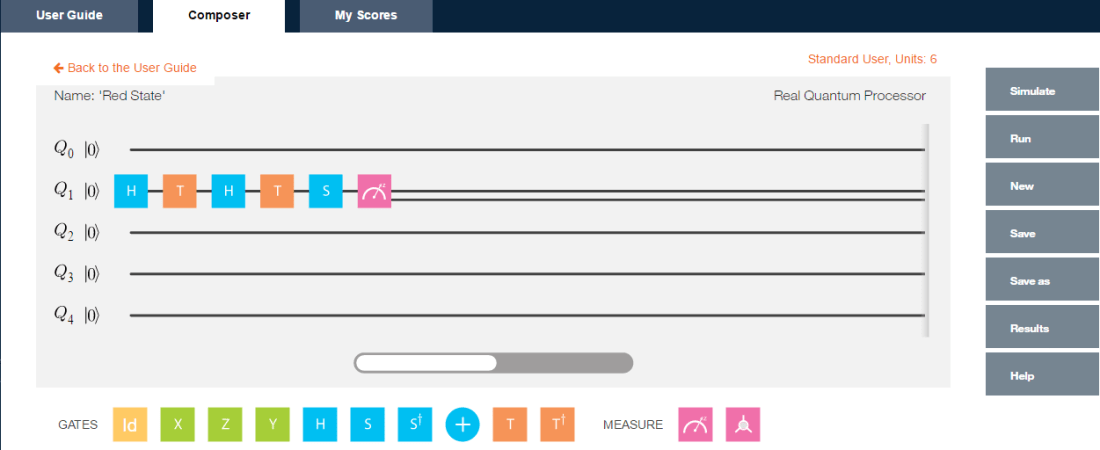
Simulating in Composer
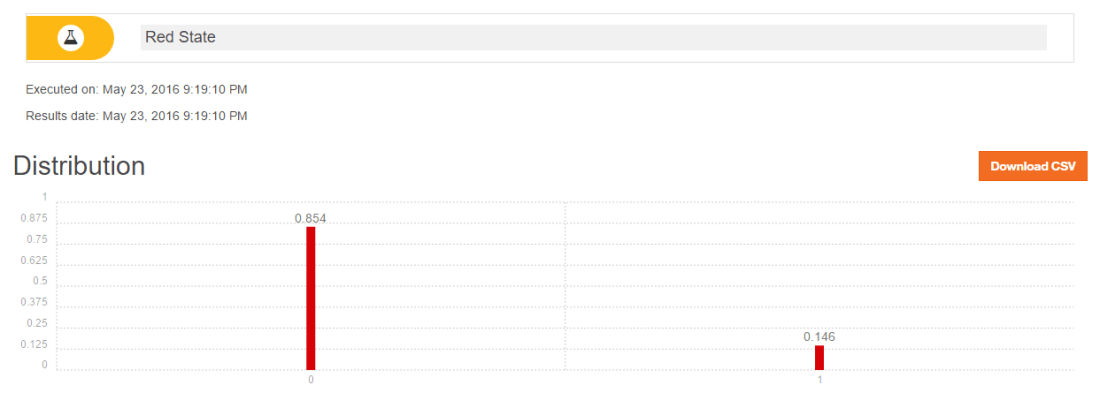
iii) Simulating in R Code
Measurement only gives the real part and does not provide info on phase
# T Gate
T=matrix(c(1,0,0,exp(1i*pi/4)),nrow=2,ncol=2)
# Simulating T Gate depth-2 - Computational measurement
a=S%*%T%*%H%*%T%*%H%*%q0
a## [,1]
## [1,] 0.8535534+0.3535534i
## [2,] 0.1464466+0.3535534iiv) 2 T Gates – Bloch Measurement
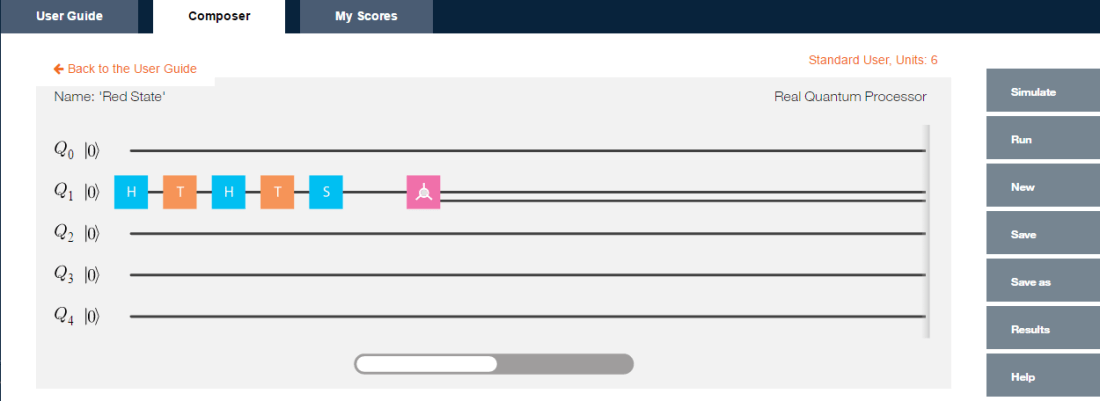
Bloch measurement

v) Simulating T gate in R code
This gives the phase values as shown in the Bloch sphere
# Simulating T Gate depth-2 - Bloch measurement (use a diagonal basis H gate in front)
a=H%*%S%*%T%*%H%*%T%*%H%*%q0
a## [,1]
## [1,] 0.7071068+0.5i
## [2,] 0.5000000+0.0i
E) Quantum Entanglement – The case of ‘The Spooky action at a distance’
One of the infamous counter-intuitive ideas of quantum mechanics is that two systems that appear too far apart to influence each other can nevertheless behave in ways that, though individually random, are too strongly correlated to be described by any classical local theory. For e.g. when the 1st qubit of a pair of “quantum entangled” qubits are measured, this automatically determines the 2nd qubit, though the individual qubits may be separated by extremely large distances. It appears that the measurement of the first qubit cannot affect the 2nd qubit which is too far apart to be be influenced and also given the fact that nothing can travel faster than the speed of light. More specifically
“Suppose Alice has the first qubit of the pair, and Bob has the second. If Alice measures her qubit in the computational basis and gets outcome b ∈ {0, 1}, then the state collapses to |bb> . In other words the measurements and outcome of the 1st qubit determines the outcome of the 2nd qubit . How weird is that?
Similarly, if Alice measures her qubit in some other basis, this will collapse the joint state (including Bob’s qubit) to some state that depends on her measurement basis as well as its outcome. Somehow Alice’s action seems to have an instantaneous effect on Bob’s side—even if the two qubits are light-years apart!”
How weird is that!
Einstein, whose theory of relativity posits that information and causation cannot travel faster than the speed of light, was greatly troubled by this, . Einstein called such effects of entanglement “spooky action at a distance”.
In the 1960s, John Bell devised entanglement-based experiments whose behavior cannot be reproduced by any “local realist” theory where the implication of local and realist is given below
Locality: No information can travel faster than the speed of light. There is a hidden variable that defines all the correlations.
Realism: All observables have a definite value independent of the measurement
i) Bell state measurements
The mathematical proof for the Bell tests are quite abstract and mostly escaped my grasp. I hope to get my arms around this beast, in the weeks and months to come. However, I understood how to run the tests and perform the calculations which are included below. I have executed the Bell Tests on
a) Ideal Quantum Processor (Simulator with ideal conditions)
b) Realistic Quantum Processor (Simulator with realistic conditions)
c) Real Quantum Processor. For this I used 8192 ‘shots’ repeats of the experiment
I finally calculate |C| for all 3 tests
The steps involved in calculating |C|
1. Execute ZW, ZV, XW, XV
2. Calculate = P(00) + P(11) – P(01) – P(10)
3. Finally |C| = ZW + ZV + XW – XV
Preparation of Qubit |00>
The qubits are in state |00> The H gate takes the first qubit to the equal superposition
1/√2(|00> + |10>) and the CNOT gate flips the second qubit if the first is excited, making the state 1/√2(|00> + |11>). This is the entangled state (commonly called a Bell state)

Simulating in Composer
This prepares the entangled state 1/√2(|00> + |11>)

It can be seen that the the qubits |00> and |11> are created
1) Simulations on Ideal Quantum processor
a) Bell state ZW (Ideal)

Simulation

P(00) = 0.427
P(01) = 0.073
P(10) =0.073
P(11) = 0.427
b) Bell state ZV (Ideal)

Simulation
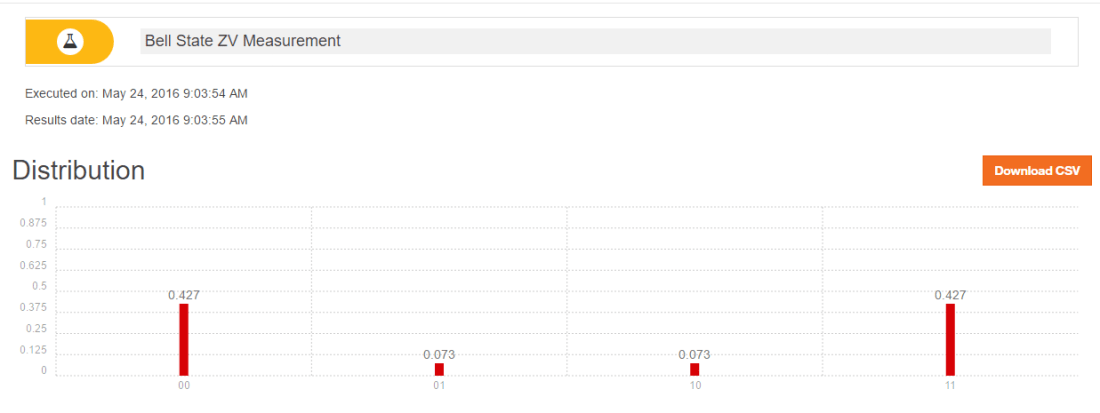
P(00) = 0.427
P(01) = 0.073
P(10) =0.073
P(11) = 0.427
c) Bell state XW (Ideal)

Measurement

P(00) = 0.427
P(01) = 0.073
P(10) =0.073
P(11) = 0.427
d) Bell state XV (Ideal)

Simulating Bell State XV in Composer
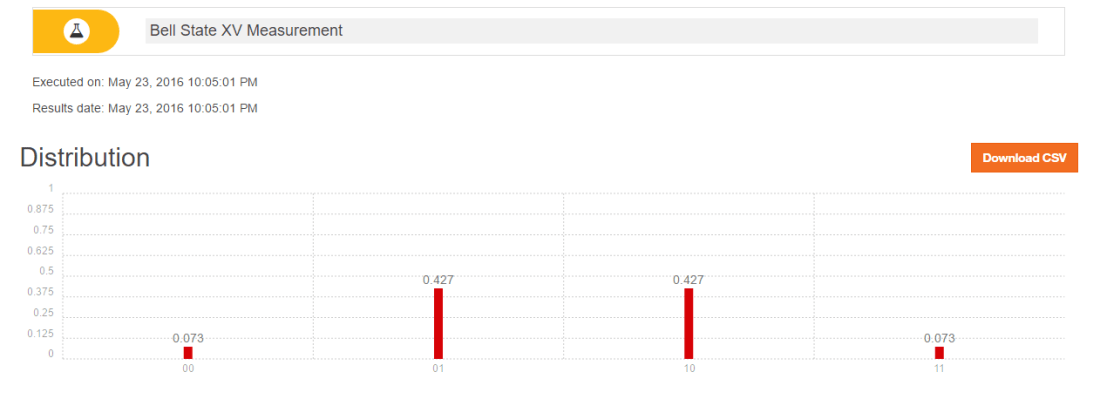
P(00) = 0.073
P(01) = 0.473
P(10) = 0.473
P(11) =0.73
Bell test measurement in Ideal Quantum Processor are given below

For the Ideal Quantum Processor
|C) = 2.832
2) Simulations on the Realistic Quantum Processor
The Bell tests above were simulated on Realistic Quantum Processor. The results are included below
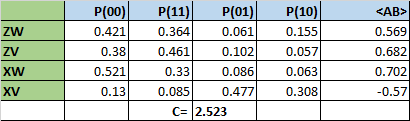
For the Realistic Quantum Processor
|C) = 2.523
3) Real IBM Quantum Processor (8192 shots)
Finally the Bell Tests were executed in IBM’s Real Quantum Processor for 8192 shots, each requiring 5 standard units. The tests were queued, executed and the results sent by mail. The results are included below
a) Bell State ZW measurement (Real)
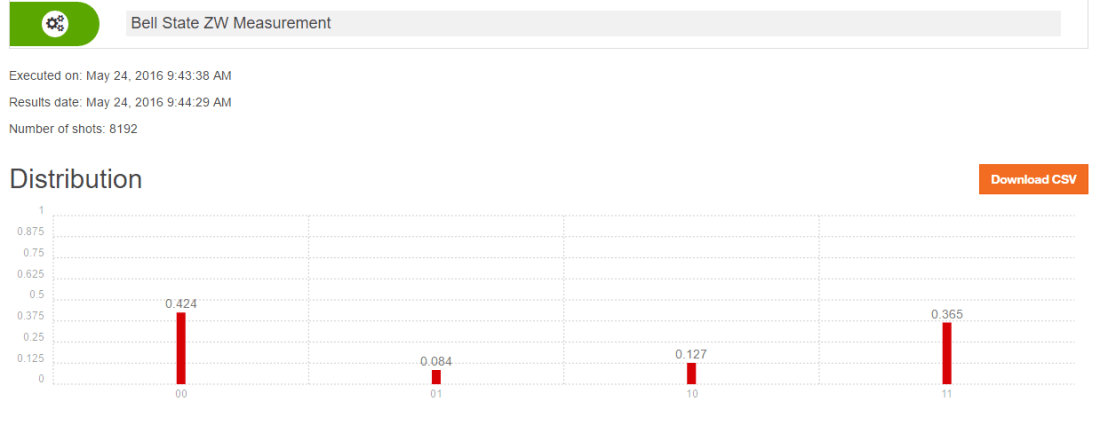
b) Bell state ZV measurement (Real)

c) Bell State XW measurement (Real)
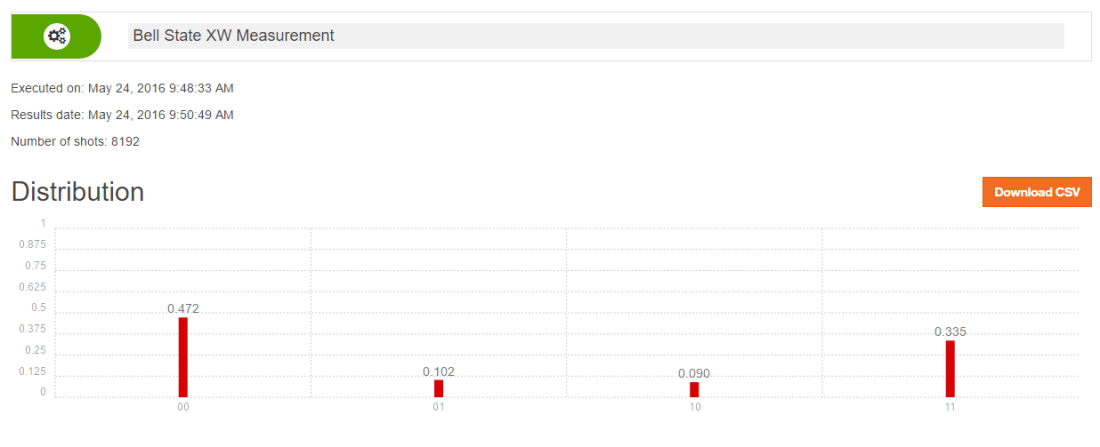
d) Bell state XV measurement (Real)

;
The results were tabulated and |C| computed. Bell test measurement in Real Quantum Processor are given below
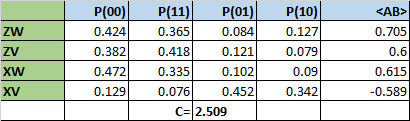
The Bell measurements on the Reak Quantum Processor is
|C) = 2.509
Conclusion
This post included details on the CNOT and the non-Clifford gates. The Bell tests were performed on all 3 processors Ideal, Realistic and Real Quantum Processors and in each case the |C| > 2. While I have been to execute the tests I will definitely have to spend more time understanding the nuances.
I hope to continue this journey into quantum computing the months to come. Watch this space!
Disclaimer: This article represents the author’s viewpoint only and doesn’t necessarily represent IBM’s positions, strategies or opinions
References
1.IBM Quantum Experience – User Guide
2.Quantum Computing lecture notes – Ronald De Wolf
3.Bloch sphere
4.Basic concepts in quantum computation
5.Physics Stack Exchange
You may also like
1.Revisiting crimes against women in India
2.Natural language processing: What would Shakespeare say?
3. My book ‘Practical Machine Learning with R and Python’ on Amazon
4. Introducing QCSimulator: A 5-qubit quantum computing simulator in R
5.Beaten by sheer pace – Cricket analytics with yorkr
6.A method for optimal bandwidth usage by auctioning available bandwidth using the OpenFlow protocol
7.TWS-4: Gossip protocol: Epidemics and rumors to the rescue
8.Bend it like Bluemix, MongoDB using Auto-scale – Part 1!
9.Fun simulation of a Chain in Android
10.Cricket analytics with cricketr in paperback and Kindle versions

