In this post I take a peek into the literacy landscape across India as a whole using R language. The dataset from Open Government Data (OGD) platform India was used for this purpose. This data is based on the 2011 census. The XL sheets for the states were downloaded for data for each state. The Union Territories were not included in the analysis.
A thin slice of the data from each data set was taken from the data for each individual state (Note: This could also have been done from the consolidated india.xls XL sheet which I came to know of, much later).
I calculate the following for age group
Males (%) attending education institutions = (Males attending educational institutions * 100)/ Total males
Females (%) attending education institutions = (Females attending educational institutions * 100)/ Total Females
This is then plotted as a bar chart with the age distribution. I then overlay the national average for each state over the barchart to check whether the literacy in the state is above or below the national average. The implementation in R is included below
The code and data can be forked/cloned from GitHub at india-literacy
The results based on the analysis is given below.
- Kerala is clearly the top ranker with the literacy rates for both males and females well above the average
- The states with above average literacy are – Kerala, Himachal Pradesh, Uttarakhand, Tamil Nadu, Haryana, Himachal Pradesh, Karnataka, Maharashtra, Punjab, Uttarakhand
- The states with just about average literacy – Karnataka, Andhra Pradesh, Chattisgarh, Gujarat, Madhya Pradesh, Odisha, West Bengal
- The states with below average literacy – Uttar Pradesh, Bihar, Jharkhand, Arunachal Pradesh, Assam, Jammu and Kashmir, Jharkhand, Rajasthan
A brief implementation of the basic code in R is shown bwelow
# Read the Arunachal Pradhesh literacy related data
arunachal = read.csv("arunachal.csv")
# Create as a matrix
arunachalmat = as.matrix(arunachal)
arunachalTotal = arunachalmat[2:19,7:28]
# Take transpose as this is necessary for plotting bar charts
arunachalmat = t(arunachalTotal)
# Set the scipen option to format the y axis (otherwise prints as e^05 etc.)
getOption("scipen")
opt <- options("scipen" = 20)
getOption("scipen")
#Create a vector of total Males & Females
arunachalTotalM = arunachalmat[3,]
arunachalTotalF = arunachalmat[4,]
#Create a vector of males & females attending education institution
arunachalM = arunachalmat[6,]
arunachalF = arunachalmat[7,]
#Calculate percent of males attending education of total
arunachalpercentM = round(as.numeric(arunachalM) *100/as.numeric(arunachalTotalM),1)
barplot(arunachalpercentM,names.arg=arunachalmat[1,],main ="Percentage males attending educational institutions in Arunachal Pradesh",
xlab = "Age", ylab= "Percentage",ylim = c(0,100), col ="lightblue", legend= c("Males"))
points(age,indiapercentM,pch=15)
lines(age,indiapercentM,col="red",pch=20,lty=2,lwd=3)
legend( x="bottomright",
legend=c("National average"),
col=c("red"), bty="n" , lwd=1, lty=c(2),
pch=c(15) )
#Calculate percent of females attending education of total
arunachalpercentF = round(as.numeric(arunachalF) *100/as.numeric(arunachalTotalF),1)
barplot(arunachalpercentF,names.arg=arunachalmat[1,],main ="Percentage females attending educational institutions in Arunachal Pradesh ",
xlab = "Age", ylab= "Percentage", ylim = c(0,100), col ="lightblue", legend= c("Females"))
points(age,indiapercentF,pch=15)
lines(age,indiapercentF,col="red",pch=20,lty=2,lwd=3)
legend( x="bottomright",
legend=c("National average"),
col=c("red"), bty="n" , lwd=1, lty=c(2),
pch=c(15) )
A) Overall plot for India
a) India – Males

b) India – females

The plots for each individual state is given below
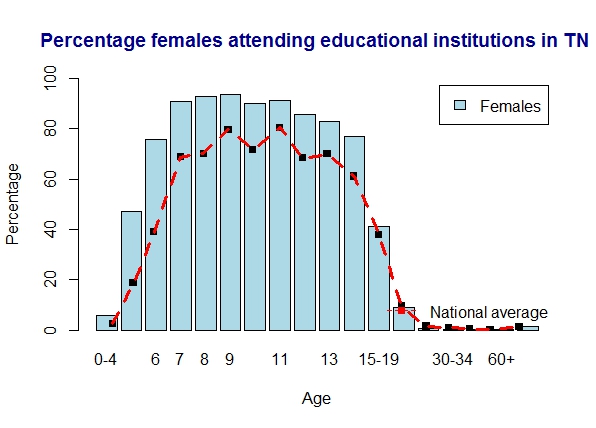
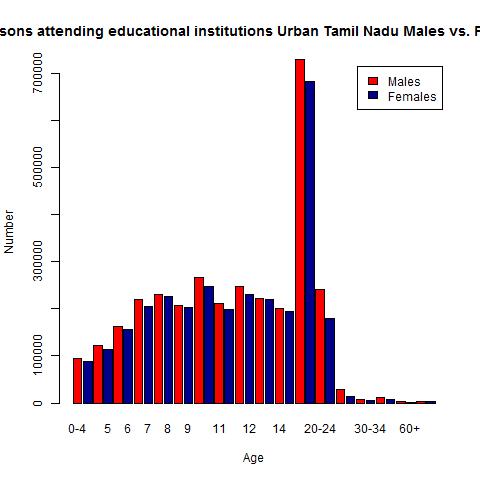
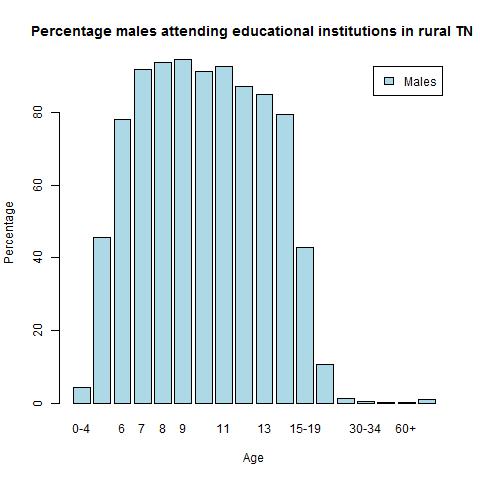
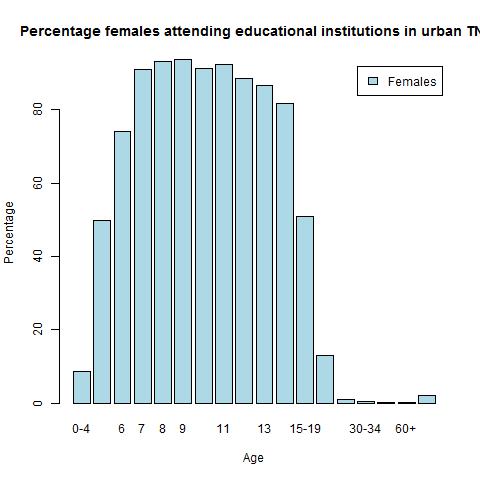
1) Literacy in Tamil Nadu
Tamil Nadu is slightly over the national average. The women seem to do marginally better than the males
a) Tamil Nadu – males

b) Tamil Nadu – females
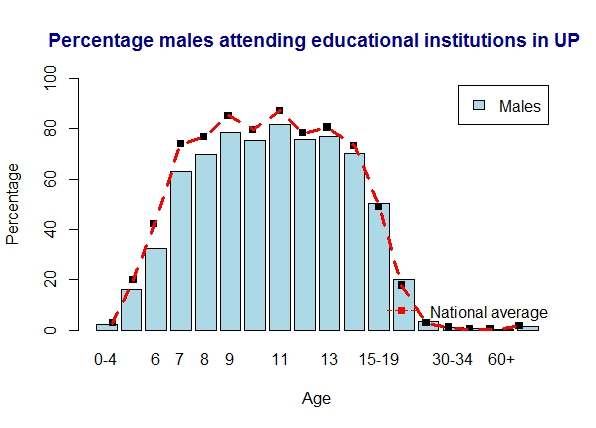
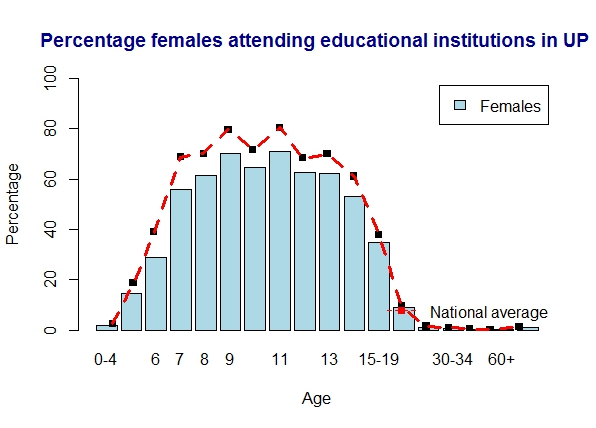
2) Literacy in Uttar Pradesh
UP is slightly below the national average. Women are comparatively below men here
a) Uttar Pradesh – males
b) Uttar Pradesh – females
3) Literacy in Bihar
Bihar is well below the national average for both men and women
a) Bihar – males

b) Bihar – females

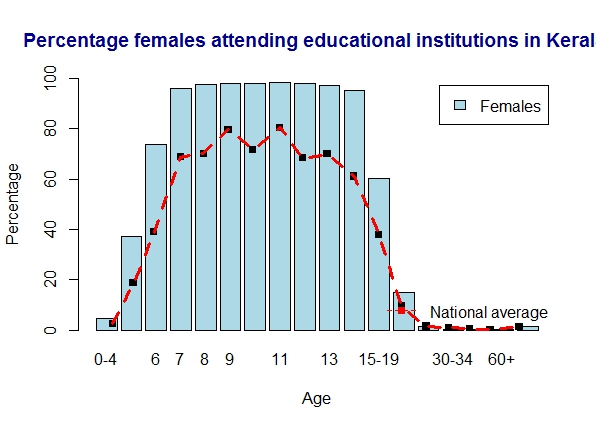
4. Literacy in Kerala
Kerala is the winner all the way in literacy with almost 100% literacy across all age groups
a) Kerala – males
b) Kerala -females
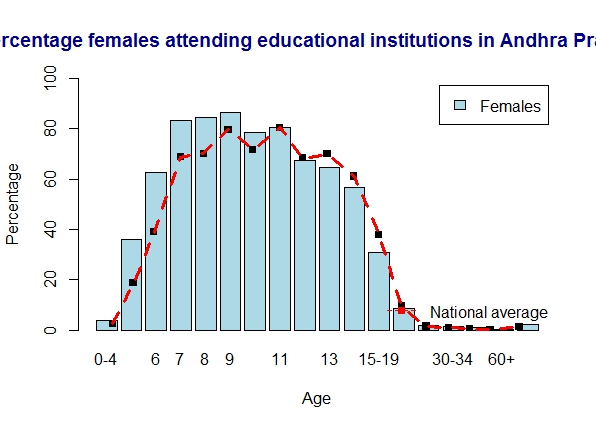
5. Literacy in Andhra Pradesh
AP just meets the national average for literacy.
a) Andhra Pradesh – males

b) Andhra Pradesh – females
6. Literacy in Arunachal Pradesh
Arunachal Pradesh is below average for most of the age groups
a) Arunachal Pradesh – males
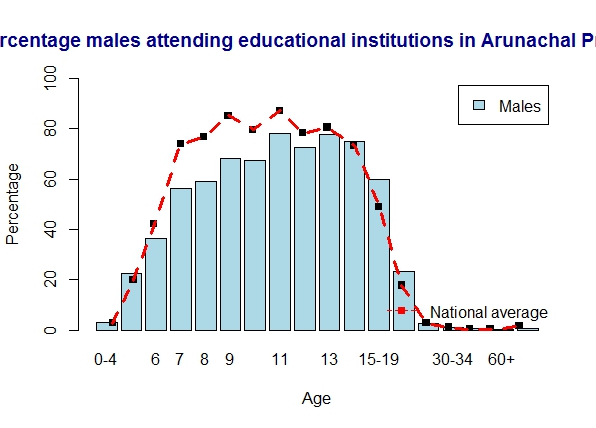
b) Arunachal Pradesh – females

7. Literacy in Assam
Assam is below national average
a) Assam – males
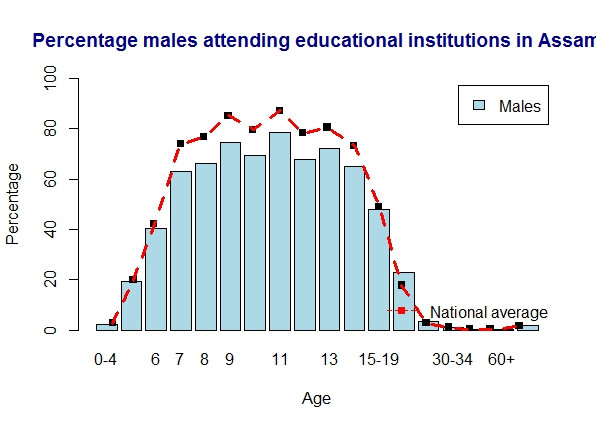
b) Assam – females

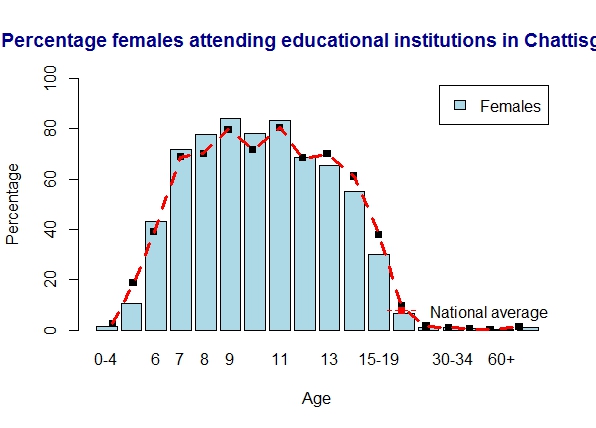
8. Literacy in Chattisgarh
Chattisgarh is on par with the national average for both men and women
a) Chattisgarh – males
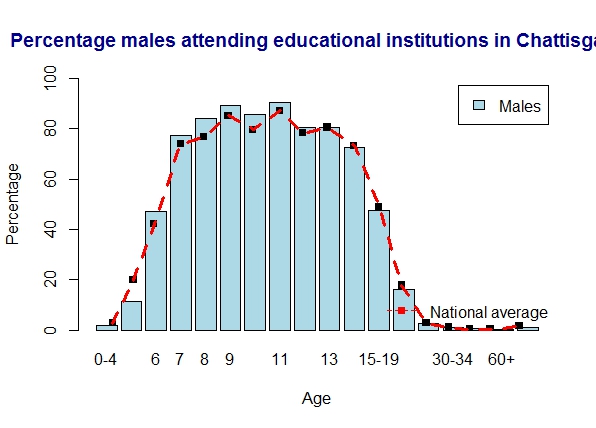
b) Chattisgarh – females
9. Literacy in Gujarat
Gujarat is just about average
a) Gujarat – males

b) Gujarat – females

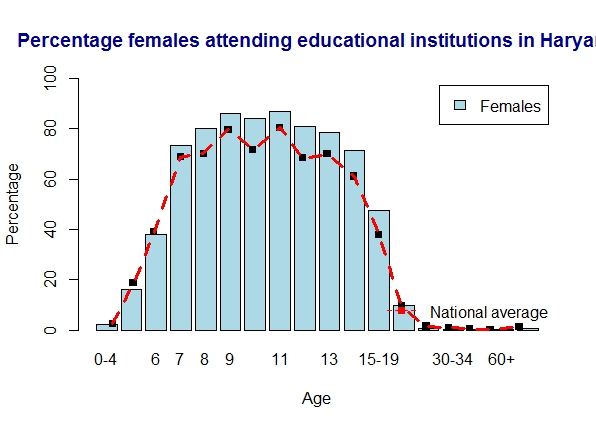
10. Literacy in Haryana
Haryana is slightly above average
a) Haryana – males

b) Haryana – females
 11. Literacy in Himachal Pradesh
11. Literacy in Himachal Pradesh
Himachal Pradesh is cool and above average.
a) Himachal Pradesh – males

b) Himachal Pradesh – females

12. Literacy in Jammu and Kashmir
J & K is marginally below average
a) Jammu and Kashmir – males

b) Jammu and Kashmir – females

13. Literacy in Jharkhand
Jharkhand is some ways below average
a) Jharkhand – males

b) Jharkhand – females

14. Literacy in Karnataka
Karnataka is on average for men. Womem seem to do better than men here
a) Karnataka – males

b) Karnataka – females

15. Literacy in Madhya Pradesh
Madhya Pradesh meets the national average
a) Madhya Pradesh – males

b) Madhya Pradesh – females

16. Literacy in Maharashtra
Maharashtra is front-runner in literacy
a) Maharashtra – females

b) Maharastra – females

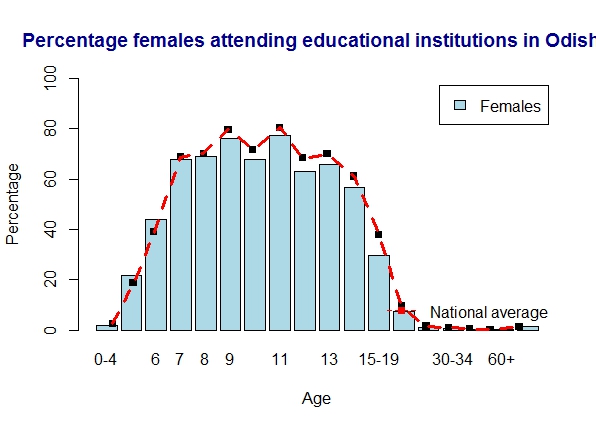
17. Literacy in Odisha
Odisha meets national average
a) Odisha – males

b) Odisha – females
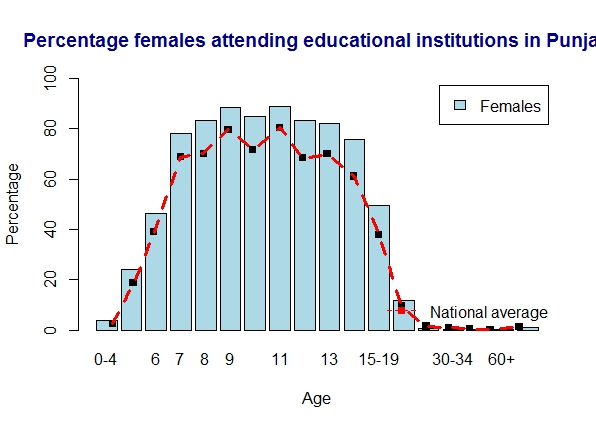
18. Literacy in Punjab
Punjab is marginally above average with women doing even better
a) Punjab – males

b) Punjab – females
 19. Literacy in Rajasthan
19. Literacy in Rajasthan
Rajasthan is average for males and below average for females
a) Rajasthan – males

b) Rajasthan – females
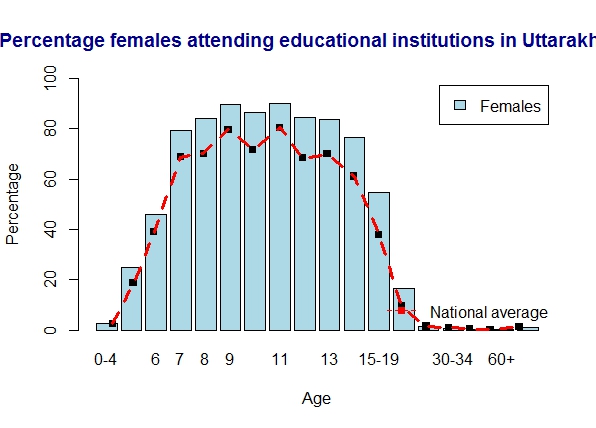
 20. Literacy in Uttarakhand
20. Literacy in Uttarakhand
Uttarakhand rocks and is above average
a) Uttarakhand – males

b) Uttarakhand – females
21. Literacy in West Bengal
West Bengal just about meets the national average.
a) West Bengal – males

b) West Bengal – females

The code can be cloned/forked from GitHub india-literacy. I have done my analysis on the overall data. The data is further sub-divided across districts in each state and further into urban and rural. Many different ways of analysing are possible. One method is shown here
Conclusion
- Kerala is clearly head and shoulders above all states when it comes to literacy
- Many states are above average. They are Kerala, Himachal Pradesh, Uttarakhand, Tamil Nadu, Haryana, Himachal Pradesh, Karnataka, Maharashtra, Punjab, Uttarakhand
- States with average literacy are – Karnataka, Andhra Pradesh, Chattisgarh, Gujarat, Madhya Pradesh, Odisha, West Bengal
- States which fall below the national average are – Uttar Pradesh, Bihar, Jharkhand, Arunachal Pradesh, Assam, Jammu and Kashmir, Jharkhand, Rajasthan
See also
– A crime map of India in R: Crimes against women
– What’s up Watson? Using IBM Watson’s QAAPI with Bluemix, NodeExpress – Part 1
– Bend it like Bluemix, MongoDB with autoscaling – Part 1
























{kind=link}