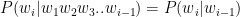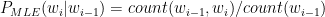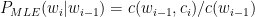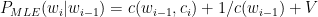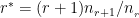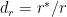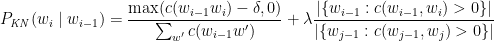Ever since I started to use ChatGPT, I have been fascinated by its capabilities. To a large extent, the abilities of Large Language Models (LLMs) is quite magical – the way it answers questions, the way it summarises passages, the way it creates poems et cetera. All the LLMs need is a large corpus of data from the internet, articles, wikis, blogs, and so on.
On delving a little deeper into Generative AI, LLMs I learnt that, this is based on the principle of being able to predict the most probable word in a given sequence. It made me wonder whether the world of ideas, language and communication are actually governed by probabilities. Does what we communicate fall within the purview of statistics?
As an aside, just by extending further if we visualise a world in which every human action to a situation is assigned an embedding vector, and if we feed the responses of all humans over time in different situations, to the equivalent of a Transformer of a Large Human Reaction Model (LHRM) ;-), we can envisage the model being capable of predicting the response of human in a given situation. In my opinion, the machine would be fairly right most of the occasions as it could select the most probable choice of action, much like ‘The Machine’ in Person of Interest. However, this does not mean that the machine (AI) is actually more intelligent than humans. All it means is that the choice of humans responses are a part of a finite subset possibilities and The Machine (AI) can compute the possibilities and associated probabilities much quicker than humans. Does it mean that the world is deterministic? Possibly.
In this post, I use the T5 transformer to summarise Indian philosophy. For this task, I have fine-tuned the T5 model with a curated dataset taken from random passages on Hindu philosophy available on the internet. For each passage, I had to and hand-create the corresponding summary. This was a fairly tedious and demanding task but an enlightening one. It was interesting to understand how our ancestors, the Rishis, understood reality, the physical world, senses, the mind, the intellect, consciousness (Atman) and universal consciousness (Brahman). (Incidentally I was only able to curate only about 130 rows of philosophical snippets and manually create the corresponding summaries. Probably this is a very small dataset for fine-tuning but I just wanted to see the performance of the T5 model in a new domain.)
In this post the T5 model is fine-tuned with the curated dataset and the rouge1 and rouge2 scores are used to evaluate the model’s performance.
I have used the Hugging Face Hub for the transformer model, corresponding LLM functions and management of the dataset etc. The Hugging Face ecosystem is simply wow!!
Summarisation with T5-small model
a) Install the necessary libraries
! pip install transformers[torch] datasets evaluate rouge_score accelerate -U
! pip install -U accelerate
! pip install -U transformersb) Login to Hugging Face account
from huggingface_hub import notebook_login
notebook_login()
Login successfulc) Load the curated dataset on Hindu philosophy
from datasets import load_dataset
df1 = load_dataset("tvganesh/philosophy",split='train')d) Load a T5 tokenizer to process text and summary
- Prefix the input with a prompt so T5 knows this is a summarization task.
- Use the keyword
text_targetargument when tokenizing labels. - Truncate sequences to be no longer than the maximum length set by the
max_lengthparameter. The max_length of the text kept at 220 words and the max_length of the summary is kept at 50 words. - The ‘map’ function of the Huggingface dataset can be used to apply the pre_process function across the entire data.
from transformers import AutoTokenizer
checkpoint = "t5-small"
#checkpoint = "facebook/bart-large-cnn"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
prefix = "summarize: "
def preprocess_function(passages):
inputs = [prefix + doc for doc in passages["text"]]
model_inputs = tokenizer(inputs, max_length=220, truncation=True)
labels = tokenizer(text_target=passages["summary"], max_length=50, truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
tokenized_df1 = df1.map(preprocess_function, batched=True)DataCollatorForSeq2Seq can be used to dynamically pad the sentences to the longest length in a batch during collation, instead of padding the whole dataset to the maximum length.
from transformers import DataCollatorForSeq2Seq
data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=checkpoint)e) Evaluate performance of Model
The rouge1,rouge2 metric can be used to evaluate the performance of the model
import evaluate
rouge = evaluate.load("rouge")f)Create a function compute_metrics that passes your predictions and labels to ‘compute’ to calculate the ROUGE metric:
import numpy as np
def compute_metrics(eval_pred):
# evaluate predictions and labels
predictions, labels = eval_pred
decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# compute rouge score between the labels and predictions
result = rouge.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True)
prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in predictions]
result["gen_len"] = np.mean(prediction_lens)
return {k: round(v, 4) for k, v in result.items()}g) Split the data into training(80%) and test(20%) data set
train_dataset = tokenized_df1.shuffle(seed=42).select(range(100))
test_dataset = tokenized_df1.shuffle(seed=42).select(range(30))
len(train_dataset)h) Train the model with AutoModelForSeq2SeqLM
from transformers import AutoModelForSeq2SeqLM, Seq2SeqTrainingArguments, Seq2SeqTrainer
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)i)
- Set training hyperparameters in Seq2SeqTrainingArguments. The Adam optimization, with learning rate, beta1 & beta2 are used
- Pass the training arguments to Seq2SeqTrainer along with the model, dataset, tokenizer, data collator, and compute_metrics function.
- Call train() to finetune your model.
training_args = Seq2SeqTrainingArguments(
output_dir="philosophy_model",
evaluation_strategy="epoch",
learning_rate= 5.6e-03,
adam_beta1=0.9,
adam_beta2=0.99,
adam_epsilon=1e-06,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
weight_decay=0.01,
save_total_limit=3,
num_train_epochs=20,
predict_with_generate=True,
fp16=True,
push_to_hub=True,
)
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
trainer.train()
Epoch Training Loss Validation Loss Rouge1 Rouge2 Rougel Rougelsum Gen Len
1 No log 2.246223 0.363200 0.146200 0.311400 0.312600 18.333300
2 No log 1.461140 0.459000 0.303900 0.417800 0.417800 18.566700
3 No log 0.832312 0.546500 0.425900 0.524700 0.520800 17.133300
4 No log 0.472341 0.616100 0.517600 0.601000 0.600400 18.366700
5 No log 0.312106 0.681200 0.607800 0.674700 0.671400 18.233300
6 No log 0.154585 0.741800 0.702300 0.733800 0.731300 18.066700
7 No log 0.112100 0.783200 0.763000 0.780200 0.778900 18.500000
8 No log 0.069882 0.801400 0.788200 0.802700 0.800900 18.533300
9 No log 0.045941 0.795800 0.780500 0.794600 0.791700 18.500000
10 No log 0.051655 0.809100 0.795800 0.810500 0.809000 18.466700
11 No log 0.035792 0.799400 0.785200 0.797300 0.794600 18.500000
12 No log 0.041766 0.779900 0.754800 0.774700 0.773200 18.266700
13 No log 0.010703 0.810000 0.800400 0.810700 0.809000 18.500000
14 No log 0.006519 0.807700 0.797100 0.809400 0.807500 18.500000
15 No log 0.017779 0.808000 0.796000 0.809400 0.807500 18.366700
16 No log 0.001681 0.810000 0.800400 0.810700 0.809000 18.500000
17 No log 0.005469 0.810000 0.800400 0.810700 0.809000 18.500000
18 No log 0.002003 0.810000 0.800400 0.810700 0.809000 18.500000
19 No log 0.000638 0.810000 0.800400 0.810700 0.809000 18.500000
20 No log 0.000498 0.810000 0.800400 0.810700 0.809000 18.500000
TrainOutput(global_step=260, training_loss=0.6491916949932391, metrics={'train_runtime': 57.99, 'train_samples_per_second': 34.489, 'train_steps_per_second': 4.484, 'total_flos': 101132046434304.0, 'train_loss': 0.6491916949932391, 'epoch': 20.0})As we can see the rouge1 to rouge2 scores are fairly good. Anything above 0.5 is considered good. Maybe this is because the T5 model has already been pre-trained on a fairly large philosophical dataset
j) Push to hub
trainer.push_to_hub()k) Summarise using pipeline
text = "summarize: A seeker who has the necessary qualifications, in order that he may be redeemed from his inner weaknesses, attachments, animalisms and false values is advised to serve with devotion a Teacher who is well- established in the experience of the Self."
from transformers import pipeline
summarizer = pipeline("summarization", model="tvganesh/philosophy_model")
summarizer(text)
[{'summary_text': 'A seeker who has the necessary qualifications will be able to free oneself of sense objects, and one cannot expect this to happen without any mental tossing'}]l) Summarise using model generate
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("tvganesh/philosophy_model")
inputs = tokenizer(text, return_tensors="pt").input_ids
from transformers import AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained("tvganesh/philosophy_model")
outputs = model.generate(inputs, max_new_tokens=70, do_sample=False)
tokenizer.decode(outputs[0], skip_special_tokens=True)
'A seeker who has the necessary qualifications will help in his journey to redeem himself'l) Number of beams
summary_ids = model.generate(inputs,
num_beams=10,
no_repeat_ngram_size=3,
min_length=20,
max_length=70,
early_stopping=True)
output = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
output
'A seeker who has the necessary qualifications will be able to free himself of sense objects and false values'I also tried Facebook’s BART Large model but the performance was not good at all.
You can try out the model at the following link philosophy_model
Anyway this was a good learning experience.
References
Also see
- Deep Learning from first principles in Python, R and Octave – Part 4
- Introducing QCSimulator: A 5-qubit quantum computing simulator in R
- Computing IPL player similarity using Embeddings, Deep Learning
- Natural language processing: What would Shakespeare say?
- Using Linear Programming (LP) for optimizing bowling change or batting lineup in T20 cricket
- Revisiting World Bank data analysis with WDI and gVisMotionChart
- Big Data-4: Webserver log analysis with RDDs, Pyspark, SparkR and SparklyR
- Sea shells on the seashore
- Experiments with deblurring using OpenCV
- A closer look at “Robot Horse on a Trot” in Android
To see all posts click Index of posts


 Checkout my book ‘Deep Learning from first principles- In vectorized Python, R and Octave’. My book is available on Amazon as
Checkout my book ‘Deep Learning from first principles- In vectorized Python, R and Octave’. My book is available on Amazon as