‘Would you tell me, please, which way I ought to go from here?’
‘That depends a good deal on where you want to get to,’ said the Cat.
‘I don’t much care where—’ said Alice.
‘Then it doesn’t matter which way you go,’ said the Cat.
‘—so long as I get somewhere,’ Alice added as an explanation.
‘Oh, you’re sure to do that,’ said the Cat, ‘if you only walk long enough.’
Alice in Wonderland, Lewis Caroll, 1864
About three years ago, I implemented a T20 Match Win Probability model, using Deep Learning with batsman and bowler embeddings to compute the the ball-by-ball probability of winning by the competing teams as the match progresses (see
GooglyPlusPlus: Win Probability using Deep Learning and player embeddings.). Ball-by-ball match data is available for different T20 leagues in Cricsheet. This Deep Learning algorithm was originally written in TensorFlow and Keras at that time (Win Probabilty Computation – TensorflowKeras). I had got a training and validation accuracy of around 0.8876 (this is very similar to Win Probability model in baseball, NFL etc.)
I recently, revisited this code and asked Sonnet 4.6 to convert the TensorFlow-Keras DL algorithm into PyTorch, (more compact and probably more efficient), which it promptly did, without breaking a sweat. However, even after converting to Pytorch, the validation accuracy still remained ~ 0.8959 (see notebook Match Win Probability Computation – Pytorch). The T20 Win Probability Model was trained on 2.14 million rows of T20 data taken from 9 different T20 leagues across the globe. The ball-by-ball match data is available in Cricsheet as yaml files which have been pre-processed suitably.
I was wondering whether it was possible to use Karpathy’s auto-research to optimise this DL algorithm Providentially, I came across EPOCH: An agentic protocol for multi-round system optimisation by Liu, Li, and Srikanth (2026), which was a paper that was published by my colleagues at Prorata.ai. EPOCH, enables system fine-tuning, optimisations of model, code, and rule-based components. Since, this was exactly what I wanted, I decided to give EPOCH a try. The result was quite impressive!!!
The setup and installation was pretty straightforward. I then started EPOCH by typing in /epoch in Claude Code. Initially, I was just given a set of questions. I set the goal of 0.95 as the target validation accuracy for the agentic protocol.
Incidentally, earlier, I did try a couple of things to improve the performance of the DL algorithm by playing around with the hyper-parameters, including brute-force Gridsearch, but none of it seemed to help. I think I hit a plateau around 0.8876.
EPOCH, created an initial scaffolding and baseline metrics. It then ran multiple experiments to optimise the validation accuracy which started to inch towards 0.95. Here is a summary of the experiments of EPOCH and the outcomes. EPOCH and Claude Code stored the baseline metrics and results of each experiment in github repo claude_wpa
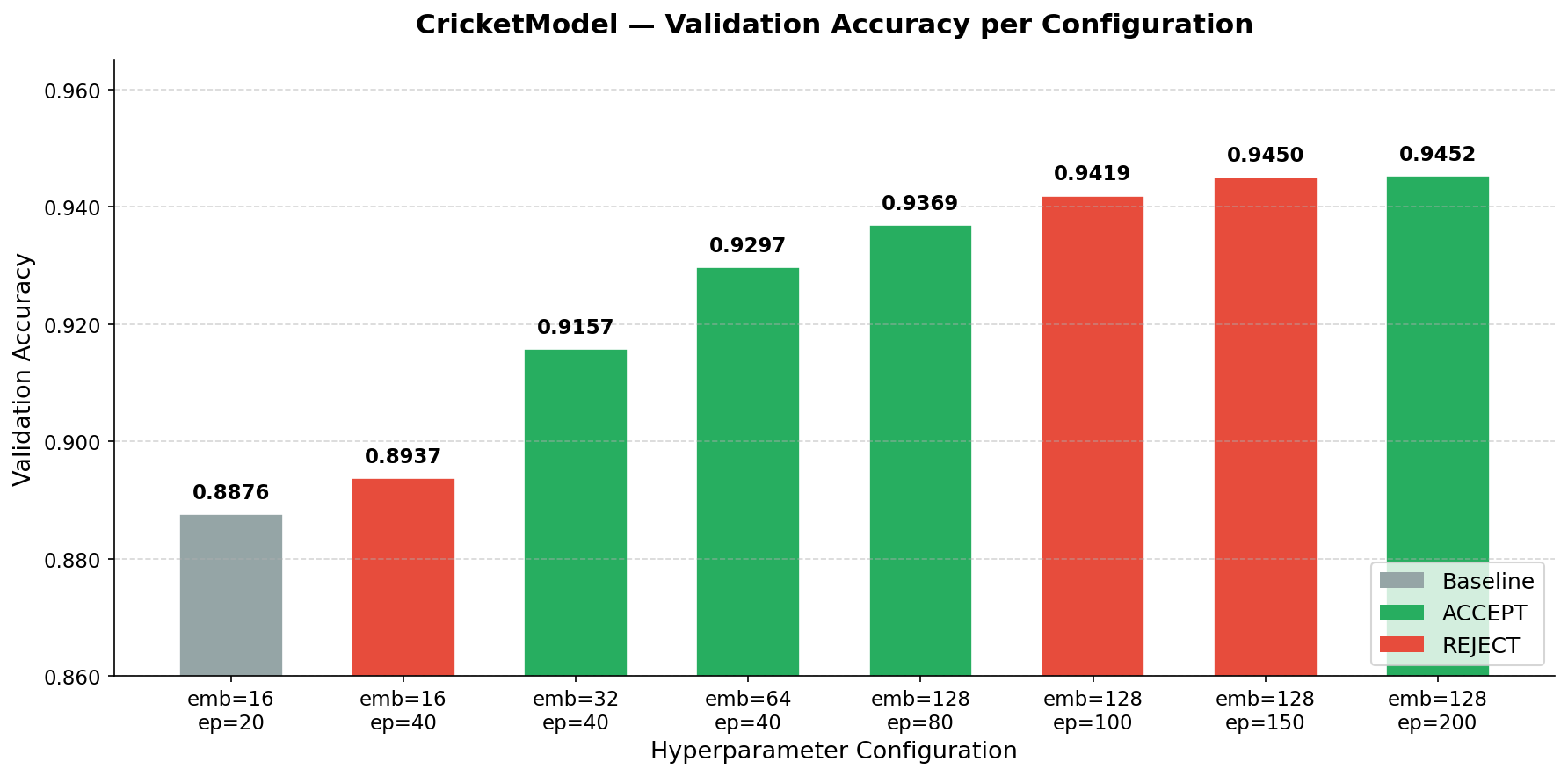
a) Hyperparameter tuning vs Validation accuracy improvement
Included below are the hyperparameter changes and the corresponding validation accuracy improvement in each round
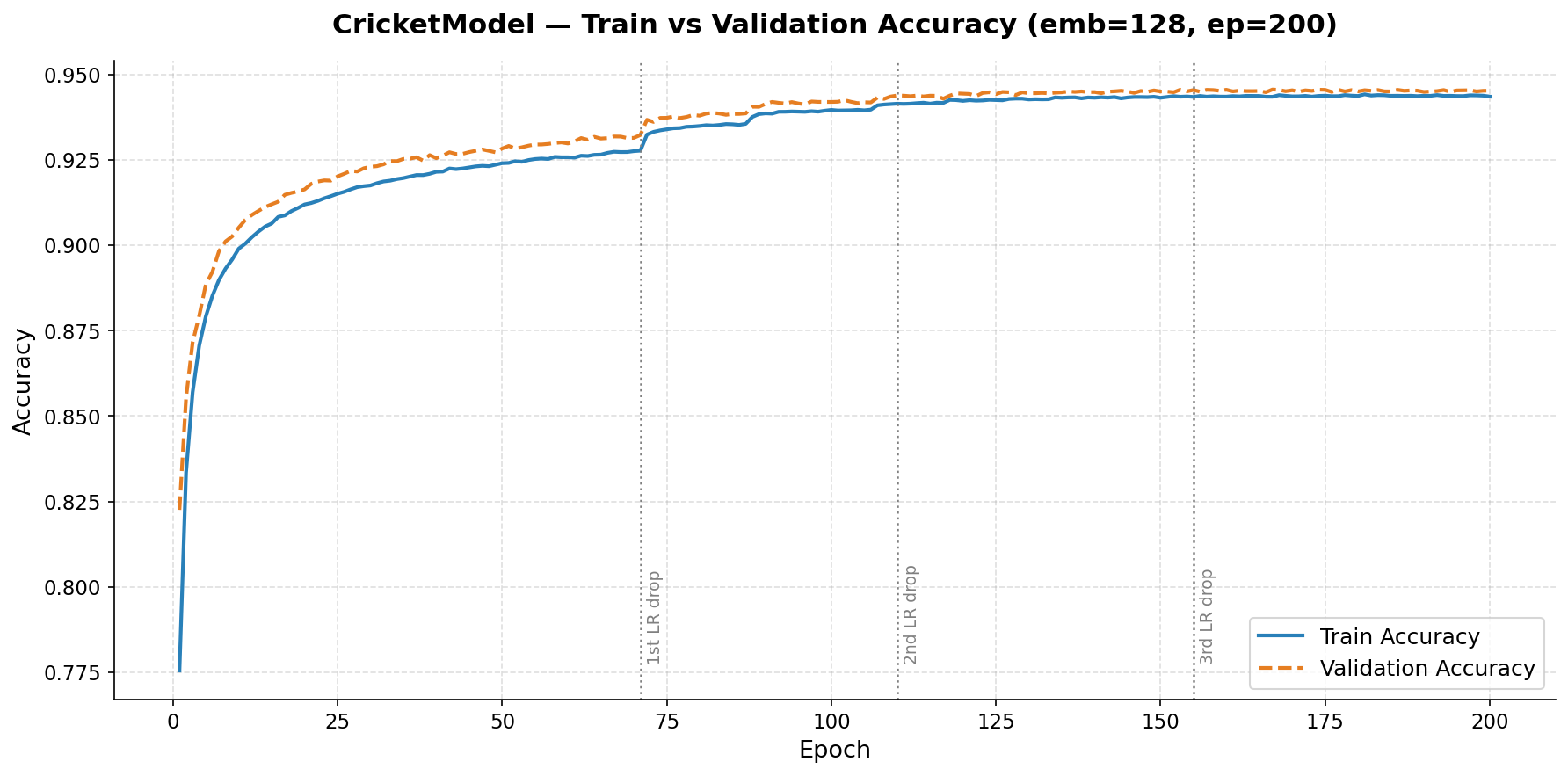
b) Train vs Validation Accuracy improvement in final round
EPOCH Optimization — Experiment Log
| # | Change Made | Val Acc | Delta | Verdict | Remarks |
|---|---|---|---|---|---|
| 1 | Baseline: emb=16, ep=20, lr=0.01 | 0.8876 | — | Baseline | Starting point. 16-dim embeddings for 7,785 batsmen + 5,742 bowlers is severely under-capacity. |
| 2 | epochs: 20 → 40 (emb=16) | 0.8937 | +0.0061 | ❌ REJECT | More epochs alone not enough — embedding bottleneck is the real constraint. |
| 3 | emb: 16 → 32, epochs=40 | 0.9157 | +0.0281 | ✅ ACCEPT | Biggest single jump (+2.81%). Doubling embedding capacity gave the model enough room to represent player identities. |
| 4 | emb: 32 → 64, epochs=40 | 0.9297 | +0.0140 | ✅ ACCEPT | Scaling embedding further yielded another solid gain. Diminishing returns beginning to show. |
| 5 | emb: 64 → 128, epochs=80, lr=0.01 | 0.9369 | +0.0072 | ✅ ACCEPT | Good gain. LR scheduler fired at ep76 with only 4 epochs left — couldn’t fully exploit the reduction. |
| 6 | epochs: 80 → 100 (emb=128) | 0.9419 | +0.0050 | ❌ REJECT | 2nd LR drop just starting at ep95–100 when training ended. Model plateaued at 0.9419. |
| 7 | epochs: 100 → 150 (emb=128) | 0.9450 | +0.0081 | ❌ REJECT | Progress, but just below the min_delta threshold. 3rd LR drop just beginning. |
| 8 | epochs: 150 → 200 (emb=128) | 0.9452 | +0.0083 | ✅ ACCEPT | 3rd LR scheduler drop fully exploited. Well-regularized (train_eval_gap = −0.0017). Final model. |
Key Findings
| Finding | Detail |
|---|---|
| Embedding dim was the biggest lever | Going 16→32→64→128 drove most of the accuracy gain (+4.93% combined) |
| LR scheduler is crucial but fires late | ReduceLROnPlateau (patience=3, factor=0.5) fires at ~ep71, ~ep110, ~ep155 — each firing gives ~+0.005 |
| Epochs must be long enough post-firing | Each LR drop needs ~40–50 epochs to propagate — that’s why ep=200 was needed |
| No overfitting throughout | train_eval_gap was always small and negative (−0.0017 to −0.0061), meaning BatchNorm+Dropout regularized well |
| lr=0.001 from random init causes regression | Tried lower LR early on — model under-converged. lr=0.01 with scheduler is the right combination |
Total improvement: 0.8876 → 0.9452 (+6.76%) across 8 experiments.
Here is the baseline versus the final experiment and comparison posted on Gist GitHub –Win Probability – Baseline vs Final Comparison
The final trained T20 Win Probability model had a validation accuracy of 0.9452 at which point I stoppd further experiments. This model was downloaded with all the necessary metadata which included the trained weights, the architecture config, and the standard scaler, which needs to be applied on any new data on which the model is actually applied. The trained T20 Win Probability DL Model was applied the three T20 matches in the latest ICC T20 World Cup held this year from Feb 07,206 to Mar 8, 2026.
The ball-by-ball Win probability for each team in the T20 match is computed in the charts below. There will be two charts for each of the matches.
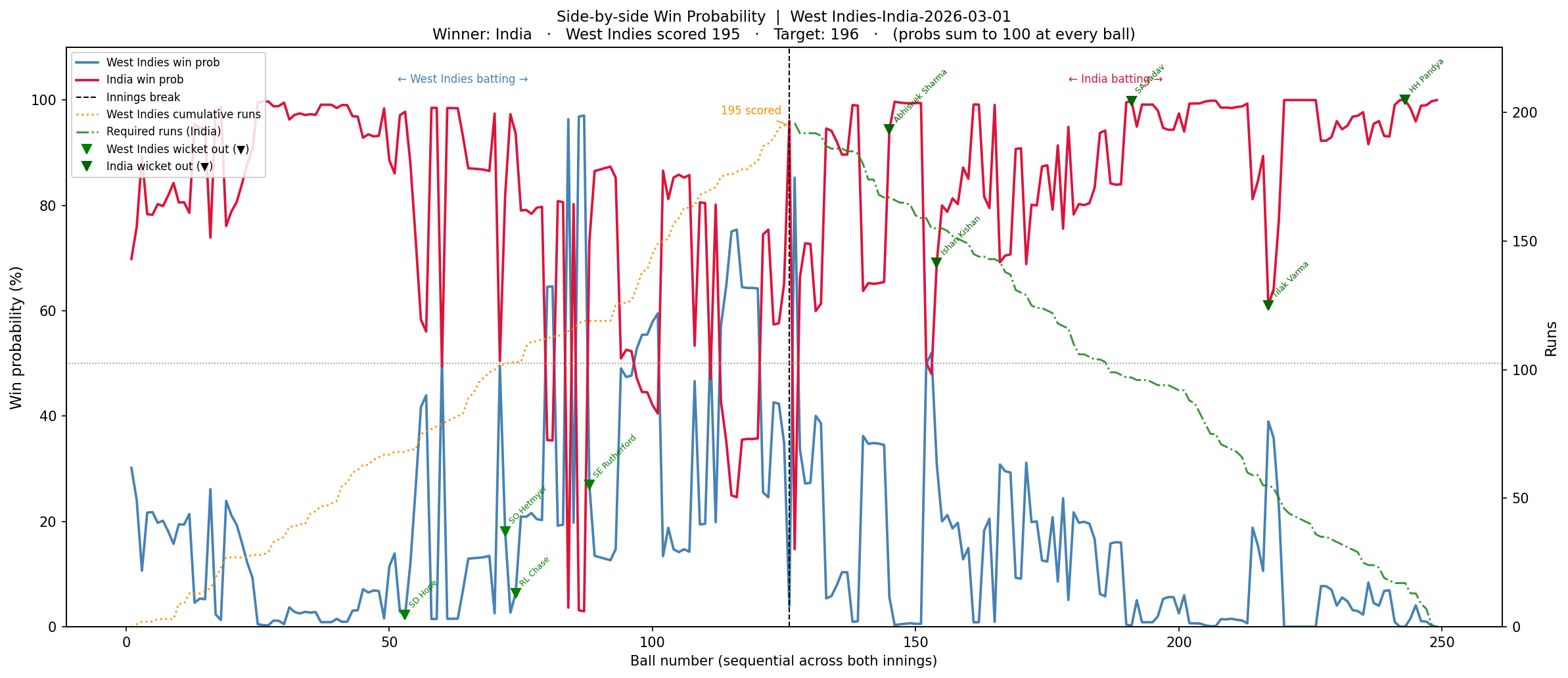
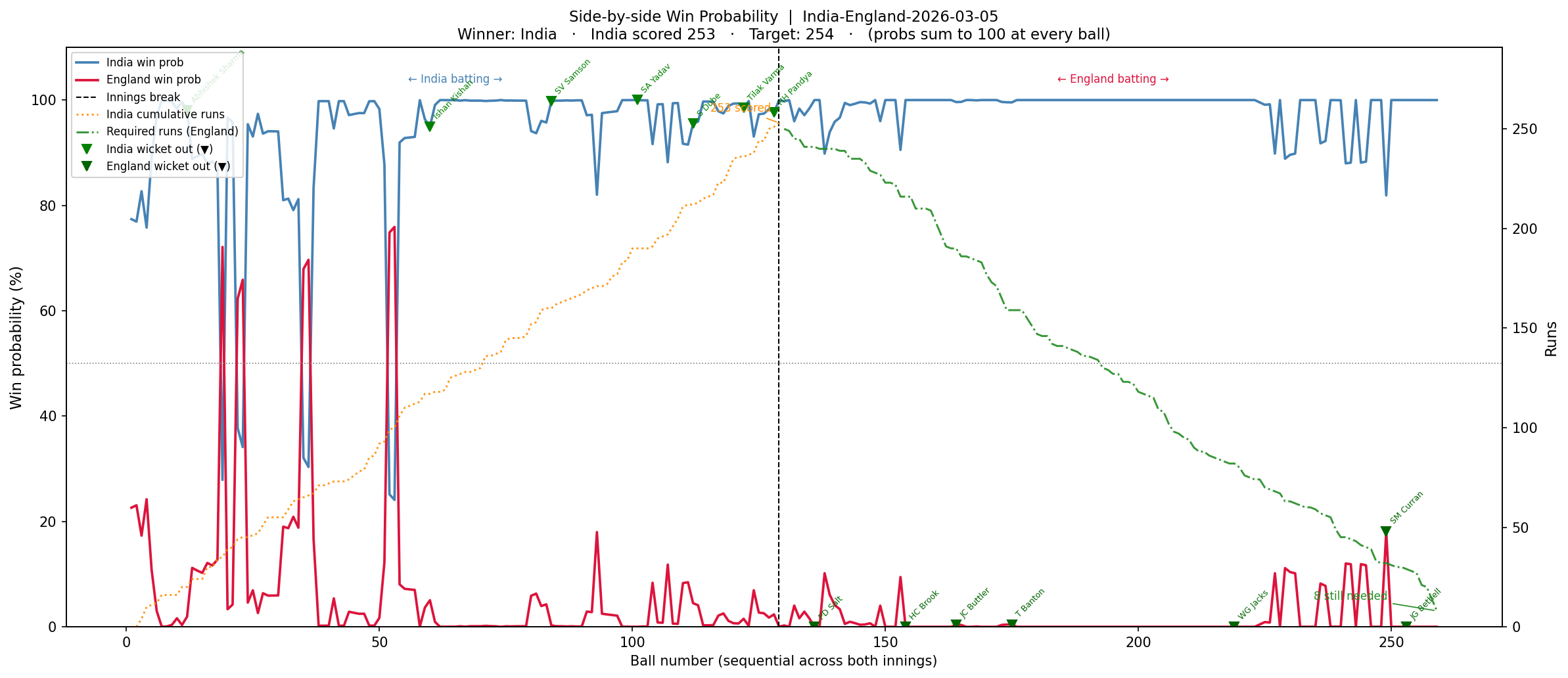
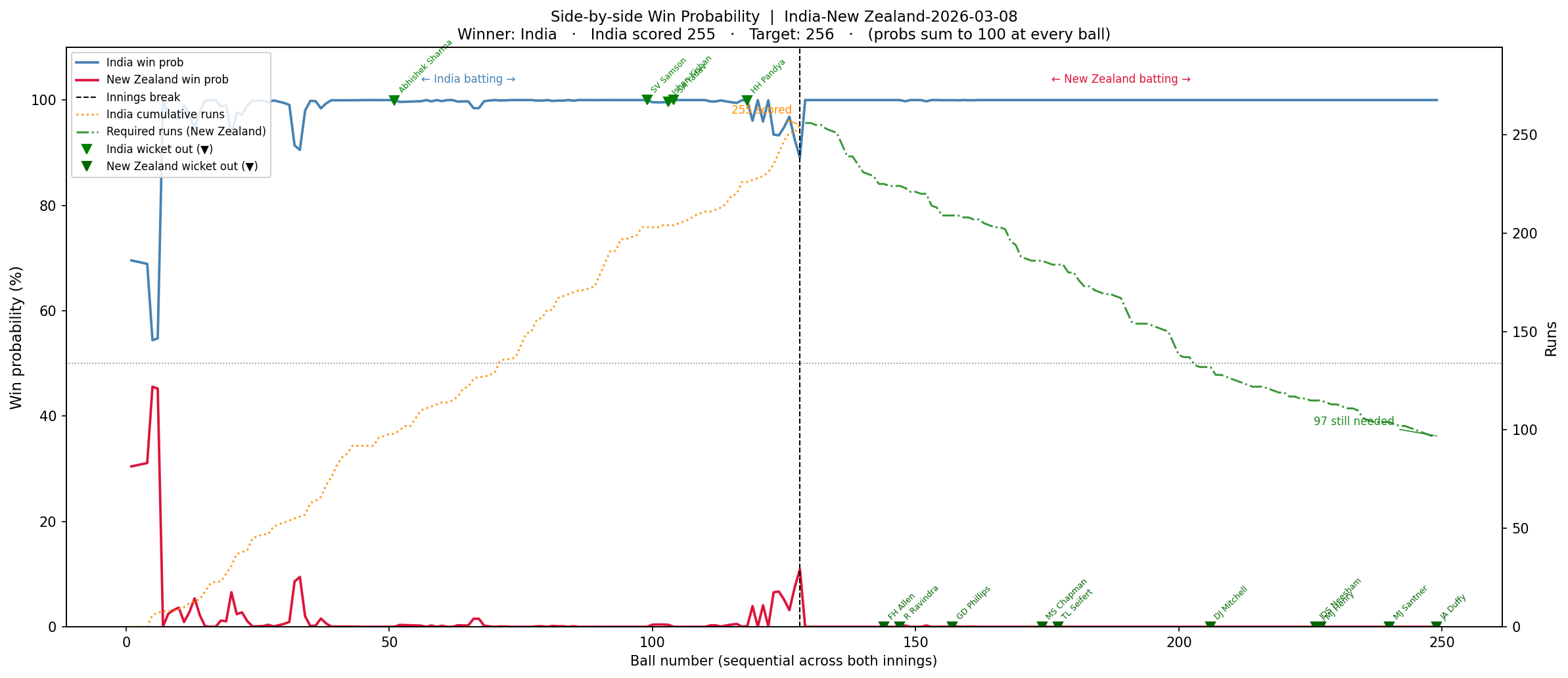
a) Win Probability- Side-by-side chart : The first chart is a side-by-side Win Probability Analysis where the win probability of each team will be computed using the DL model on a ball-by-ball basis. The win probability of the other team is just 100 minus the win probability of the first team.
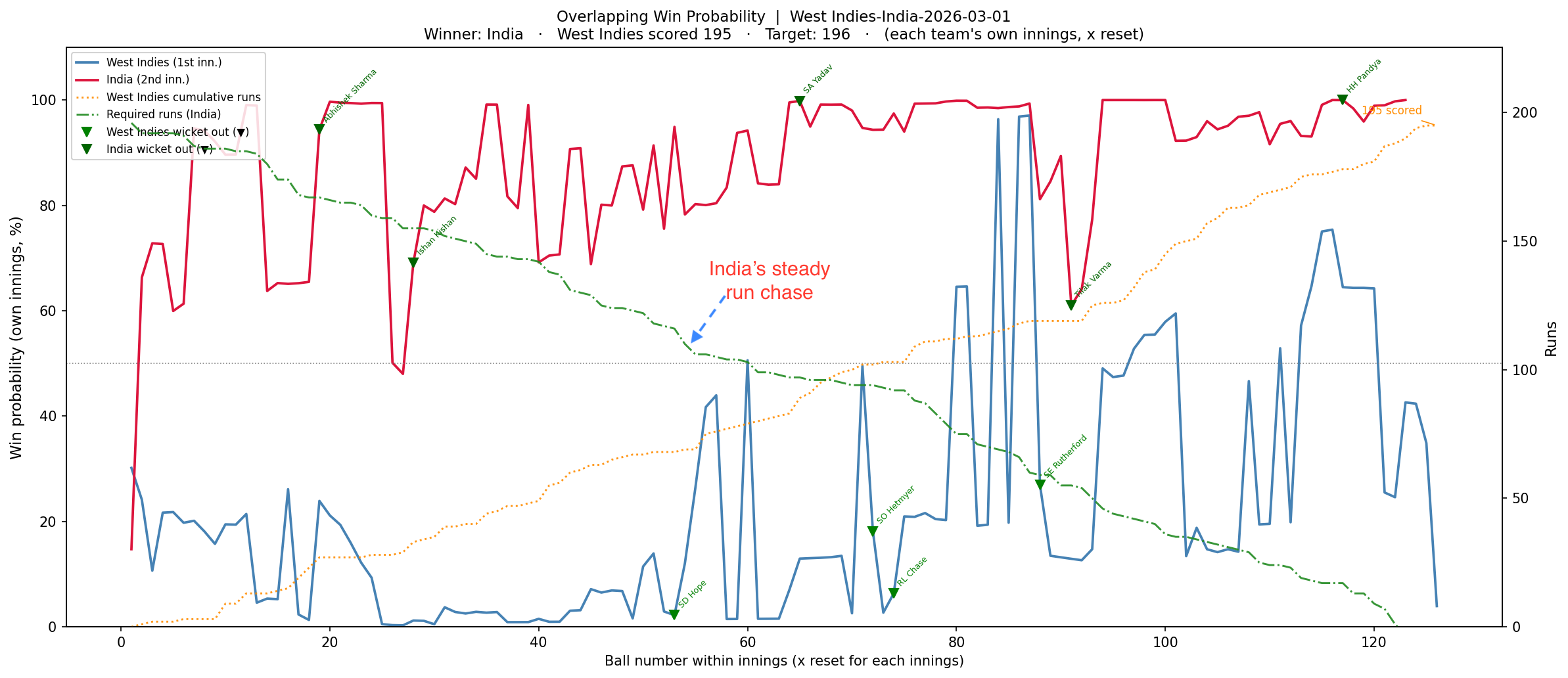
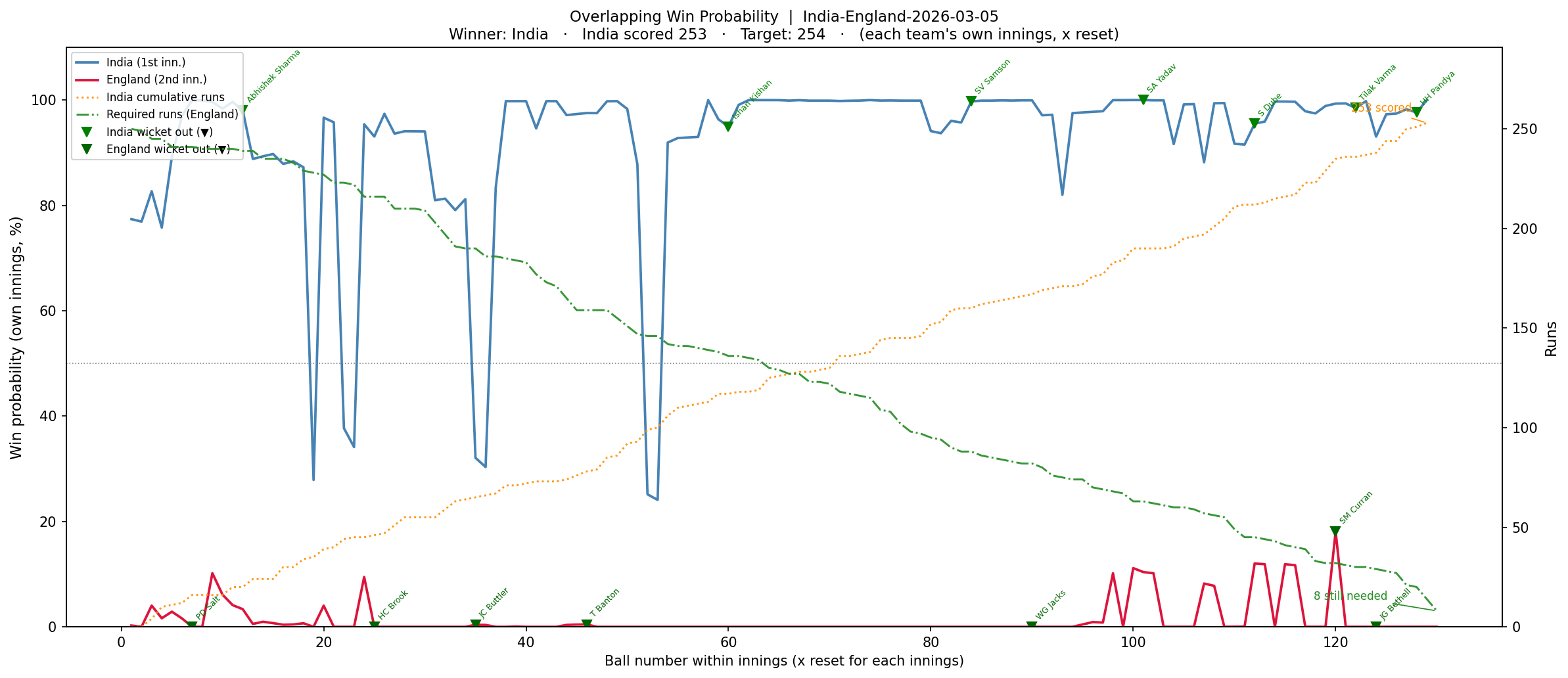
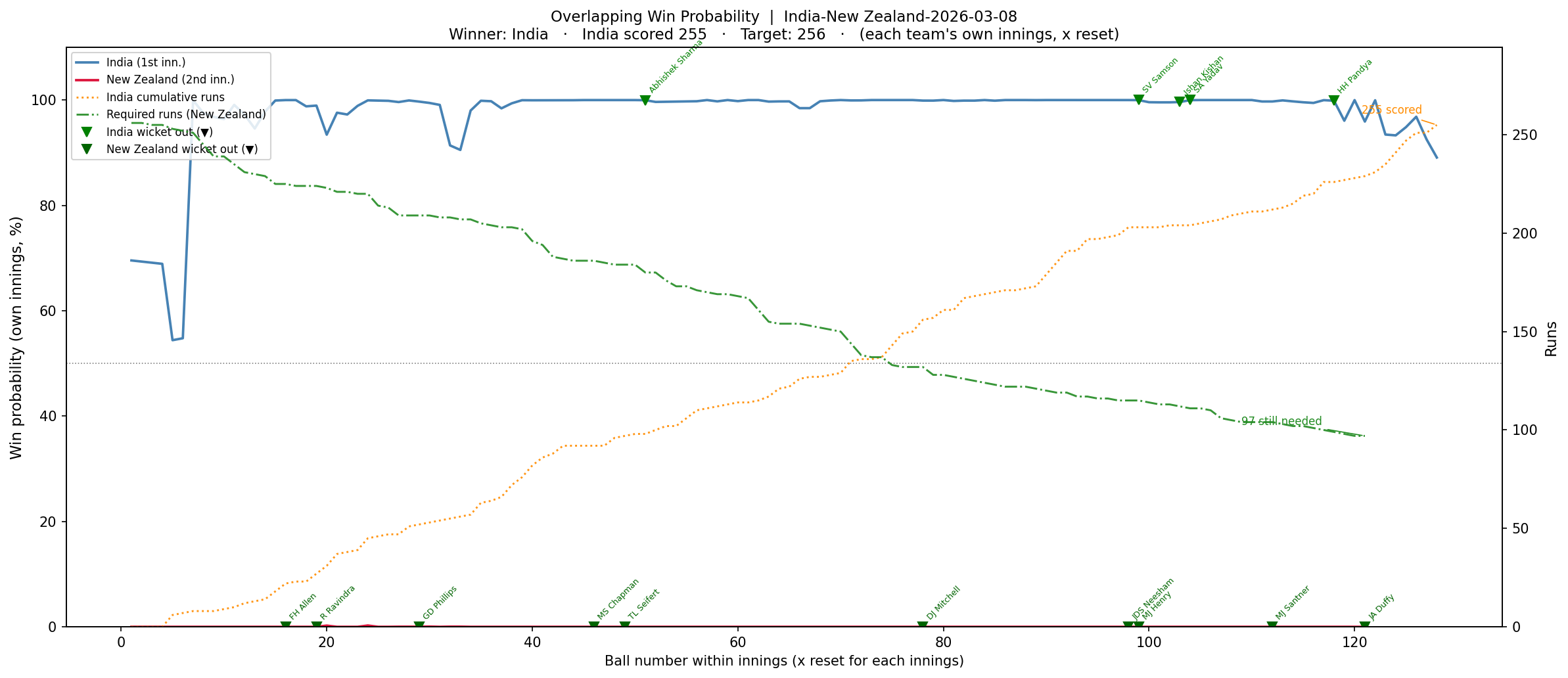
b) Win Probability – Overlapping chart : This chart will be computed using the Deep Learning model for each team independently on a ball-by-ball basis, and then both the probabilities will be super-imposed on one another so that we can see how the probability changed and whether the second team, which had to chase a total, actually was able to do so. If it could, then the win probability would actually exceed the the first team with Win Probability
I will be taking the final three matches of this ICC World Cup in 2026 namely to use the Win Proability Model against
1) West Indies vs India – Quarter Finals – Winner – India (1 Mar 2026)
In this this match, Sanju Samson stood like a rock and played a well-paced innings and chased the target comfortably scoring 97 runs not out.
a) Side-by-side chart
b) Overlapping chart
2) India vs England – Semi Finals – Winner- India (5 Mar 2026)
India set a sizable target of 253 with good contributions from Sanju Samsom, Shivam Dube and Ishan Kishan
a) Side-by-side chart
b) Overlapping chart
3) India vs New Zealand – Finals – Winner – India (8 Mar 2026)
Put into bat first, India put up a mammoth total of 255 with contributions from Sanju Samson, Abhishek Sharma, Ishan Kishan, and Shivam Dube. New Zealand lost wickets regularly and could not keep up with the required run rate, which kept climbing ever so high, so it was never in contention
a) Side-by-side chart
b) Overlapping chart
Conclusion
It was quite interesting to see agentic protocol EPOCH work. Things have really changed these days, with the agents automatically making judgement calls on what would be hyper-parameter changes would result in better performance. I remember I had used Grid Search to optimise the DeepLearning algorithm, but it didn’t help much.
References
- EPOCH: An Agentic Protocol for Multi-Round System Optimization by Liu, Li, and Srikanth (2026)
Also see
To see all posts click Index of posts

