Fresh, and slightly dizzy, from my foray into Quantum Computing with IBM’s Quantum Experience, I now turn my attention to IBM’s Data Science Experience (DSE).
I am on the verge of completing a really great 3 module ‘Data Science and Engineering with Spark XSeries’ from the University of California, Berkeley and I have been thinking of trying out some form of integrated delivery platform for performing analytics, for quite some time. Coincidentally, IBM comes out with its Data Science Experience. a month back. There are a couple of other collaborative platforms available for playing around with Apache Spark or Data Analytics namely Jupyter notebooks, Databricks, Data.world.
I decided to go ahead with IBM’s Data Science Experience as the GUI is a lot cooler, includes shared data sets and integrates with Object Storage, Cloudant DB etc, which seemed a lot closer to the cloud, literally! IBM’s DSE is an interactive, collaborative, cloud-based environment for performing data analysis with Apache Spark. DSE is hosted on IBM’s PaaS environment, Bluemix. It should be possible to access in DSE the plethora of cloud services available on Bluemix. IBM’s DSE uses Jupyter notebooks for creating and analyzing data which can be easily shared and has access to a few hundred publicly available datasets
Disclaimer: This article represents the author’s viewpoint only and doesn’t necessarily represent IBM’s positions, strategies or opinions
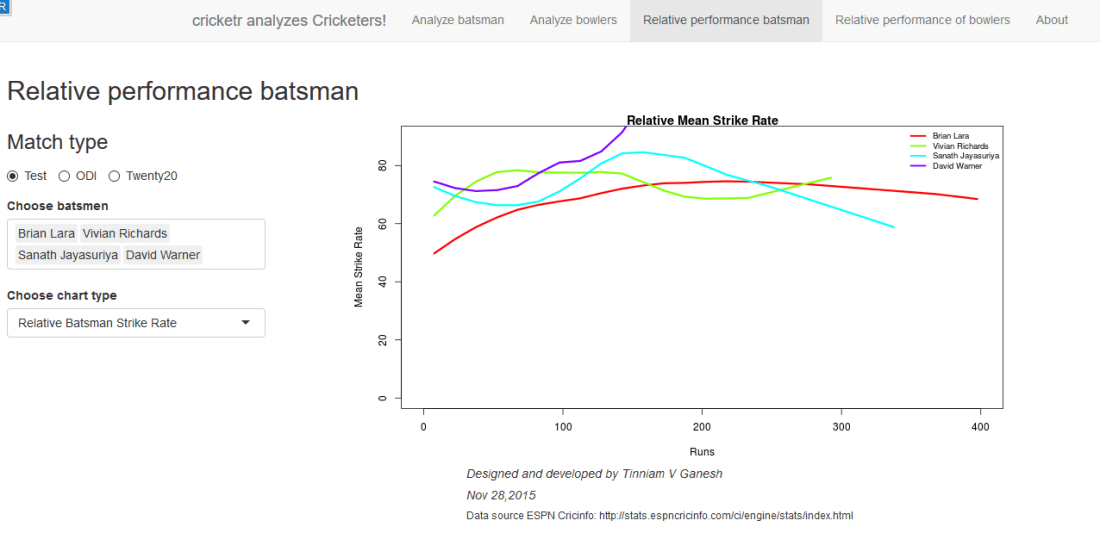
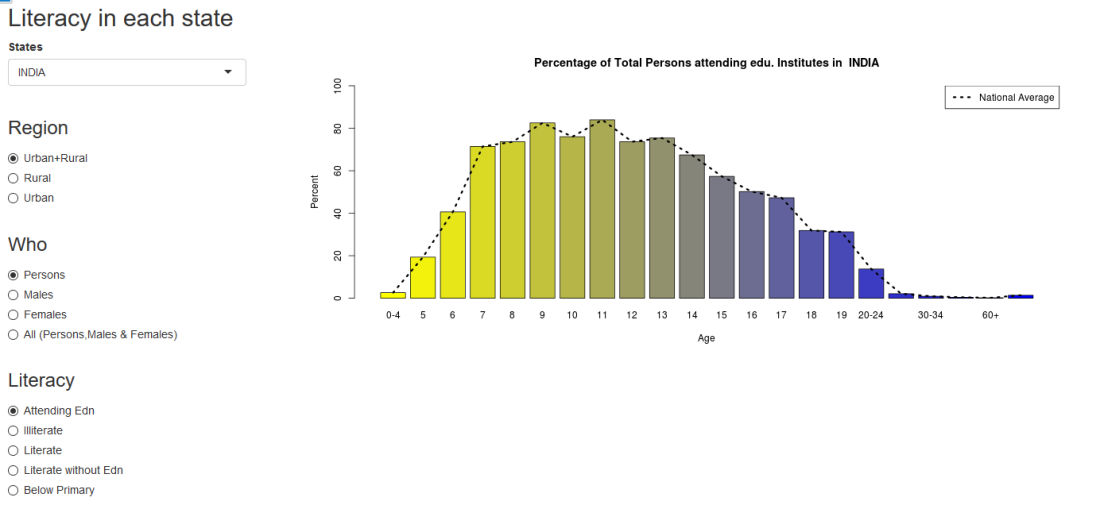
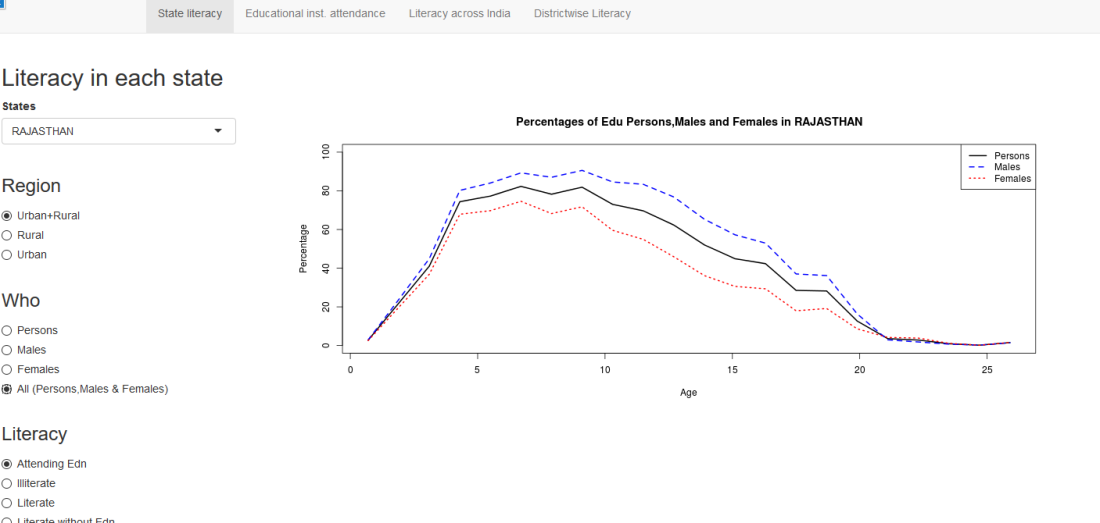
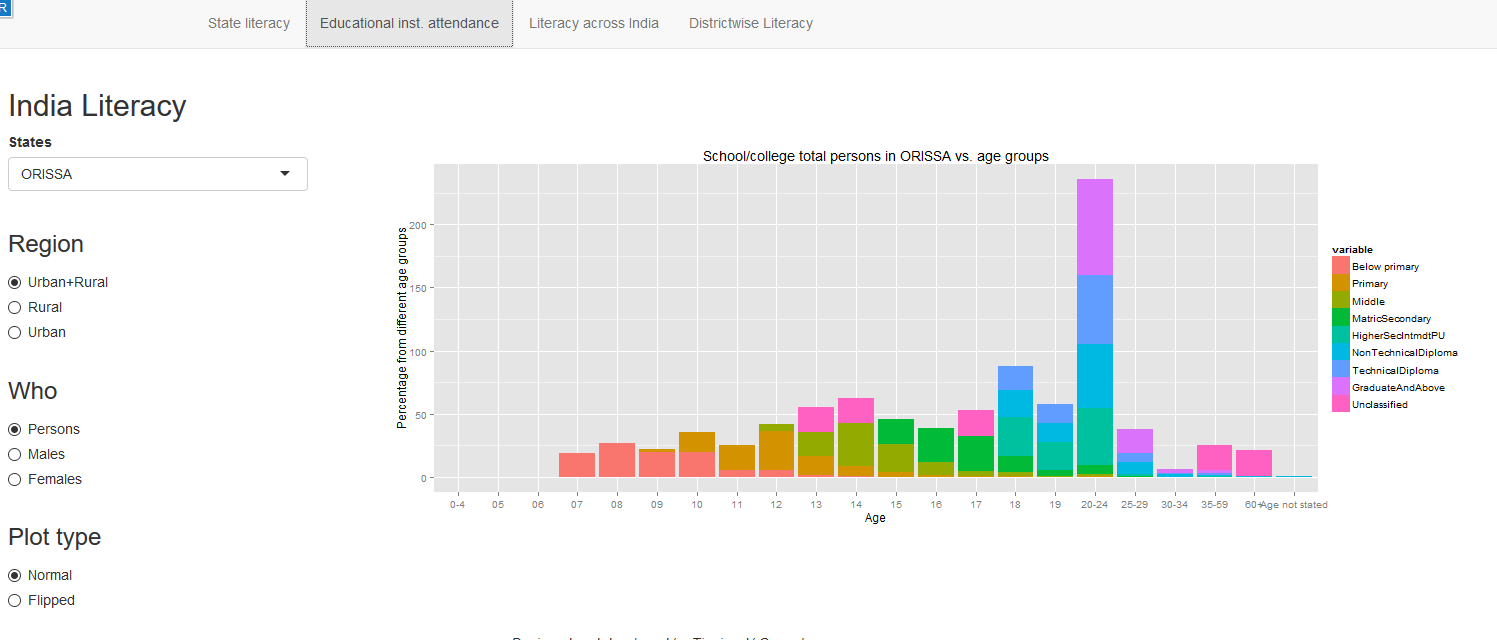
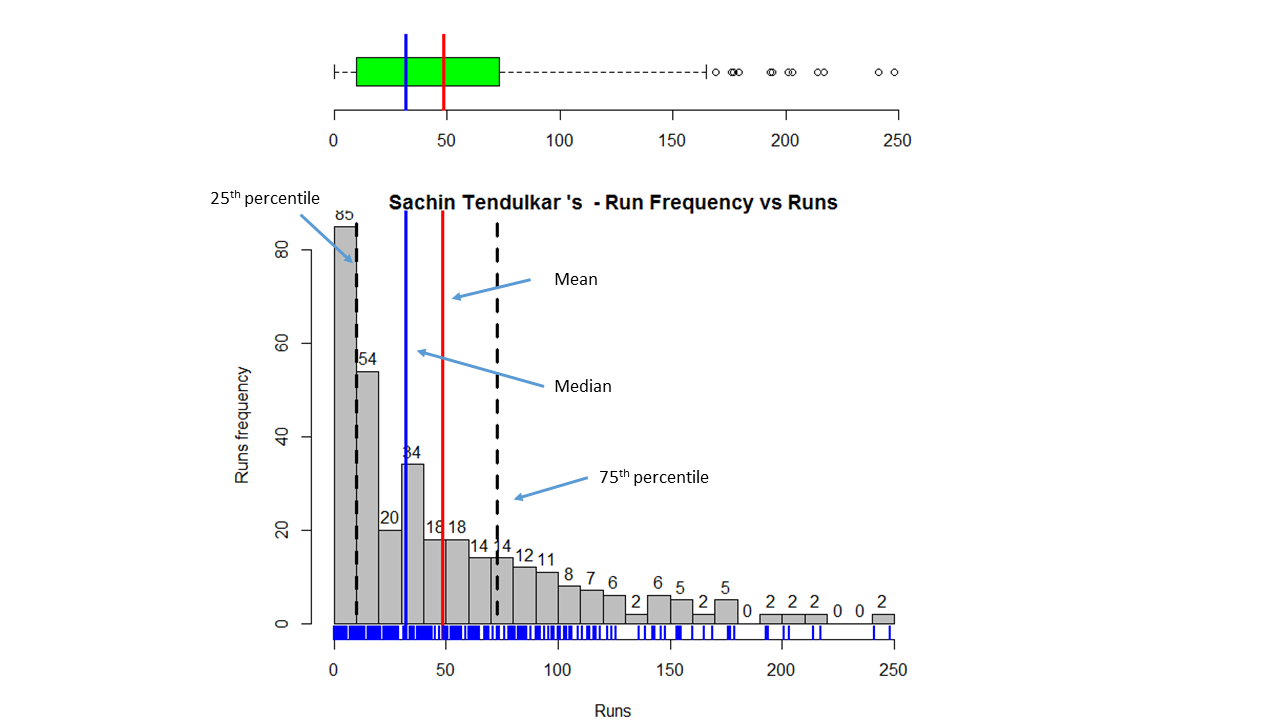
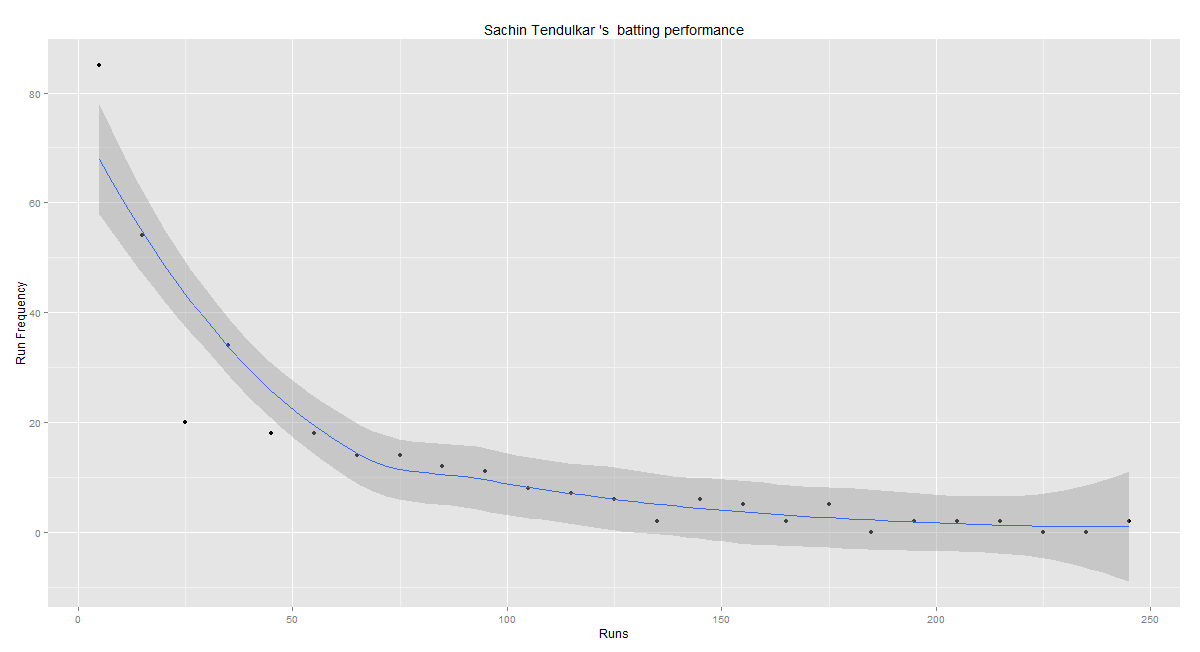
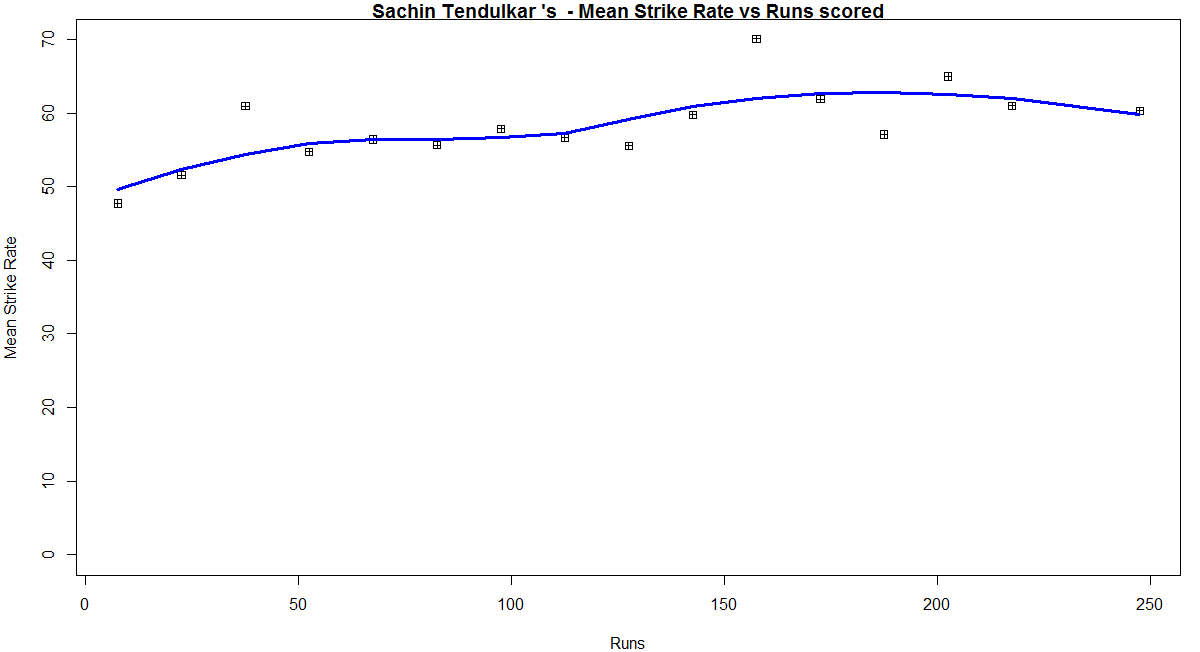
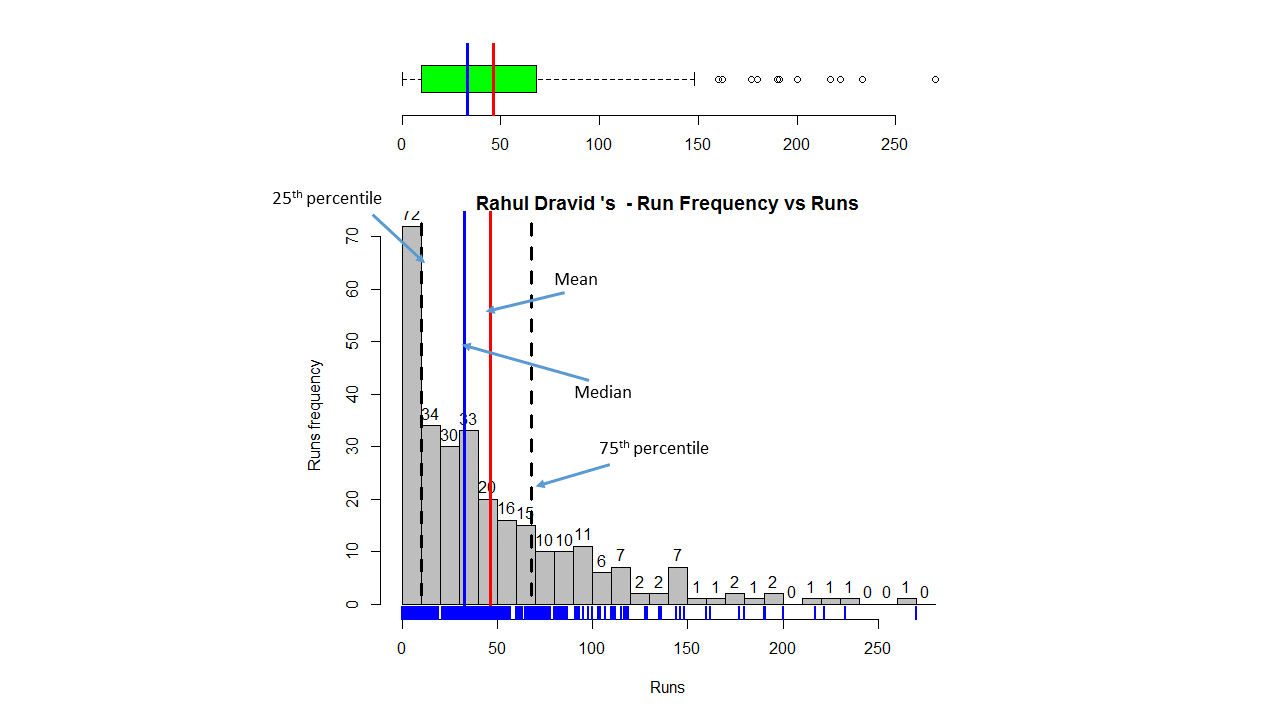
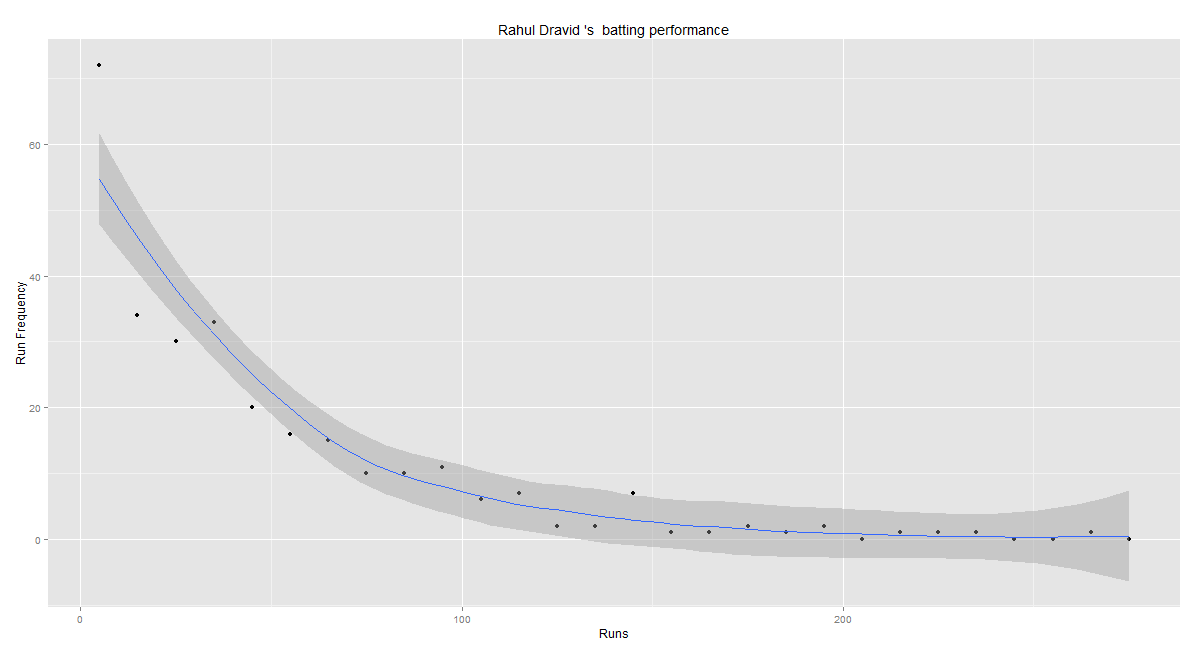
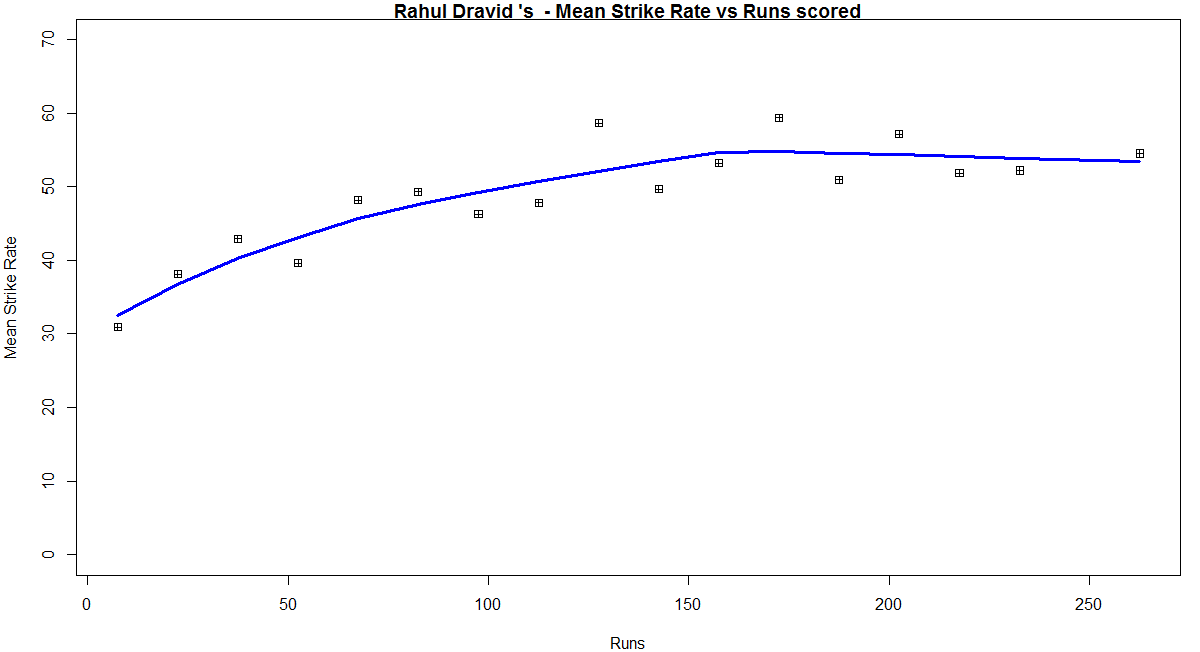
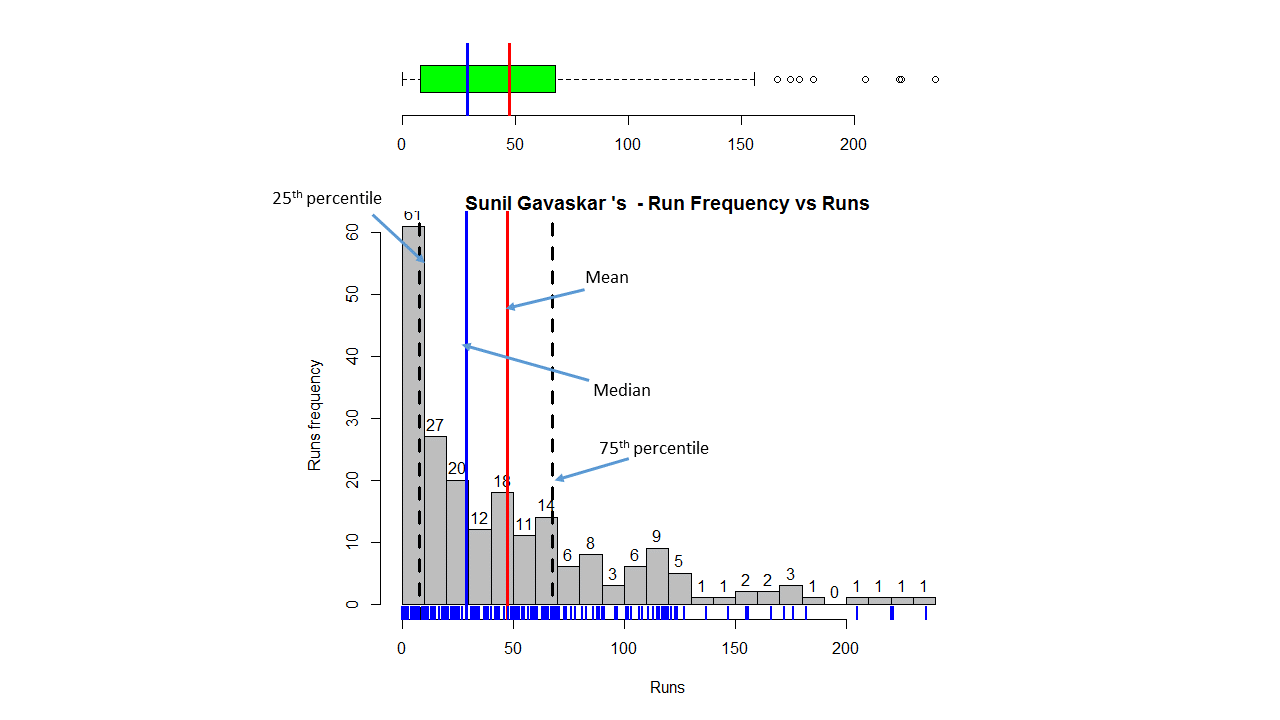
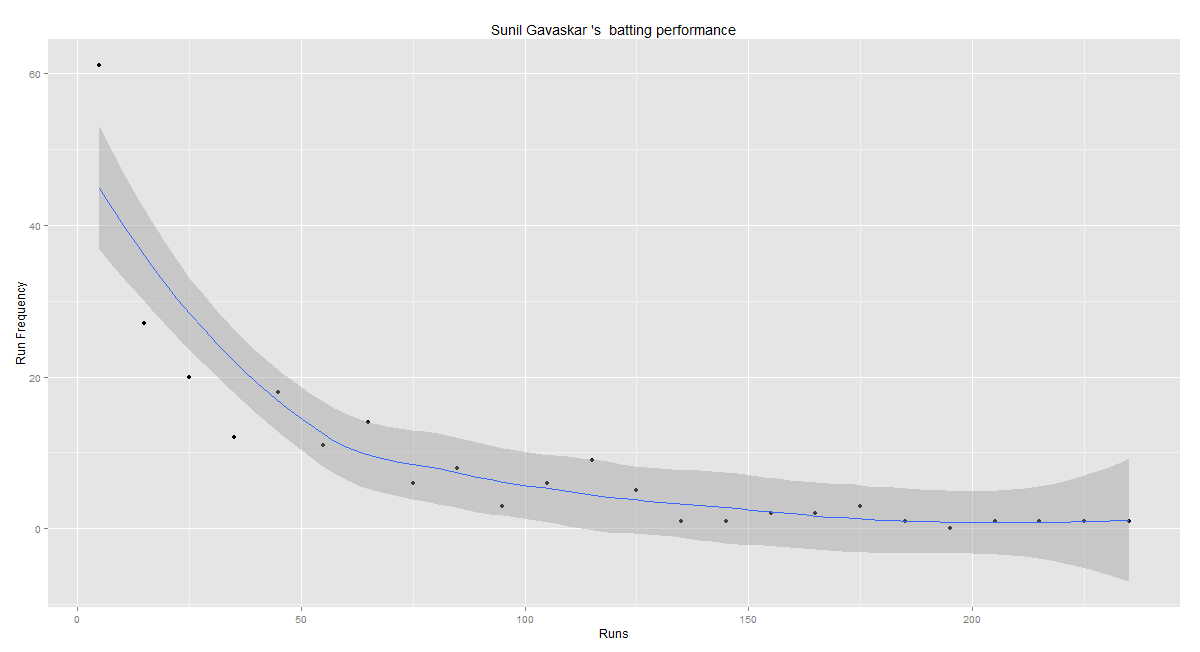
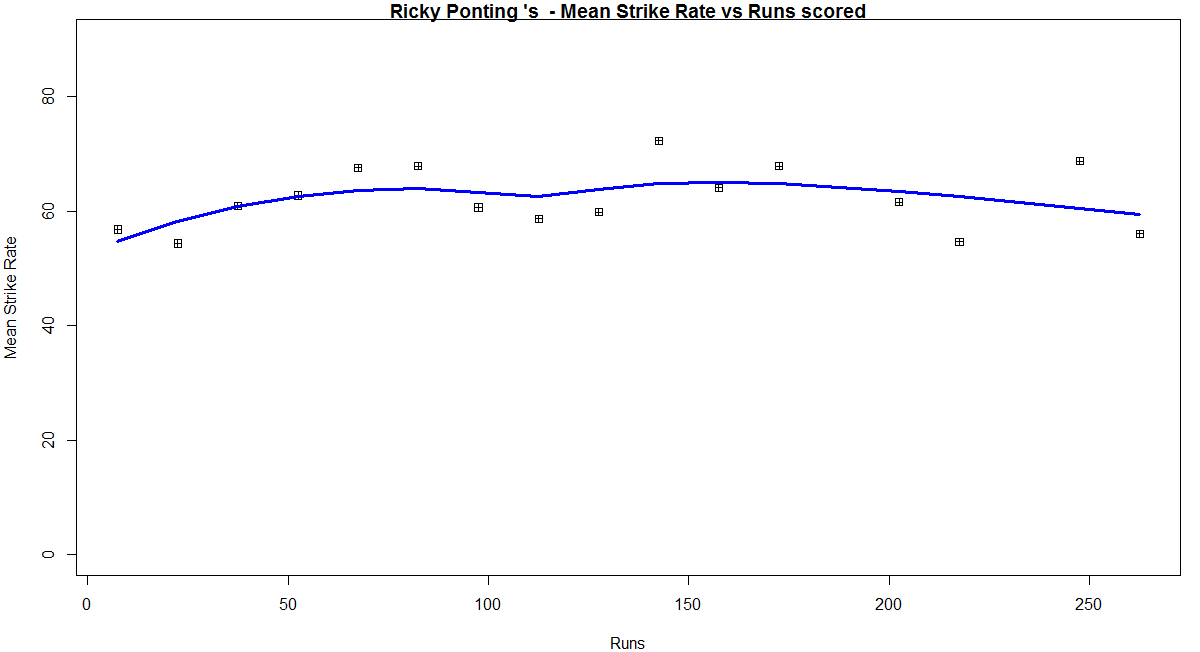
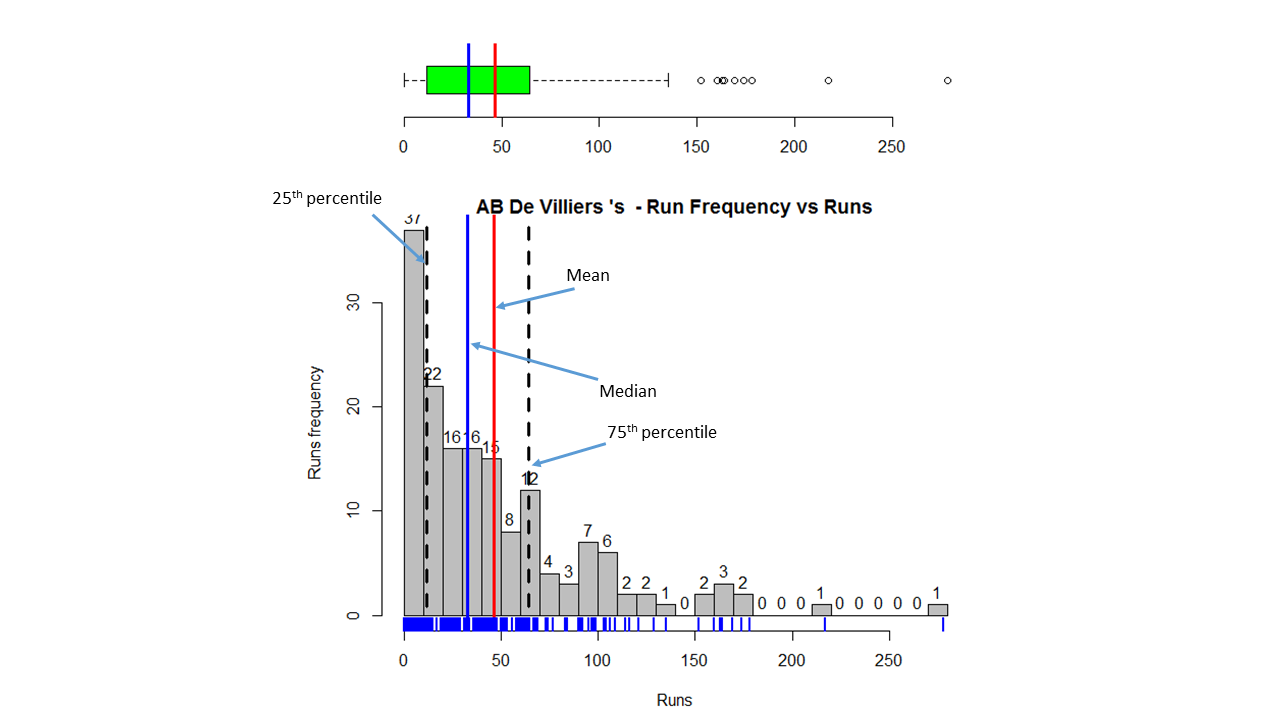
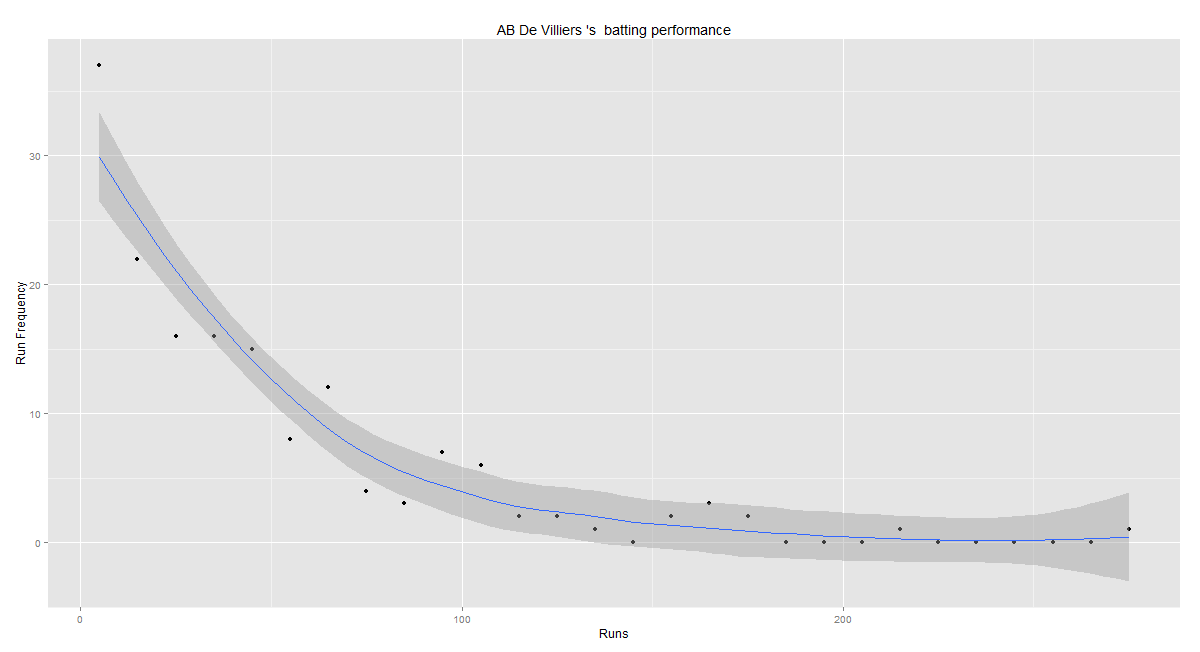
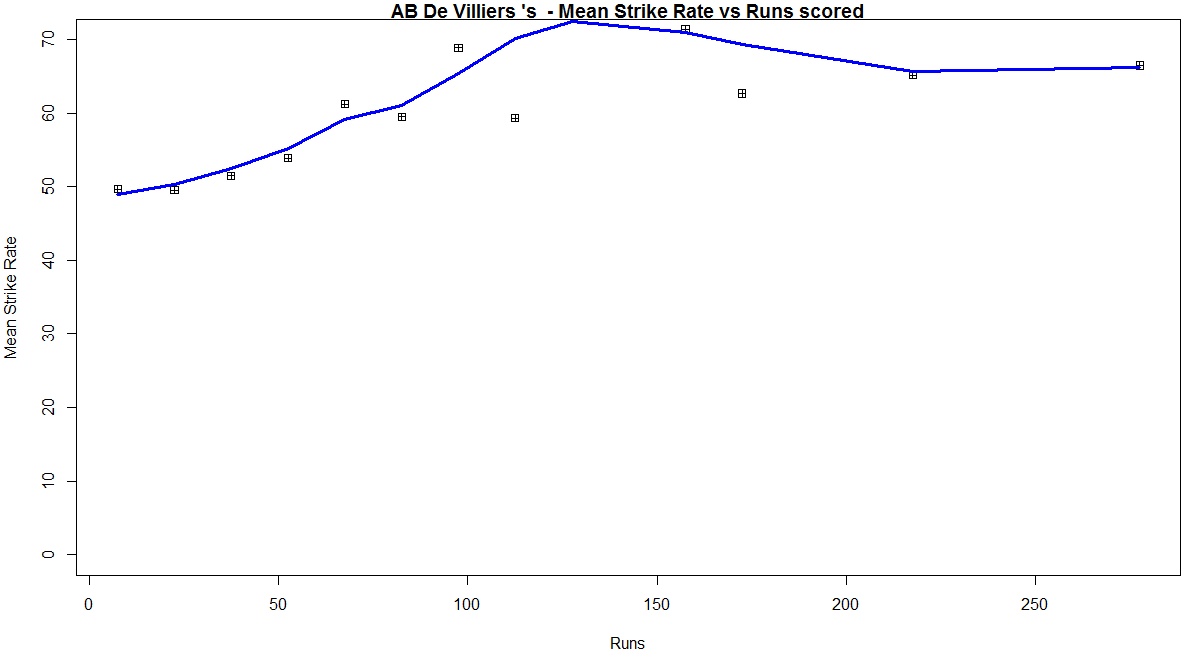
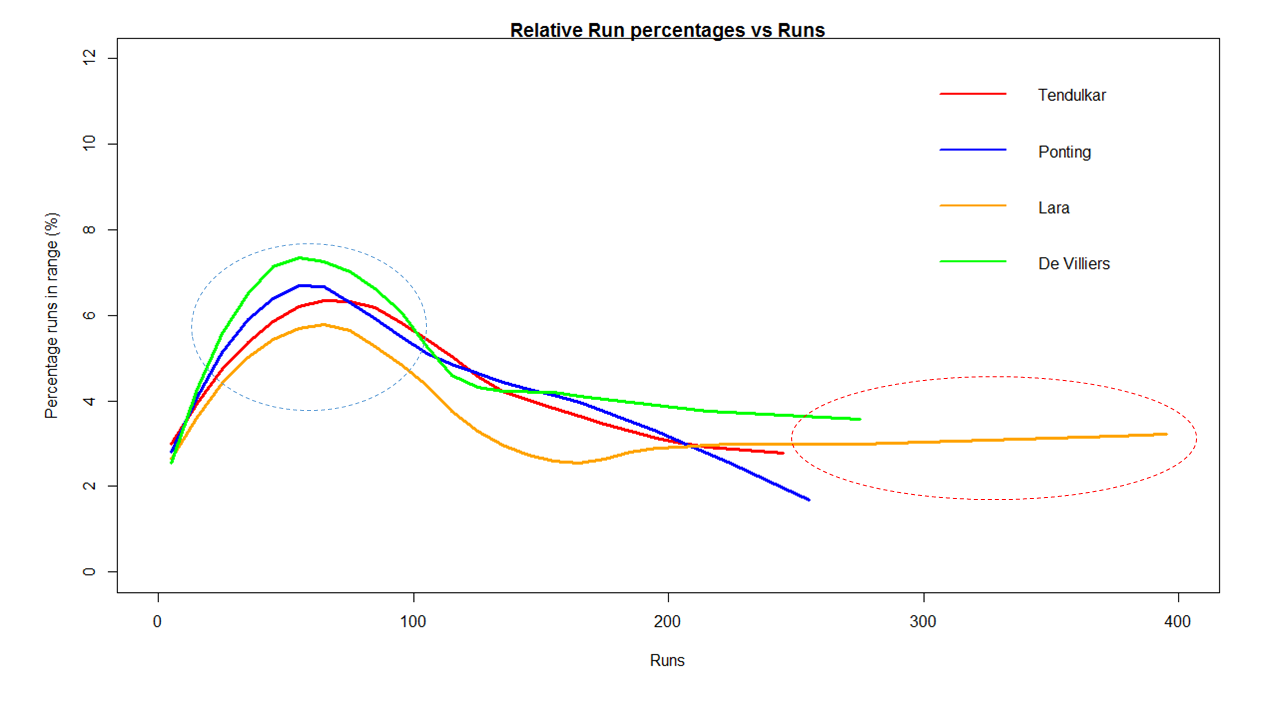
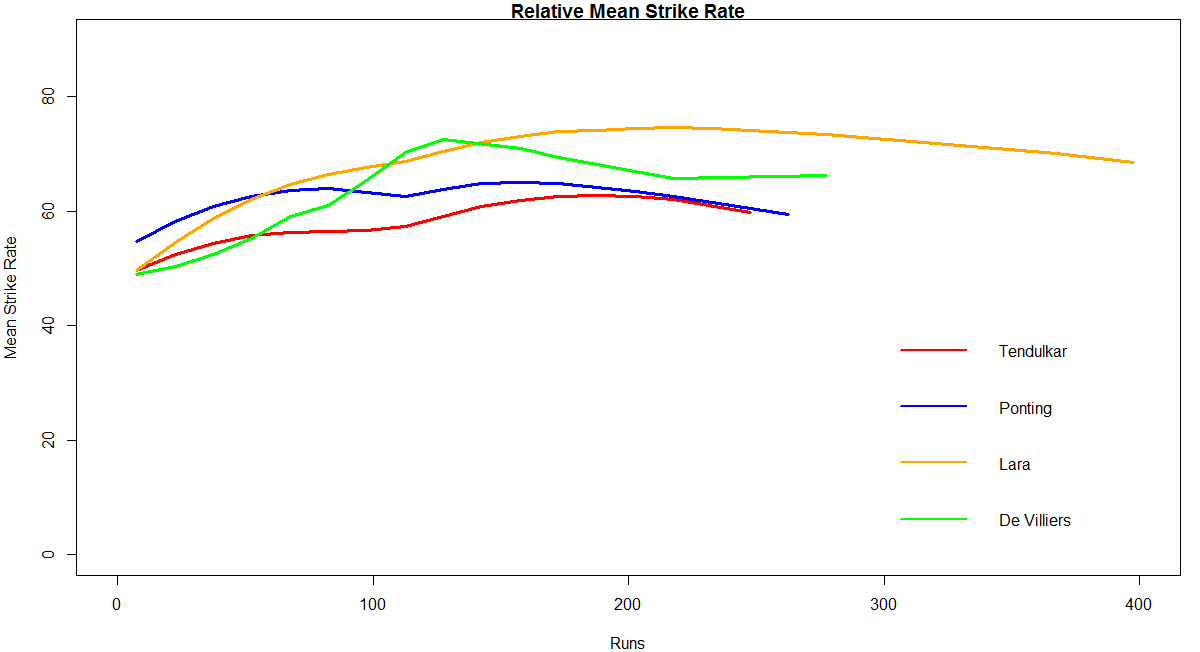
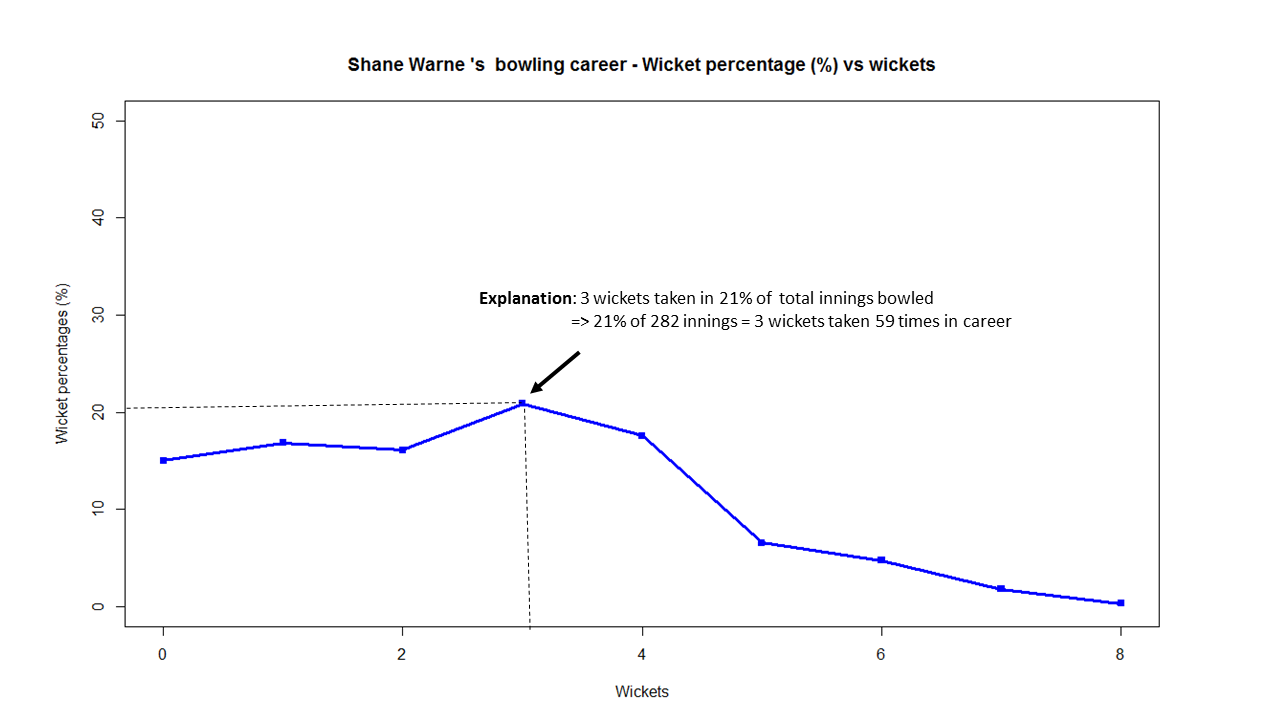
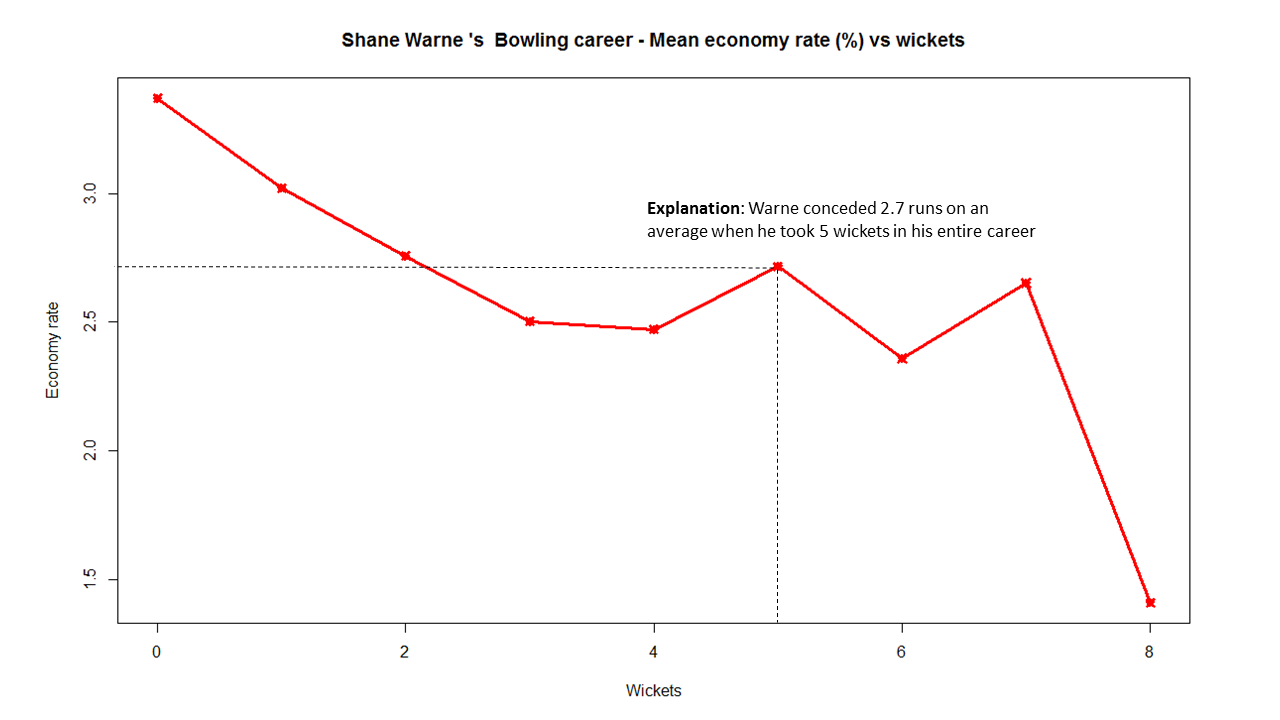
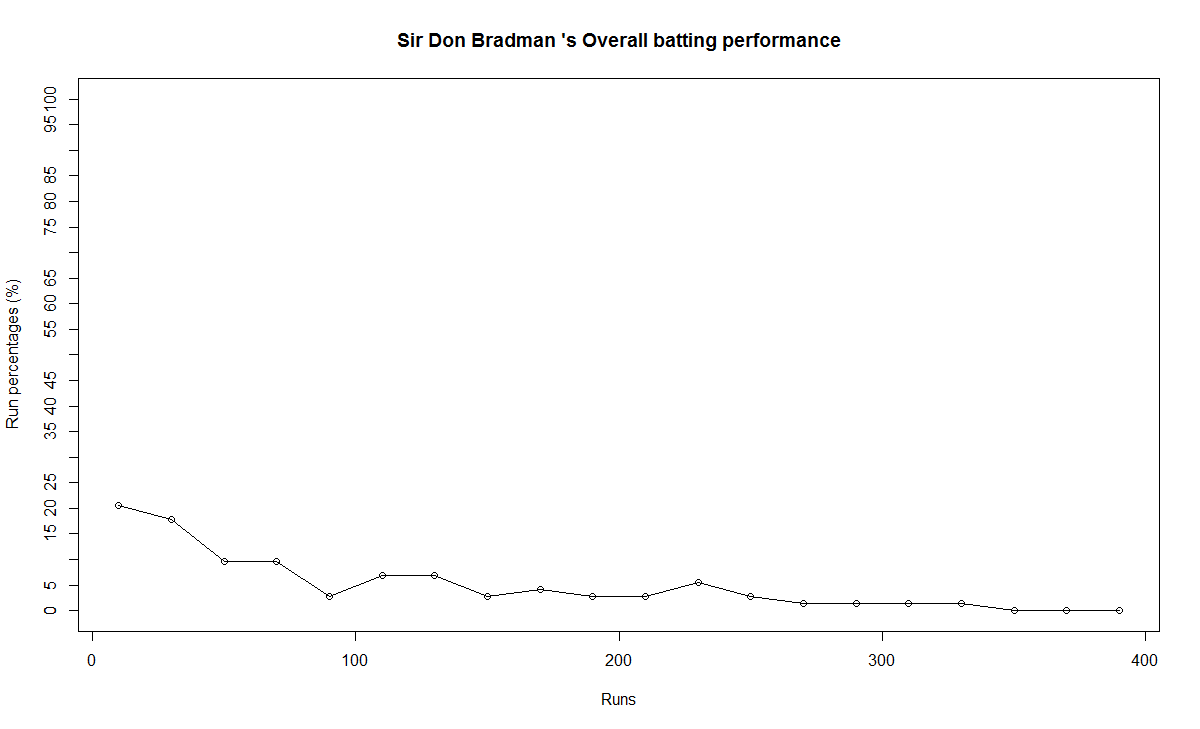
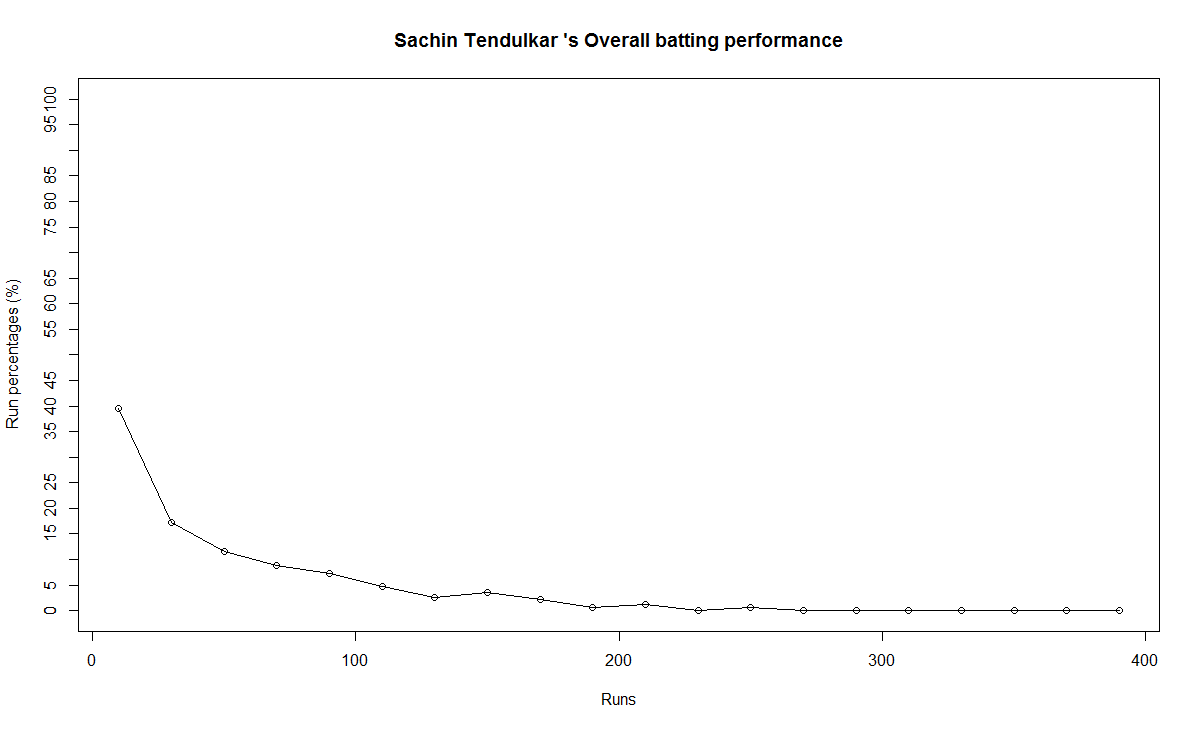
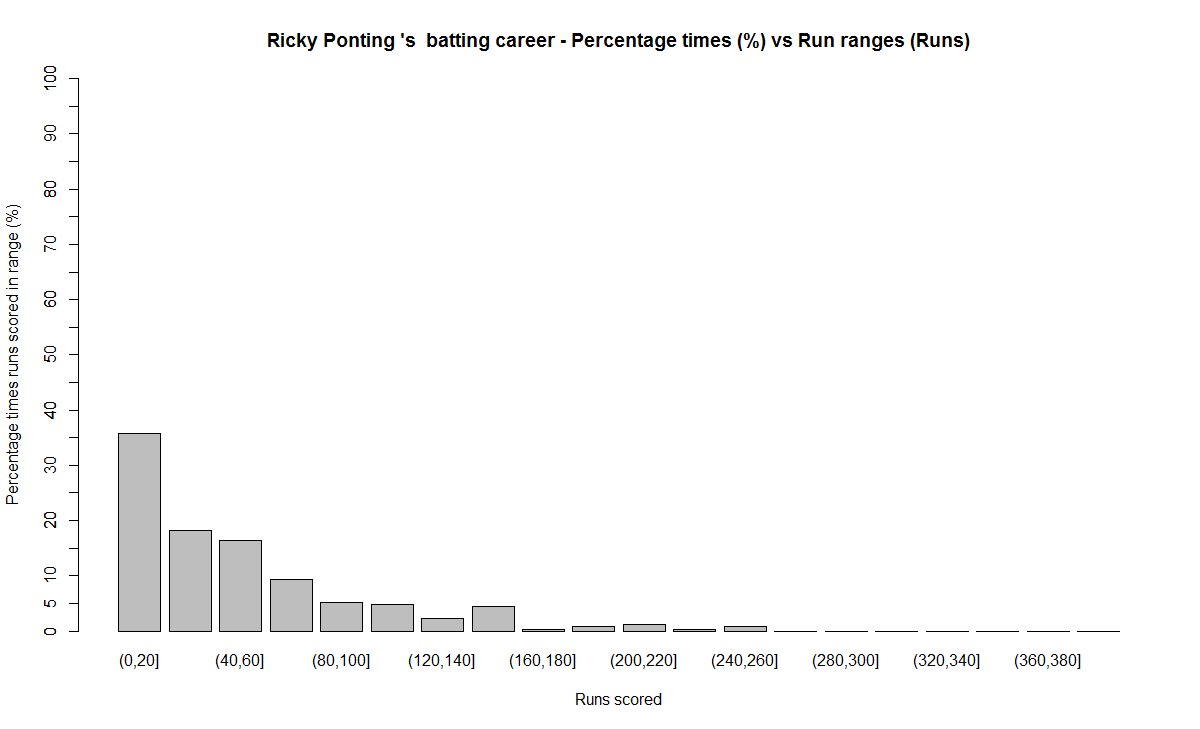
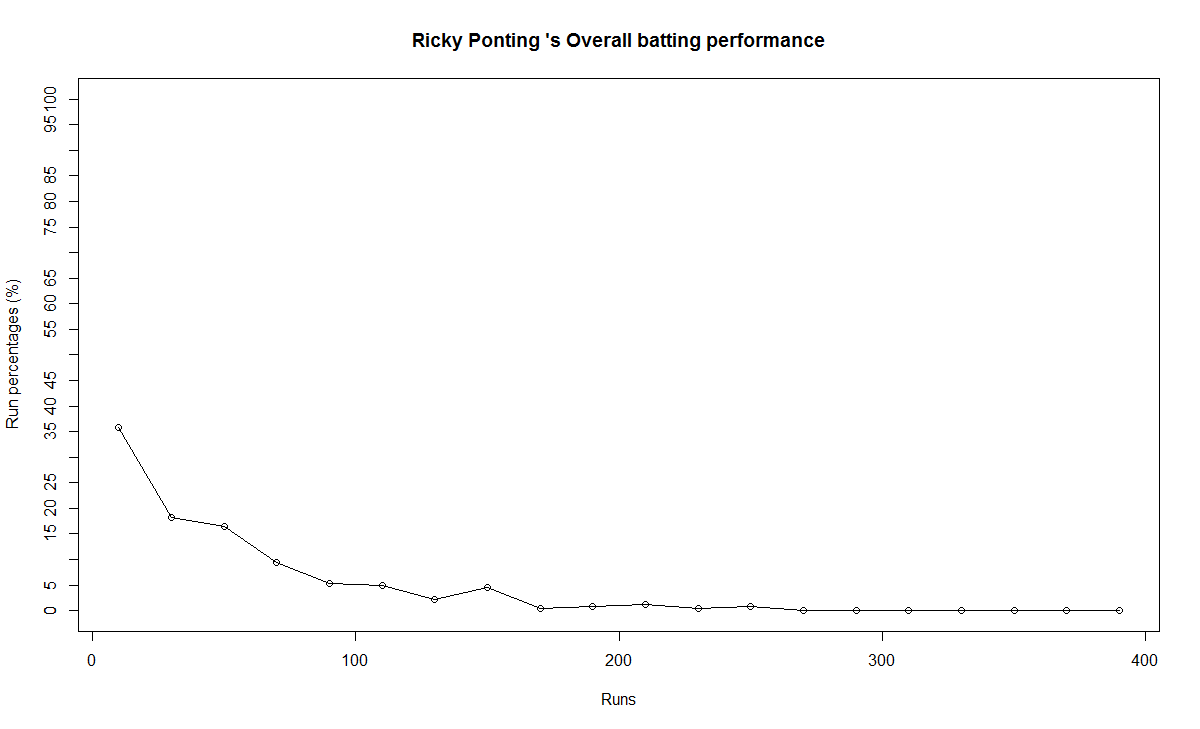
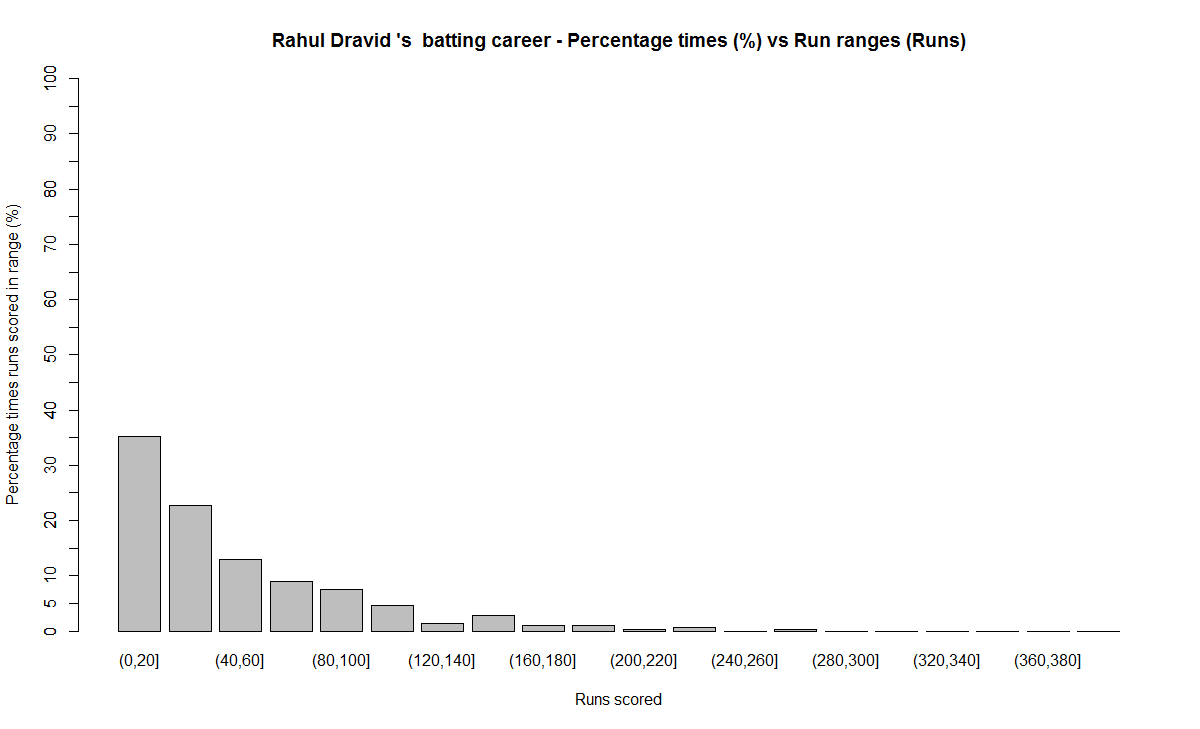
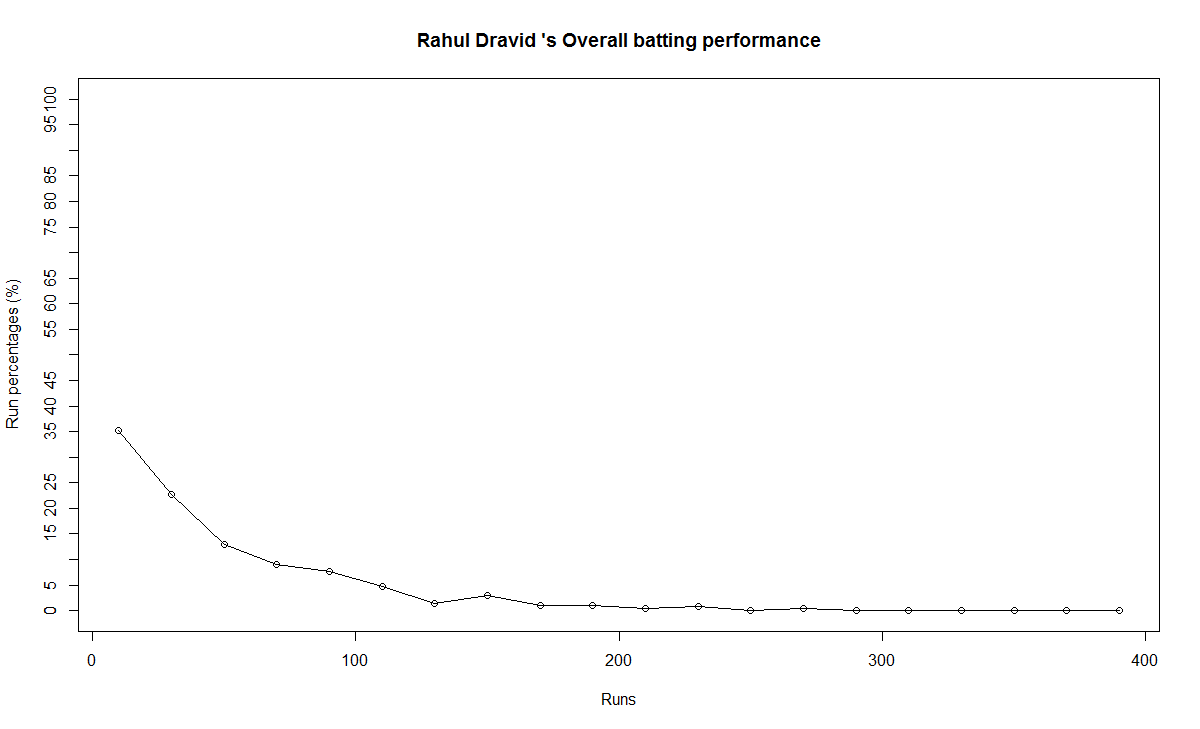
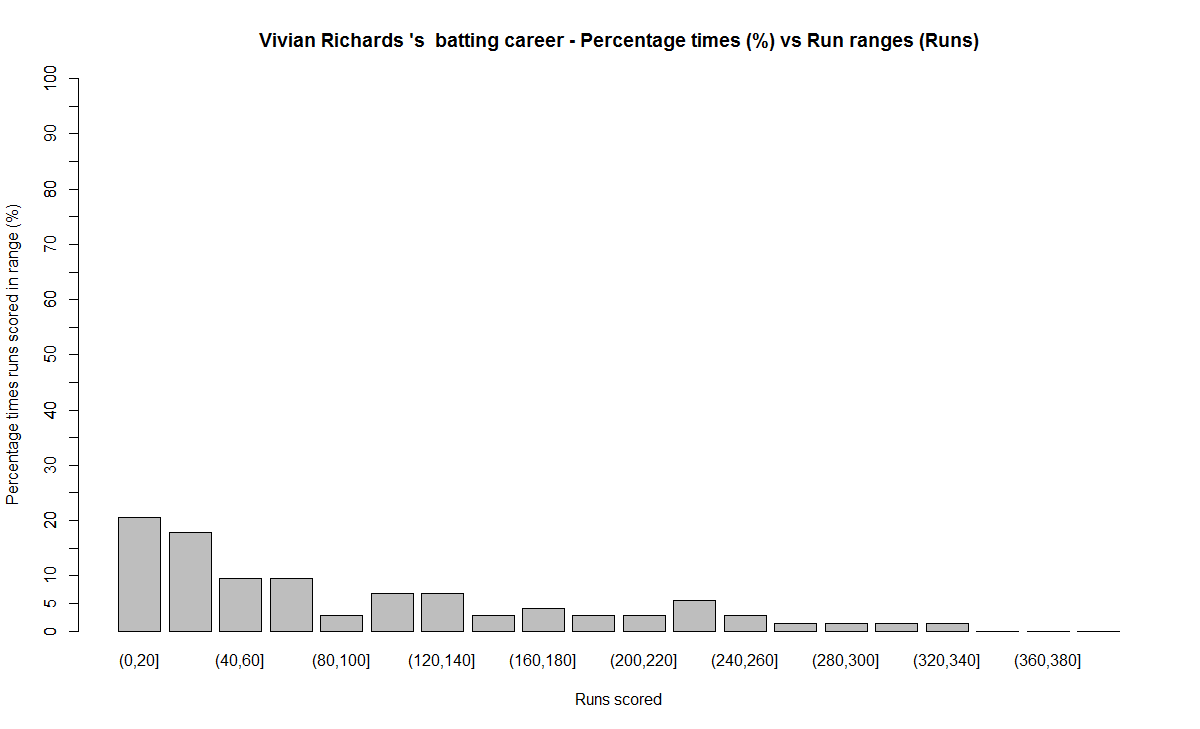
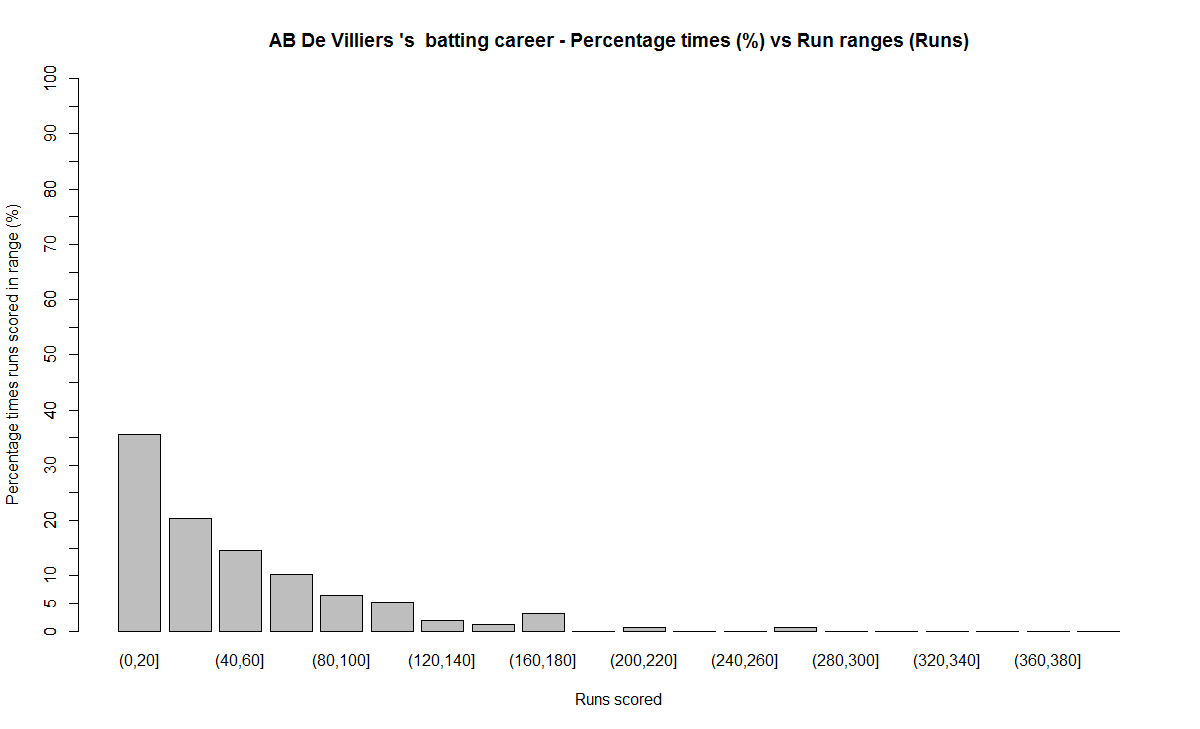
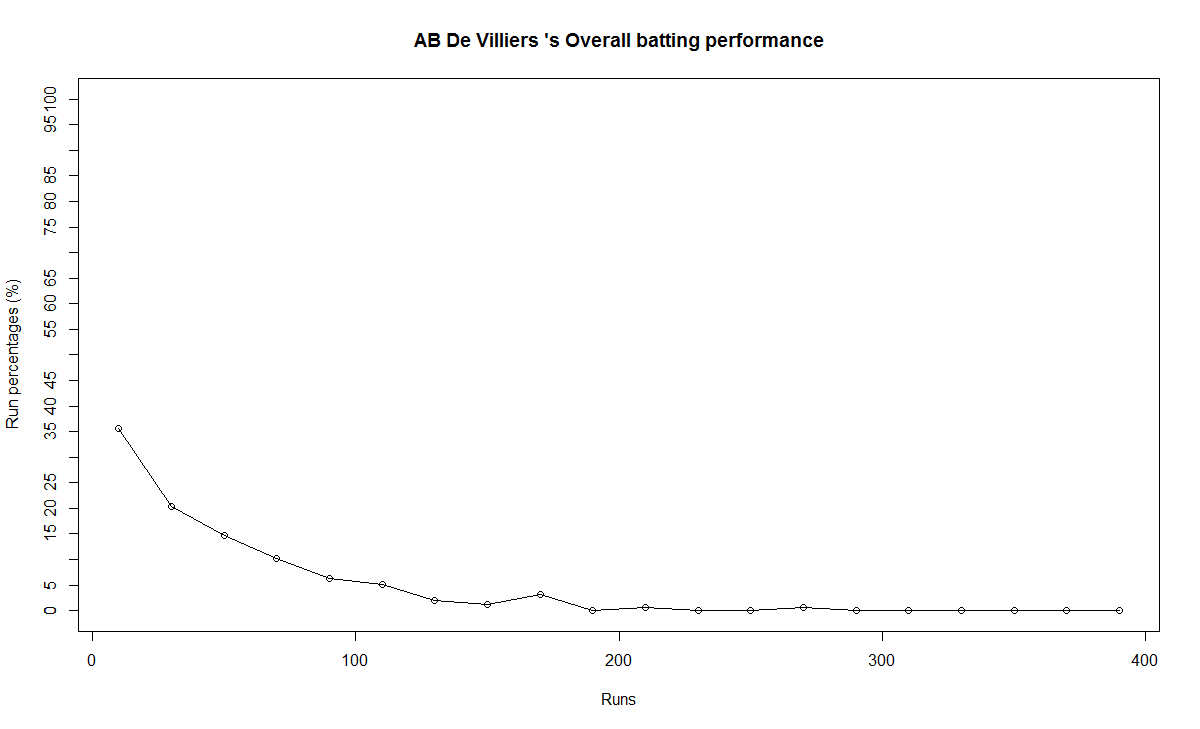
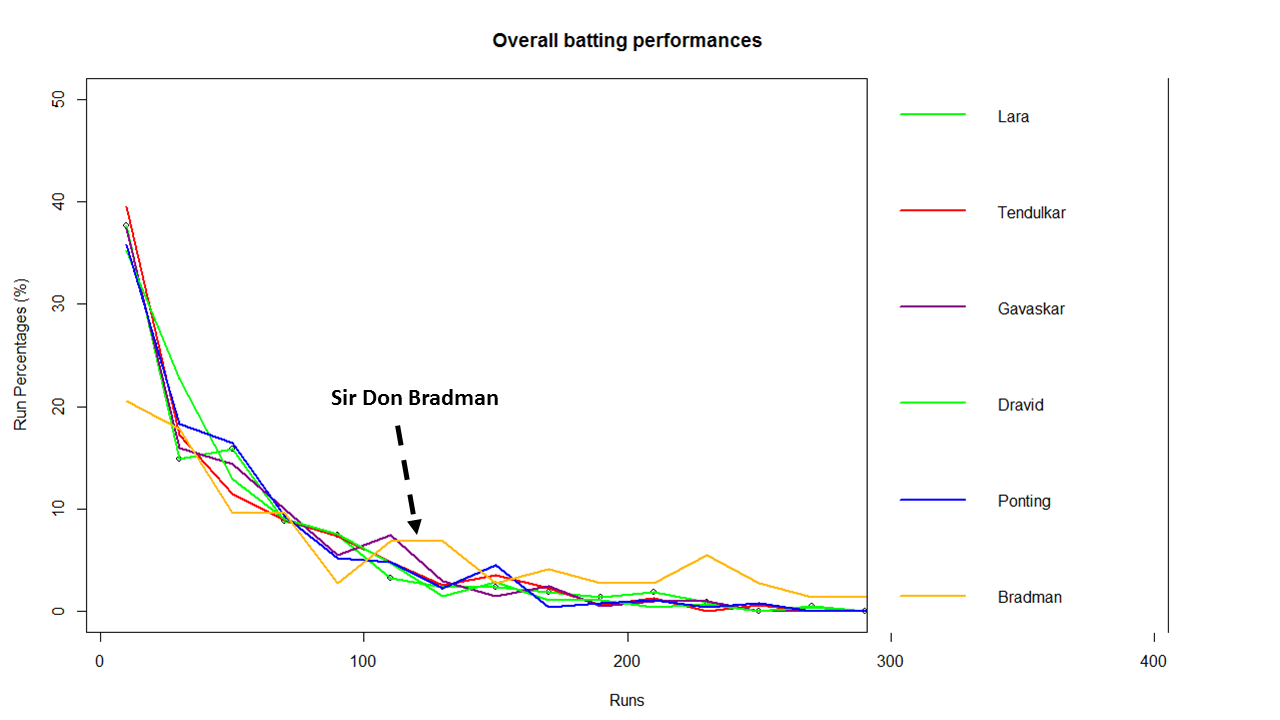
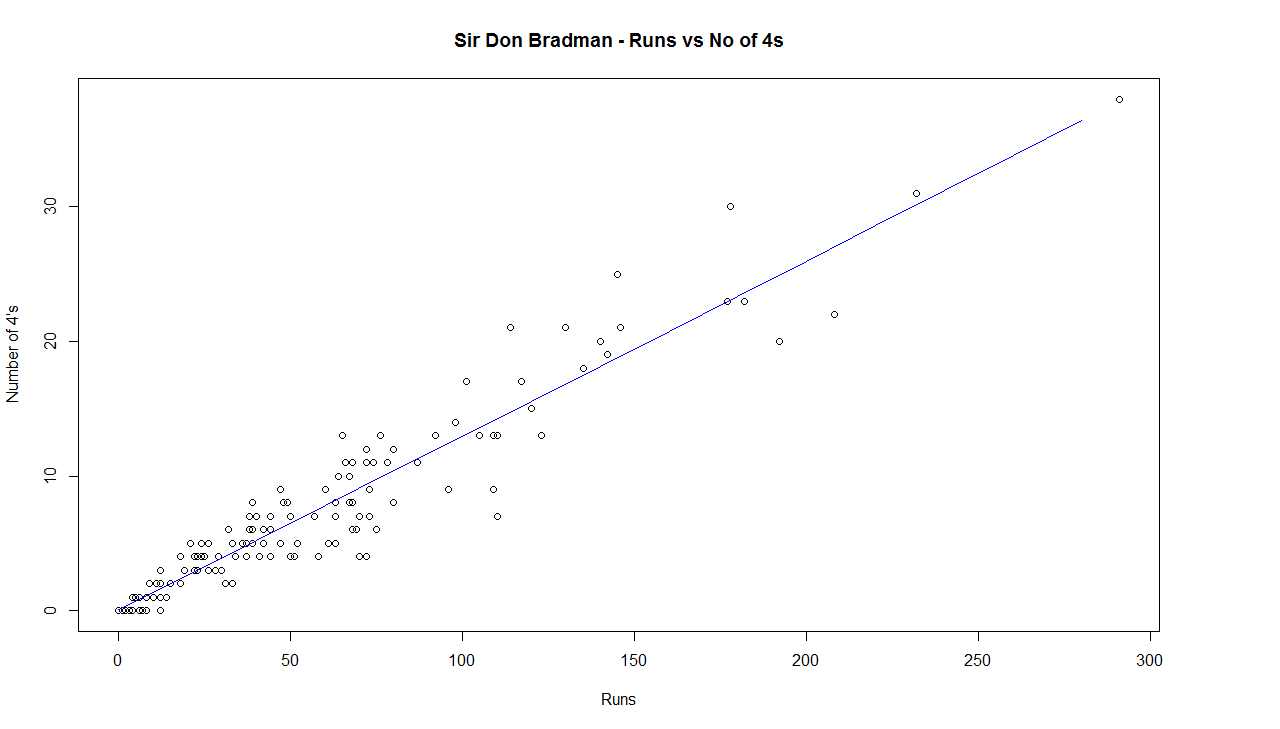
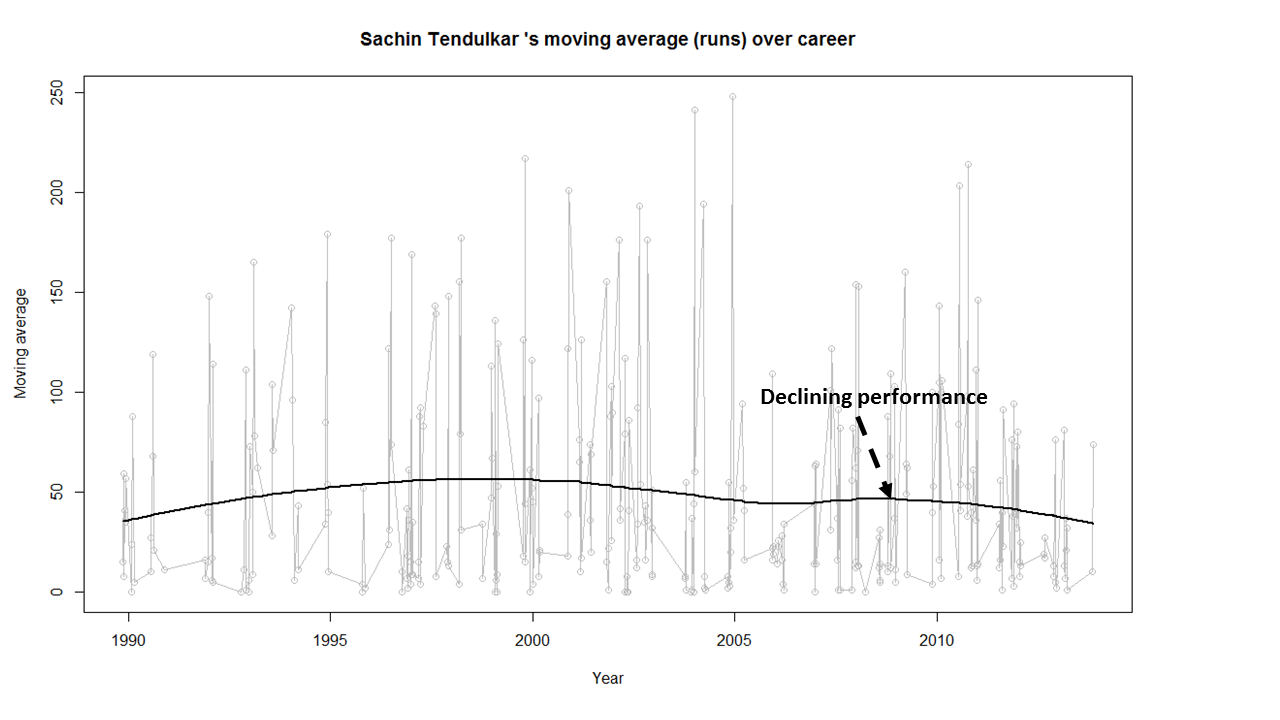
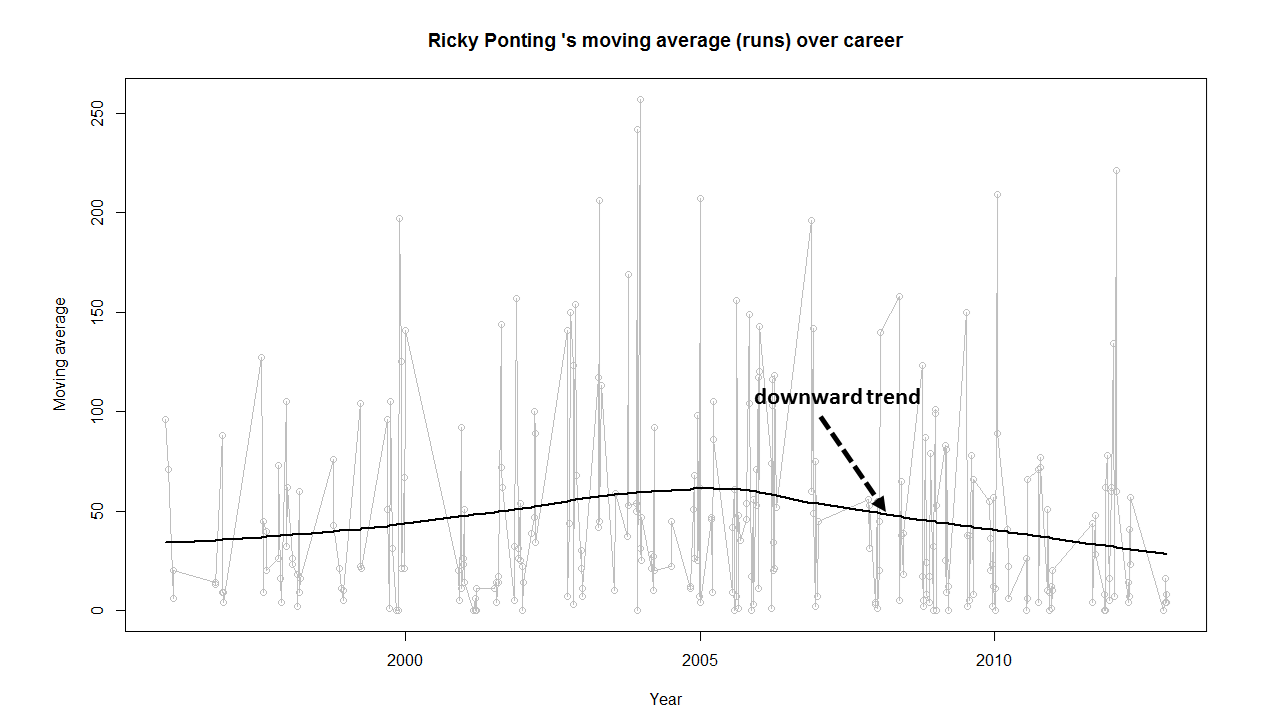
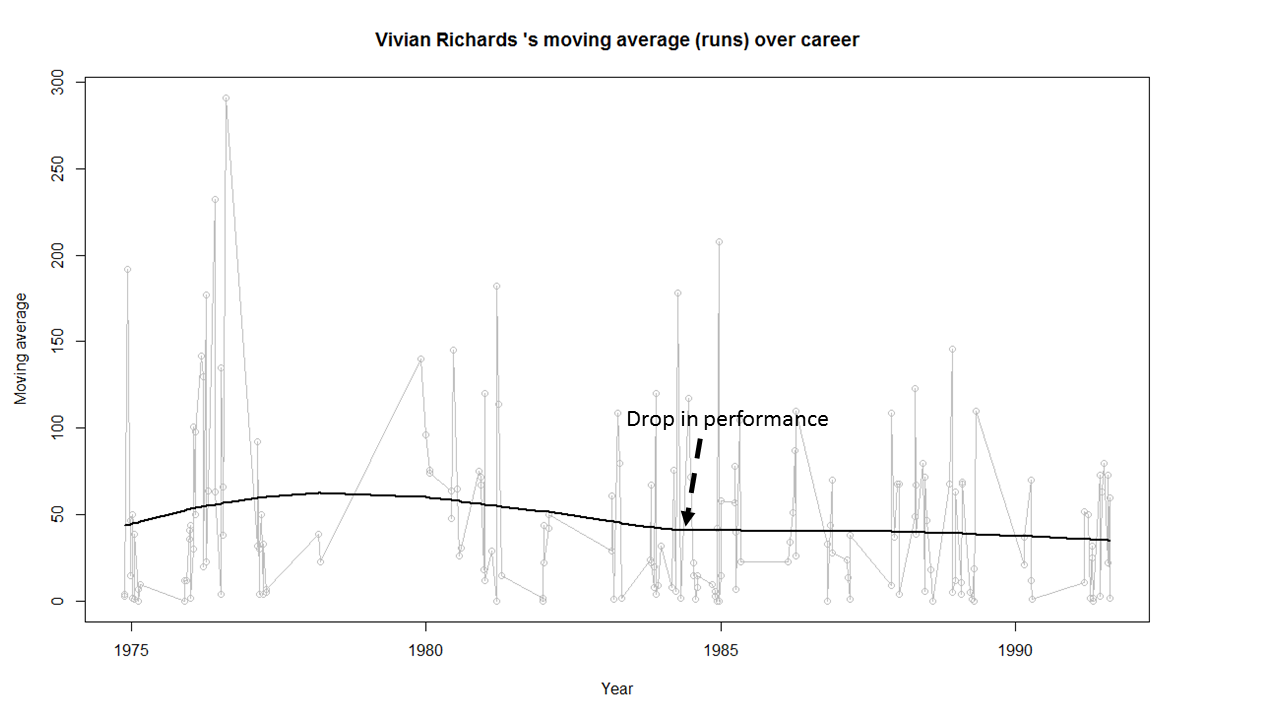
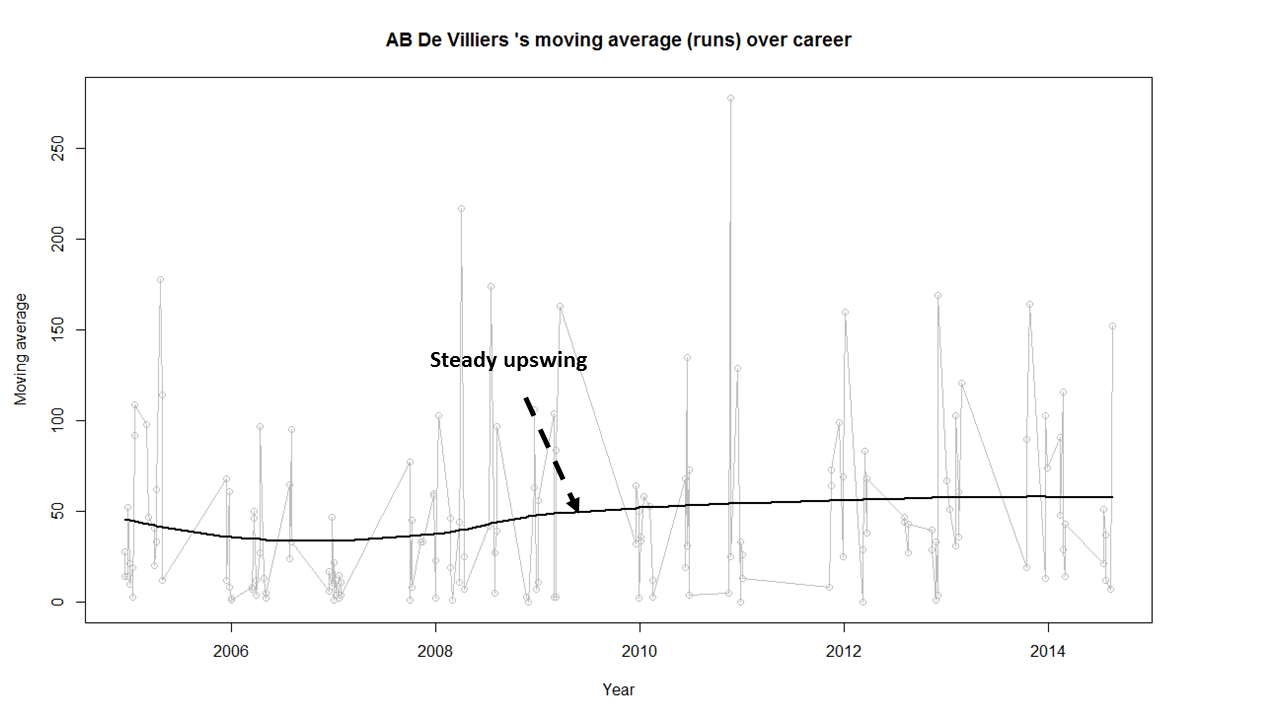
In this post, I use IBM’s DSE and my R package yorkr, for analyzing the performance of 1 ODI match (Aus-Ind, 2 Feb 2012) and the batting performance of Virat Kohli in IPL matches. These are my ‘first’ steps in DSE so, I use plain old “R language” for analysis together with my R package ‘yorkr’. I intend to do more interesting stuff on Machine learning with SparkR, Sparklyr and PySpark in the weeks and months to come.
You can checkout the Jupyter notebooks created with IBM’s DSE Y at Github – “Using R package yorkr – A quick overview’ and on NBviewer at “Using R package yorkr – A quick overview”
Working with Jupyter notebooks are fairly straight forward which can handle code in R, Python and Scala. Each cell can either contain code (Python or Scala), Markdown text, NBConvert or Heading. The code is written into the cells and can be executed sequentially. Here is a screen shot of the notebook.
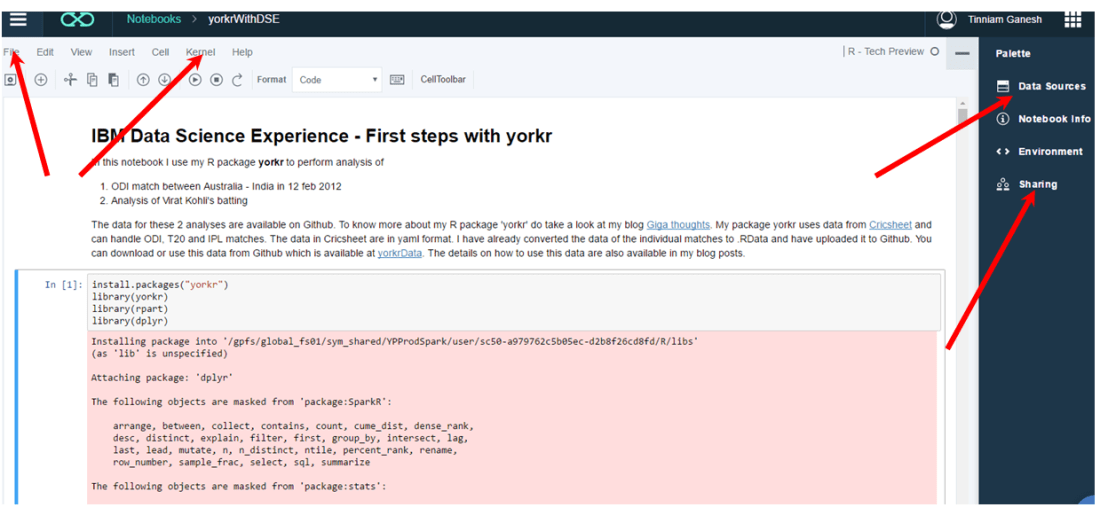
The ‘File’ menu can be used for ‘saving and checkpointing’ or ‘reverting’ to a checkpoint. The ‘kernel’ menu can be used to start, interrupt, restart and run all cells etc. Data Sources icon can be used to load data sources to your code. The data is uploaded to Object Storage with appropriate credentials. You will have to import this data from Object Storage using the credentials. In my notebook with yorkr I directly load the data from Github. You can use the sharing to share the notebook. The shared notebook has an extension ‘ipynb’. You can use the ‘Sharing’ icon to share the notebook. The shared notebook has an extension ‘ipynb’. You an import this notebook directly into your environment and can get started with the code available in the notebook.
You can import existing R, Python or Scala notebooks as shown below. My notebook ‘Using R package yorkr – A quick overview’ can be downloaded using the link ‘yorkrWithDSE’ and clicking the green download icon on top right corner.
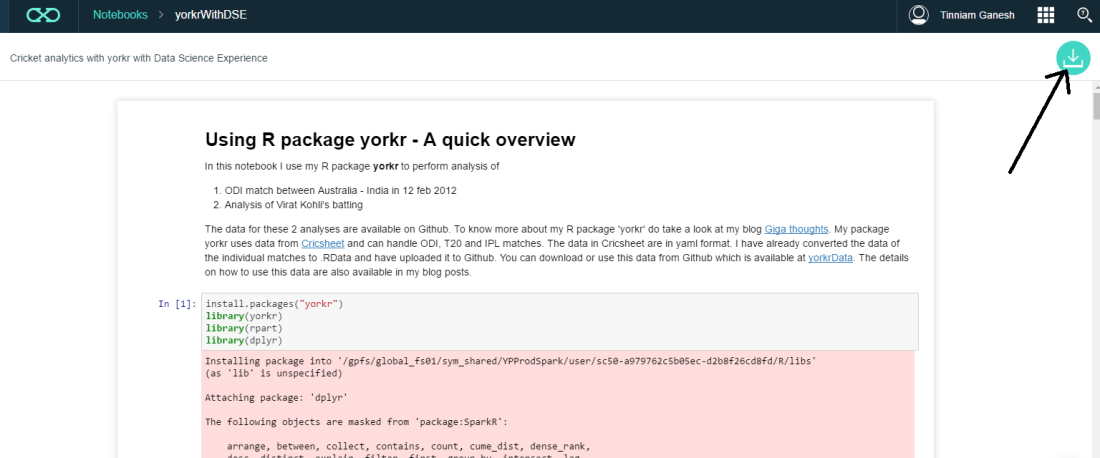
I have also uploaded the file to Github and you can download from here too ‘yorkrWithDSE’. This notebook can be imported into your DSE as shown below
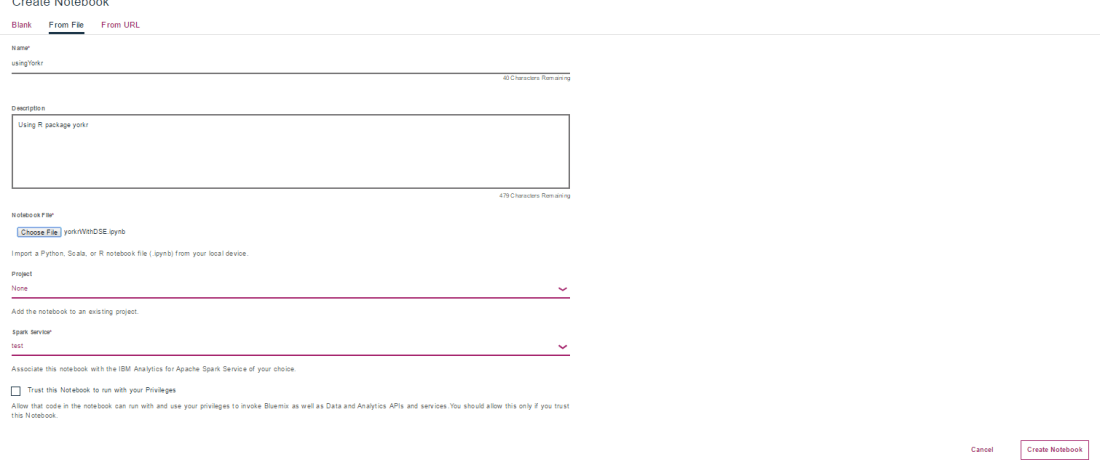
Jupyter notebooks have been integrated with Github and are rendered directly from Github. You can view my Jupyter notebook here – “Using R package yorkr – A quick overview’. You can also view it on NBviewer at “Using R package yorkr – A quick overview”
So there it is. You can download my notebook, import it into IBM’s Data Science Experience and then use data from ‘yorkrData” as shown. As already mentioned yorkrData contains converted data for ODIs, T20 and IPL. For details on how to use my R package yorkr please my posts on yorkr at “Index of posts”
Hope you have fun playing wit IBM’s Data Science Experience and my package yorkr.
I will be exploring IBM’s DSE in weeks and months to come in the areas of Machine Learning with SparkR,SparklyR or pySpark.
Watch this space!!!
Disclaimer: This article represents the author’s viewpoint only and doesn’t necessarily represent IBM’s positions, strategies or opinions
Also see
1. Introducing QCSimulator: A 5-qubit quantum computing simulator in R
2. Natural Processing Language : What would Shakespeare say?
3. Introducing cricket package yorkr:Part 1- Beaten by sheer pace!
4. A closer look at “Robot horse on a Trot! in Android”
5. Re-introducing cricketr! : An R package to analyze performances of cricketers
6. What’s up Watson? Using IBM Watson’s QAAPI with Bluemix, NodeExpress – Part 1
7. Deblurring with OpenCV: Wiener filter reloaded
To see all my posts check
Index of posts

























































































{kind=link}