 Here is a scene from Christopher Nolan’s classic movie Interstellar. In this scene Cooper, a crew member of the Endurance spaceship which is on its way to 3 distant planets via a wormhole, is conversing with TARS which is one of US Marine Corps former robots some year in the future.
Here is a scene from Christopher Nolan’s classic movie Interstellar. In this scene Cooper, a crew member of the Endurance spaceship which is on its way to 3 distant planets via a wormhole, is conversing with TARS which is one of US Marine Corps former robots some year in the future.
TARS (flippantly): “Everybody good? Plenty of slaves for my robot colony?”
TARS: [as Cooper repairs him] Settings. General settings. Security settings.
TARS: Honesty, new setting: ninety-five percent.
TARS: Confirmed. Additional settings.
Cooper: Humor, seventy-five percent.
TARS: Confirmed. Self-destruct sequence in T minus 10, 9…
Cooper: Let’s make that sixty percent.
TARS: Sixty percent, confirmed. Knock knock.
Cooper: You want fifty-five?
Natural Language has been an area of serious research for several decades ever since Alan Turing in 1950 proposed a test in which a human evaluator would simultaneously judge natural language conversations between another human and a machine, that is designed to generate human-like responses, behind a closed doors. If the responses of the human and machine were indistinguishable then we can say that the machine has passed the Turing test signifying machine intelligence.
How cool would it be if we could converse with a machines using Natural Language with all the subtleties of language including irony, sarcasm and humor? While considerable progress has been made in Natural Language Processing for e.g. Watson, Siri and Cortana the ability to handle nuances like humor, sarcasm is probably many years away.
This post looks at one aspect of Natural Language Processing, particularly in dealing with the ability to predict the next word(s) given a word or phrase.
This title of this post should really be ‘Natural language Processing: What would Shakespeare say, and what would you say’ because this post includes two interactive apps that can predict the next word
a) The first app given a (Shakespearean) phrase will predict the most likely word that Shakespeare would have said
Try the Shiny app : What would Shakespeare have said?
b) The second app will, given a regular phrase predict the next word(s) in regular day to day English usage
Try the Shiny app: What would you say?
 Checkout my book ‘Deep Learning from first principles- In vectorized Python, R and Octave’. My book is available on Amazon as paperback ($16.99) and in kindle version($6.65/Rs449).
Checkout my book ‘Deep Learning from first principles- In vectorized Python, R and Octave’. My book is available on Amazon as paperback ($16.99) and in kindle version($6.65/Rs449).
You may also like my companion book “Practical Machine Learning with R and Python:Second Edition- Machine Learning in stereo” available in Amazon in paperback($10.99) and Kindle($7.99/Rs449) versions.
Natural Language Processing (NLP) is a field of computer science, artificial intelligence, and computational linguistics concerned with the interactions between computers and human (natural) languages. NLP encompasses many areas from computer science besides inputs from the domain of linguistics , psychology, information theory, mathematics and statistics
However NLP is a difficult domain as each language has its own quirkiness and ambiguities, and English is no different. Let us take the following 2 sentences
Time flies like an arrow.
Fruit flies like a banana.
Clearly the 2 sentences mean entirely different things when referencing the words ‘flies like’. The English language is filled with many such ambiguous constructions
There have been 2 main approaches to Natural Language Processing – The rationalist approach and the empiricist’s approach. The empiricists approached natural language as a data driven problem based on statistics while the rationalist school led by Noam Chomsky, the linguist, strongly believed that sentence structure should be analyzed at a deeper level than mere surface statistics.
In his book Syntactic Structures, Chomsky introduces a famous example of his criticism of finite-state probabilistic models. He cites 2 sentences (a) ‘colorless green ideas sleep furiously’ (b) ‘furiously sleep ideas green colorless’. Chomsky’s contention is that while neither sentence or any of its parts, have ever occurred in the past linguistic experience of English it can be easily inferred that (a) is grammatical, while (b) is not. Chomsky argument is that sentence structure is critical to Natural Language processing of any kind. Here is a good post by Peter Norvig ‘On Chomsky and the two cultures of statistical learning’. In fact, from 1950 to the 1980s the empiricists approach fell out of favor while reasonable progress was made based on rationalist approach to NLP.
The return of the empiricists
But thanks to great strides in processing power and the significant drop in hardware the empiricists approach to Natural Language Processing made a comeback in the mid 1980s. The use of probabilistic language models combined with the increase in the power of processing saw the rise of the empiricists again. Also there had been significant improvement in machine learning algorithms which allowed the use of the computing resources more efficiently.
In this post I showcase 2 Shiny apps written in R that predict the next word given a phrase using statistical approaches, belonging to the empiricist school of thought. The 1st one will try to predict what Shakespeare would have said given a phrase (Shakespearean or otherwise) and the 2nd is a regular app that will predict what we would say in our regular day to day conversation. These apps will predict the next word as you keep typing in each word.
In NLP the first step is a to build a language model. In order to build a language model the program ingests a large corpora of documents. For the a) Shakespearean app, the corpus is the “Complete Works of Shakespeare“. This is also available in Free ebooks by Project Gutenberg but you will have to do some cleaning and tokenzing before using it. For the b) regular English next word predicting app the corpus is composed of several hundred MBs of tweets, news items and blogs.
Once the corpus is ingested the software then creates a n-gram model. A 1-gram model is representation of all unique single words and their counts. Similarly a bigram model is representation of all 2 words and their counts found in the corpus. Similar we can have trigram, quadgram and n-gram as required. Typically language models don’t go beyond 5-gram as the processing power needed increases for these larger n-gram models.
The probability of a sentence can be determined using the chain rule. This is shown for the bigram model below where P(s) is the probability of a sentence ‘s’
P( The quick brown fox jumped) =
P(The) P(quick|The) P(brown|The quick) * P(fox||The quick brown) *P(jumped|The quick brown fox)
where BOS -> is the beginning of the sentence and
P(quick|The) – The probability of the word being ‘quick’ given that the previous word was ‘The’. This probability can be approximated based on Markov’s chain rule which allows that the we can compute the conditional probability

of a word based on a couple of its preceding words. Hence this allows this approximation as follows
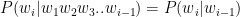
The Maximum Likelihood Estimate (MLE) is given as follows for a bigram
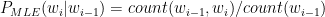

Hence for a corpus
We can calculate the maximum likelihood estimates of a given word from its previous word. This computation of the MLE can be extended to the trigram and the quadgram
For a trigram

Smoothing techniques
The MLE estimates for many bigrams and trigrams will be 0, because we may have not have yet seen certain combinations. But the fact that we have not seen these combinations in the corpus should not mean that they could never occur, So the MLE for the bigrams, trigrams etc have be smoothed so that it does not have a 0 conditional probability. One such method is to use ‘Laplace smoothing’. This smoothing tries to steal from the probability mass of words that occur in the corpus and re-distribute it to the words that do not occur in the corpus. In a way this equivalent to probability mass stealing. This is the simplest smoothing technique and is also known as the ‘add +1’ smoothing technique and requires that 1 be added to all counts
So the MLE below
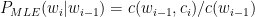
With the add +1 smoothing this becomes
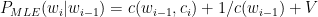
This smoothing is done for bigram, trigam and quadgram. Smoothing is usually used with an associated technique called ‘backoff’. If the phrase is not found in a n-gram model then we need to backoff to a n-1 gram model. For e.g. a lookup will be done in quadgrams, if not found the algorithm will backoff to trigram, bigram and finally to unigram.
Hence if we had the phrase
“on my way”
The smoothed MLE for a quadgram will be checked for the next word. If this is not found this is backed of my searching smoothed MLEs for trigrams for the phrase ‘my way’ and if this not found search the bigram for the next word to ‘way’.
One such method is the Katz backoff which is given by which is based on the following method
Bigrams with nonzero count are discounted according to discount ratio d_{r} (i.e. the unigram model).
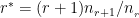
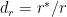
Count mass subtracted from nonzero counts is redistributed among the zero-count bigrams according to next lower-order distribution
A better performance is obtained with the Kneser-Ney algorithm which computes the continuation probability of words. The Kneser-Ney algorithm is included below
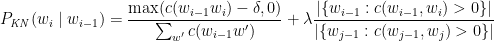
where

This post was inspired by the final Capstone Project in which I had to create a Shiny app for predicting the next word as a part of Data Science Specialization conducted by John Hopkins University, Bloomberg School of Public health at Coursera.
I further extended this concept where I try to predict what Shakespeare would have said. For this I ingest the Complete Works of Shakespeare which is the corpus. The +1 Add smoothing with Katz backoff and the Kneser-Ney algorithm on the unigram, bigram, trigram and quadgrams were then implemented.
Note: This post in no way tries to belittle the genius of Shakespeare. From the table below it can be seen that our day to day conversation has approximately 210K, 181K & 65K unique bigrams, trigrams and quadgrams. On the other hand, Shakespearean literature has 271K, 505K, & 517K bigrams, trigrams and quadgrams. It can be seen that Shakespeare had a rich and complex set of word combination.
Not surprisingly the computation of the conditional and continuation probabilities for the Shakespearean literature is orders of magnitude larger.
Here is a small table as comparison

This implementation was done entirely using R. The main R packages used for this implementation were tm,Rweka,dplyr. Here is a slide deck on the the implementation details of the apps and key lessons learnt: PredictNextWord
Unfortunately I will not be able to include the implementation details as I am bound by The Coursera Honor Code.
If you have not already given the apps a try do give them a try
Try the Shiny apps
– What would Shakespeare say?
– What would you say?
References
a. http://www.foldl.me/2014/kneser-ney-smoothing/
b. http://mkoerner.de/media/bachelor-thesis.pdf
c. https://www.coursera.org/course/nlp (Week 2)
d. http://www.cs.berkeley.edu/~klein/cs294-5/chen_goodman.pdf
You may like
1. My book ‘Practical Machine Learning in R and Python: Second edition’ on Amazon
2. Introducing cricketr! : An R package to analyze performances of cricketers
3. cricketr digs the Ashes!
4. A peek into literacy in India: Statistical Learning with R
5. A crime map of India in R – Crimes against women
6. Analyzing cricket’s batting legends – Through the mirage with R
7. Informed choices through Machine Learning : Analyzing Kohli, Tendulkar and Dravid
Also see
1. Re-working the Lucy-Richardson Algorithm in OpenCV
2. What’s up Watson? Using IBM Watson’s QAAPI with Bluemix, NodeExpress – Part 1
3. Bend it like Bluemix, MongoDB with autoscaling – Part 2
4. TWS-4: Gossip protocol: Epidemics and rumors to the rescue
5. Thinking Web Scale (TWS-3): Map-Reduce – Bring compute to data
6. Deblurring with OpenCV:Weiner filter reloaded
