In my recent post My travels through the realms of Data Science, Machine Learning, Deep Learning and (AI),I had recounted my journey in the domains of of Data Science, Machine Learning (ML), and more recently Deep Learning (DL) all of which are useful while analyzing data. Of late, I have come to the realization that there are many facets to data. And to glean insights from data, Data Science, ML and DL alone are not sufficient and one needs to also have a good handle on linear programming and optimization. My colleague at IBM Research also concurred with this view and told me he had arrived at this conclusion several years ago. While ML & DL are useful and interesting to make inferences and predictions of outputs from input variables, optimization computes the choice of input which result in maximum or minimum. So I made a small course correction and started on a course from India’s own NPTEL Introduction to Linear Programming by Prof G. Srinivasan of IIT Madras. The lectures are delivered with remarkable clarity by the Prof and I am just about halfway through the course (each lecture is of 50-55 min duration) when I decided that I needed to try to formulate and solve some real world Linear Programming problem.
As usual, I turned towards cricket for some appropriate situations, and sure enough it was there in the open. For this LP formulation I take International T20 and IPL, though International ODI will also work equally well. You can download the associated code and data for this from Github at LP-cricket-analysis
In T20 matches the captain has to make choice of how to rotate bowlers with the aim of restricting the batting side. Conversely, the batsmen need to take advantage of the bowling strength to maximize the runs scored.
Note:
a) A simple and obvious strategy would be
– If the ith bowler’s economy rate is less than the economy rate of the jth bowler i.e.
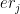
b)A better strategy would be to consider the economy rate of each bowler against each batsman. How often we have seen bowlers who have a great bowling average get punished by some batsman, or a bowler who is generally very poor is very effective against a particular batsman. i.e. 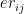
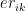
This post uses the latter approach to optimize bowling change and batting lineup.
Let is take a hypothetical situation
Assume there are 3 bowlers –
and there are 4 batsmen –
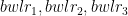

Let the economy rate
and the total number of overs left to be bowled are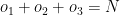
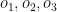
a) Given the economy rate of each bowler per batsman, how many overs should each bowler bowl, so that the total runs scored by all the batsmen are minimum?
b) Alternatively, if the know the individual strike rate of a batsman against the individual bowlers, how many overs should each batsman face with a bowler so that the total runs scored is maximized?
1. LP Formulation for bowling order
Let the economy rate
be the Economy Rate of the jth bowler to the ith batsman.
Objective function : Minimize –

Where k is the number overs o, remaining for the jth bowler 
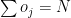
The overs that any bowler can bowl can be >=0
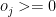
2. LP Formulation for batting lineup
Where k is the number overs o, remaining for the jth bowler
The overs that any bowler can bowl can be >= 0 or any number that the bowler has already bowled.
For this maximization and minimization problem I used lpSolveAPI.
3. LP formulation (Example 1)
Initially I created a test example to ensure that I get the LP formulation and solution correct. Here the er1=4 and er2=3 and o1 & o2 are the overs bowled by bowlers 1 & 2. Also o1+o2=4 In this example as below
o1 o2 Obj Fun(=4o1+3o2)
1 3 13
2 2 14
3 1 15
library(lpSolveAPI)
library(dplyr)
library(knitr)
lprec <- make.lp(0, 2)
a <-lp.control(lprec, sense="min")
set.objfn(lprec, c(4, 3)) # Economy Rate of 4 and 3 for er1 and er2
add.constraint(lprec, c(1, 1), "=",4) # o1 + o2 =4
add.constraint(lprec, c(1, 0), ">",1) # o1 > 1
add.constraint(lprec, c(0, 1), ">",1) # o2 > 1
lprec
## Model name:
## C1 C2
## Minimize 4 3
## R1 1 1 = 4
## R2 1 0 >= 1
## R3 0 1 >= 1
## Kind Std Std
## Type Real Real
## Upper Inf Inf
## Lower 0 0
b <-solve(lprec)
get.objective(lprec) # 13
## [1] 13
get.variables(lprec) # 1 3
## [1] 1 3
Note 1: In the above example 13 runs is the minimum that can be scored and this requires
- o1=1
- o2=3
Note 2:The numbers in the columns represent the number of overs that need to be bowled by a bowler to the corresponding batsman.
4. LP formulation (Example 2)
In this formulation there are 2 bowlers and 2 batsmen o11,o12 are the oves bowled by bowler 1 to batsmen 1 & 2 and o21, o22 are the overs bowled by bowler 2 to batsmen 1 & 2 er11=4, er12=2,er21=2,er22=5 o11+o12+o21+o22=5
The solution for this manually computed is B1 B2 B1 B2 Runs
1 1 1 2 18
1 2 1 1 15
2 1 1 1 17
1 1 2 1 15
lprec <- make.lp(0, 4)
a <-lp.control(lprec, sense="min")
set.objfn(lprec, c(4, 2,2,5))
add.constraint(lprec, c(1, 1,0,0), "<=",8)
add.constraint(lprec, c(0, 0,1,1), "<=",7)
add.constraint(lprec, c(1, 1,1,1), "=",5)
add.constraint(lprec, c(1, 0,0,0), ">",1)
add.constraint(lprec, c(0, 1,0,0), ">",1)
add.constraint(lprec, c(0, 0,1,0), ">",1)
add.constraint(lprec, c(0, 0,0,1), ">",1)
lprec
## Model name:
## C1 C2 C3 C4
## Minimize 4 2 2 5
## R1 1 1 0 0 <= 8
## R2 0 0 1 1 <= 7
## R3 1 1 1 1 = 5
## R4 1 0 0 0 >= 1
## R5 0 1 0 0 >= 1
## R6 0 0 1 0 >= 1
## R7 0 0 0 1 >= 1
## Kind Std Std Std Std
## Type Real Real Real Real
## Upper Inf Inf Inf Inf
## Lower 0 0 0 0
b<-solve(lprec)
get.objective(lprec)
## [1] 15
get.variables(lprec)
## [1] 1 2 1 1
Note: In the above example 15 runs is the minimum that can be scored and this requires
- o11=1
- o12=2
- o21=1
- o22=1
It is possible to keep the minimum to other values and solves also.
5. LP formulation for International T20 India vs Australia (Batting lineup)
To analyze batting and bowling lineups in the cricket world I needed to get the ball-by-ball details of runs scored by each batsman against each of the bowlers. Fortunately I had already created this with my R package yorkr. yorkr processes yaml data from Cricsheet. So I copied the data of all matches between Australia and India in International T20s. You can download my processed data for International T20 at Inswinger
load("Australia-India-allMatches.RData")
dim(matches)
## [1] 3541 25
The following functions compute the ‘Strike Rate’ of a batsman as
SR=1/overs∗∑RunsScoredSR=1/overs∗∑RunsScored
Also the Economy Rate is computed as
ER=1/overs∗∑RunsConcededER=1/overs∗∑RunsConcededIncidentally the SR=ER
# Compute the Strike Rate of the batsman
computeSR <- function(batsman1,bowler1){
a <- matches %>% filter(batsman==batsman1 & bowler==bowler1)
a1 <- a %>% summarize(totalRuns=sum(runs),count=n()) %>% mutate(SR=(totalRuns/count)*6)
a1
}
# Compute the Economy Rate of the batsman
computeER <- function(batsman1,bowler1){
a <- matches %>% filter(batsman==batsman1 & bowler==bowler1)
a1 <- a %>% summarize(totalRuns=sum(runs),count=n()) %>% mutate(ER=(totalRuns/count)*6)
a1
}
Here I compute the Strike Rate of Virat Kohli, Yuvraj Singh and MS Dhoni against Shane Watson, Brett Lee and MA Starc
# Kohli
kohliWatson<- computeSR("V Kohli","SR Watson")
kohliWatson
## totalRuns count SR
## 1 45 37 7.297297
kohliLee <- computeSR("V Kohli","B Lee")
kohliLee
## totalRuns count SR
## 1 10 7 8.571429
kohliStarc <- computeSR("V Kohli","MA Starc")
kohliStarc
## totalRuns count SR
## 1 11 9 7.333333
# Yuvraj
yuvrajWatson<- computeSR("Yuvraj Singh","SR Watson")
yuvrajWatson
## totalRuns count SR
## 1 24 22 6.545455
yuvrajLee <- computeSR("Yuvraj Singh","B Lee")
yuvrajLee
## totalRuns count SR
## 1 12 7 10.28571
yuvrajStarc <- computeSR("Yuvraj Singh","MA Starc")
yuvrajStarc
## totalRuns count SR
## 1 12 8 9
# MS Dhoni
dhoniWatson<- computeSR("MS Dhoni","SR Watson")
dhoniWatson
## totalRuns count SR
## 1 33 28 7.071429
dhoniLee <- computeSR("MS Dhoni","B Lee")
dhoniLee
## totalRuns count SR
## 1 26 20 7.8
dhoniStarc <- computeSR("MS Dhoni","MA Starc")
dhoniStarc
## totalRuns count SR
## 1 11 8 8.25
When we consider the batting lineup, the problem is one of maximization. Formulating and solving
# 3 batsman x 3 bowlers
lprec <- make.lp(0, 9)
# Maximization
a<-lp.control(lprec, sense="max")
# Set the objective function
set.objfn(lprec, c(kohliWatson$SR, kohliLee$SR,kohliStarc$SR,
yuvrajWatson$SR,yuvrajLee$SR,yuvrajStarc$SR,
dhoniWatson$SR,dhoniLee$SR,dhoniStarc$SR))
#Assume the bowlers have 3,4,3 overs left respectively
add.constraint(lprec, c(1, 1,1,0,0,0, 0,0,0), "<=",3)
add.constraint(lprec, c(0,0,0,1,1,1,0,0,0), "<=",4)
add.constraint(lprec, c(0,0,0,0,0,0,1,1,1), "<=",3)
#o11+o12+o13+o21+o22+o23+o31+o32+o33=8 (overs remaining)
add.constraint(lprec, c(1,1,1,1,1,1,1,1,1), "=",8)
add.constraint(lprec, c(1,0,0,0,0,0,0,0,0), ">=",1) #o11 >=1
add.constraint(lprec, c(0,1,0,0,0,0,0,0,0), ">=",0) #o12 >=0
add.constraint(lprec, c(0,0,1,0,0,0,0,0,0), ">=",0) #o13 >=0
add.constraint(lprec, c(0,0,0,1,0,0,0,0,0), ">=",1) #o21 >=1
add.constraint(lprec, c(0,0,0,0,1,0,0,0,0), ">=",1) #o22 >=1
add.constraint(lprec, c(0,0,0,0,0,1,0,0,0), ">=",0) #o23 >=0
add.constraint(lprec, c(0,0,0,0,0,0,1,0,0), ">=",1) #o31 >=1
add.constraint(lprec, c(0,0,0,0,0,0,0,1,0), ">=",0) #o32 >=0
add.constraint(lprec, c(0,0,0,0,0,0,0,0,1), ">=",0) #o33 >=0
lprec
## Model name:
## a linear program with 9 decision variables and 13 constraints
b <-solve(lprec)
get.objective(lprec) #
## [1] 68.91418
get.variables(lprec) #
## [1] 1 2 0 1 3 0 1 0 0
This shows that the maximum runs that can be scored for the current strike rate is 81.9 runs in 8 overs The breakup is as follows
Batsman Watson B Lee MA Starc
Kohli 1 1 1
Yuvraj 0 3 0
Dhoni 2 0 0
Overs 3 4 1
Total=8
This is also shown below
e <- as.data.frame(rbind(c(1,1,1),c(0,3,0),c(2,0,0),c(3,4,1)))
names(e) <- c("S Watson","B Lee","MA Starc")
rownames(e) <- c("Kohli","Yuvraj","Dhoni","Overs")
e
## S Watson B Lee MA Starc
## Kohli 1 1 1
## Yuvraj 0 3 0
## Dhoni 2 0 0
## Overs 3 4 1
Note: This assumes that the batsmen perform at their current Strike Rate. Howvever anything can happen in a real game, but nevertheless this is a fairly reasonable estimate of the performance
Note 2:The numbers in the columns represent the number of overs that need to be bowled by a bowler to the corresponding batsman.
6. LP formulation for International T20 India vs Australia (Bowling lineup)
For this I compute how the bowling should be rotated between R Ashwin, RA Jadeja and JJ Bumrah when taking into account their performance against batsmen like Shane Watson, AJ Finch and David Warner. For the bowling performance I take the Economy rate of the bowlers. The data is the same as above
computeSR <- function(batsman1,bowler1){
a <- matches %>% filter(batsman==batsman1 & bowler==bowler1)
a1 <- a %>% summarize(totalRuns=sum(runs),count=n()) %>% mutate(SR=(totalRuns/count)*6)
a1
}
# RA Jadeja
jadejaWatson<- computeER("SR Watson","RA Jadeja")
jadejaWatson
## totalRuns count ER
## 1 60 29 12.41379
jadejaFinch <- computeER("AJ Finch","RA Jadeja")
jadejaFinch
## totalRuns count ER
## 1 36 33 6.545455
jadejaWarner <- computeER("DA Warner","RA Jadeja")
jadejaWarner
## totalRuns count ER
## 1 23 11 12.54545
# Ashwin
ashwinWatson<- computeER("SR Watson","R Ashwin")
ashwinWatson
## totalRuns count ER
## 1 41 26 9.461538
ashwinFinch <- computeER("AJ Finch","R Ashwin")
ashwinFinch
## totalRuns count ER
## 1 63 36 10.5
ashwinWarner <- computeER("DA Warner","R Ashwin")
ashwinWarner
## totalRuns count ER
## 1 38 28 8.142857
# JJ Bunrah
bumrahWatson<- computeER("SR Watson","JJ Bumrah")
bumrahWatson
## totalRuns count ER
## 1 22 20 6.6
bumrahFinch <- computeER("AJ Finch","JJ Bumrah")
bumrahFinch
## totalRuns count ER
## 1 25 19 7.894737
bumrahWarner <- computeER("DA Warner","JJ Bumrah")
bumrahWarner
## totalRuns count ER
## 1 2 4 3
Formulating solving the bowling lineup is shown below
lprec <- make.lp(0, 9)
a <-lp.control(lprec, sense="min")
# Set the objective function
set.objfn(lprec, c(jadejaWatson$ER, jadejaFinch$ER,jadejaWarner$ER,
ashwinWatson$ER,ashwinFinch$ER,ashwinWarner$ER,
bumrahWatson$ER,bumrahFinch$ER,bumrahWarner$ER))
add.constraint(lprec, c(1, 1,1,0,0,0, 0,0,0), "<=",4) # Jadeja has 4 overs
add.constraint(lprec, c(0,0,0,1,1,1,0,0,0), "<=",3) # Ashwin has 3 overs left
add.constraint(lprec, c(0,0,0,0,0,0,1,1,1), "<=",4) # Bumrah has 4 overs left
add.constraint(lprec, c(1,1,1,1,1,1,1,1,1), "=",10) # Total overs = 10
add.constraint(lprec, c(1,0,0,0,0,0,0,0,0), ">=",1)
add.constraint(lprec, c(0,1,0,0,0,0,0,0,0), ">=",0)
add.constraint(lprec, c(0,0,1,0,0,0,0,0,0), ">=",1)
add.constraint(lprec, c(0,0,0,1,0,0,0,0,0), ">=",0)
add.constraint(lprec, c(0,0,0,0,1,0,0,0,0), ">=",1)
add.constraint(lprec, c(0,0,0,0,0,1,0,0,0), ">=",0)
add.constraint(lprec, c(0,0,0,0,0,0,1,0,0), ">=",0)
add.constraint(lprec, c(0,0,0,0,0,0,0,1,0), ">=",1)
add.constraint(lprec, c(0,0,0,0,0,0,0,0,1), ">=",0)
lprec
## Model name:
## a linear program with 9 decision variables and 13 constraints
b <-solve(lprec)
get.objective(lprec) #
## [1] 73.58775
get.variables(lprec) #
## [1] 1 2 1 0 1 1 0 1 3
The minimum runs that will be conceded by these 3 bowlers in 10 overs is 73.58 assuming the bowling is rotated as follows
e <- as.data.frame(rbind(c(1,0,0),c(2,1,1),c(1,1,3),c(4,2,4)))
names(e) <- c("RA Jadeja","R Ashwin","JJ Bumrah")
rownames(e) <- c("S Watson","AJ Finch","DA Warner","Overs")
e
## RA Jadeja R Ashwin JJ Bumrah
## S Watson 1 0 0
## AJ Finch 2 1 1
## DA Warner 1 1 3
## Overs 4 2 4
#Total overs=10
7. LP formulation for IPL (Mumbai Indians – Kolkata Knight Riders – Bowling lineup)
As in the case of International T20s I also have processed IPL data derived from my R package yorkr. yorkr. yorkr processes yaml data from Cricsheet. The processed data for all IPL matches can be downloaded from GooglyPlus
load("Mumbai Indians-Kolkata Knight Riders-allMatches.RData")
dim(matches)
## [1] 4237 25
# Compute the Economy Rate of the batsman
# Gambhir
gambhirMalinga <- computeER("G Gambhir","SL Malinga")
gambhirHarbhajan <- computeER("G Gambhir","Harbhajan Singh")
gambhirPollard <- computeER("G Gambhir","KA Pollard")
#Yusuf Pathan
yusufMalinga <- computeER("YK Pathan","SL Malinga")
yusufHarbhajan <- computeER("YK Pathan","Harbhajan Singh")
yusufPollard <- computeER("YK Pathan","KA Pollard")
#JH Kallis
kallisMalinga <- computeER("JH Kallis","SL Malinga")
kallisHarbhajan <- computeER("JH Kallis","Harbhajan Singh")
kallisPollard <- computeER("JH Kallis","KA Pollard")
#RV Uthappa
uthappaMalinga <- computeER("RV Uthappa","SL Malinga")
uthappaHarbhajan <- computeER("RV Uthappa","Harbhajan Singh")
uthappaPollard <- computeER("RV Uthappa","KA Pollard")
Formulating and solving this for the bowling lineup of Mumbai Indians against Kolkata Knight Riders
library("lpSolveAPI")
lprec <- make.lp(0, 12)
a=lp.control(lprec, sense="min")
set.objfn(lprec, c(gambhirMalinga$ER, yusufMalinga$ER,kallisMalinga$ER,uthappaMalinga$ER,
gambhirHarbhajan$ER,yusufHarbhajan$ER,kallisHarbhajan$ER,uthappaHarbhajan$ER,
gambhirPollard$ER,yusufPollard$ER,kallisPollard$ER,uthappaPollard$ER))
add.constraint(lprec, c(1,1,1,1, 0,0,0,0, 0,0,0,0), "<=",4)
add.constraint(lprec, c(0,0,0,0,1,1,1,1,0,0,0,0), "<=",4)
add.constraint(lprec, c(0,0,0,0,0,0,0,0,1,1,1,1), "<=",4)
add.constraint(lprec, c(1,1,1,1,1,1,1,1,1,1,1,1), "=",10)
add.constraint(lprec, c(1,0,0,0,0,0,0,0,0,0,0,0), ">=",0)
add.constraint(lprec, c(0,1,0,0,0,0,0,0,0,0,0,0), ">=",1)
add.constraint(lprec, c(0,0,1,0,0,0,0,0,0,0,0,0), ">=",0)
add.constraint(lprec, c(0,0,0,1,0,0,0,0,0,0,0,0), ">=",0)
add.constraint(lprec, c(0,0,0,0,1,0,0,0,0,0,0,0), ">=",0)
add.constraint(lprec, c(0,0,0,0,0,1,0,0,0,0,0,0), ">=",1)
add.constraint(lprec, c(0,0,0,0,0,0,1,0,0,0,0,0), ">=",0)
add.constraint(lprec, c(0,0,0,0,0,0,0,1,0,0,0,0), ">=",1)
add.constraint(lprec, c(0,0,0,0,0,0,0,0,1,0,0,0), ">=",0)
add.constraint(lprec, c(0,0,0,0,0,0,0,0,0,1,0,0), ">=",1)
add.constraint(lprec, c(0,0,0,0,0,0,0,0,0,0,1,0), ">=",0)
add.constraint(lprec, c(0,0,0,0,0,0,0,0,0,0,0,1), ">=",0)
lprec
## Model name:
## a linear program with 12 decision variables and 16 constraints
b=solve(lprec)
get.objective(lprec) #
## [1] 55.57887
get.variables(lprec) #
## [1] 3 1 0 0 0 1 0 1 3 1 0 0
e <- as.data.frame(rbind(c(3,1,0,0,4),c(0, 1, 0,1,2),c(3, 1, 0,0,4)))
names(e) <- c("Gambhir","Yusuf","Kallis","Uthappa","Overs")
rownames(e) <- c("Malinga","Harbhajan","Pollard")
e
## Gambhir Yusuf Kallis Uthappa Overs
## Malinga 3 1 0 0 4
## Harbhajan 0 1 0 1 2
## Pollard 3 1 0 0 4
#Total overs=10
8. LP formulation for IPL (Mumbai Indians – Kolkata Knight Riders – Batting lineup)
As I mentioned it is possible to perform a maximation with the same formulation since computeSR<==>computeER
This just flips the problem around and computes the maximum runs that can be scored for the batsman’s Strike rate (this is same as the bowler’s Economy rate)
library("lpSolveAPI")
lprec <- make.lp(0, 12)
a=lp.control(lprec, sense="max")
a <-set.objfn(lprec, c(gambhirMalinga$ER, yusufMalinga$ER,kallisMalinga$ER,uthappaMalinga$ER,
gambhirHarbhajan$ER,yusufHarbhajan$ER,kallisHarbhajan$ER,uthappaHarbhajan$ER,
gambhirPollard$ER,yusufPollard$ER,kallisPollard$ER,uthappaPollard$ER))
add.constraint(lprec, c(1,1,1,1, 0,0,0,0, 0,0,0,0), "<=",4)
add.constraint(lprec, c(0,0,0,0,1,1,1,1,0,0,0,0), "<=",4)
add.constraint(lprec, c(0,0,0,0,0,0,0,0,1,1,1,1), "<=",4)
add.constraint(lprec, c(1,1,1,1,1,1,1,1,1,1,1,1), "=",11)
add.constraint(lprec, c(1,0,0,0,0,0,0,0,0,0,0,0), ">=",0)
add.constraint(lprec, c(0,1,0,0,0,0,0,0,0,0,0,0), ">=",1)
add.constraint(lprec, c(0,0,1,0,0,0,0,0,0,0,0,0), ">=",0)
add.constraint(lprec, c(0,0,0,1,0,0,0,0,0,0,0,0), ">=",0)
add.constraint(lprec, c(0,0,0,0,1,0,0,0,0,0,0,0), ">=",0)
add.constraint(lprec, c(0,0,0,0,0,1,0,0,0,0,0,0), ">=",1)
add.constraint(lprec, c(0,0,0,0,0,0,1,0,0,0,0,0), ">=",0)
add.constraint(lprec, c(0,0,0,0,0,0,0,1,0,0,0,0), ">=",1)
add.constraint(lprec, c(0,0,0,0,0,0,0,0,1,0,0,0), ">=",0)
add.constraint(lprec, c(0,0,0,0,0,0,0,0,0,1,0,0), ">=",1)
add.constraint(lprec, c(0,0,0,0,0,0,0,0,0,0,1,0), ">=",0)
add.constraint(lprec, c(0,0,0,0,0,0,0,0,0,0,0,1), ">=",0)
lprec
## Model name:
## a linear program with 12 decision variables and 16 constraints
b=solve(lprec)
get.objective(lprec) #
## [1] 94.22649
get.variables(lprec) #
## [1] 0 3 0 0 0 1 0 3 0 1 3 0
e <- as.data.frame(rbind(c(0,3,0,0,3),c(0, 1, 0,3,4),c(0, 1, 3,0,4)))
names(e) <- c("Gambhir","Yusuf","Kallis","Uthappa","Overs")
rownames(e) <- c("Malinga","Harbhajan","Pollard")
e
## Gambhir Yusuf Kallis Uthappa Overs
## Malinga 0 3 0 0 3
## Harbhajan 0 1 0 3 4
## Pollard 0 1 3 0 4
#Total overs=11
Conclusion: It is possible to thus determine the optimum no of overs to give to a specific bowler based on his/her Economy Rate with a particular batsman. Similarly one can determine the maximim runs that can be scored by a batsmen based on their strike rate with bowlers. However, while this may provide some indication a cricket like any other game depends on a fair amount of chance.

 Then felt I like some watcher of the skies
Then felt I like some watcher of the skies 
