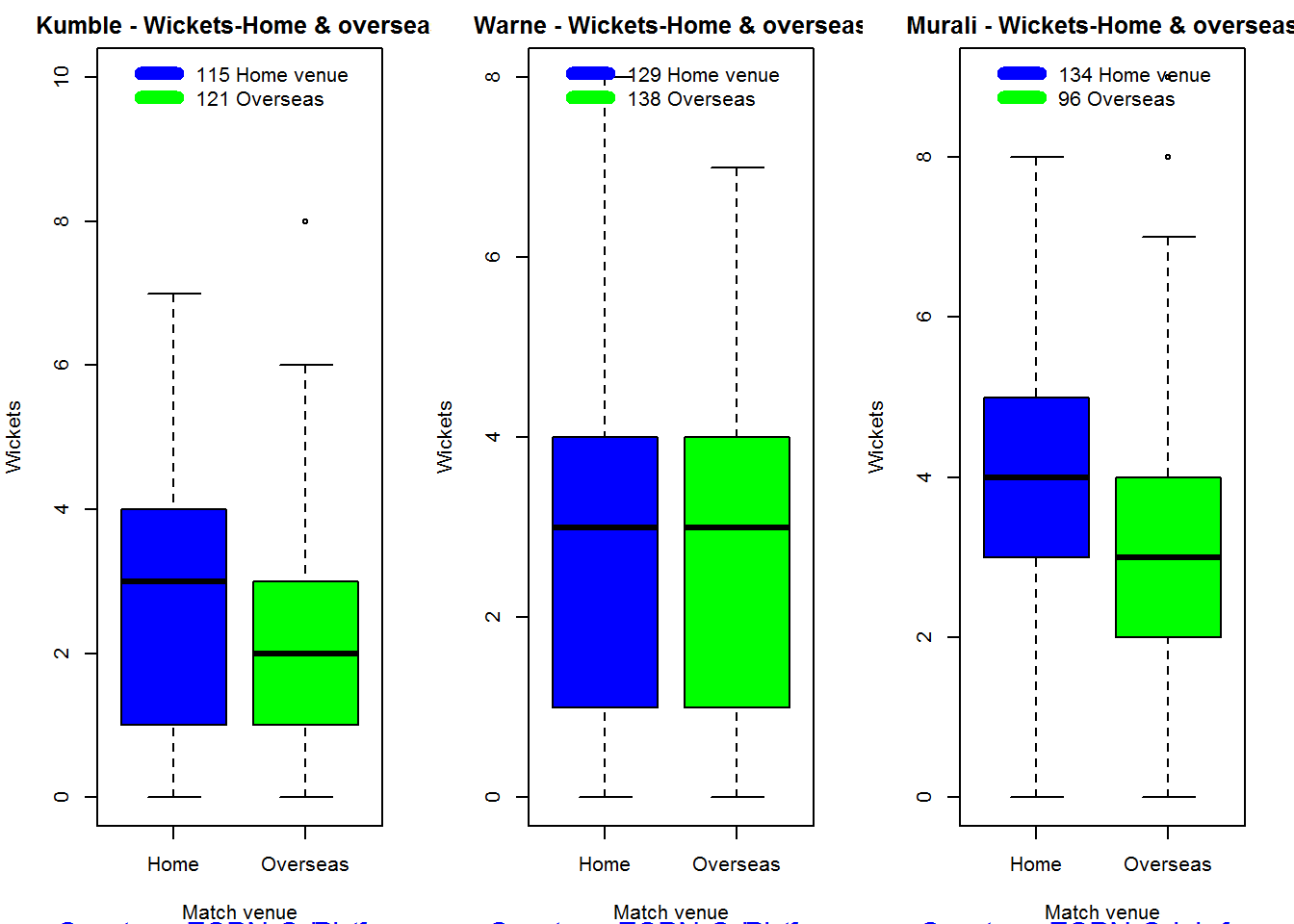
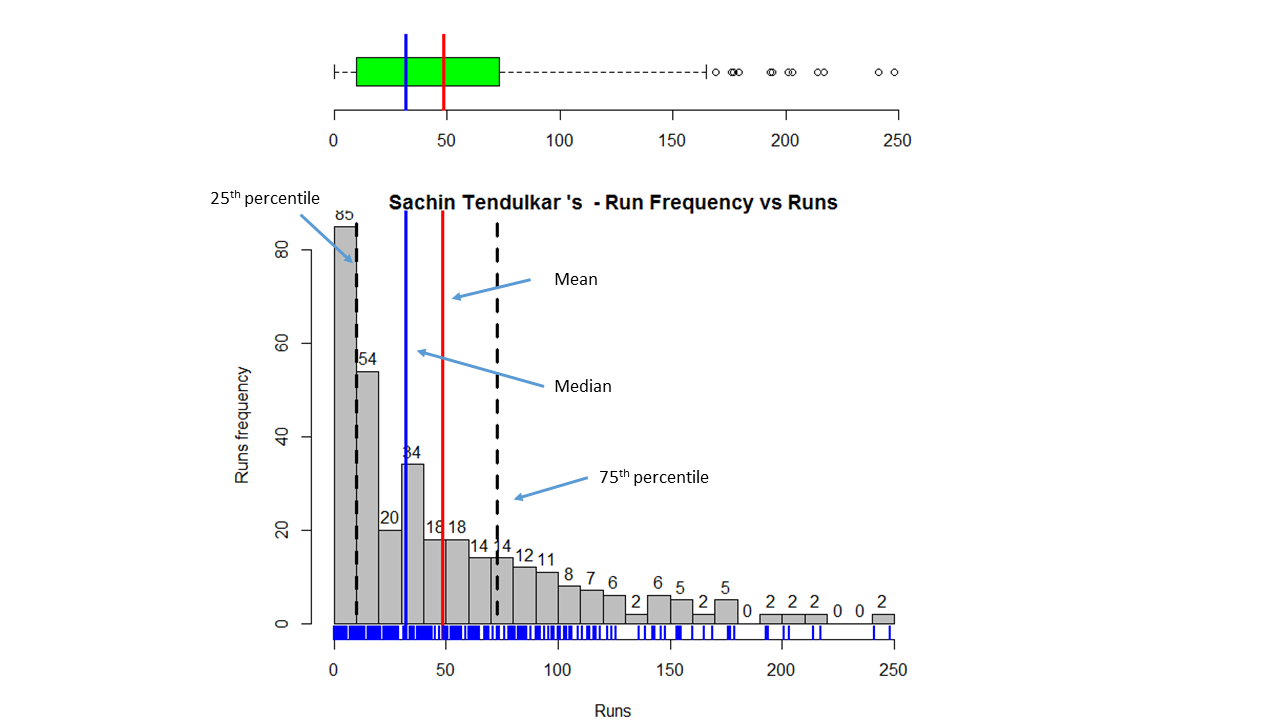
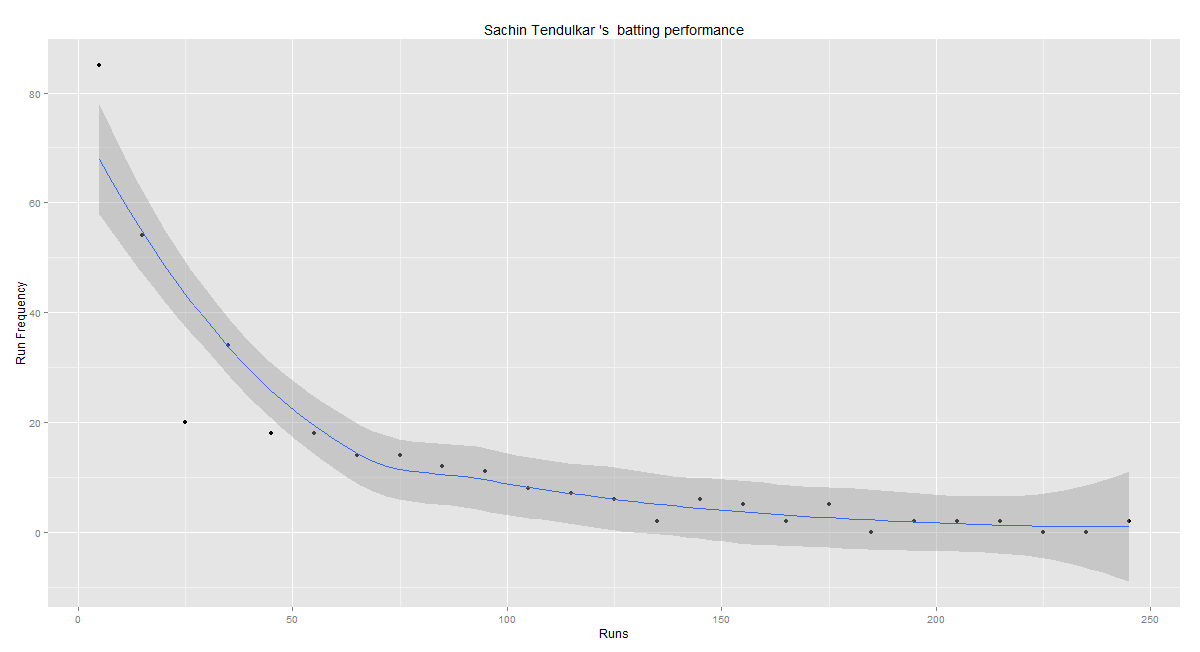
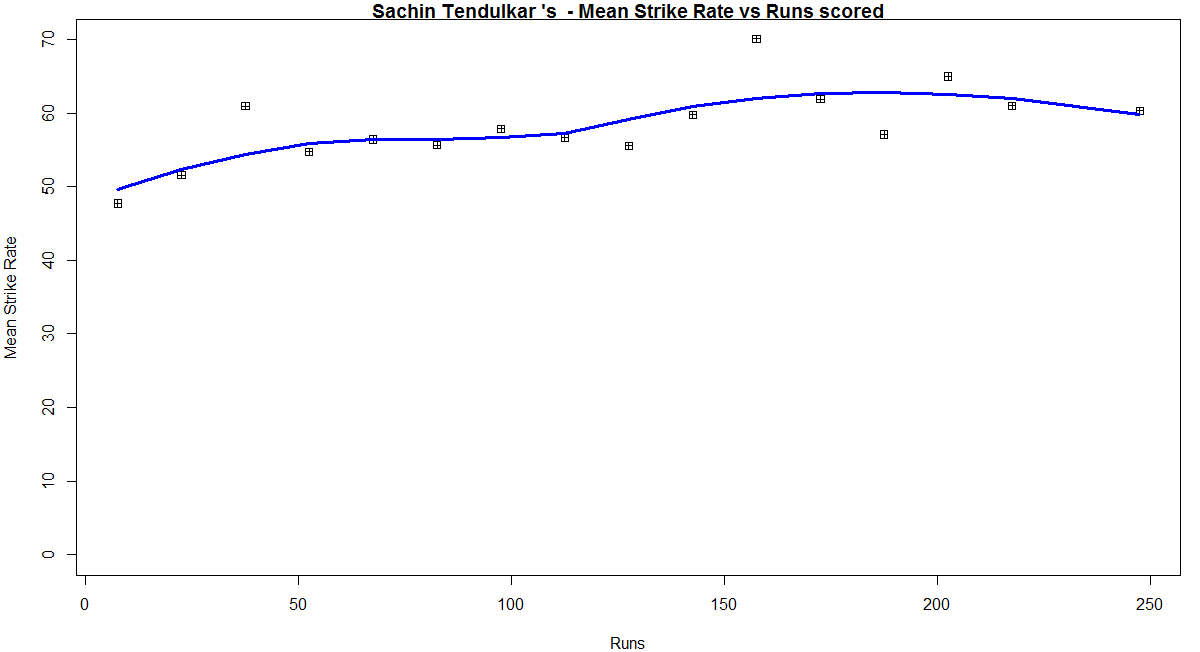
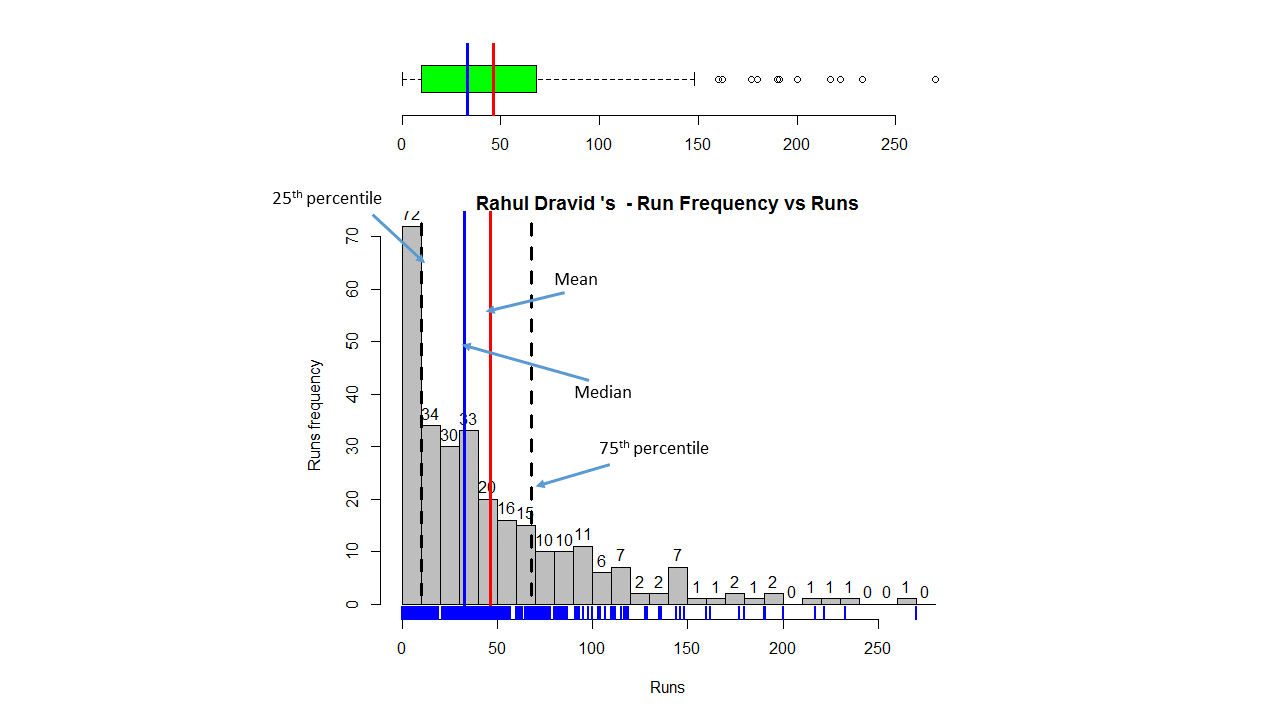
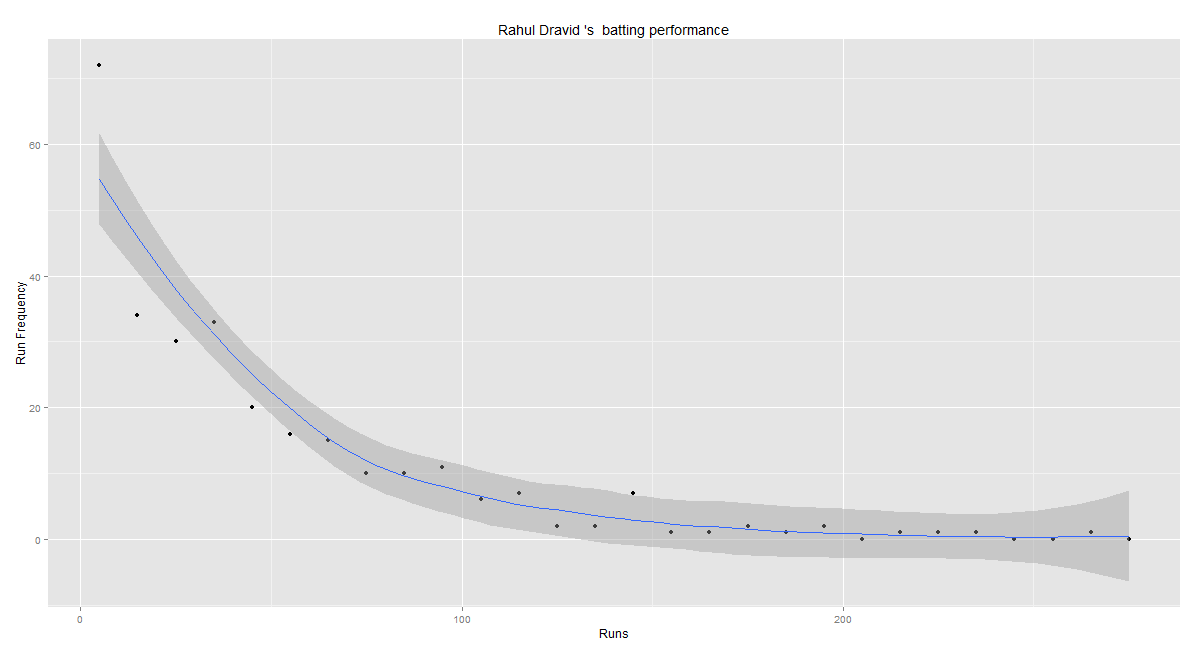
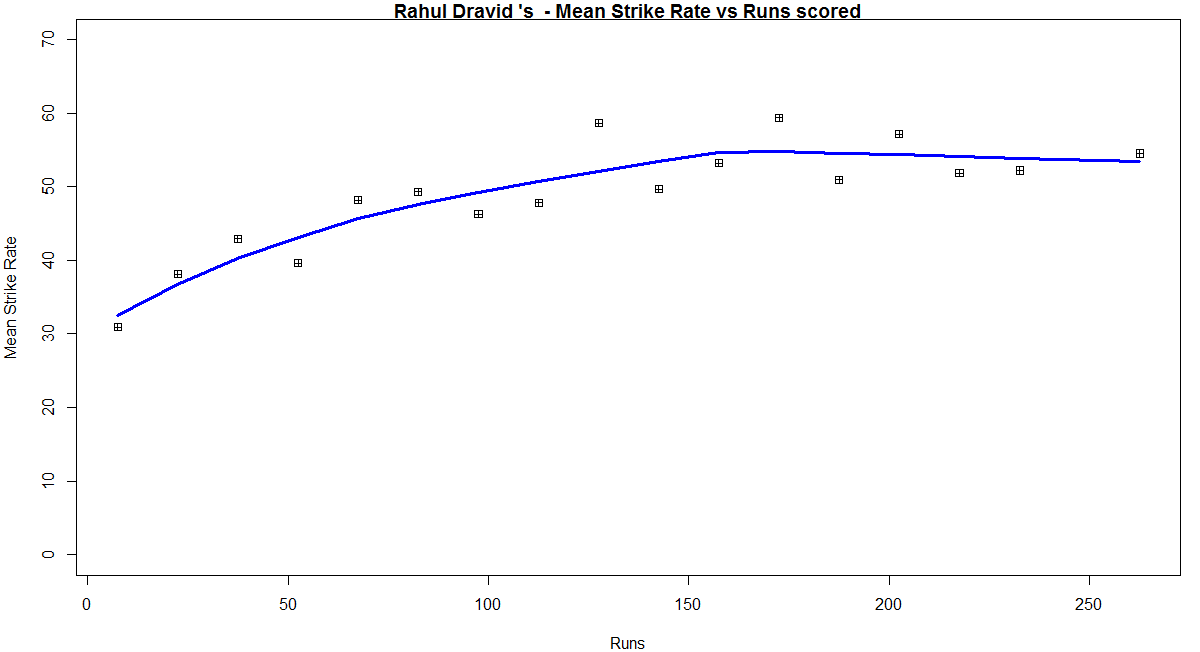
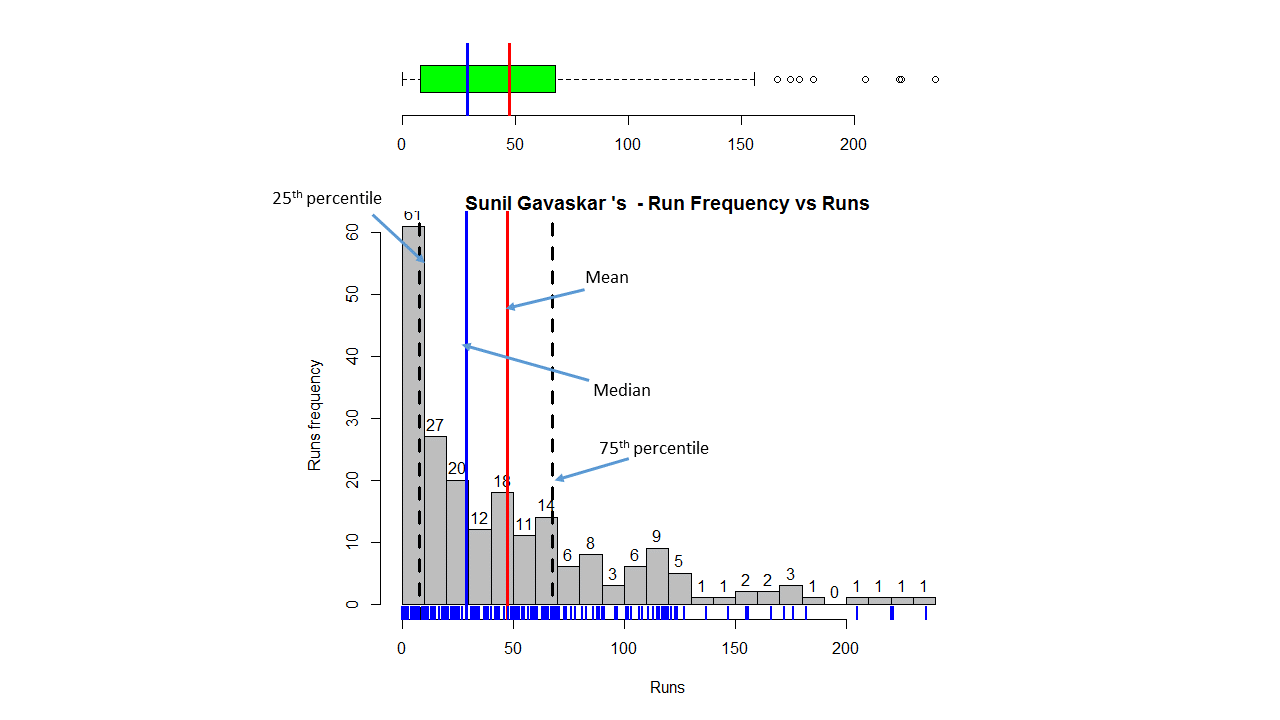
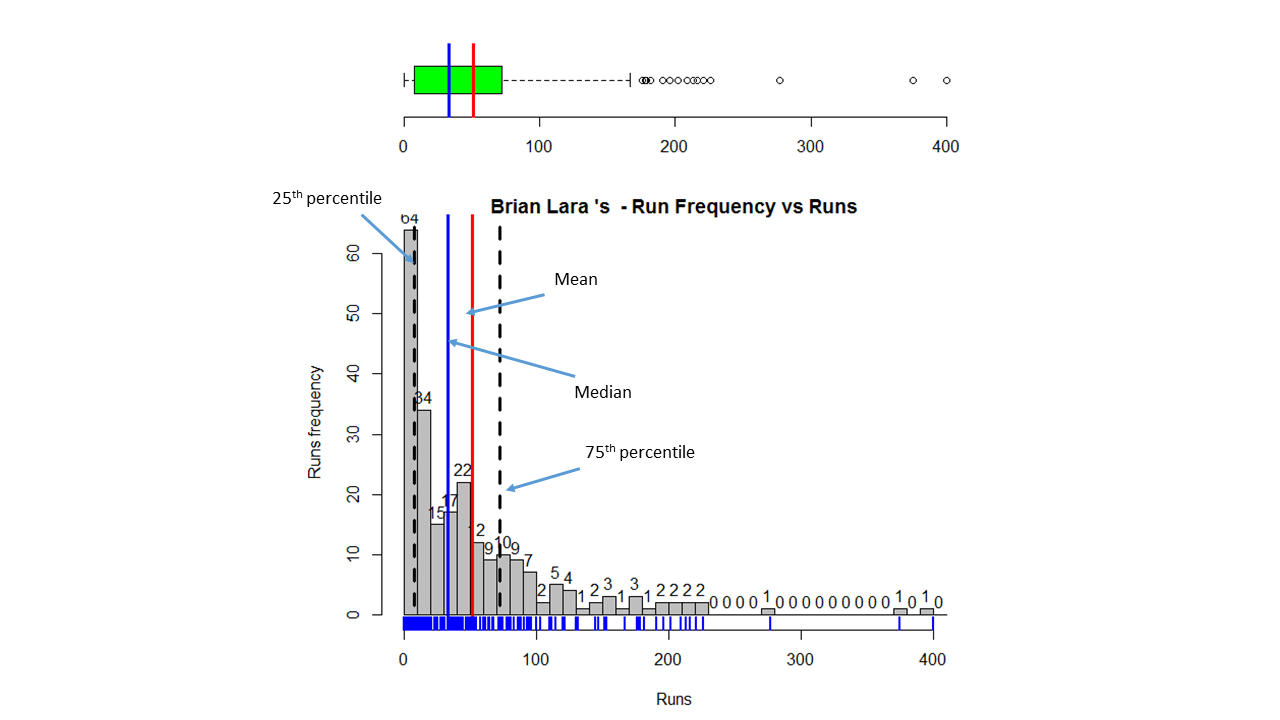
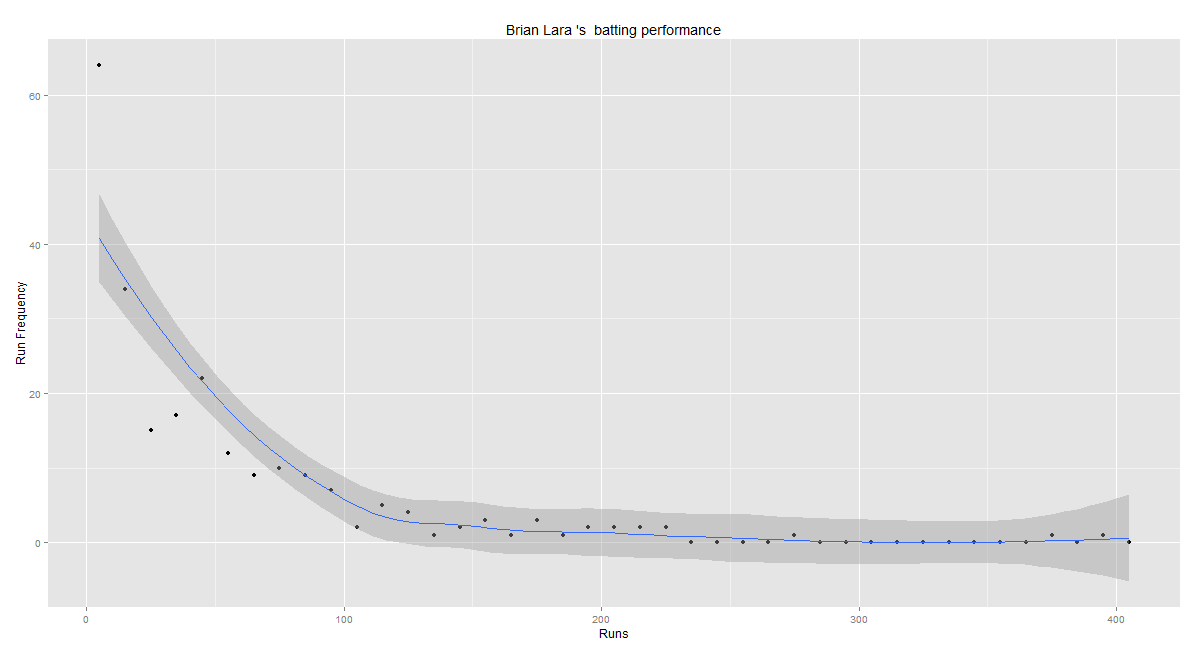
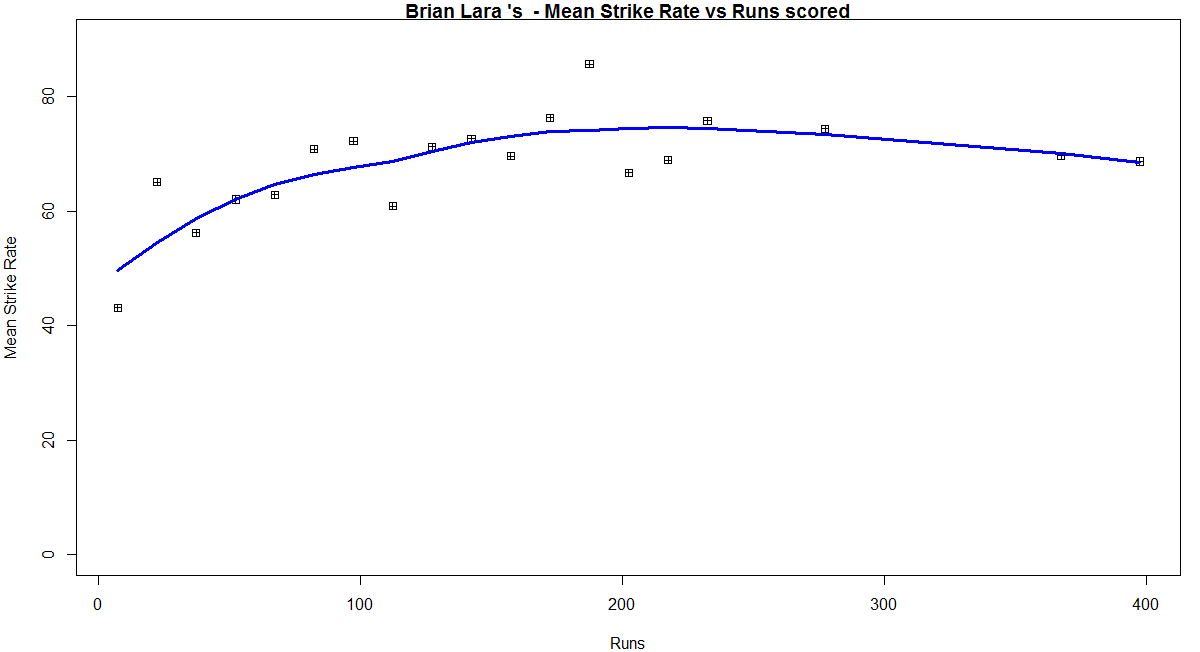
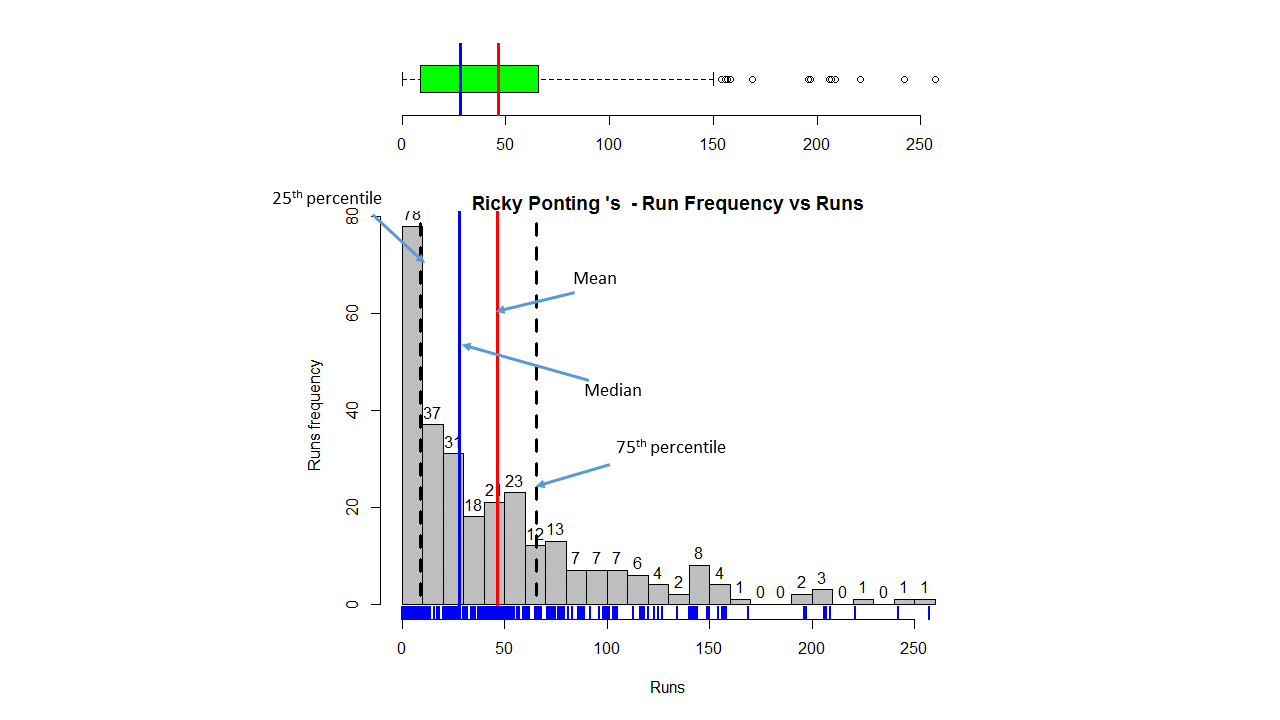
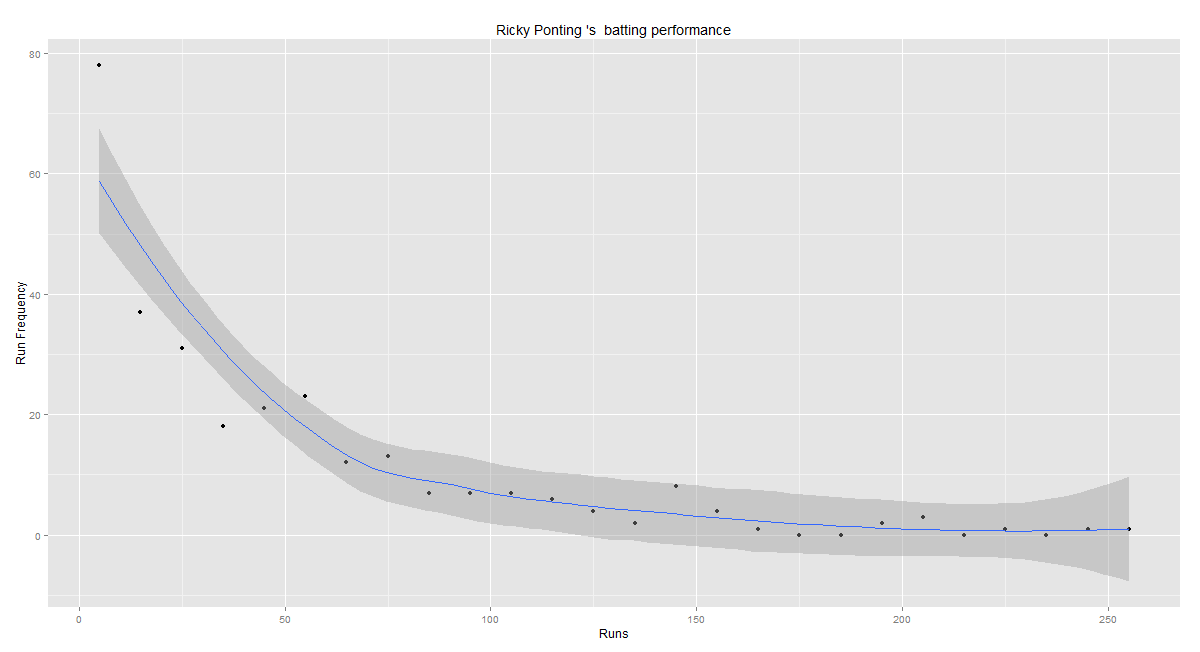
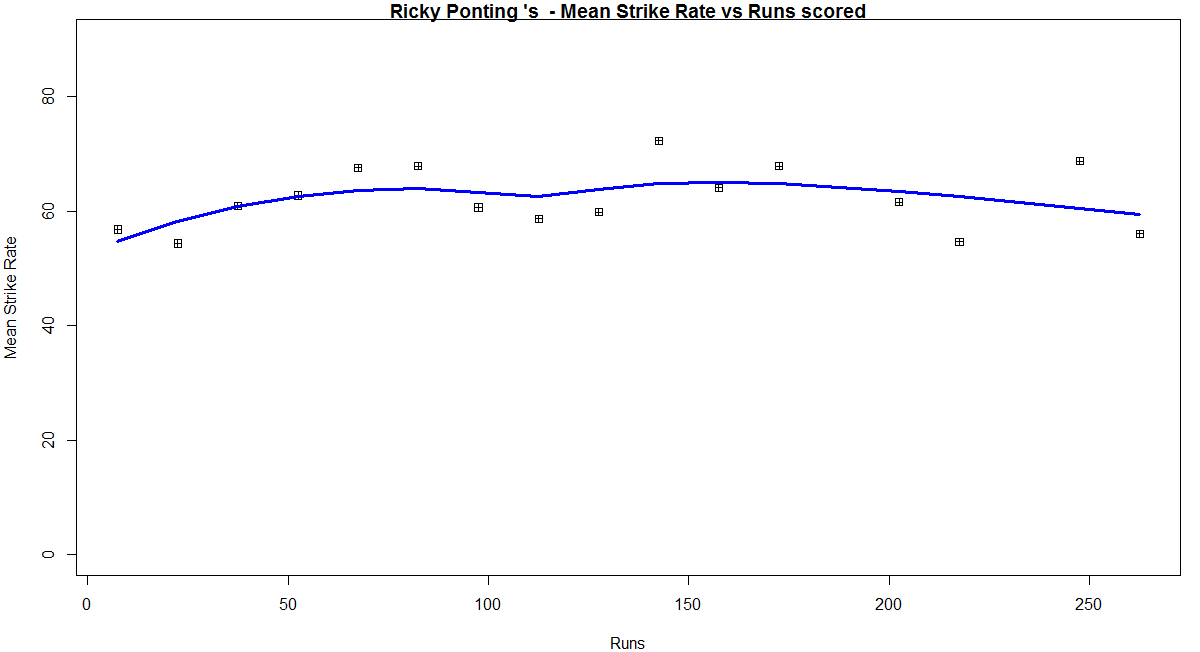
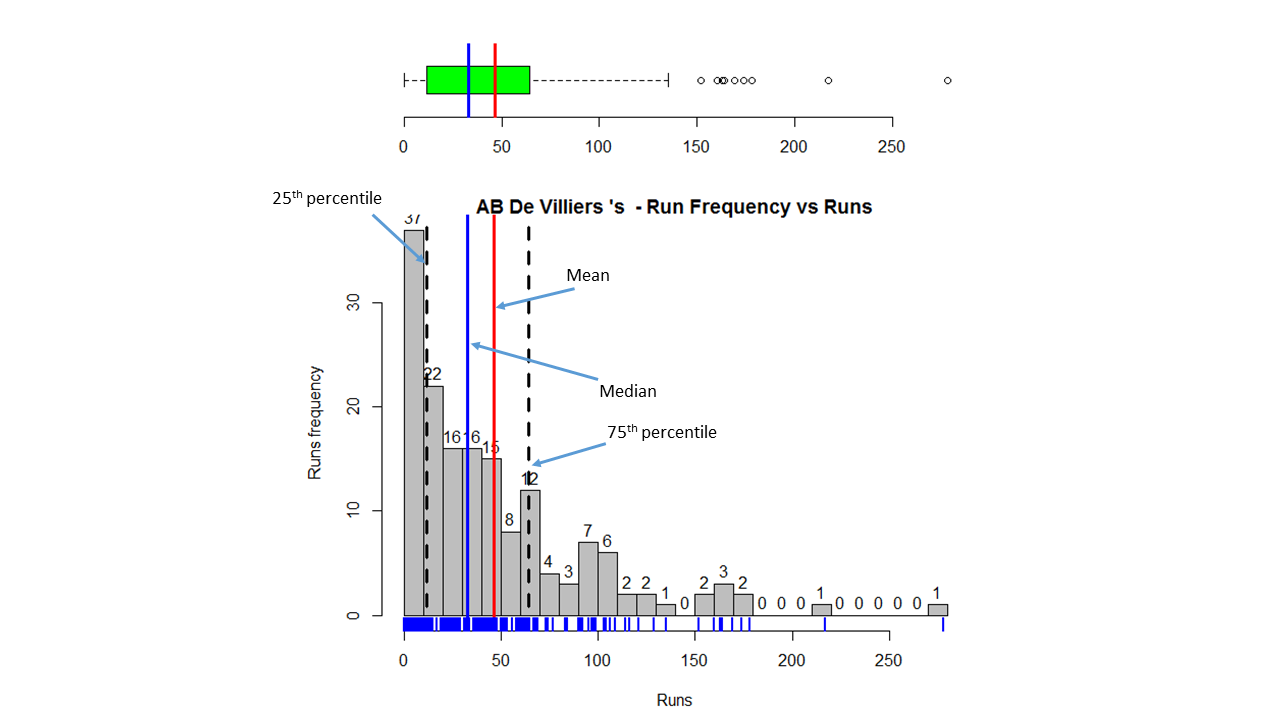
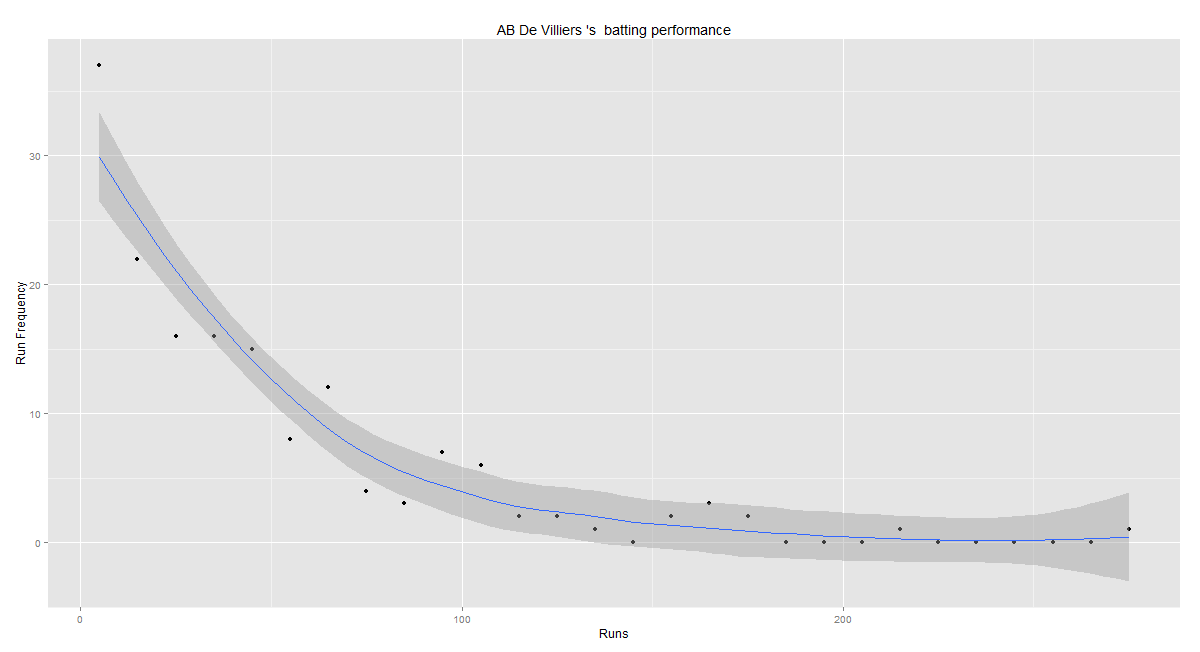
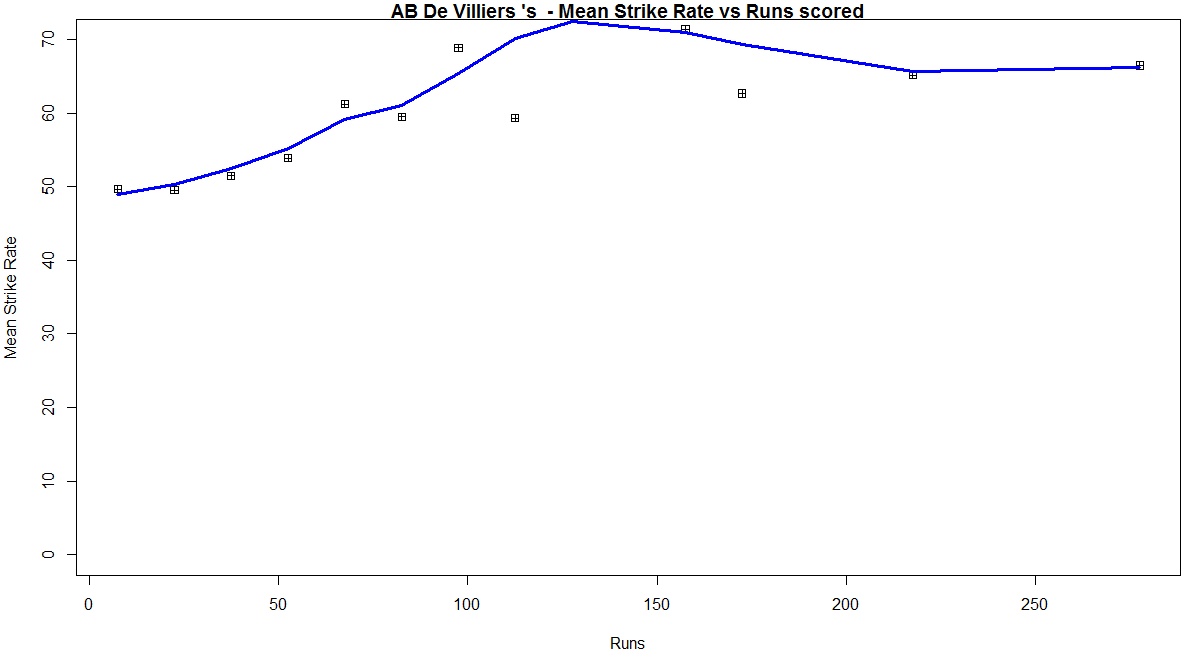
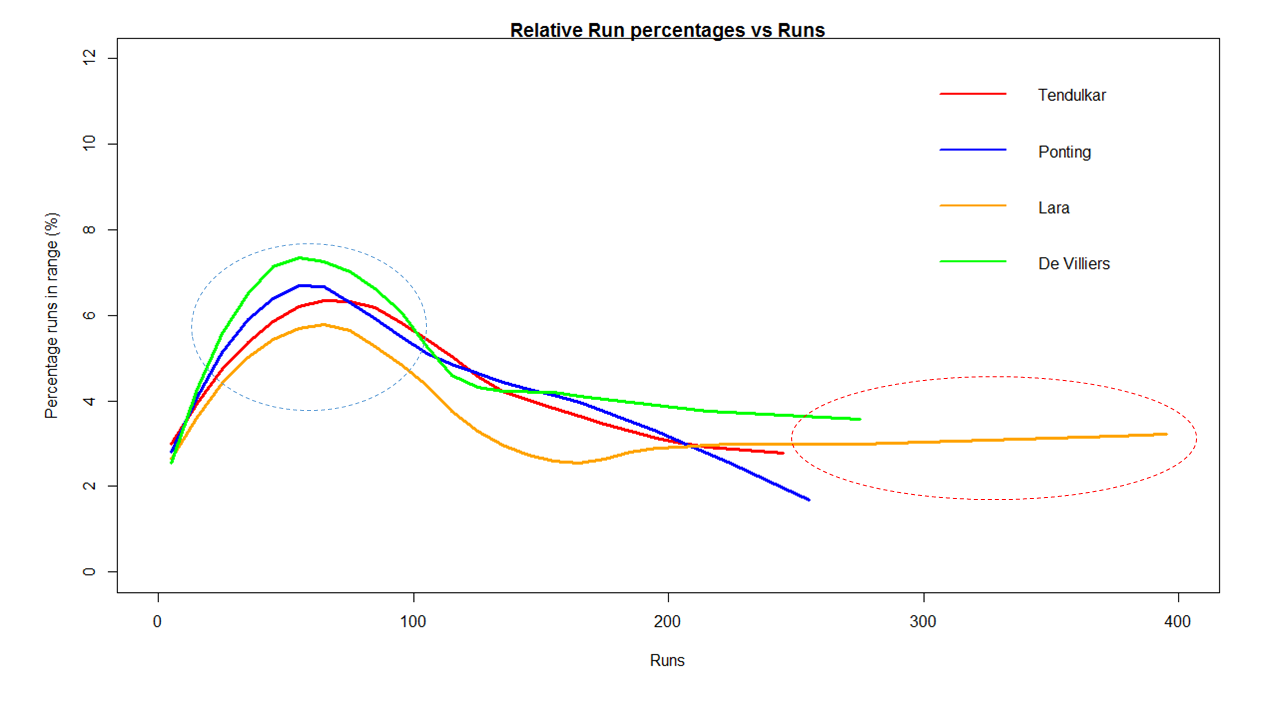
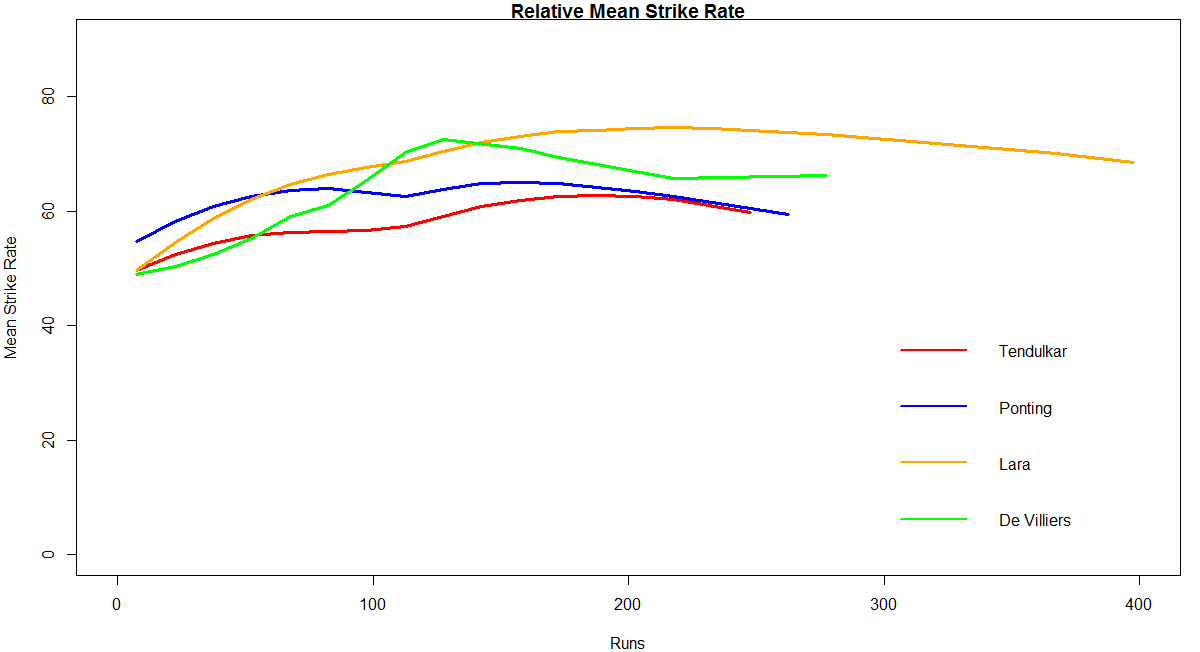
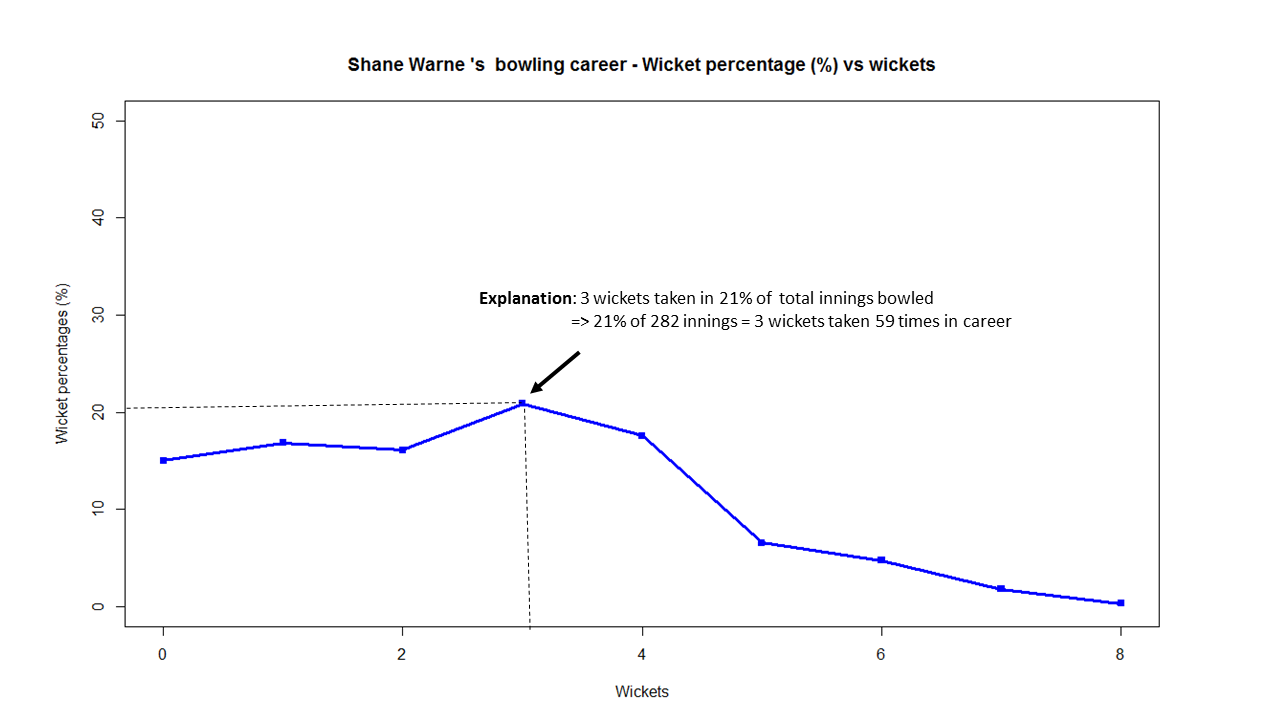
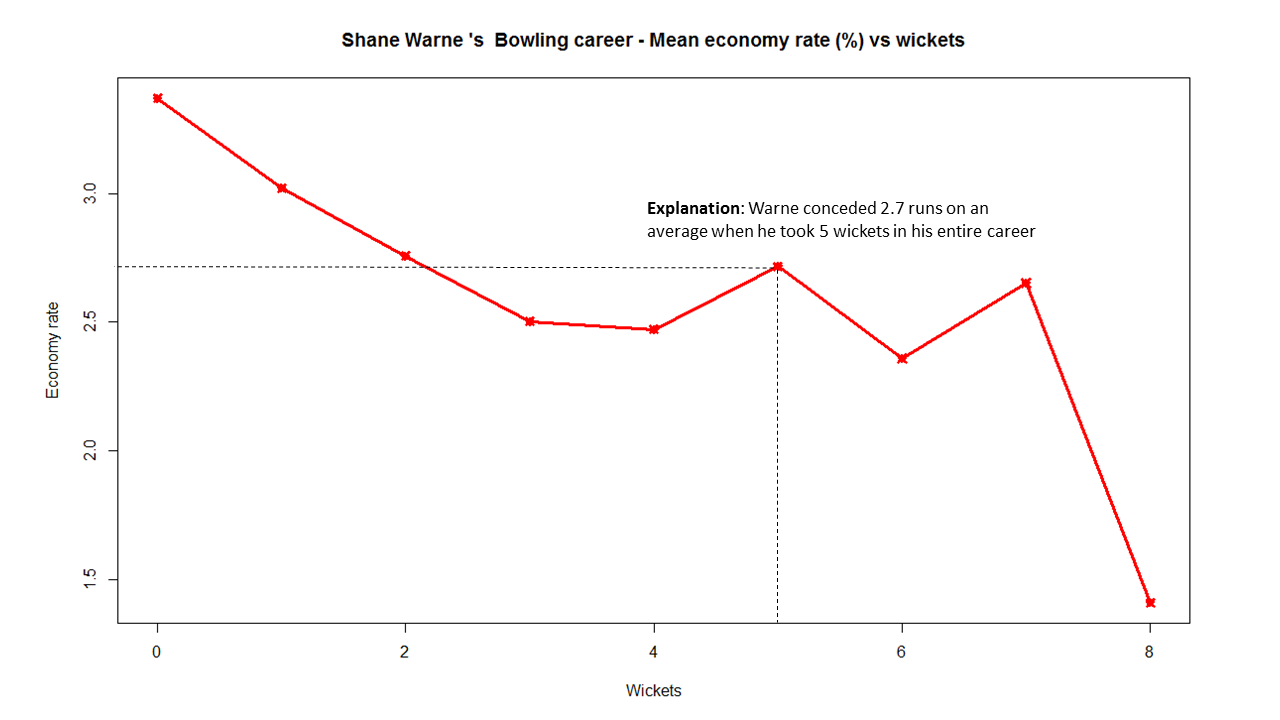
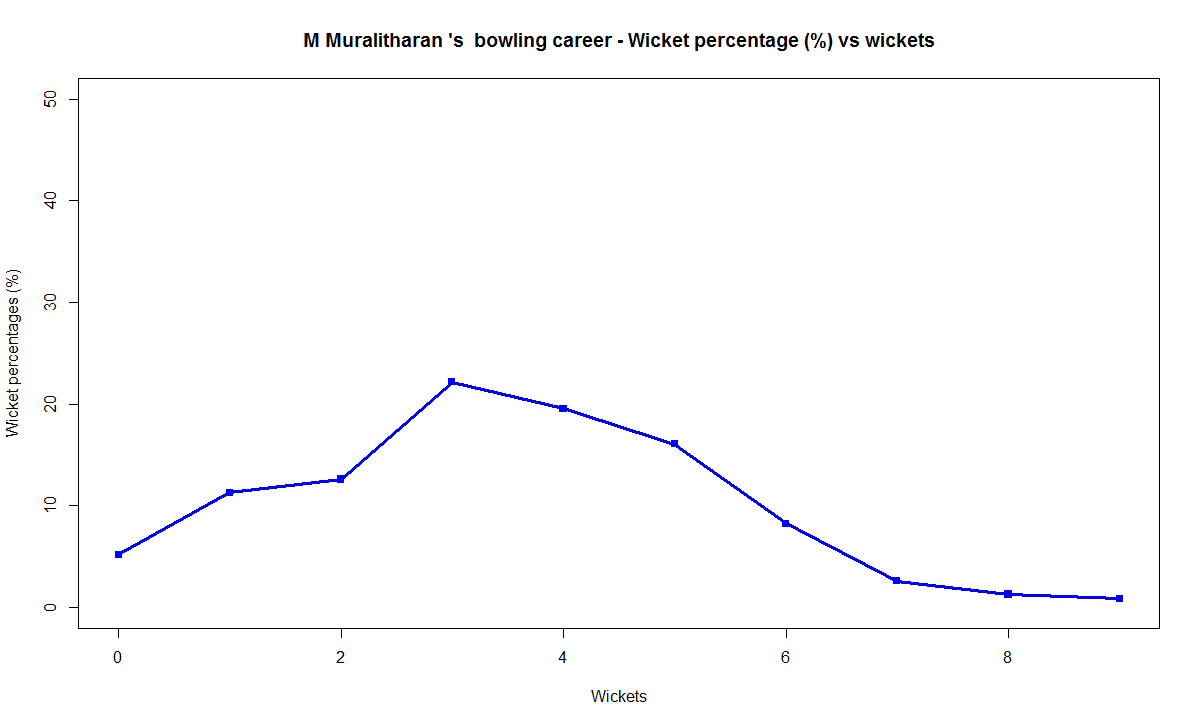
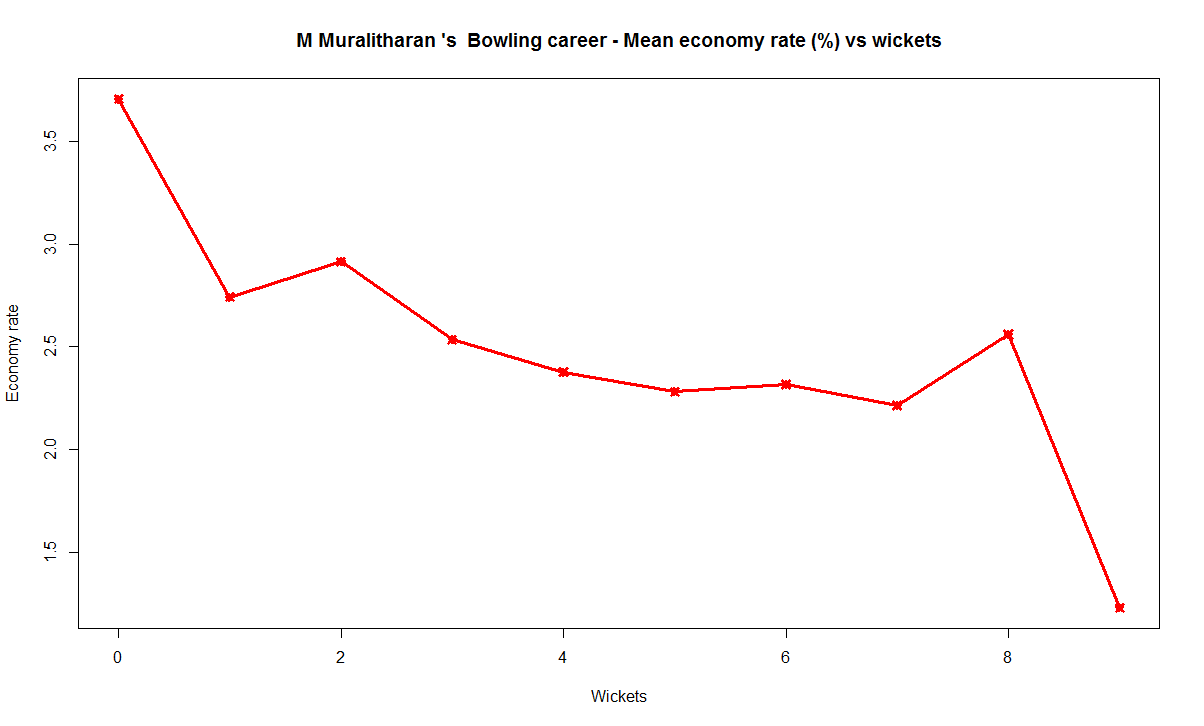
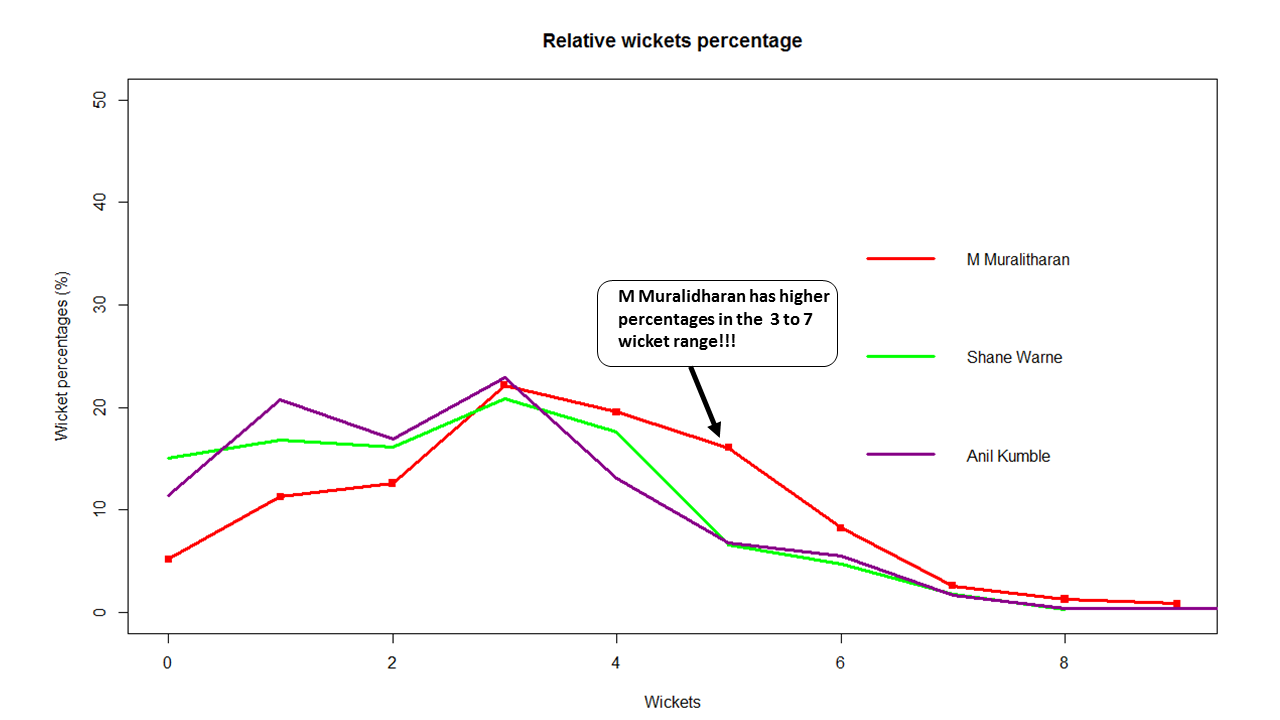
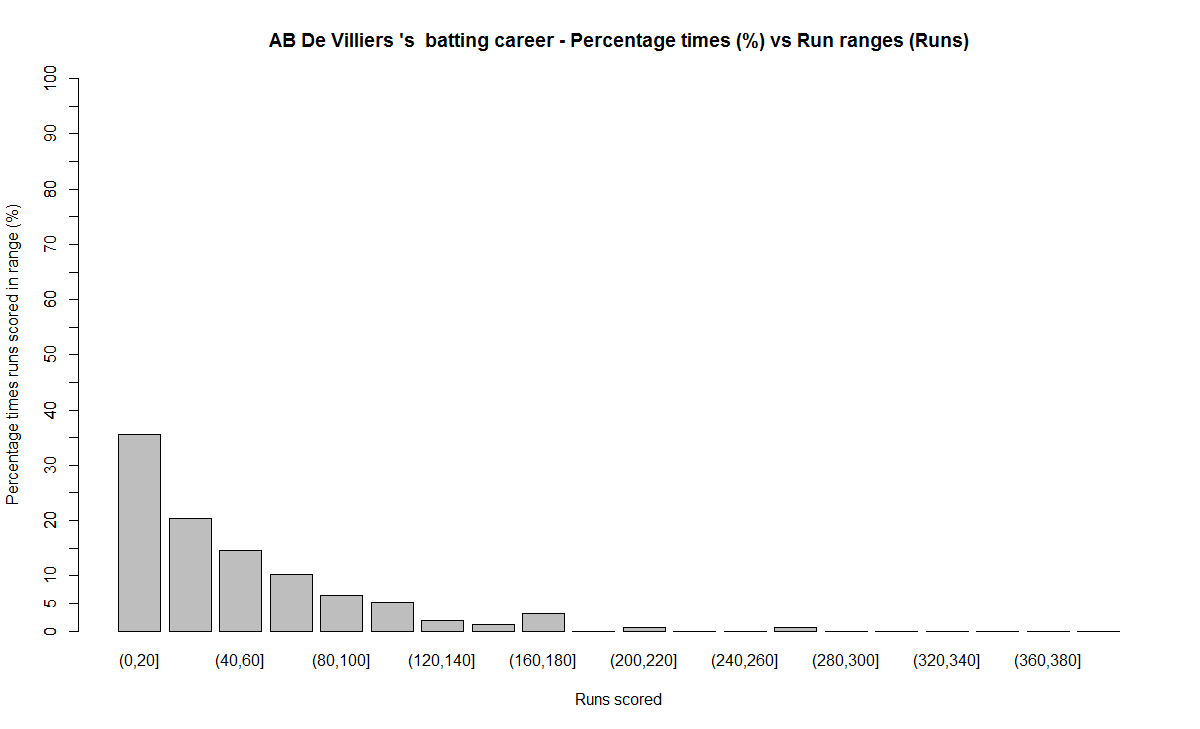
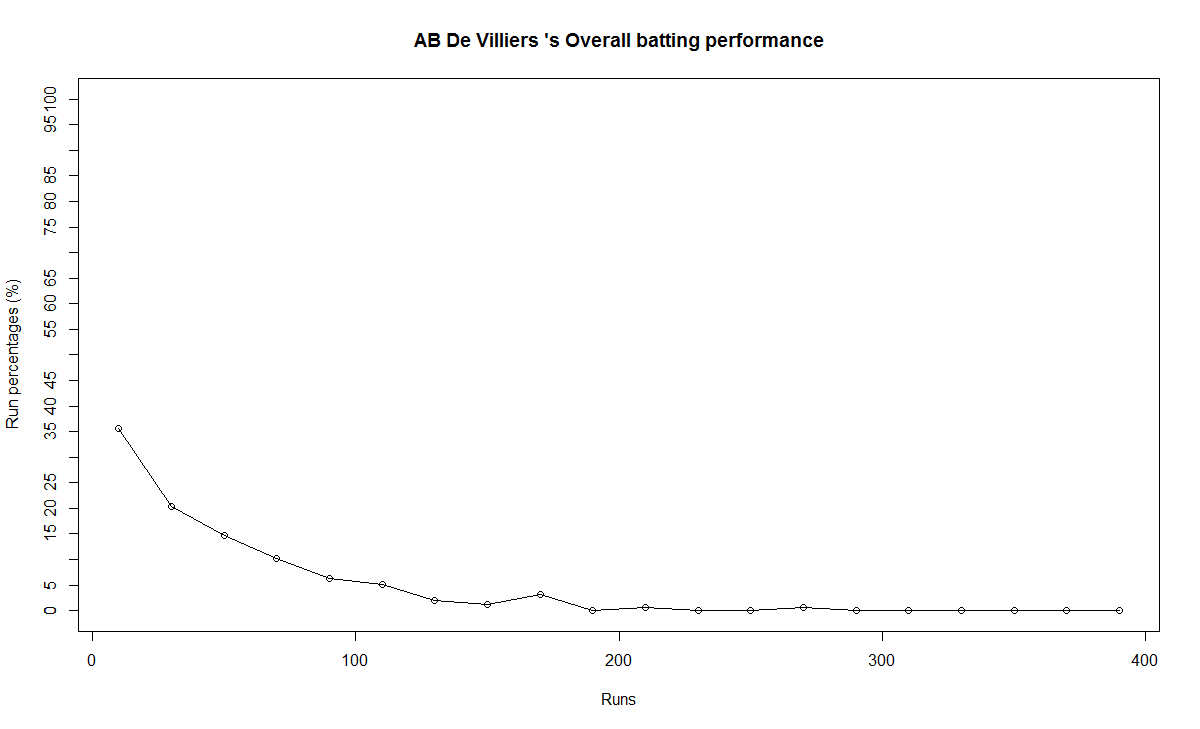
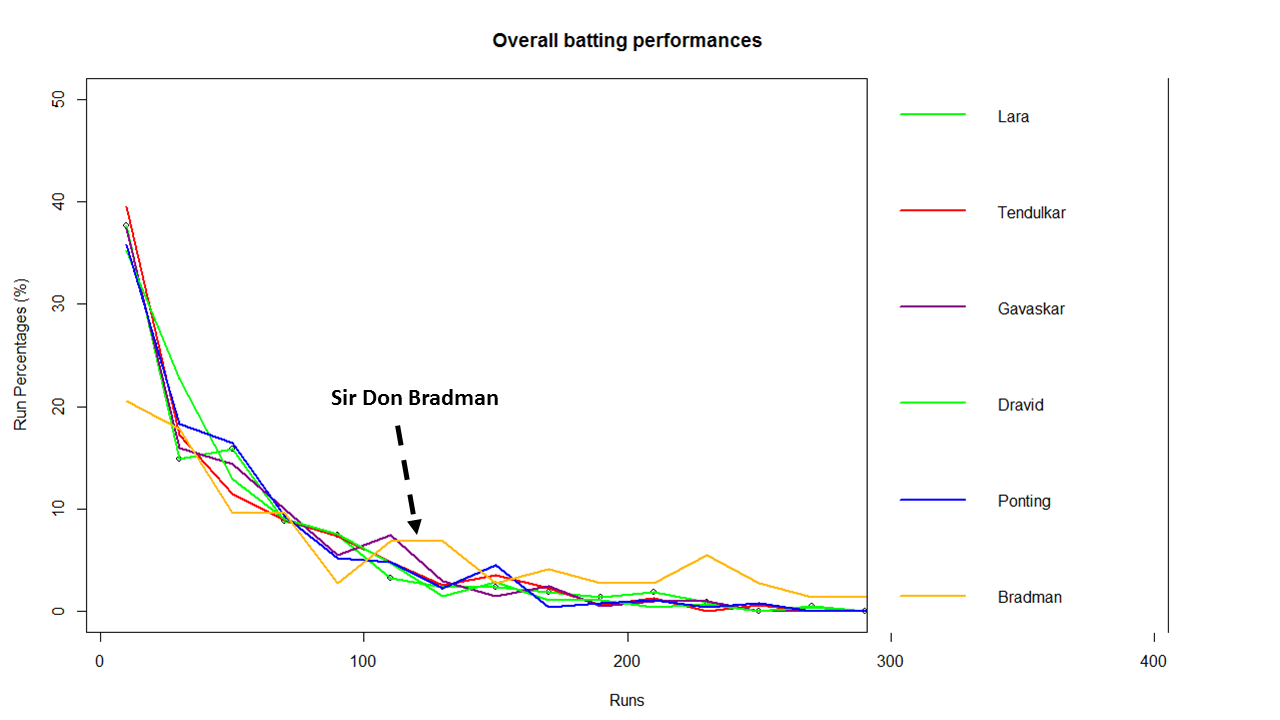
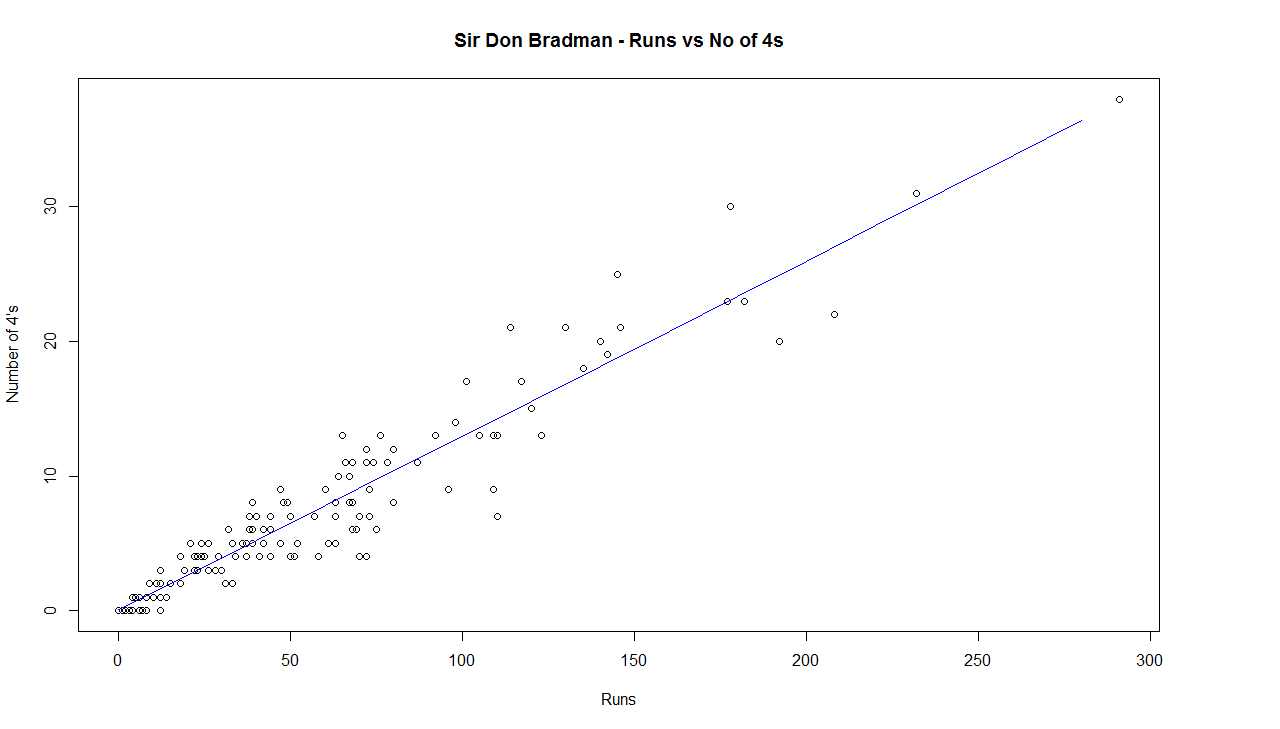
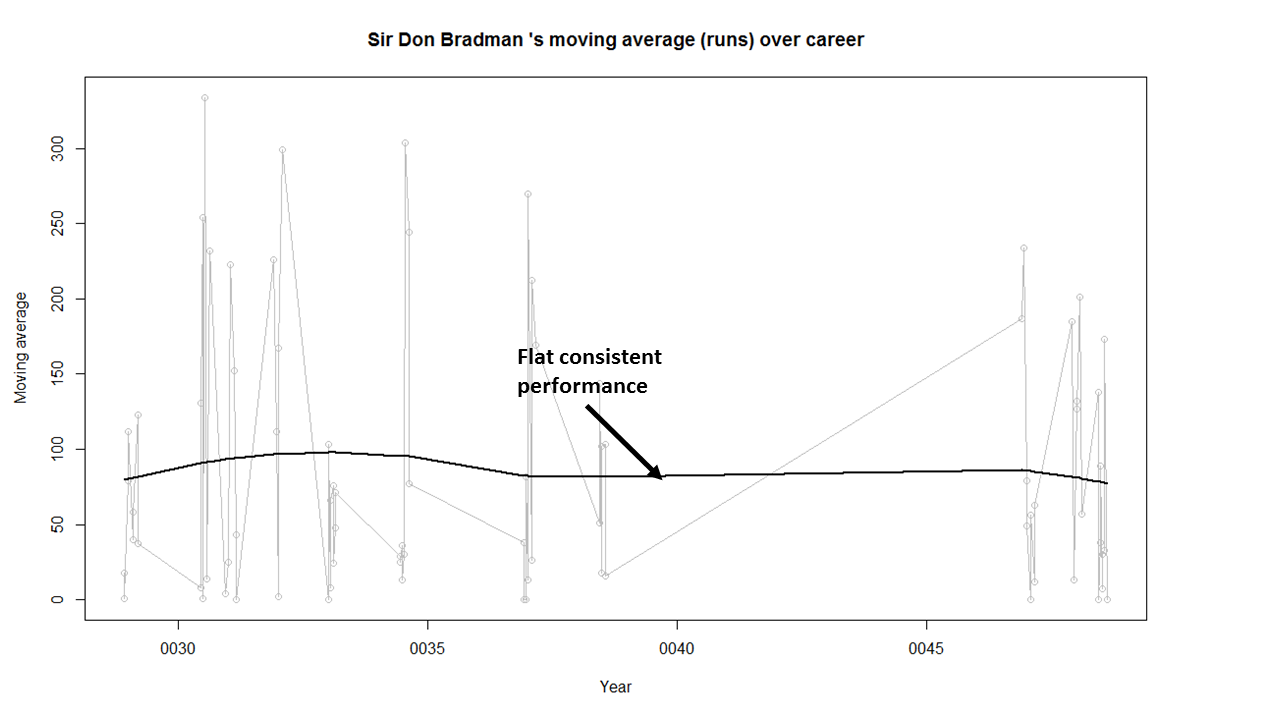
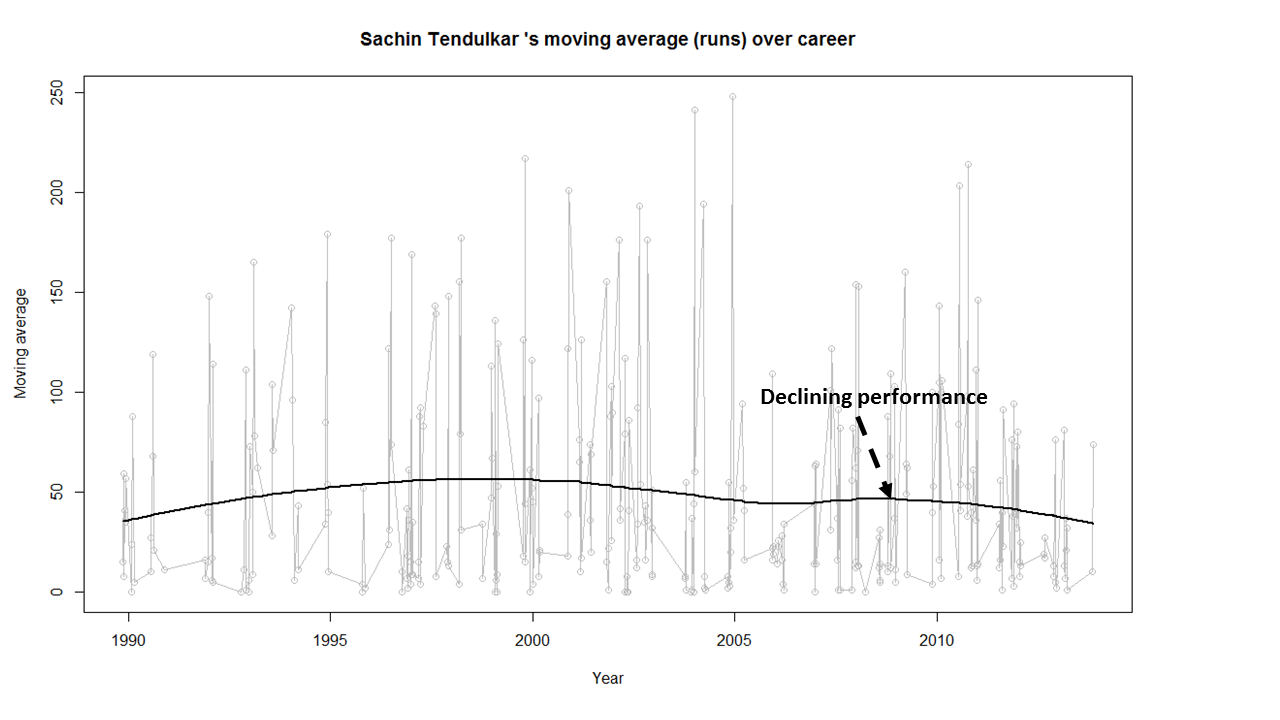
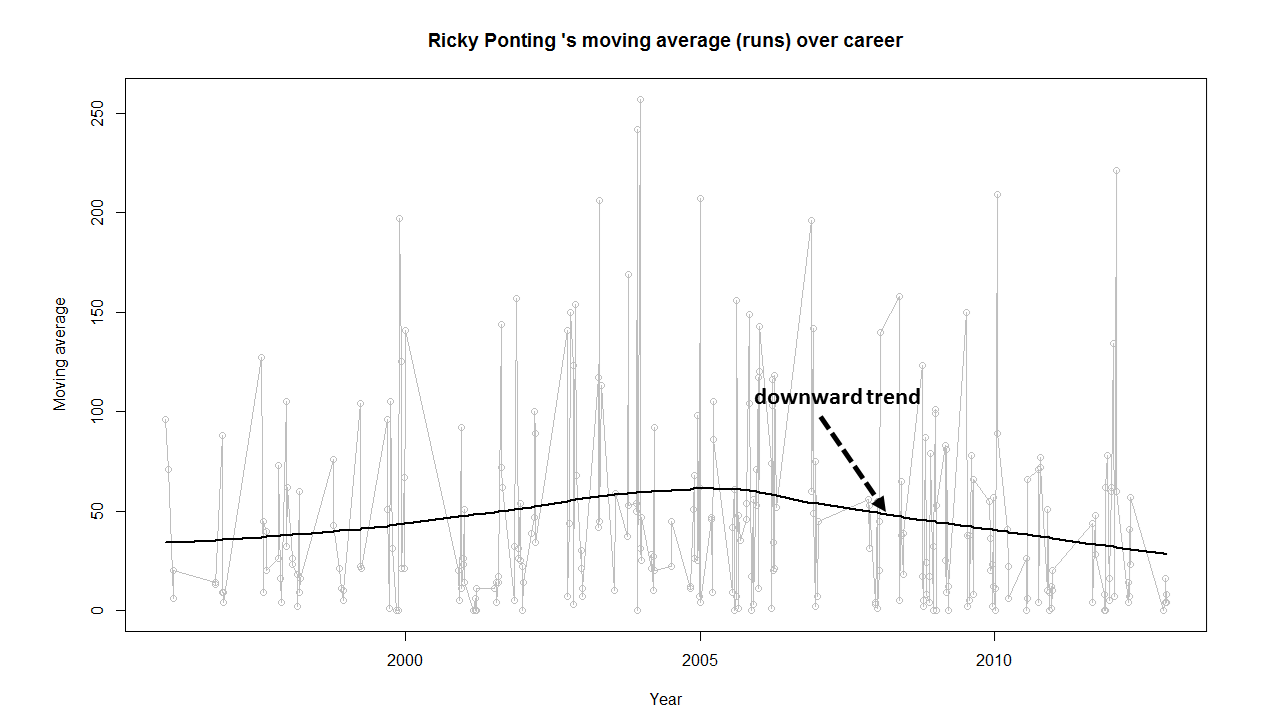
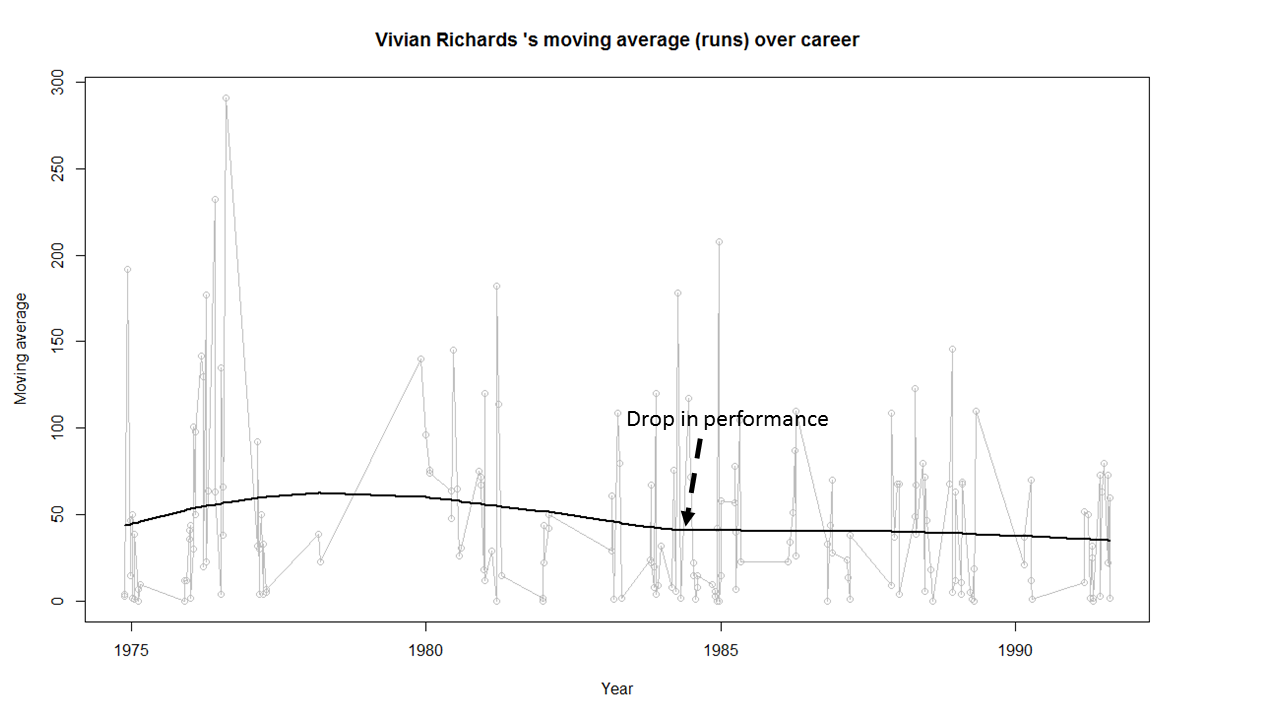
Introduction
In this post I create yorkr templates for International T20 matches that are available on Cricsheet. With these templates you can convert all T20 data which is in yaml format to R dataframes. Further I create data and the necessary templates for analyzing. All of these templates can be accessed from Github at yorkrT20Template. The templates are
- Template for conversion and setup – T20Template.Rmd
- Any T20 match – T20Matchtemplate.Rmd
- T20 matches between 2 nations – T20Matches2TeamTemplate.Rmd
- A T20 nations performance against all other T20 nations – T20AllMatchesAllOppnTemplate.Rmd
- Analysis of T20 batsmen and bowlers of all T20 nations – T20BatsmanBowlerTemplate.Rmd
Besides the templates the repository also includes the converted data for all T20 matches I downloaded from Cricsheet in Dec 2016, You can recreate the files as more matches are added to Cricsheet site. This post contains all the steps needed for T20 analysis, as more matches are played around the World and more data is added to Cricsheet. This will also be my reference in future if I decide to analyze T20 in future!
If you are passionate about cricket, and love analyzing cricket performances, then check out my 2 racy books on cricket! In my books, I perform detailed yet compact analysis of performances of both batsmen, bowlers besides evaluating team & match performances in Tests , ODIs, T20s & IPL. You can buy my books on cricket from Amazon at $12.99 for the paperback and $4.99/$6.99 respectively for the kindle versions. The books can be accessed at Cricket analytics with cricketr and Beaten by sheer pace-Cricket analytics with yorkr A must read for any cricket lover! Check it out!!
Feel free to download/clone these templates from Github yorkrT20Template and perform your own analysis
There will be 5 folders at the root
- T20data – Match files as yaml from Cricsheet
- T20Matches – Yaml match files converted to dataframes
- T20MatchesBetween2Teams – All Matches between any 2 T20 teams
- allMatchesAllOpposition – A T20 countries match data against all other teams
- BattingBowlingDetails – Batting and bowling details of all countries
library(yorkr)
library(dplyr)
The first few steps take care of the data setup. This needs to be done before any of the analysis of T20 batsmen, bowlers, any T20 match, matches between any 2 T20 countries or analysis of a teams performance against all other countries
There will be 5 folders at the root
- T20data
- T20Matches
- T20MatchesBetween2Teams
- allMatchesAllOpposition
- BattingBowlingDetails
The source YAML files will be in T20Data folder
1.Create directory T20Matches
Some files may give conversions errors. You could try to debug the problem or just remove it from the T20data folder. At most 2-4 file will have conversion problems and I usally remove then from the files to be converted.
Also take a look at my Inswinger shiny app which was created after performing the same conversion on the Dec 16 data .
convertAllYaml2RDataframesT20("T20Data","T20Matches")
2.Save all matches between all combinations of T20 nations
This function will create the set of all matches between every T20 country against every other T20 country. This uses the data that was created in T20Matches, with the convertAllYaml2RDataframesT20() function.
setwd("./T20MatchesBetween2Teams")
saveAllMatchesBetweenTeams(dir=".",odir=".")
3.Save all matches against all opposition
This will create a consolidated dataframe of all matches played by every T20 playing nation against all other nattions. This also uses the data that was created in T20Matches, with the convertAllYaml2RDataframesT20() function.
setwd("../allMatchesAllOpposition")
saveAllMatchesAllOpposition(dir=".",odir=".")
4. Create batting and bowling details for each T20 country
These are the current T20 playing nations. You can add to this vector as more countries start playing T20. You will get to know all T20 nations by also look at the directory created above namely allMatchesAllOpposition. his also uses the data that was created in T20Matches, with the convertAllYaml2RDataframesT20() function.
setwd("../BattingBowlingDetails")
teams <-c("Australia","India","Pakistan","West Indies", 'Sri Lanka',
"England", "Bangladesh","Netherlands","Scotland", "Afghanistan",
"Zimbabwe","Ireland","New Zealand","South Africa","Canada",
"Bermuda","Kenya","Hong Kong","Nepal","Oman","Papua New Guinea",
"United Arab Emirates")
for(i in seq_along(teams)){
print(teams[i])
val <- paste(teams[i],"-details",sep="")
val <- getTeamBattingDetails(teams[i],dir="../T20Matches", save=TRUE)
}
for(i in seq_along(teams)){
print(teams[i])
val <- paste(teams[i],"-details",sep="")
val <- getTeamBowlingDetails(teams[i],dir="../T20Matches", save=TRUE)
}
5. Get the list of batsmen for a particular country
For e.g. if you wanted to get the batsmen of Canada you would do the following. By replacing Canada for any other country you can get the batsmen of that country. These batsmen names can then be used in the batsmen analysis
country="Canada"
teamData <- paste(country,"-BattingDetails.RData",sep="")
load(teamData)
countryDF <- battingDetails
bmen <- countryDF %>% distinct(batsman)
bmen <- as.character(bmen$batsman)
batsmen <- sort(bmen)
batsmen
6. Get the list of bowlers for a particular country
The method below can get the list of bowler names for any T20 nation. These names can then be used in the bowler analysis below
country="Netherlands"
teamData <- paste(country,"-BowlingDetails.RData",sep="")
load(teamData)
countryDF <- bowlingDetails
bwlr <- countryDF %>% distinct(bowler)
bwlr <- as.character(bwlr$bowler)
bowler <- sort(bwlr)
bowler
Now we are all set
A) International T20 Match Analysis
Load any match data from the ./T20Matches folder for e.g. Afganistan-England-2016-03-23.RData
setwd("./T20Matches")
load("Afghanistan-England-2016-03-23.RData")
afg_eng<- overs
#The steps are
load("Country1-Country2-Date.Rdata")
country1_country2 <- overs
All analysis for this match can be done now
2. Scorecard
teamBattingScorecardMatch(country1_country2,"Country1")
teamBattingScorecardMatch(country1_country2,"Country2")
3.Batting Partnerships
teamBatsmenPartnershipMatch(country1_country2,"Country1","Country2")
teamBatsmenPartnershipMatch(country1_country2,"Country2","Country1")
4. Batsmen vs Bowler Plot
teamBatsmenVsBowlersMatch(country1_country2,"Country1","Country2",plot=TRUE)
teamBatsmenVsBowlersMatch(country1_country2,"Country1","Country2",plot=FALSE)
5. Team bowling scorecard
teamBowlingScorecardMatch(country1_country2,"Country1")
teamBowlingScorecardMatch(country1_country2,"Country2")
6. Team bowling Wicket kind match
teamBowlingWicketKindMatch(country1_country2,"Country1","Country2")
m <-teamBowlingWicketKindMatch(country1_country2,"Country1","Country2",plot=FALSE)
m
7. Team Bowling Wicket Runs Match
teamBowlingWicketRunsMatch(country1_country2,"Country1","Country2")
m <-teamBowlingWicketRunsMatch(country1_country2,"Country1","Country2",plot=FALSE)
m
8. Team Bowling Wicket Match
m <-teamBowlingWicketMatch(country1_country2,"Country1","Country2",plot=FALSE)
m
teamBowlingWicketMatch(country1_country2,"Country1","Country2")
9. Team Bowler vs Batsmen
teamBowlersVsBatsmenMatch(country1_country2,"Country1","Country2")
m <- teamBowlersVsBatsmenMatch(country1_country2,"Country1","Country2",plot=FALSE)
m
10. Match Worm chart
matchWormGraph(country1_country2,"Country1","Country2")
B) International T20 Matches between 2 teams
Load match data between any 2 teams from ./T20MatchesBetween2Teams for e.g.Australia-India-allMatches
setwd("./T20MatchesBetween2Teams")
load("Australia-India-allMatches.RData")
aus_ind_matches <- matches
#Replace below with your own countries
country1<-"England"
country2 <- "South Africa"
country1VsCountry2 <- paste(country1,"-",country2,"-allMatches.RData",sep="")
load(country1VsCountry2)
country1_country2_matches <- matches
2.Batsmen partnerships
m<- teamBatsmenPartnershiOppnAllMatches(country1_country2_matches,"country1",report="summary")
m
m<- teamBatsmenPartnershiOppnAllMatches(country1_country2_matches,"country2",report="summary")
m
m<- teamBatsmenPartnershiOppnAllMatches(country1_country2_matches,"country1",report="detailed")
m
teamBatsmenPartnershipOppnAllMatchesChart(country1_country2_matches,"country1","country2")
3. Team batsmen vs bowlers
teamBatsmenVsBowlersOppnAllMatches(country1_country2_matches,"country1","country2")
4. Bowling scorecard
a <-teamBattingScorecardOppnAllMatches(country1_country2_matches,main="country1",opposition="country2")
a
5. Team bowling performance
teamBowlingPerfOppnAllMatches(country1_country2_matches,main="country1",opposition="country2")
6. Team bowler wickets
teamBowlersWicketsOppnAllMatches(country1_country2_matches,main="country1",opposition="country2")
m <-teamBowlersWicketsOppnAllMatches(country1_country2_matches,main="country1",opposition="country2",plot=FALSE)
teamBowlersWicketsOppnAllMatches(country1_country2_matches,"country1","country2",top=3)
m
7. Team bowler vs batsmen
teamBowlersVsBatsmenOppnAllMatches(country1_country2_matches,"country1","country2",top=5)
8. Team bowler wicket kind
teamBowlersWicketKindOppnAllMatches(country1_country2_matches,"country1","country2",plot=TRUE)
m <- teamBowlersWicketKindOppnAllMatches(country1_country2_matches,"country1","country2",plot=FALSE)
m[1:30,]
9. Team bowler wicket runs
teamBowlersWicketRunsOppnAllMatches(country1_country2_matches,"country1","country2")
10. Plot wins and losses
setwd("./T20Matches")
plotWinLossBetweenTeams("country1","country2")
C) International T20 Matches for a team against all other teams
Load the data between for a T20 team against all other countries ./allMatchesAllOpposition for e.g all matches of India
load("allMatchesAllOpposition-India.RData")
india_matches <- matches
country="country1"
allMatches <- paste("allMatchesAllOposition-",country,".RData",sep="")
load(allMatches)
country1AllMatches <- matches
2. Team’s batting scorecard all Matches
m <-teamBattingScorecardAllOppnAllMatches(country1AllMatches,theTeam="country1")
m
3. Batting scorecard of opposing team
m <-teamBattingScorecardAllOppnAllMatches(matches=country1AllMatches,theTeam="country2")
4. Team batting partnerships
m <- teamBatsmenPartnershipAllOppnAllMatches(country1AllMatches,theTeam="country1")
m
m <- teamBatsmenPartnershipAllOppnAllMatches(country1AllMatches,theTeam='country1',report="detailed")
head(m,30)
m <- teamBatsmenPartnershipAllOppnAllMatches(country1AllMatches,theTeam='country1',report="summary")
m
5. Team batting partnerships plot
teamBatsmenPartnershipAllOppnAllMatchesPlot(country1AllMatches,"country1",main="country1")
teamBatsmenPartnershipAllOppnAllMatchesPlot(country1AllMatches,"country1",main="country2")
6, Team batsmen vs bowlers report
m <-teamBatsmenVsBowlersAllOppnAllMatchesRept(country1AllMatches,"country1",rank=0)
m
m <-teamBatsmenVsBowlersAllOppnAllMatchesRept(country1AllMatches,"country1",rank=1,dispRows=30)
m
m <-teamBatsmenVsBowlersAllOppnAllMatchesRept(matches=country1AllMatches,theTeam="country2",rank=1,dispRows=25)
m
7. Team batsmen vs bowler plot
d <- teamBatsmenVsBowlersAllOppnAllMatchesRept(country1AllMatches,"country1",rank=1,dispRows=50)
d
teamBatsmenVsBowlersAllOppnAllMatchesPlot(d)
d <- teamBatsmenVsBowlersAllOppnAllMatchesRept(country1AllMatches,"country1",rank=2,dispRows=50)
teamBatsmenVsBowlersAllOppnAllMatchesPlot(d)
8. Team bowling scorecard
teamBowlingScorecardAllOppnAllMatchesMain(matches=country1AllMatches,theTeam="country1")
teamBowlingScorecardAllOppnAllMatches(country1AllMatches,'country2')
9. Team bowler vs batsmen
teamBowlersVsBatsmenAllOppnAllMatchesMain(country1AllMatches,theTeam="country1",rank=0)
teamBowlersVsBatsmenAllOppnAllMatchesMain(country1AllMatches,theTeam="country1",rank=2)
teamBowlersVsBatsmenAllOppnAllMatchesRept(matches=country1AllMatches,theTeam="country1",rank=0)
10. Team Bowler vs bastmen
df <- teamBowlersVsBatsmenAllOppnAllMatchesRept(country1AllMatches,theTeam="country1",rank=1)
teamBowlersVsBatsmenAllOppnAllMatchesPlot(df,"country1","country1")
11. Team bowler wicket kind
teamBowlingWicketKindAllOppnAllMatches(country1AllMatches,t1="country1",t2="All")
teamBowlingWicketKindAllOppnAllMatches(country1AllMatches,t1="country1",t2="country2")
12.
teamBowlingWicketRunsAllOppnAllMatches(country1AllMatches,t1="country1",t2="All",plot=TRUE)
teamBowlingWicketRunsAllOppnAllMatches(country1AllMatches,t1="country1",t2="country2",plot=TRUE)
D) Batsman functions
Get the batsman’s details for a batsman
setwd("../BattingBowlingDetails")
kohli <- getBatsmanDetails(team="India",name="Kohli",dir=".")
batsmanDF <- getBatsmanDetails(team="country1",name="batsmanName",dir=".")
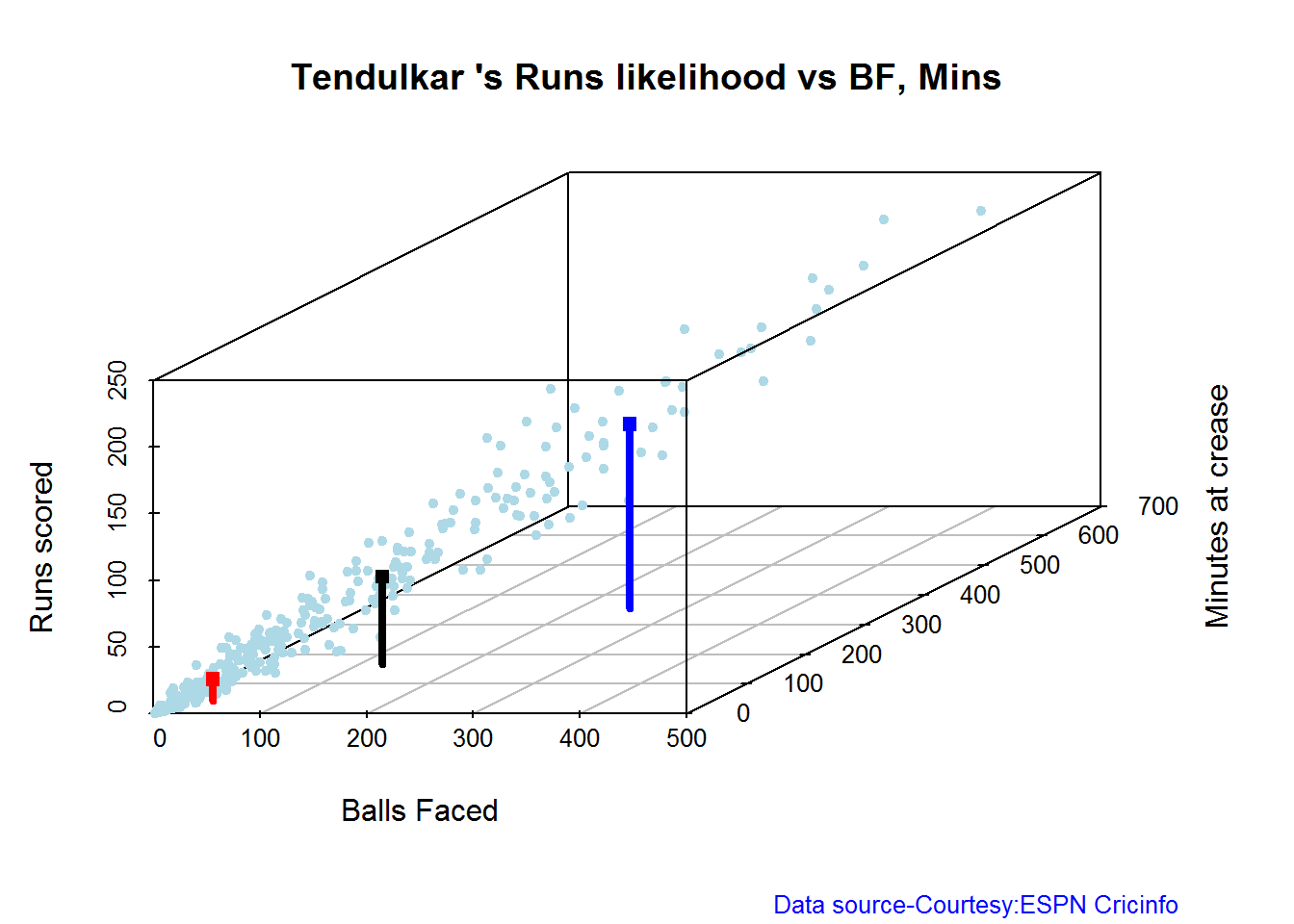
2. Runs vs deliveries
batsmanRunsVsDeliveries(batsmanDF,"batsmanName")
3. Batsman 4s & 6s
batsman46 <- select(batsmanDF,batsman,ballsPlayed,fours,sixes,runs)
p1 <- batsmanFoursSixes(batsman46,"batsmanName")
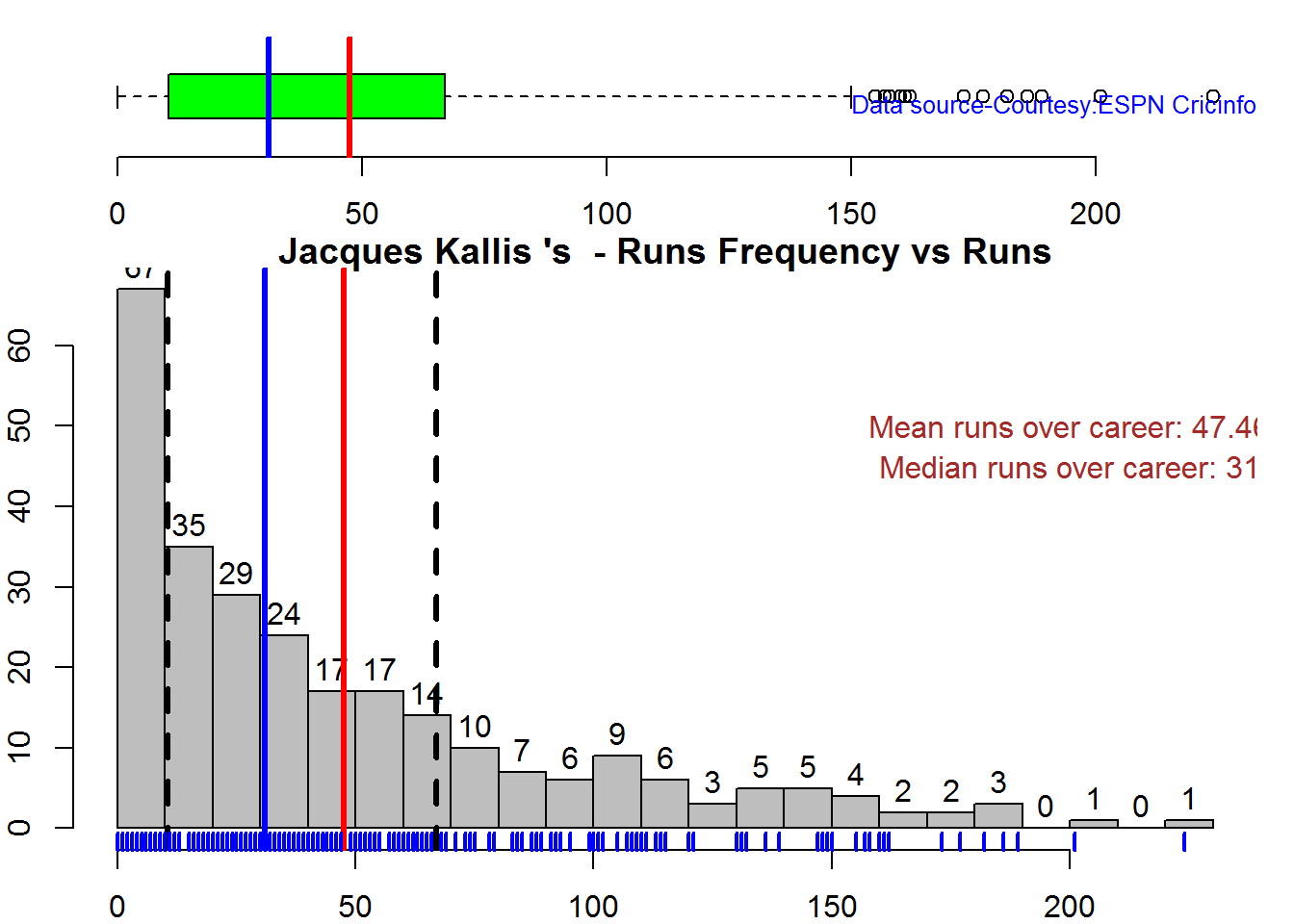
4. Batsman dismissals
batsmanDismissals(batsmanDF,"batsmanName")
5. Runs vs Strike rate
batsmanRunsVsStrikeRate(batsmanDF,"batsmanName")
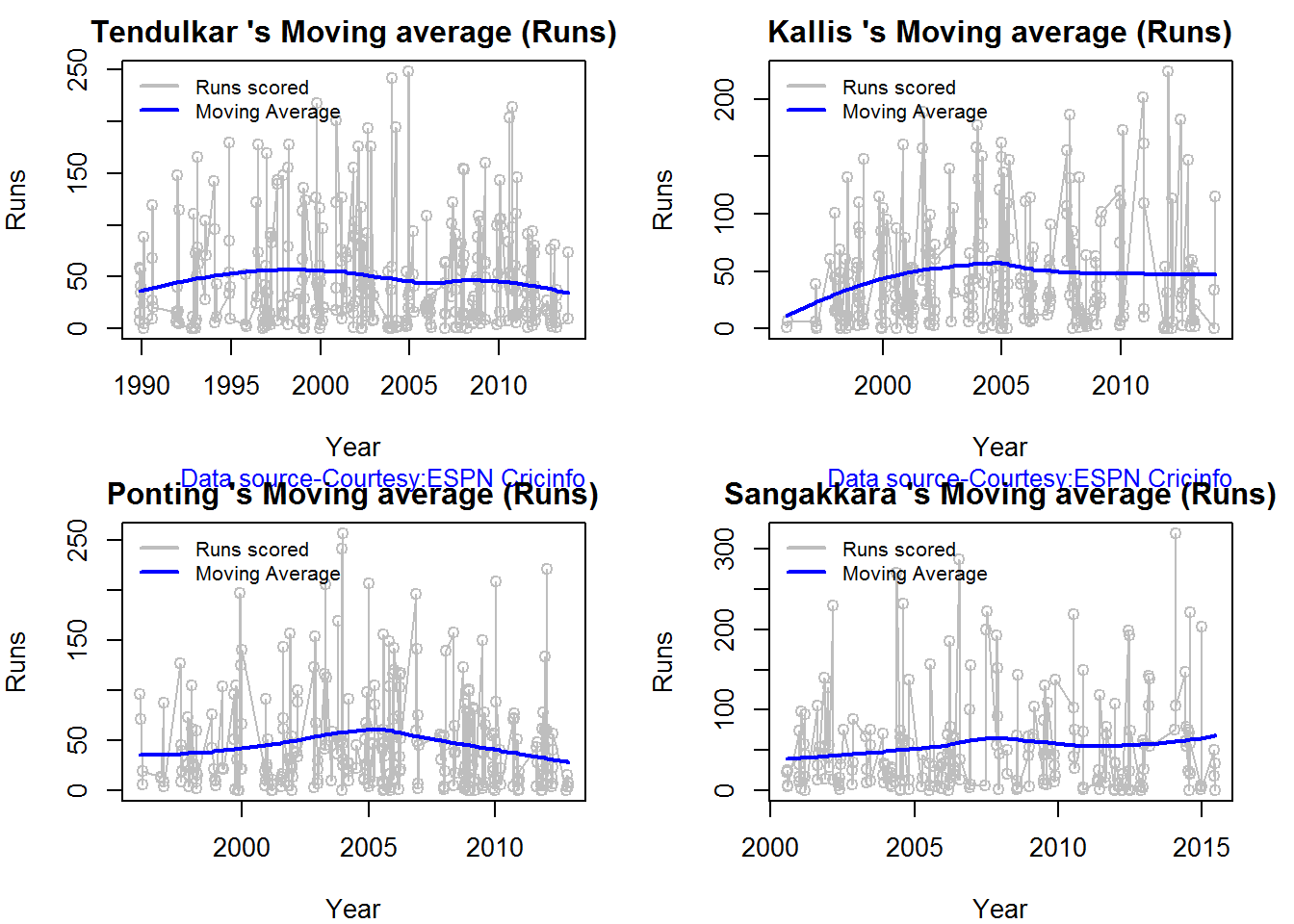
6. Batsman Moving Average
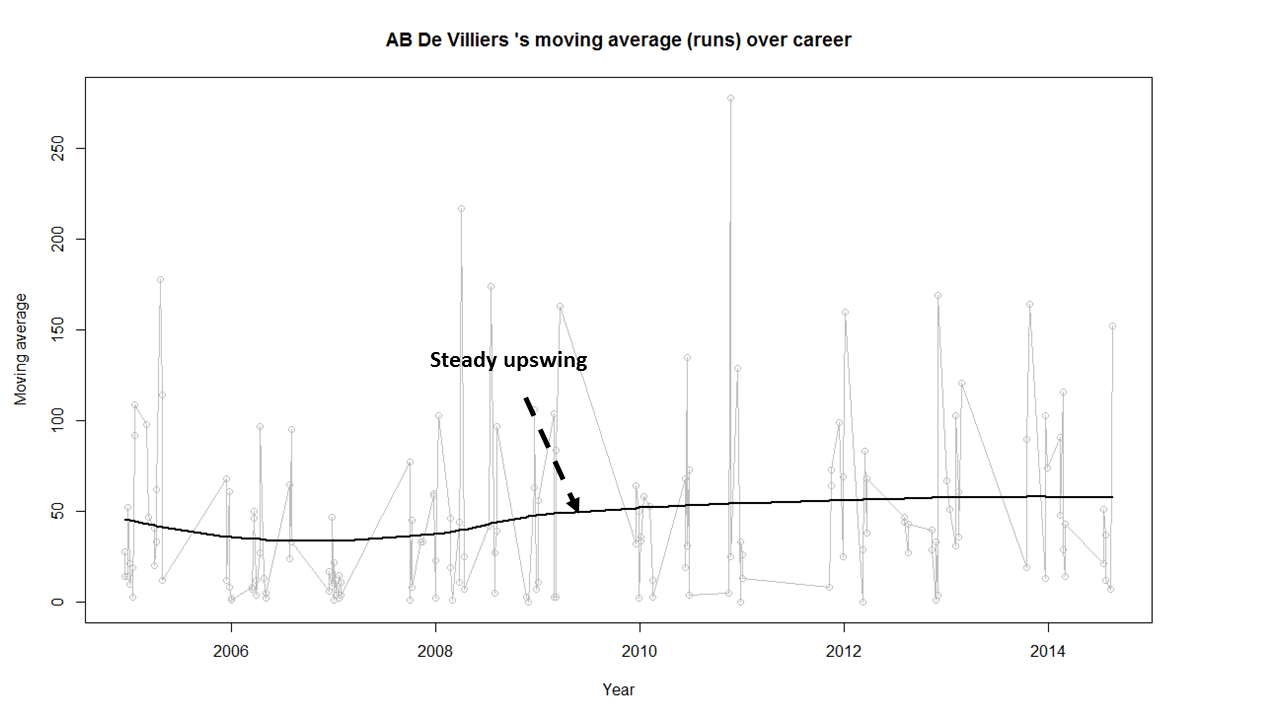
batsmanMovingAverage(batsmanDF,"batsmanName")
7. Batsman cumulative average
batsmanCumulativeAverageRuns(batsmanDF,"batsmanName")
8. Batsman cumulative strike rate
batsmanCumulativeStrikeRate(batsmanDF,"batsmanName")
9. Batsman runs against oppositions
batsmanRunsAgainstOpposition(batsmanDF,"batsmanName")
10. Batsman runs vs venue
batsmanRunsVenue(batsmanDF,"batsmanName")
11. Batsman runs predict
batsmanRunsPredict(batsmanDF,"batsmanName")
12. Bowler functions
For example to get Ravicahnder Ashwin’s bowling details
setwd("../BattingBowlingDetails")
ashwin <- getBowlerWicketDetails(team="India",name="Ashwin",dir=".")
bowlerDF <- getBatsmanDetails(team="country1",name="bowlerName",dir=".")
13. Bowler Mean Economy rate
bowlerMeanEconomyRate(bowlerDF,"bowlerName")
14. Bowler mean runs conceded
bowlerMeanRunsConceded(bowlerDF,"bowlerName")
15. Bowler Moving Average
bowlerMovingAverage(bowlerDF,"bowlerName")
16. Bowler cumulative average wickets
bowlerCumulativeAvgWickets(bowlerDF,"bowlerName")
17. Bowler cumulative Economy Rate (ER)
bowlerCumulativeAvgEconRate(bowlerDF,"bowlerName")
18. Bowler wicket plot
bowlerWicketPlot(bowlerDF,"bowlerName")
19. Bowler wicket against opposition
bowlerWicketsAgainstOpposition(bowlerDF,"bowlerName")
20. Bowler wicket at cricket grounds
bowlerWicketsVenue(bowlerDF,"bowlerName")
21. Predict number of deliveries to wickets
setwd("./T20Matches")
bowlerDF1 <- getDeliveryWickets(team="country1",dir=".",name="bowlerName",save=FALSE)
bowlerWktsPredict(bowlerDF1,"bowlerName")















































 Checkout my book ‘Deep Learning from first principles Second Edition- In vectorized Python, R and Octave’. My book is available on Amazon as
Checkout my book ‘Deep Learning from first principles Second Edition- In vectorized Python, R and Octave’. My book is available on Amazon as