In this post, I revisit the visualisation of IPL batsman and bowler similarities using Google’s Embedding Projector. I had previously done this using multivariate regression in my earlier post ‘Using embeddings, collaborative filtering with Deep Learning to analyse T20 players.’ However, I was not too satisfied with the result since I was not getting the required accuracy.
This post uses the win-loss status of IPL matches from 2014 onwards upto 2023 in Logistic Regression with Deep Learning. A 16-dimensional embedding layer is added for the batsman and the bowler for ball-by-ball data. Since I have used a reduced size data set (from 2014) I get a slightly reduced accuracy, but still I think this is a well-formulated problem.
A Deep Learning network performs gradient descent based using Adam optimisation to arrive at an accuracy of 0.8047. The weights of the learnt Deep Learning network in ‘layer 0’ is used for displaying the batsman and bowler similarities.
Similarity measures –Cosine similarity
A cosine similarity is a value that is bound by a constrained range of 0 and 1. The closer the value is to 0 means that the two vectors are orthogonal or perpendicular to each other. When the value is closer to one, it means the angle is smaller and the batsman and bowler are similar.
a) Data set
For the data set only IPL T20 matches from Jan 2014 upto the present (May 2023) was taken. A Deep Learning model using Logistic Regression with batsman and bowler embedding is used to minimise the error. An accuracy of 0.8047 is obtained. In my earlier post ‘GooglyPlusPlus: Win Probability using Deep Learning and player embeddings‘ I had used data from all T20 leagues (~1.2 million rows) and got an accuracy of 0.8647
b) Import the data
import pandas as pd
import numpy as np
from zipfile import ZipFile
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import regularizers
from pathlib import Path
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from zipfile import ZipFile
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import regularizers
df1=pd.read_csv('ipl2014_23.csv')
print("Shape of dataframe=",df1.shape)
train_dataset = df1.sample(frac=0.8,random_state=0)
test_dataset = df1.drop(train_dataset.index)
train_dataset1 = train_dataset[['batsmanIdx','bowlerIdx','ballNum','ballsRemaining','runs','runRate','numWickets','runsMomentum','perfIndex']]
test_dataset1 = test_dataset[['batsmanIdx','bowlerIdx','ballNum','ballsRemaining','runs','runRate','numWickets','runsMomentum','perfIndex']]
train_dataset1
train_labels = train_dataset.pop('isWinner')
test_labels = test_dataset.pop('isWinner')
train_dataset1
a=train_dataset1.describe()
stats=a.transpose
Shape of dataframe= (138896, 10)
batsmanIdx bowlerIdx ballNum ballsRemaining runs runRate numWickets runsMomentum perfIndex
count 111117.000000 111117.000000 111117.000000 111117.000000 111117.000000 111117.000000 111117.000000 111117.000000 111117.000000
mean 218.672939 169.204145 120.372067 60.749822 86.881701 1.636353 2.423167 0.296061 10.578927
std 118.405729 96.934754 69.991408 35.298794 51.643164 2.672564 2.085956 0.620872 4.436981
min 1.000000 1.000000 1.000000 1.000000 -5.000000 -5.000000 0.000000 0.057143 0.000000
25% 111.000000 89.000000 60.000000 30.000000 45.000000 1.160000 1.000000 0.106383 7.733333
50% 220.000000 170.000000 119.000000 60.000000 85.000000 1.375000 2.000000 0.142857 10.329545
75% 325.000000 249.000000 180.000000 91.000000 126.000000 1.640000 4.000000 0.240000 13.108696
max 411.000000 332.000000 262.000000 135.000000 258.000000 251.000000 10.000000 11.000000 66.000000
c) Create a Deep Learning ML model using batsman & bowler embeddings
import pandas as pd
import numpy as np
from keras.layers import Input, Embedding, Flatten, Dense
from keras.models import Model
from keras.layers import Input, Embedding, Flatten, Dense, Reshape, Concatenate, Dropout
from keras.models import Model
tf.random.set_seed(432)
# create input layers for each of the predictors
batsmanIdx_input = Input(shape=(1,), name='batsmanIdx')
bowlerIdx_input = Input(shape=(1,), name='bowlerIdx')
ballNum_input = Input(shape=(1,), name='ballNum')
ballsRemaining_input = Input(shape=(1,), name='ballsRemaining')
runs_input = Input(shape=(1,), name='runs')
runRate_input = Input(shape=(1,), name='runRate')
numWickets_input = Input(shape=(1,), name='numWickets')
runsMomentum_input = Input(shape=(1,), name='runsMomentum')
perfIndex_input = Input(shape=(1,), name='perfIndex')
# Set the embedding size
no_of_unique_batman=len(df1["batsmanIdx"].unique())
print(no_of_unique_batman)
no_of_unique_bowler=len(df1["bowlerIdx"].unique())
print(no_of_unique_bowler)
embedding_size_bat = no_of_unique_batman ** (1/4)
embedding_size_bwl = no_of_unique_bowler ** (1/4)
# create embedding layer for the categorical predictor
batsmanIdx_embedding = Embedding(input_dim=no_of_unique_batman+1, output_dim=16,input_length=1)(batsmanIdx_input)
batsmanIdx_flatten = Flatten()(batsmanIdx_embedding)
bowlerIdx_embedding = Embedding(input_dim=no_of_unique_bowler+1, output_dim=16,input_length=1)(bowlerIdx_input)
bowlerIdx_flatten = Flatten()(bowlerIdx_embedding)
# concatenate all the predictors
x = keras.layers.concatenate([batsmanIdx_flatten,bowlerIdx_flatten, ballNum_input, ballsRemaining_input, runs_input, runRate_input, numWickets_input, runsMomentum_input, perfIndex_input])
# add hidden layers
#x = Dense(64, activation='relu')(x)
#x = Dropout(0.1)(x)
x = Dense(32, activation='relu')(x)
x = Dropout(0.1)(x)
x = Dense(16, activation='relu')(x)
x = Dropout(0.1)(x)
x = Dense(8, activation='relu')(x)
x = Dropout(0.1)(x)
# add output layer
output = Dense(1, activation='sigmoid', name='output')(x)
print(output.shape)
# create model
model = Model(inputs=[batsmanIdx_input,bowlerIdx_input, ballNum_input, ballsRemaining_input, runs_input, runRate_input, numWickets_input, runsMomentum_input, perfIndex_input], outputs=output)
model.summary()
# compile model
optimizer=keras.optimizers.Adam(learning_rate=.01, beta_1=0.9, beta_2=0.999, epsilon=1e-07, amsgrad=True)
model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])
# train the model
history=model.fit([train_dataset1['batsmanIdx'],train_dataset1['bowlerIdx'],train_dataset1['ballNum'],train_dataset1['ballsRemaining'],train_dataset1['runs'],
train_dataset1['runRate'],train_dataset1['numWickets'],train_dataset1['runsMomentum'],train_dataset1['perfIndex']], train_labels, epochs=40, batch_size=1024,
validation_data = ([test_dataset1['batsmanIdx'],test_dataset1['bowlerIdx'],test_dataset1['ballNum'],test_dataset1['ballsRemaining'],test_dataset1['runs'],
test_dataset1['runRate'],test_dataset1['numWickets'],test_dataset1['runsMomentum'],test_dataset1['perfIndex']],test_labels), verbose=1)
plt.plot(history.history["loss"])
plt.plot(history.history["val_loss"])
plt.title("model loss")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.legend(["train", "test"], loc="upper left")
plt.show()
d) Project embeddings with Google’s Embedding projector
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
%load_ext tensorboard
import os
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorboard.plugins import projector
%pwd
# Set up a logs directory, so Tensorboard knows where to look for files.
log_dir='/logs/batsmen/'
if not os.path.exists(log_dir):
os.makedirs(log_dir)
df3=pd.read_csv('batsmen.csv')
batsmen = df3["batsman"].unique().tolist()
batsmen
# Create dictionary of batsman to index
batsmen2index = {x: i for i, x in enumerate(batsmen)}
batsmen2index
# Create dictionary of index to batsman
index2batsmen = {i: x for i, x in enumerate(batsmen)}
index2batsmen
# Save Labels separately on a line-by-line manner.
with open(os.path.join(log_dir, 'metadata.tsv'), "w") as f:
for batsmanIdx in range(1, 411):
# Get the name of batsman associated at the current index
batsman = index2batsmen.get([batsmanIdx][0])
f.write("{}\n".format(batsman))
# Save the weights we want to analyze as a variable. Note that the first
# value represents any unknown word, which is not in the metadata, here
# we will remove this value.
weights = tf.Variable(model.get_weights()[0][1:])
print(weights)
print(type(weights))
print(len(model.get_weights()[0]))
# Create a checkpoint from embedding, the filename and key are the
# name of the tensor.
checkpoint = tf.train.Checkpoint(embedding=weights)
checkpoint.save(os.path.join(log_dir, "embedding.ckpt"))
# Set up config.
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
# The name of the tensor will be suffixed by `/.ATTRIBUTES/VARIABLE_VALUE`.
embedding.tensor_name = "embedding/.ATTRIBUTES/VARIABLE_VALUE"
embedding.metadata_path = 'metadata.tsv'
projector.visualize_embeddings(log_dir, config)
# Now run tensorboard against on log data we just saved.
%reload_ext tensorboard
%tensorboard --logdir /logs/batsmen/
e) Here are similarity measures for some batsmen
I) Principal Component Analysis (PCA) : In the charts and video animation below, the 16-dimensional embedding vector of batsmen and bowler is reduced to 3 principal components in a lower dimension for visualisation and analysis as shown below
a) Yashasvi Jaiswal (similar players
i) PCA – Chart
Yashasvi Jaiswal style of attack is similar to Faf Du Plessis, Quentim De Kock, Bravo etc. In the below chart the ange between Jaiswal and SP Narine is 0.109, and Faf du Plessis is 0.253. These represent the angle in radians. The smaller the angle the more similar the performance style of the players and cos 0=1 or the players are similar.
ii) PCA animation video for Yashasvi Jaiswal
b) Suryakumar Yadav (SKY)
i) PCA -Chart
The closest neighbours for SKY is RV Uthappa, Rahul Tripathi, Q de Kock, Samson, Rashid Khan
ii) PCA – Animation video for Suryakumar Yadav
c) M S Dhoni
i) PCA – Chart
Dhoni rubs shoulders with Bravo, AB De Villiers, Shane Watson, Chris Gayle, Rayadu, Gautam Gambhir
ii) PCA – Animation video for M S Dhoni
f) PCA Analysis for bowlers
a) Jasprit Bumrah
i) PCA – Chart
Bumrah bowling performance is similar to Josh Hazzlewood, Chameera, Kuldeep Yadav, Nortje, Adam Zampa etc.
ii) PCA Animation video for Jasprit Bumrah
b) Yuzhvendra Chahal
i) PCA – Chart
Chahal’s performance has a strong similarity to Malinga, Zaheer Khan, Imran Tahir, R Sheperd, Adil Rashid
ii) PCA Animation video for YS Chahal
f) Other similarity measures ( t-SNE & UMAP)
There are 2 other similarity visualisations in Google’s Embedding Projector namely
i) t-SNE (t-distributed Stochastic Neighbor Embedding) – t-SNE tries to find a faithful representation of the data distribution in higher dimensional space to a lower dimensional space. t-SNE differs from PCA by preserving only or local similarities whereas PCA is maintains preserving large pairwise distances.
a) t-SNE Animationvideo
ii) UMAP – Uniform Manifold Approximation and Projection
UMAP learns the manifold structure of the high dimensional data and finds a low dimensional embedding that preserves the essential topological structure of that manifold.
ii) UMAP – Animationvideo
The Embedding projector thus helps in identifying players based on how they perform against bowlers, and probably picks up a lot of features like strike rate and performance in different stages of the game.
“The unexamined life is not worth living.” – Socrates
“There is no easy way from the earth to the stars.” – Seneca
“If you want to go fast, go alone. If you want to go far, go together.” – African Proverb
1. Introduction
In this post, I put my R package cricketr to analyze the Indian and Australia World Test Championship (WTC) final squad ahead of the World Test Championship 2023.My R package cricketr had its birth on Jul 4, 2015. Cricketr uses data from Cricinfo.
According to me, Ishan Kishan has more experience than KS Bharat, though Rishabh Pant would have been the ideal wicket keeper/left-handed batsman. I think Shardul Thakur would be handful in the English conditions. For a spinner it either Ashwin or Jadeja. Maybe the balance shifts in favor of Jadeja
Australian squad
Pat Cummins (capt), Alex Carey (wk), Cameron Green, Josh Hazlewood, Usman Khawaja, Marnus Labuschagne, Nathan Lyon, Todd Murphy, Steven Smith (vice-capt), Mitchell Starc, David Warner.
Not sure if Scott Boland would fill in, instead of Todd Murphy 1
Let me give you a lay-of-the-land (post) below
The post below is organized into the following parts
Analysis of Indian WTC batsmen from Jan 2016 – May 2023
Analysis of Indian WTC batsmen against Australia from Jan 2016 -May 2023
Analysis of Australian WTC batsmen from Jan 2016 – May 2023
Analysis of Australian WTC batsmen against India from Jan 2016 -May 2023
Analysis of Indian WTC bowlers from Jan 2016 – May 2023
Analysis of Indian WTC bowlers against Australia from Jan 2016 -May 2023
Analysis of Australian WTC bowlers from Jan 2016 – May 2023
Analysis of Australian WTC bowlers gainst India from Jan 2016 -May 2023
Team analysis of India and Australia
All the above analysis use data from ESPN Statsguru and use my R pakage cricketr
The data for the different players have been obtained using calls such as the ones below.
# Get Shubman Gill's batting data
#shubman <-getPlayerData(1070173,dir=".",file="shubman.csv",type="batting",homeOrAway=c(1,2), result=c(1,2,4))
#shubmansp <- getPlayerDataSp(1070173,tdir=".",tfile="shubmansp.csv",ttype="batting")
#Get Shubman Gill's data from Jan 2016 - May 2023
#df <-getPlayerDataHA(1070173,tfile="shubman1.csv",type="batting", matchType="Test")
#df1=getPlayerDataOppnHA(infile="shubman1.csv",outfile="shubmanTestAus.csv",startDate="2016-01-01",endDate="2023-05-01")
#Get Shubman Gills data from Jan 2016 - May 2023, against Australia
#df <-getPlayerDataHA(1070173,tfile="shubman1.csv",type="batting", matchType="Test")
#df1=getPlayerDataOppnHA(infile="shubman1.csv",outfile="shubmanTestAus.csv",opposition="Australia",startDate="2016-01-01",endDate="2023-05-01")
Note: To get data for bowlers we need to use the corresponding profile no and use type =‘bowling’. Details in my posts below
To do similar analysis please go through the following posts
Note 1: I will not be analysing each and every chart as the charts are quite self-explanatory
Note 2: I have had to tile charts together otherwise this will become a very, very long post. You are free to use my R package cricketr and check out for yourself ##3. Analysis of India WTC batsmen from Jan 2016 – May 2023
Findings
Kohli has the best average of 48+. India has won when Rohit and Rahane played well
Kohli’s tops the list in cumulative average runs, followed by Pujara and Rohit is 3rd. Gill is on the upswing.
Against Australia Pujara has the best cumulative average runs record followed by Rahane, with Gill in hot pursuit. In the strike rate department Gill tops followed by Rohit and Rahane
Since 2016 Smith, Labuschagne has an average of 53+ since 2016!! Warner & Khwaja are at ~46
Australia has won matches when Smith, Warner and Khwaja have played well.
Labuschagne, Smith and C Green have good records against India. Indian bowlers will need to contain them
Ashwin has the highest wickets followed by Jadeja against all teams. Ashwin’s performance has dropped over the years, while Siraj has been becoming better
Jadeja has the best economy rate followed by Ashwin
Against Australia specifically Jadeja has the best record followed by Ashwin. Jadeja has the best economy against Australia, followed by Siraj, then Ashwin
Cummins, Starc and Lyons are the best performers for Australia. Hazzlewood, Cummins have the best economy against all opposition
Against India Lyon, Cummins and Hazzlewood have performed well
Hazzlewood, Lyon have a good economy rate against India
Against Australia India has won 17 times, lost 60 and drawn 22 in Australia. At home India won 42, tied 2, lost 28 and drawn 24
At the Oval where the World Test Championship is going to be held India has won 4, lost 10 and drawn 10.
Note 3: You can also read this post at Rpubs at ind-aus-WTC!! The formatting will be nicer!
Note 4: You can download this post as PDF to read at your leisure ind-aus-WTC.pdf
2. Install the cricketr package
if (!require("cricketr")){
install.packages("cricketr",lib = "c:/test")
}
library(cricketr)
3a. Basic analysis
The analyses below include – Runs frequency plot – Mean strike rate – Run Ranges
Kohli’s strike rate increases with increasing runs, while Gill’s seems to drop. So it is with Pujara & Rahane
This plot shows a combined boxplot of the Runs ranges and a histog2ram of the Runs Frequency Kohli’s average is 48, while Rohit,Pujara is 40 with Rahane and Gill around 33.
batsmanPerfBoxHist("kohliTest.csv","Kohli")
batsmanPerfBoxHist("rohitTest.csv","Rohit")
batsmanPerfBoxHist("shubmanTest.csv","S Gill")
batsmanPerfBoxHist("rahaneTest.csv","Rahane")
batsmanPerfBoxHist("pujaraTest.csv","Pujara")
3d. Contribution to won and lost matches
For the functions below you will have to use the getPlayerDataSp() function. When Rohit Sharma and Pujara have played well India have tended to win more often
## Summary of Kohli 's runs scoring likelihood
## **************************************************
##
## There is a 52.91 % likelihood that Kohli will make 12 Runs in 26 balls over 35 Minutes
## There is a 30.81 % likelihood that Kohli will make 52 Runs in 100 balls over 139 Minutes
## There is a 16.28 % likelihood that Kohli will make 142 Runs in 237 balls over 335 Minutes
batsmanRunsLikelihood("rohit.csv","Rohit")
## Summary of Rohit 's runs scoring likelihood
## **************************************************
##
## There is a 43.24 % likelihood that Rohit will make 10 Runs in 21 balls over 32 Minutes
## There is a 45.95 % likelihood that Rohit will make 46 Runs in 85 balls over 124 Minutes
## There is a 10.81 % likelihood that Rohit will make 110 Runs in 199 balls over 282 Minutes
batsmanRunsLikelihood("rahane.csv","Rahane")
## Summary of Rahane 's runs scoring likelihood
## **************************************************
##
## There is a 7.75 % likelihood that Rahane will make 124 Runs in 224 balls over 318 Minutes
## There is a 62.02 % likelihood that Rahane will make 12 Runs in 26 balls over 37 Minutes
## There is a 30.23 % likelihood that Rahane will make 55 Runs in 113 balls over 162 Minutes
batsmanRunsLikelihood("pujara.csv","Pujara")
## Summary of Pujara 's runs scoring likelihood
## **************************************************
##
## There is a 60.49 % likelihood that Pujara will make 15 Runs in 38 balls over 55 Minutes
## There is a 31.48 % likelihood that Pujara will make 62 Runs in 142 balls over 204 Minutes
## There is a 8.02 % likelihood that Pujara will make 153 Runs in 319 balls over 445 Minutes
3h1. Moving average of batsman
Kohli’s moving average in tests seem to havw dropped after a peak in 2017, 2018. So it is with Rahane
Here are plots that forecast how the batsman will perform in future. In this case 90% of the career runs trend is uses as the training set. the remaining 10% is the test set.
A Holt-Winters forecating model is used to forecast future performance based on the 90% training set. The forecated runs trend is plotted. The test set is also plotted to see how close the forecast and the actual matches
Take a look at the runs forecasted for the batsman below.
The below computation uses Null Hypothesis testing and p-value to determine if the batsman is in-form or out-of-form. For this 90% of the career runs is chosen as the population and the mean computed. The last 10% is chosen to be the sample set and the sample Mean and the sample Standard Deviation are caculated.
The Null Hypothesis (H0) assumes that the batsman continues to stay in-form where the sample mean is within 95% confidence interval of population mean The Alternative (Ha) assumes that the batsman is out of form the sample mean is beyond the 95% confidence interval of the population mean.
A significance value of 0.05 is chosen and p-value us computed If p-value >= .05 – Batsman In-Form If p-value < 0.05 – Batsman Out-of-Form
Note Ideally the p-value should be done for a population that follows the Normal Distribution. But the runs population is usually left skewed. So some correction may be needed. I will revisit this later
This is done for the Top 4 batsman
checkBatsmanInForm("kohli.csv","Kohli")
## [1] "**************************** Form status of Kohli ****************************\n\n Population size: 154 Mean of population: 47.03 \n Sample size: 18 Mean of sample: 32.22 SD of sample: 42.45 \n\n Null hypothesis H0 : Kohli 's sample average is within 95% confidence interval of population average\n Alternative hypothesis Ha : Kohli 's sample average is below the 95% confidence interval of population average\n\n Kohli 's Form Status: In-Form because the p value: 0.078058 is greater than alpha= 0.05 \n *******************************************************************************************\n\n"
checkBatsmanInForm("rohit.csv","Rohit")
## [1] "**************************** Form status of Rohit ****************************\n\n Population size: 66 Mean of population: 37.03 \n Sample size: 8 Mean of sample: 37.88 SD of sample: 35.38 \n\n Null hypothesis H0 : Rohit 's sample average is within 95% confidence interval of population average\n Alternative hypothesis Ha : Rohit 's sample average is below the 95% confidence interval of population average\n\n Rohit 's Form Status: In-Form because the p value: 0.526254 is greater than alpha= 0.05 \n *******************************************************************************************\n\n"
checkBatsmanInForm("rahane.csv","Rahane")
## [1] "**************************** Form status of Rahane ****************************\n\n Population size: 116 Mean of population: 34.78 \n Sample size: 13 Mean of sample: 21.38 SD of sample: 21.96 \n\n Null hypothesis H0 : Rahane 's sample average is within 95% confidence interval of population average\n Alternative hypothesis Ha : Rahane 's sample average is below the 95% confidence interval of population average\n\n Rahane 's Form Status: Out-of-Form because the p value: 0.023244 is less than alpha= 0.05 \n *******************************************************************************************\n\n"
checkBatsmanInForm("pujara.csv","Pujara")
## [1] "**************************** Form status of Pujara ****************************\n\n Population size: 145 Mean of population: 41.93 \n Sample size: 17 Mean of sample: 33.24 SD of sample: 31.74 \n\n Null hypothesis H0 : Pujara 's sample average is within 95% confidence interval of population average\n Alternative hypothesis Ha : Pujara 's sample average is below the 95% confidence interval of population average\n\n Pujara 's Form Status: In-Form because the p value: 0.137319 is greater than alpha= 0.05 \n *******************************************************************************************\n\n"
checkBatsmanInForm("shubman.csv","S Gill")
## [1] "**************************** Form status of S Gill ****************************\n\n Population size: 23 Mean of population: 30.43 \n Sample size: 3 Mean of sample: 51.33 SD of sample: 66.88 \n\n Null hypothesis H0 : S Gill 's sample average is within 95% confidence interval of population average\n Alternative hypothesis Ha : S Gill 's sample average is below the 95% confidence interval of population average\n\n S Gill 's Form Status: In-Form because the p value: 0.687033 is greater than alpha= 0.05 \n *******************************************************************************************\n\n"
3q. Predicting Runs given Balls Faced and Minutes at Crease
A multi-variate regression plane is fitted between Runs and Balls faced +Minutes at crease.
4. Analysis of India WTC batsmen from Jan 2016 – May 2023 against Australia
4a. Relative cumulative average
Against Australia specifically between 2016 – 2023, Pujara has the best record followed by Rahane, with Gill in hot pursuit. Kohli and Rohit trail behind
For the 2 functions below you will have to use the getPlayerDataSp() function. Australia has won matches when Smith, Warner and Khwaja have played well.
## Summary of S Smith 's runs scoring likelihood
## **************************************************
##
## There is a 58.76 % likelihood that S Smith will make 21 Runs in 38 balls over 56 Minutes
## There is a 24.74 % likelihood that S Smith will make 70 Runs in 148 balls over 210 Minutes
## There is a 16.49 % likelihood that S Smith will make 148 Runs in 268 balls over 398 Minutes
batsmanRunsLikelihood("warnerTest.csv","Warner")
## Summary of Warner 's runs scoring likelihood
## **************************************************
##
## There is a 7.22 % likelihood that Warner will make 155 Runs in 253 balls over 372 Minutes
## There is a 62.89 % likelihood that Warner will make 14 Runs in 21 balls over 32 Minutes
## There is a 29.9 % likelihood that Warner will make 65 Runs in 94 balls over 135 Minutes
## Summary of M Labuschagne 's runs scoring likelihood
## **************************************************
##
## There is a 32.76 % likelihood that M Labuschagne will make 74 Runs in 144 balls over 206 Minutes
## There is a 55.17 % likelihood that M Labuschagne will make 22 Runs in 37 balls over 54 Minutes
## There is a 12.07 % likelihood that M Labuschagne will make 168 Runs in 297 balls over 420 Minutes
batsmanRunsLikelihood("khwajaTest.csv","Khwaja")
## Summary of Khwaja 's runs scoring likelihood
## **************************************************
##
## There is a 64.94 % likelihood that Khwaja will make 14 Runs in 29 balls over 42 Minutes
## There is a 27.27 % likelihood that Khwaja will make 79 Runs in 148 balls over 210 Minutes
## There is a 7.79 % likelihood that Khwaja will make 165 Runs in 351 balls over 515 Minutes
5i. Moving average of batsman
Smith and Warner’s moving average has been on a downward trend lately. Khwaja is playing well
Here are plots that forecast how the batsman will perform in future. In this case 90% of the career runs trend is uses as the training set. the remaining 10% is the test set.
A Holt-Winters forecating model is used to forecast future performance based on the 90% training set. The forecated runs trend is plotted. The test set is also plotted to see how close the forecast and the actual matches
Take a look at the runs forecasted for the batsman below.
The below computation uses Null Hypothesis testing and p-value to determine if the batsman is in-form or out-of-form. For this 90% of the career runs is chosen as the population and the mean computed. The last 10% is chosen to be the sample set and the sample Mean and the sample Standard Deviation are caculated.
The Null Hypothesis (H0) assumes that the batsman continues to stay in-form where the sample mean is within 95% confidence interval of population mean The Alternative (Ha) assumes that the batsman is out of form the sample mean is beyond the 95% confidence interval of the population mean.
A significance value of 0.05 is chosen and p-value us computed If p-value >= .05 – Batsman In-Form If p-value < 0.05 – Batsman Out-of-Form
Note Ideally the p-value should be done for a population that follows the Normal Distribution. But the runs population is usually left skewed. So some correction may be needed. I will revisit this later
This is done for the Top 4 batsman
checkBatsmanInForm("stevesmith.csv","S Smith")
## [1] "**************************** Form status of S Smith ****************************\n\n Population size: 144 Mean of population: 53.76 \n Sample size: 17 Mean of sample: 45.65 SD of sample: 56.4 \n\n Null hypothesis H0 : S Smith 's sample average is within 95% confidence interval of population average\n Alternative hypothesis Ha : S Smith 's sample average is below the 95% confidence interval of population average\n\n S Smith 's Form Status: In-Form because the p value: 0.280533 is greater than alpha= 0.05 \n *******************************************************************************************\n\n"
checkBatsmanInForm("warner.csv","Warner")
## [1] "**************************** Form status of Warner ****************************\n\n Population size: 164 Mean of population: 45.2 \n Sample size: 19 Mean of sample: 26.63 SD of sample: 44.62 \n\n Null hypothesis H0 : Warner 's sample average is within 95% confidence interval of population average\n Alternative hypothesis Ha : Warner 's sample average is below the 95% confidence interval of population average\n\n Warner 's Form Status: Out-of-Form because the p value: 0.042744 is less than alpha= 0.05 \n *******************************************************************************************\n\n"
## [1] "**************************** Form status of M Labuschagne ****************************\n\n Population size: 52 Mean of population: 59.56 \n Sample size: 6 Mean of sample: 29.67 SD of sample: 19.96 \n\n Null hypothesis H0 : M Labuschagne 's sample average is within 95% confidence interval of population average\n Alternative hypothesis Ha : M Labuschagne 's sample average is below the 95% confidence interval of population average\n\n M Labuschagne 's Form Status: Out-of-Form because the p value: 0.005239 is less than alpha= 0.05 \n *******************************************************************************************\n\n"
checkBatsmanInForm("khwaja.csv","Khwaja")
## [1] "**************************** Form status of Khwaja ****************************\n\n Population size: 89 Mean of population: 41.62 \n Sample size: 10 Mean of sample: 53.1 SD of sample: 76.34 \n\n Null hypothesis H0 : Khwaja 's sample average is within 95% confidence interval of population average\n Alternative hypothesis Ha : Khwaja 's sample average is below the 95% confidence interval of population average\n\n Khwaja 's Form Status: In-Form because the p value: 0.677691 is greater than alpha= 0.05 \n *******************************************************************************************\n\n"
5r. Predicting Runs given Balls Faced and Minutes at Crease
A multi-variate regression plane is fitted between Runs and Balls faced +Minutes at crease.
Here are plots that forecast how the bowler will perform in future. In this case 90% of the career wickets trend is used as the training set. the remaining 10% is the test set.
A Holt-Winters forecasting model is used to forecast future performance based on the 90% training set. The forecasted wickets trend is plotted. The test set is also plotted to see how close the forecast and the actual matches
The below computation uses Null Hypothesis testing and p-value to determine if the bowler is in-form or out-of-form. For this 90% of the career wickets is chosen as the population and the mean computed. The last 10% is chosen to be the sample set and the sample Mean and the sample Standard Deviation are caculated.
The Null Hypothesis (H0) assumes that the bowler continues to stay in-form where the sample mean is within 95% confidence interval of population mean The Alternative (Ha) assumes that the bowler is out of form the sample mean is beyond the 95% confidence interval of the population mean.
A significance value of 0.05 is chosen and p-value us computed If p-value >= .05 – Batsman In-Form If p-value < 0.05 – Batsman Out-of-Form
Note Ideally the p-value should be done for a population that follows the Normal Distribution. But the runs population is usually left skewed. So some correction may be needed. I will revisit this later
Note: The check for the form status of the bowlers indicate
checkBowlerInForm("shami.csv","Shami")
## [1] "**************************** Form status of Shami ****************************\n\n Population size: 106 Mean of population: 1.93 \n Sample size: 12 Mean of sample: 1.33 SD of sample: 1.23 \n\n Null hypothesis H0 : Shami 's sample average is within 95% confidence interval \n of population average\n Alternative hypothesis Ha : Shami 's sample average is below the 95% confidence\n interval of population average\n\n Shami 's Form Status: In-Form because the p value: 0.058427 is greater than alpha= 0.05 \n *******************************************************************************************\n\n"
checkBowlerInForm("siraj.csv","Siraj")
## [1] "**************************** Form status of Siraj ****************************\n\n Population size: 29 Mean of population: 1.59 \n Sample size: 4 Mean of sample: 0.25 SD of sample: 0.5 \n\n Null hypothesis H0 : Siraj 's sample average is within 95% confidence interval \n of population average\n Alternative hypothesis Ha : Siraj 's sample average is below the 95% confidence\n interval of population average\n\n Siraj 's Form Status: Out-of-Form because the p value: 0.002923 is less than alpha= 0.05 \n *******************************************************************************************\n\n"
checkBowlerInForm("ashwin.csv","Ashwin")
## [1] "**************************** Form status of Ashwin ****************************\n\n Population size: 154 Mean of population: 2.77 \n Sample size: 18 Mean of sample: 2.44 SD of sample: 1.76 \n\n Null hypothesis H0 : Ashwin 's sample average is within 95% confidence interval \n of population average\n Alternative hypothesis Ha : Ashwin 's sample average is below the 95% confidence\n interval of population average\n\n Ashwin 's Form Status: In-Form because the p value: 0.218345 is greater than alpha= 0.05 \n *******************************************************************************************\n\n"
checkBowlerInForm("jadeja.csv","Jadeja")
## [1] "**************************** Form status of Jadeja ****************************\n\n Population size: 108 Mean of population: 2.22 \n Sample size: 12 Mean of sample: 1.92 SD of sample: 2.35 \n\n Null hypothesis H0 : Jadeja 's sample average is within 95% confidence interval \n of population average\n Alternative hypothesis Ha : Jadeja 's sample average is below the 95% confidence\n interval of population average\n\n Jadeja 's Form Status: In-Form because the p value: 0.333095 is greater than alpha= 0.05 \n *******************************************************************************************\n\n"
checkBowlerInForm("shardul.csv","Shardul")
## [1] "**************************** Form status of Shardul ****************************\n\n Population size: 13 Mean of population: 2 \n Sample size: 2 Mean of sample: 0.5 SD of sample: 0.71 \n\n Null hypothesis H0 : Shardul 's sample average is within 95% confidence interval \n of population average\n Alternative hypothesis Ha : Shardul 's sample average is below the 95% confidence\n interval of population average\n\n Shardul 's Form Status: Out-of-Form because the p value: 0.04807 is less than alpha= 0.05 \n *******************************************************************************************\n\n"
8. Analysis of India WTC bowlers from Jan 2016 – May 2023 against Australia
8a Relative cumulative average wickets of bowlers in career
Against Australia specifically Jadeja has the best record followed by Ashwin
Here are plots that forecast how the bowler will perform in future. In this case 90% of the career wickets trend is used as the training set. the remaining 10% is the test set.
A Holt-Winters forecasting model is used to forecast future performance based on the 90% training set. The forecated wickets trend is plotted. The test set is also plotted to see how close the forecast and the actual matches
The below computation uses Null Hypothesis testing and p-value to determine if the bowler is in-form or out-of-form. For this 90% of the career wickets is chosen as the population and the mean computed. The last 10% is chosen to be the sample set and the sample Mean and the sample Standard Deviation are calculated.
The Null Hypothesis (H0) assumes that the bowler continues to stay in-form where the sample mean is within 95% confidence interval of population mean The Alternative (Ha) assumes that the bowler is out of form the sample mean is beyond the 95% confidence interval of the population mean.
A significance value of 0.05 is chosen and p-value us computed If p-value >= .05 – Batsman In-Form If p-value < 0.05 – Batsman Out-of-Form
Note Ideally the p-value should be done for a population that follows the Normal Distribution. But the runs population is usually left skewed. So some correction may be needed. I will revisit this later
Note: The check for the form status of the bowlers indicate
checkBowlerInForm("cummins.csv","Cummins")
## [1] "**************************** Form status of Cummins ****************************\n\n Population size: 81 Mean of population: 2.46 \n Sample size: 9 Mean of sample: 2 SD of sample: 1.5 \n\n Null hypothesis H0 : Cummins 's sample average is within 95% confidence interval \n of population average\n Alternative hypothesis Ha : Cummins 's sample average is below the 95% confidence\n interval of population average\n\n Cummins 's Form Status: In-Form because the p value: 0.190785 is greater than alpha= 0.05 \n *******************************************************************************************\n\n"
checkBowlerInForm("starc.csv","Starc")
## [1] "**************************** Form status of Starc ****************************\n\n Population size: 126 Mean of population: 2.18 \n Sample size: 15 Mean of sample: 1.67 SD of sample: 1.18 \n\n Null hypothesis H0 : Starc 's sample average is within 95% confidence interval \n of population average\n Alternative hypothesis Ha : Starc 's sample average is below the 95% confidence\n interval of population average\n\n Starc 's Form Status: In-Form because the p value: 0.057433 is greater than alpha= 0.05 \n *******************************************************************************************\n\n"
checkBowlerInForm("hazzlewood.csv","Hazzlewood")
## [1] "**************************** Form status of Hazzlewood ****************************\n\n Population size: 99 Mean of population: 2.04 \n Sample size: 12 Mean of sample: 1.67 SD of sample: 1.5 \n\n Null hypothesis H0 : Hazzlewood 's sample average is within 95% confidence interval \n of population average\n Alternative hypothesis Ha : Hazzlewood 's sample average is below the 95% confidence\n interval of population average\n\n Hazzlewood 's Form Status: In-Form because the p value: 0.204787 is greater than alpha= 0.05 \n *******************************************************************************************\n\n"
checkBowlerInForm("lyon.csv","N Lyon")
## [1] "**************************** Form status of N Lyon ****************************\n\n Population size: 193 Mean of population: 2.08 \n Sample size: 22 Mean of sample: 2.95 SD of sample: 1.96 \n\n Null hypothesis H0 : N Lyon 's sample average is within 95% confidence interval \n of population average\n Alternative hypothesis Ha : N Lyon 's sample average is below the 95% confidence\n interval of population average\n\n N Lyon 's Form Status: In-Form because the p value: 0.975407 is greater than alpha= 0.05 \n *******************************************************************************************\n\n"
9. Analysis of Australia WTC bowlers from Jan 2016 – May 2023 against India
9a Relative cumulative average wickets of bowlers in career
Against India Lyon, Cummins and Hazzlewood have performed well
#The data for India & Australia teams were obtained with the following calls
#indiaTest <-getTeamDataHomeAway(dir=".",teamView="bat",matchType="Test",file="indiaTest.csv",save=TRUE,teamName="India")
#australiaTest <- getTeamDataHomeAway(matchType="Test",file="australiaTest.csv",save=TRUE,teamName="Australia")
10a. Win-loss of India against all oppositions in Test cricket
Against Australia India has won 17 times, lost 60 and drawn 22 in Australia. At home India won 42, tied 2, lost 28 and drawn 24
The above analysis performs various analysis of India and Australia in home and away matches. While we know the performance of the player at India or Australia, we cannot judge how the match will progress in the neutral, swinging conditions of the Oval. Let us hope for a good match!
Feel free to try out your own analysis with cricketr. Have fun with cricketr!!
It is carnival time again as IPL 2023 is underway!! The new GooglyPlusPlus now includes AI/ML models for computing ball-by-ball Win Probability of matches and each individual player’s Win Probability Contribution (WPC). GooglyPlusPlus uses 2 ML models
Deep Learning (Tensorflow) – accuracy : 0.8584
Logistic Regression (glmnet-tidymodels) : 0.728
Besides, as before, GooglyPlusPlus will also include the usual near real-time analytics with the Shiny app being automatically updated with the previous day’s match data.
Note: The Win Probability Computation can also be done on a live feed of streaming data. Since, I don’t have access to live feeds, the app will show how Win Probability changed during the course of completed matches. For more details on Win Probability and Win Probability Contribution see my posts
GooglyPlusPlus has been also updated with all the latest T20 league’s match data. It includes data from BBL 2022, NTB 2022, CPL 2022, PSL 2023, ICC T20 2022 and now IPL 2023.
GooglyPlusPlus has the following functionality
Batsman tab: For detailed analysis of batsmen
Bowler tab: For detailed analysis of bowlers
Match tab: Analysis of individual matches, plot of Runs vs SR, Wickets vs ER in power play, middle and death overs, Win Probability Analysis of teams and Win Probability Contribution of players
Head-to-head tab: Detailed analysis of team-vs-team batting/bowling scorecard, batting, bowling performances, performances in power play, middle and death overs
Team performance tab: Analysis of team-vs-all other teams with batting /bowling scorecard, batting, bowling performances, performances in power play, middle and death overs
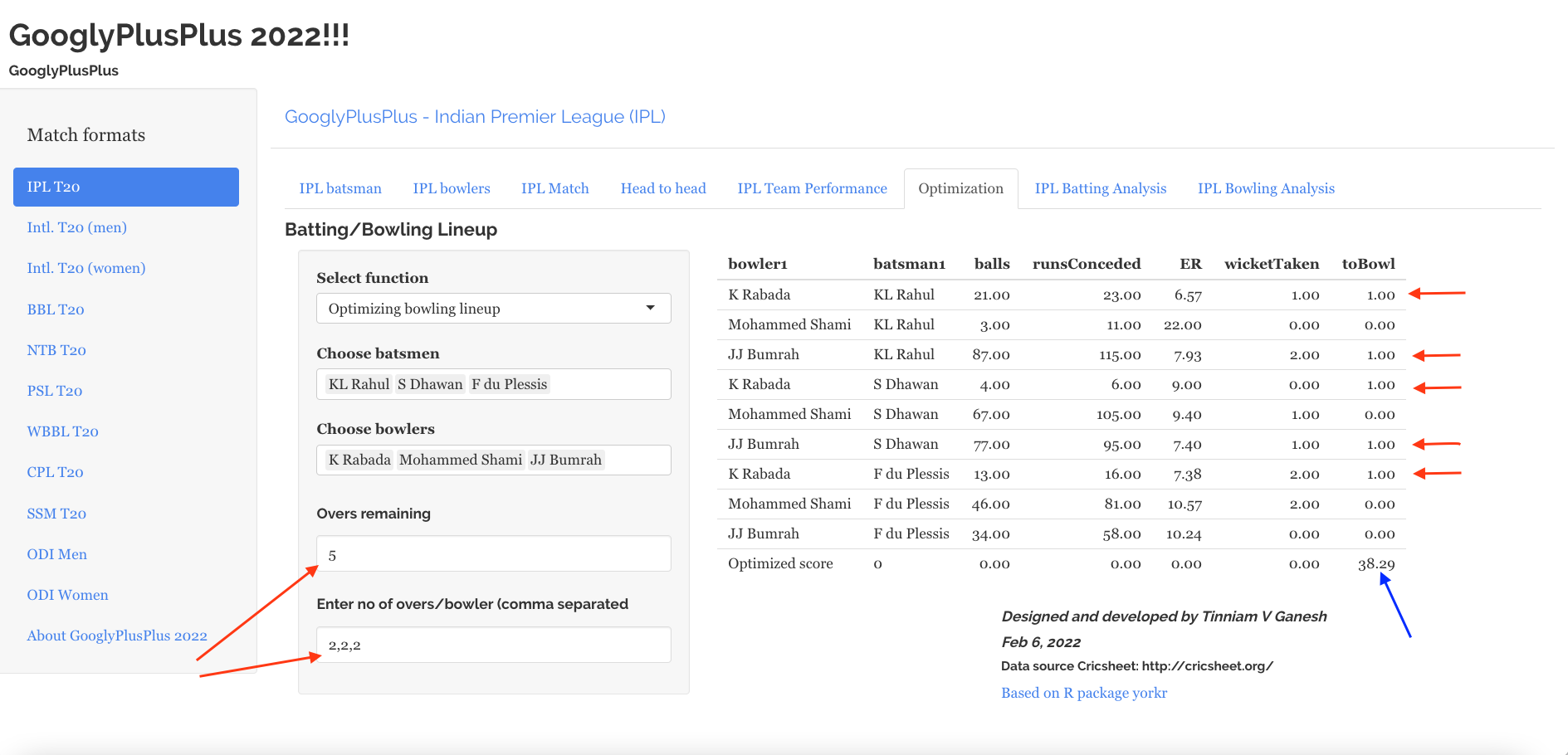
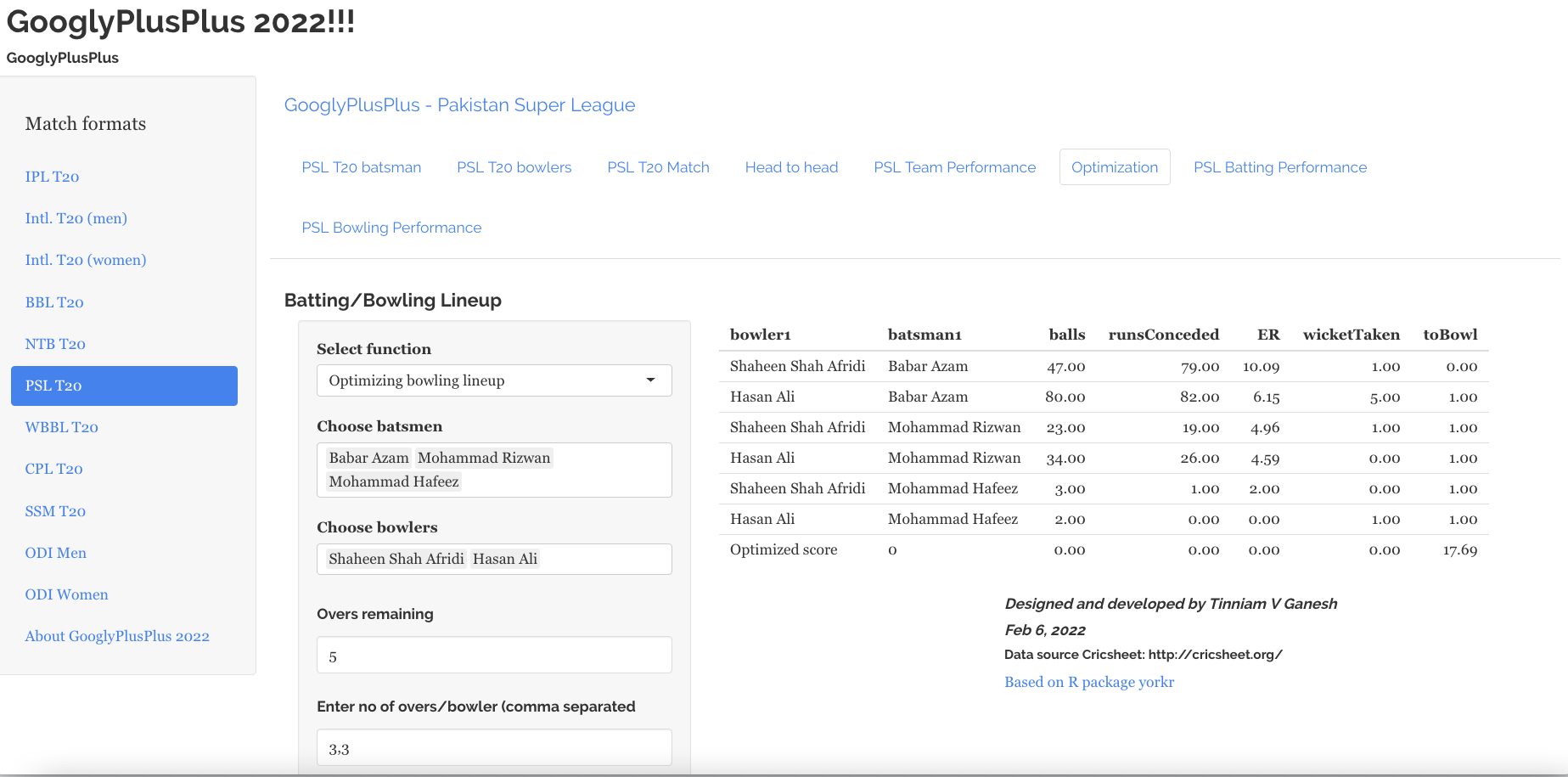
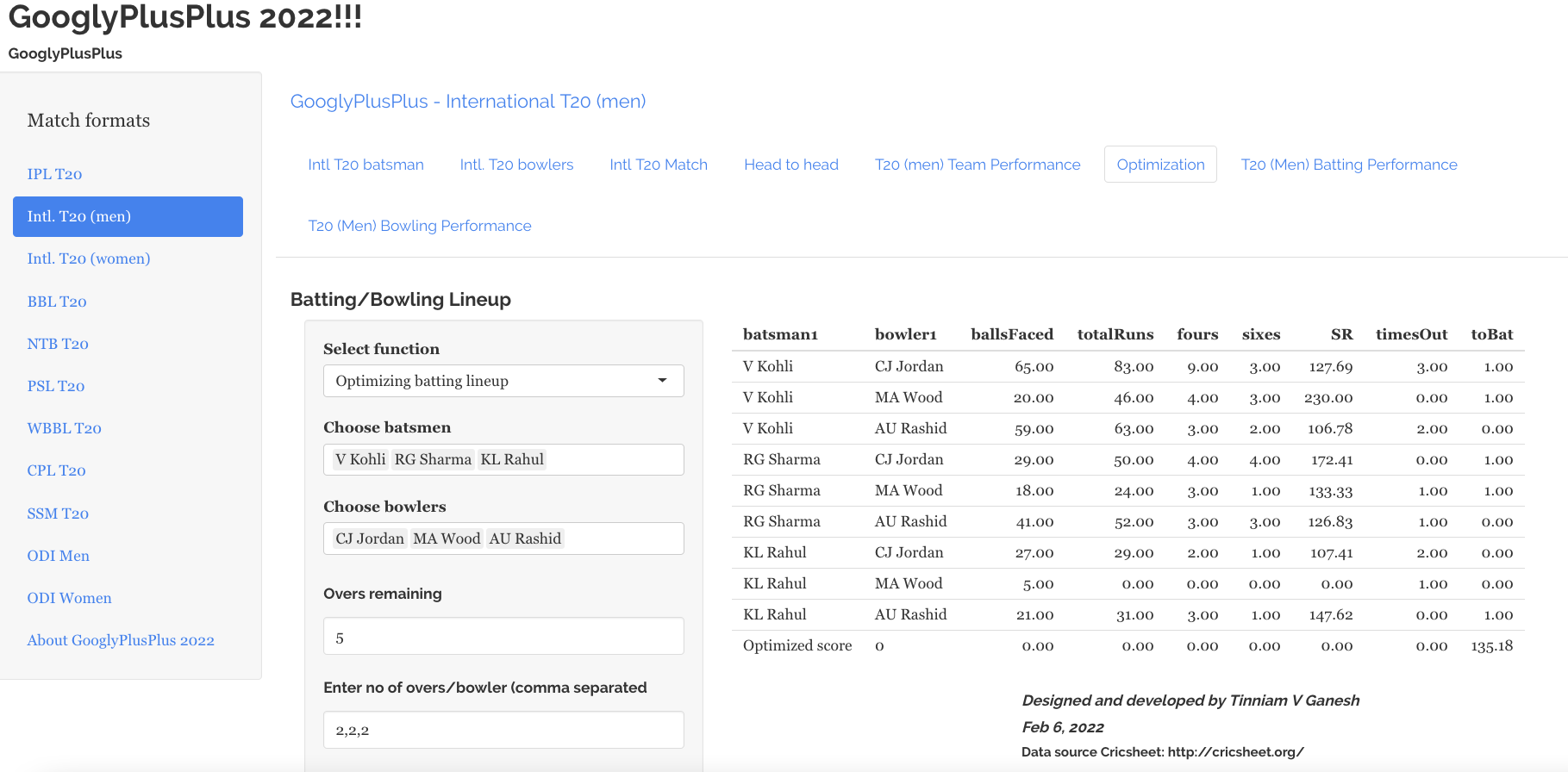
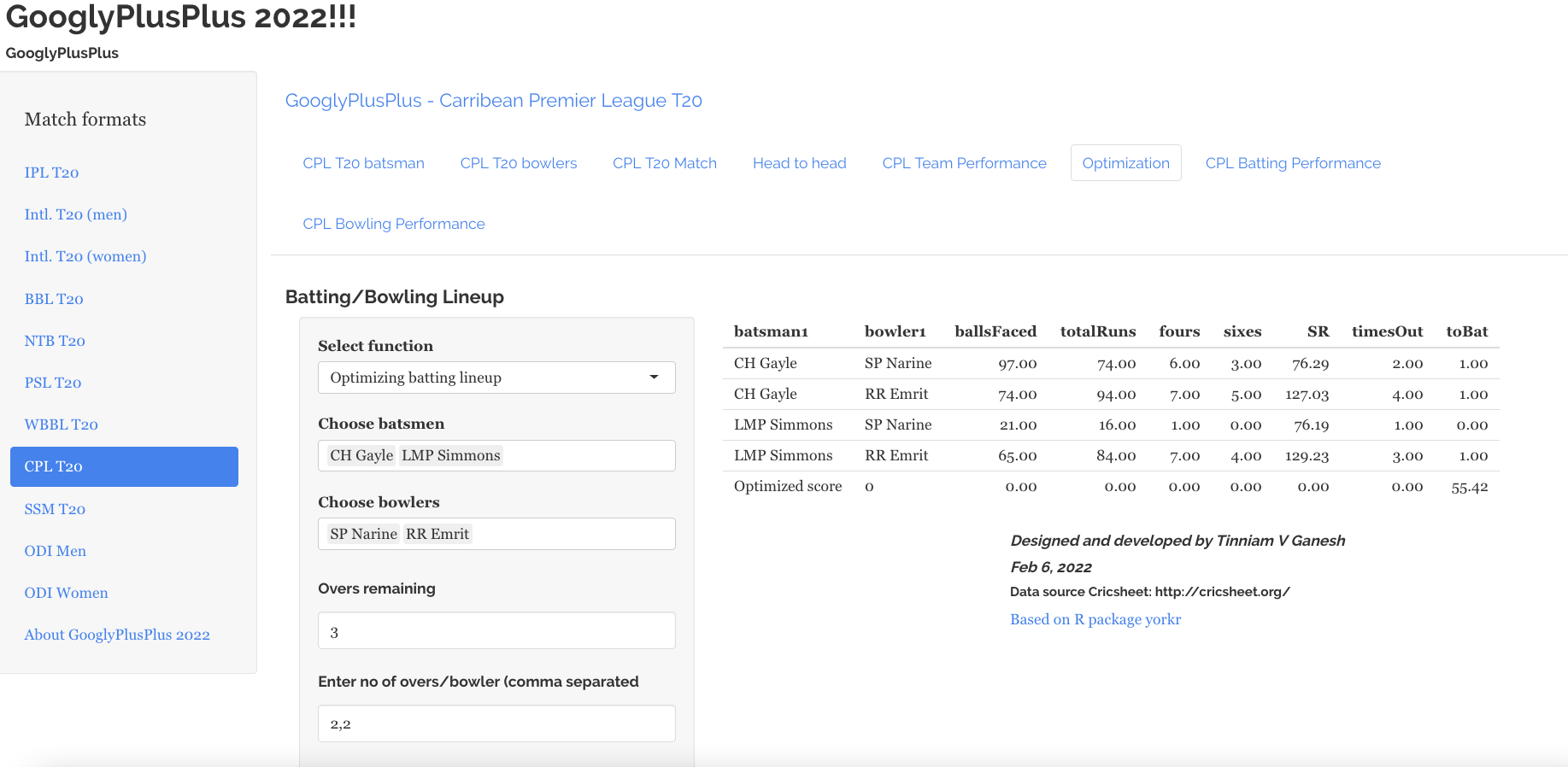
Optimisation tab: Allows one to pit batsmen vs bowlers and vice-versa. This tab also uses integer programming to optimise batting and bowling lineup
Batting analysis tab: Ranks batsmen using Runs or SR. Also plots performances of batsmen in power play, middle and death overs and plots them in a 4×4 grid
Bowling analysis tab: Ranks bowlers based on Wickets or ER. Also plots performances of bowlers in power play, middle and death overs and plots them in a 4×4 grid
Also note all these tabs and features are available for all T20 formats namely IPL, Intl. T20 (men, women), BBL, NTB, PSL, CPL, SSM.
Important note: It is possible, that at times, the Win Probability (Deep Learning) for some recent IPL matches will give an error. This is because I need to rebuild the models on a daily basis as the matches use player embeddings and there are new players. While I will definitely rebuild the models on weekends and whenever I find time, you may have to bear with this error occasionally.
Note: All charts are interactive, which means that you can hover, zoom-in, zoom-out, pan etc on the charts
The latest avatar of GooglyPlusPlus2023 is based on my R package yorkr with data from Cricsheet.
Follow me on twitter for daily highlights @tvganesh_85
GooglyPlusPlus can analyse players, matches, teams, rank, compute win probability and much more.
Included below are some random analyses of IPL 2023 matches so far
A) Chennai Super Kings vs Gujarat Titans – 31 Mar 2023
GT won by 5 wickets ( 4 balls remaining)
a) Worm Wicket Chart
b) Ball-by-ball Win Probability (Logistic Regression) (side-by-side)
This model shows that CSK had the upper hand in the 2nd last over, before it changed to GT. More details on Win Probability and Win Probability Contribution in the posts given by the links above.
c) b) Ball-by-ball Win Probability (Logistic Regression) (overlapping)
Here the ball-by-ball win probability is overlapped. CSK and GT both had nearly the same probability of winning in the 2nd last over before GT edges CSK out
B) Punjab Kings vs Rajasthan Royals – 05 Apr 2023
This was a another closely fought match. PBKS won by 5 runs
a) Worm wicket chart
b) Batting partnerships
Shikhar Dhawan scored 86 runs
c) Ball-by-ball Win Probability using Deep Learning (overlapping)
PBKS was generally ahead in the win probability race
d) Batsman Win Probability Contribution
This plot shows how the different batsmen contributed to the Win Probability. We can see that Shikhar Dhawan has a highest win probability. He played a very sensible innings. Also it appears that there is no difference between Prabhsimran Singh and others, though he score 60 runs. This computation is based on when they come to bat and how the win probability changes when they get dismissed, as seen in the 2nd chart
C) Delhi Capitals vs Gujarat Titans – 4 Apr 2023
GT won by 6 wickets (11 balls remaining)
a) Worm wicket chart
b) Runs scored across 20 overs
c) Runs vs SR plot
d) Batting scorecard (Gujarat Titans)
e) Batsman Win Probability Contribution (Gujarat Titans)
Miller has a higher percentage in the Win Contribution than Sai Sudershan who held the innings together.Strange are the ways of the ML models!!
D) Sunrisers Hyderabad vs Lucknow Supergiants ( 7 Apr 2023)
LSG won by 5 wickets (24 balls left). SRH were bamboozled by the pitch while LSG was able to cruise along
a) Worm wicket chart
b) Wickets vs ER plot
c) Wickets across 20 overs
d) Ball-by-ball win probability using Deep Learning (overlapping)
e) Bowler Win Probability Contribution (LSG)
Bishnoi has a higher win probability contribution than Krunal, though he just took 1 wicket to Krunal’s 3 wickets. This is based on how the Win Probability changed at that point in the game.
The above set of plots are just a random sample.
Note: There are 8 tabs each for 9 T20 leagues (BBL, CPL, T20 (men), T20 (women), IPL, PSL, NTB, SSM, WBB). So there are a lot more detailed charts/analses.
In this post, I compute each batsman’s or bowler’s Win Probability Contribution (WPC) in a T20 match. This metric captures by how much the player (batsman or bowler) changed/impacted the Win Probability of the T20 match. For this computation I use my machine learning models, I had created earlier, which predicts the ball-by-ball win probability as the T20 match progresses through the 2 innings of the match.
In the picture snippet below, you can see how the win probability changes ball-by-ball for each batsman for a T20 match between CSK vs LSG- 31 Mar 2022
In my previous posts I had created several Machine Learning models. In order to compute the player’s Win Probability contribution in this post, I have used the following ML models
The batsman’s or bowler’s win probability contribution changes ball-by=ball. The player’s contribution is calculated as the difference in win probability when the batsman faces the 1st ball in his innings and the last ball either when is out or the innings comes to an end. If the difference is +ve the the player has had a positive impact, and likewise for negative contribution. Similarly, for a bowler, it is the win probability when he/she comes into bowl till, the last delivery he/she bowls
Note: The Win Probability Contribution does not have any relation to the how much runs or at what strike rate the batsman scored the runs. Rather the model computes different win probability for each player, based on his/her embedding, the ball in the innings and six other feature vectors like runs, run rate, runsMomentum etc. These values change for every ball as seen in the table above. Also, this is not continuous. The 2 ML models determine the Win Probability for a specific player, ball and the context in the match.
This metric is similar to Win Probability Added (WPA) used in Sabermetrics for baseball. Here is the definition of WPA from Fangraphs “Win Probability Added (WPA) captures the change in Win Expectancy from one plate appearance to the next and credits or debits the player based on how much their action increased their team’s odds of winning.” This article in Fangraphs explains in detail how this computation is done.
In this post I have added 4 new function to my R package yorkr.
batsmanWinProbLR – batsman’s win probability contribution based on glmnet (Logistic Regression)
bowlerWinProbLR – bowler’s win probability contribution based on glmnet (Logistic Regression)
batsmanWinProbDL – batsman’s win probability contribution based on Deep Learning Model
bowlerWinProbDL – bowlerWinProbLR – bowler’s win probability contribution based on Deep Learning
Hence there are 4 additional features in GooglyPlusPlus based on the above 4 functions. In addition I have also updated
-winProbLR (overLap) function to include the names of batsman when they come to bat and when they get out or the innings comes to an end, based on Logistic Regression
-winProbDL(overLap) function to include the names of batsman when they come to bat and when they get out based on Deep Learning
Hence there are 6 new features in this version of GooglyPlusPlus.
Note: All these new 6 features are available for all 9 formats of T20 in GooglyPlusPlus namely
a) IPL b) BBL c) NTB d) PSL e) Intl, T20 (men) f) Intl. T20 (women) g) WBB h) CSL i) SSM
Check out the latest version of GooglyPlusPlus at gpp2023-2
Note: The data for GooglyPlusPlus comes from Cricsheet and the Shiny app is based on my R package yorkr
A) Chennai SuperKings vs Delhi Capitals – 04 Oct 2021
To understand Win Probability Contribution better let us look at Chennai Super Kings vs Delhi Capitals match on 04 Oct 2021
This was closely fought match with fortunes swinging wildly. If we take a look at the Worm wicket chart of this match
a) Worm Wicket chart – CSK vs DC – 04 Oct 2021
Delhi Capitals finally win the match
b) Win Probability Logistic Regression (side-by-side) – CSK vs DC – 4 Oct 2021
Plotting how win probability changes over the course of the match using Logistic Regression Model
In this match Delhi Capitals won. The batting scorecard of Delhi Capitals
c) Batting Scorecard of Delhi Capitals – CSK vs DC – 4 Oct 2021
d) Win Probability Logistic Regression (Overlapping) – CSK vs DC – 4 Oct 2021
The Win Probability LR (overlapping) shows the probability function of both teams superimposed over one another. The plot includes when a batsman came into to play and when he got out. This is for both teams. This looks a little noisy, but there is a way to selectively display the change in Win Probability for each team. This can be done , by clicking the 3 arrows (orange or blue) from top to bottom. First double-click the team CSK or DC, then click the next 2 items (blue,red or black,grey) Sorry the legends don’t match the colors! 😦
Below we can see how the win probability changed for Delhi Capitals during their innings, as batsmen came into to play. See below
e)Batsman Win Probability contribution:DC – CSK vs DC – 4 Oct 2021
Computing the individual batsman’s Win Contribution and plotting we have. Hetmeyer has a higher Win Probability contribution than Shikhar Dhawan depsite scoring fewer runs
f) Bowler’s Win Probability contribution :CSK – CSK vs DC – 4 Oct 2021
We can also check the Win Probability of the bowlers. So for e.g the CSK bowlers and which bowlers had the most impact. Moeen Ali has the least impact in this match
B) Intl. T20 (men) Australia vs India – 25 Sep 2022
a) Worm wicket chart – Australia vs India – 25 Sep 2022
This was another close match in which India won with the penultimate ball
b) Win Probability based on Deep Learning model (side-by-side) –Australia vs India – 25 Sep 2022
c) Win Probability based on Deep Learning model (overlapping) –Australia vs India – 25 Sep 2022
The plot below shows how the Win Probability of the teams varied across the 20 overs. The 2 Win Probability distributions are superimposed over each other
d) Batsman Win Probability Contribution : India – Australia vs India – 25 Sep 2022
Selectively choosing the India Win Probability plot by double-clicking legend ‘India’ on the right , followed by single click of black, grey legend we have
We see that Kohli, Suryakumar Yadav have good contribution to the Win Probability
e) Plotting the Runs vs Strike Rate:India – Australia vs India – 25 Sep 2022
f) Batsman’s Win Probability Contribution-Australia vs India – 25 Sep 2022
Finally plotting the Batsman’s Win Probability Contribution
Interestingly, Kohli has a greater Win Probability Contribution than SKY, though SKY scored more runs at a better strike rate. As mentioned above, the Win Probability is context dependent and also depends on past performances of the player (batsman, bowler)
Finally let us look at
C) India vs England Intll T20 Women (11 July 2021)
a) Worm wicket chart – India vs England Intl. T20 Women (11 July 2021)
India won this T20 match by 8 runs
b) Win Probability using the Logistic Regression Model –India vs England Intl. T20 Women (11 July 2021)
c) Win Probability with the DL model –India vs England Intl. T20 Women (11 July 2021)
d) Bowler Win Probability Contribution with the LR model–India vs England Intl. T20 Women (11 July 2021)
e) Bowler Win Contribution with the DL model–India vs England Intl. T20 Women (11 July 2021)
Go ahead and try out the latest version of GooglyPlusPlus
This should be my last post on computing T20 Win Probability. In this post I compute Win Probability using Augmented Data with the help of Conditional Tabular Generative Adversarial Networks (CTGANs).
A.Introduction
I started the computation of T20 match Win Probability in my earlier post
This was lightweight and could be easily deployed in my Shiny GooglyPlusPlus app as opposed to the Tidymodel’s Random Forest, which was bulky and slow.
d) Finally I decided to try and improve the accuracy of my Deep Learning Model using Synthetic data. Towards this end, my explorations led me to Conditional Tabular Generative Adversarial Networks (CTGANs). CTGAN are GAN networks that can be used with Tabular data as GAN models are not useful with tabular data. However, the best performance I got for
DL Keras Model + Synthetic data : accuracy =0.77
The poorer accuracy was because CTGAN requires enormous computing power (GPUs) and RAM. The free version of Colab, Kaggle kept crashing when I tried with even 0.1 % of my 1.2 million dataset size. Finally, I tried with just 0.05% and was able to generate synthetic data. Most likely, it is the small sample size and the smaller number of epochs could be the reason for the poor result. In any case, it was worth trying and this approach would possibly work with sufficient computing resources.
B.Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) was the brain child of Ian Goodfellow who demonstrated it in 2014. GANs are capable of generating synthetic text, tables, images, videos using available data. In Adversarial nets framework, the generative model is pitted against an adversary: a discriminative model that learns to determine whether a sample is from the model distribution or the data distribution.
GANs have 2 Deep Neural Networks , the Generator and Discriminator which compete against other
The Generator (Counterfeiter) takes random noise as input and generates fake images, tables, text. The generator learns to generate plausible data. The generated instances become negative training examples for the discriminator.
The Discriminator (Police) which tries to distinguish between the real and fake images, text. The discriminator learns to distinguish the generator’s fake data from real data. The discriminator penalises the generator for producing implausible results.
A pictorial representation of the GAN model can be shown below
Theoretically best performance of GANs are supposed to happen when the network reaches the ‘Nash equilibrium‘, i.e. when the Generator produces near fake images and the Discriminator’s loss is f ~0.5 i.e. the discriminator is unable to distinguish between real and fake images.
Note: Though I have mentioned T20 data in the above GAN model, the T20 tabular data is actually used in CTGAN which is slightly different from the above. See Reference 2) below.
C. Conditional Tabular Generative Adversial Networks (CTGANs)
“Modeling the probability distribution of rows in tabular data and generating realistic synthetic data is a non-trivial task. Tabular data usually contains a mix of discrete and continuous columns. Continuous columns may have multiple modes whereas discrete columns are sometimes imbalanced making the modeling difficult.” CTGANs handle these challenges.
I came upon CTGAN after spending some time exploring GANs via blogs, videos etc. For building the model I use real T20 match data. However, CTGAN requires immense raw computing power and a lot of RAM. My initial attempts on Colab, my Mac (12 core, 32GB RAM), took forever before eventually crashing, I switched to Kaggle and used GPUs. Still I was only able to use only a miniscule part of my T20 dataset. My match data has 1.2 million rows, hoanything > 0.05% resulted in Kaggle crashing. Since I was able to use only a fraction, I executed the CTGAN model over several iterations, each iteration with a random 0.05% sample of the dataset. At the end of each iterations I also generate synthetic dataset. Over 12 iterations, I generate close 360K of ‘synthetic‘ T20 match data.
I then augment the 1.2 million rows of ‘real‘ T20 match data with the generated ‘synthetic T20 match data to run my Deep Learning model
Here the quality of the synthetic data set is evaluated.
a) Statistical evaluation
Read the real T20 match data
Read the generated T20 synthetic match data
import pandas as pd
# Read the T20 match and synthetic match data
df = pd.read_csv('/kaggle/input/cricket1/t20.csv'). #1.2 million rows
synthetic=pd.read_csv('/kaggle/input/synthetic/synthetic.csv') #300K
# Randomly sample 1000 rows, and generate stats
df1=df.sample(n=1000)
real=df1.describe()
realData_stats=real.transpose
print(realData_stats)
synthetic1=synthetic.sample(n=1000)
synthetic=synthetic1.describe()
syntheticData_stats=synthetic.transpose
syntheticData_stats
import pandas as pd
# CTGAN prints out a new line for each epoch
epochs_output = str(output).split('\n')
# CTGAN separates the values with commas
raw_values = [line.split(',') for line in epochs_output]
loss_values = pd.DataFrame(raw_values)[:-1] # convert to df and delete last row (empty)
# Rename columns
loss_values.columns = ['Epoch', 'Generator Loss', 'Discriminator Loss']
# Extract the numbers from each column
loss_values['Epoch'] = loss_values['Epoch'].str.extract('(\d+)').astype(int)
loss_values['Generator Loss'] = loss_values['Generator Loss'].str.extract('([-+]?\d*\.\d+|\d+)').astype(float)
loss_values['Discriminator Loss'] = loss_values['Discriminator Loss'].str.extract('([-+]?\d*\.\d+|\d+)').astype(float)
# the result is a row for each epoch that contains the generator and discriminator loss
loss_values.head()
import plotly.graph_objects as go
# Plot loss function
fig = go.Figure(data=[go.Scatter(x=loss_values['Epoch'], y=loss_values['Generator Loss'], name='Generator Loss'),
go.Scatter(x=loss_values['Epoch'], y=loss_values['Discriminator Loss'], name='Discriminator Loss')])
# Update the layout for best viewing
fig.update_layout(template='plotly_white',
legend_orientation="h",
legend=dict(x=0, y=1.1))
title = 'CTGAN loss function for T20 dataset - '
fig.update_layout(title=title, xaxis_title='Epoch', yaxis_title='Loss')
fig.show()
G. Qualitative evaluation of Synthetic data
a) Quality of continuous columns in synthetic data
KSComplement -This metric computes the similarity of a real column vs. a synthetic column in terms of the column shapes.The KSComplement uses the Kolmogorov-Smirnov statistic. Closer to 1.0 is good and 0 is worst
The performance is decent but not excellent. I was unable to execute more epochs as it it required larger than the memory allowed
c) Correlation similarity
This metric measures the correlation between a pair of numerical columns and computes the similarity between the real and synthetic data – it compares the trends of 2D distributions. Best 1.0 and 0.0 is worst
In this final part I augment my T20 match data set with the generated synthetic T20 data set.
import pandas as pd
from numpy import savetxt
import tensorflow as tf
from tensorflow import keras
import pandas as pd
import numpy as np
from keras.layers import Input, Embedding, Flatten, Dense, Reshape, Concatenate, Dropout
from keras.models import Model
import matplotlib.pyplot as plt
# Read real and synthetic data
df = pd.read_csv('/kaggle/input/cricket1/t20.csv')
synthetic=pd.read_csv('/kaggle/input/synthetic/synthetic.csv')
# Augment the data. Concatenate real & synthetic data
df1=pd.concat([df,synthetic])
# Create training and test samples
print("Shape of dataframe=",df1.shape)
train_dataset = df1.sample(frac=0.8,random_state=0)
test_dataset = df1.drop(train_dataset.index)
train_dataset1 = train_dataset[['batsmanIdx','bowlerIdx','ballNum','ballsRemaining','runs','runRate','numWickets','runsMomentum','perfIndex']]
test_dataset1 = test_dataset[['batsmanIdx','bowlerIdx','ballNum','ballsRemaining','runs','runRate','numWickets','runsMomentum','perfIndex']]
train_dataset1
train_labels = train_dataset.pop('isWinner')
test_labels = test_dataset.pop('isWinner')
print(train_dataset1.shape)
a=train_dataset1.describe()
stats=a.transpose
print(a)
As can be seen the accuracy with augmented dataset is around 0.77, while without it I was getting 0.867 with just the real data. This degradation is probably due to the folllowing reasons
Only a fraction of the dataset was used for training. This was not representative of the data distribution for CTGAN to correctly synthesise data
The number of epochs had to be kept low to prevent Kaggle/Colab from crashing
I. Conclusion
This post shows how we can generate synthetic T20 match data to augment real T20 match data. Assuming we have sufficient processing power we should be able to generate synthetic data for augmenting our data set. This should improve the accuracy of the Win Probabily Deep Learning model.
In my last post GooglyPlusPlus gets ready for ICC Men’s T20 World Cup, I had mentioned that GooglyPlusPlus was preparing for the big event the ICC Men’s T20 World cup. Now that the T20 World cup is underway, my Shiny app in R, GooglyPlusPlus ,will be generating near real-time analytics of matches completed the previous day. Besides the app can also do historical analysis of players, teams and matches.
The whole process is automated. A cron job will execute every day, in the morning, which will automatically download the matches of the previous day from Cricsheet, unzip them, start a pipeline which will transform and process the match data into necessary folders and finally upload the newly acquired data into my Shiny app. Hence, you will be able to access all the breathless, pulsating cricketing action in timeless, interactive plots and tables which will capture all aspects of Men’s T20 matches, namely batsman, bowler performance, match analysis, team-vs-team, team-vs-all teams besides ranking of batsmen & bowlers. Since the data is cumulative, all the analytics are historical and current.
The data for GooglyPlusPlus is taken from Cricsheet
Interest in cricket, has mushroomed in recent times around the world, with the addition of new formats which started with ODI, T20, T10, 100 ball and so on. There are leagues which host these matches at different levels around the world. While GooglyPlusPlus, provides near real-time analytics of Men’s T20 World cup, we can clearly envision a big data platform which ingests matches daily from multiple cricket formats, leagues around the world generating real-time and near real-time analytics which are essential these days to selection of teams at different levels through auctions. For more discussion on this see my posts
We could imagine a Data Lake, into which are ingested data from the different cricket formats, leagues through appropriate technology connectors. Once the data is ingested, we could have data pipelines, based on Azure ADF, Apache NiFi, Apache Airflow or Amazon EMR etc., to transform, process and enhance the data, generating real-time analytics on the fly. Recent formats like T20, T10 require more urgency in strategic thinking based on scoring within limited overs, or containing batsmen from going on a rampage within the set of overs, the analytics on a fly may help the coach to modify the batting or bowling lineup at points in match. In this context see my earlier post Using Linear Programming (LP) for optimizing bowling change or batting lineup in T20 cricket
All of these are not just possible, but are likely to become reality as more and more formats, leagues and cricket data proliferate around the world.
This post, focuses on generating near-real time analytics for ICC Men’s T20 World Cup using GooglyPlusPlus. Included below, is a sampling of the analytics that you can perform for analysing the matches. In addition you can do all the analysis included in my post GooglyPlusPlus gets ready for ICC Men’s T20 World Cup
Namibia-Sri Lanka-16 Oct 2022 : Match Worm graph
The opening match between Namibia vs Sri Lanka resulted in an upset. We can see this in the match worm-wicket graph below
2. Scotland vs West Indies – 17 Oct 2022: Batsmen vs Bowlers
George Munsey was the top scorer for Scotland and was instrumental in the win against WI. His performance against West Indies bowlers is shown below. Note, the charts are interactive
3. Zimbabwe vs Ireland – 17 Oct 2022 : Team Runs vs SR
Sikander Raza of Zimbabwe with 82 runs with the strike rate ~ 170
4.United Arab Emirates vs Netherlands – 16 Oct 2022: Team runs across 20 overs
UAE pipped Netherlands in the middle overs and were able to win by 1 ball and 3 wickets
5.Scotland vs Ireland – 19 Oct 2022 : Team Runs vs SR Middle overs plot
Curtis Campher snatched the game away from Scotland with his stellar performance in middle and death overs
6. UAE vs Namibia : 20 Oct 2022 : Team Wickets vs ER plot
Basoor Hameed and Zahoor Khan got 2 wickets apiece with an economy rate of ~5.00 but still they were not able to stop UAE from stealing a win
7. Overall Runs vs SR in T20 World Cup 2022
It is too early to rank the players, nevertheless in the current T20 World Cup, MP O’Dowd (Netherlands), BKG Mendis (Sri Lanka) and JN Frylinck(Namibia) are the top 3 batsmen with good runs and Strike Rate
8. Overall Wickets over ER in T20 World Cup 2022
The top 3 bowlers so far in T20 World Cup 2022 are a) BFW de Leede (Netherlands) b) PWH De Silva (Sri Lanka) c) KP Meiyappan (UAE) with a total of 7,7, and 6 wickets respectively
Note: Besides the match analysis GooglyPlusPlus also provides detailed analysis of batsmen, bowlers, matches as above, team-vs-team, team-vs-all teams, ranking of batsmen & bowlers etc. For more details see my post GooglyPlusPlus gets ready for ICC Men’s T20 World Cup
Do visit GooglyPlusPlus everyday to check out the cricketing actions of matches gone by. You can also follow me on twitter @tvganesh_85 for daily highlights.
It is time!! So last weekend, I turned the wheels, moved the levers and listened to the hiss of steam, as I cranked up my Shiny app GooglyPlusPlus. The ICC Men’s T20 World Cup is just around the corner, and it was time to prepare for this event. This latest GooglyPlusPlus is current with the latest Intl. men’s T20 match data, give or take a few. GooglyPlusPlus can analyze batsmen, bowlers, matches, team-vs-team, team-vs-all teams, besides also ranking batsmen, bowlers and plot performances in Powerplay, middle and death overs.
In this post, I include a quick refresher of some of features of my app GooglyPlusPlus. Note: This is a random sampling of the functions available. There are more than 120+ features available in the app.
Check out your favourite players and your country’s team with GooglyPlusPlus
Note 1: All charts are interactive
Note 2: You can choose a date range for your analysis
Note 3: The data for this app is taken from Cricsheet
T20Batsman tab
This tab includes functions pertaining to individual batsmen. Functions include Runs vs Deliveries, moving average runs, cumulative average run, cumulative average strike rate, runs against opposition, runs at venue etc.
For e.g.
a) Suryakumar Yadav’s (India) cumulative strike rate
b) Mohammed Rizwan’s (Pakistan) performance against opposition
2. T20 Bowler’s Tab
The bowlers tab has functions for computing mean economy rate, moving average wickets, cumulative average wicks, cumulative economy rate, bowlers performance against opposition, bowlers performance in venue, predict wickets and others
A random function is shown below
a) Predict wickets for Wanindu Hasaranga of Sri Lanka
3. T20 Match tab
The match tab has functions that can compute match batting & bowling scorecard, batting partnerships, batsmen performance vs bowlers, bowler’s wicket kind, bowler’s wicket match, match worm graph, match worm wicket graph, team runs across 20 overs, team wickets in 20 overs, teams runs or wickets in powerplay, middle and death overs
Here are a couple of functions from this tab
a) Afghanistan vs Ireland – 2022-08-15
b) Australia vs Sri Lanka – 2019-11-01 – Runs across 20 overs
4. T20 Head-to-head tab
This tab provides the analysis of all combination of T20 teams (countries) in different aspects. This tab can compute the overall batting, bowling scorecard in all matches between 2 countries, batsmen partnerships, performances against bowlers, bowlers vs batsmen, runs, strike rate, wickets, economy rate across 20 overs, runs vs SR plot and wicket vs ER plot in all matches between team and so on. Here are a couple of examples from this tab
a) Bangladesh vs West Indies – Batting scorecard from 2019-01-01 to 2022-07-07
b) Wickets vs ER plot – England vs New Zealand – 2019-01-01 to 2021-11-10
5. T20 Team performance overalltab
This tab provides detailed analysis of the team’s performance against all other teams. As in the previous tab there are functions to compute the overall batting, bowling scorecard of a team against all other teams for any specific interval of time. This can help in picking out the most consistent batsmen, bowlers. Besides there are functions to compute overall batting partnerships, bowler vs batsmen, runs, wickets across 20 overs, run vs SR and wickets vs ER etc.
a) Batsmen vs Bowlers (Rank 1- V Kohli 2019-01-01 to 2022-09-25)
b) team Runs vs SR in Death overs (India) (2019-01-01 to 2022-09-25)
6) Optimisation tab
In the optimisation tab we can check the performance of a specific batsmen against specific bowlers or bowlers against batsmen
a) Batsmen vs Bowlers
b) Bowlers vs batsmen
7) T20 Batting Performancetab
This tab performs various analytics like ranking batsmen based on Run over SR and SR over Runs. Also you can plot overall Runs vs SR, and more specifically Runs vs SR in Powerplay, Middle and Death overs. All of this can be done for a specific date range. Here are some examples. The data includes all of T20 (all countries all matches)
a) Rank batsmen (Runs over SR, minimum matches played=33, date range=2019-01-01 to 2022-09-27)
The top 3 batsmen are Mohamen Rizwan, V Kohli and Babar Azam
b) Overall runs vs SR plot (2019-01-01 to 2022-09-27)
c) Overall Runs vs SR in Powerplay (all teams- 2019-01-01-2022-09-27)
This plot will be crowded. However, we can zoom into an area of interest. The controls for interacting with the plot are in the top of the plot as shown
Zooming in and panning to the area we can see the best performers in powerplay are as below
8) T20 Bowling Performancetab
This tab computes and ranks bowlers on Wickets over Economy and Economy rate over wickets. We can also compute and plot the Wickets vs ER in all matches , besides the Wickets vs ER in powerplay, middle and death overs with data from all countries
a) Rank Bowlers (Wickets over ER, minimum matches=28, 2019-01-01 to 2022-09-27)
b) Wickets vs ER plot
S Lamichhane (NEP), Hasaranga (SL) and Shamsi (SA) are excellent bowlers with high wickets and low ER as seen in the plot below
c) Wickets vs ER in death overs (2019-01-01 to 2022-09-27, min matches=24)
Zooming in and panning we see the best performers in death overs are MR Adair (IRE), Haris Rauf(PAK) and Chris Jordan (ENG)
With the excitement building up, it is time you checked out how your country will perform and the players who will do well.
IPL 2022 has just concluded and yet again, it is has thrown a lot of promising and potential youngsters in its wake, while established players have fallen! With IPL 2022, we realise that “Sceptre and Crownmusttumble down” and that ‘theglories‘ of form and class like everything else are “shadows not substantial things” (Death the Leveller by James Shirley).
So King Kohli had to kneel, and hitman’ himself got hit. Rishabh Pant, Jadeja also had a poor season. On the contrary there were several youngsters who shone like Abhishek Sharma, Tilak Verma, Umran Malik or a Mohsin Khan
This post is about my potential T20 Indian players for the World Cup 2022 and beyond.
The post below includes my own analysis and thoughts. Feel free to try out my Shiny app GooglyPlusPlus and draw your own conclusions.
How often we hear that data by itself is useless, unless we can draw insights from it? This is a prevailing theme in the corporate world and everybody uses all sorts of tools to analyse and subsequently draw insights. Data analysis can be done in many ways as data can be sliced, diced, chopped in a zillion ways. There are many facets and perspectives to analysing data. Creating insights is easy, but arriving at actionable insights is anything but. So, the problem of selecting the best 11 is difficult as there are so many ways to look at the analysis. My Shiny app GooglyPlusPlus based on my R package yorkr can analyse data in several ways namely
Batsman analysis
Bowler analysis
Match analysis
Team vs team analysis
Team vs all teams analysis
Batsman vs bowler and vice versa
Analysis of in 3,4,5 in power play, middle and death overs
GooglyPlusPlus uses my R package yorkr which has ~ 160 functions some which have several options. So, we can say roughly there are ~500 different ways that analysis can be done or in other words we can gather almost roughly 500+ different insights, not to mention that there are so many combinations of head-on matches and one-vs-all matches.
So generating insights or different ways of analysis data alone is not enough. The question is whether we can get a consolidated view from the different insights. In this post, I try to identify the best contenders for the Indian T20 team. This is far more difficult than it looks. Do you select players on past historical performance or do you choose from the newer crop of players, who have excelled in the recent IPL season. I think this boils down the typical situation in any domain. In engineering, we have tradeoffs – processing power vs memory tradeoff, throughput vs latency tradeoff or in the financial domain it is cost vs benefit or risk vs reward tradeoff. For team selection, the quandary is, whether to choose seasoned players with good historical performance but a poor performances in recent times or go with youngsters who have played with great courage and flair in this latest episode of IPL 2022. Hence there is a tradeoff between reliable but below average performance or risky but superlative performances of new players.
For this I base my potential list from
Then (past history of batsmen & bowlers) – I have chosen the performance of batsmen and bowlers in the last 3 years. With we can arrive at those who have had reasonably reliable performance for the last 3 years
Now (IPL 2022) – Performance in the current season IPL 2022
A. Then (Jan 2020 – May 2022) – Batsmen analysis
In this section I analyse the performances of batsmen and bowlers from Jan 2022 – May 2022. This is done based on ranking, and plots of Runs vs Strike Rate in Power Play, Middle and Death overs
Also I analyse bowlers based on the overall rank from Jan 2022- May 2022. Further more analysis is done on Wickets vs Economy Rate overall and in Power Play, Middle and Death overs
a. Ranks of batsmen (Runs over Strike Rate) : Jan 2020 – May 2022
IPL 2022 just finished and clearly brings out the batsmen who are in great nick. It is always going to be a judgment call of whether to go for ‘old reliable’ or ‘new and awesome’.
a. Ranks of batsmen (Runs over Strike Rate) : IPL 2022
The best batsmen this season in Runs over Strike rate are
f. Best batsmen Runs vs SR in Death overs:IPL 2022
Top batsmen in death overs in IPL 2022
[Dinesh Karthik, Rahul Tewatia, MS Dhoni, KL Rahul, Azar Patel, Washington Sundar, R Ashwin, Hardik Pandya, Ayush Badoni, Shivam Dube, Suryakumar Yadav, Ravindra Jadeja, Sanju Samson]
OverallBattingPerformance in season
Kohli peaked in 2016 and from then on it has been a downward slide (see below)
Taking a look at Kohli’s moving average it is clear that he is past his prime and it will take a herculean effort to regain his lost glory
Similarly, Rohit Sharma’s moving average is constantly around ~30 as seen below
The cumulative average of Rohit Sharma is shown below
Comparing KL Rahul, Shikhar Dhawan, Rohit Sharma and V Kohli we see that KL Rahul and Shikhar Dhawan have had a much superior performance in the last 2-3 years. Rohit has averaged about ~25 runs every season.
Comparing the 4 wicket-keeper batsmen Sanju Samson, Rishabh Pant, Ishan Kishan and Dinesh Karthik from 2016
i) Runs over Strike Rate
We see that Pant peaked in 2018 but has not performed as well since. In the last 2 years Sanju Samson and Ishan Kishan have done well
ii) Strike Rate over Runs
For the last couple of seasons Rishabh Pant and Dinesh Kartik top the strike rate over the other 2
Similar analysis can be done other combinations of batsmen
Choosing the best batsmen from the above, my top 5 batsmen would be
Personally, I feel Ishan Kishan and Shreyas Iyer are a little tardy while playing express speeds, as compared to Sanju Samson or Rishabh Pant.
If you notice, I have not included both Virat Kohli or Rohit Sharma who have been below par for some time
C.Then (Jan 2020 – May 2022) – Bowler analysis
This section I analyse the performances of bowlers from Jan 2022 – May 2022. This is done based on ranking, and plots of Wickets vs Economy Rate in Power Play, Middle and Death overs
a. Ranks of bowlers (Wickets over Economy Rate) : Jan 2020 – May 2022
The most consistent bowlers Wickets over Economy Rate for the last 3 years are
[YS Chahal, Jasprit Bumrah, Mohammed Dhami, Harshal Patel, Shardul Thakur, Arshdeep Singh, Rahul Chahar, Varun Chakravarthy, Ravi Bishnoi, Prasidh Krishna, R Ashwon, Axar Patel, Mohammed Siraj, Ravindra Jadeja, Krunal Pandya, Rahul Tewatia]
b. Ranks of bowlers (Economy Rate over Wickets) : Jan 2020 – May 2022
The most economical bowlers since 2020 are
[Axar Patel, Krunal Pandya, Jasprit Bumrah, CV Varun, R Ashwin, Ravi Bishnoi, Rahul Chahar, YS Chahal, Ravindra Jadeja, Harshal Patel, Mohammed Shami, Mohammed Siraj, Rahul Tewatia, Arshdeep Singh, Prasidh Krishna, Shardul Thakur]
c.BestBowlers Wickets vs ER :Jan 2020 – May 2022
The best bowlers Wickets vs ER will be in the bottom right quadrant. The most consistent and reliable bowlers are
[YS Chahal, Jasprit Bumrah, Mohammed Shami, Harshal Patel, CV Arun, Ravi Bishnoi, Rahul Chahar, R Ashwin, Axar Patel]
d. Best bowlers Wickets vs ER in Powerplay:Jan 2020 – May 2022
The best bowlers in Powerplay are
[Mohammed Shami, Deepak Chahar, Mohammed Siraj, Arshdeep Singh, Jasprit Bumrah, Avesh Khan, Mukesh Choudhary, Shardul Thakur, T Natarajan, Bhuvaneshwar Kumar, WashingtonSundar, Shivam Mavi]
e. Best bowlers Wickets vs ER in Middle overs : Jan 2020 – May 2022
The most reliable performers in middle overs from 2020-2022 are
[YS Chahal, Rahul Chahr, Ravi Bishnoi, Harshal Patel, Axar Patel, Jasprit Bumrah, Umran Malik, R Ashwin, Avesh Khan, Shardul Thakur, Kuldeep Yadav]
f. Best bowlers Wickets vs ER in Death overs : Jan 2020 – May 2022
The most reliable bowlers are
[Harshal Patel, Mohammed Shami, Jasprit Bumrah, Arshdeep Singh, T Natarajan, Avesh Khan, Shardul Thakur, Bhuvaneshwar Kumar, Shivam Mavi, YS Chahal, Prasidh Krishna, Mohammed Siraj, Chetan Sakariya]
B) Now (IPL 2022)– Bowler analysis
a. Ranks of bowlers (Wickets over Economy Rate) : IPL 2022
The best bowlers in IPL 2022 when considering Wickets over Economy Rate
[YS Chahal, Umran Malik, Prasidh Krishna, Mohammed Shami, Kuldeep Yadav, Harshal Patel, T Natarajan, Avesh Khan, Shardul Thakur, Mukesh Choudhary, Jasprit Bumrah, Ravi Bishnoi]
a. Ranks of bowlers (Economy Rate over Wickets) : IPL 2022
The most economical bowlers in IPL 2022 are
[Axar Patel, Jasprit Bumrah, Krunal Pandya, Umesh Yadav, Bhuvaneshwar Kumar, Rahul Chahr, Harshal Patel, Arshdeep Singh, R Ashwion, Umran Malik, Kuldeep Yadav, YS Chahal, Mohammed Shami, Avesh Khan, Prasidh Krishna]
c.BestBowlers Wickets vs ER :IPL 2022
The overall best bowlers in IPL 2022 are
[YS Chahal, Umran Malik, Harshal Patel, Prasidh Krishna, Mohammed Shami, Kuldeep Yadav, Avesh Khan, Jasprit Bumrah, Umesh Yadav, Bhuvaneshwar Kumar, Arshdeep Singh, R Ashwin, Rahul Chahar, Krunal Pandya]
d. Best bowlers Wickets vs ER in Powerplay: IPL 2022
The best bowlers in IPL 2022 in Power play are
[Mukesh Choudhary, Mohammed Shami, Prasidh Krishna, Umesh Yadav, Avesh Khan, Mohsin Khan, T Natarajan, Jasprit Bumrah, Yash Dayal, Mohammed Siraj]
d. Best bowlers Wickets vs ER in Middle overs: IPL 2022
The best bowlers in IPL 2022 during middle overs
The best bowlers are
[YS Chahal, Umran Malik, Kuldeep Yadav, Harshal Patel, Ravi Bishnoi, R Ashwin]
e. Best bowlers Wickets vs ER in Death overs: IPL 2022
The best bowlers in death overs in IPL 2022 are
[T Natarajan, Harshal Patel, Bhuvaneshwar Kumar, Mohammed Shami, Jasprit Bumrah, Shardul Thakur, YS Chahal, Prasidh Krishna, Avesh Khan, Mohsin Khan, Yash Dayal, Umran Malik, Arshdeep Singh]
Typically in a team we would need a combination of 4 bowlers (2 fast & 2 spinner or 3 fast and 1 spinner) with an additional player who is all rounder.
For 4 bowlers we could have
JJ Bumrah
Mohammed Shami, Umran Malik, Bhuvaneshwar Kumar, Umesh Yadav
Arshdeep Singh, Avesh Khan, Mohsin Khan, Harshal Patel
YS Chahal, Ravi Bishnoi, Rahul Chahar, Axar Patel
Ravindra Jadeja, Hardik Pandya, Rahul Tewathia, R Ashwin
i) Performance comparison (Wickets over Economy Rate)
Bumrah had the best season in 2020. He has been doing quite well and has been among the wickets
ii) Performance comparison (Economy Rate over Wickets)
Bumrah has the best Economy Rate
We can do a wicket prediction of bowlers. So for example for Bumrah it is
iii) Performance evaluation(Wickets over Economy Rate)
Harshal Patel followed by Avesh Khan had a good season last year, but Umran Malik pipped them this year (see below)
iv) Performance analysis of spinners
a. Wickets over Economy Rate: 2022
Chahal has the best season followed by Bishnoi and Chahar this season
b) Economy Rate over WIckets
Axar Patel has the best economy rate followed by Rahul Chahar
Conclusion
The above post identified the best candidates for the Indian team in the future and beyond. In my T20 list, I have neither included Virat Kohli or Rohit Sharma. The data in T20 clearly indicates that they have had their days. There is a lot more talent around. The tradeoff is a little risk for a greater potential performance. My list would be
It is that time of the year when there is “a song in the air, the lark’s on the wing, and the snail’s on the the thorn“. Yes, it is the that time of year when the grand gala event of IPL 2022 is underway. So, I managed to wake myself from my Covid-induced slumber, worked up my ‘creaking bones‘ and cranked up the GooglyPlusPlus machinery.
So now, every morning, a scheduled CRON tab entry will automatically download the previous night’s match data from Cricsheet, unzip, process and transform it into the necessary format required by my R package yorkr, and make it available to my Shiny app GooglyPlusPlus. Hence the data is current and you have access to ‘analytics-in-the-now’!.
As you know in 2021, I added a lot of new features to GooglyPlusPlus, new tabs to do even more. analytics – or in other words there is “more GooglyPlusPlus per click!!”. So now, you have the following
Batsman tab: For detailed analysis of batsmen
Bowler tab: For detailed analysis of bowlers
Match tab: Analysis of individual matches, plot of Runs vs SR, Wickets vs ER in power play, middle and death overs
Head-to-head tab: Detailed analysis of team-vs-team batting/bowling scorecard, batting, bowling performances, performances in power play, middle and death overs
Team performance tab: Analysis of team-vs-all other teams with batting /bowling scorecard, batting, bowling performances, performances in power play, middle and death overs
Optimisation tab: Allows one to pit batsmen vs bowlers and vice-versa. This tab also uses integer programming to optimise batting and bowling lineup
Batting analysis tab: Ranks batsmen using Runs or SR. Also plots performances of batsmen in power play, middle and death overs and plots them in a 4×4 grid
Bowling analysis tab: Ranks bowlers based on Wickets or ER. Also plots performances of bowlers in power play, middle and death overs and plots them in a 4×4 grid
Also note all these tabs and features are available for all T20 formats namely IPL, Intl. T20 (men, women), BBL, NTB, PSL, CPL, SSM.
Note: All charts are interactive, which means that you can hover, zoom-in, zoom-out, pan etc on the charts
The latest avatar of GooglyPlusPlus2022 is based on my R package yorkr with data from Cricsheet.
Here are some random analysis that can be done by GooglyPlusPlus across the tabs. Note the app will be updated daily and the analytics will be current throughout the season of IPL 2022
A) Match tab
a) GT vs DC – 2 Apr 2022
Runs vs SR – Gujarat Titans
b) CSK vs LSG – 31 Mar 2022
Runs across 20 overs
c) KKR vs PBKS -Match wicket worm chart – 1 Apr 2022
B) Batsmen tab
a) Faf Du Plessis – Runs vs Deliveries
b) Sanju Samson – Runs against opposition
C) Bowler’s tab
a) D J Bravo – No of deliveries to wicket
b) Trent Boult – Wickets at Venues
D) Head-to-head tab
a) DC vs MI – Mar -2019 till date : Batting scorecard
b) CSK vs KKR – Jan 2019 till date : Runs vs SR
E) Team vs All Teams tab
a) Punjab Kings vs all Teams – Wickets vs ER in Power play
b) Rajasthan Royals vs all Teams : Jan 2019 till date : Runs vs SR in Power play
F) Optimisation tab
a) Batsmen vs Bowlers
b) Bowlers vs batsmen
G) Batting analysis
This tab is for ranking batsmen
a) Batsmen rank from 2019 till date (Runs over SR)
GooglyPlusPlus2022 is the new avatar of last year’s GooglyPlusPlus2021. Roughly, about 5 years back I had written a post on Using linear programming to optimize T20 batting and bowling line up. This post has been on the back of my mind for a long time and I decided to pay this post a revisit. This requires computing performance of individual batsmen vs bowlers and vice-versa for performing the optimization. So in this latest incarnation, there are 4 new functions
batsmanVsBowlerPerf – Performance of batsmen against chosen bowlers
bowlerVsBatsmanPerf – Performance of bowlers versus specific batsmen
battingOptimization – Optimizing batting line up based on strike rates ad remaining overs
bowlingOptimization – Optimizing bowling line up based on economy rates and remaining overs
These 4 functions have been incorporated in all the supported 9 T20 formats namely a. IPL b. Intl. T20(men) c. Intl. T20 (women) d. BBL e. NTB f. PSL g. WBB h. CPL i. SSM
You can clone/fork the code for GooglyPlusPlus2022 from Github from gpp2022-1
With this latest update you can do a myriad of analyses of batsmen, bowlers, teams, matches. This is just-in-time for the IPL Mega-auction!! Do check out these other posts of GooglyPlusPlus for other detailed analysis
A) Batsman Vs Bowlers – This option computes the performance of individual batsman against individual bowlers
a) IPL Batsmen vs Bowlers
Included below are the performances of Dhoni, Raina and Kohli against Malinga, Ashwin and Bumrah. Note: The last 2 text box input are not required for this.
b) Intl. T20 (men) Batsmen vs Bowlers
Note: You can type the name and choose from the drop down list
B) Bowler vs Batsmen – You can check the performance of specific bowlers against specific batsmen
a) Intl. T20 (women) India vs Australia
b) PSL Bowlers vs Batsmen
C) Strategy for optimizing batting and bowling line up
From the above 2 tabs, it is obvious, that different bowlers have different ER and wicket rate against different batsmen. In other words, the effectiveness of the bowlers varies by batsmen. Conversely, batsmen are more comfortable with certain bowlers versus others and this shows up in different strike rates.
Hence during the death overs, when trying to restrict batsmen to a certain score or on the flip side when the batting side needs to score a target within certain overs, we need to take advantage of the relative effectiveness of bowlers vs batsmen for optimising bowling and aggressiveness of batsmen versus bowlers to quickly reach the target.
This is the approach that is used for bowling and batting optimisation. For optimising bowling, we need to formulate a minimisation problem based on ER rates and for optimising batting, a maximisation strategy is chosen based on SR. ‘Integer programming’ is used to compute during the last set of overs
This latest version includes optimization using “integer programming” based on R package lpSolve.
Here are the 2 formulations
Assume there are 3 bowlers – and there are 3 batsmen –
I) LP Formulation for bowling order
Let the economy rate be the Economy Rate of the jth bowler to the ith batsman. Also if remaining overs for the bowlers are and the total number of overs left to be bowled are
Let the economy rate be the Economy Rate of the jth bowler to the ith batsman. Objective function : Minimize – i.e. Constraints Where is the number of overs remaining for the jth bowler against ‘k’ batsmen and if the total number of overs remaining to be bowled is N then or The overs that any bowler can bowl is
II) LP Formulation for batting lineup
Let the strike rate be the Strike Rate of the ith batsman to the jth bowler Objective function : Maximize – i.e. Constraints Where is the number of overs remaining for the jth bowler against ‘k’ batsmen and the total number of overs remaining to be bowled is N then or The overs that any bowler can bowl is
C) Optimized bowling lineup
a) IPL – Optimizing bowling line up
Note: For computing the Optimal bowling lineup, the total number of overs remaining and the number of overs for each bowler have to be entered.
b) PSL – Optimizing batting line up
d) Optimized batting lineup
a) Intl. T20 (men) India vs England
b) Carribean Premier League – Optimizing batting line up
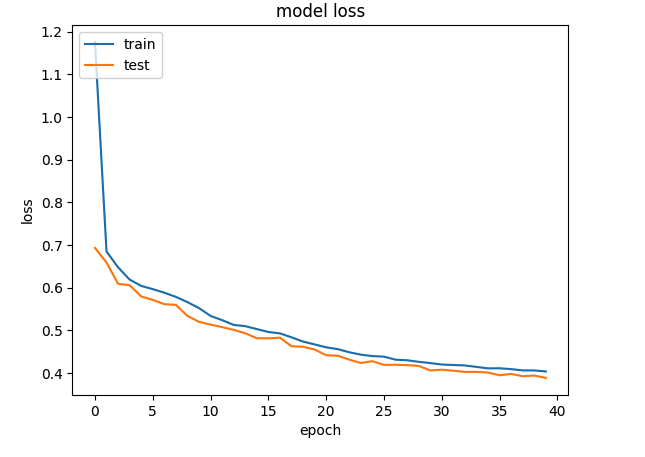
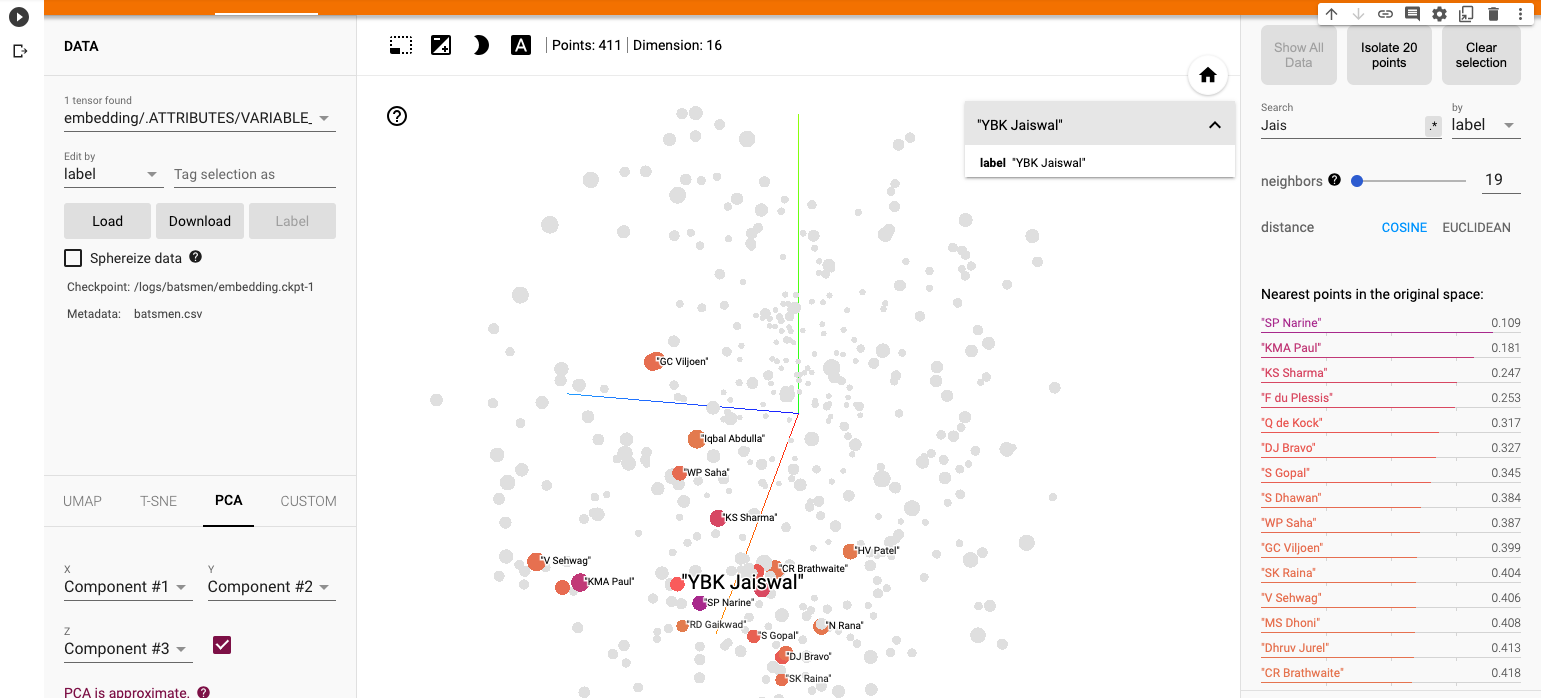
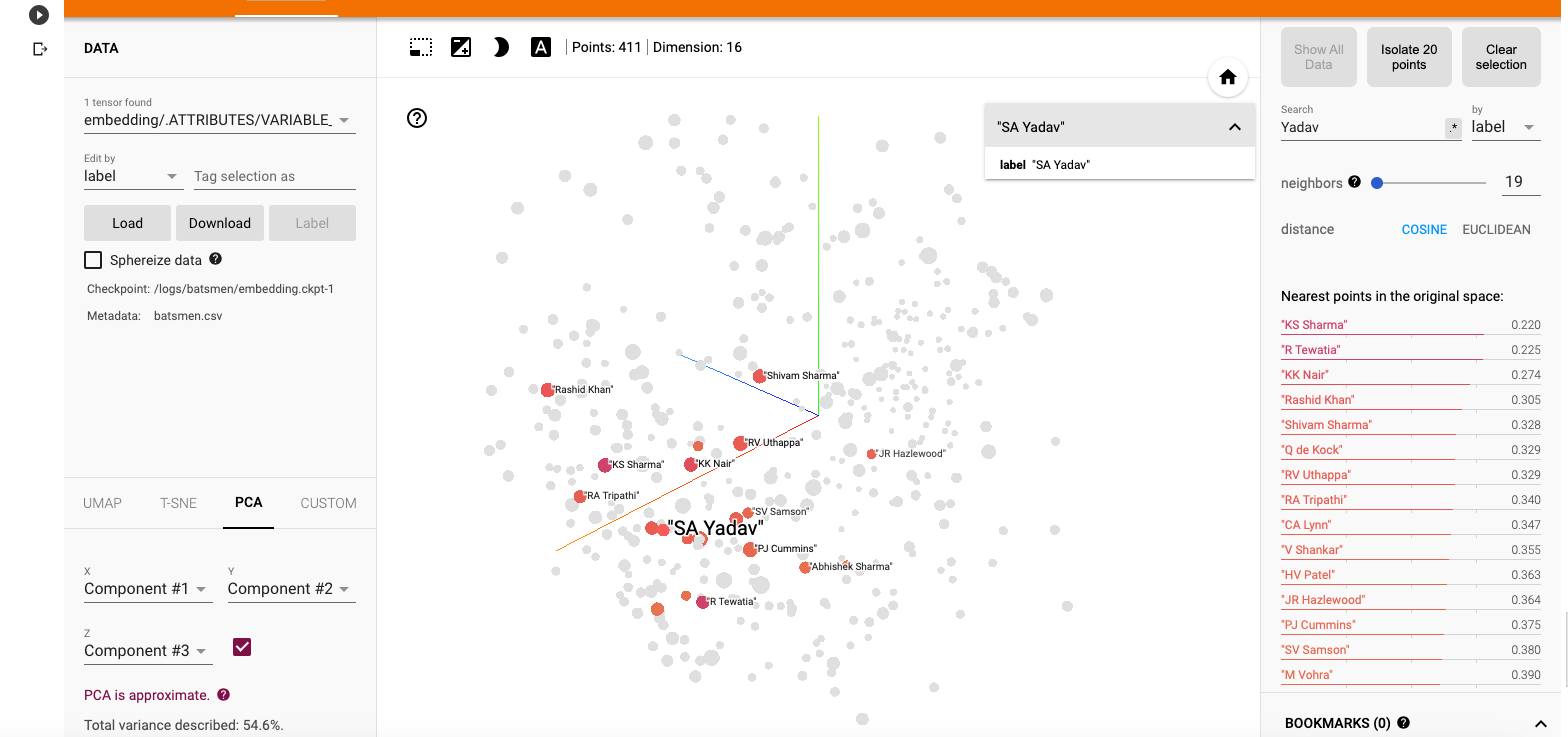
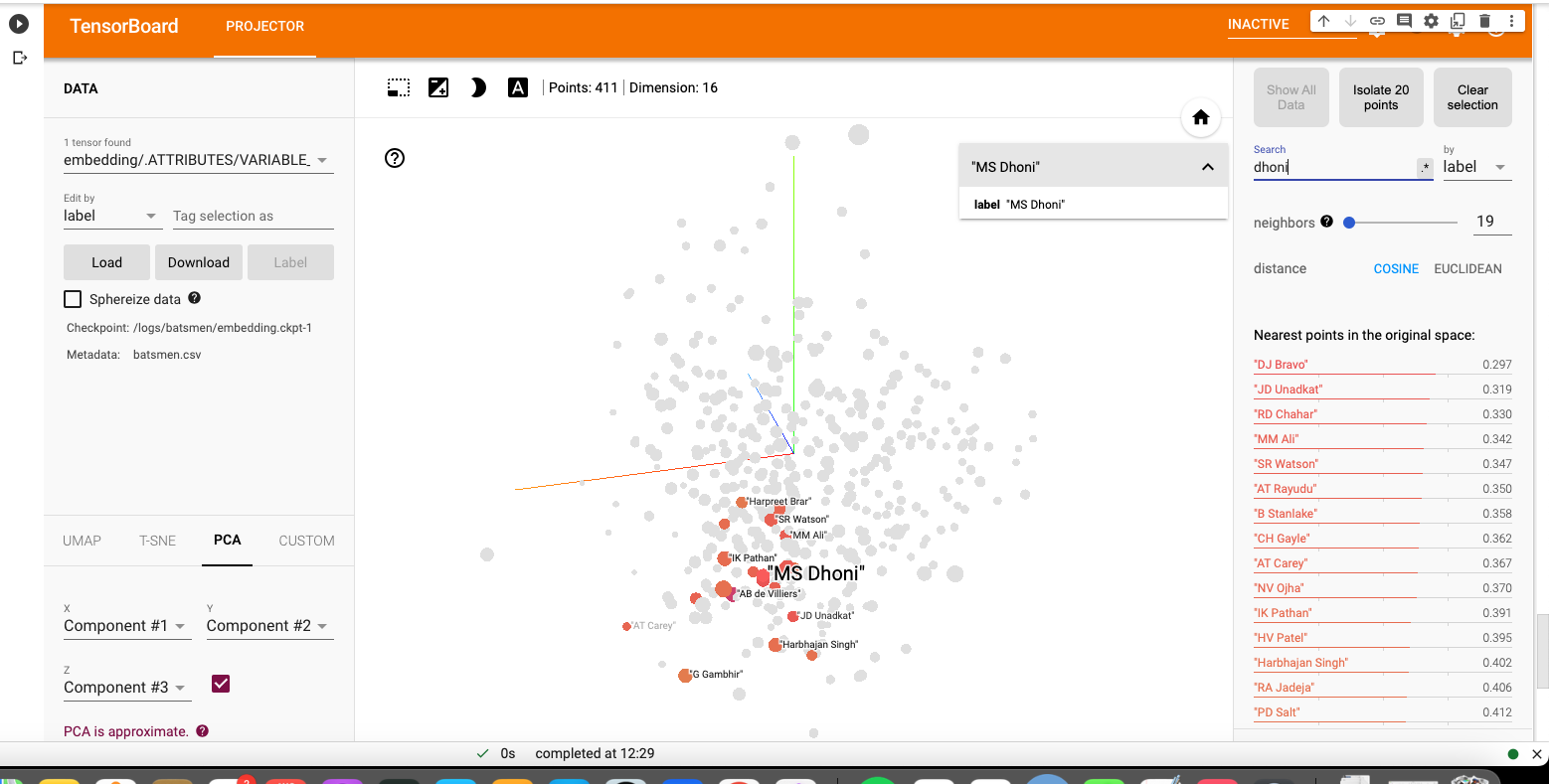
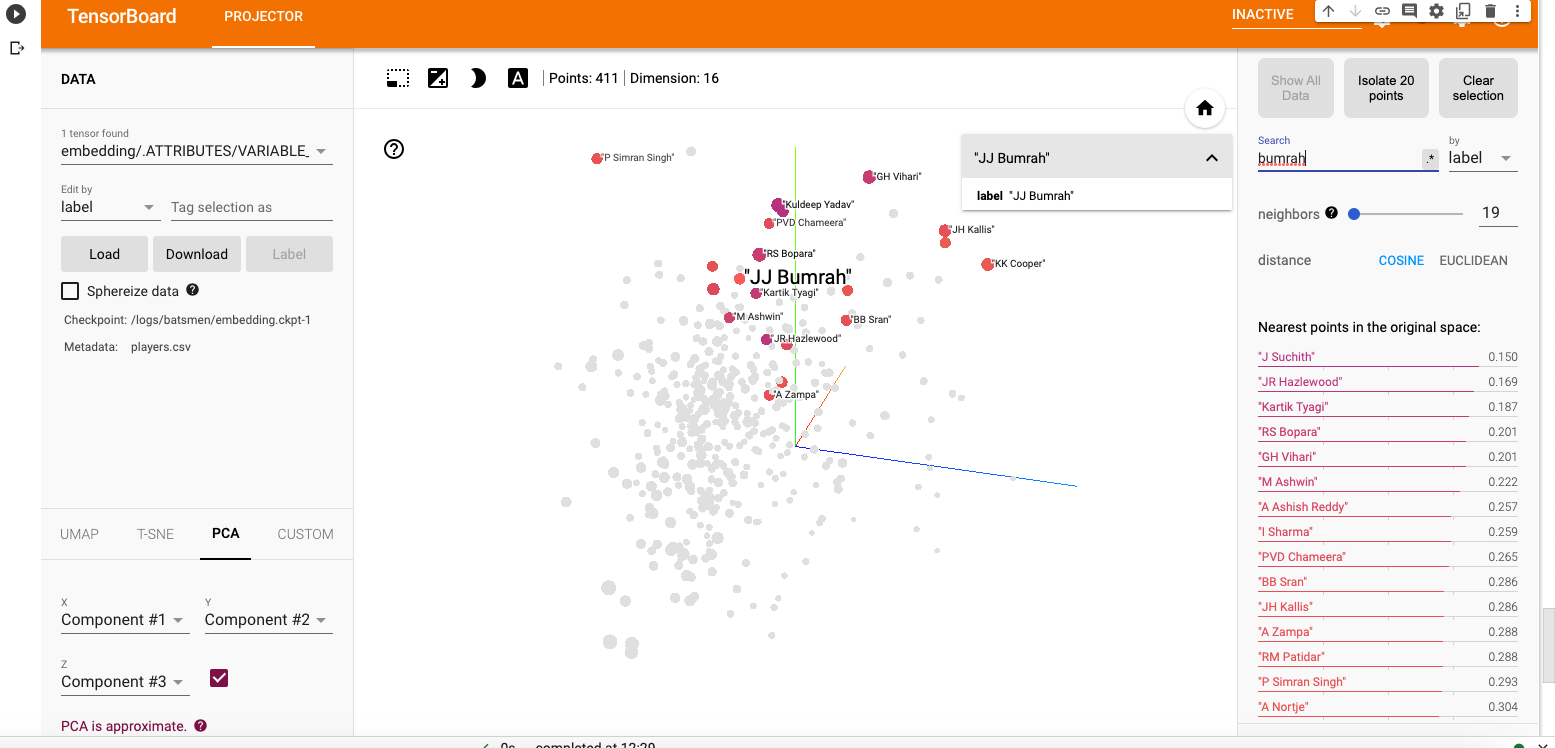
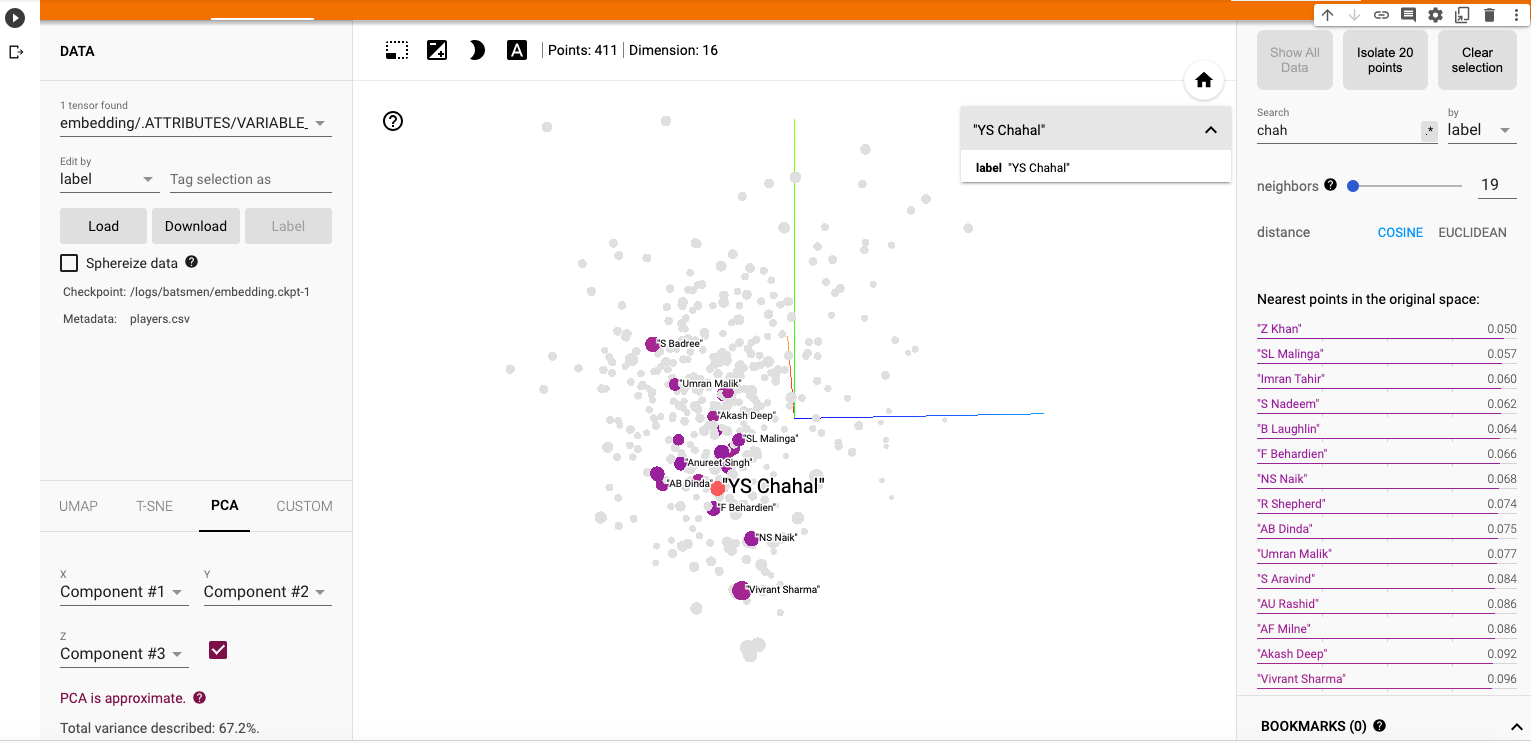

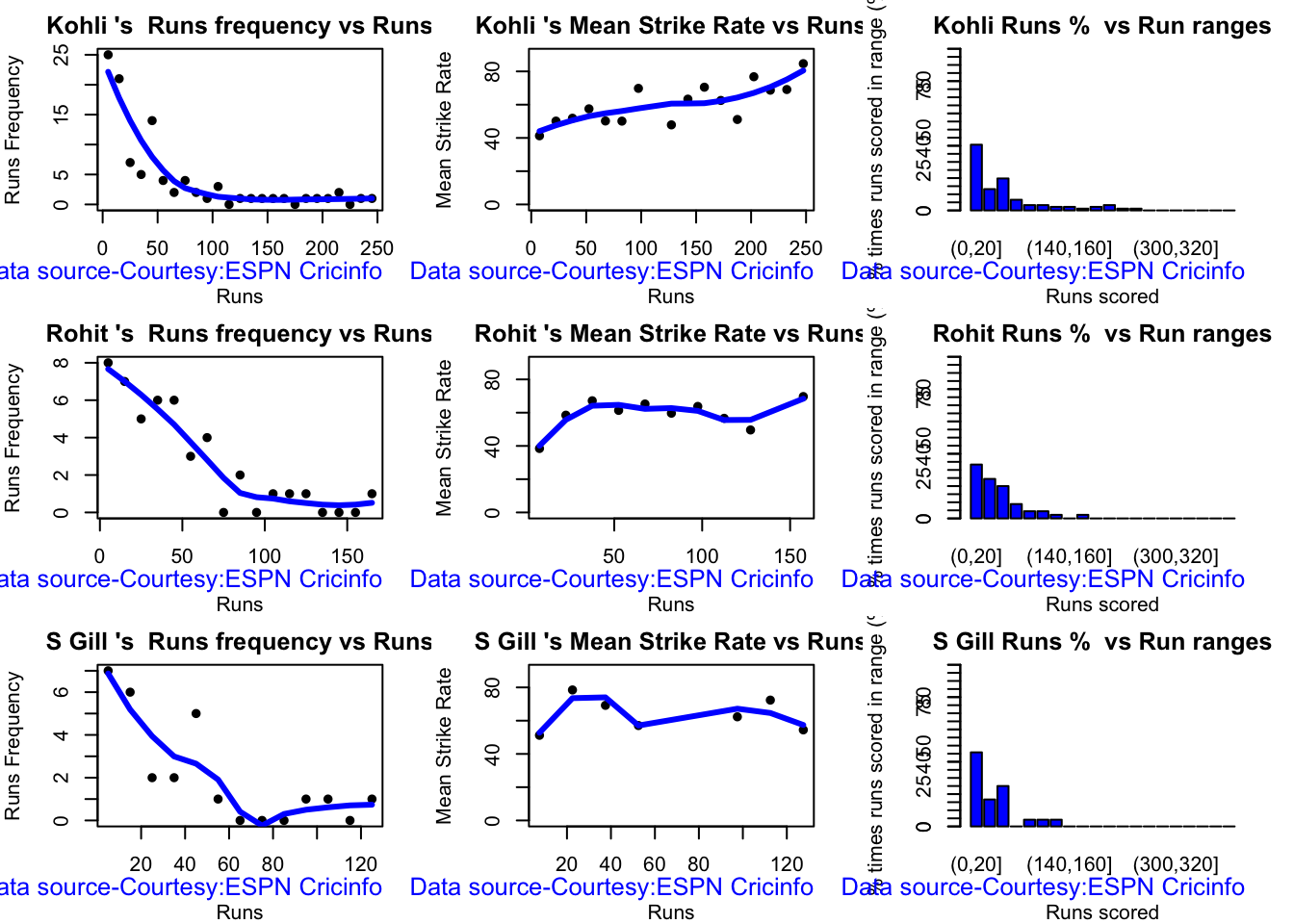
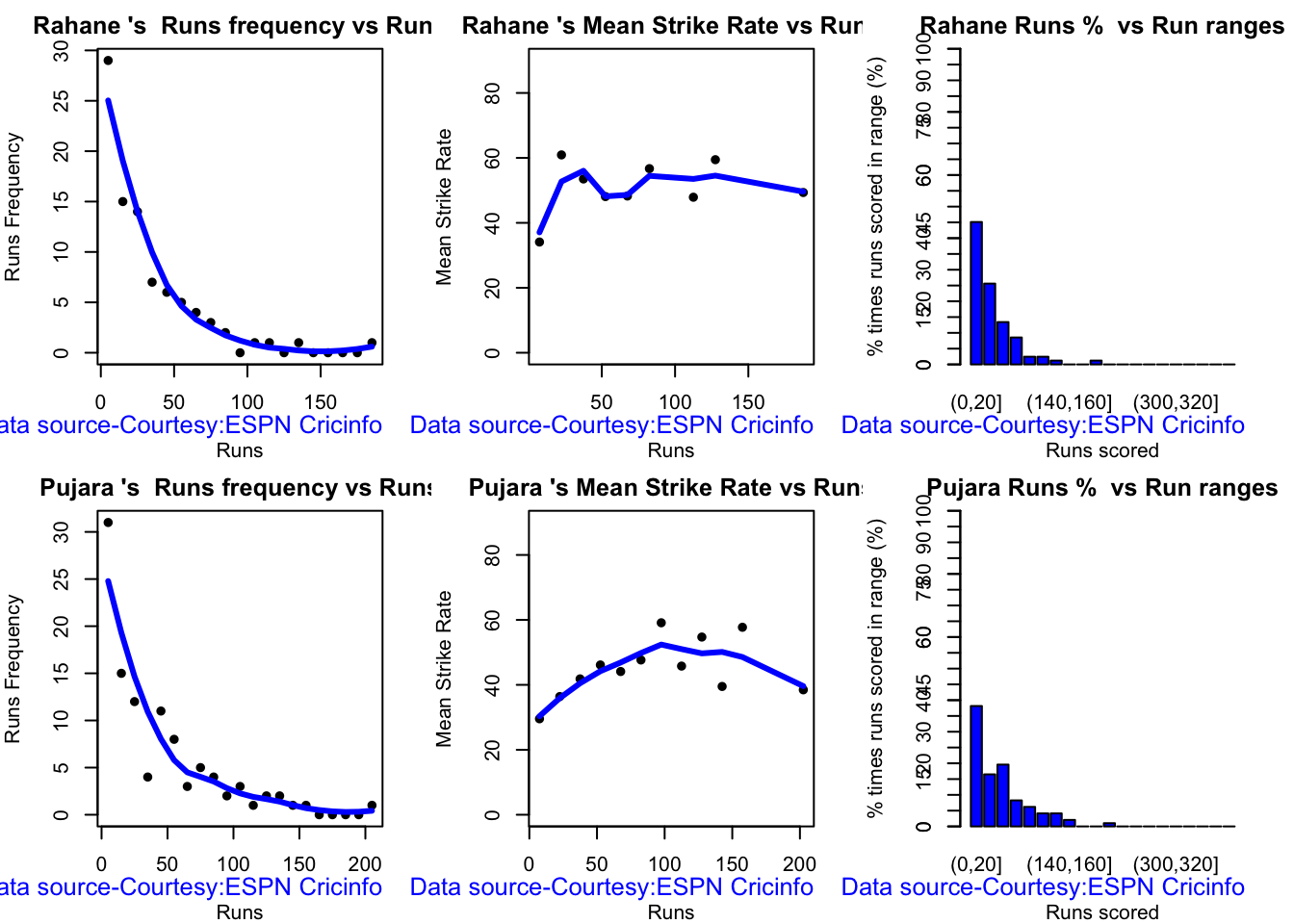


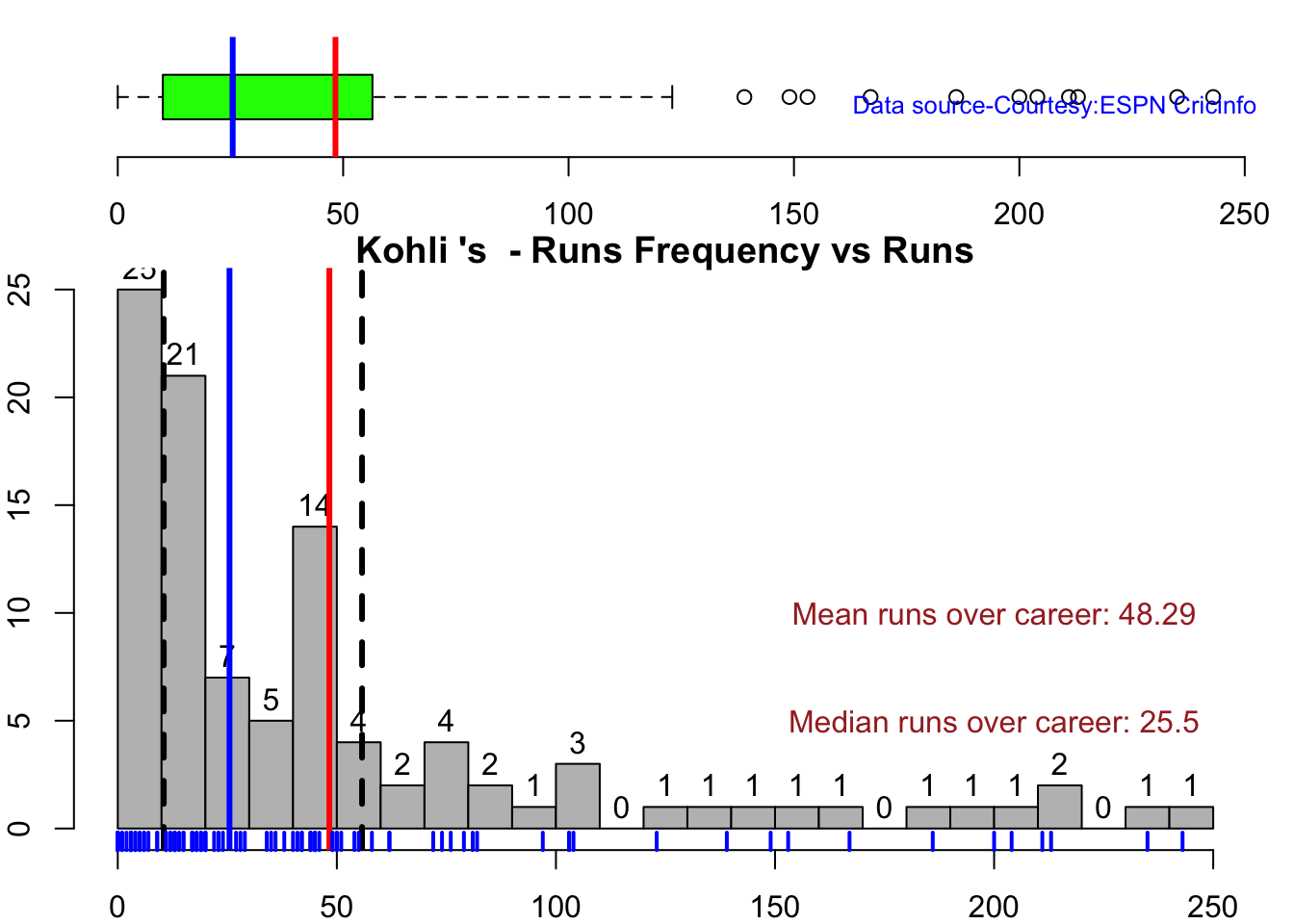
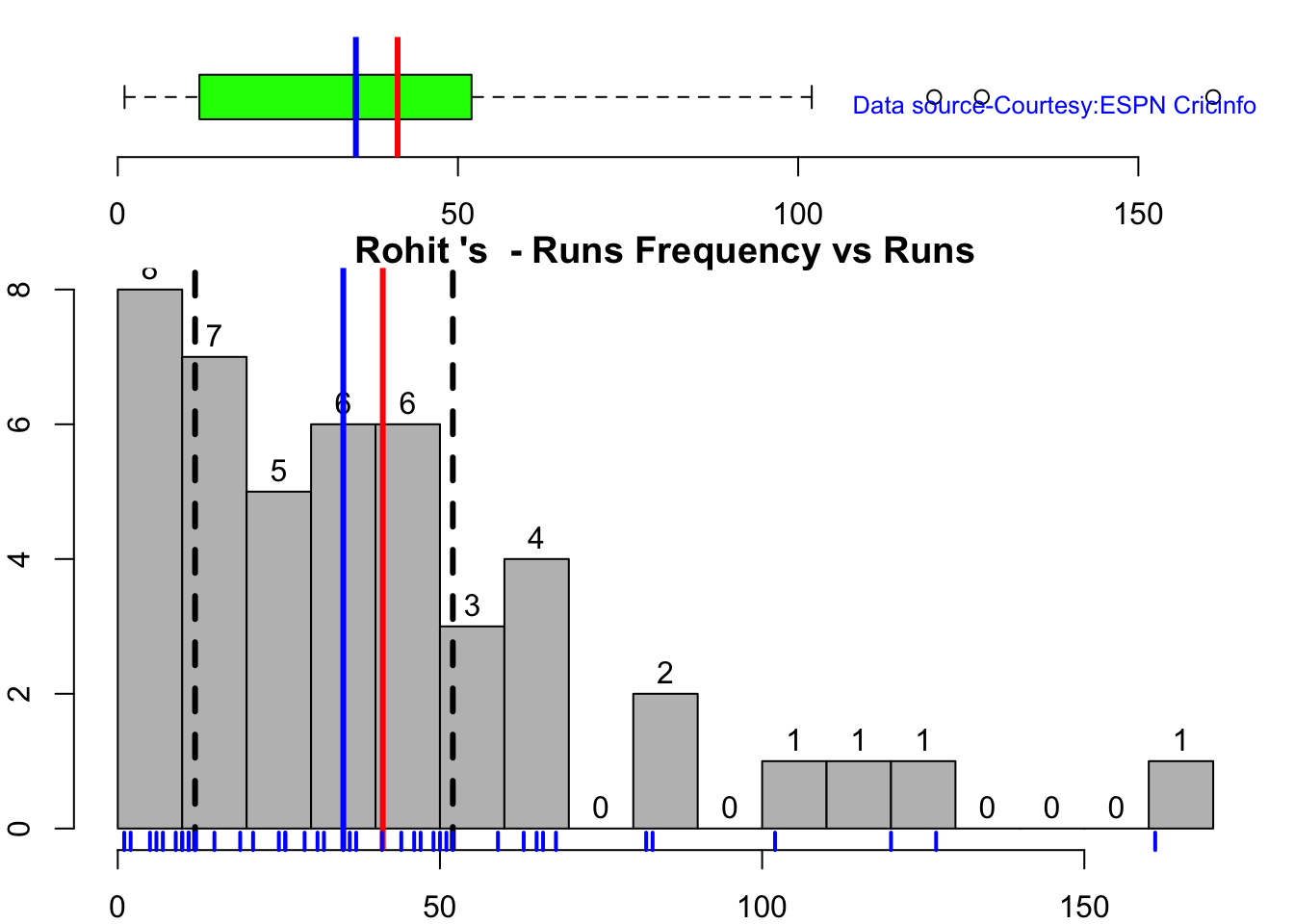
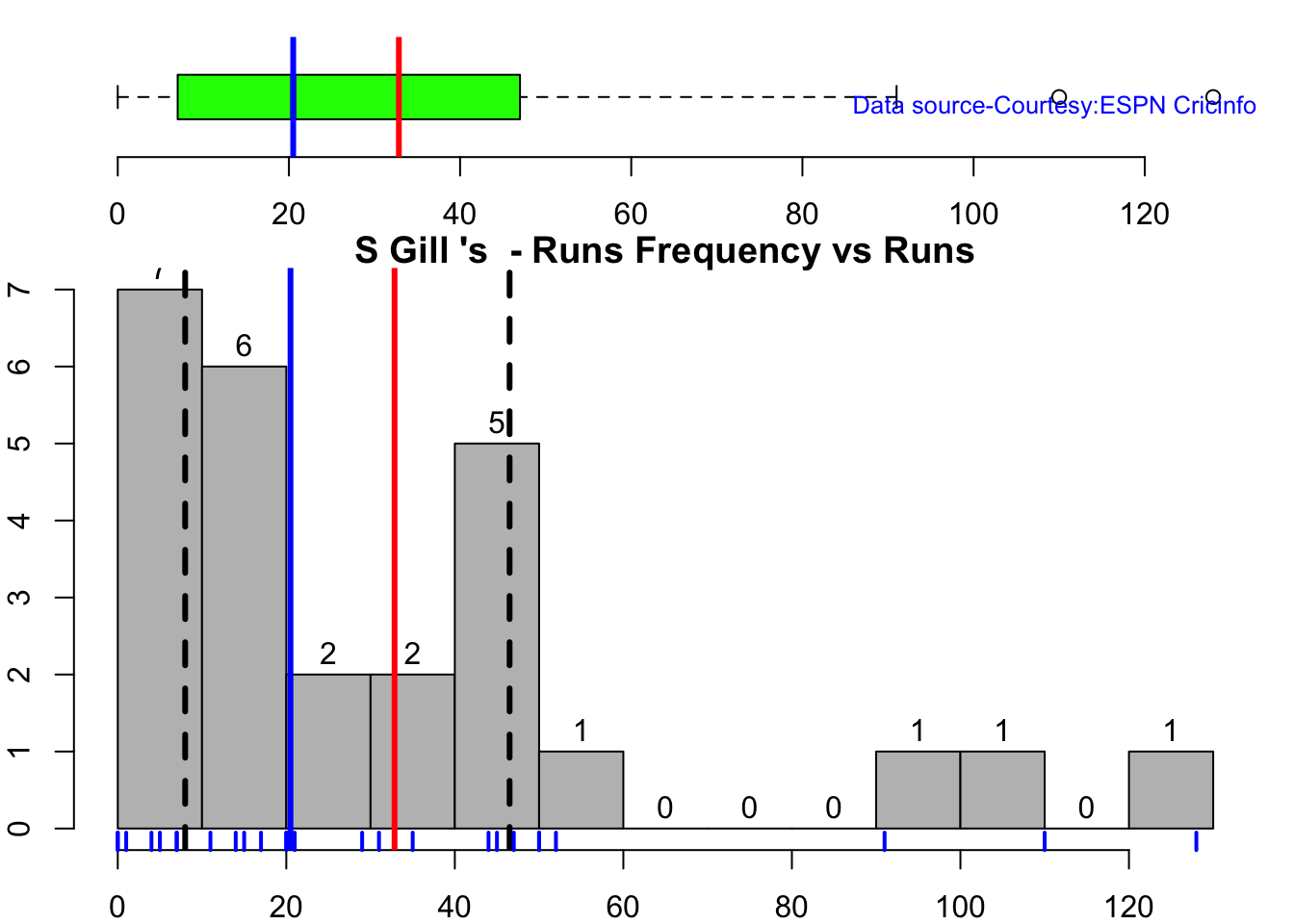
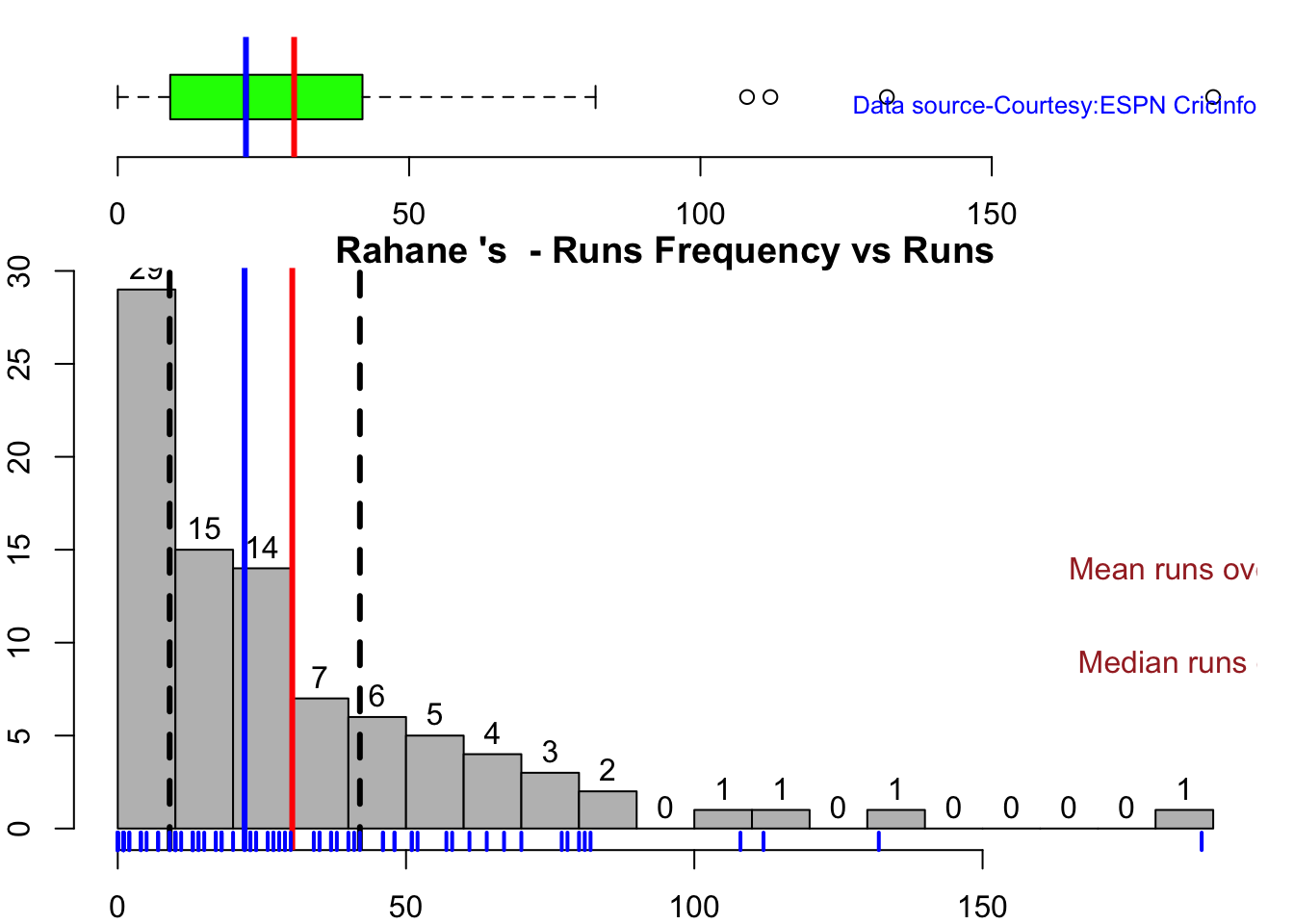
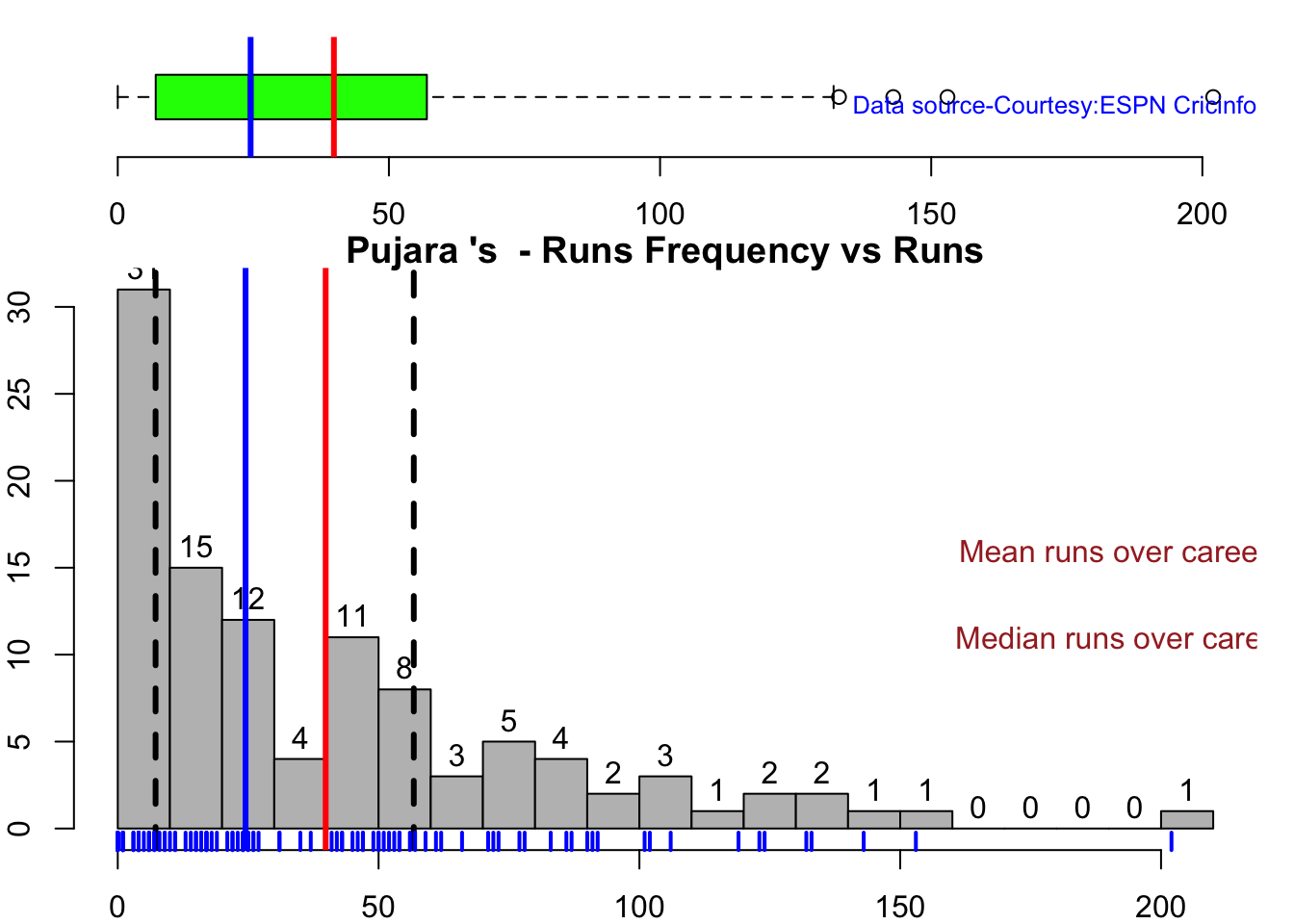


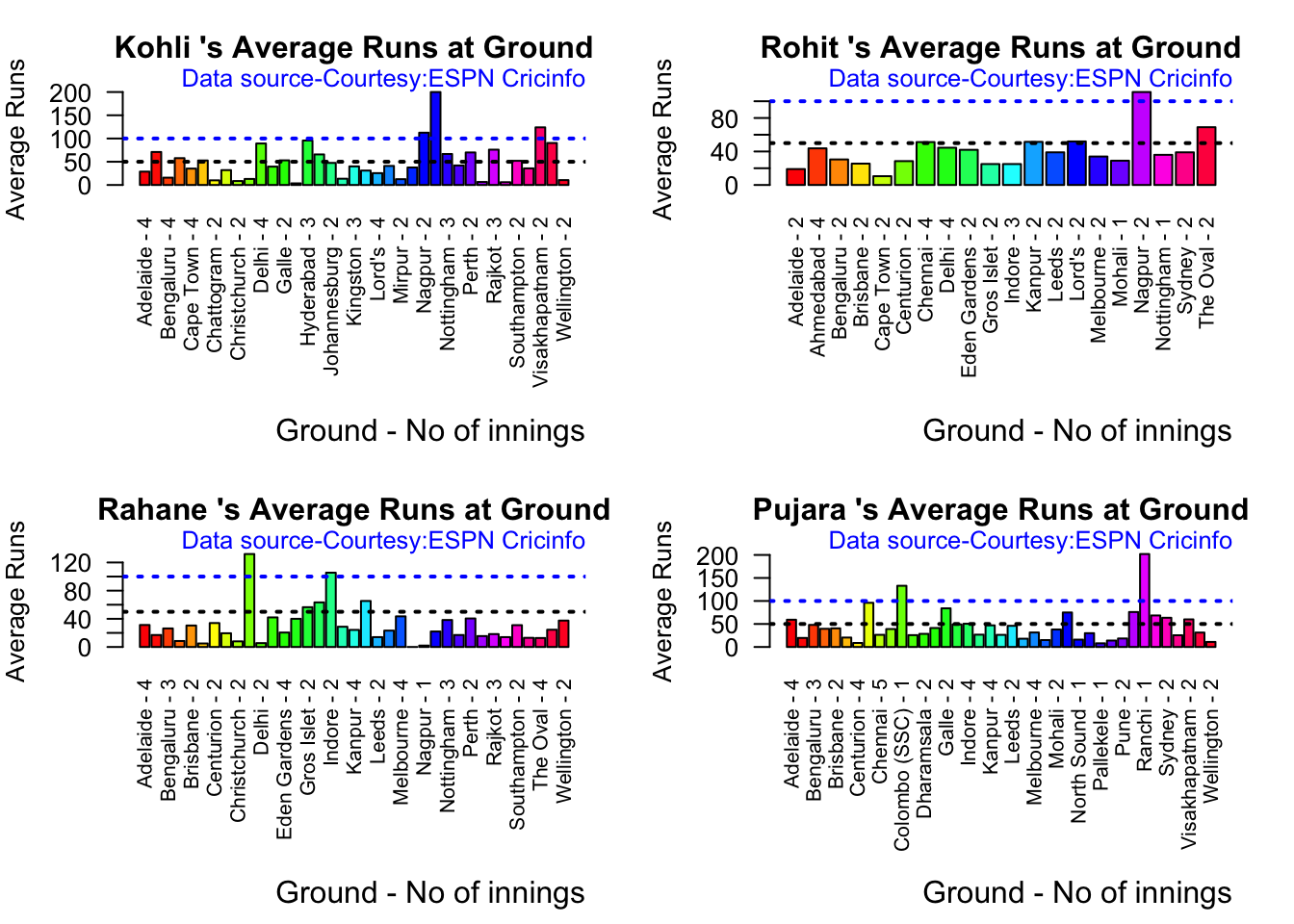

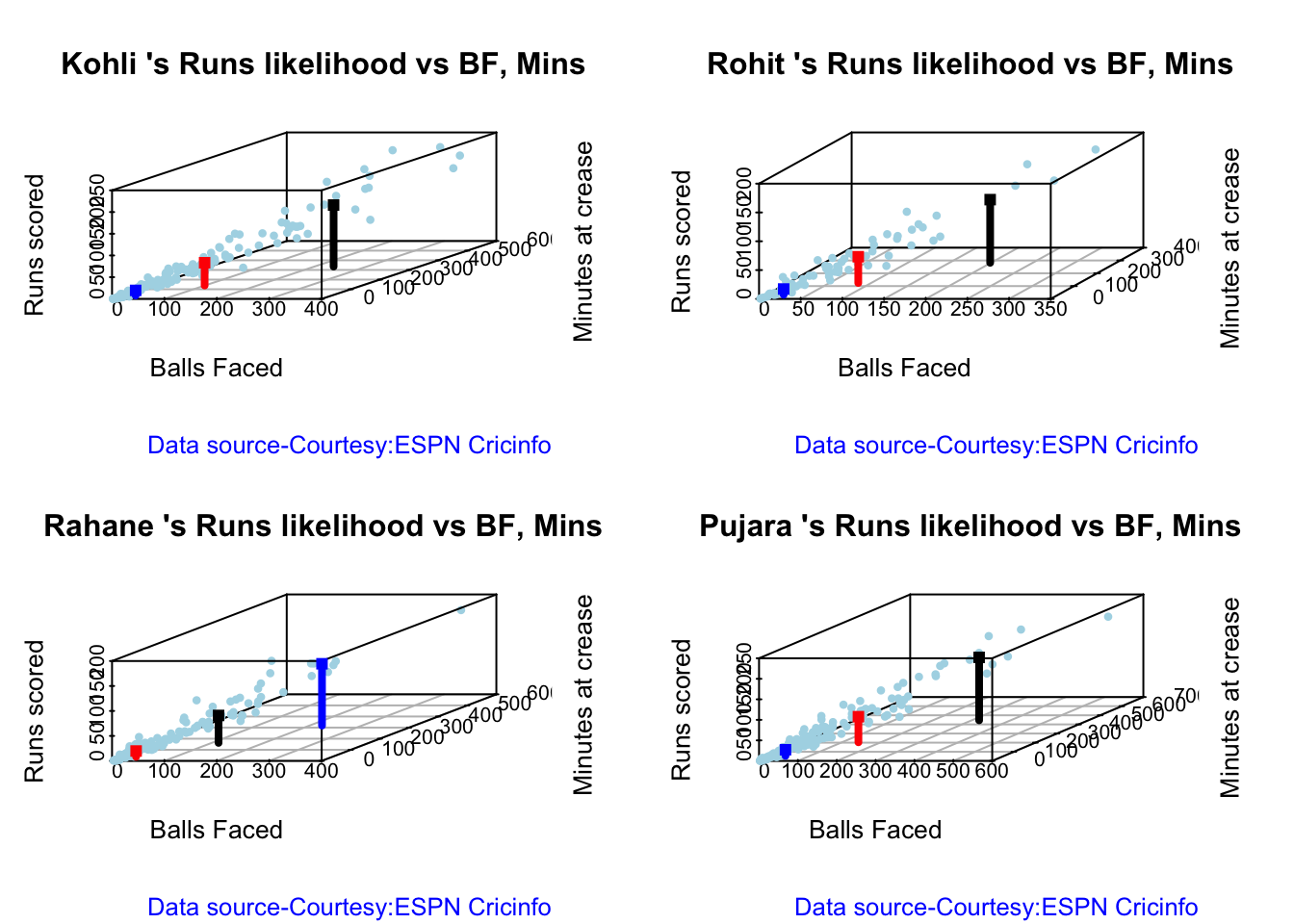
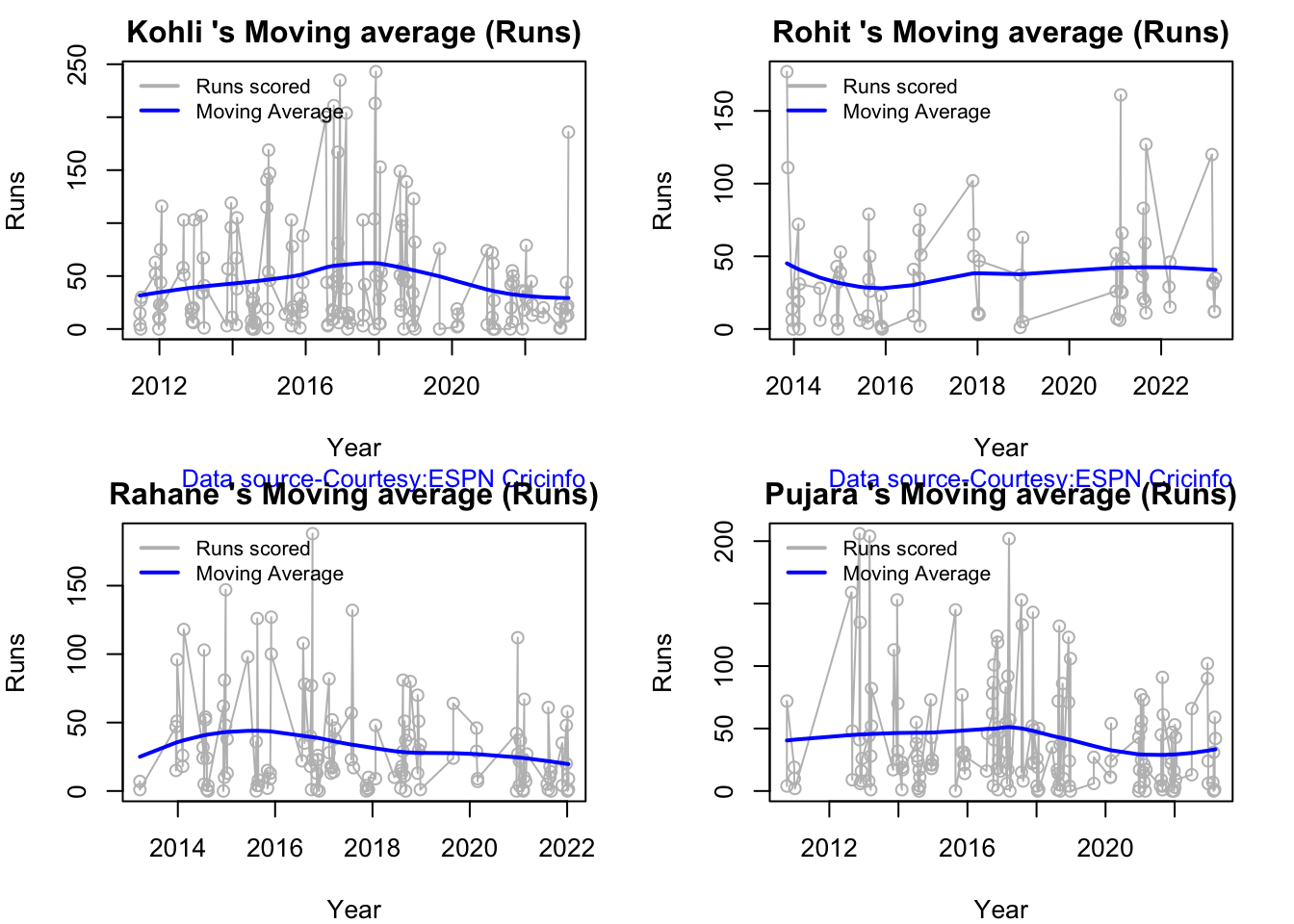
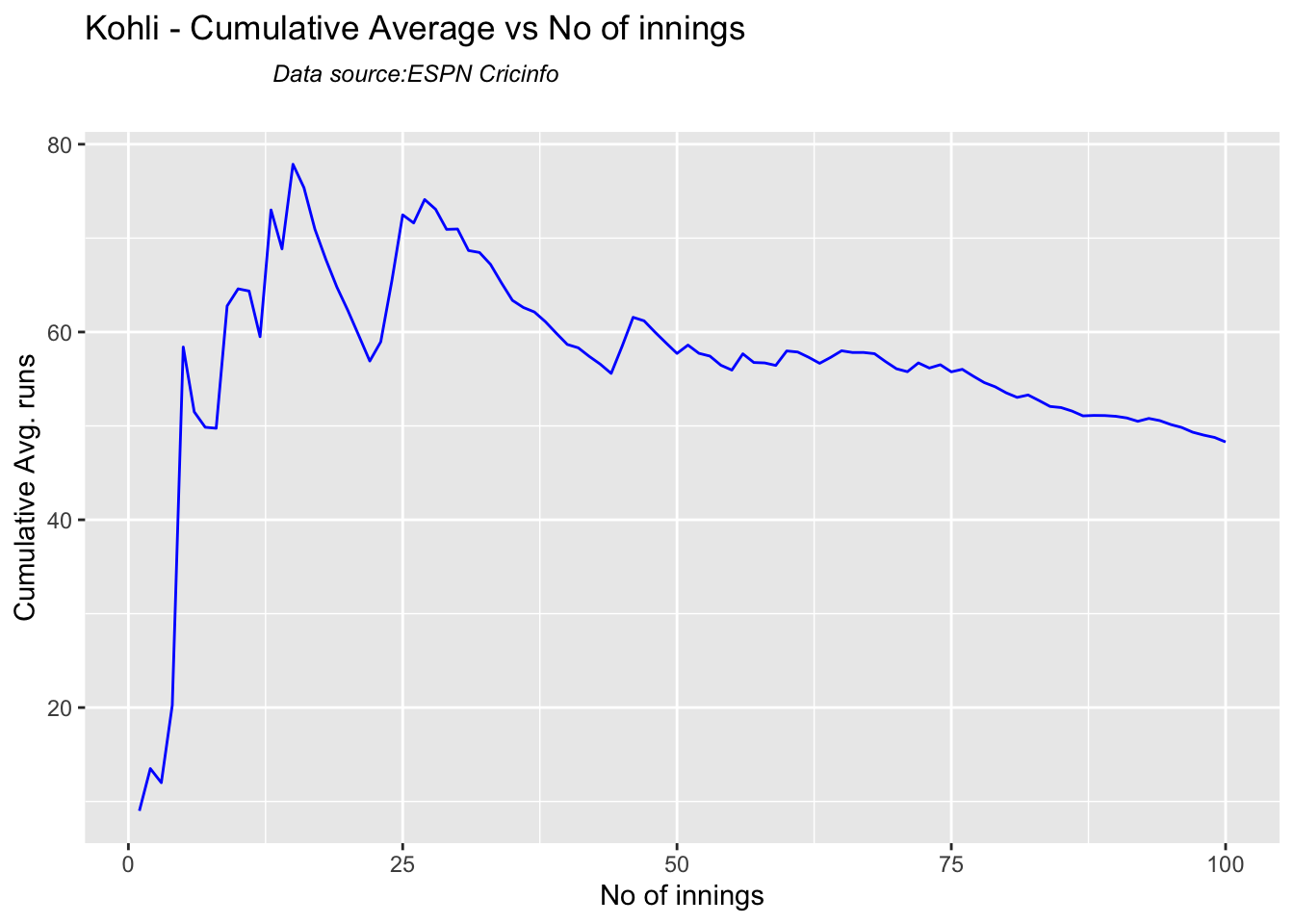




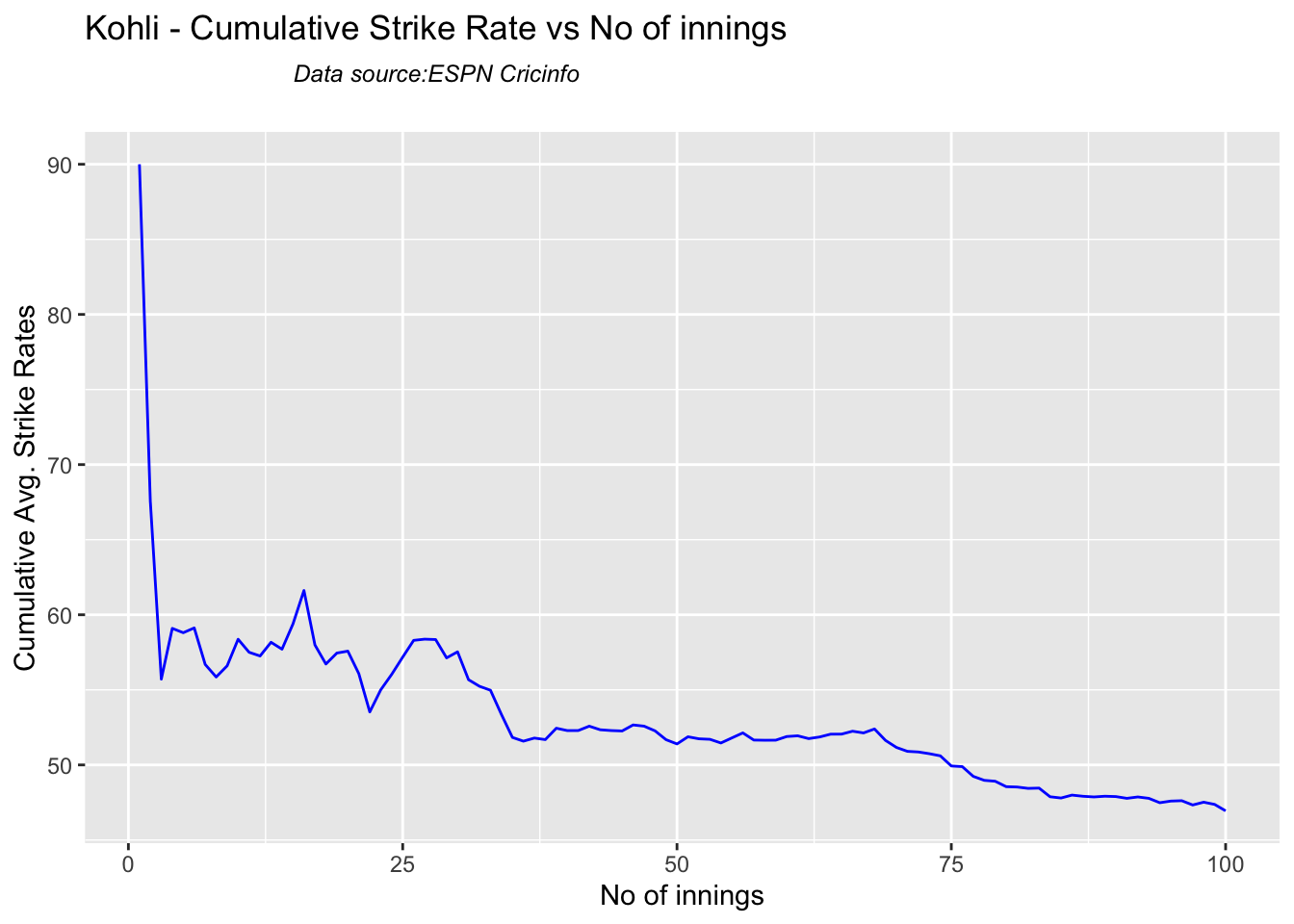
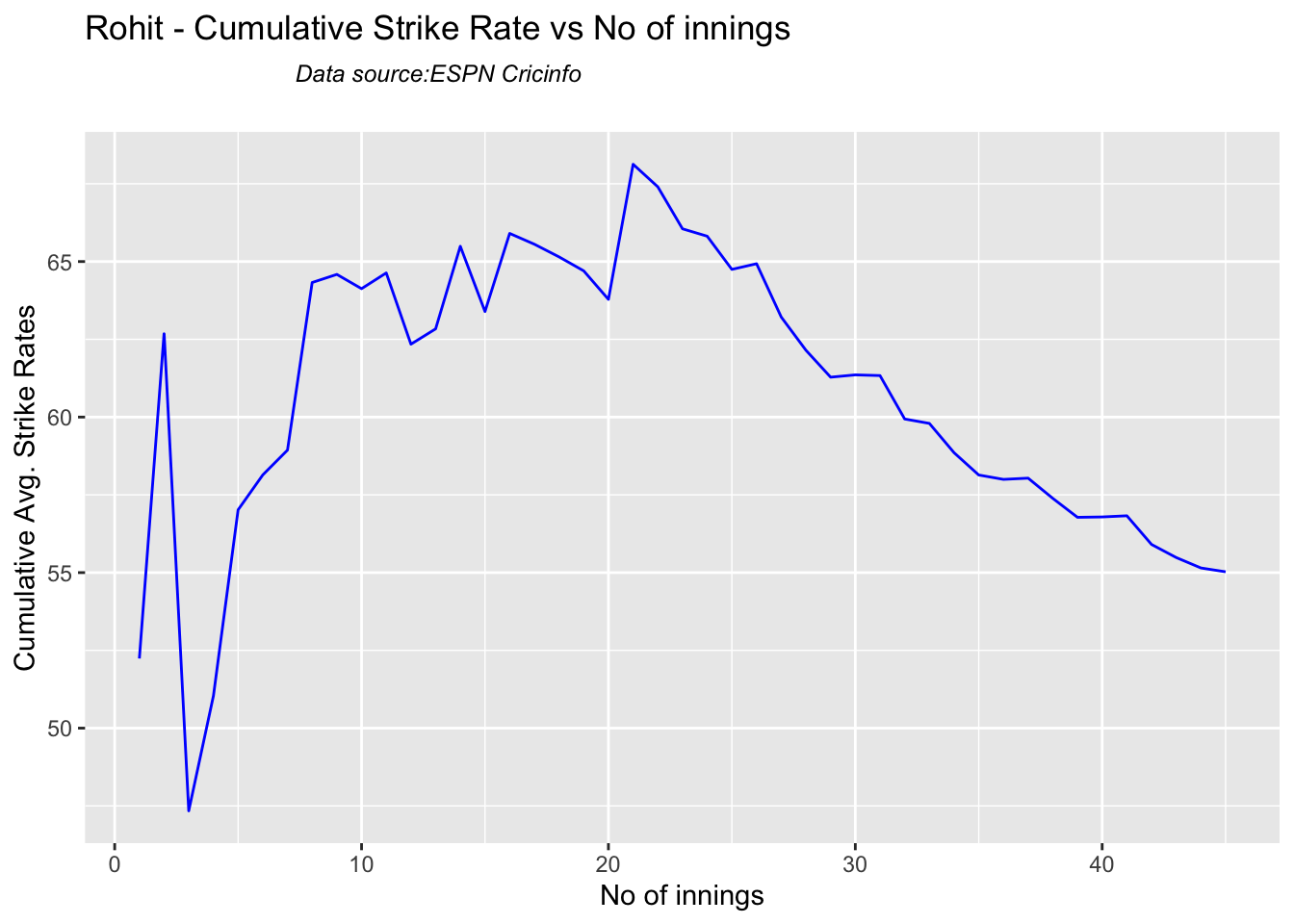



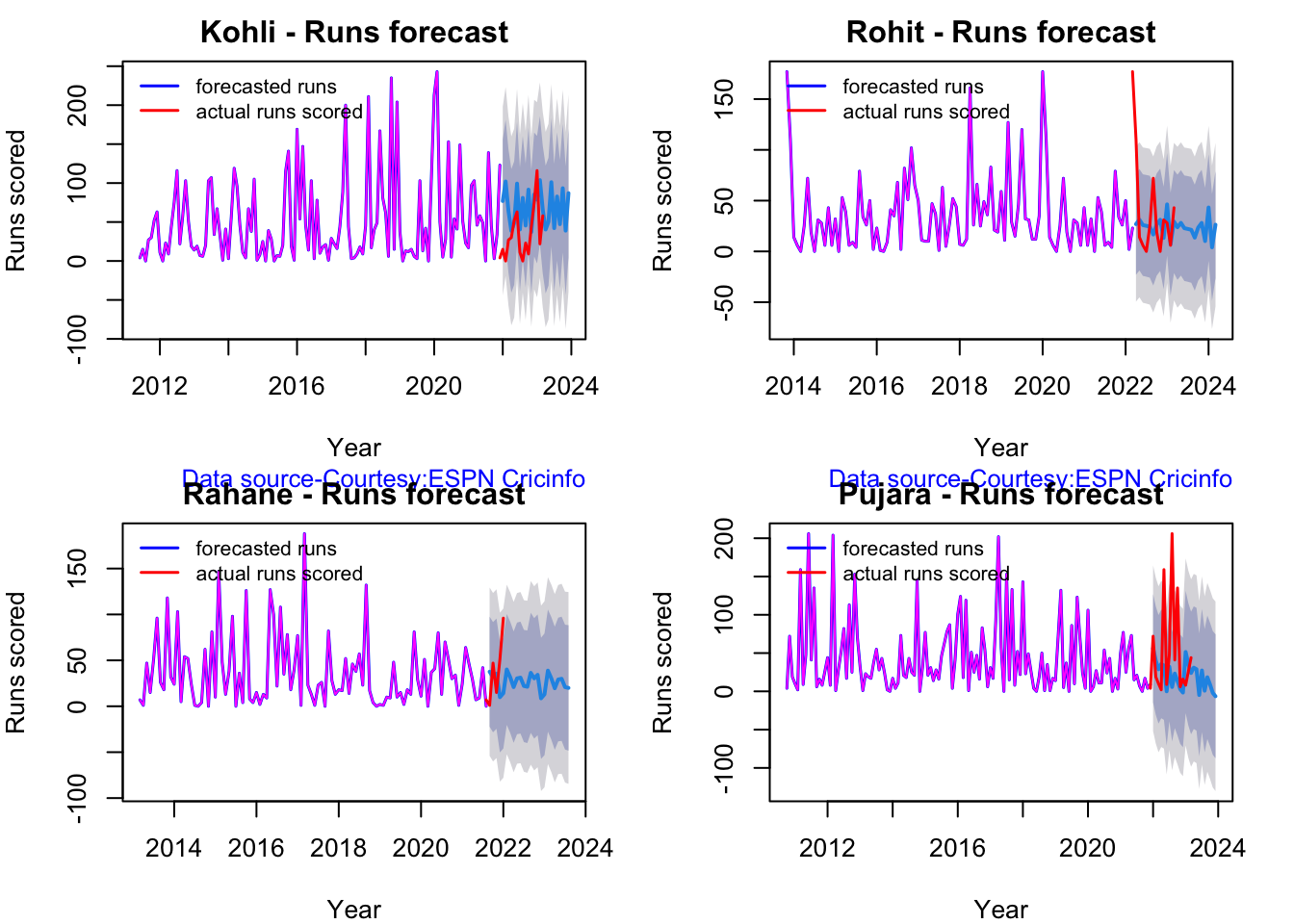
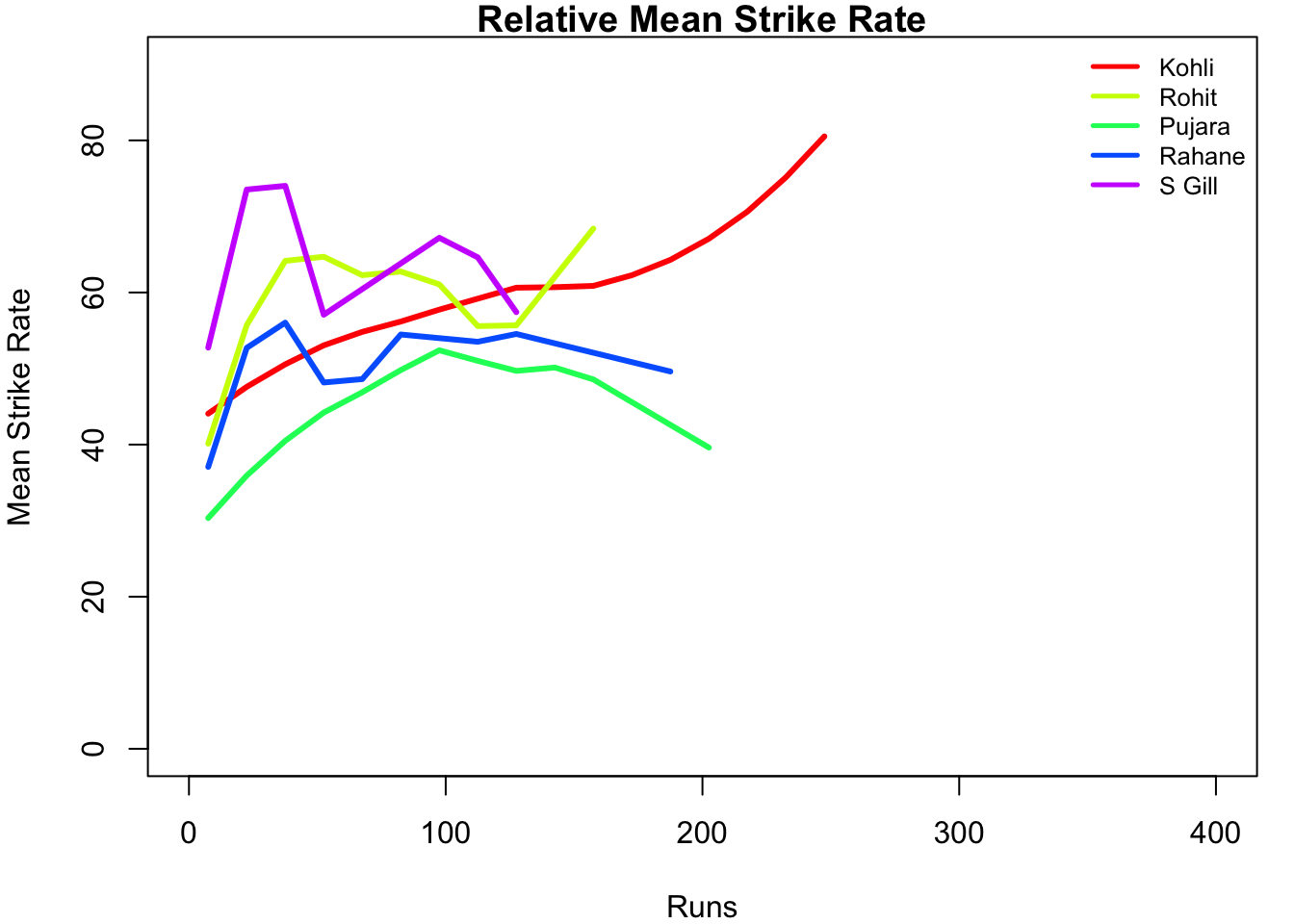
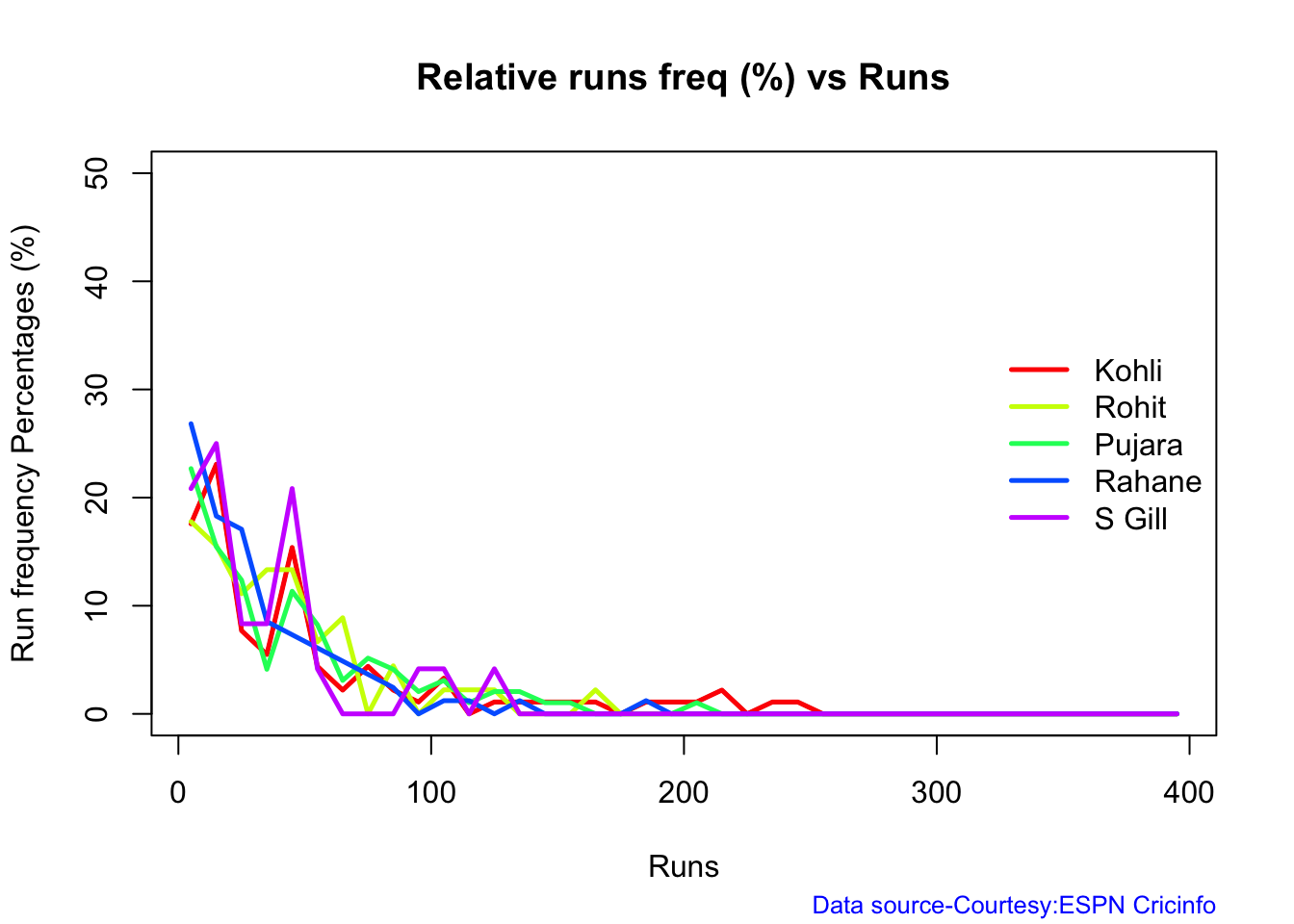

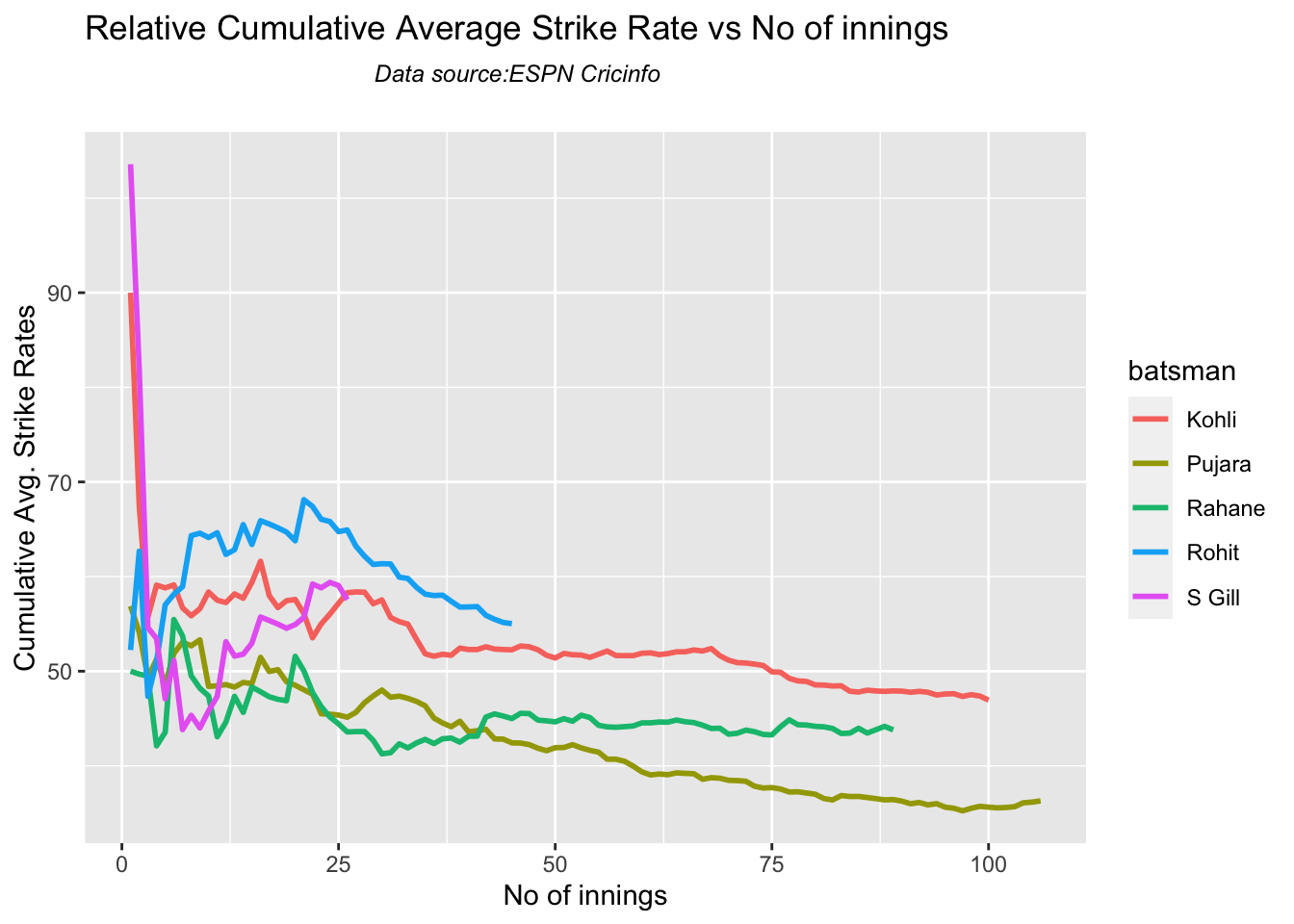
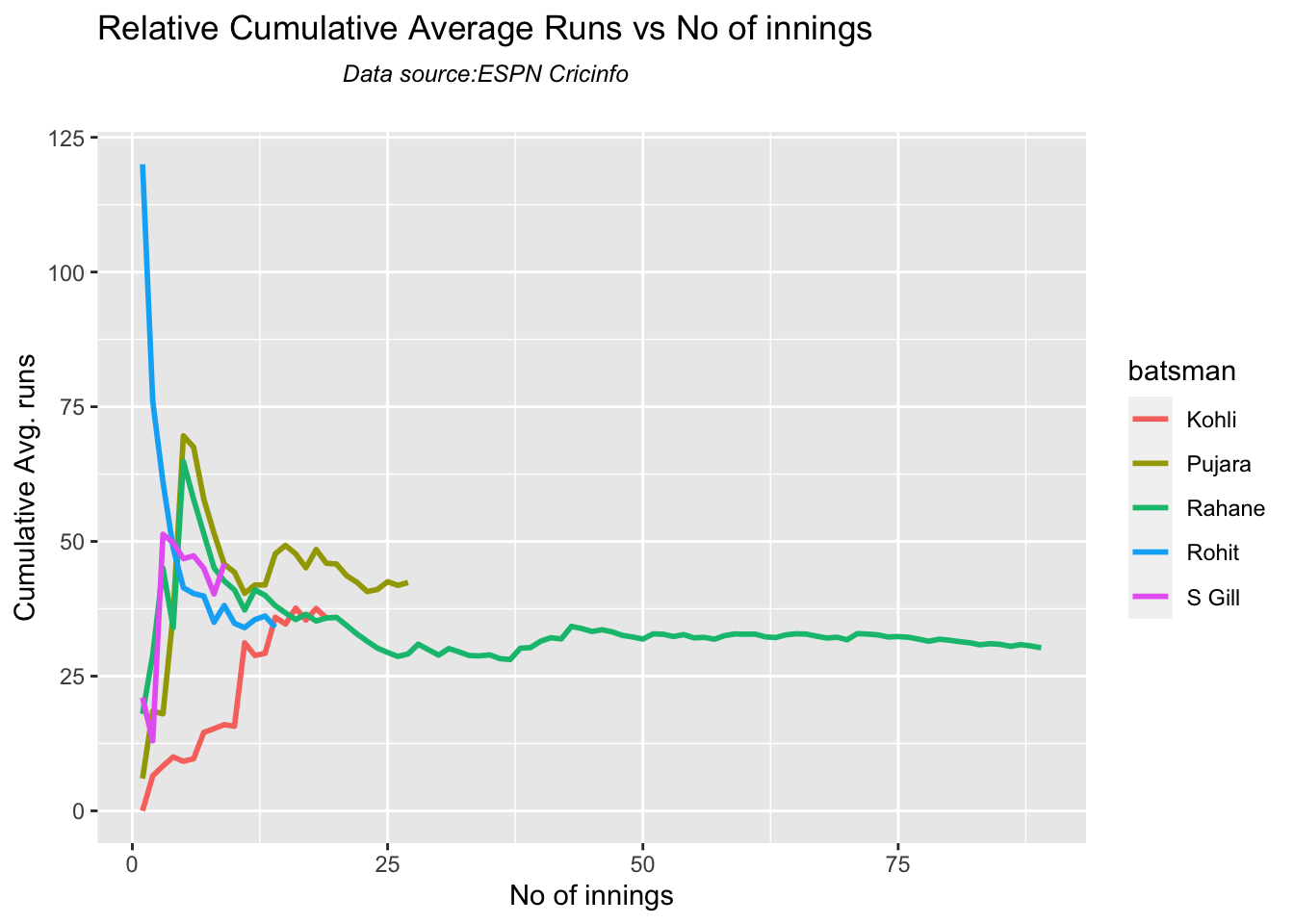

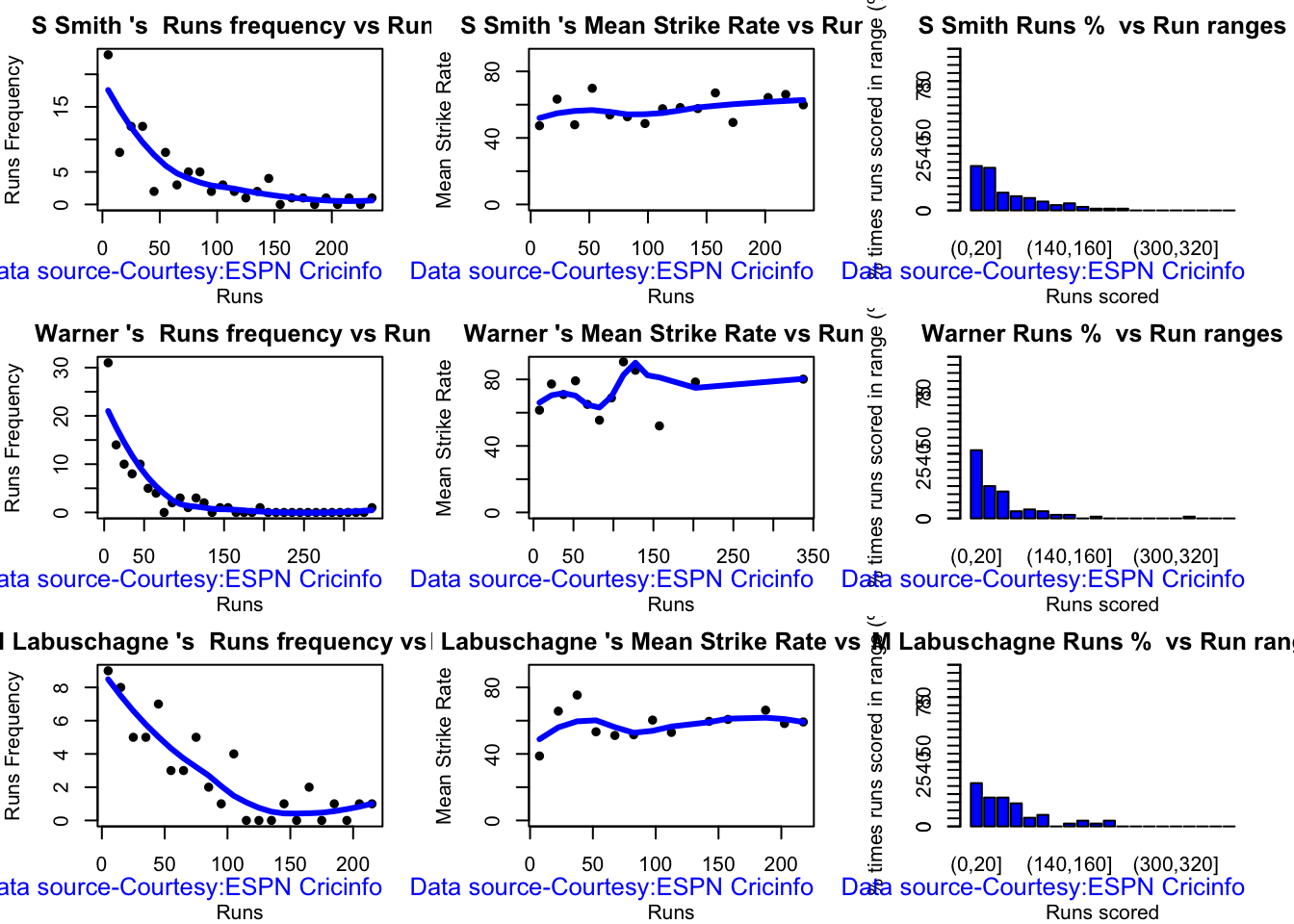




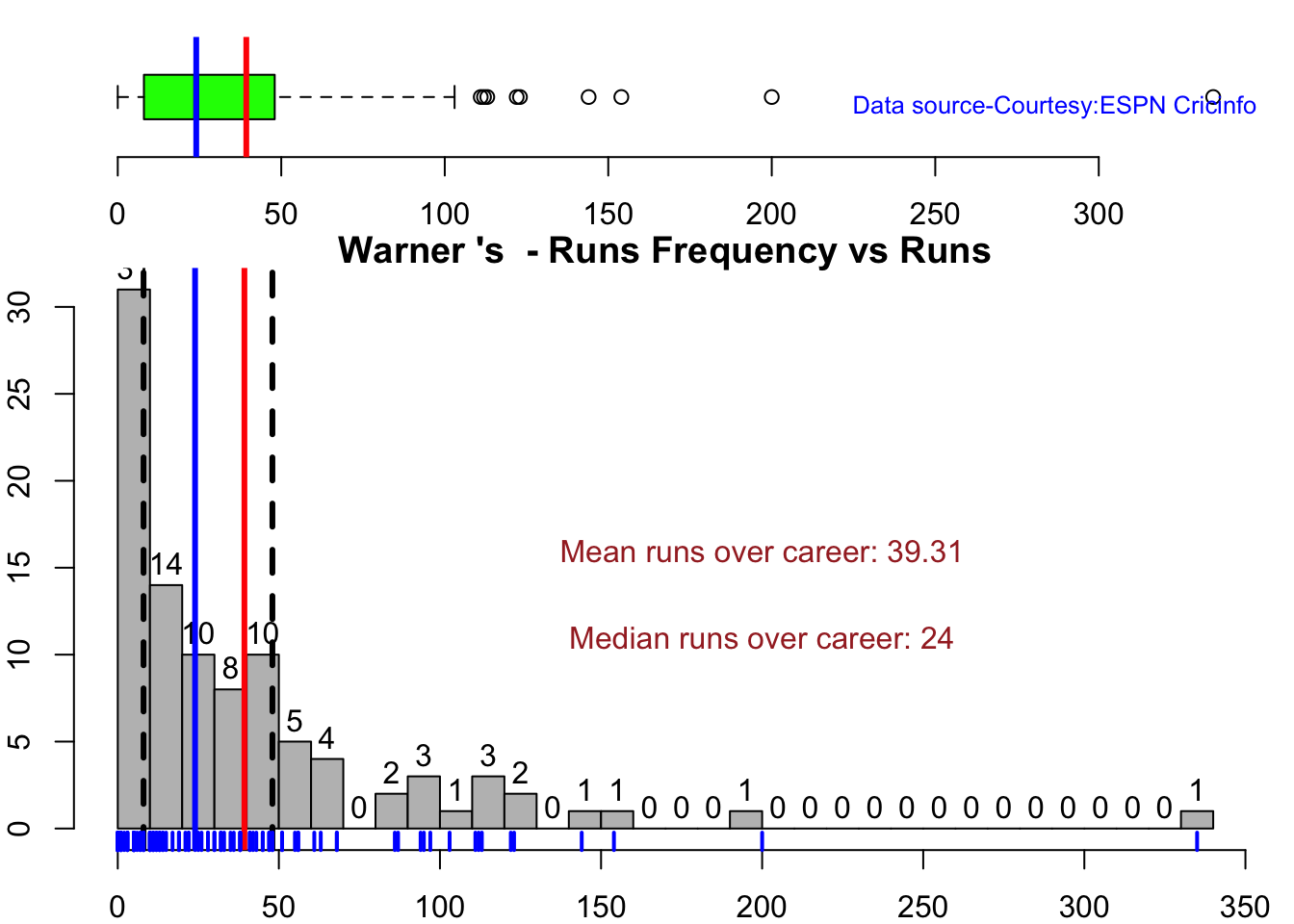
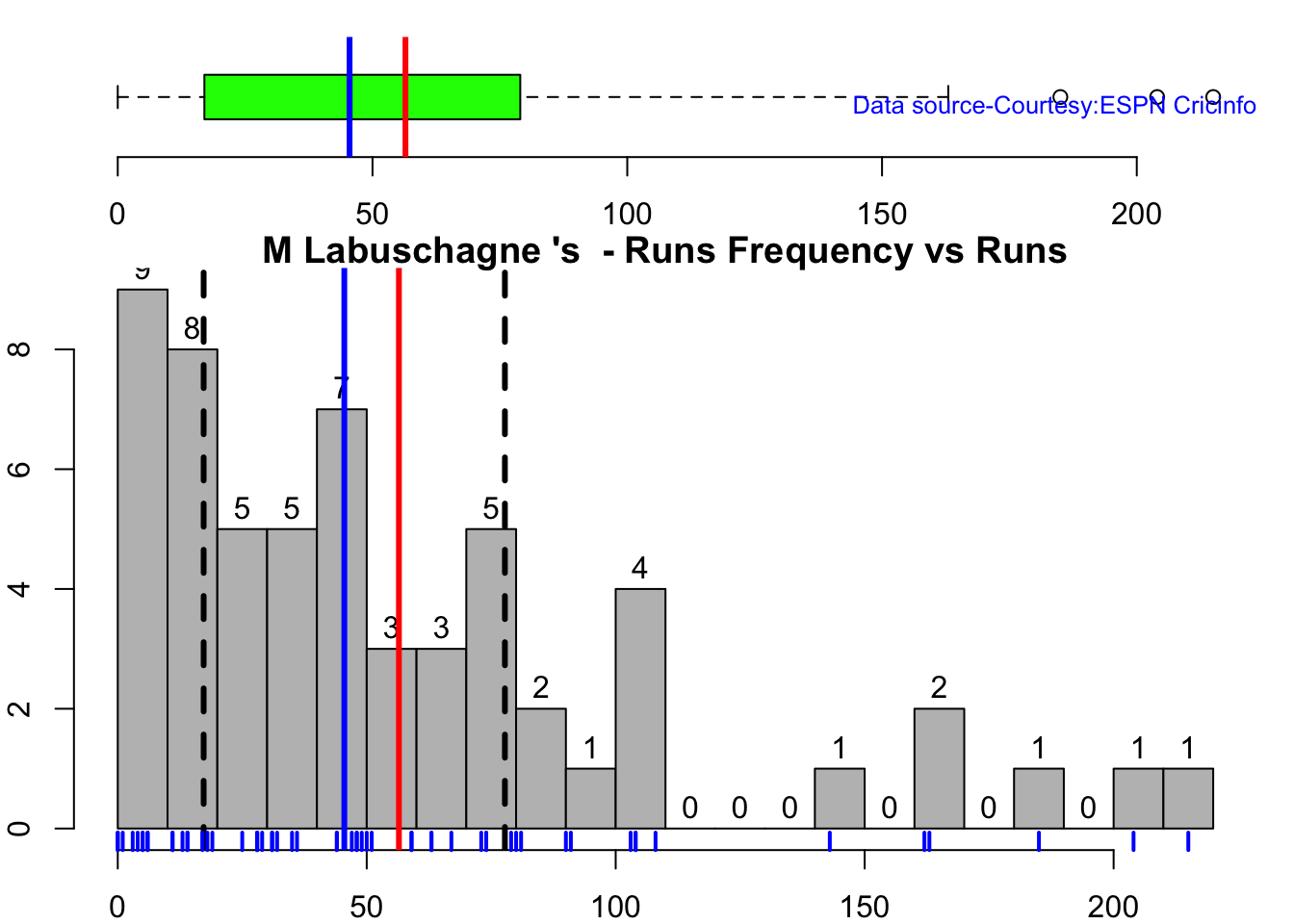



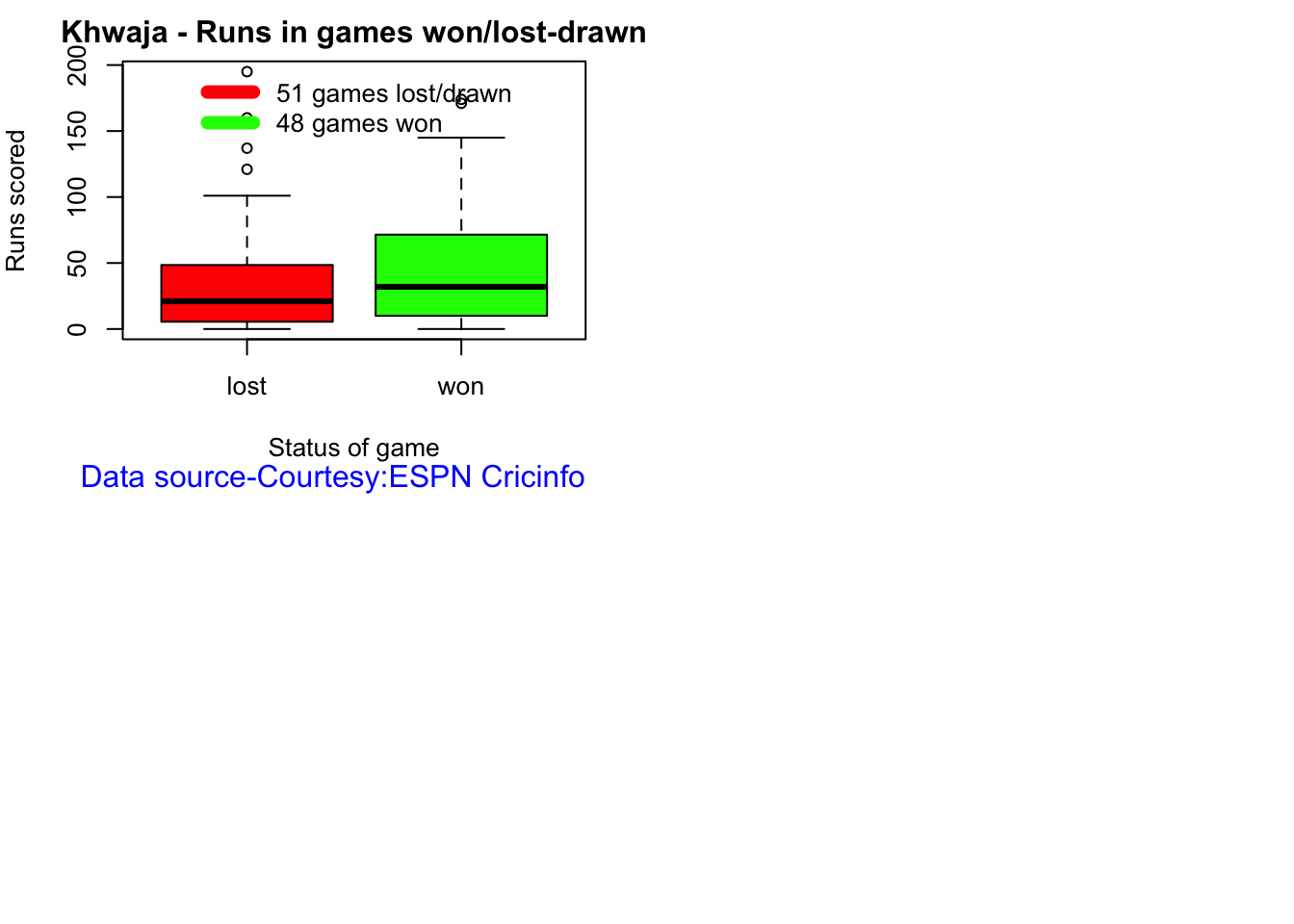


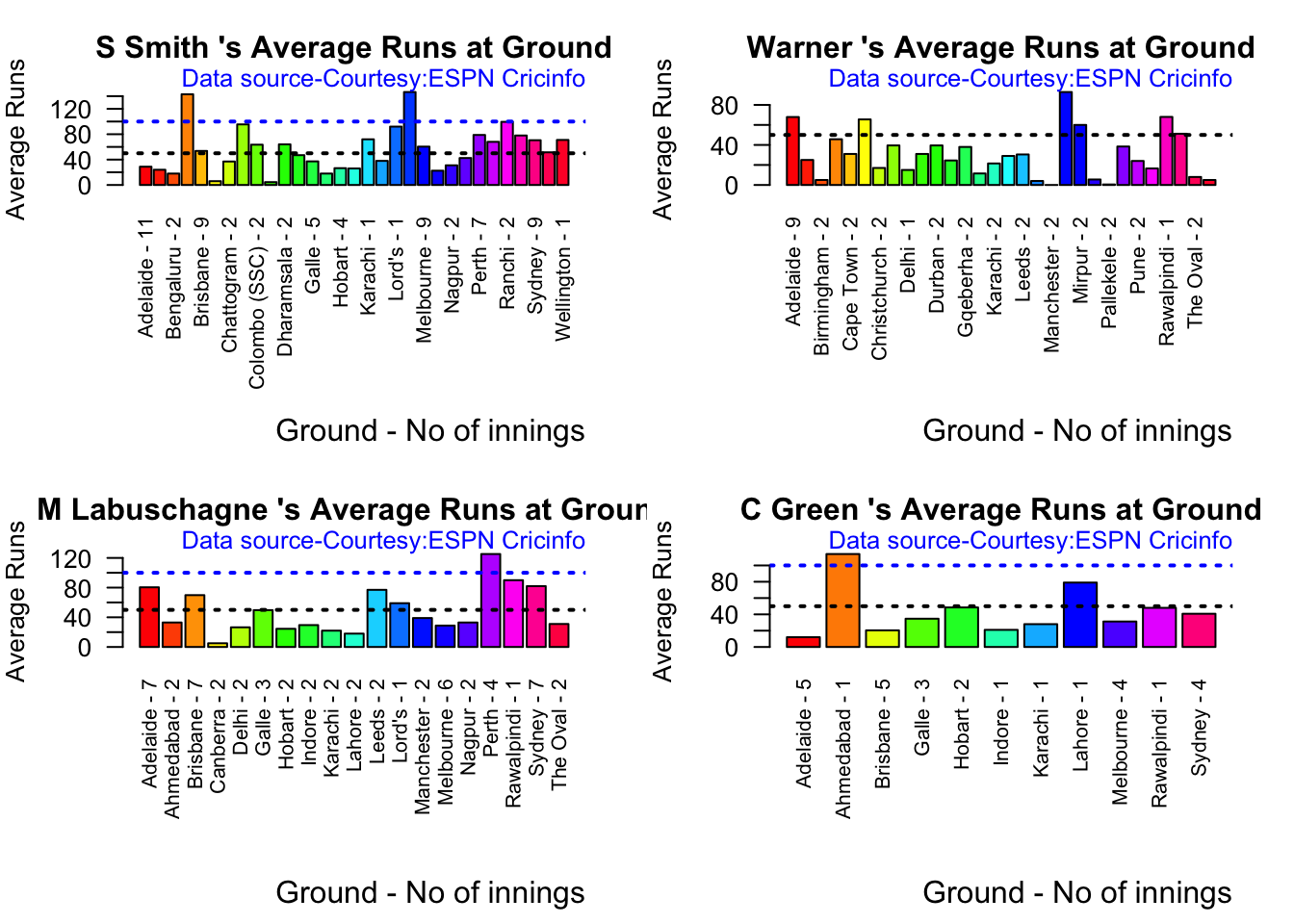


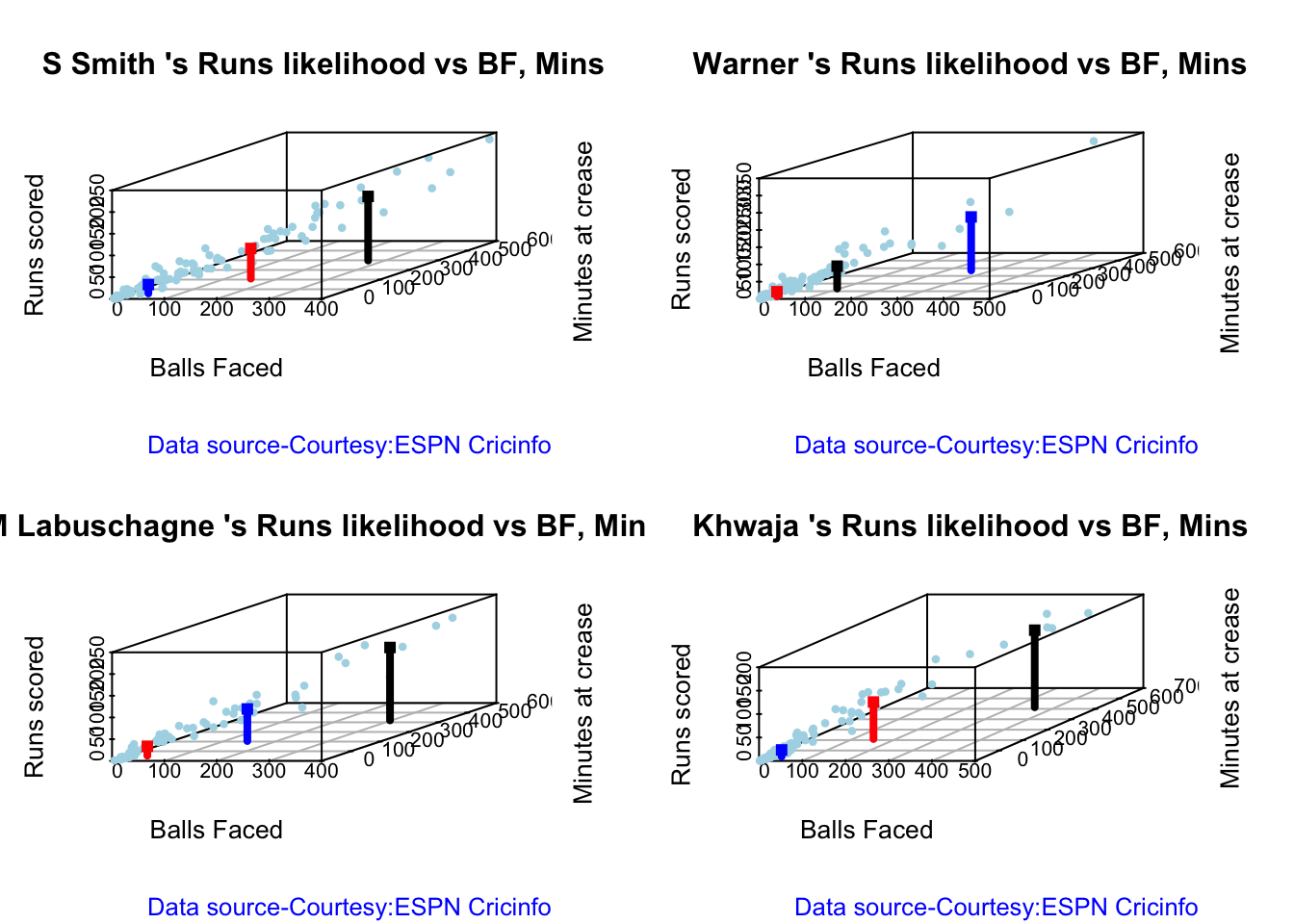
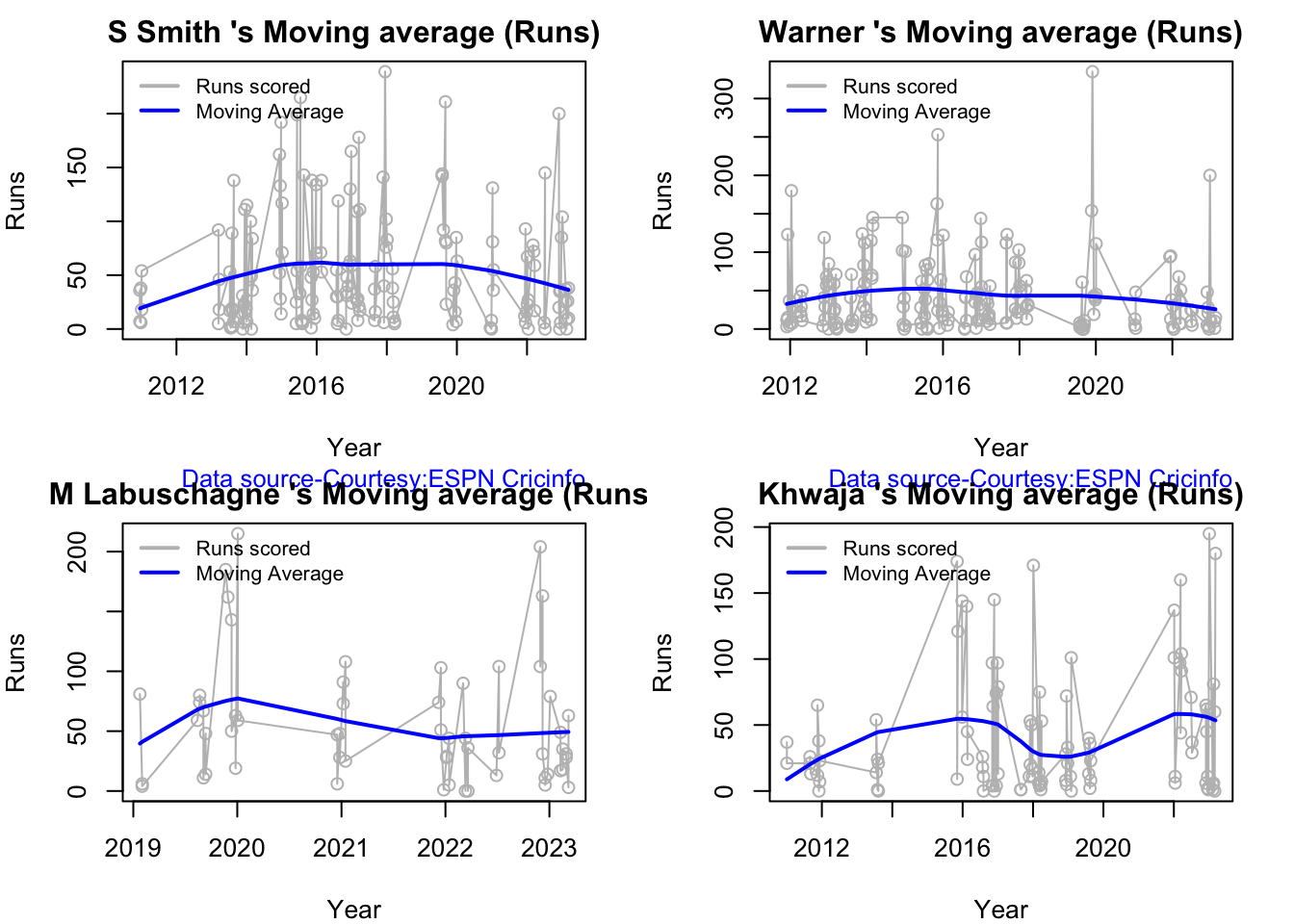
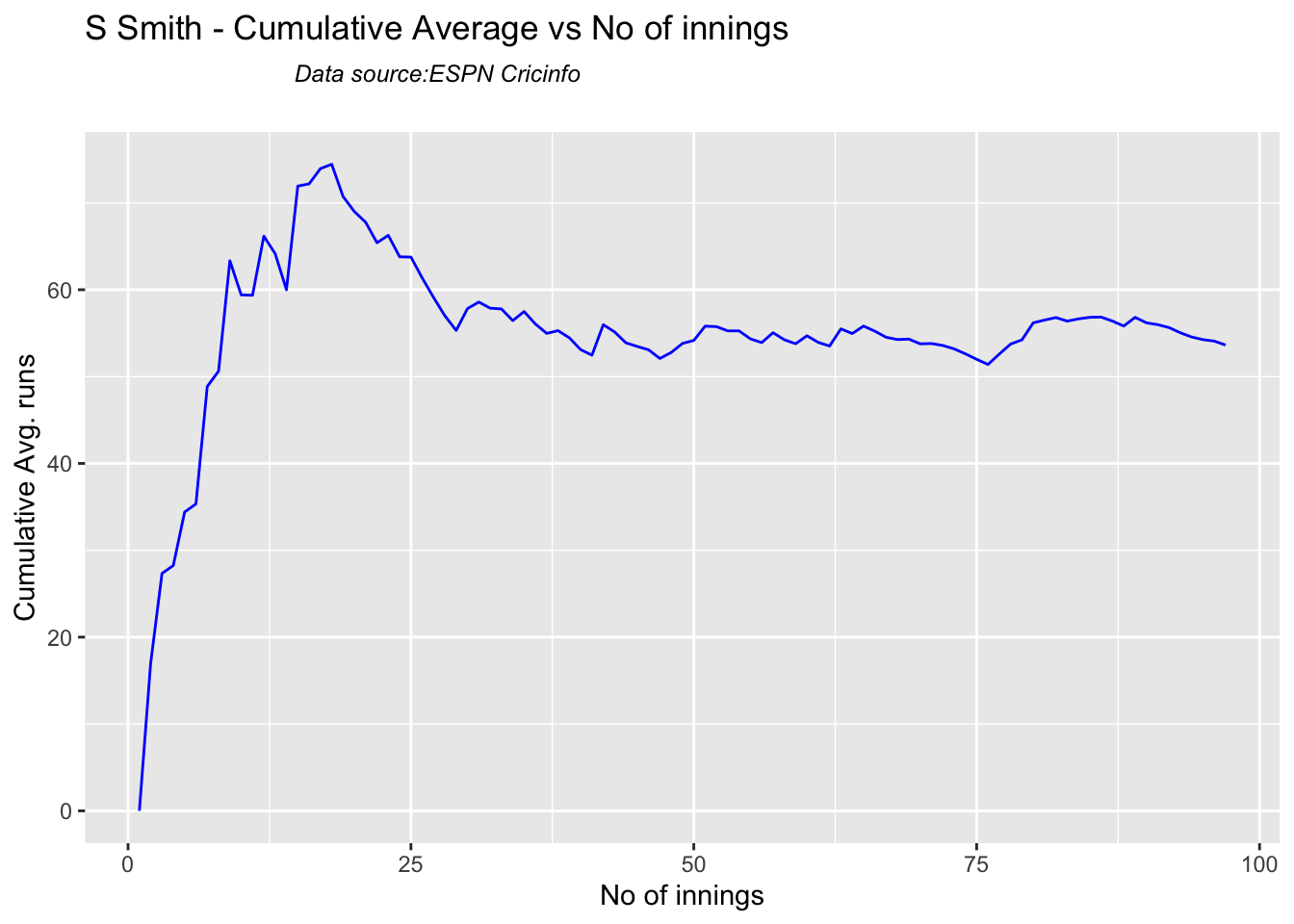

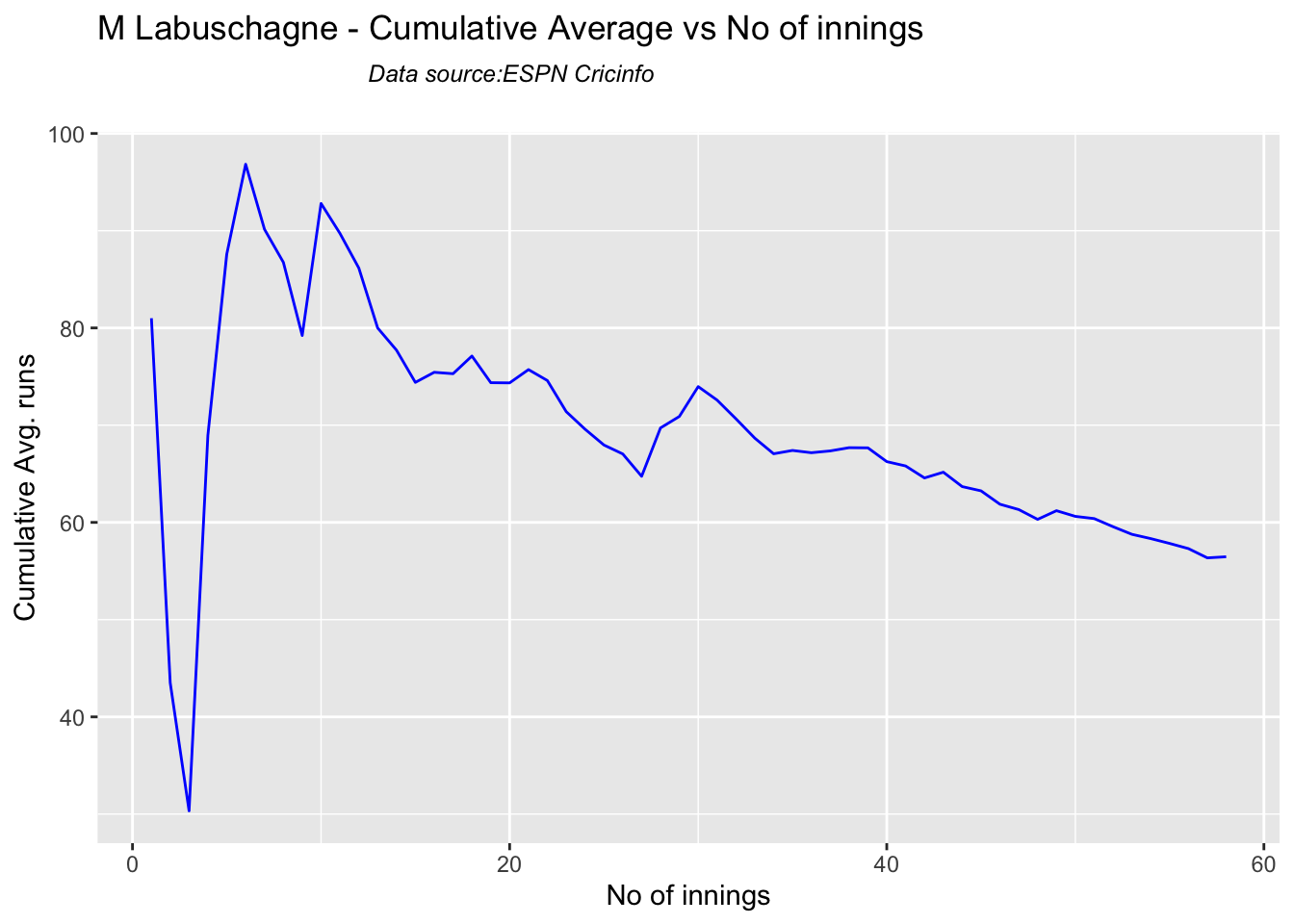


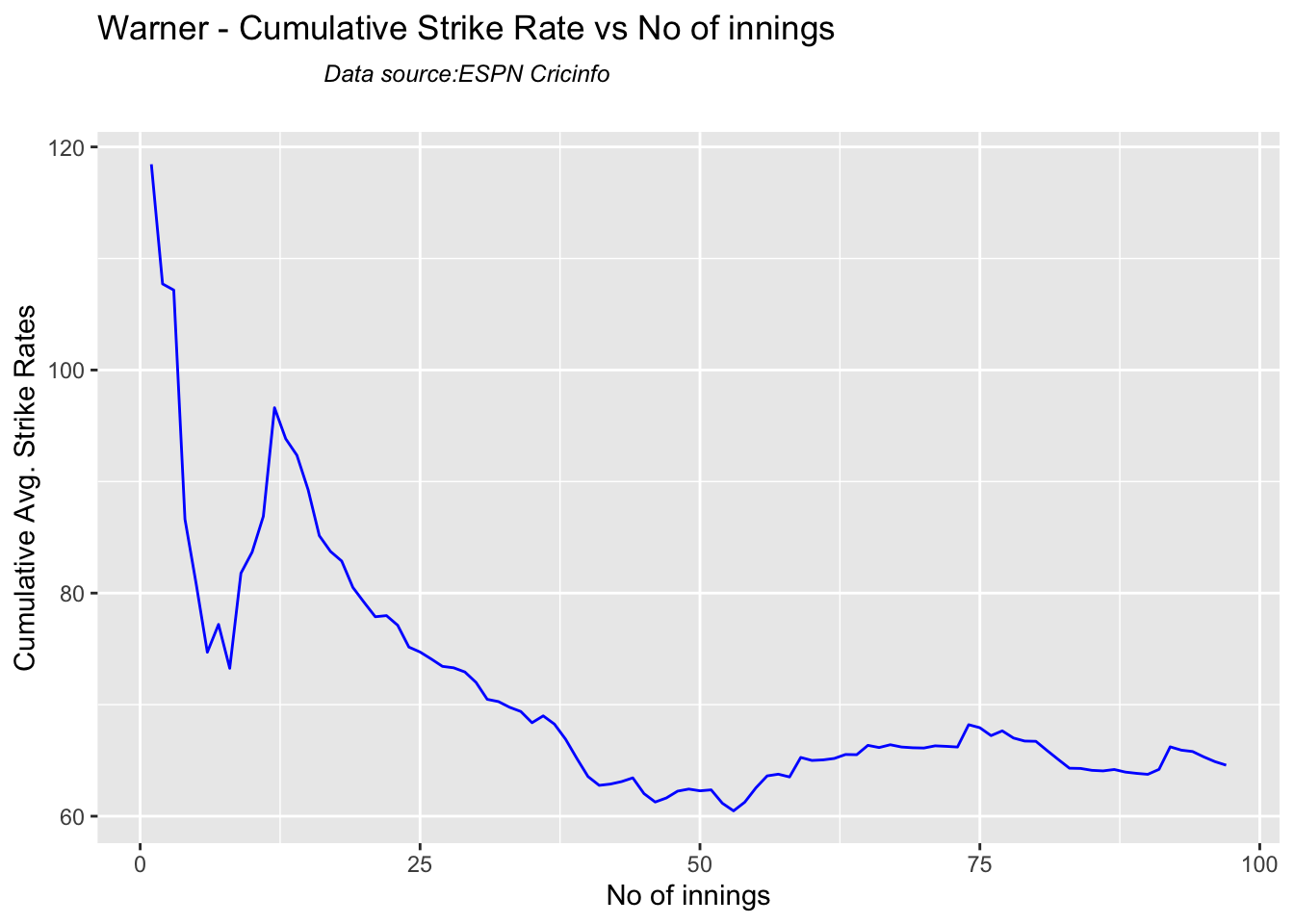
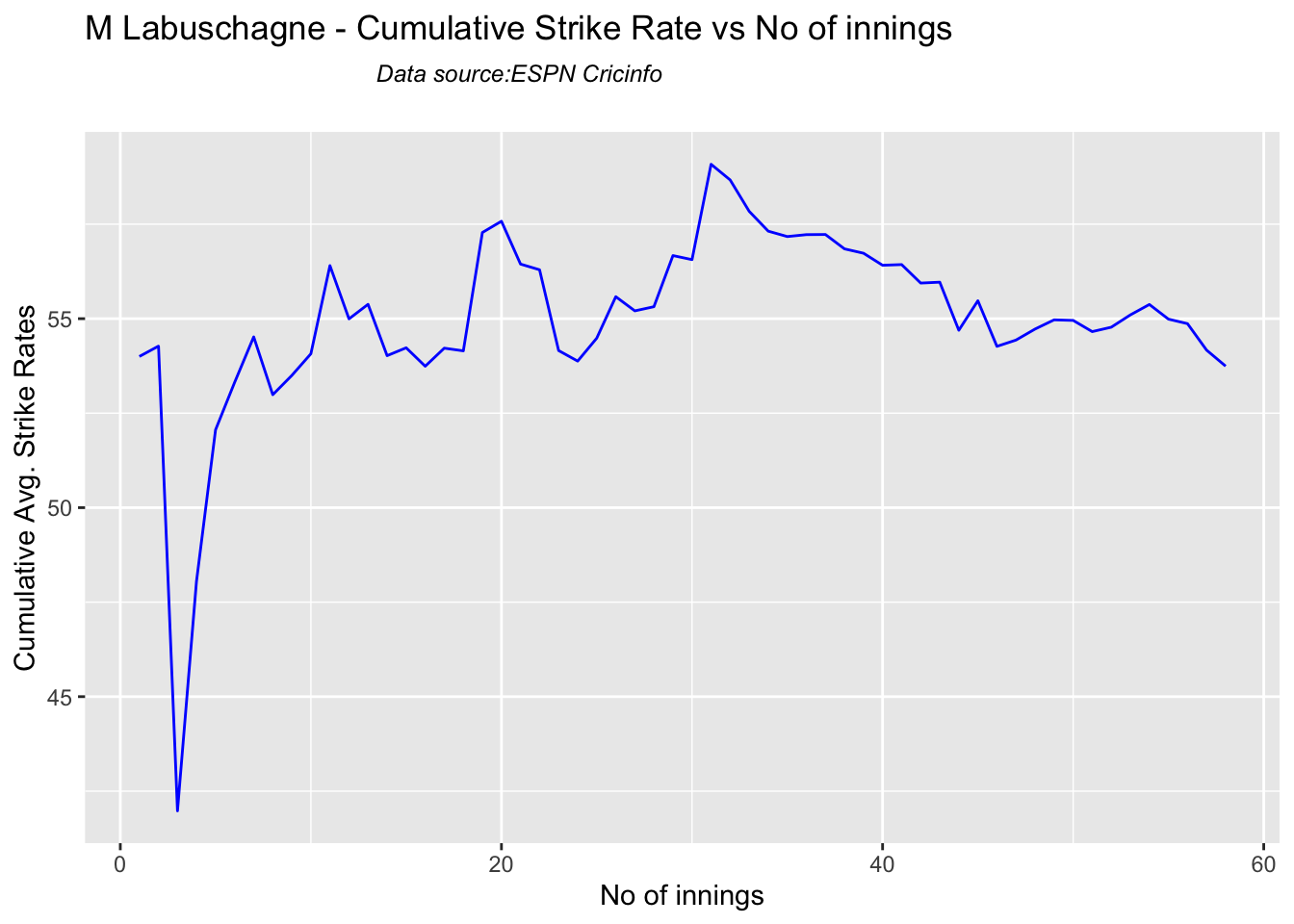
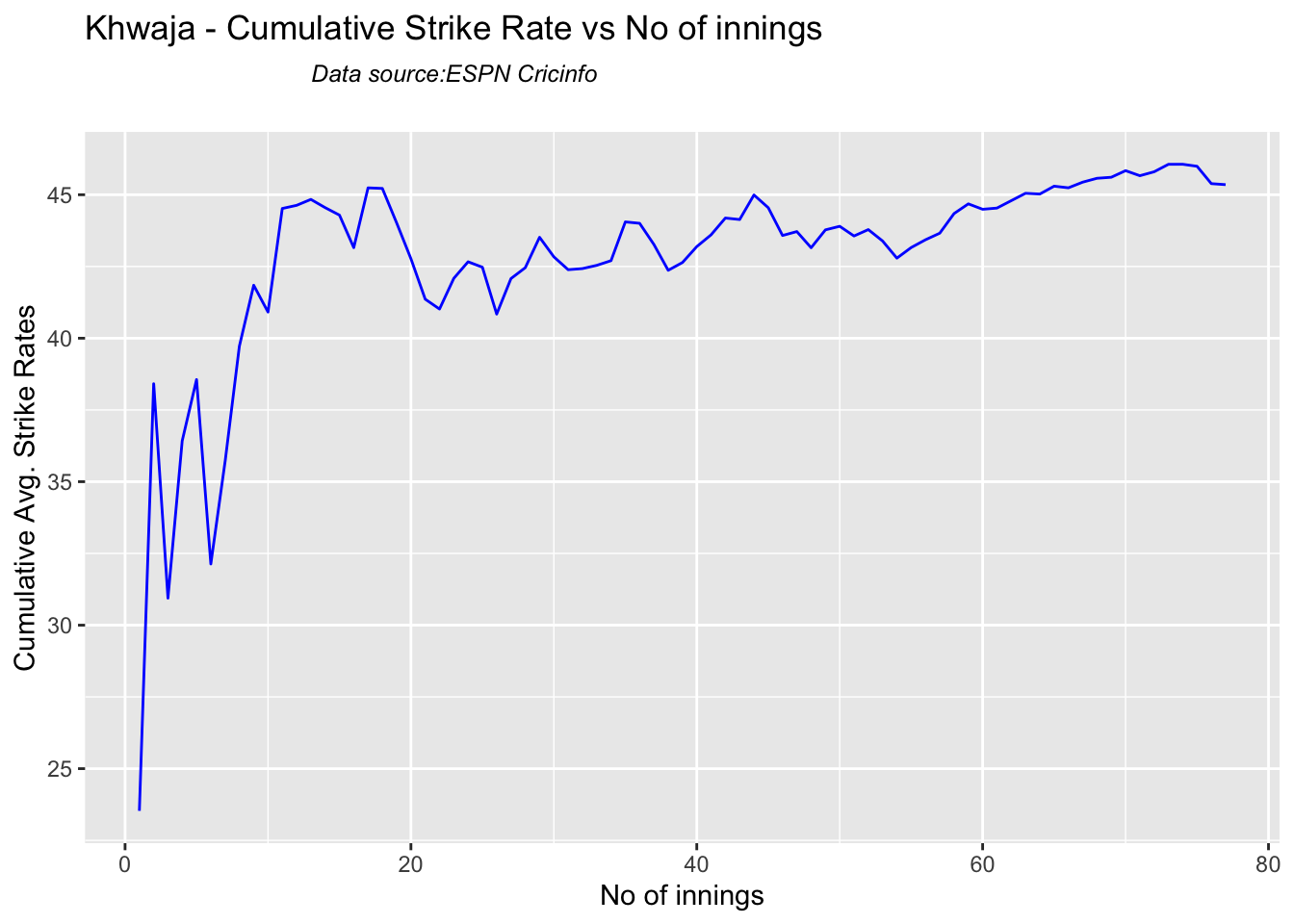
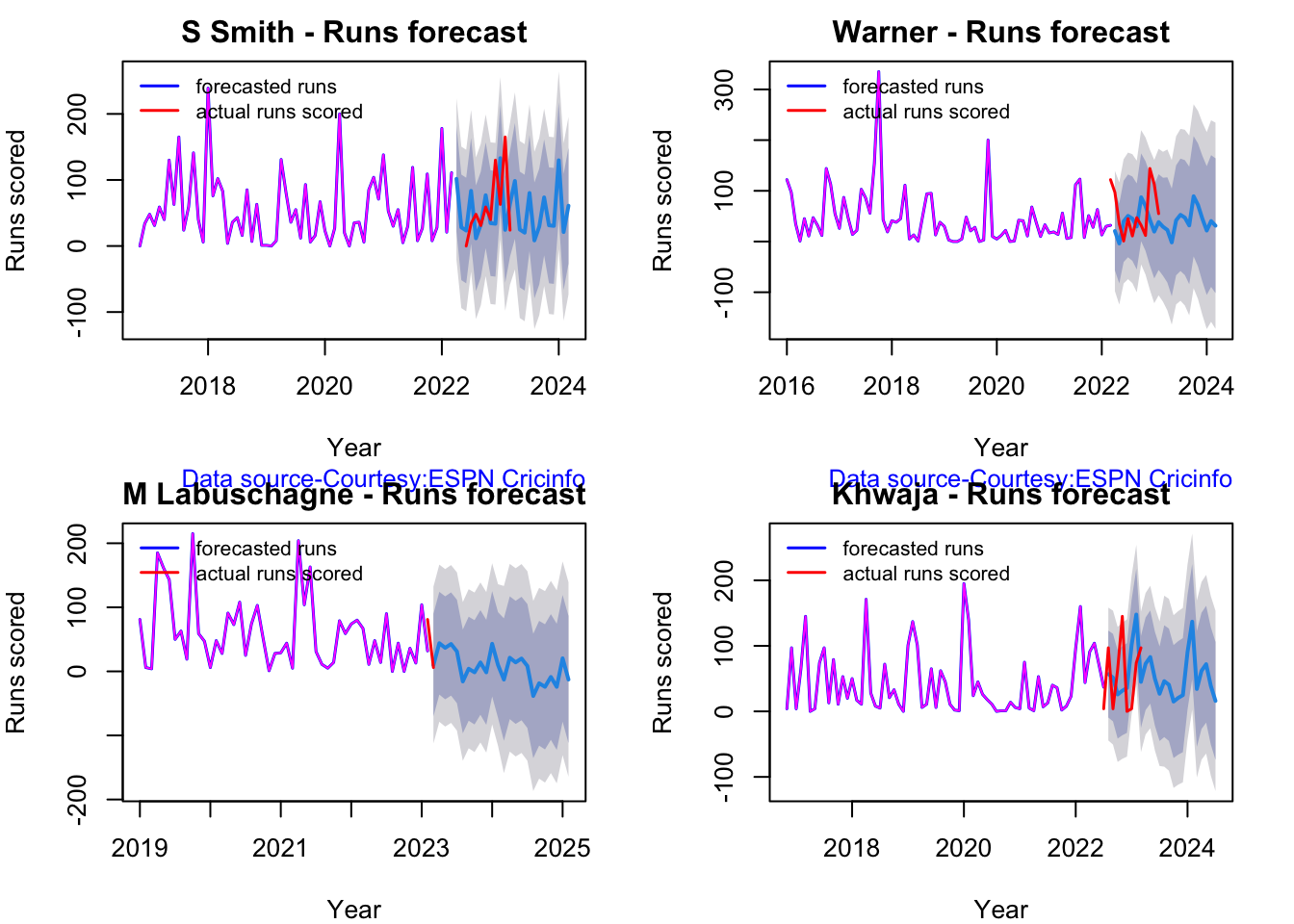


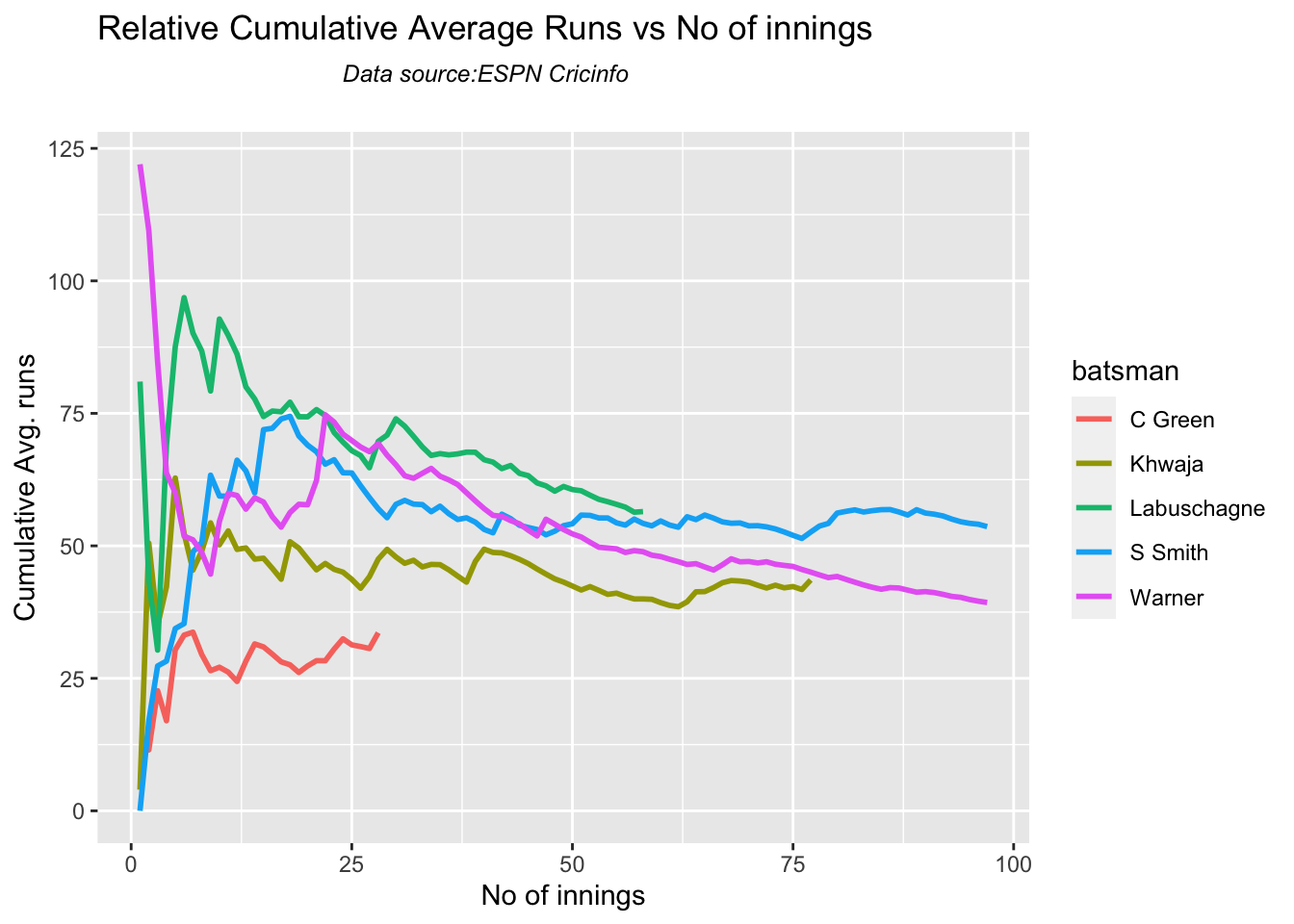
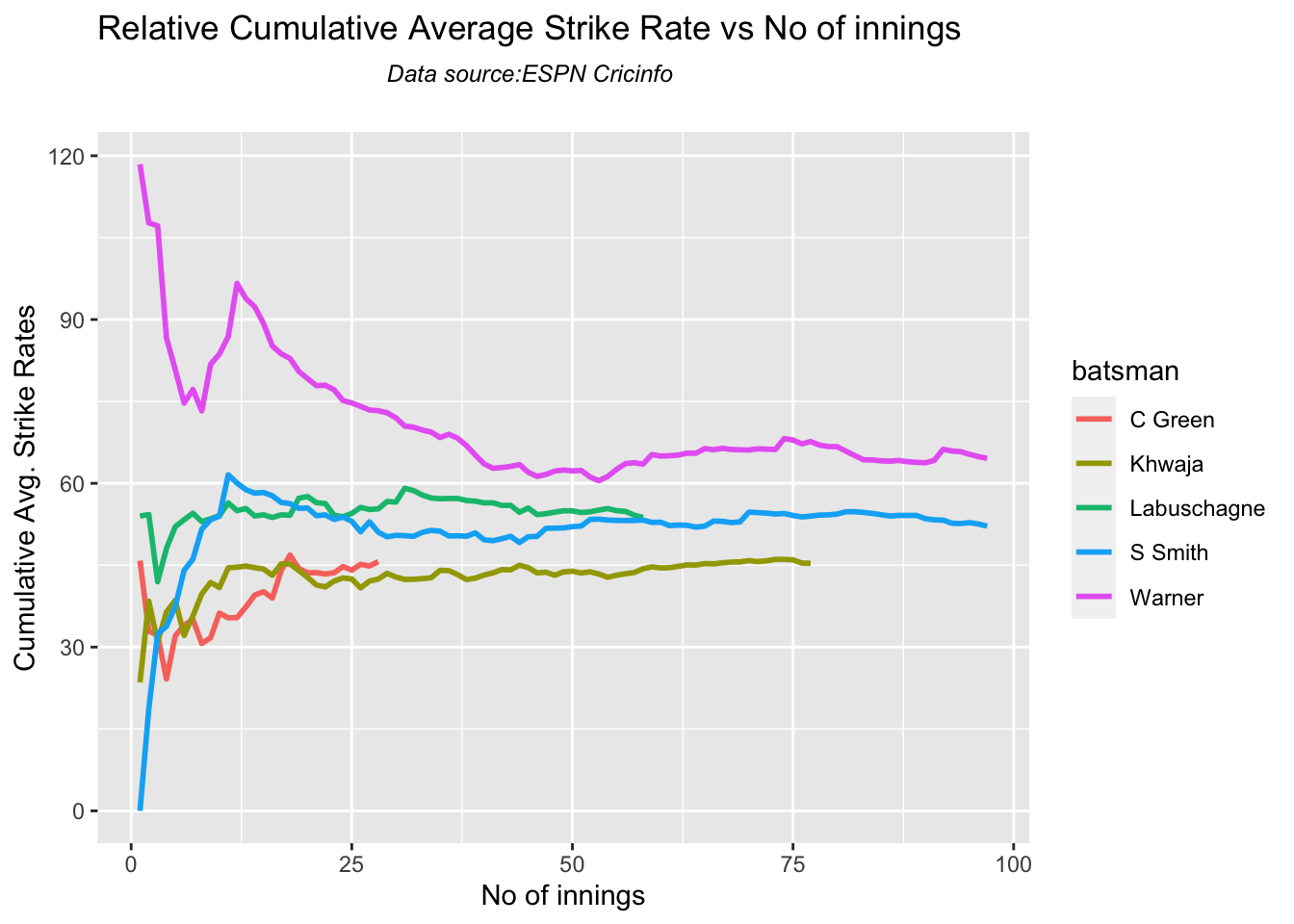

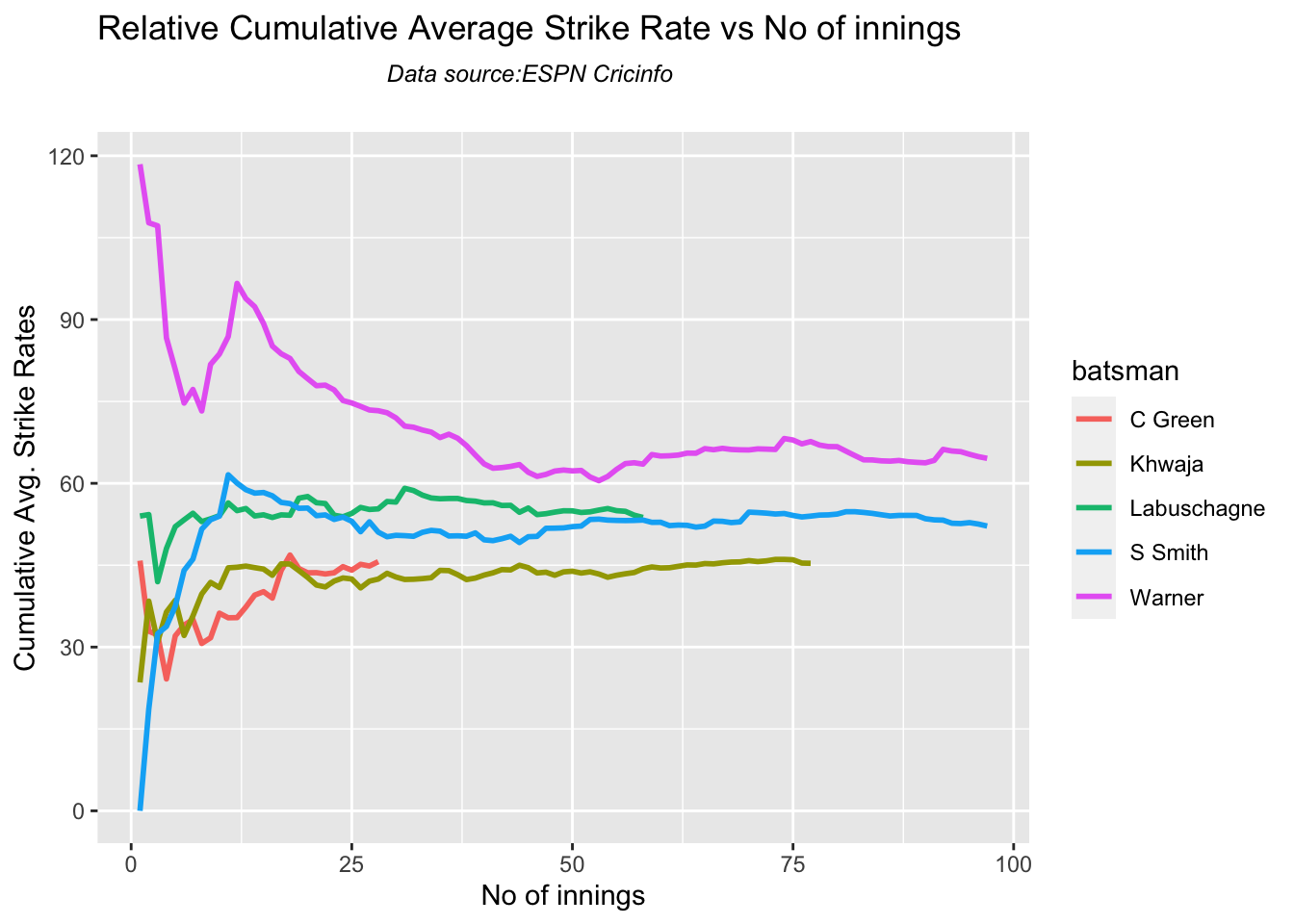
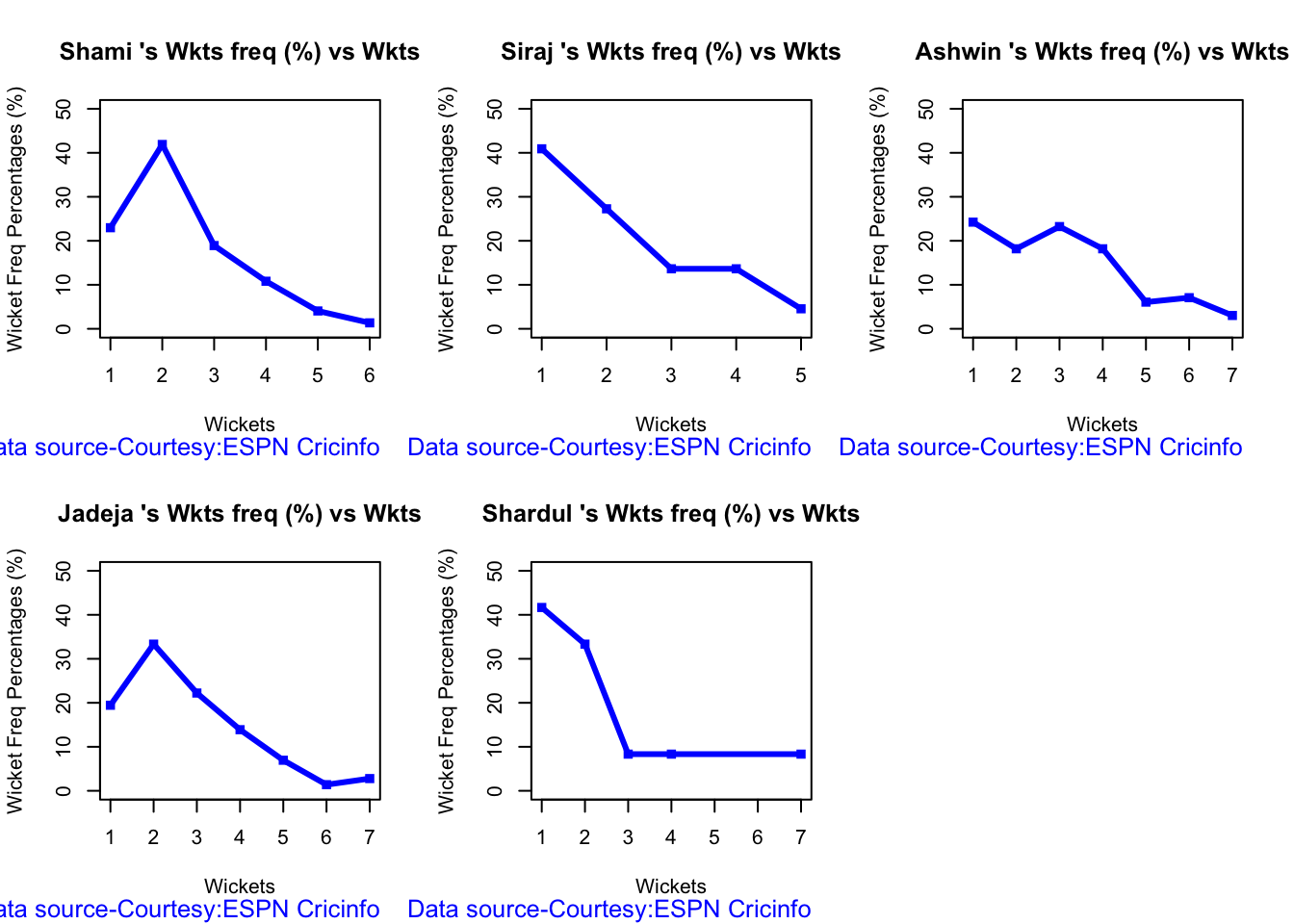
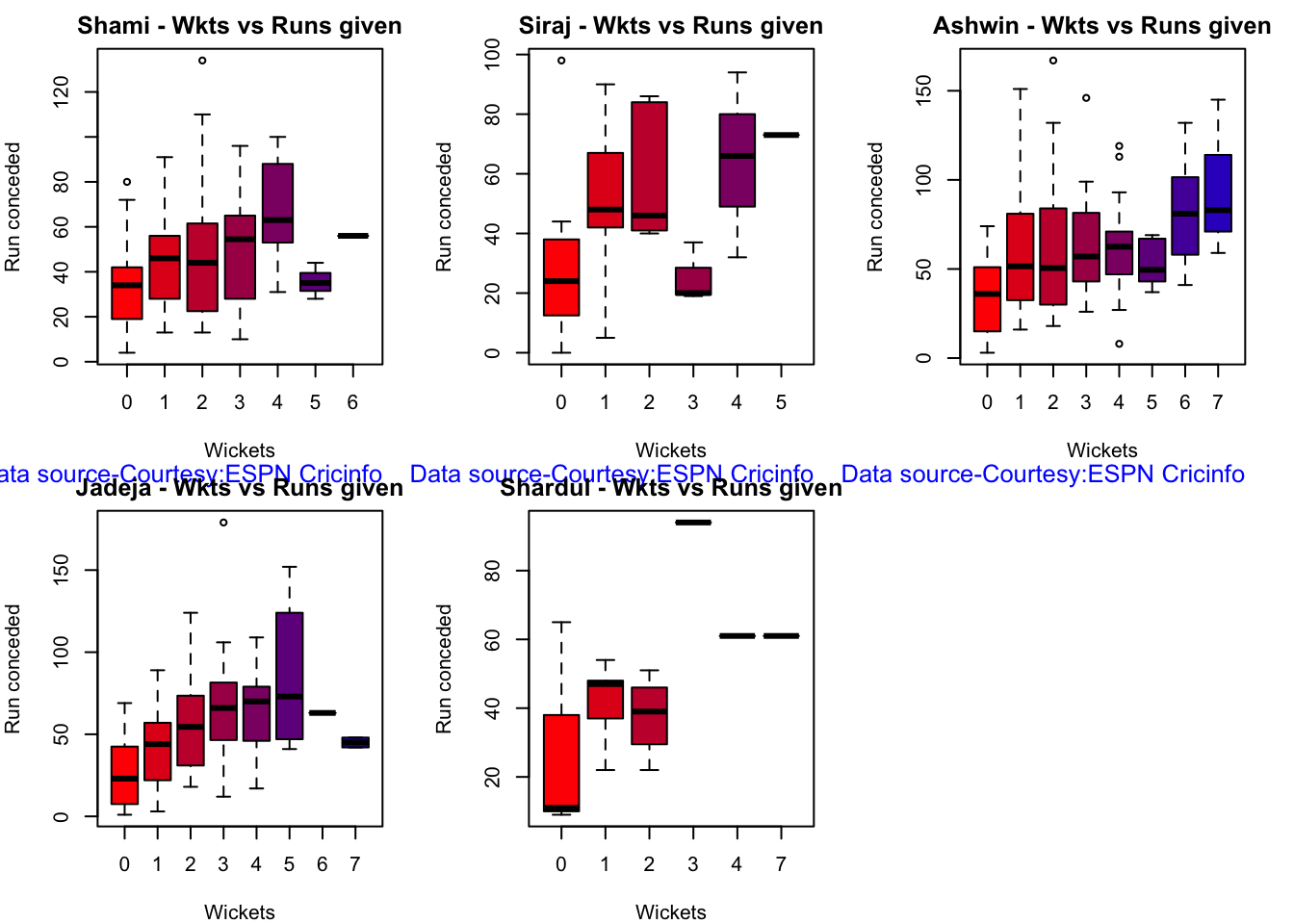
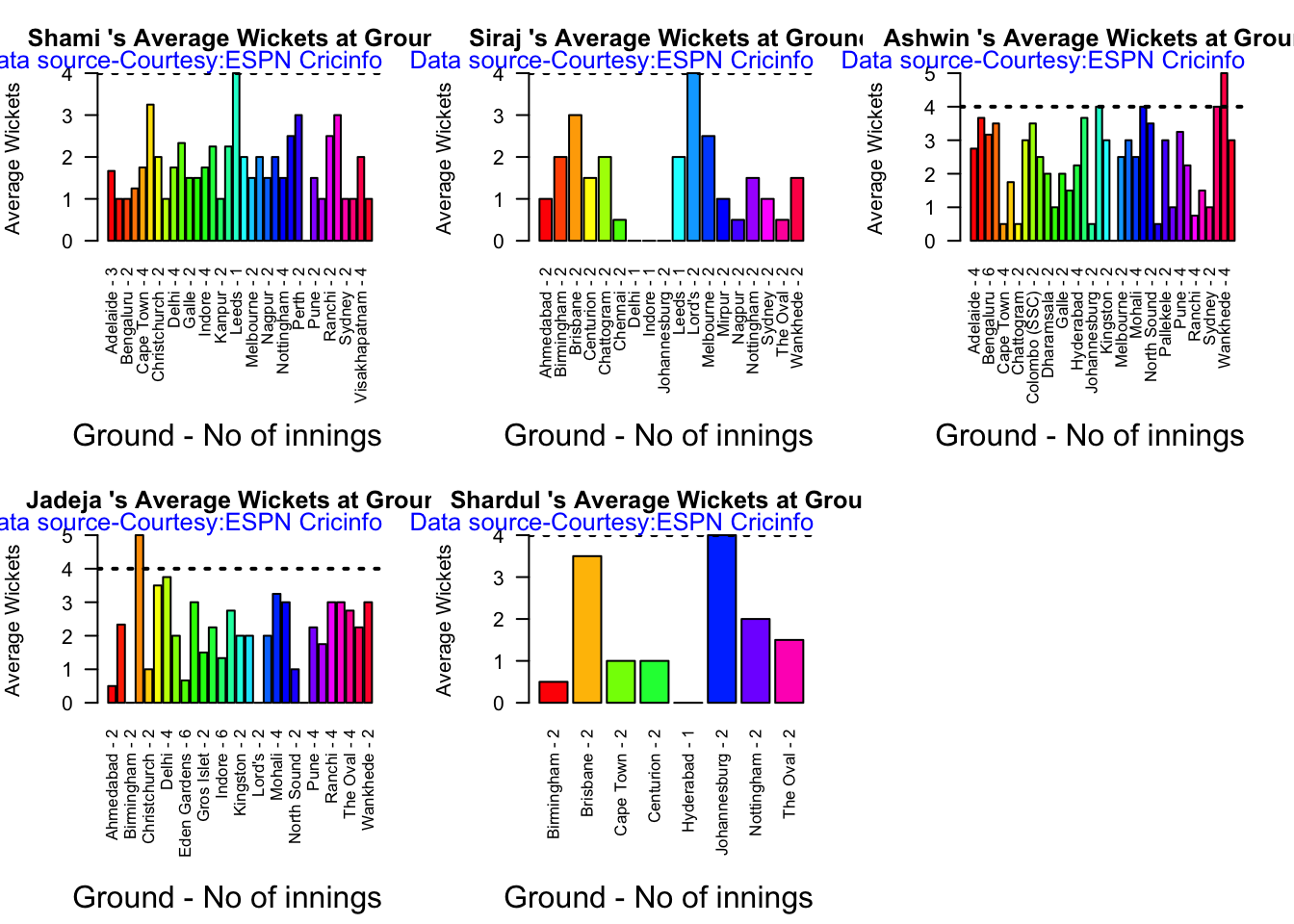




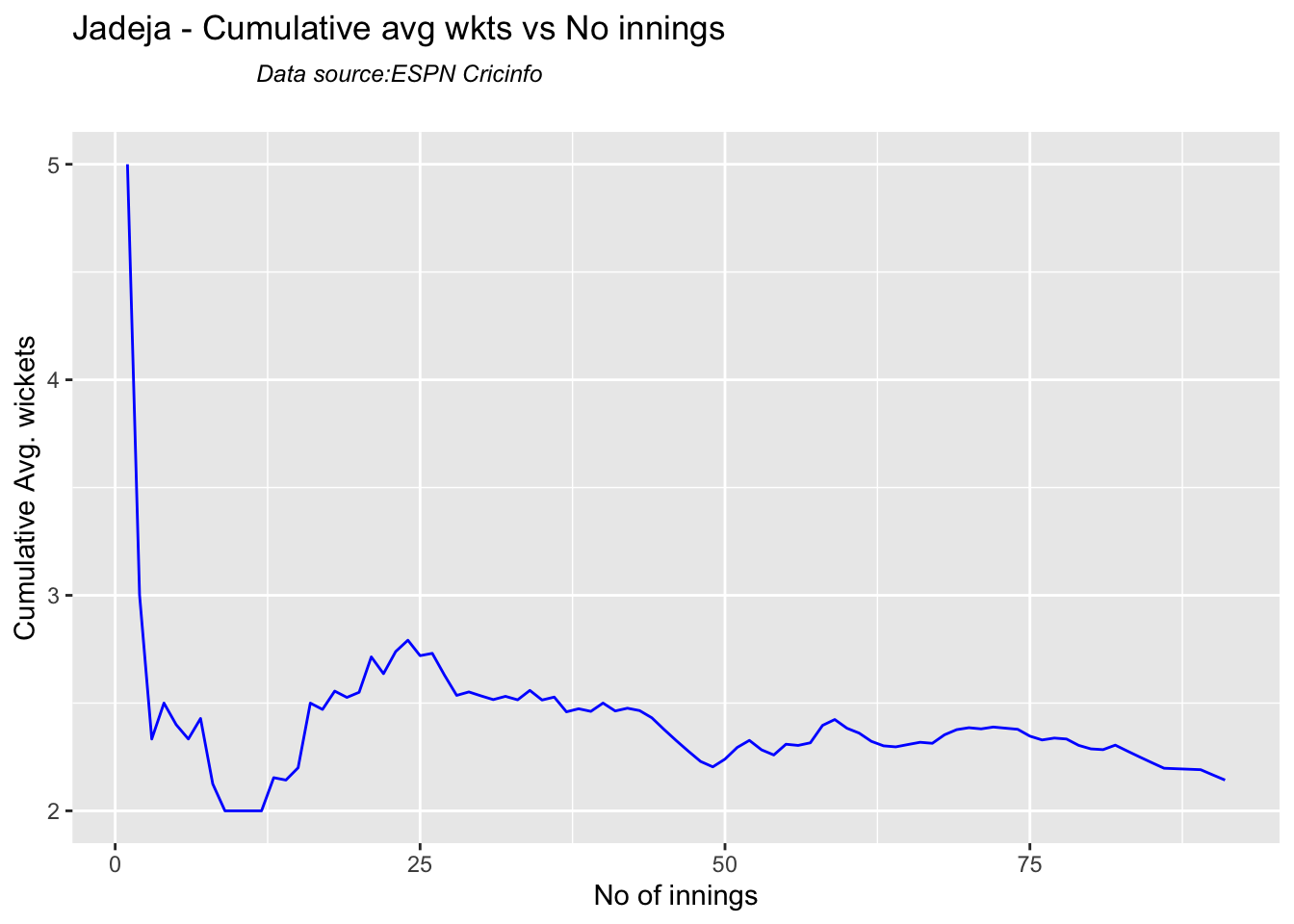
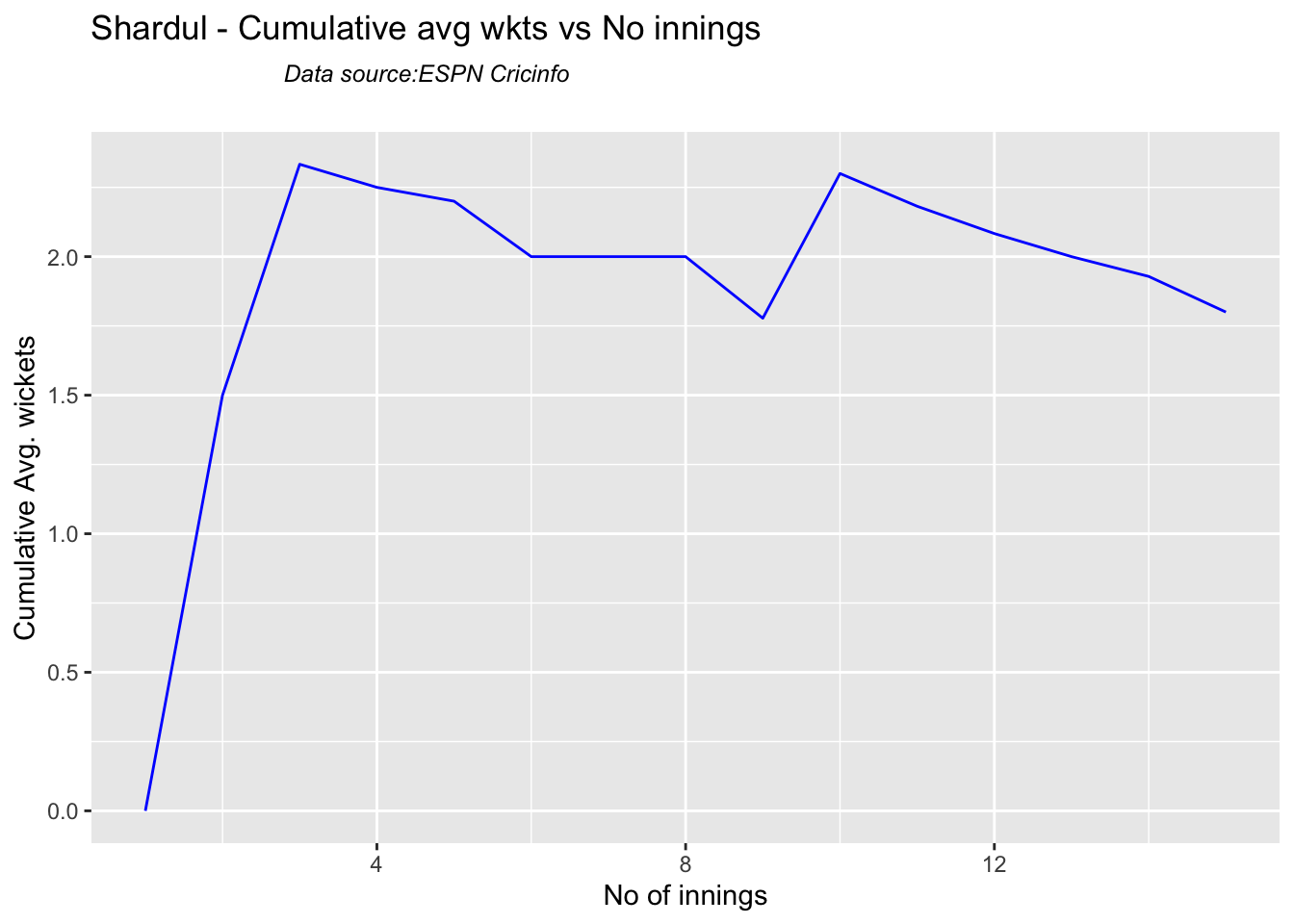


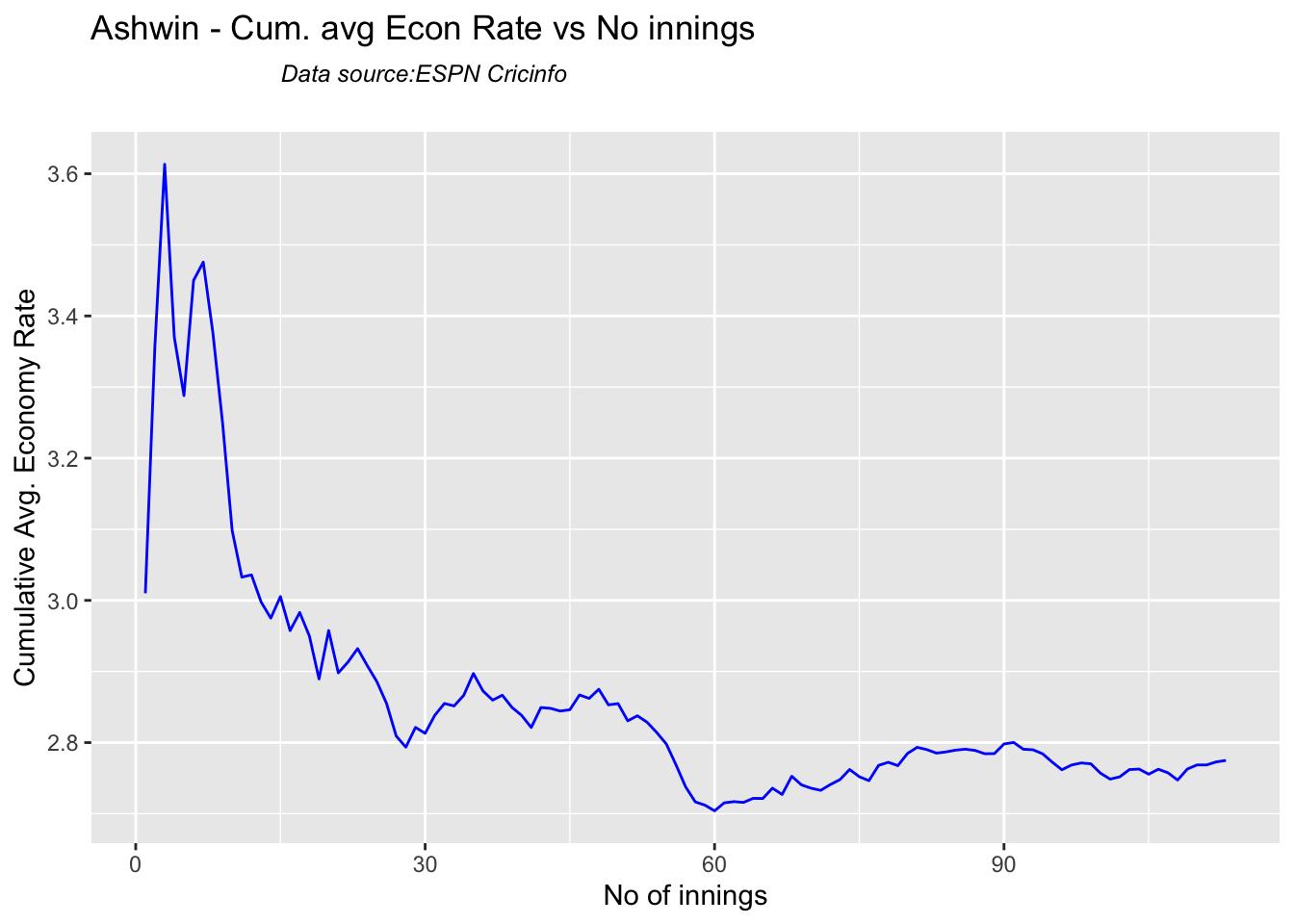

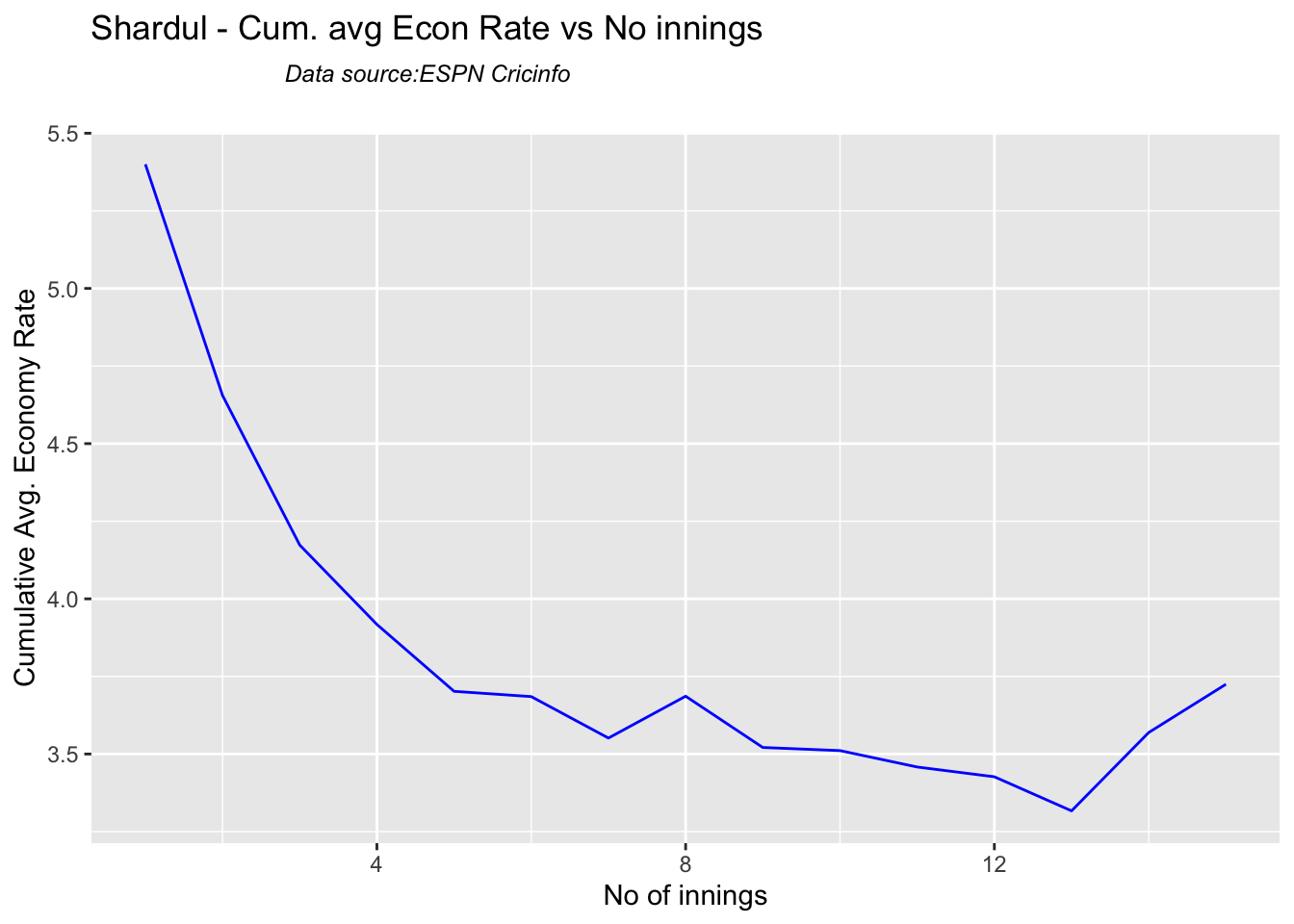
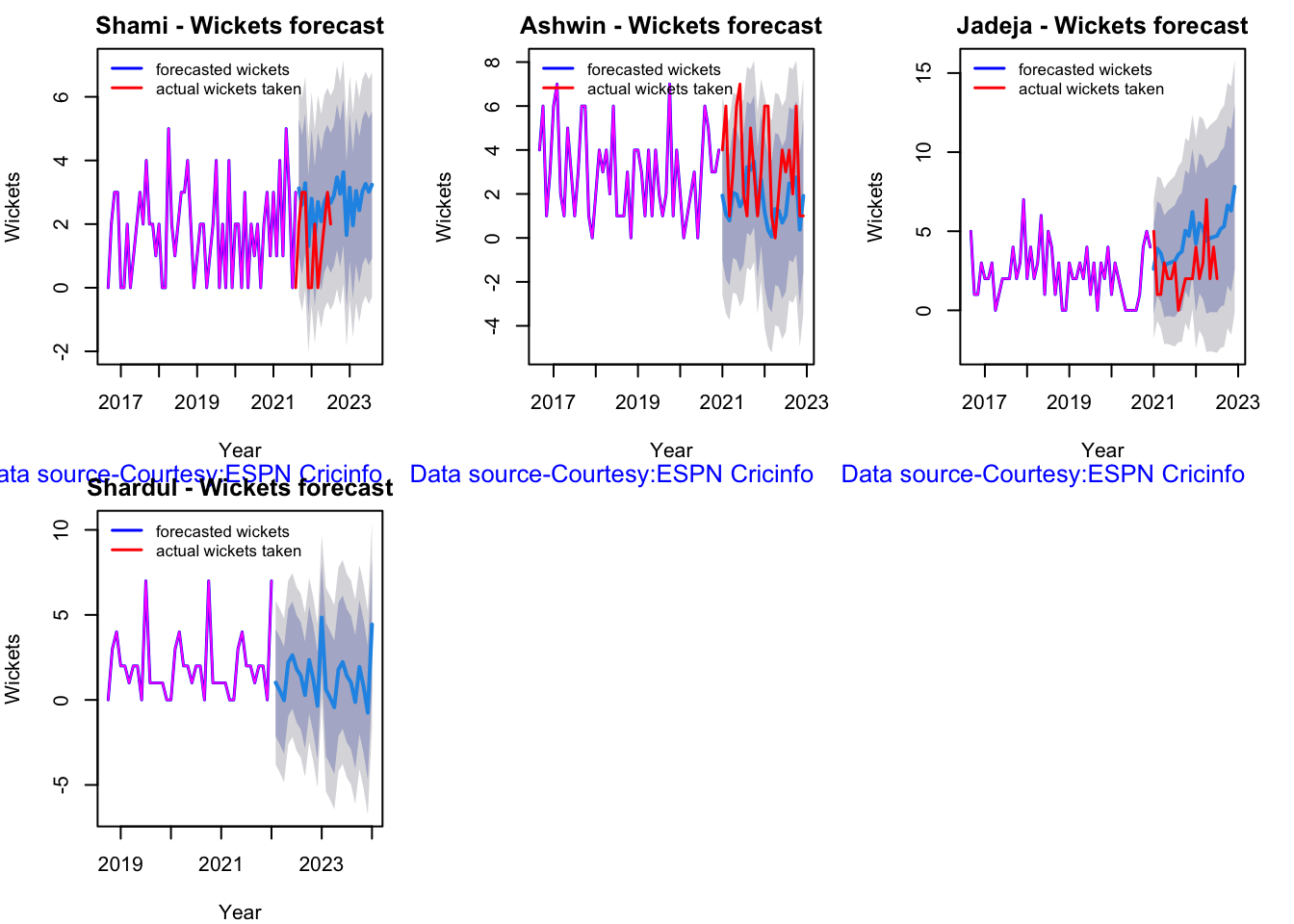

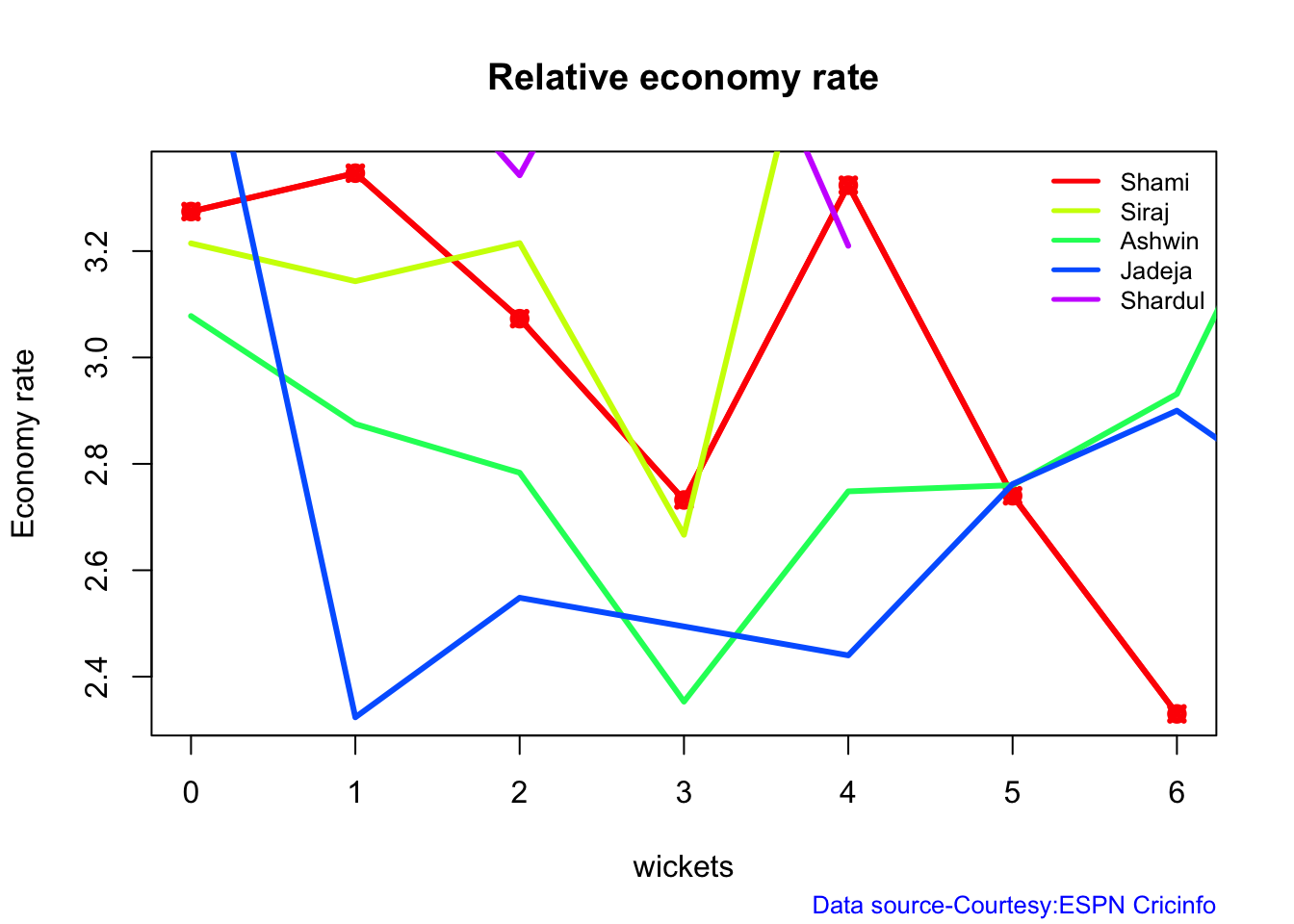
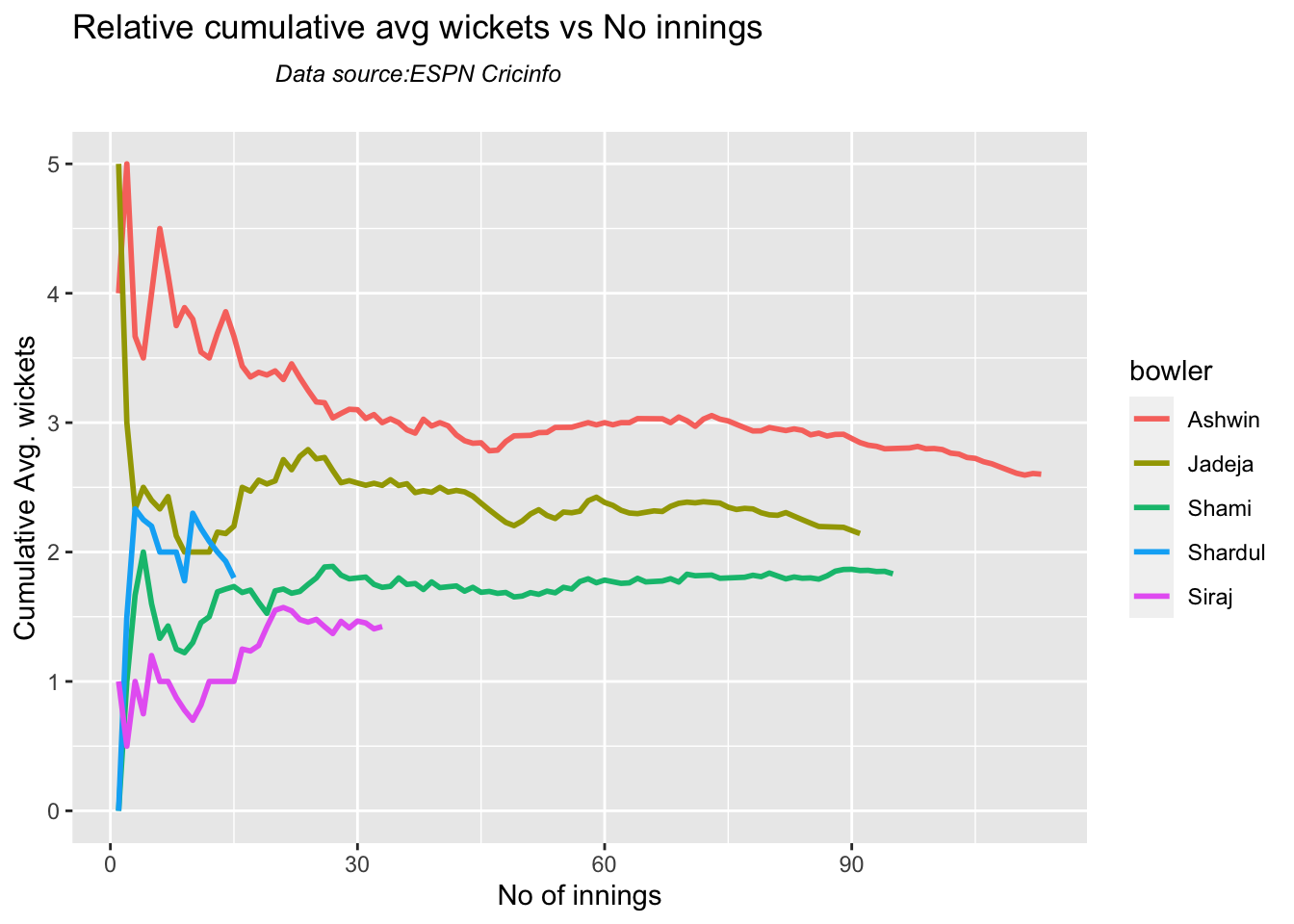
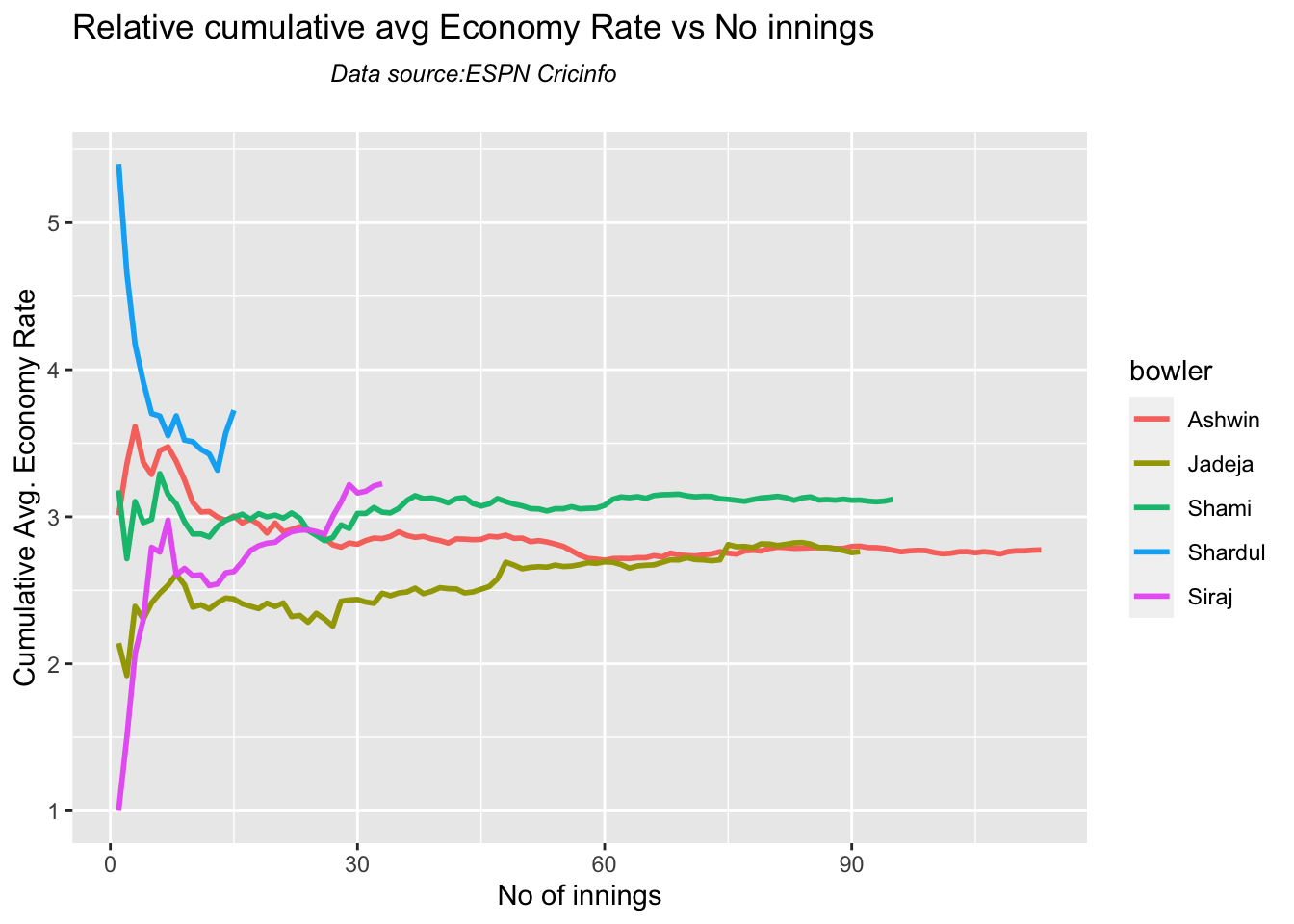
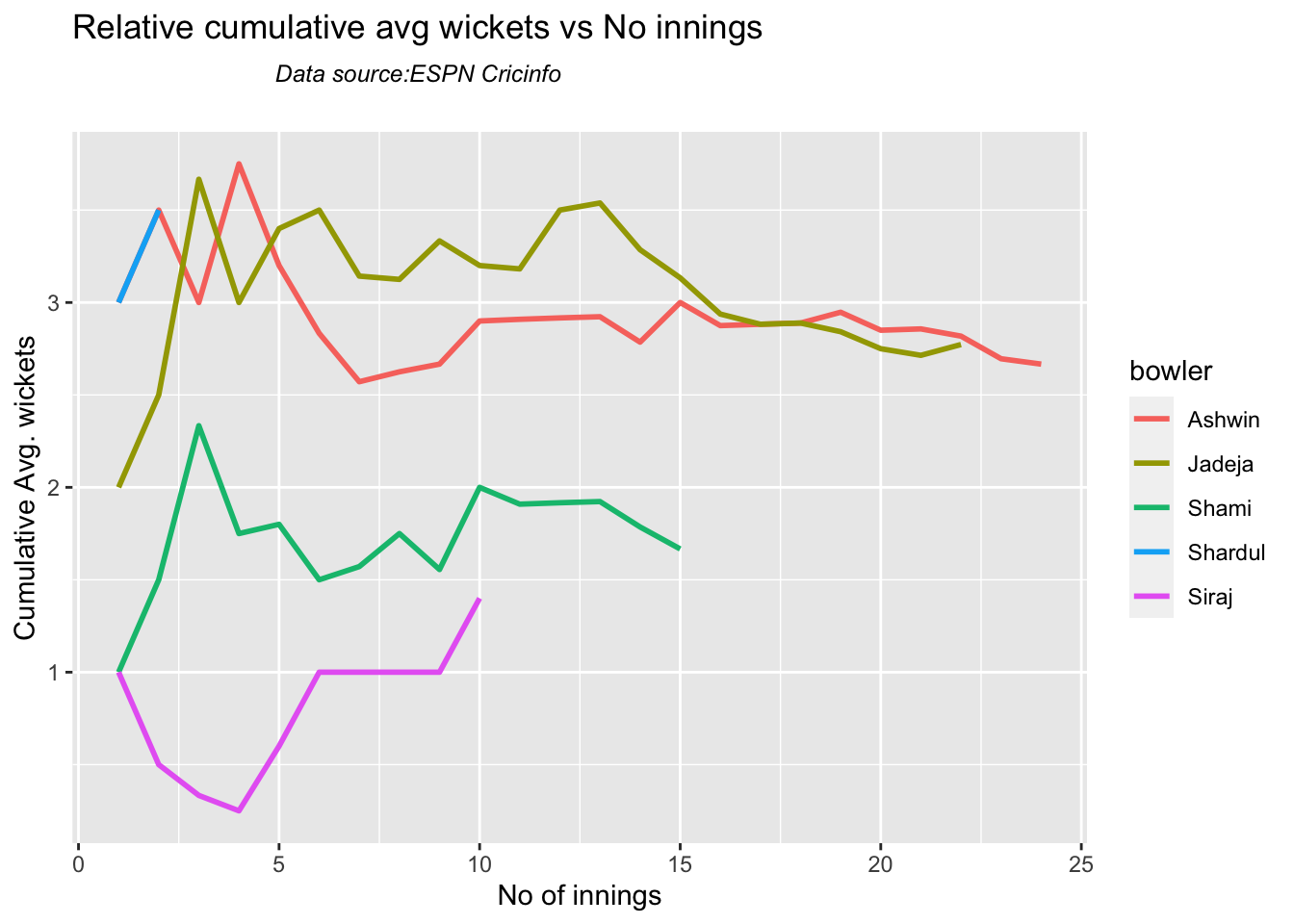
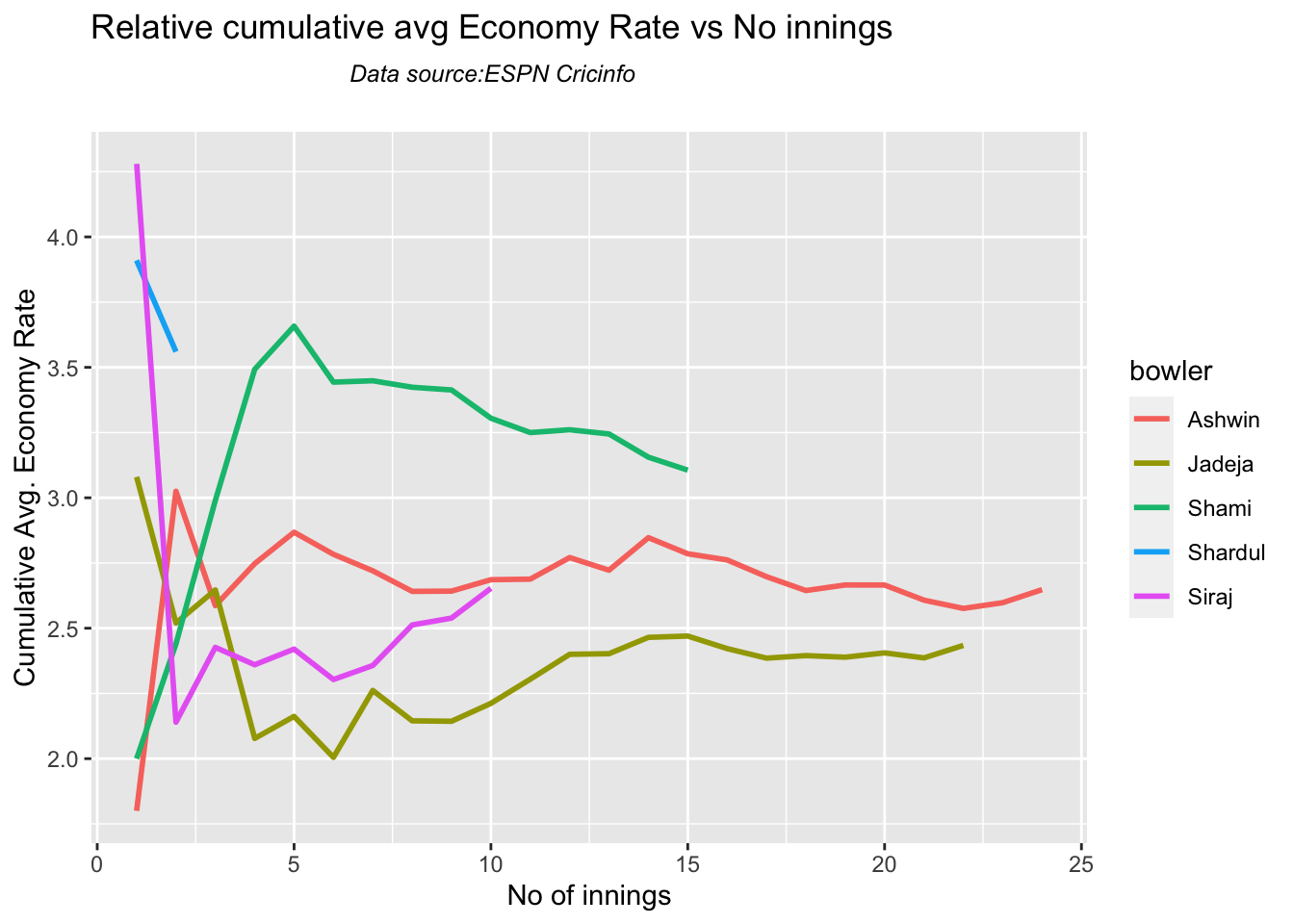

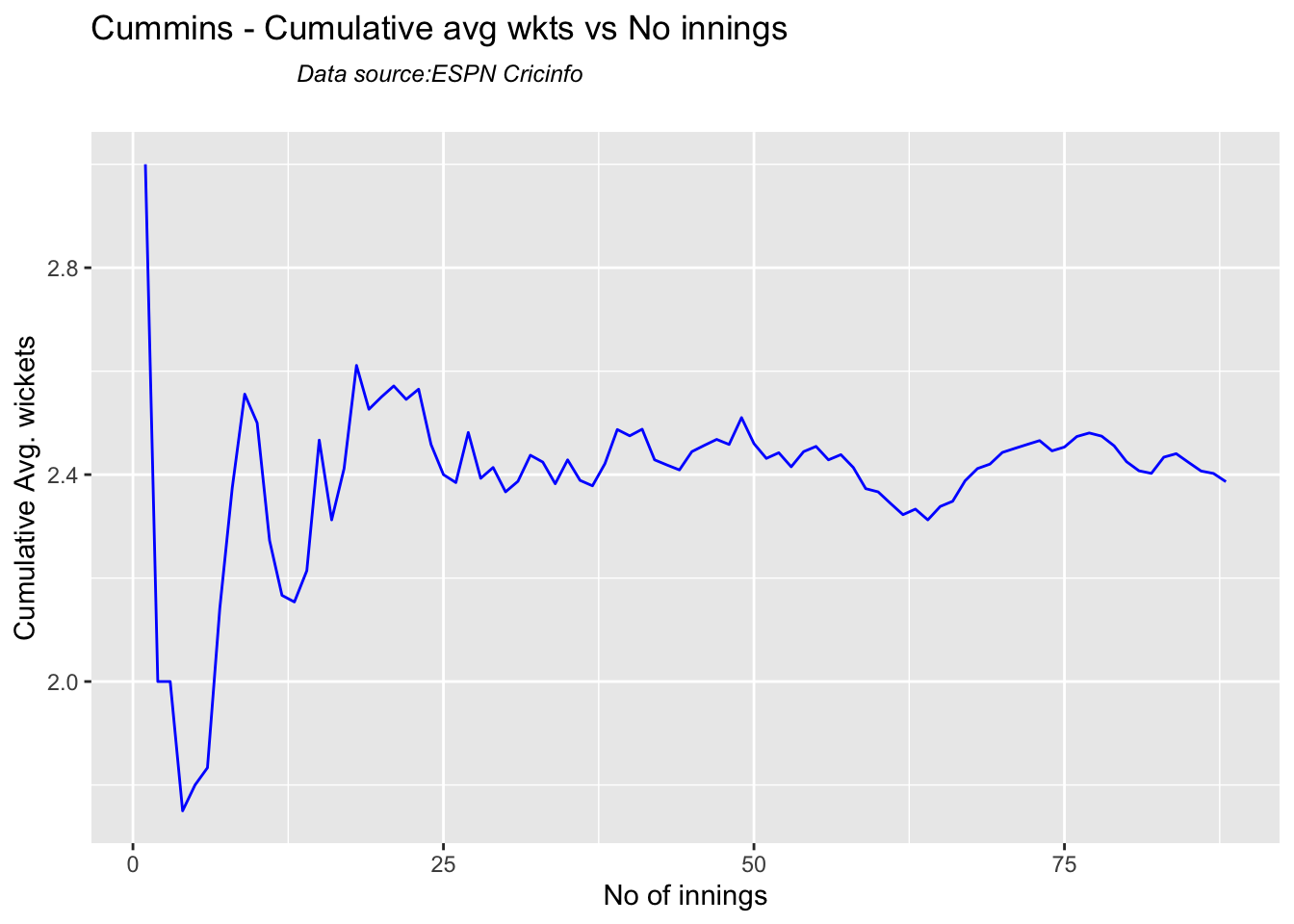


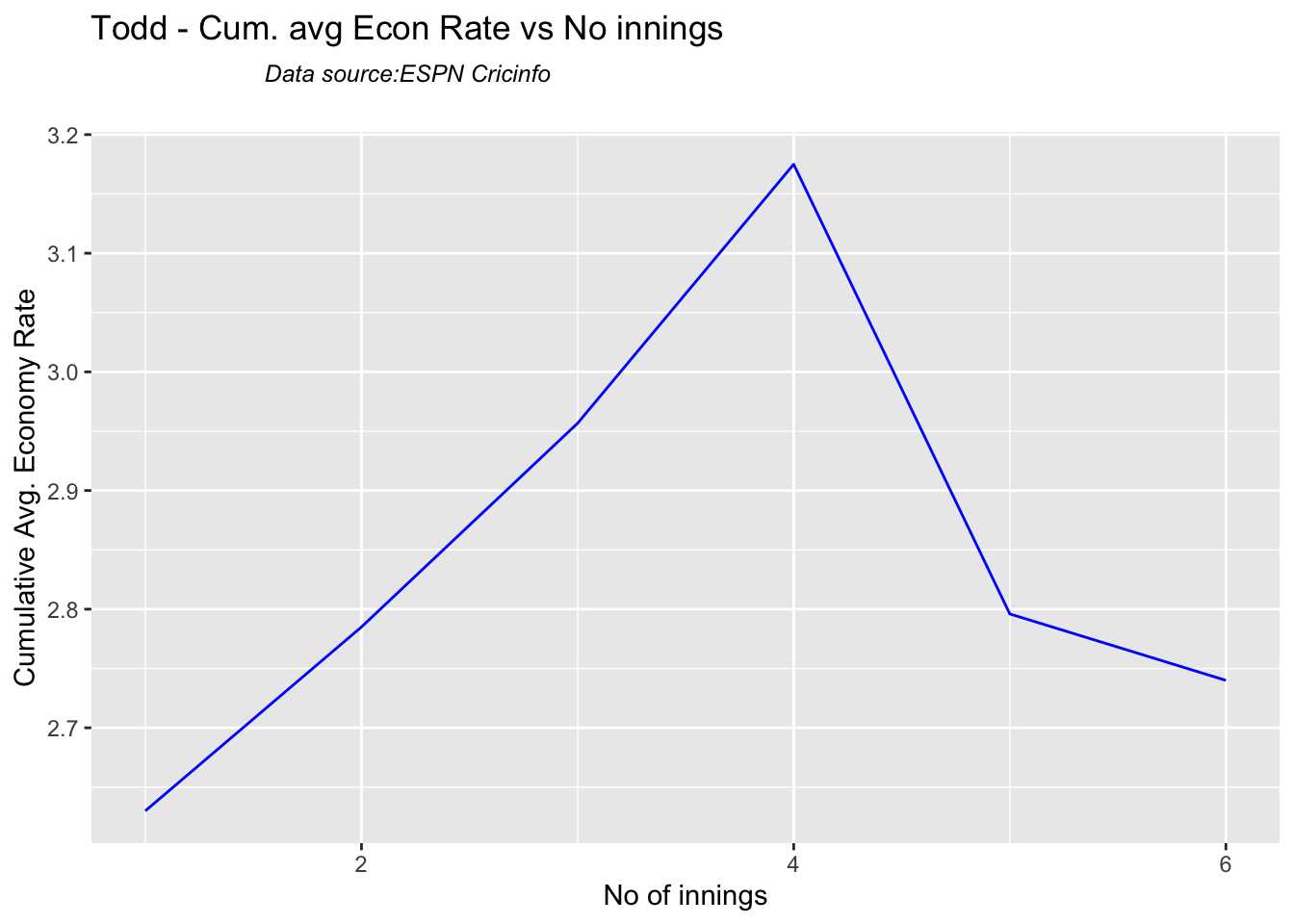

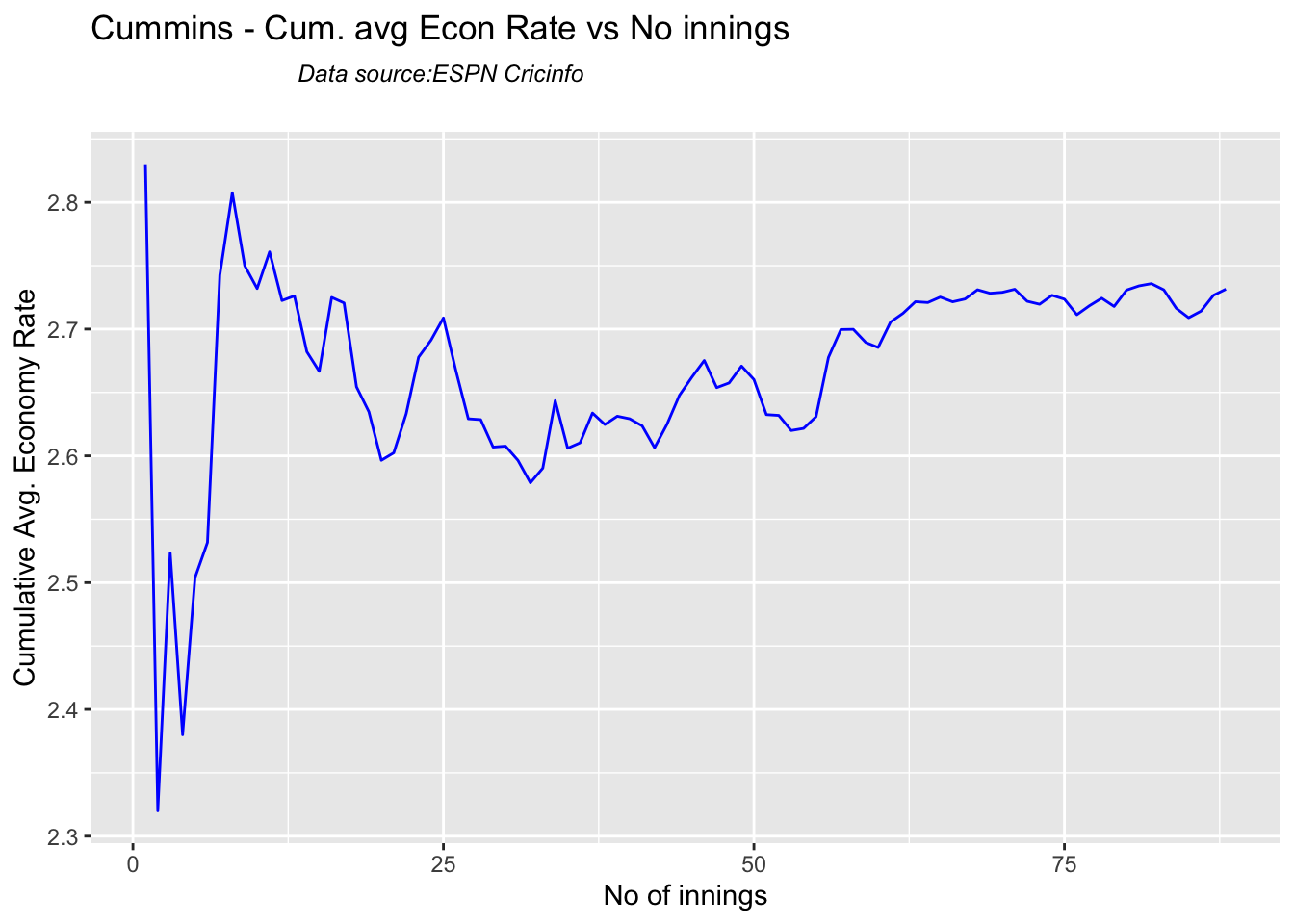
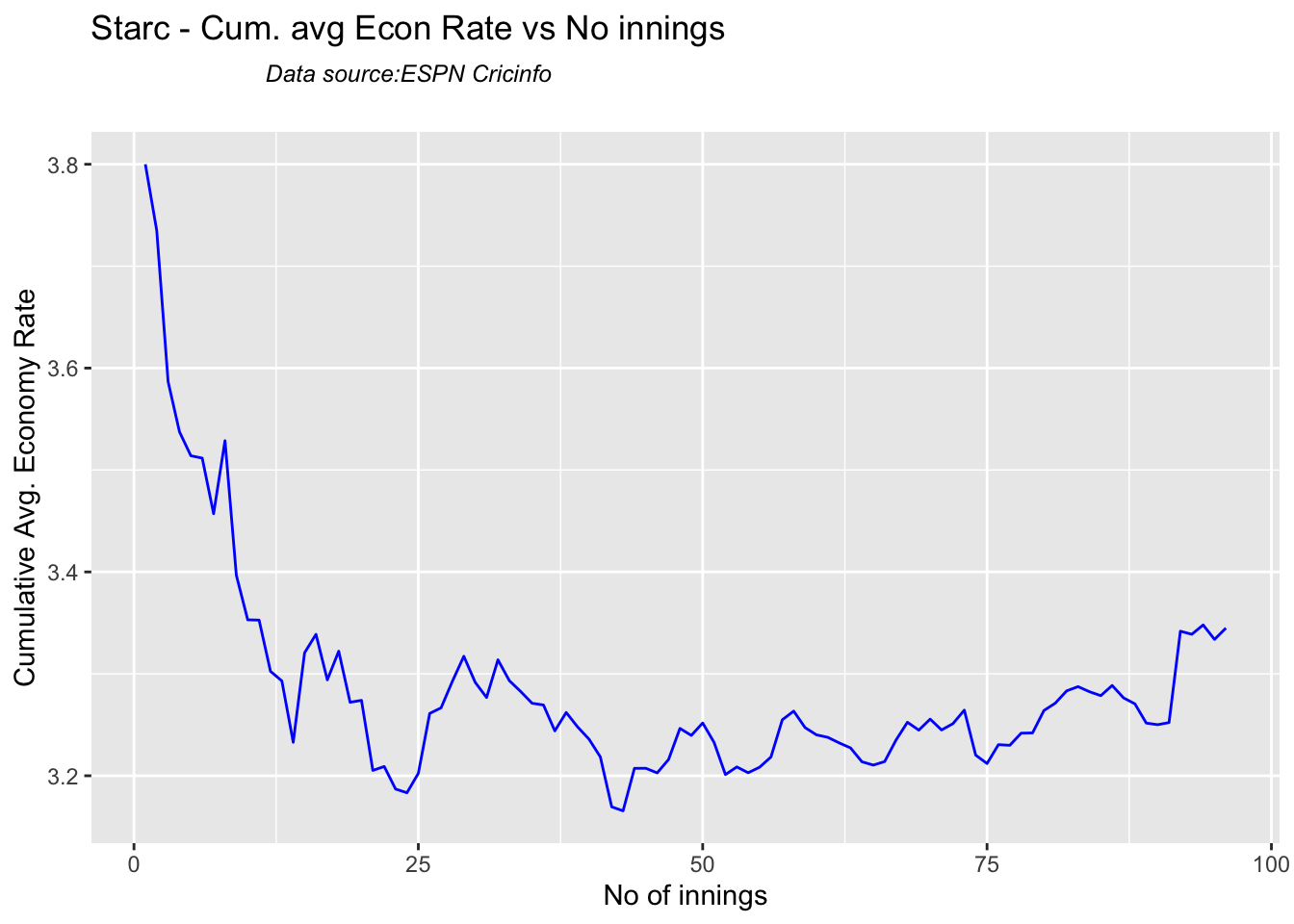
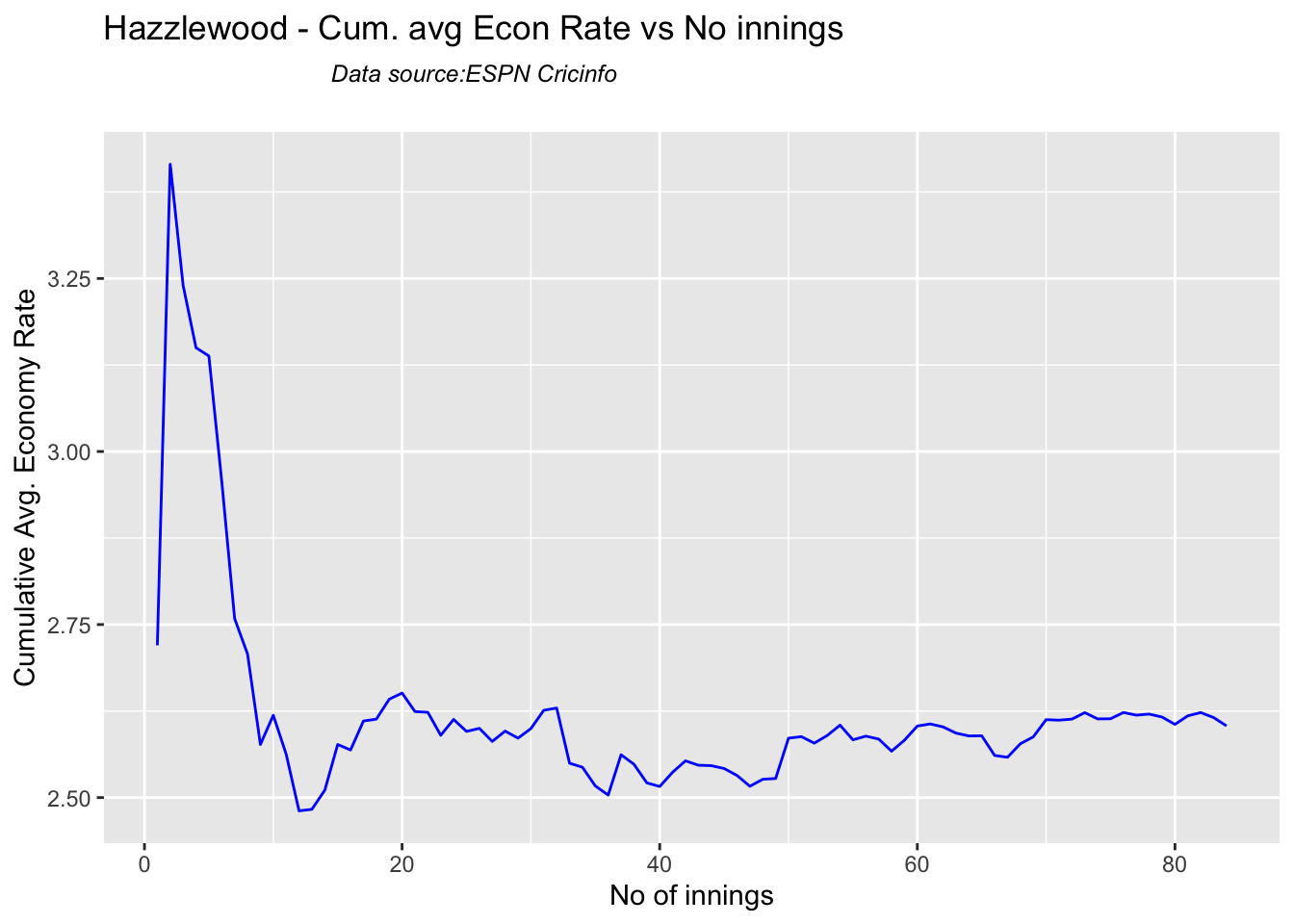
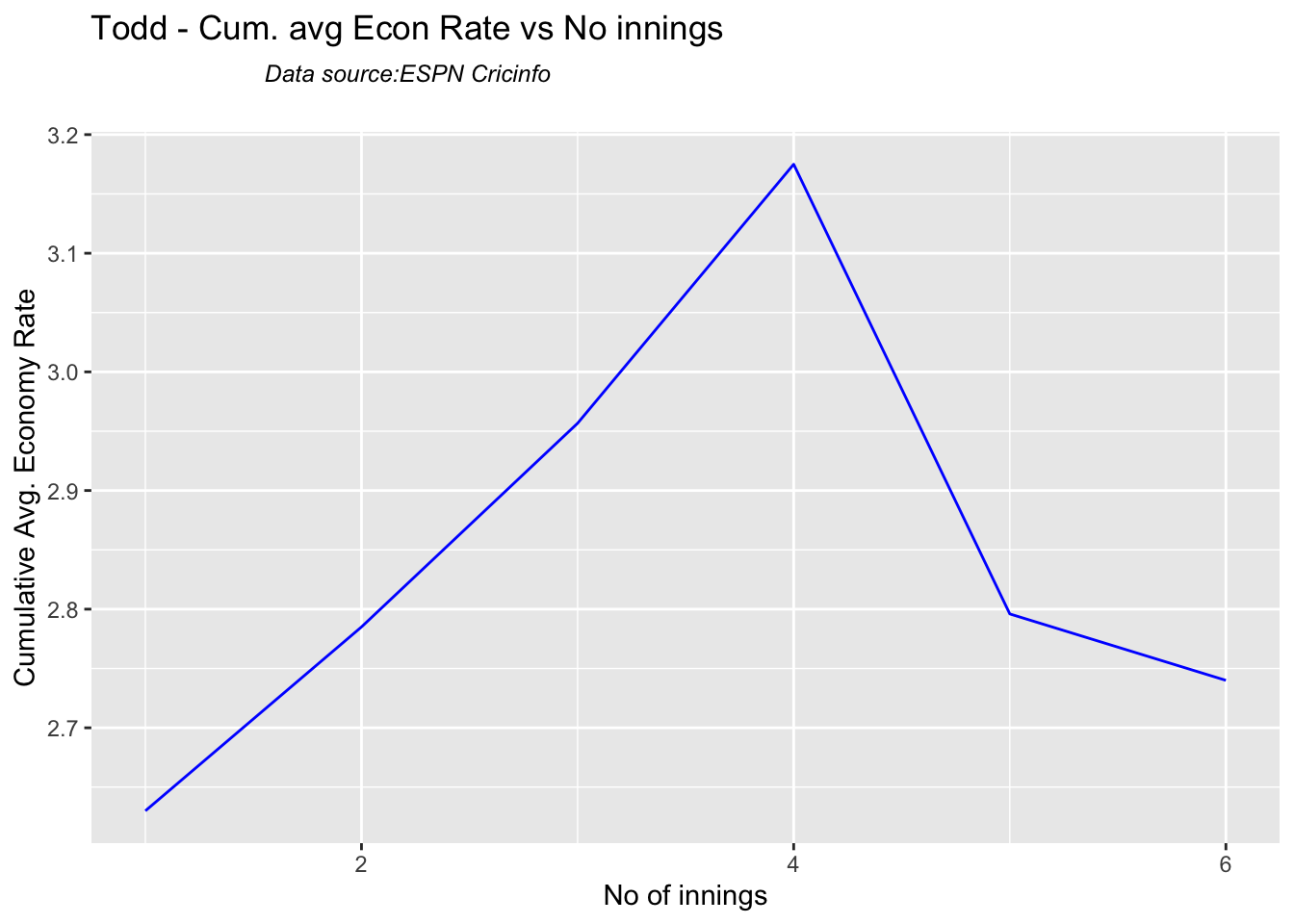
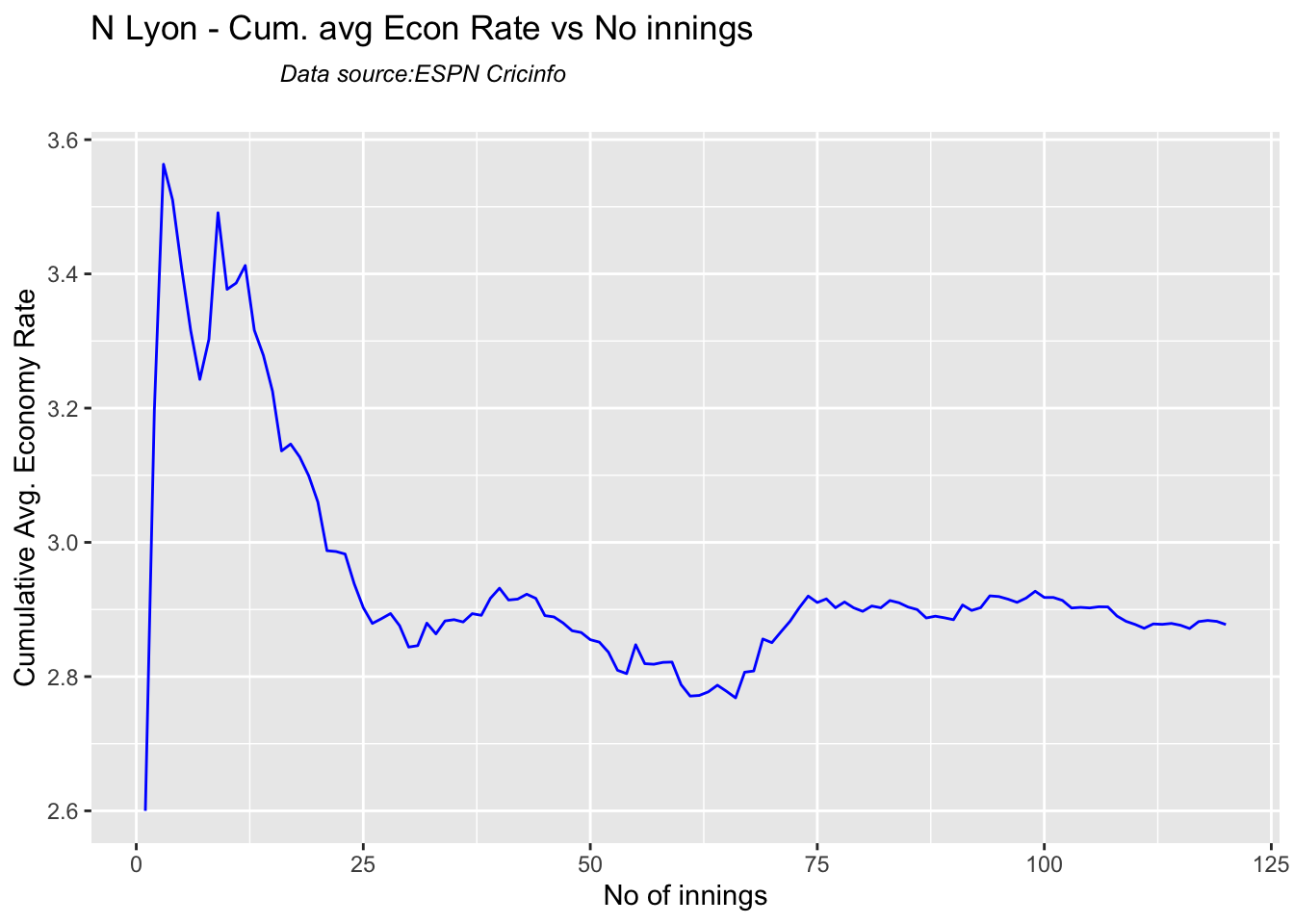
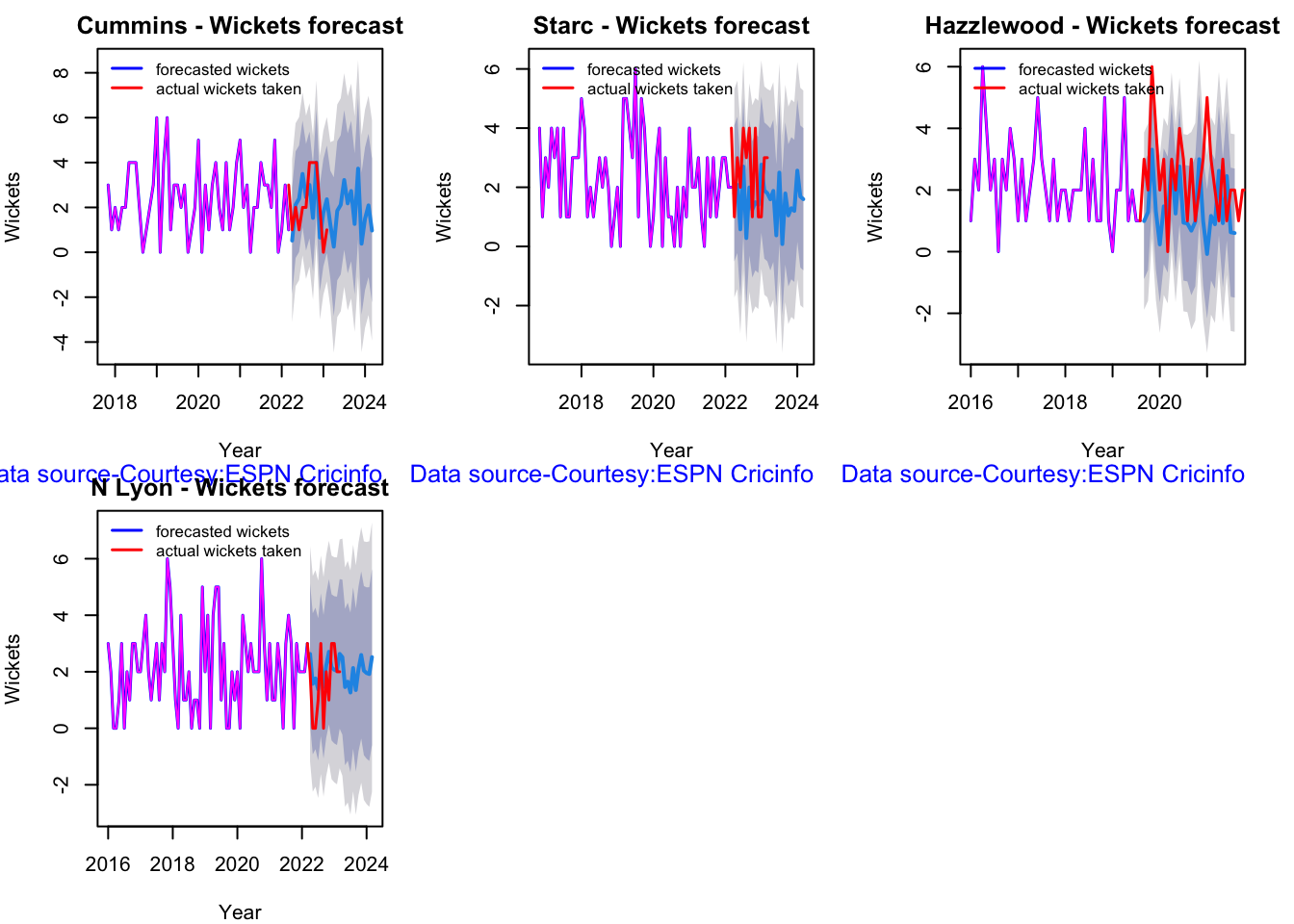
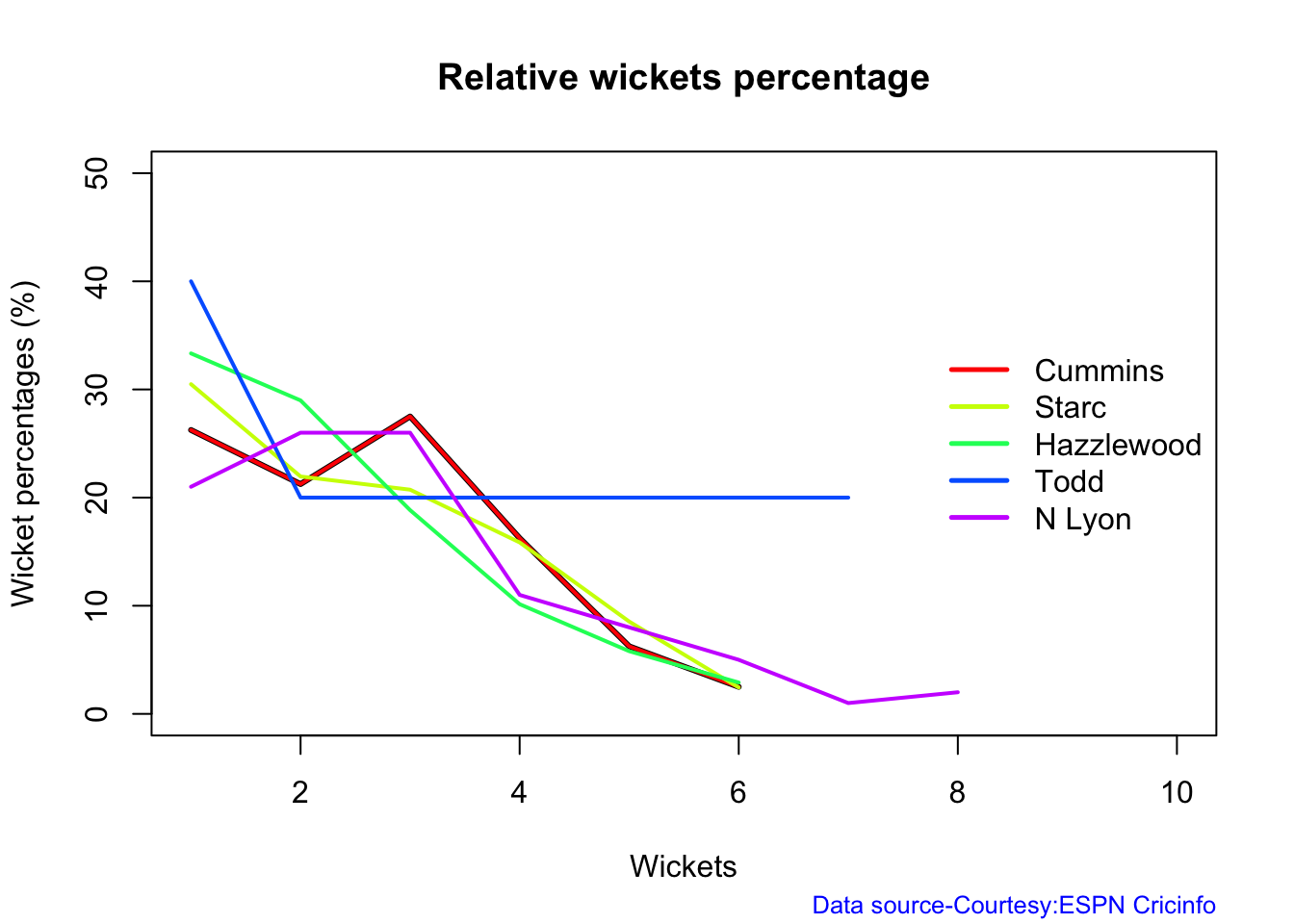
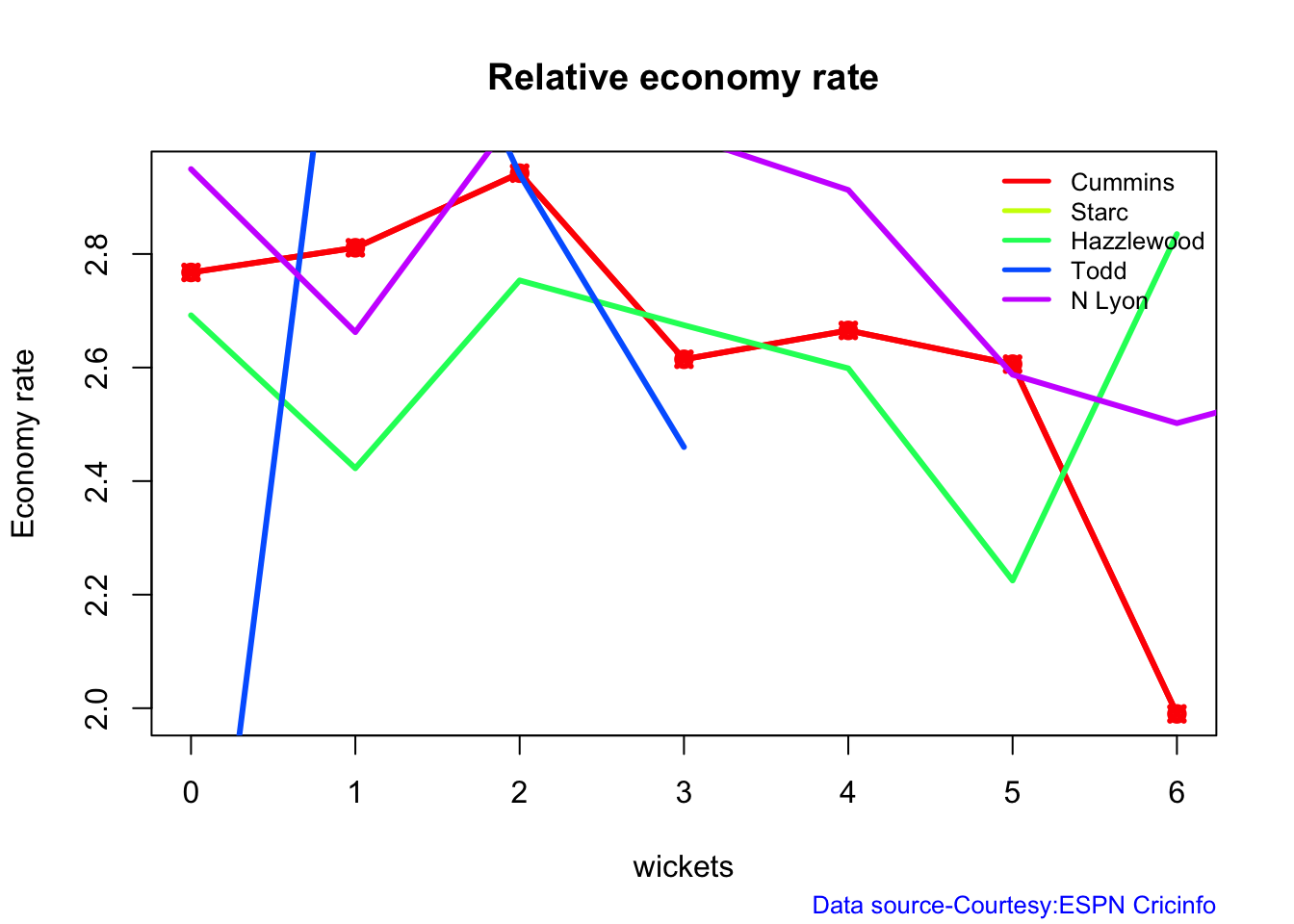
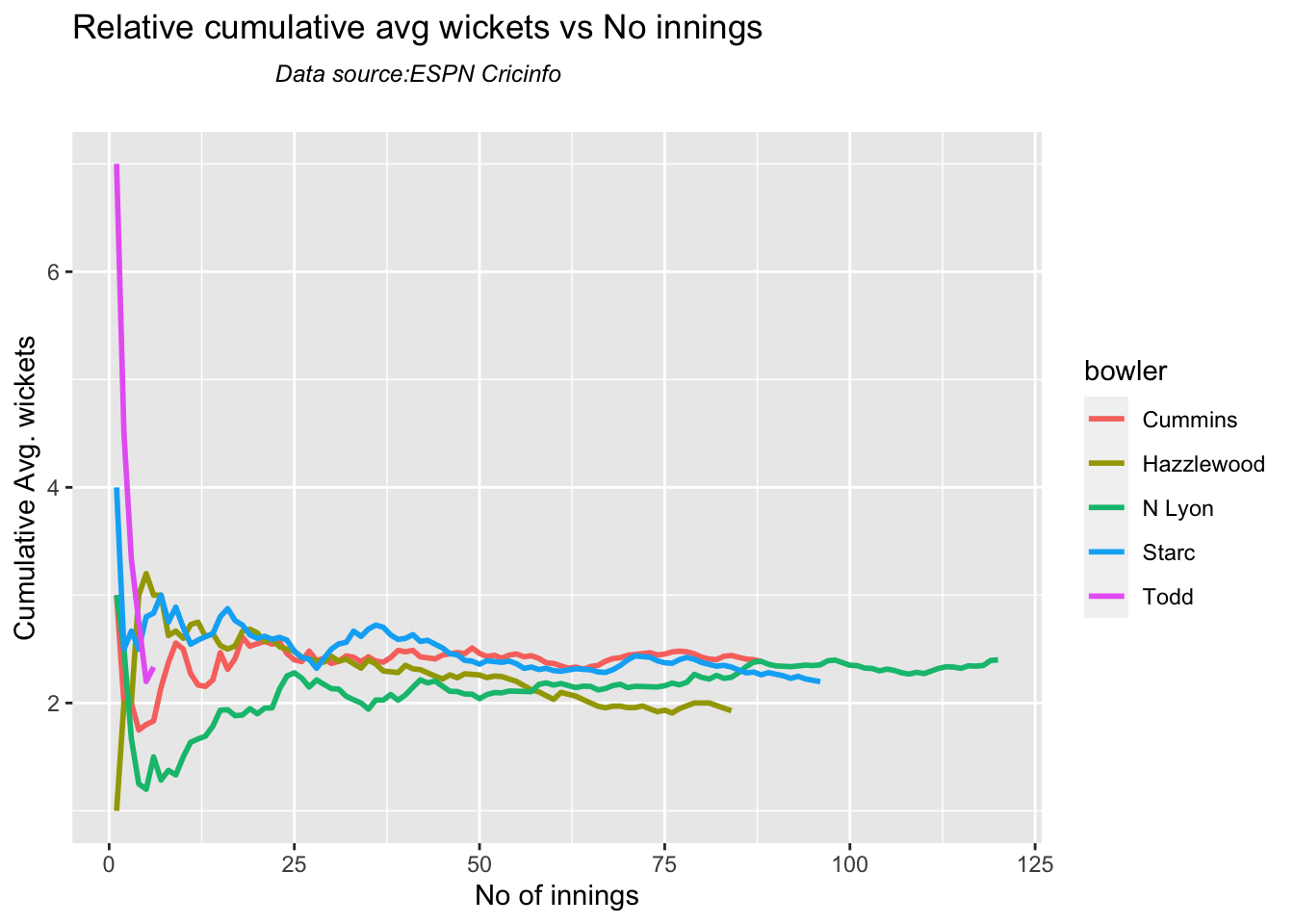
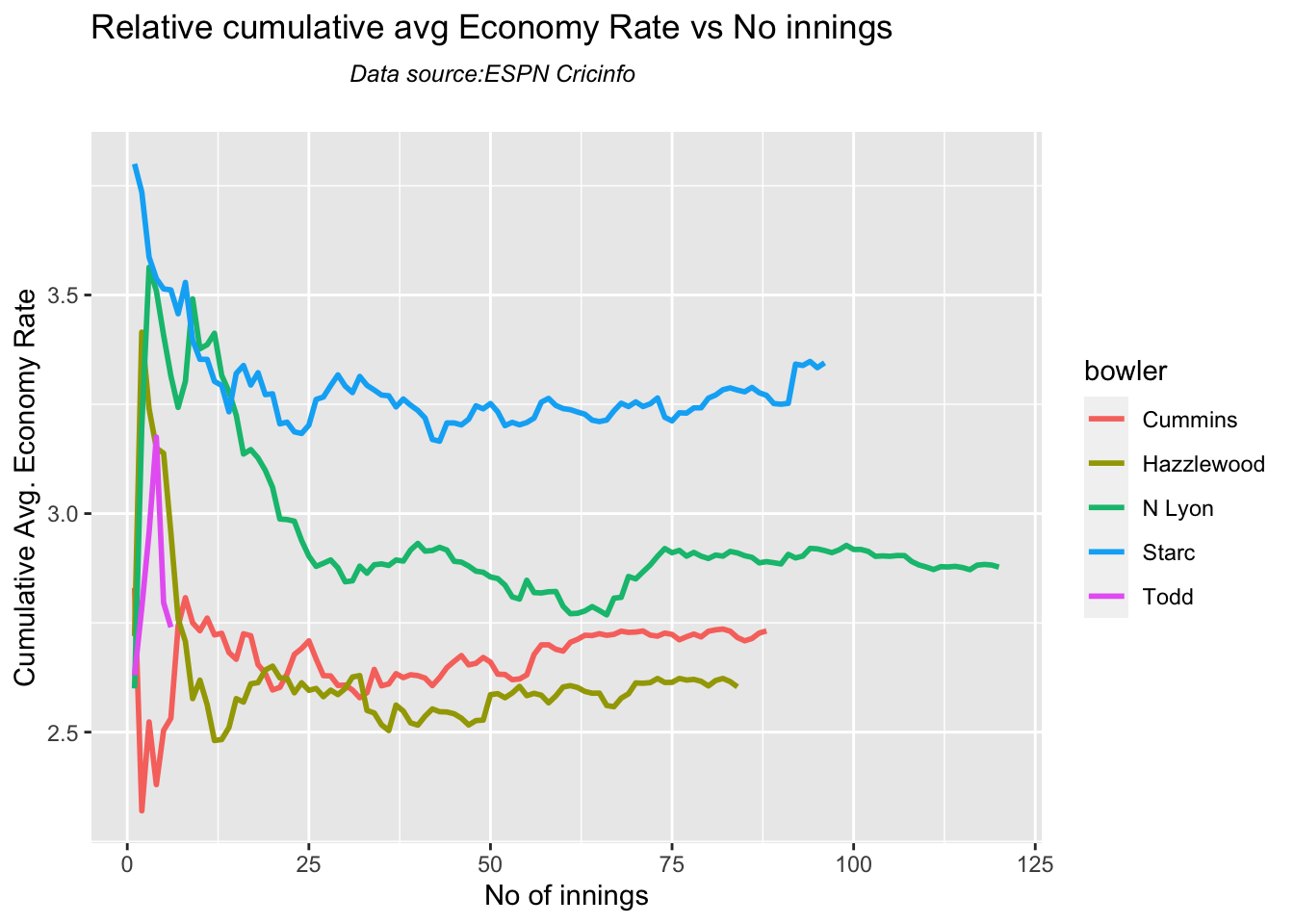
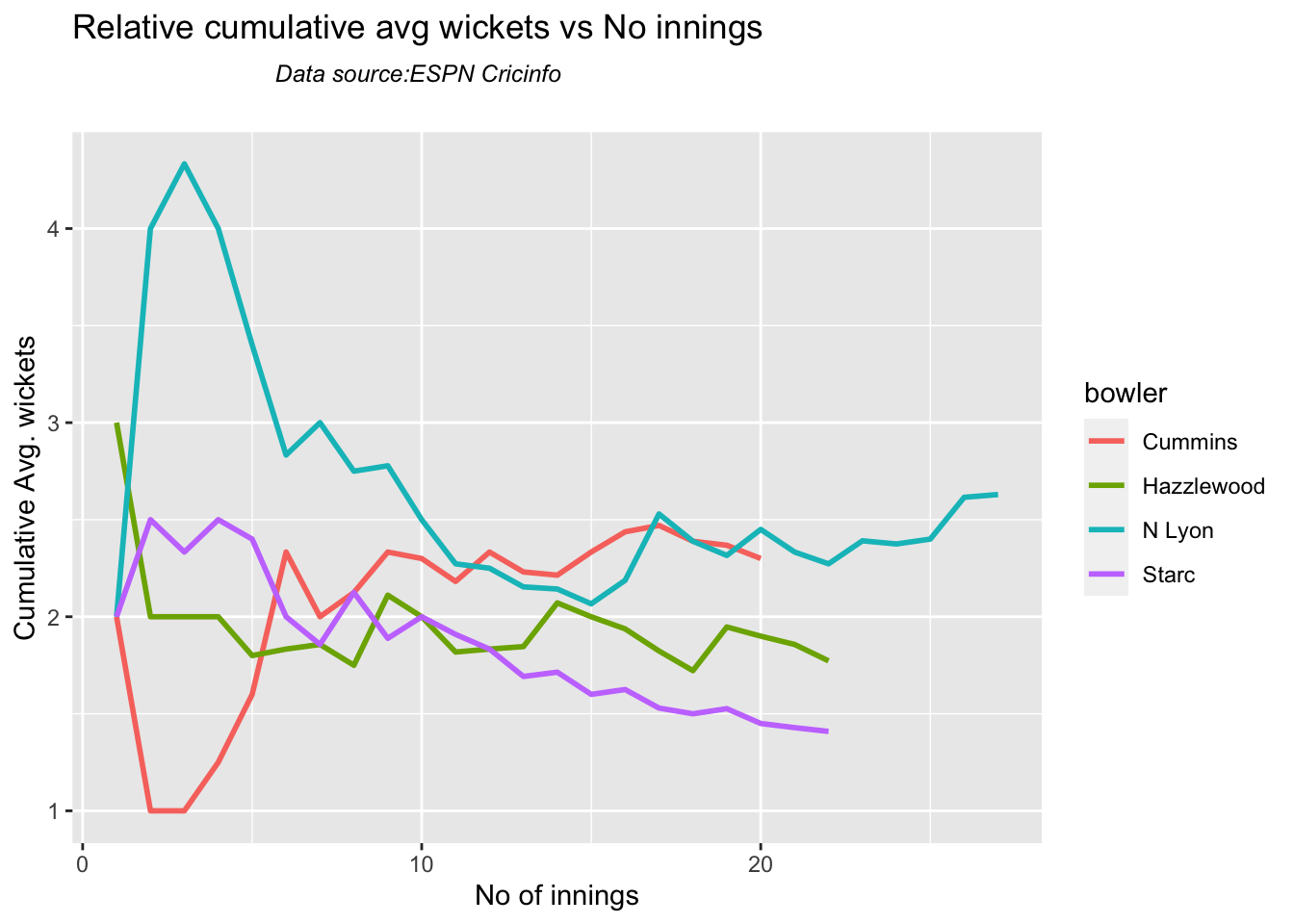
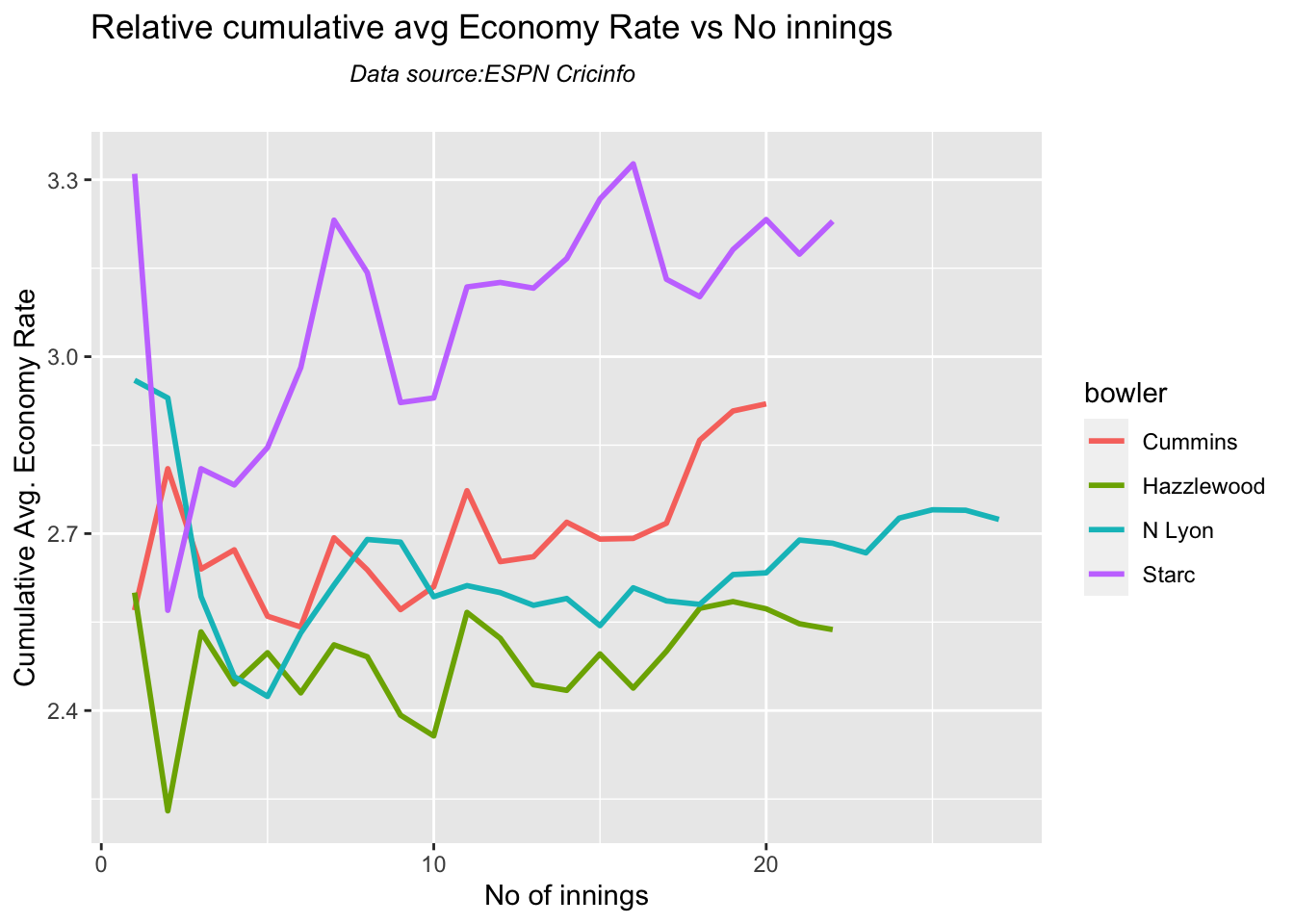

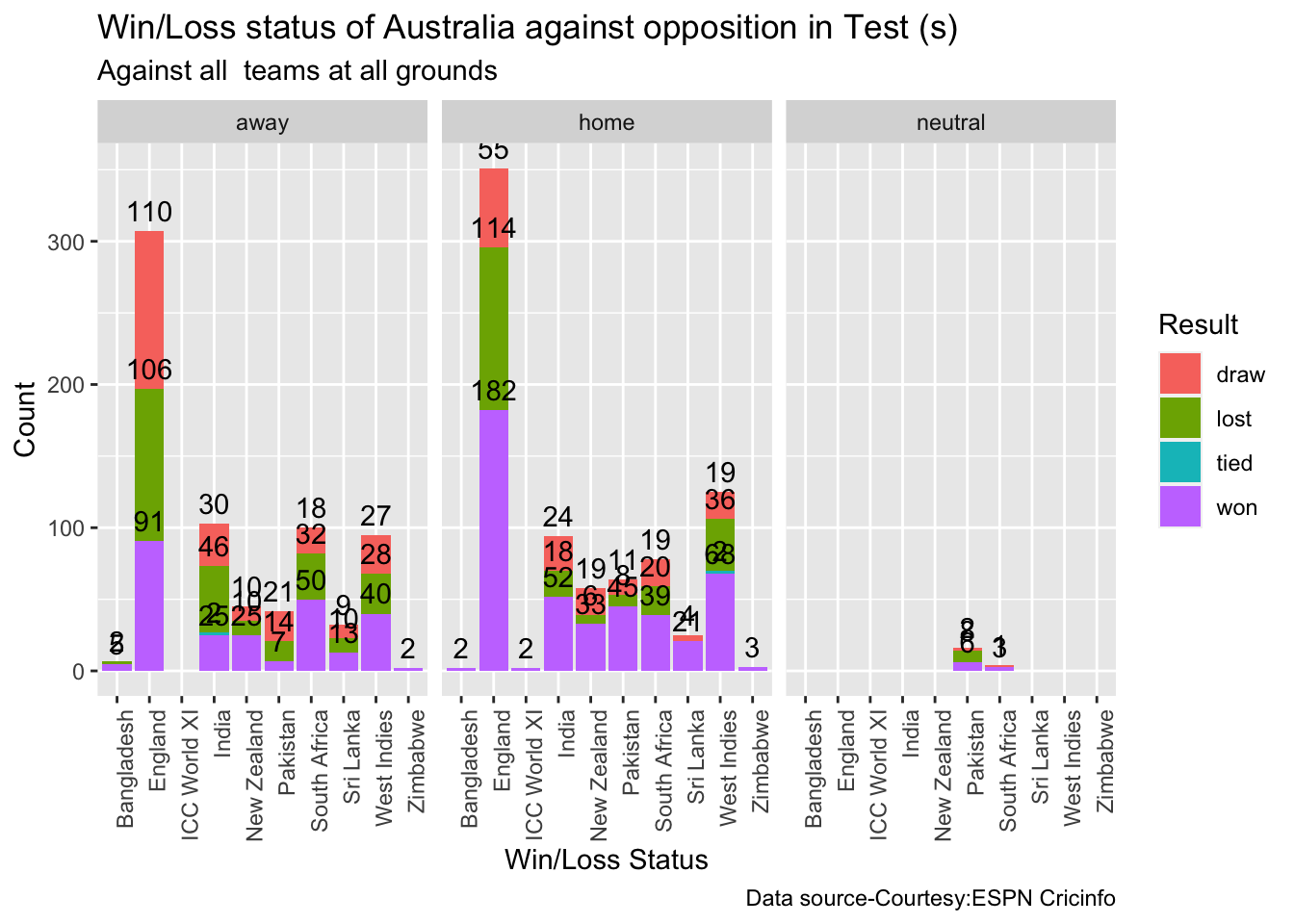
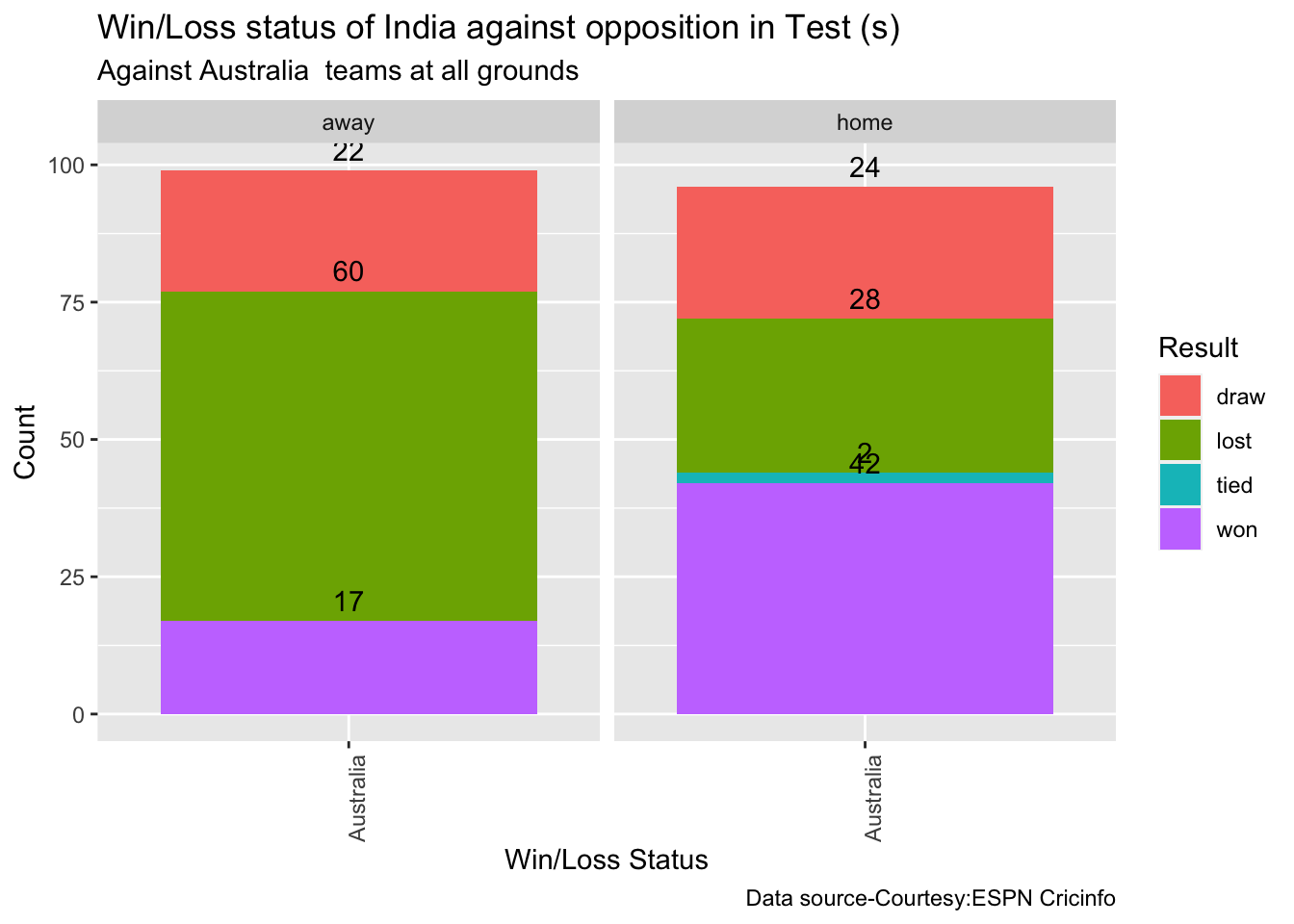
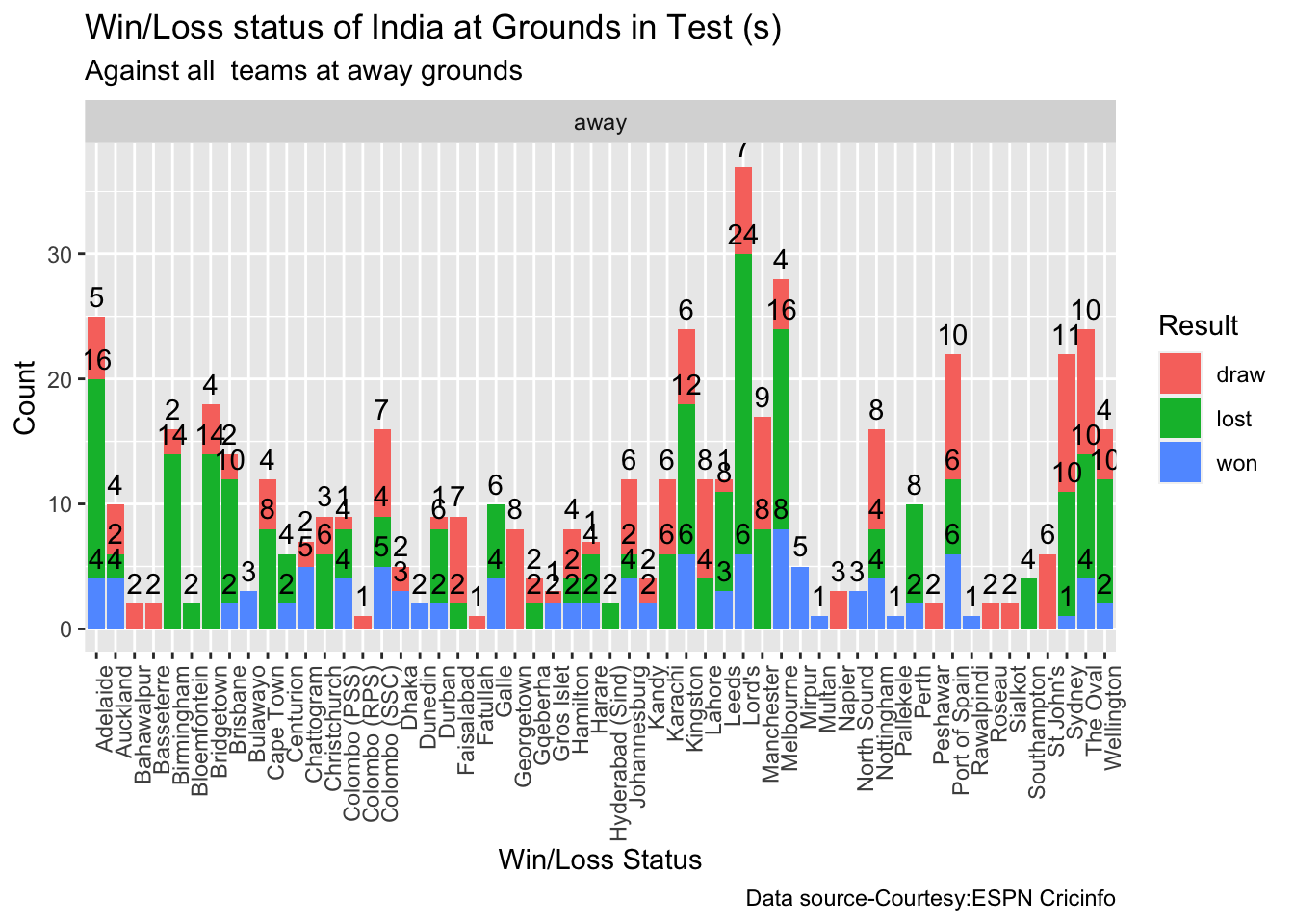



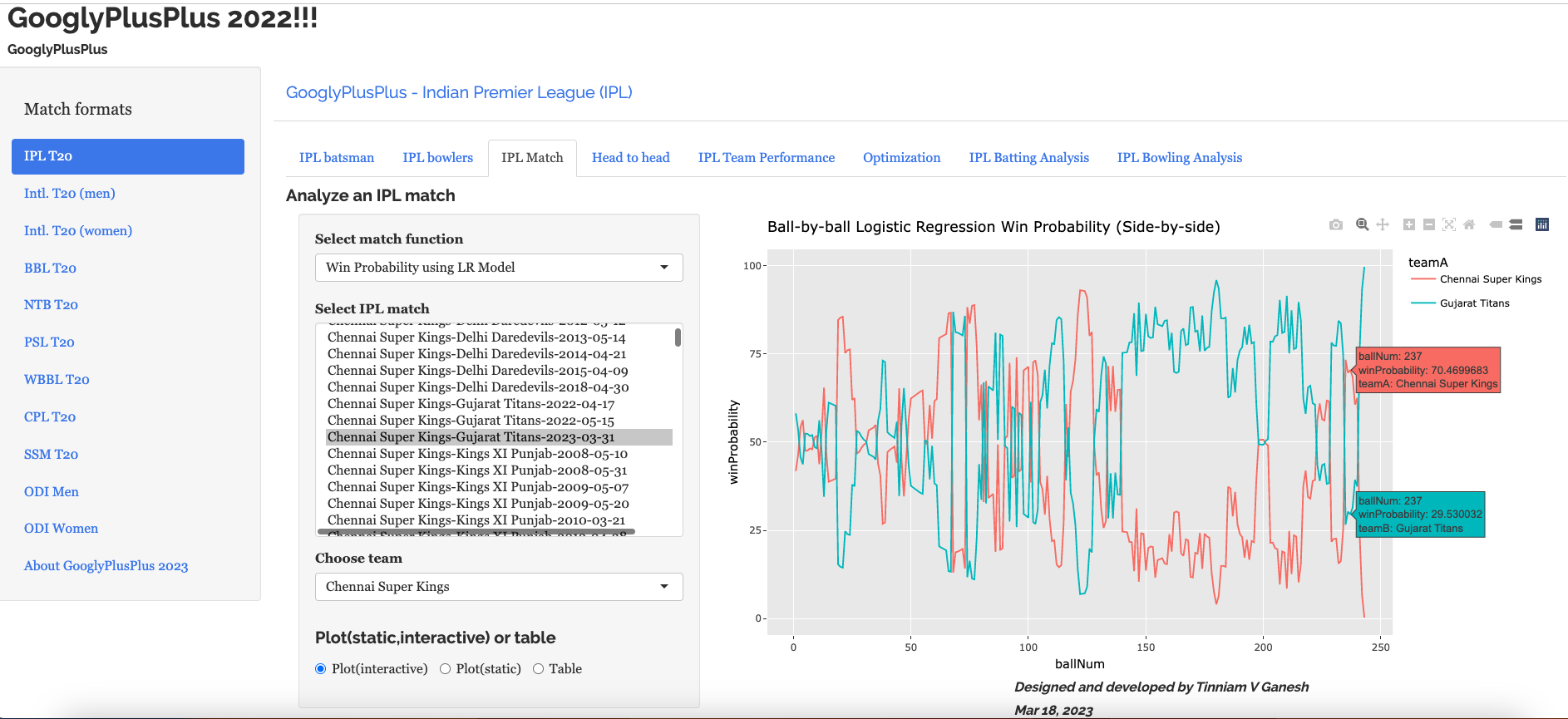
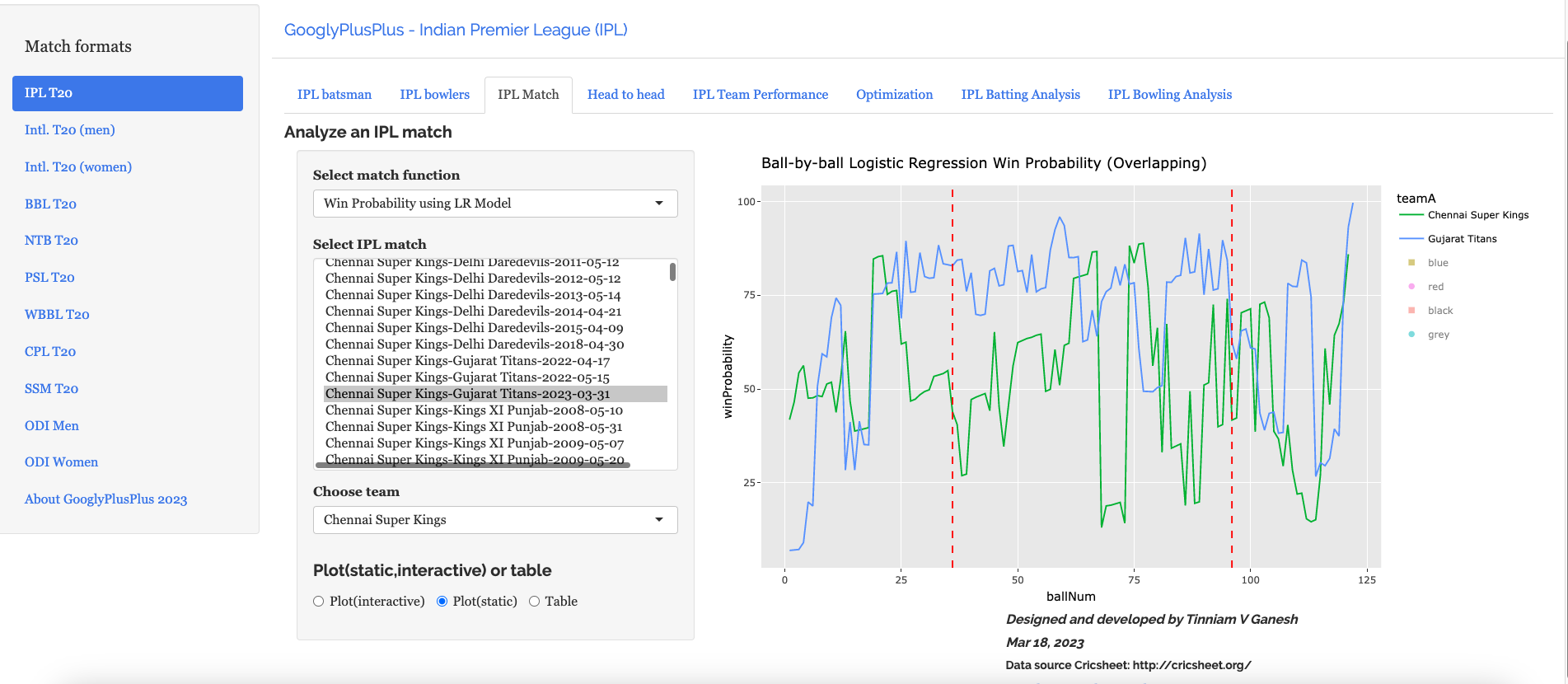

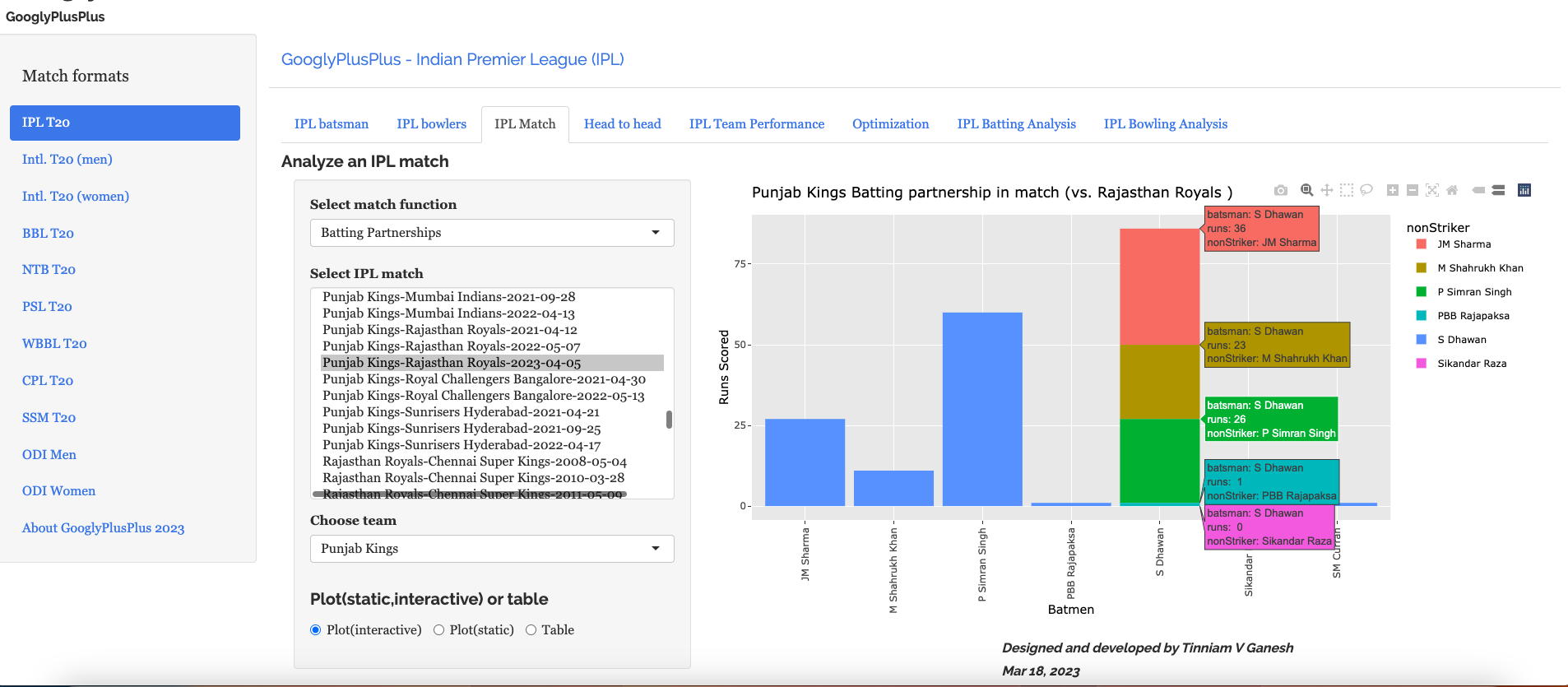
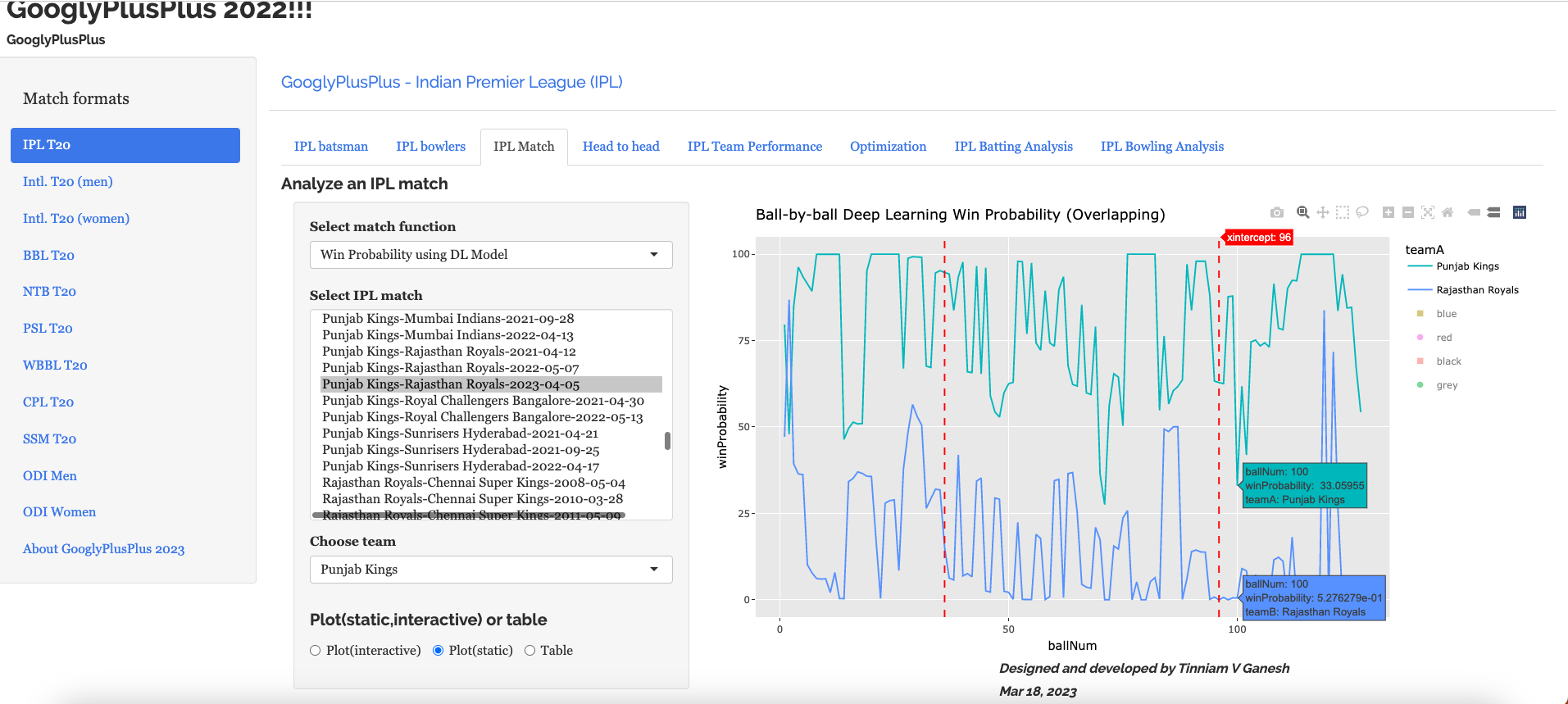
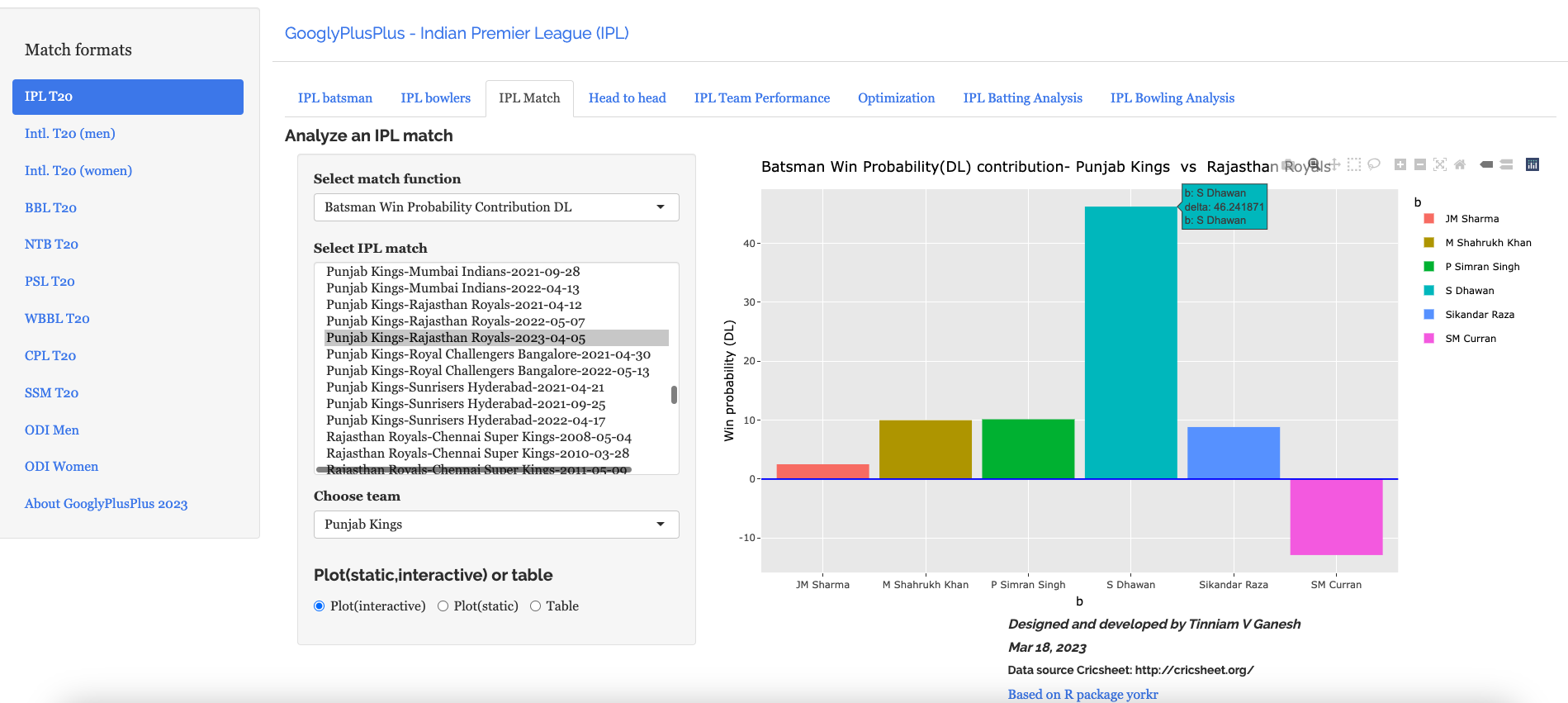

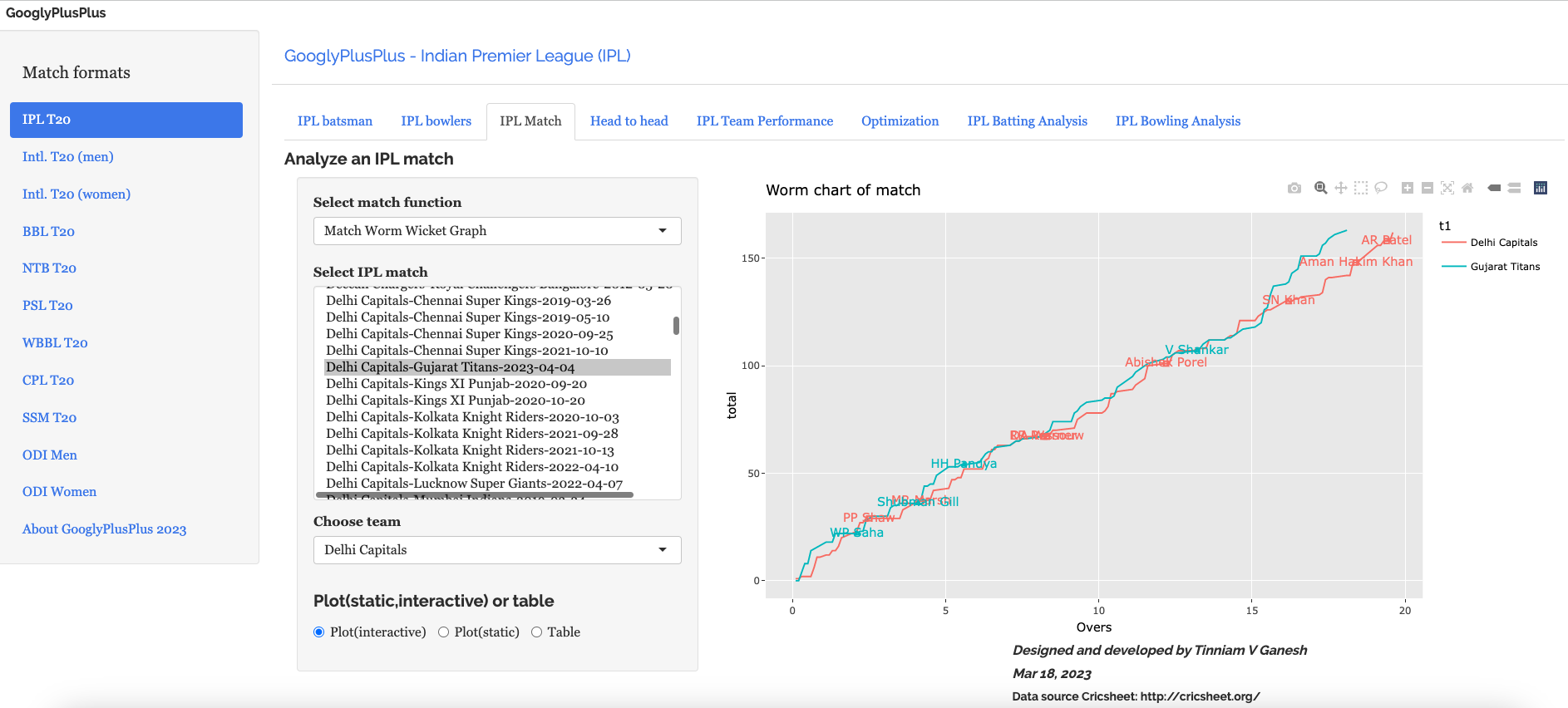



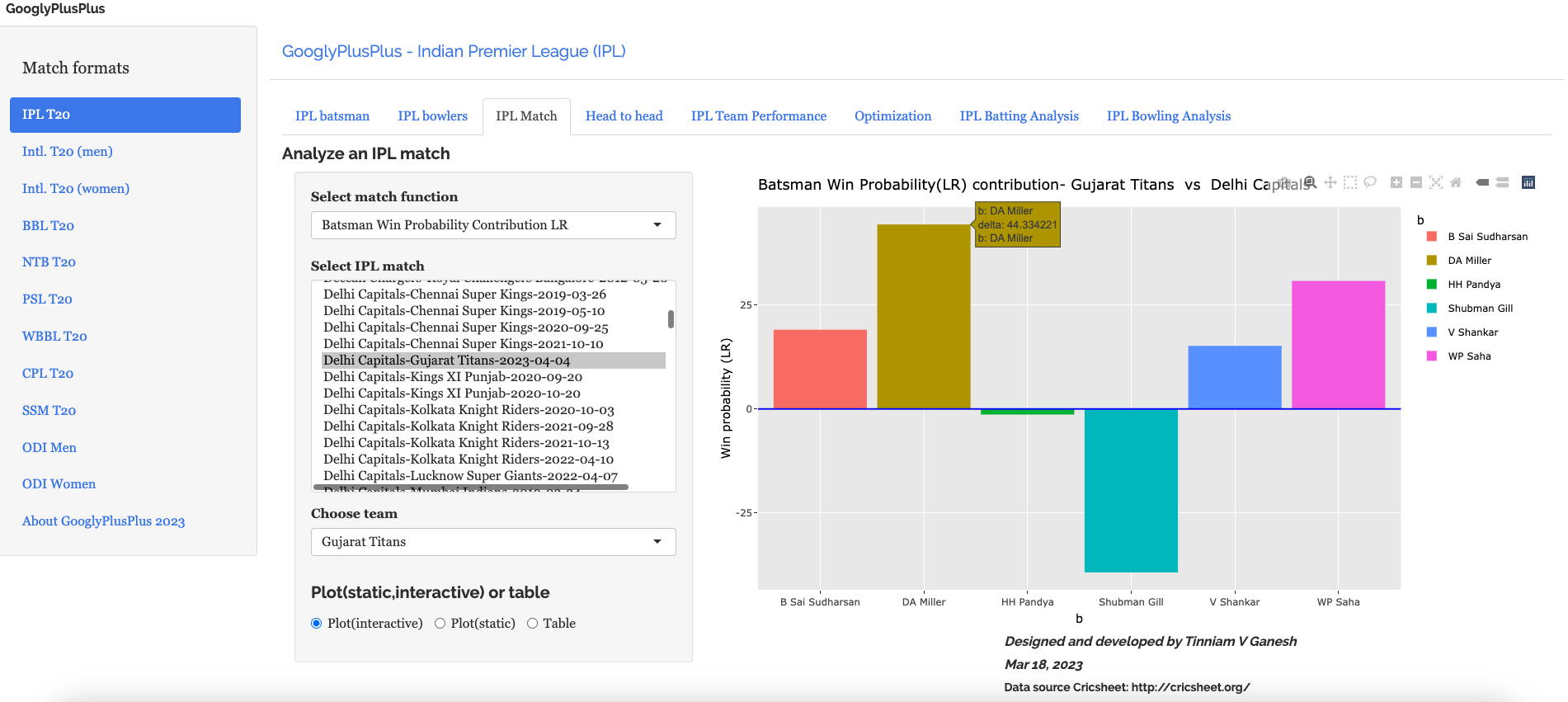
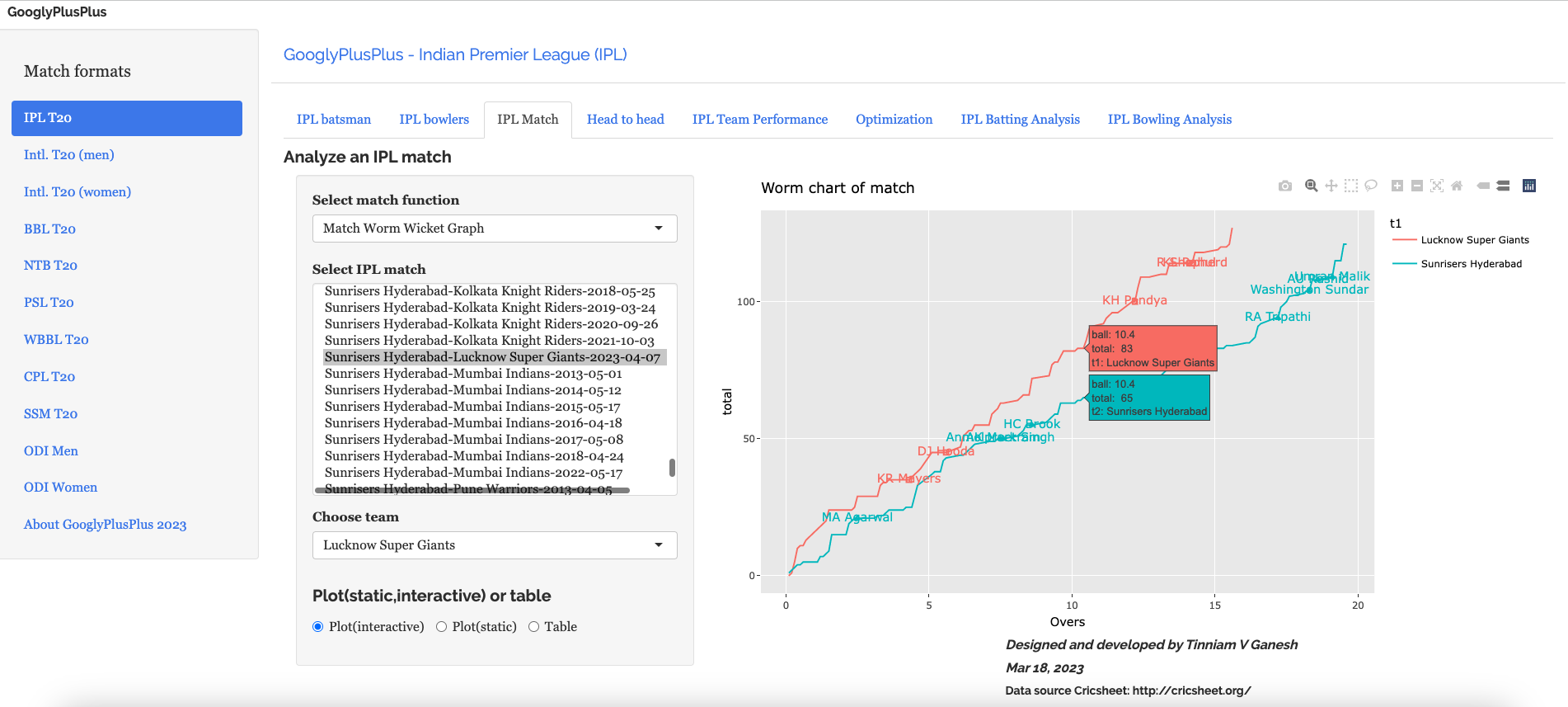
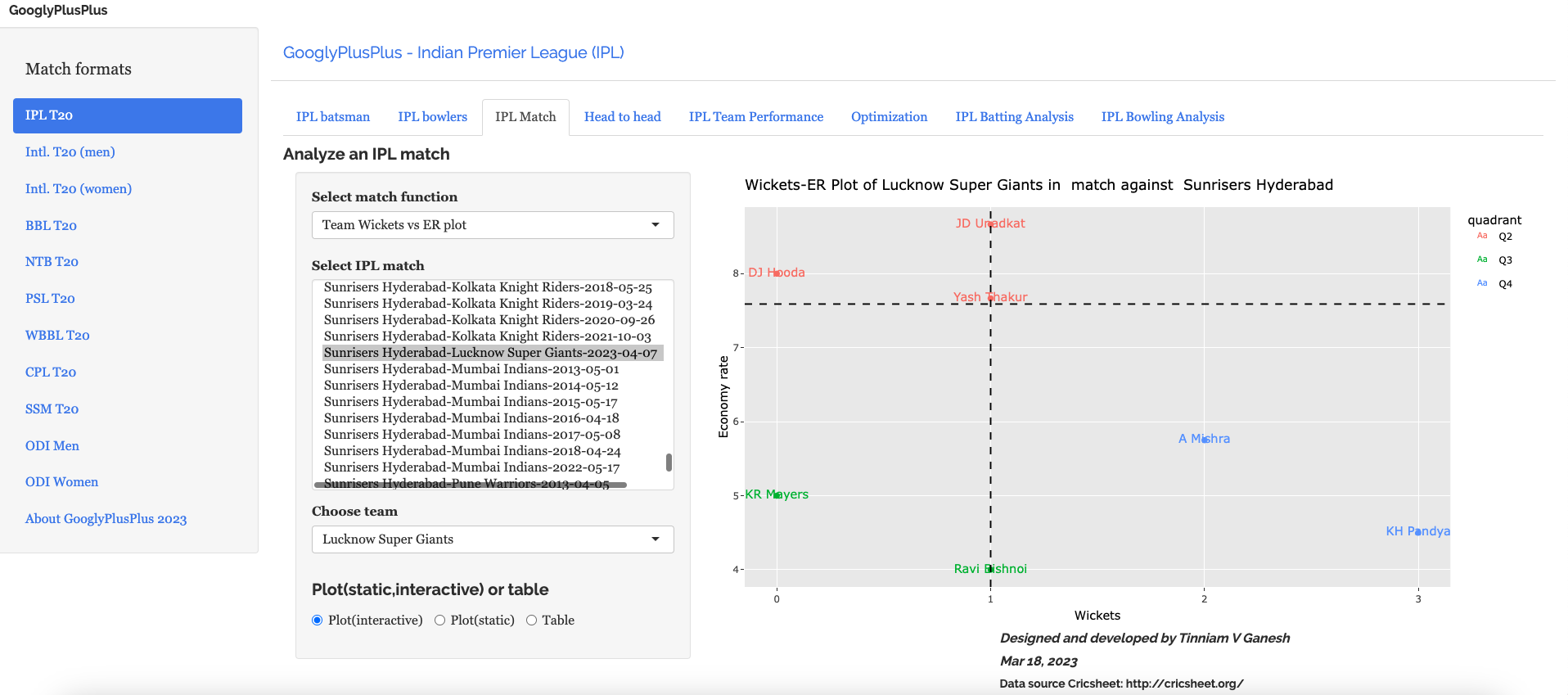

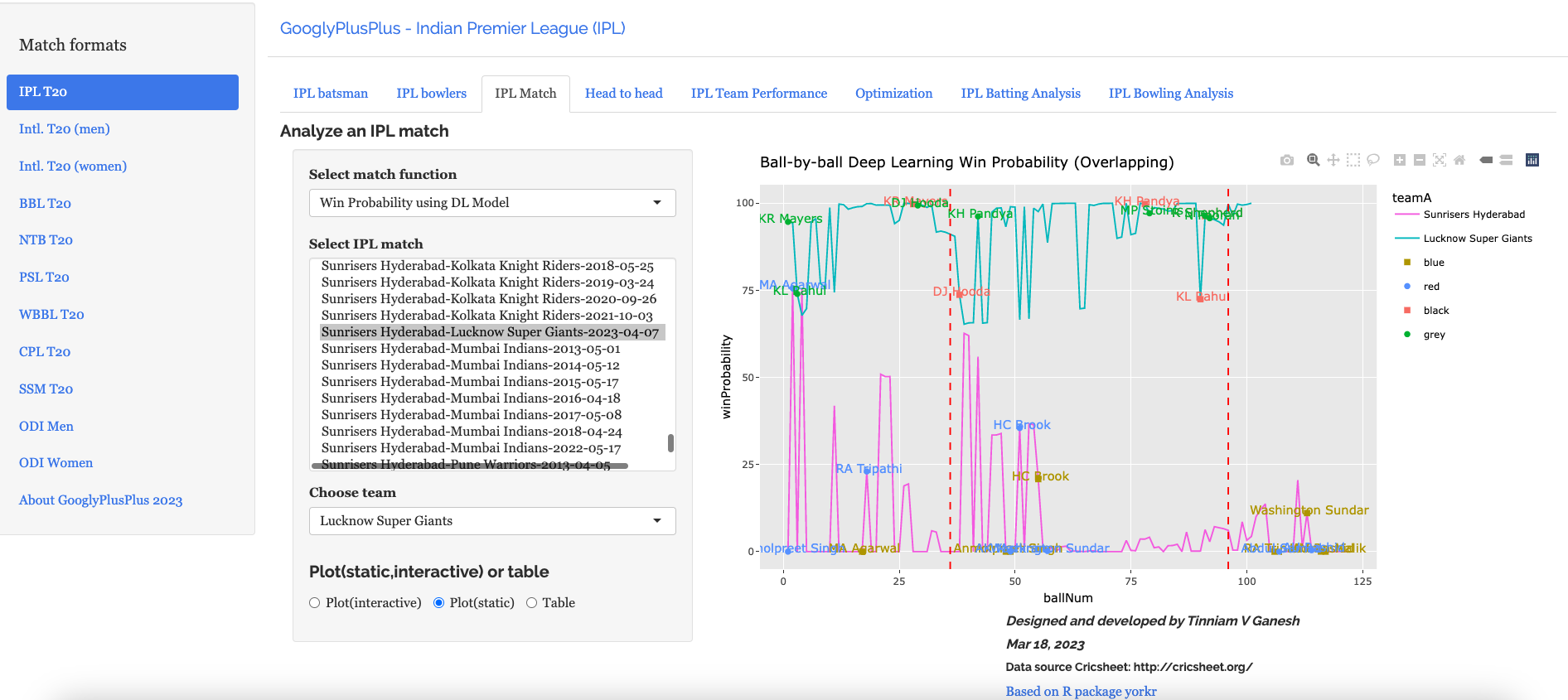




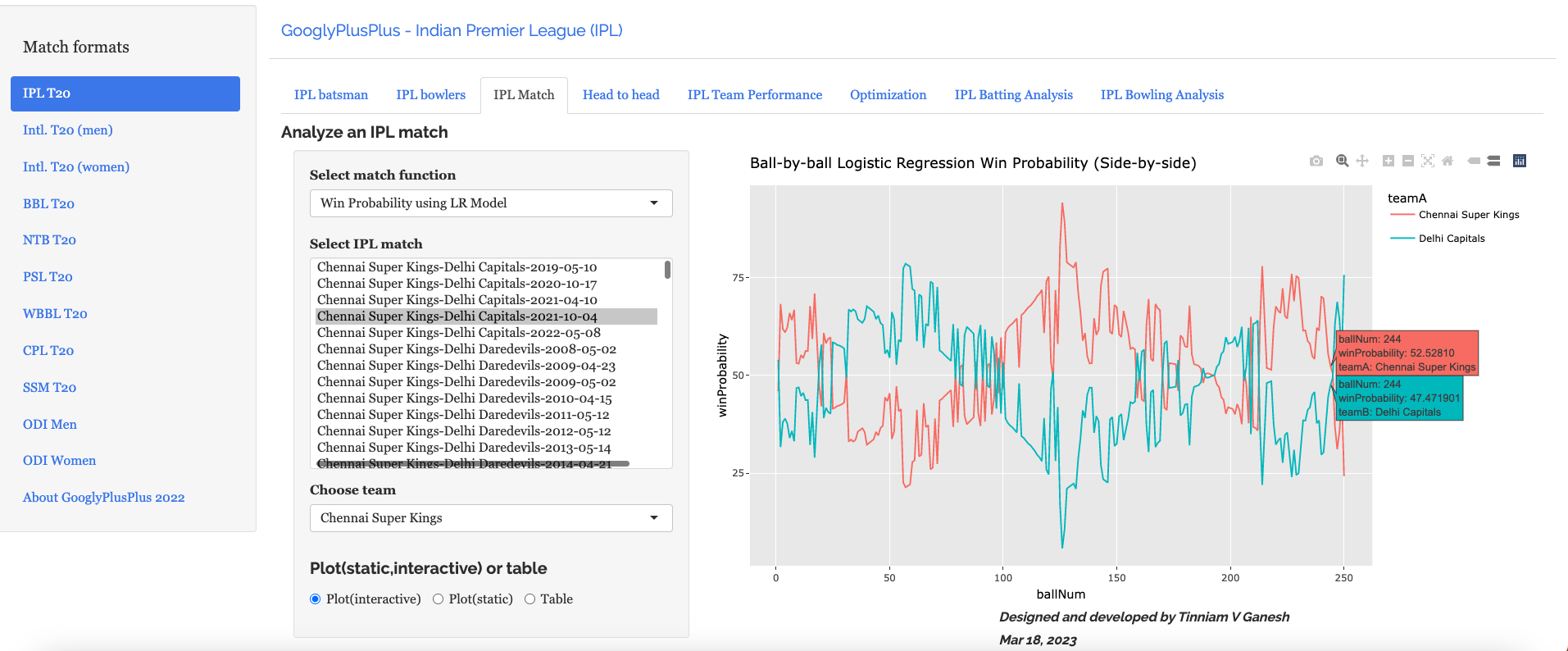

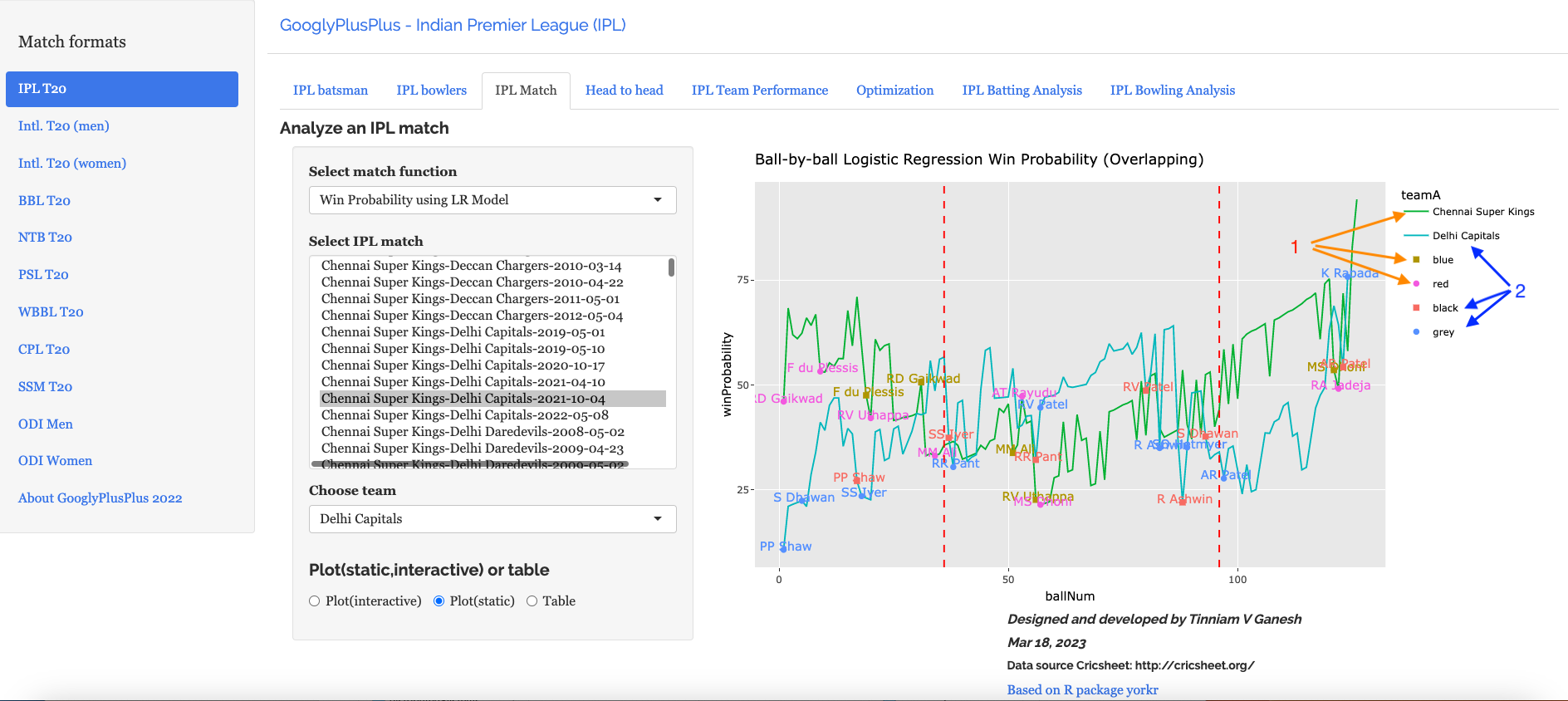
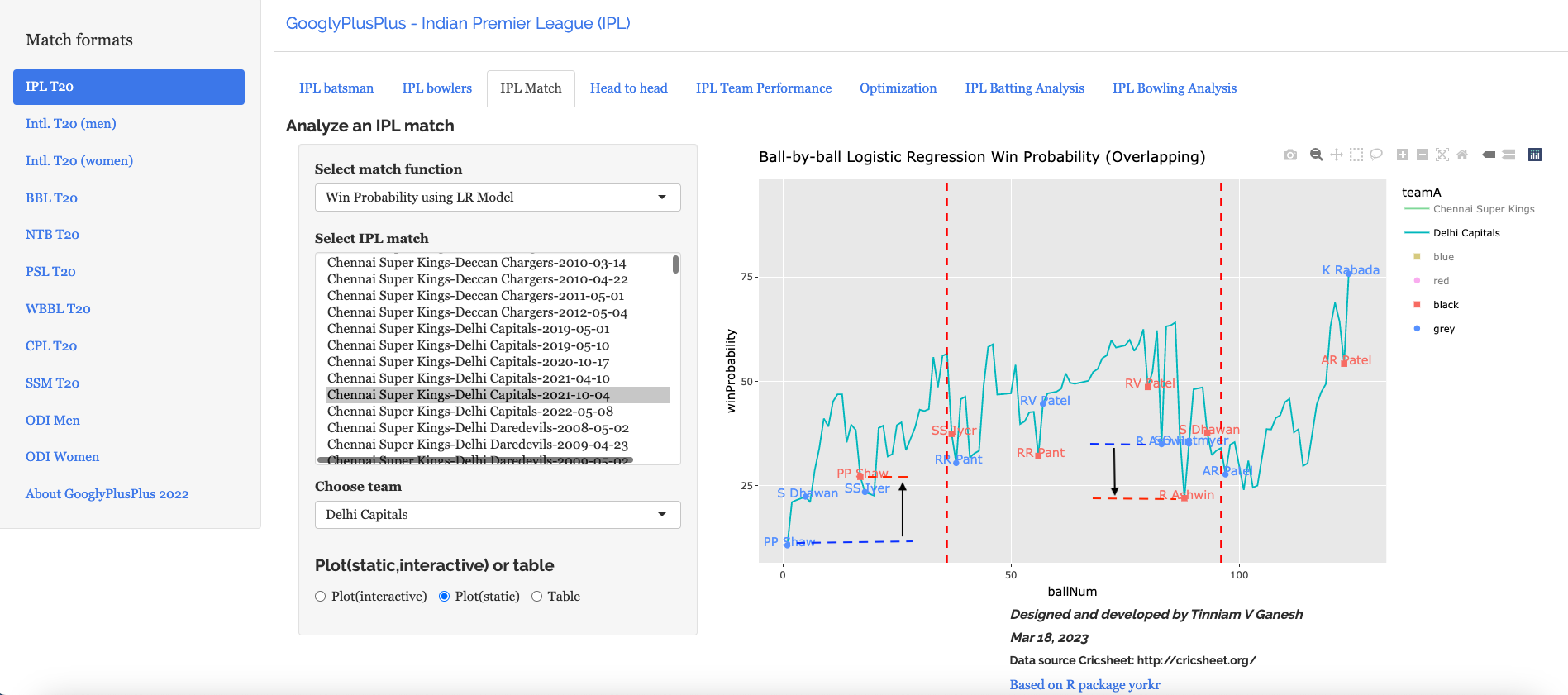
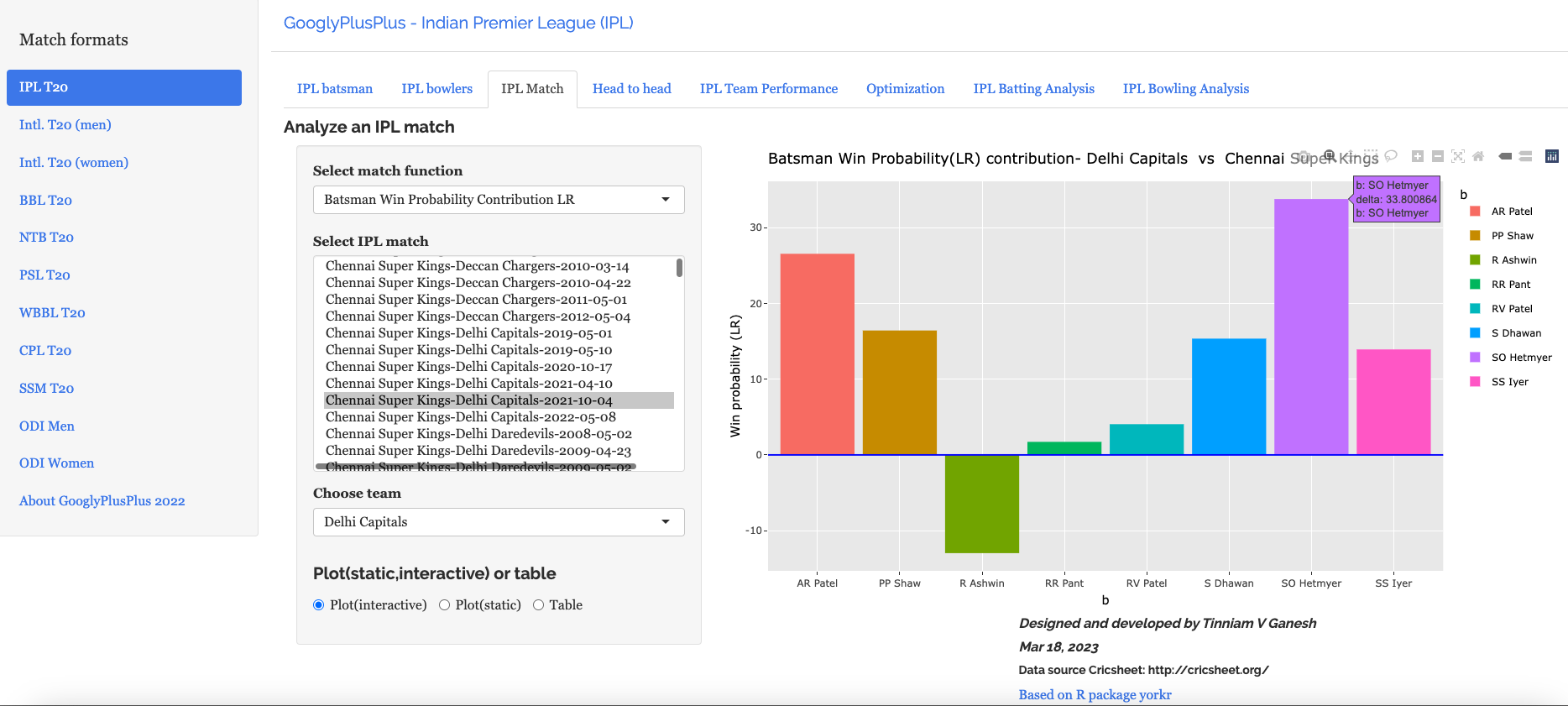
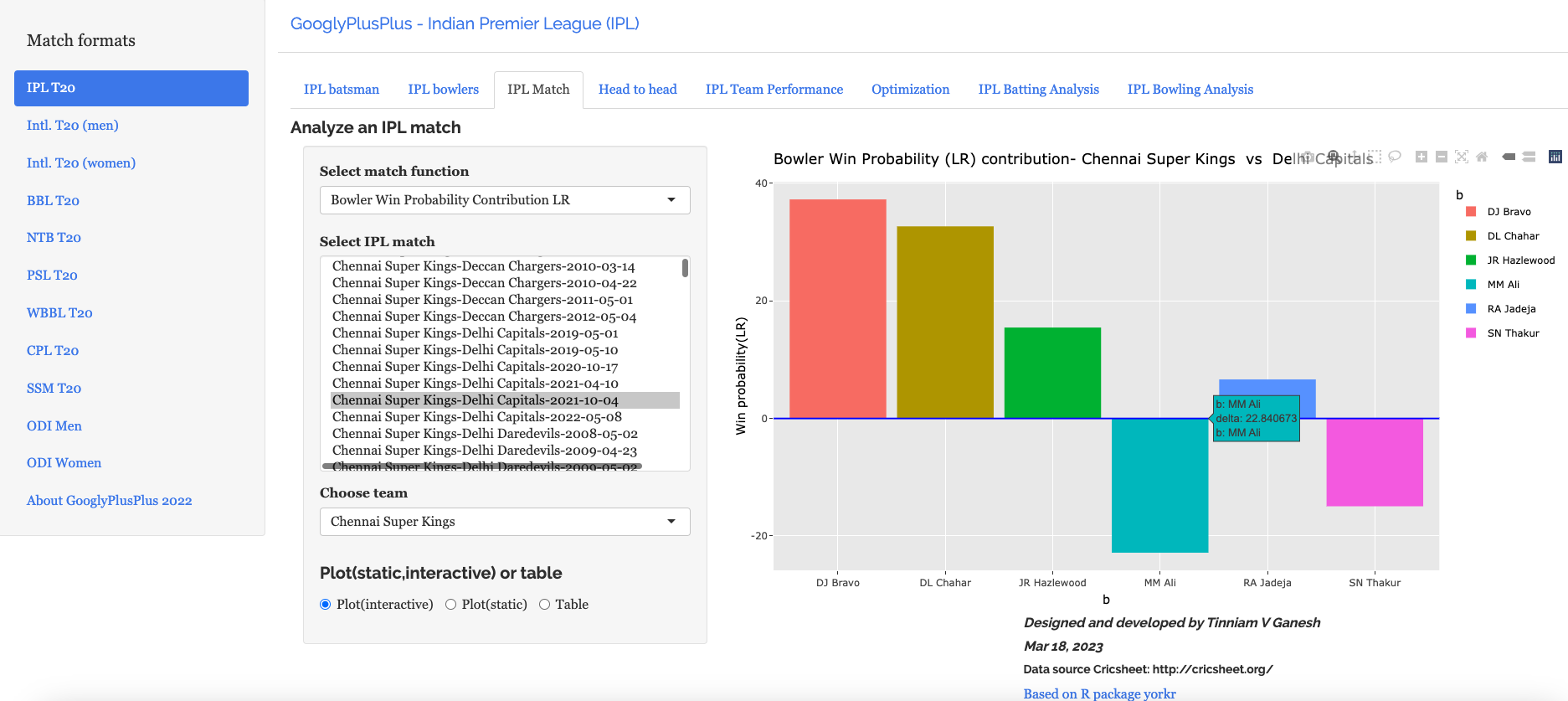

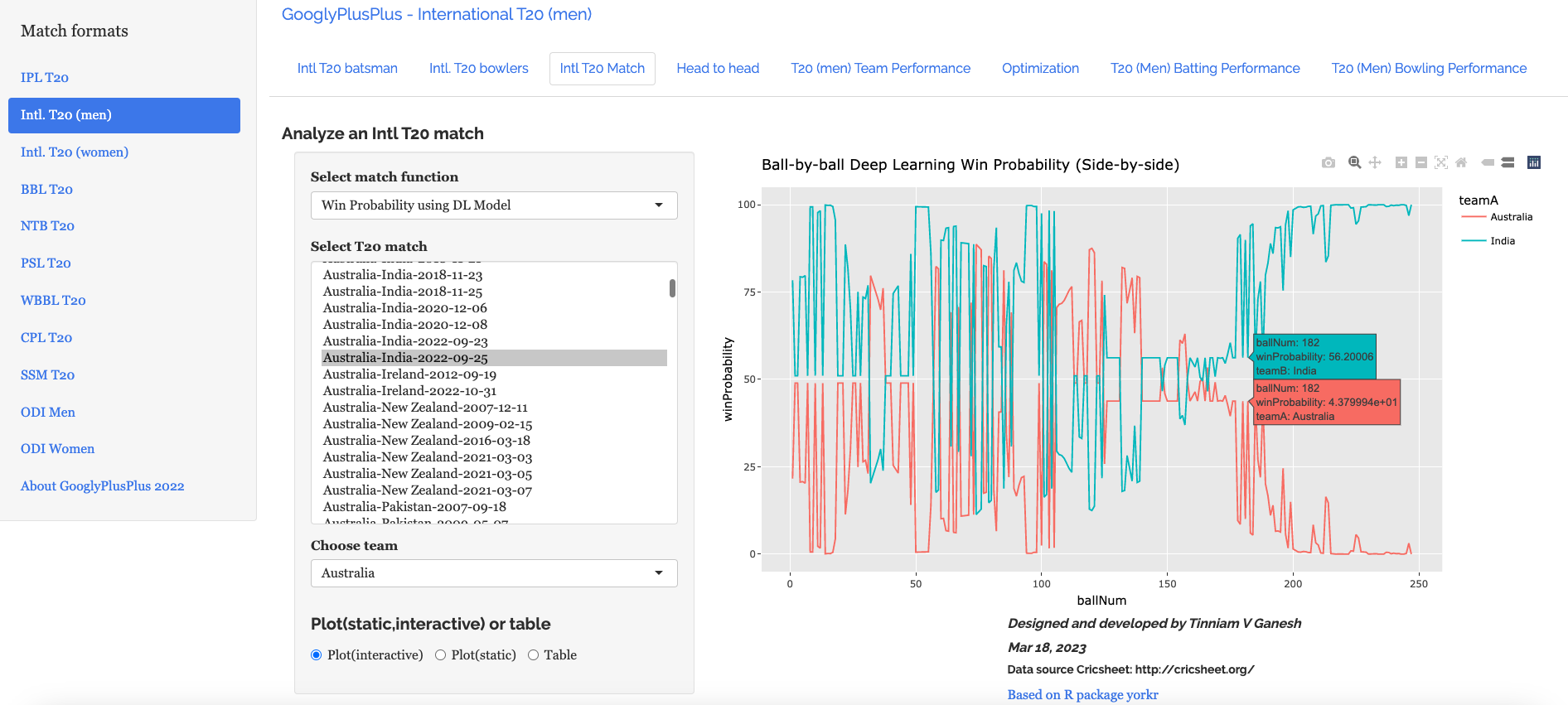

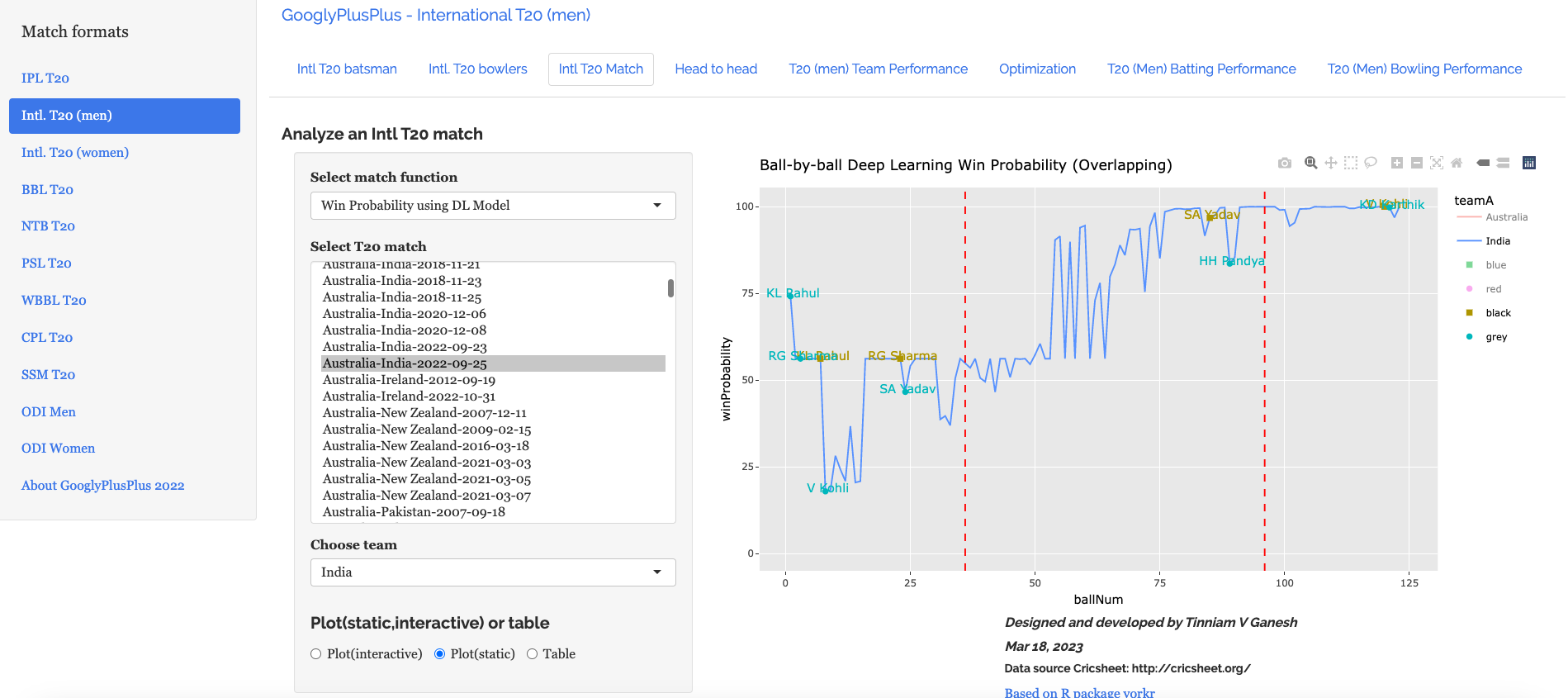
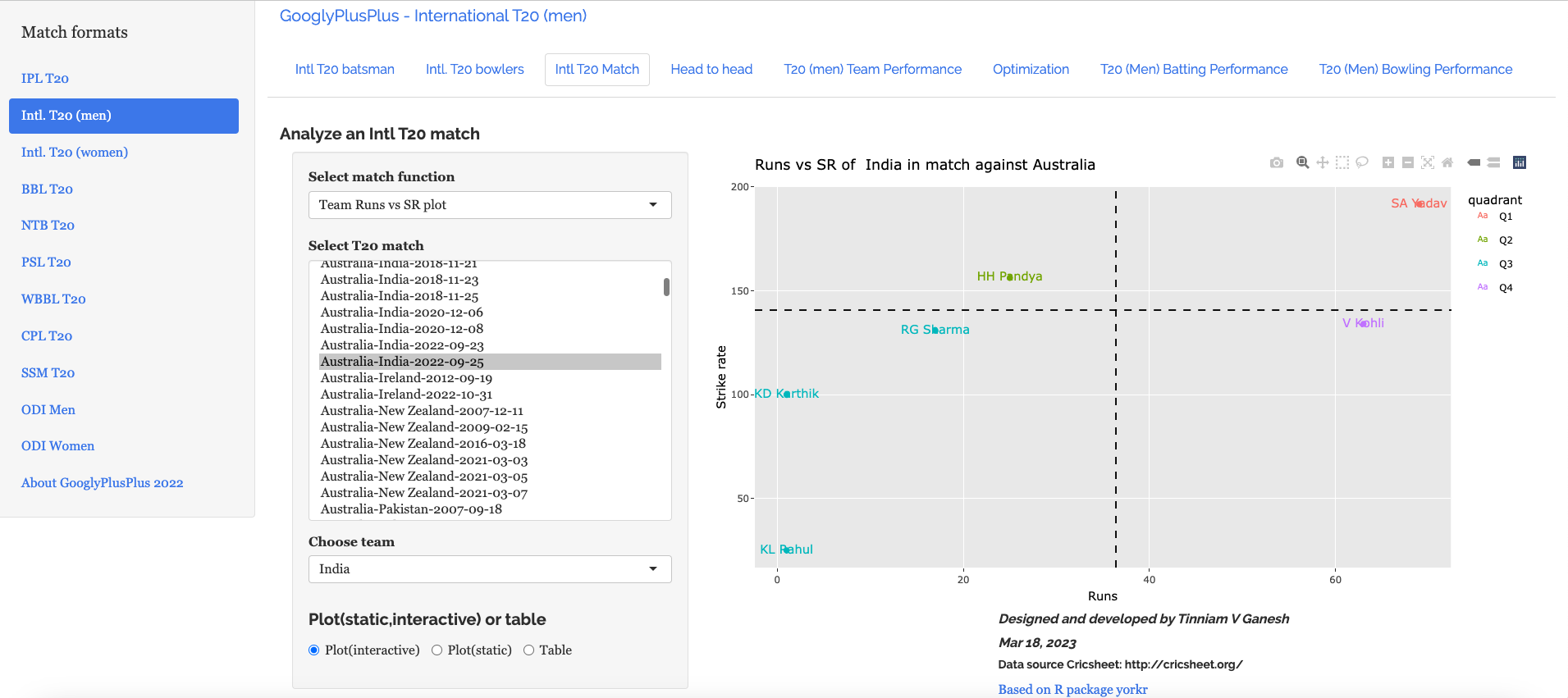
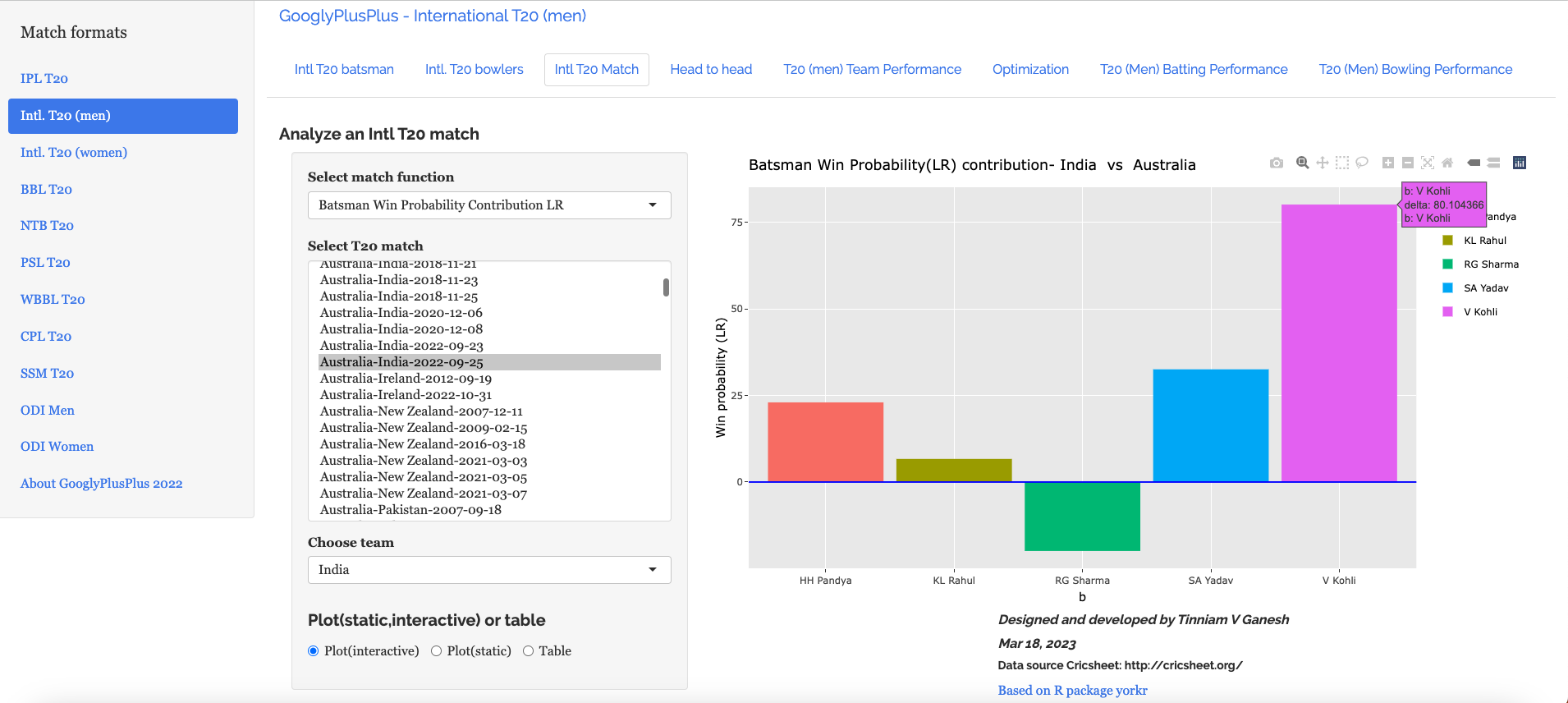
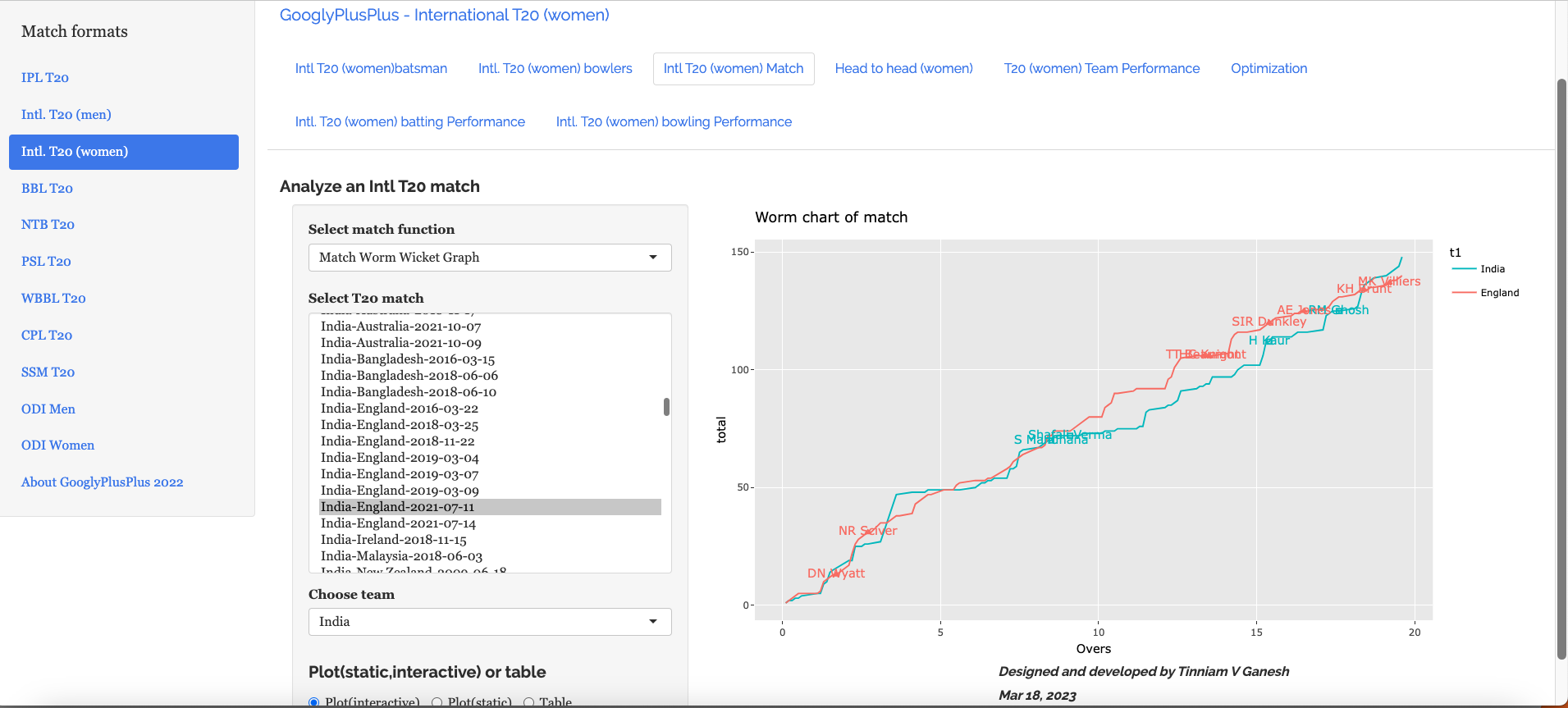
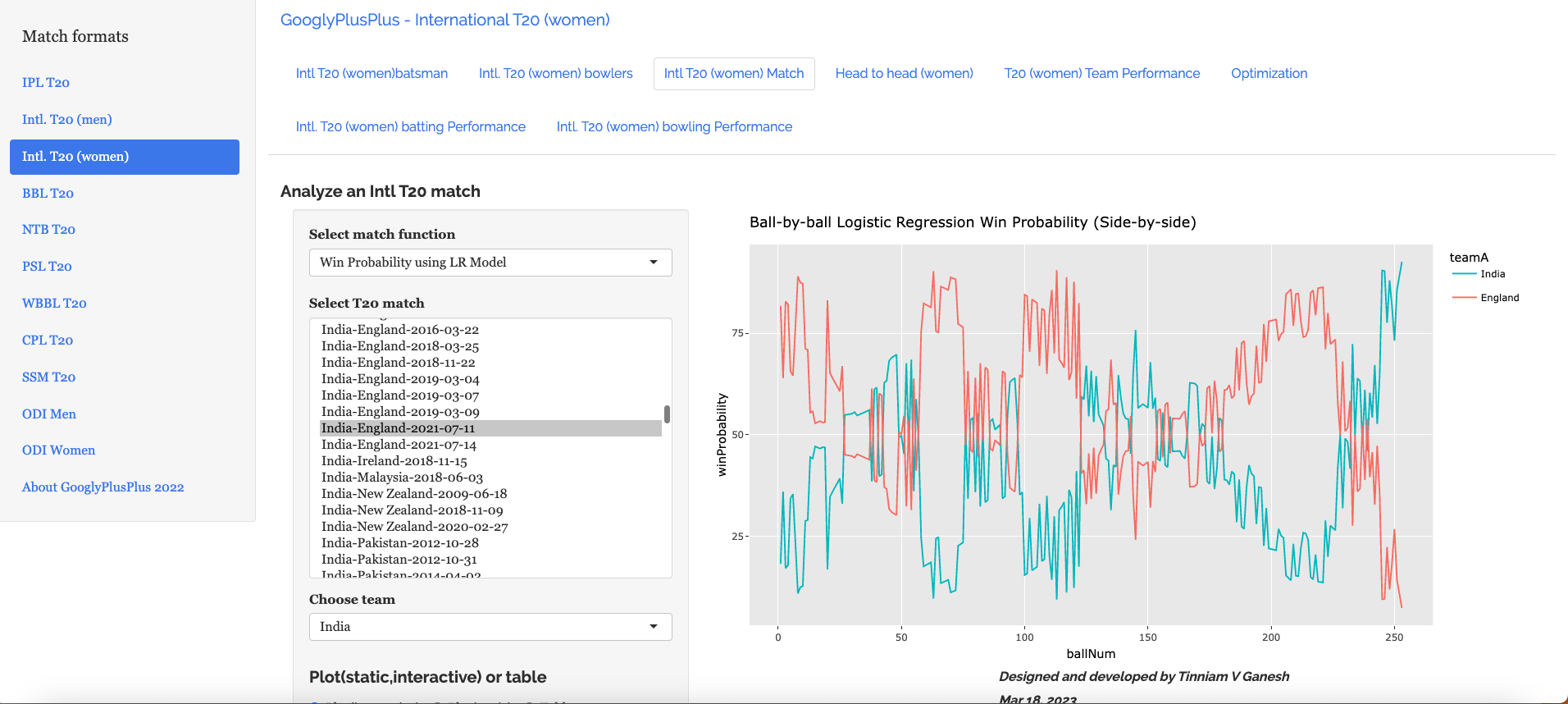




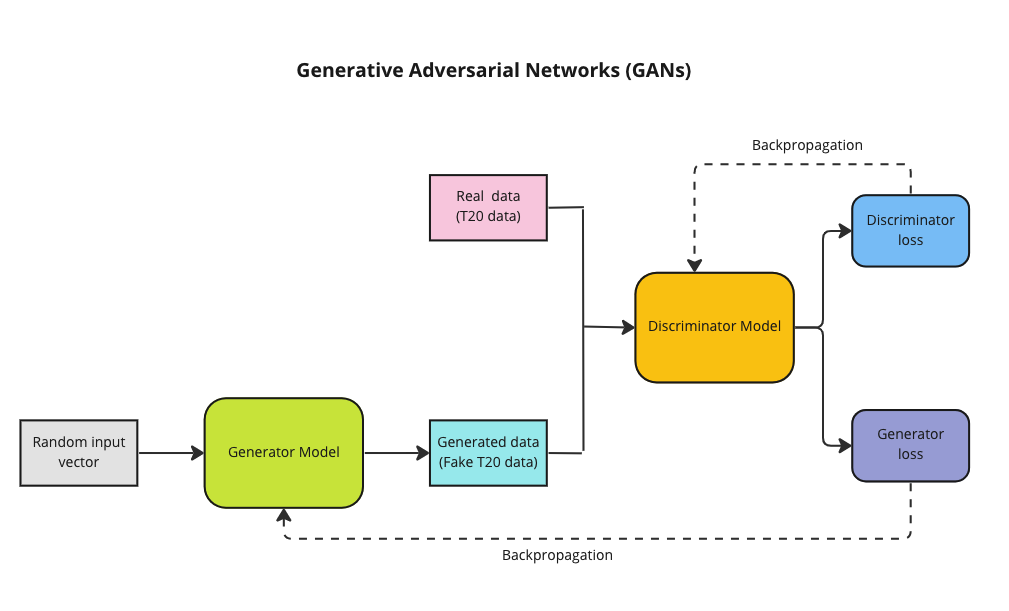
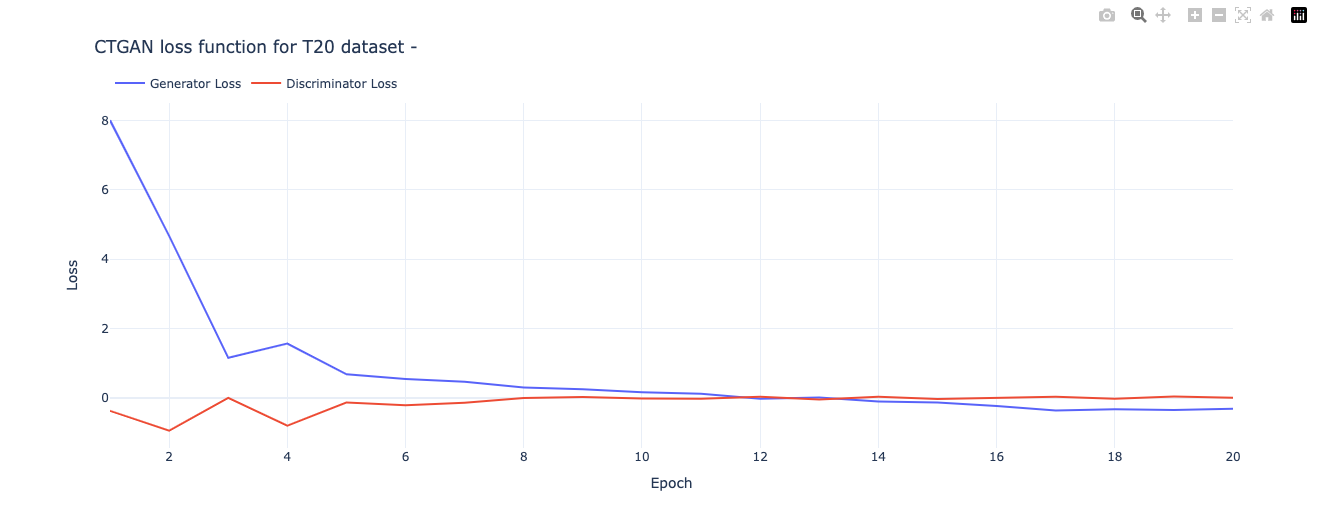
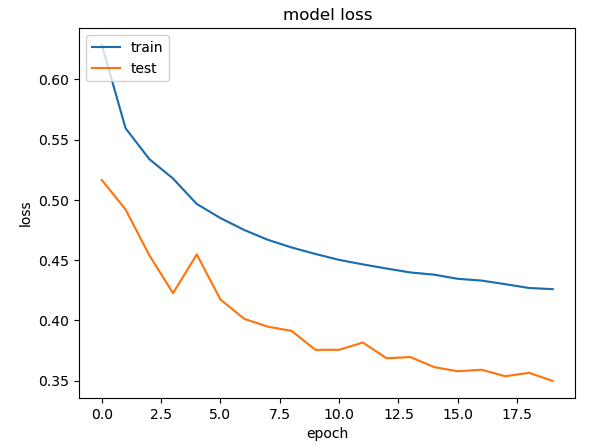

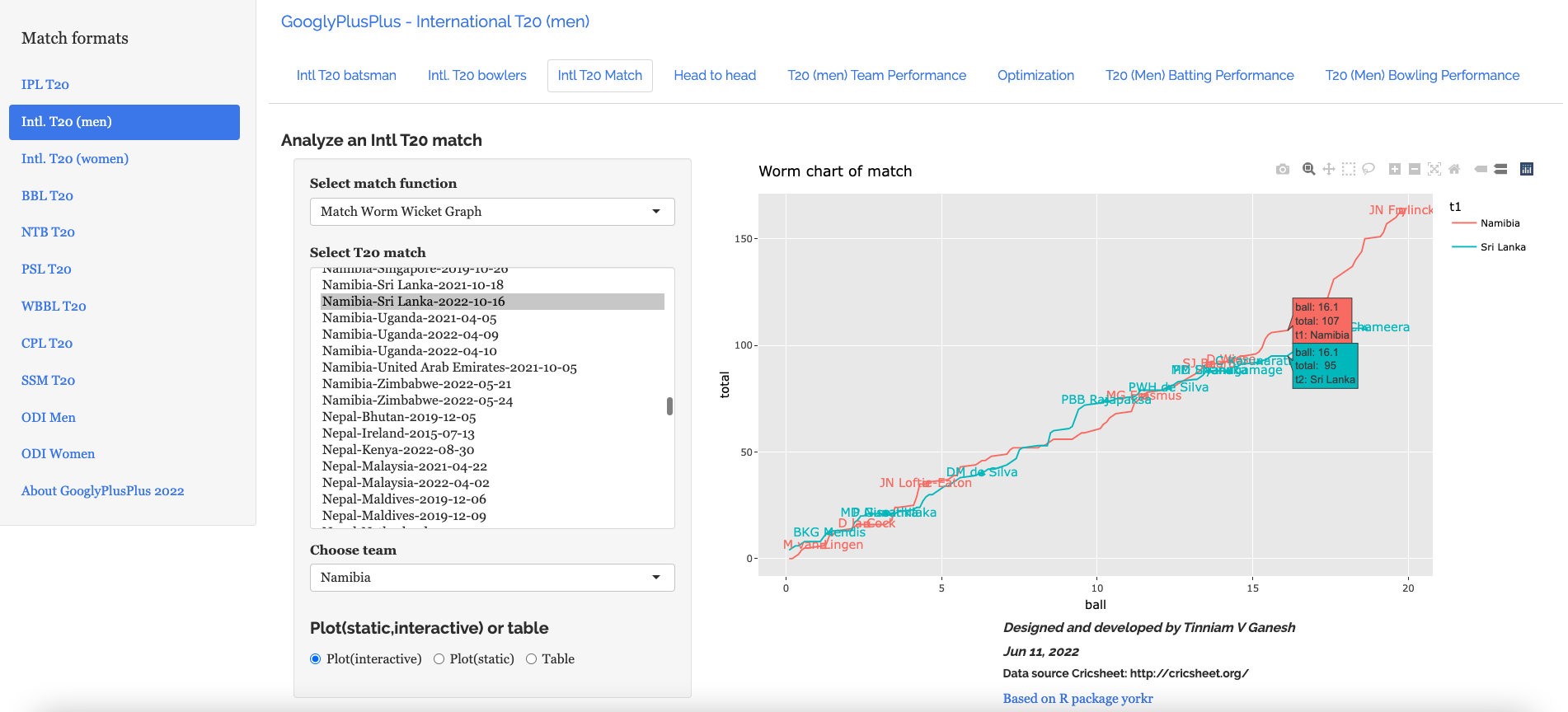

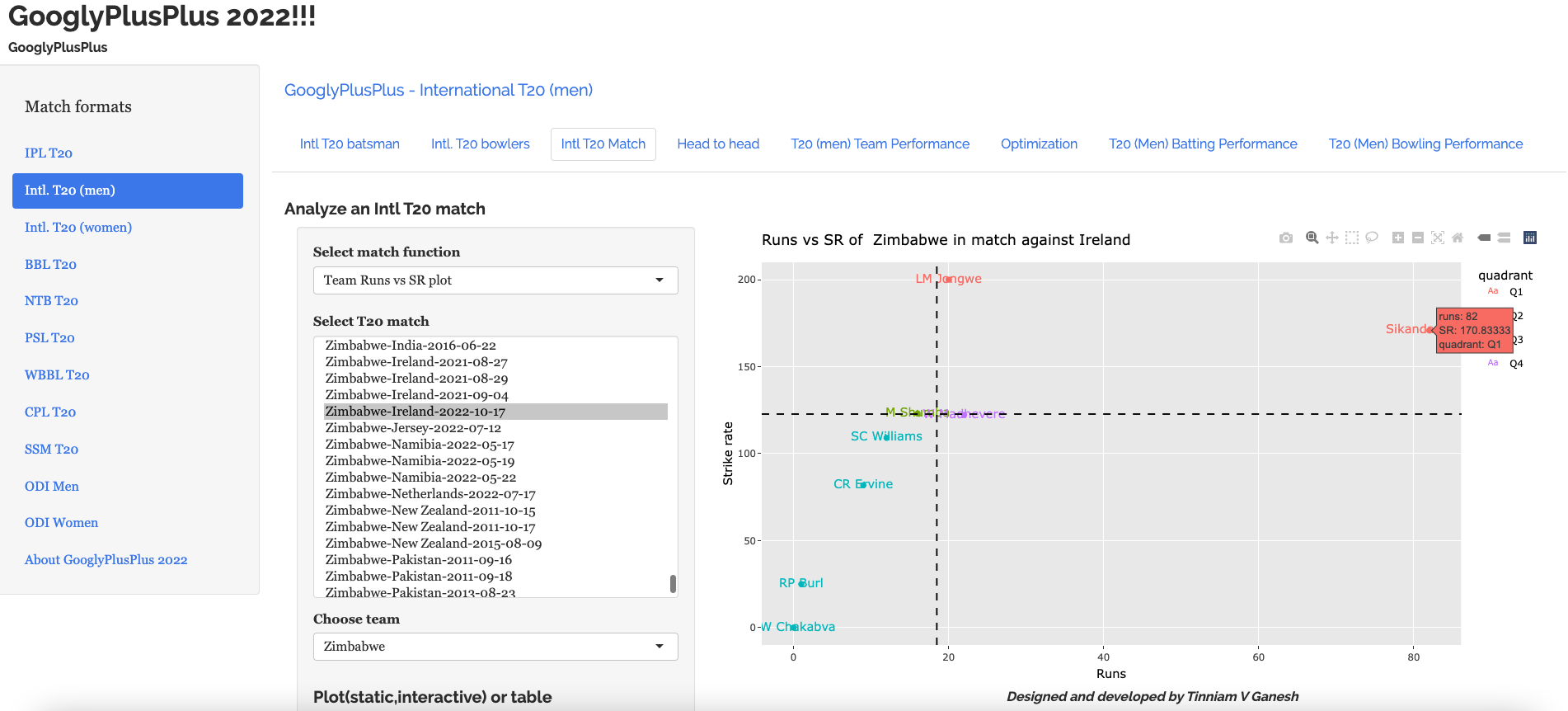
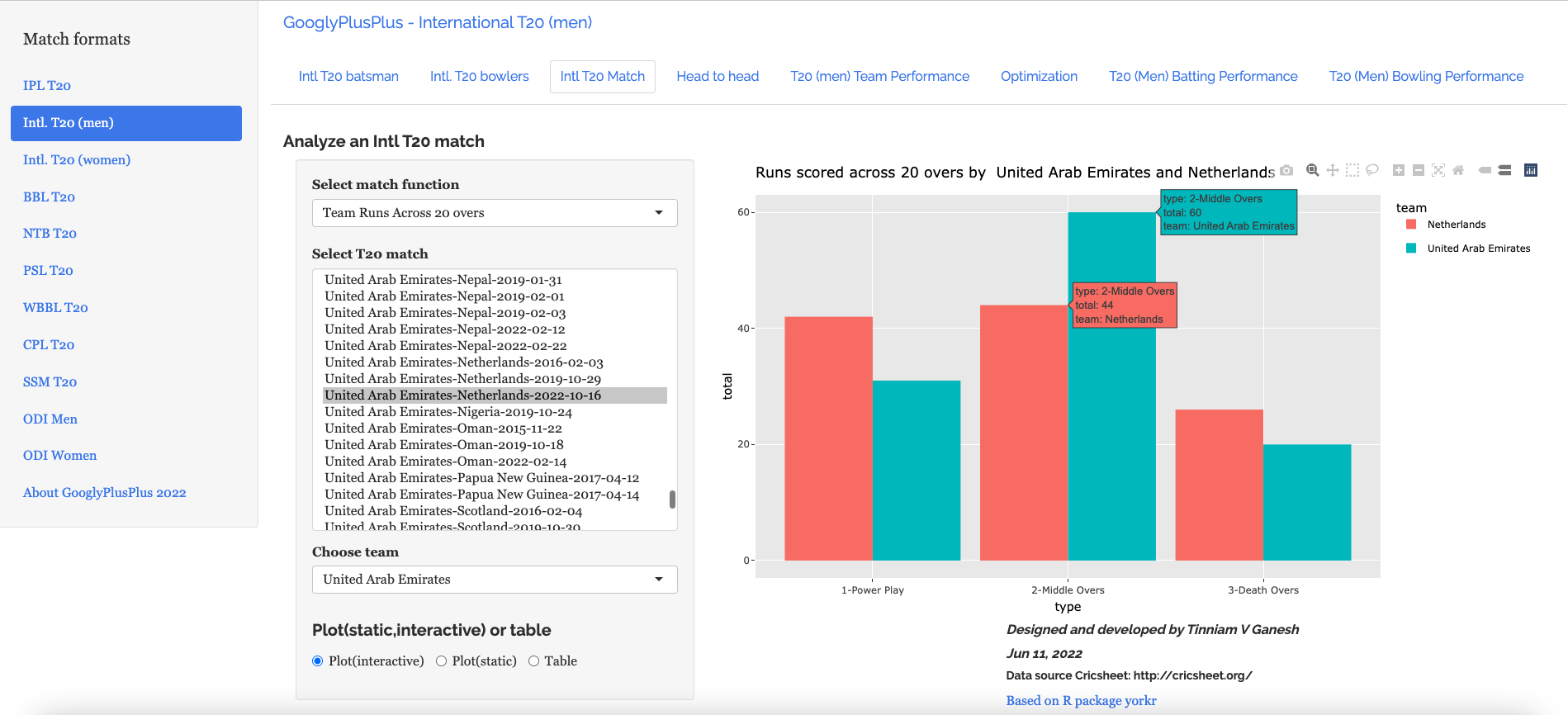
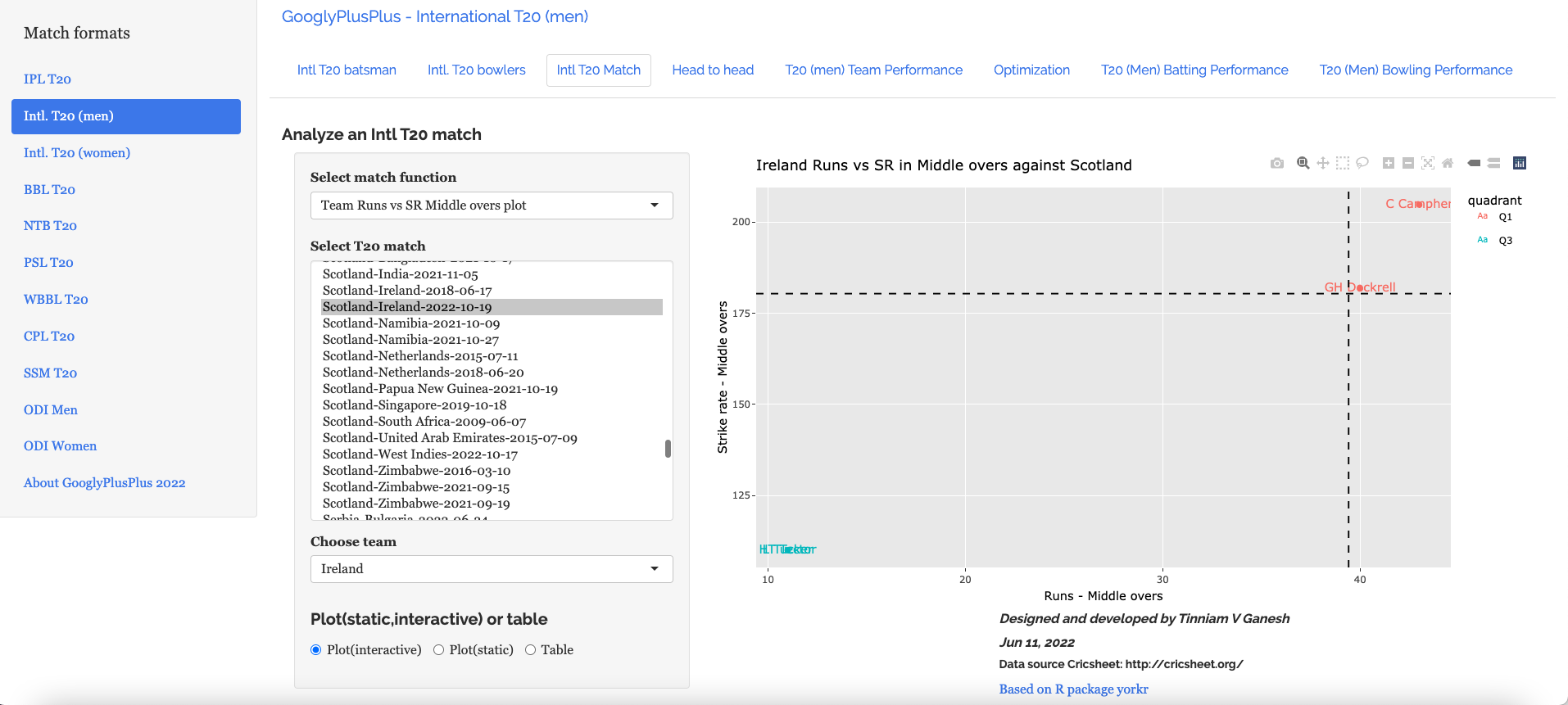
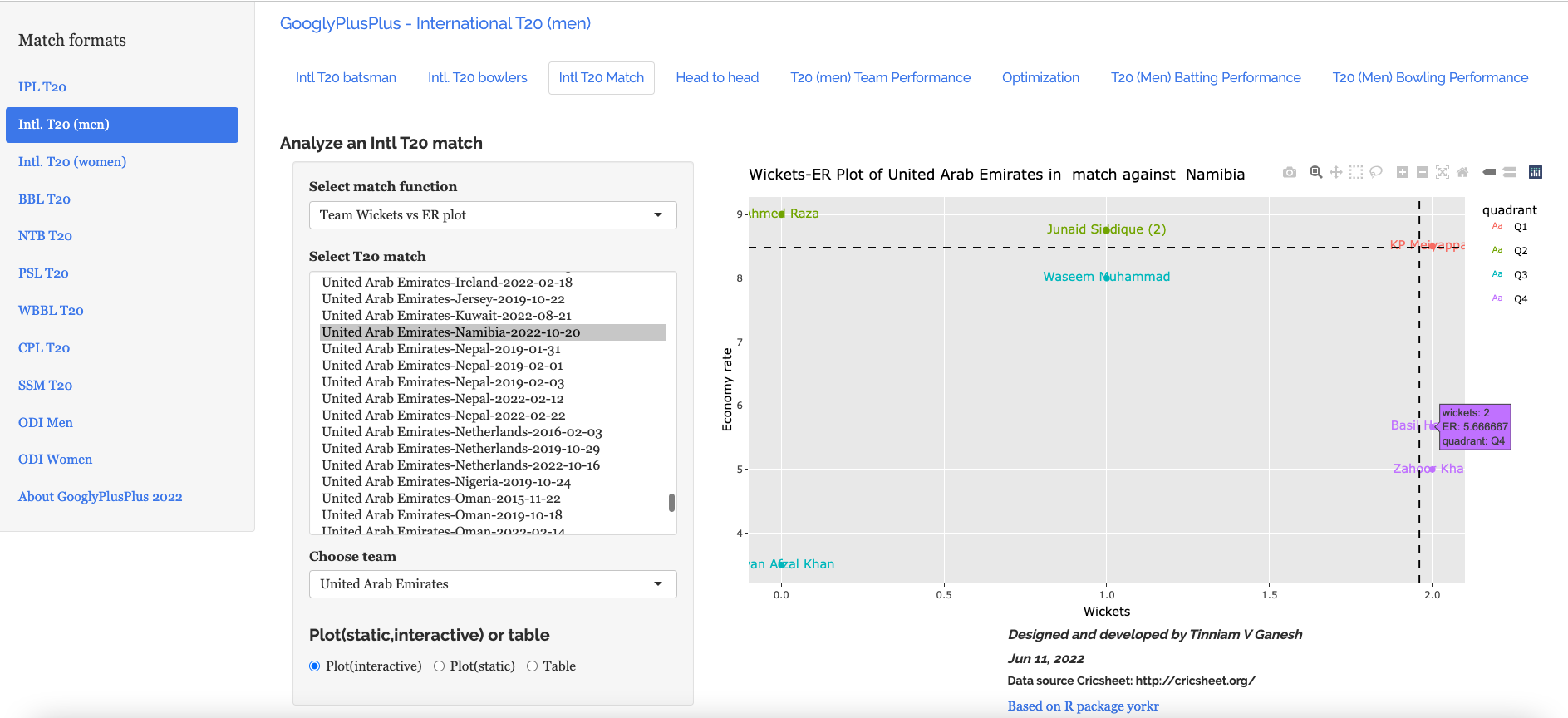
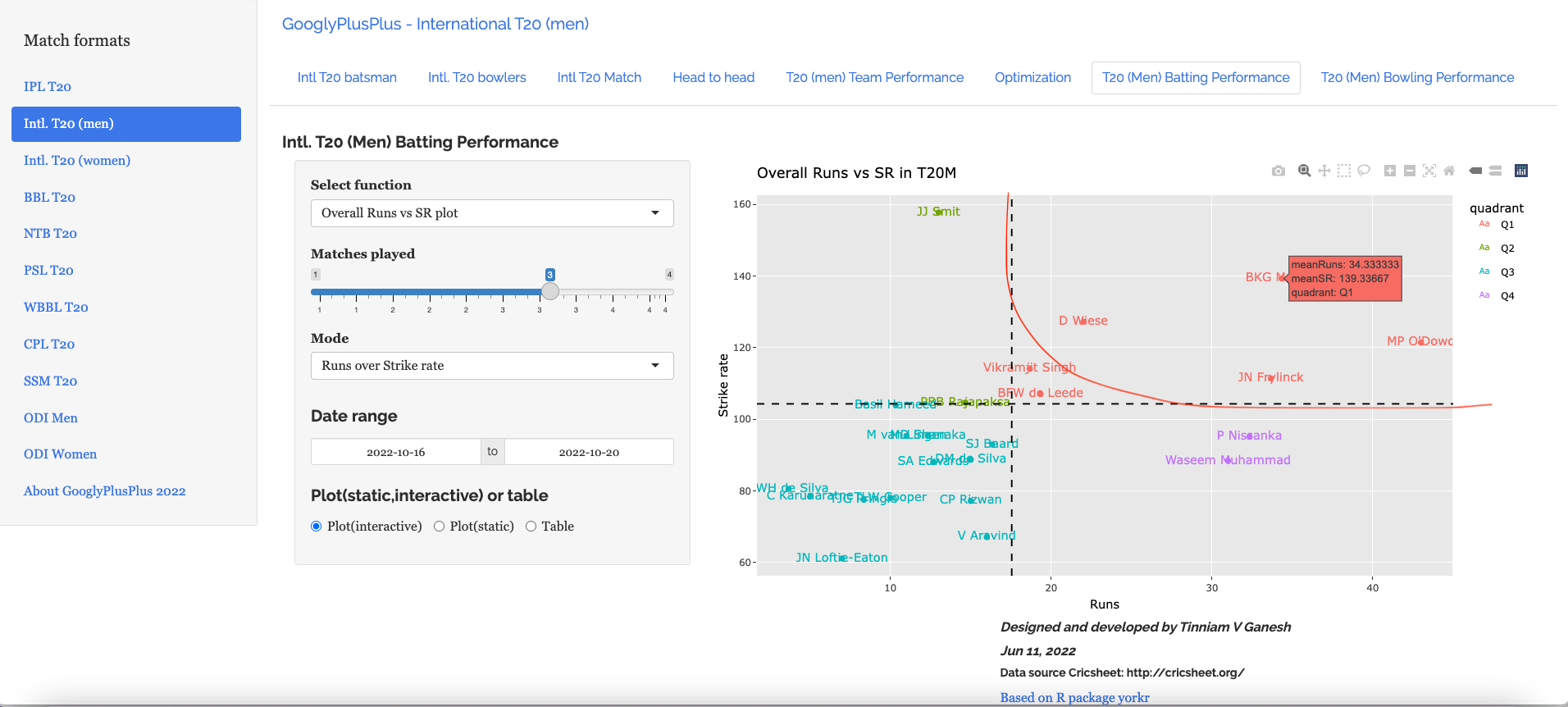
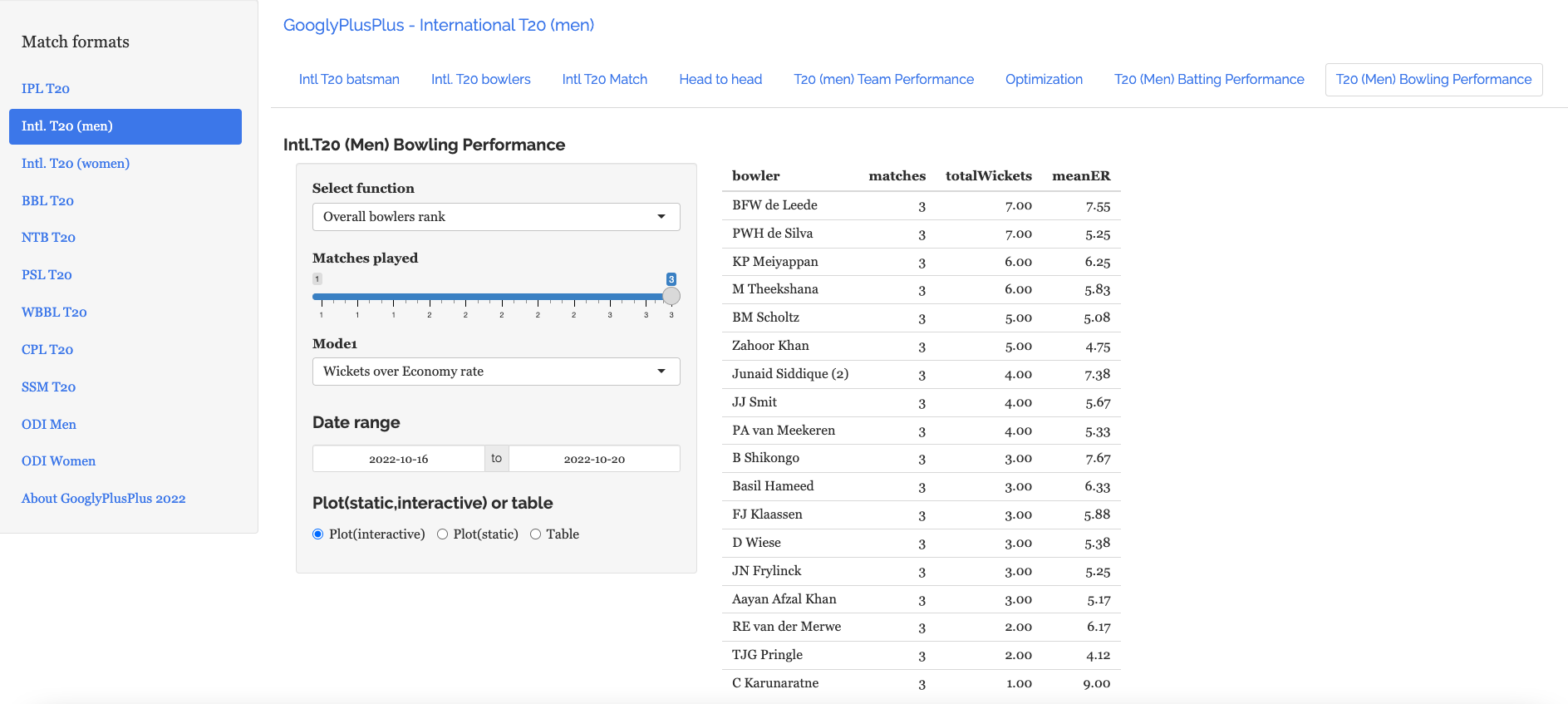




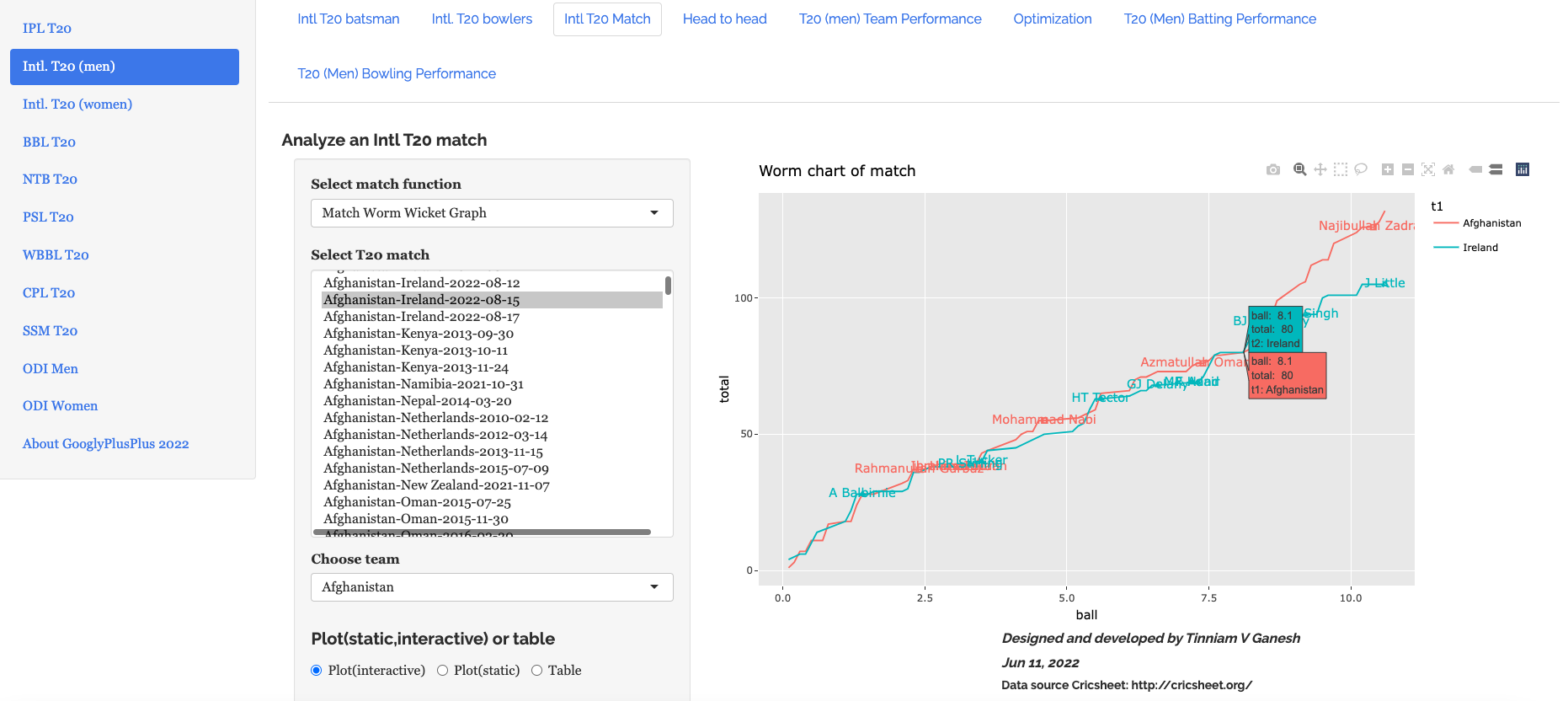
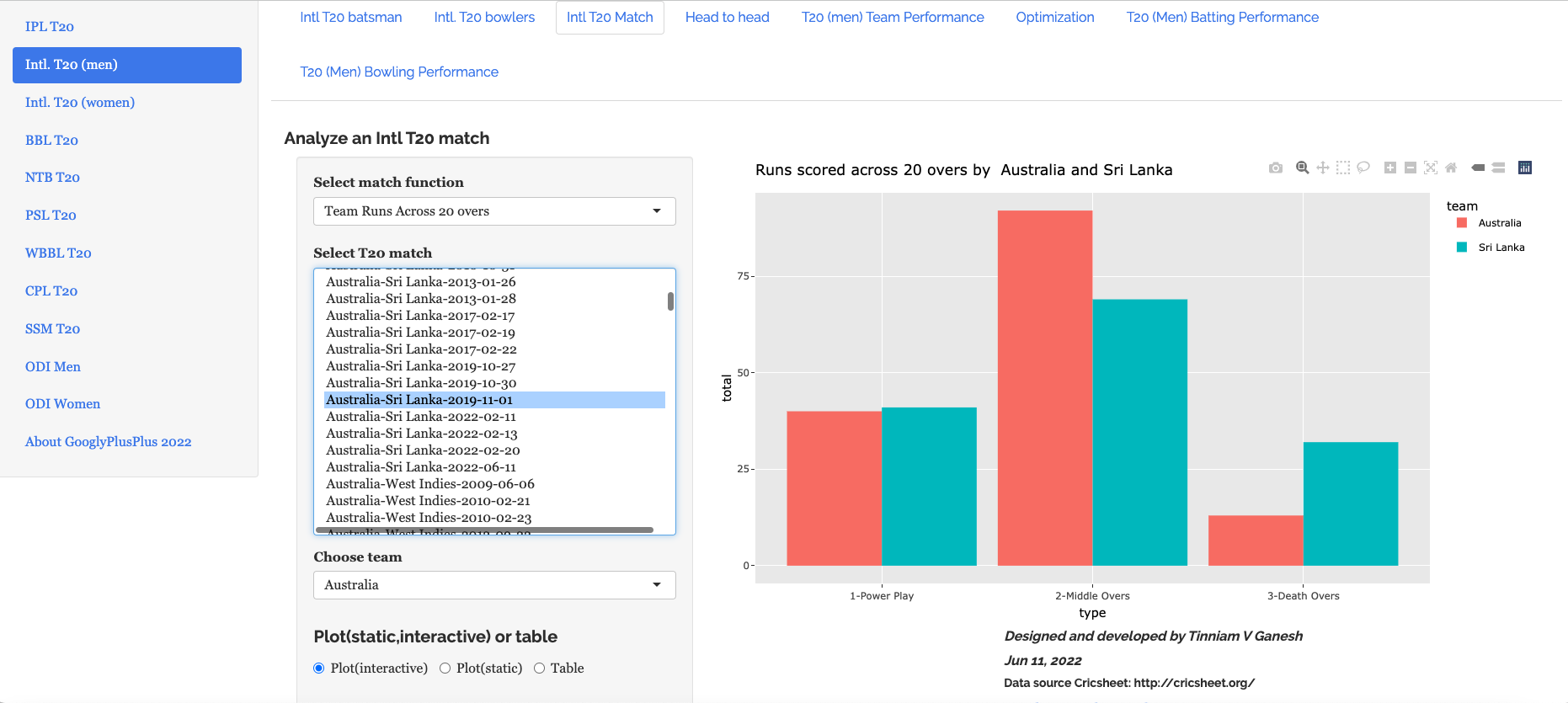
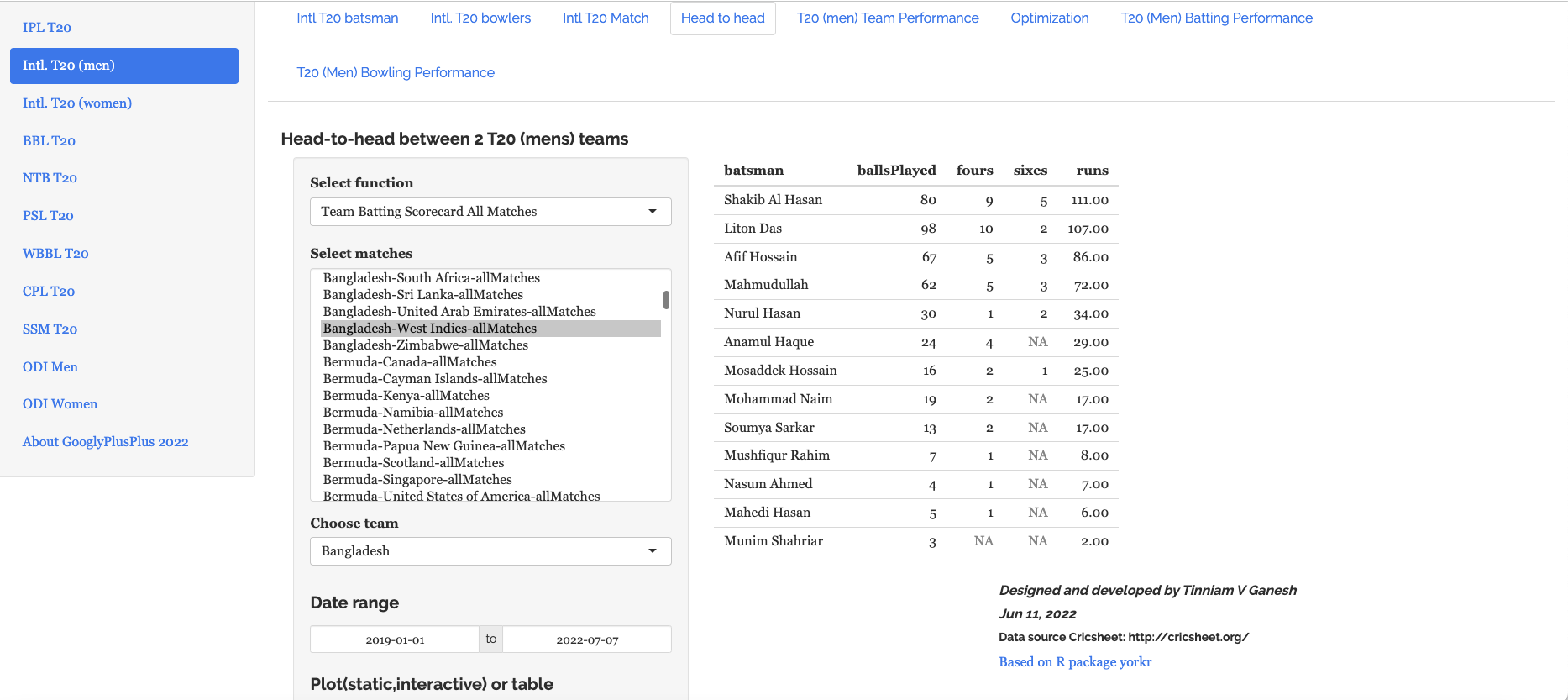

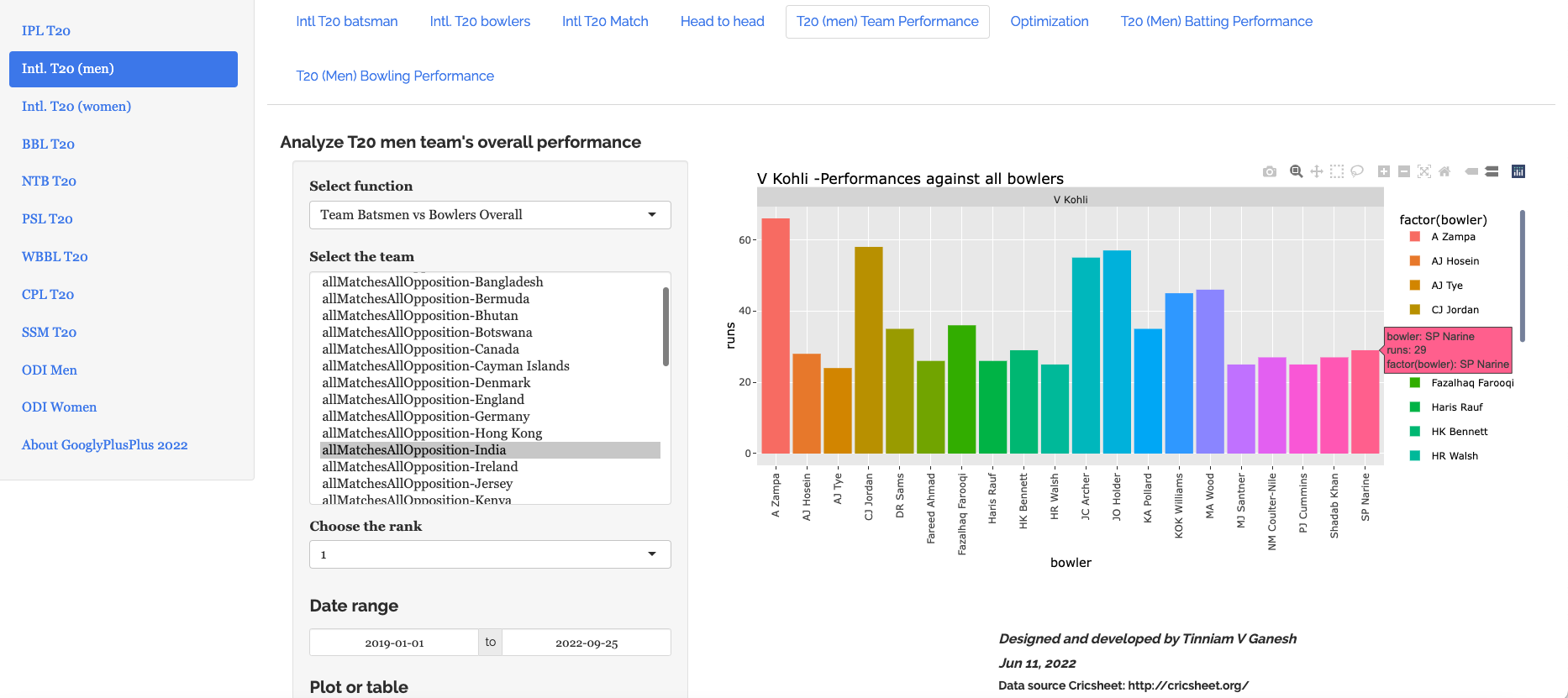

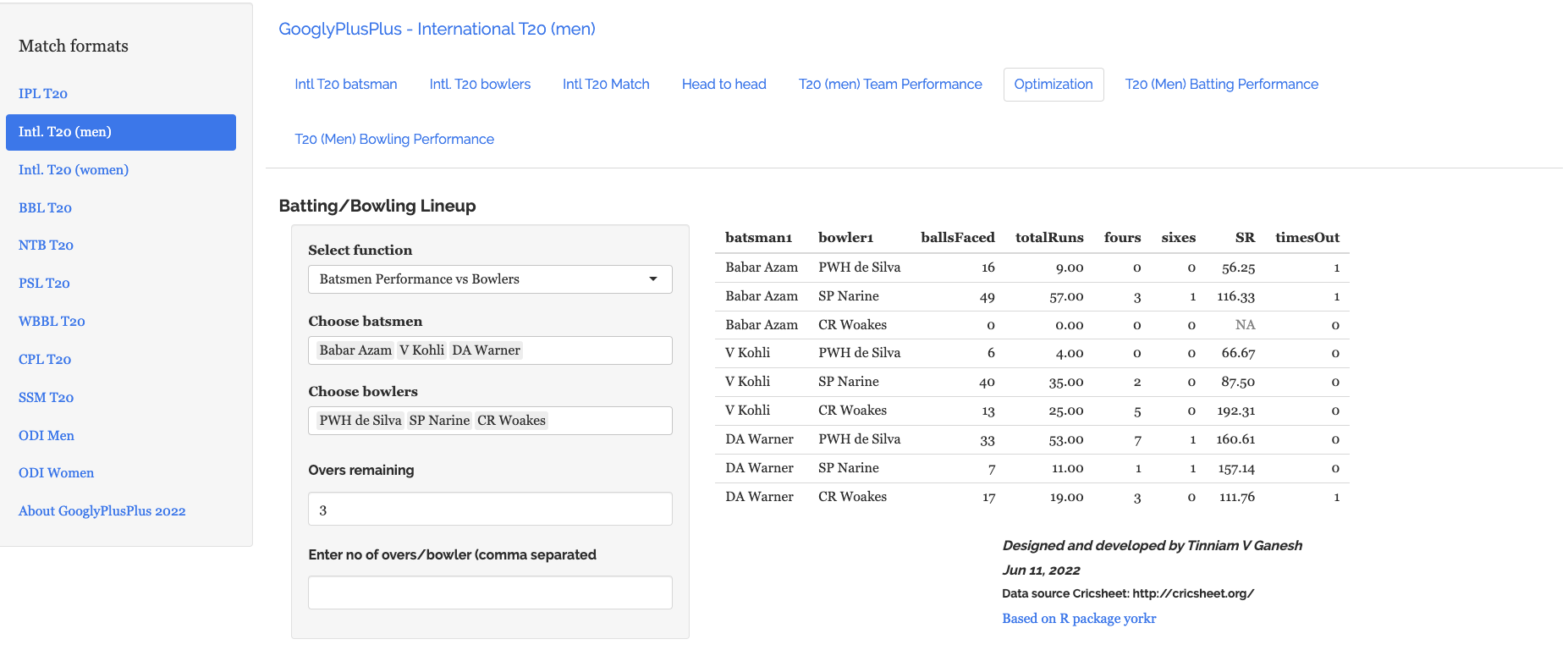
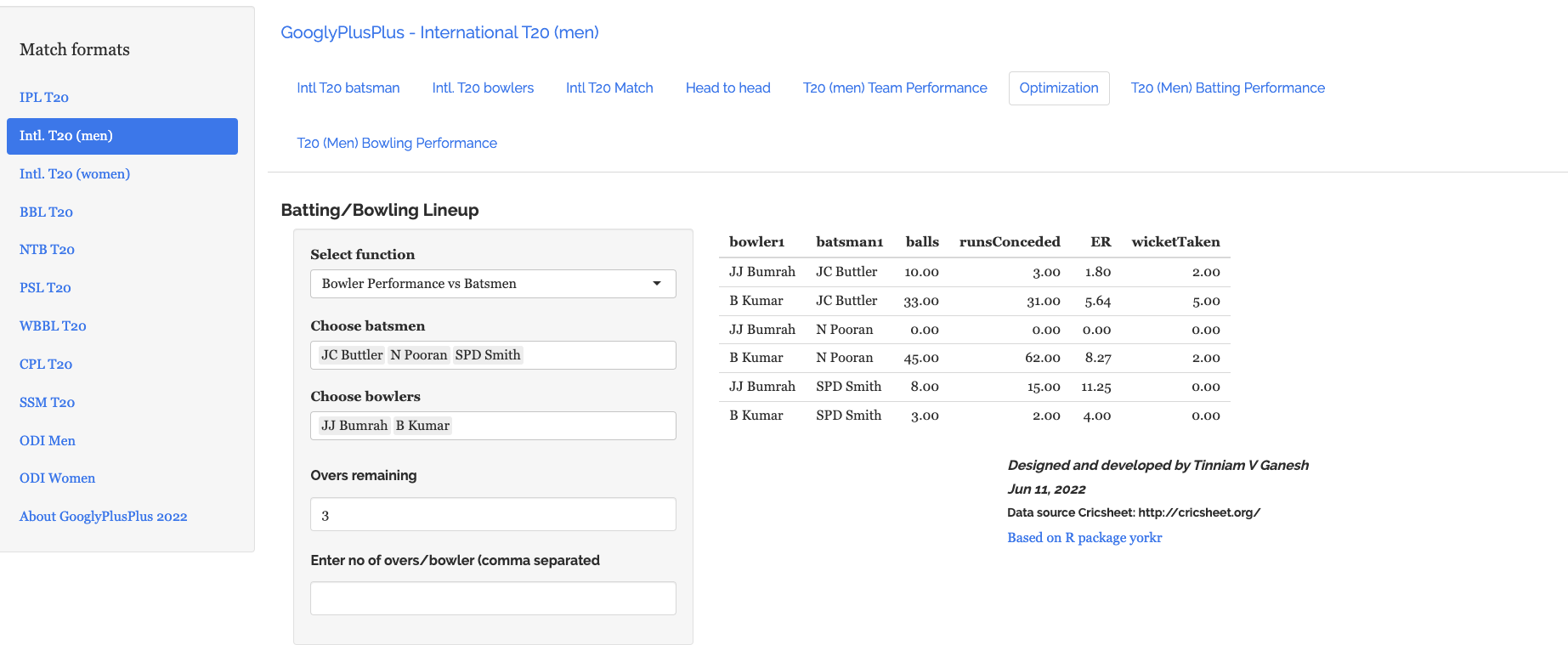

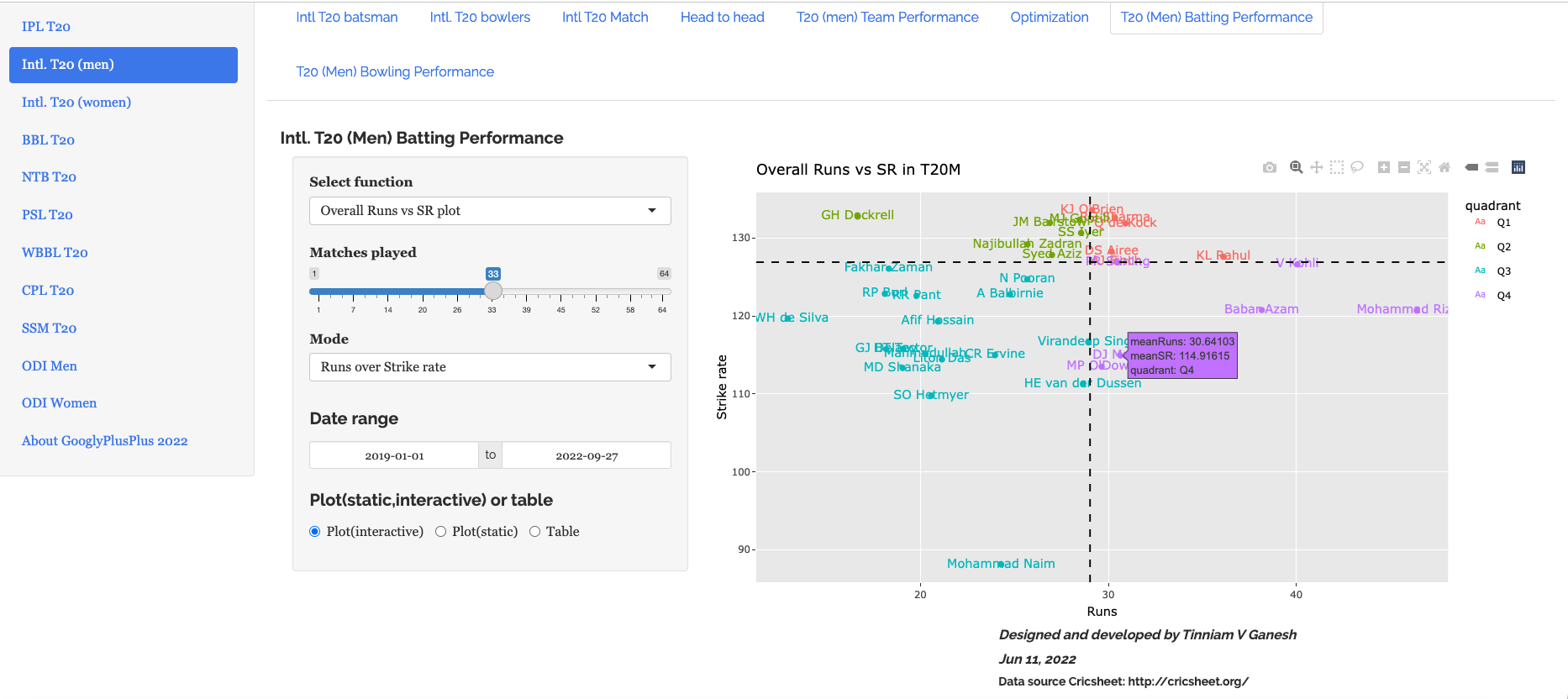
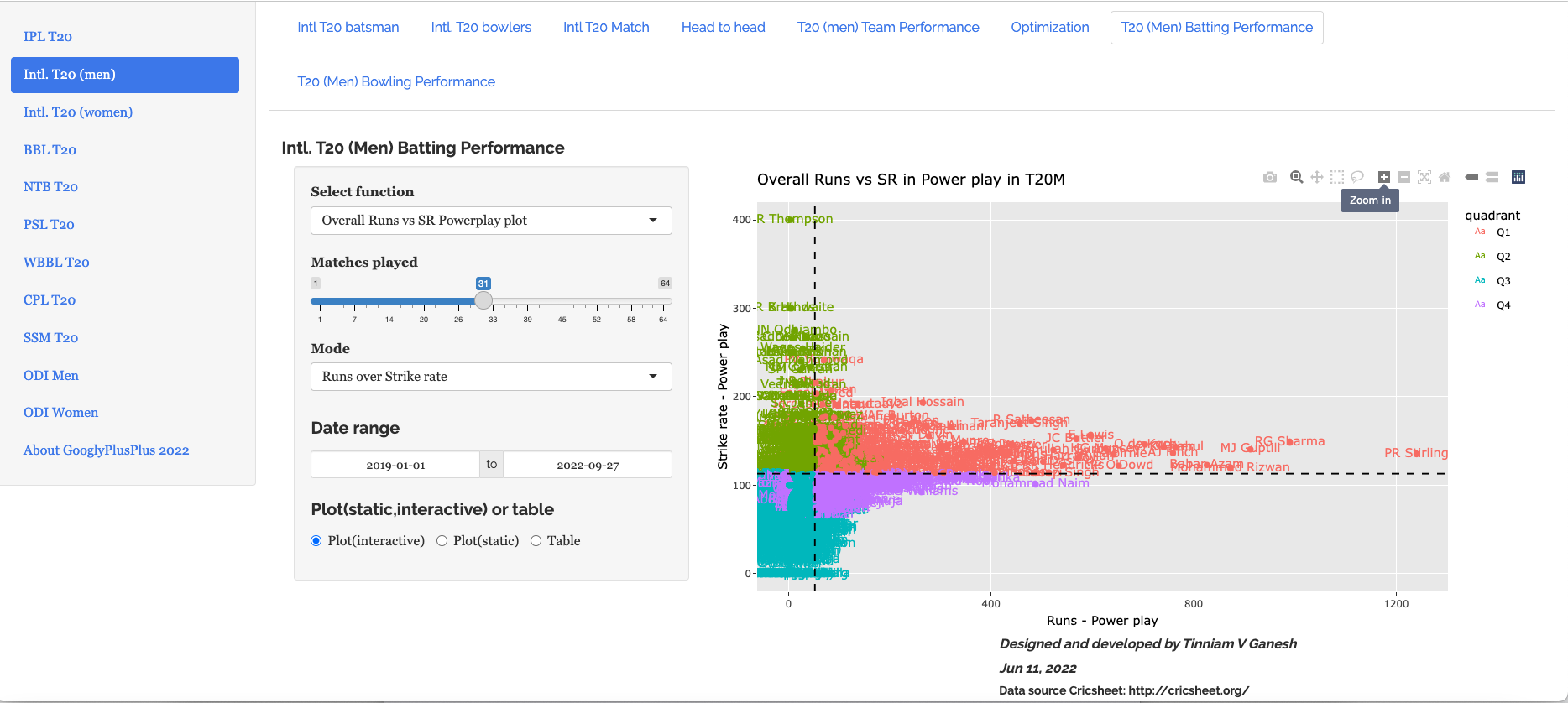

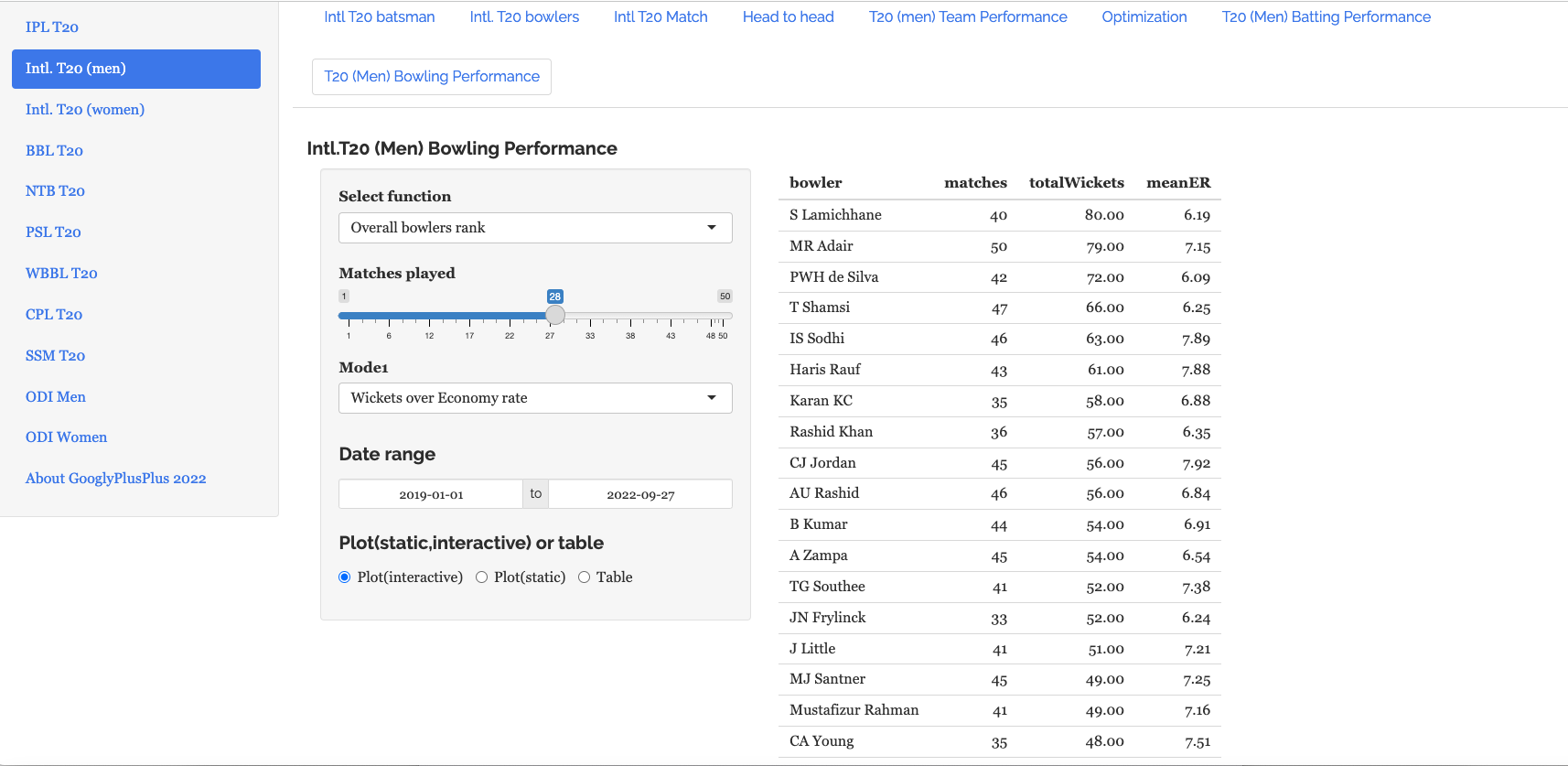
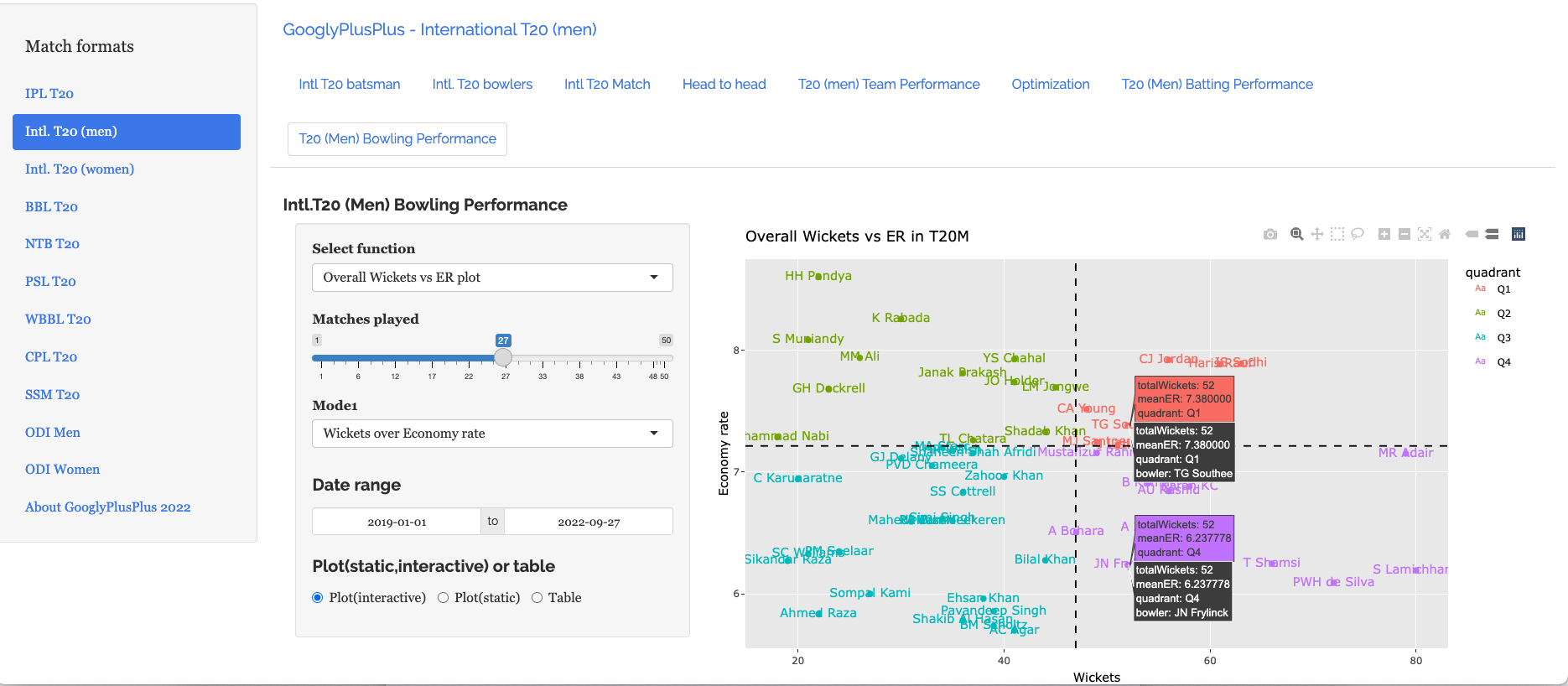
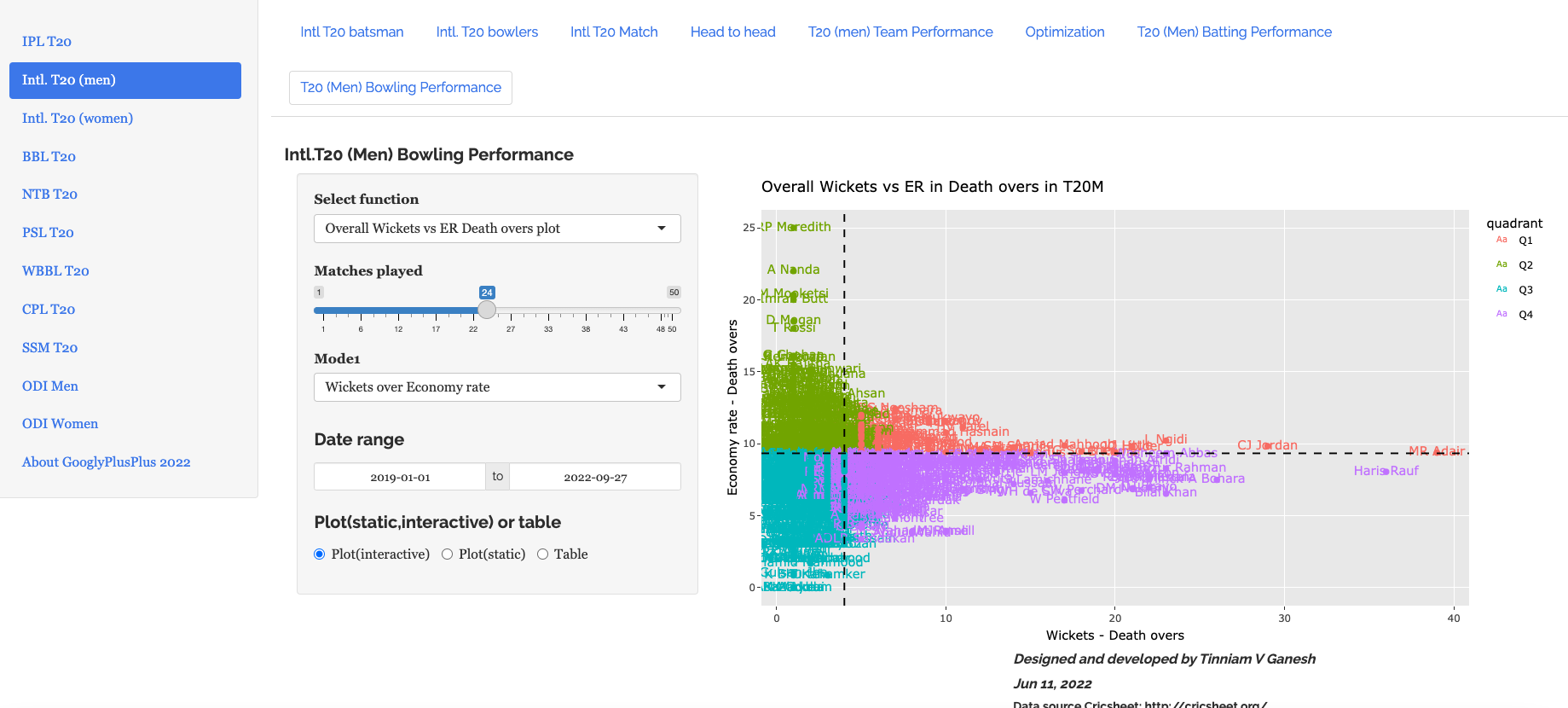



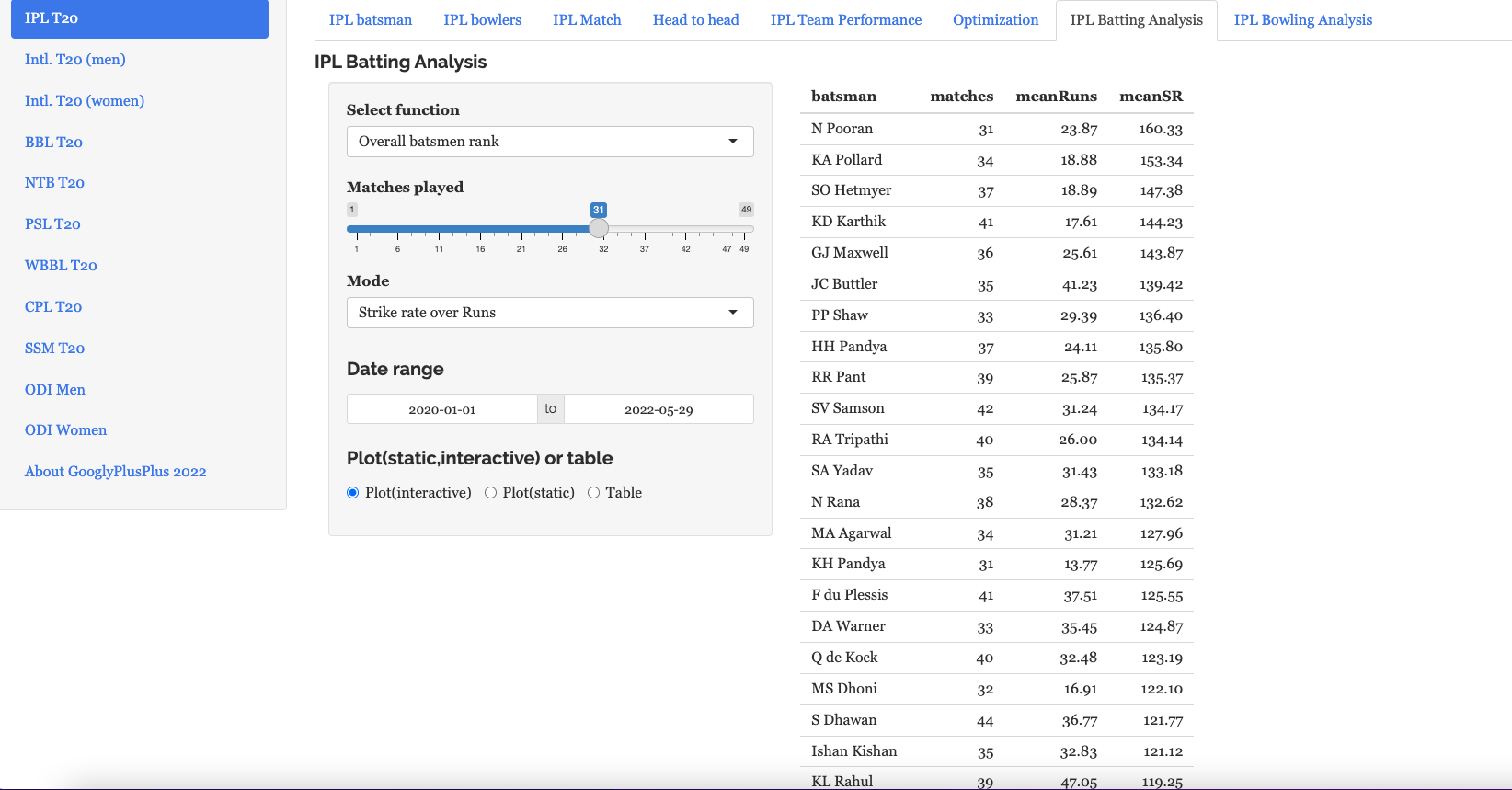
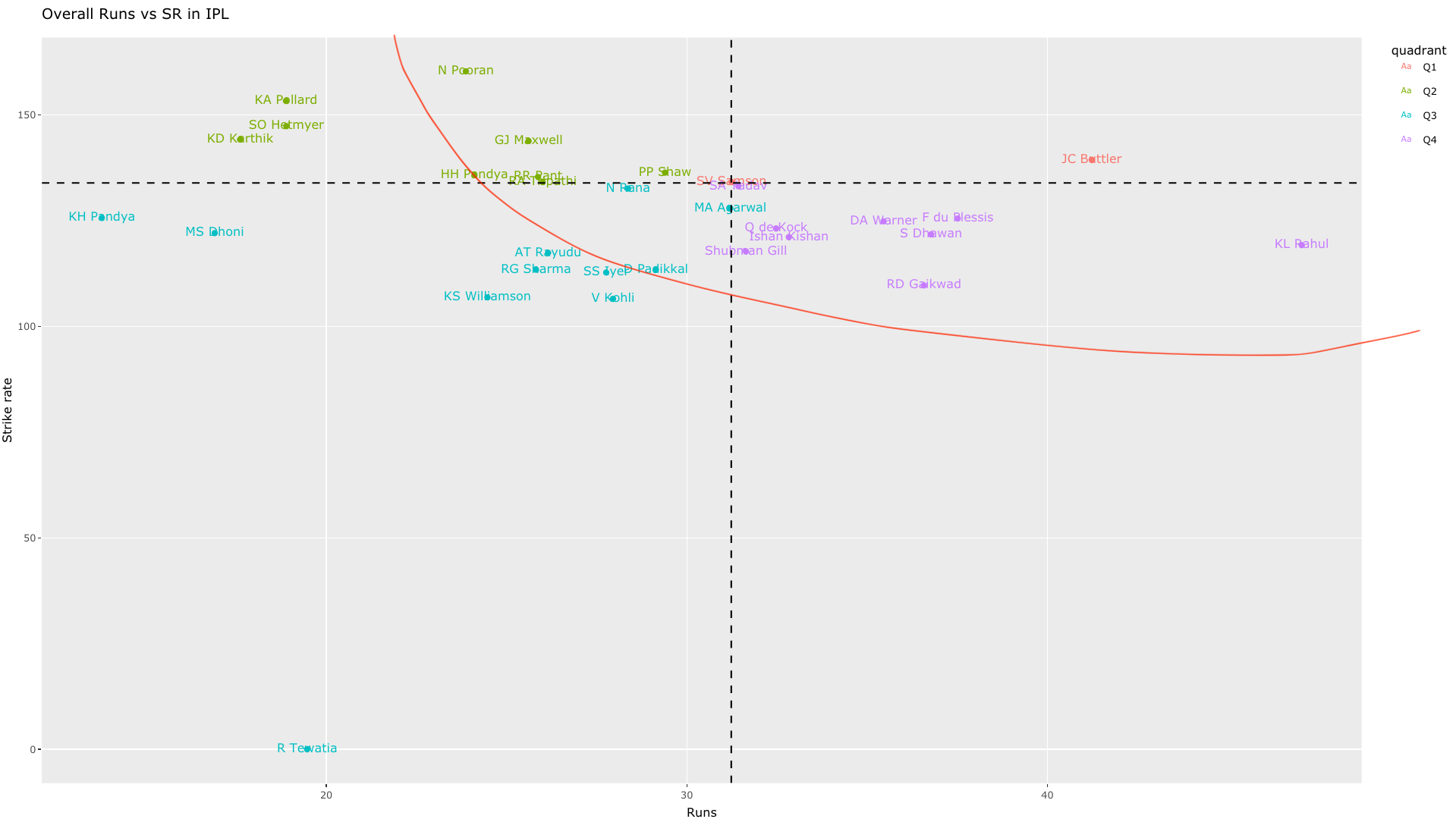
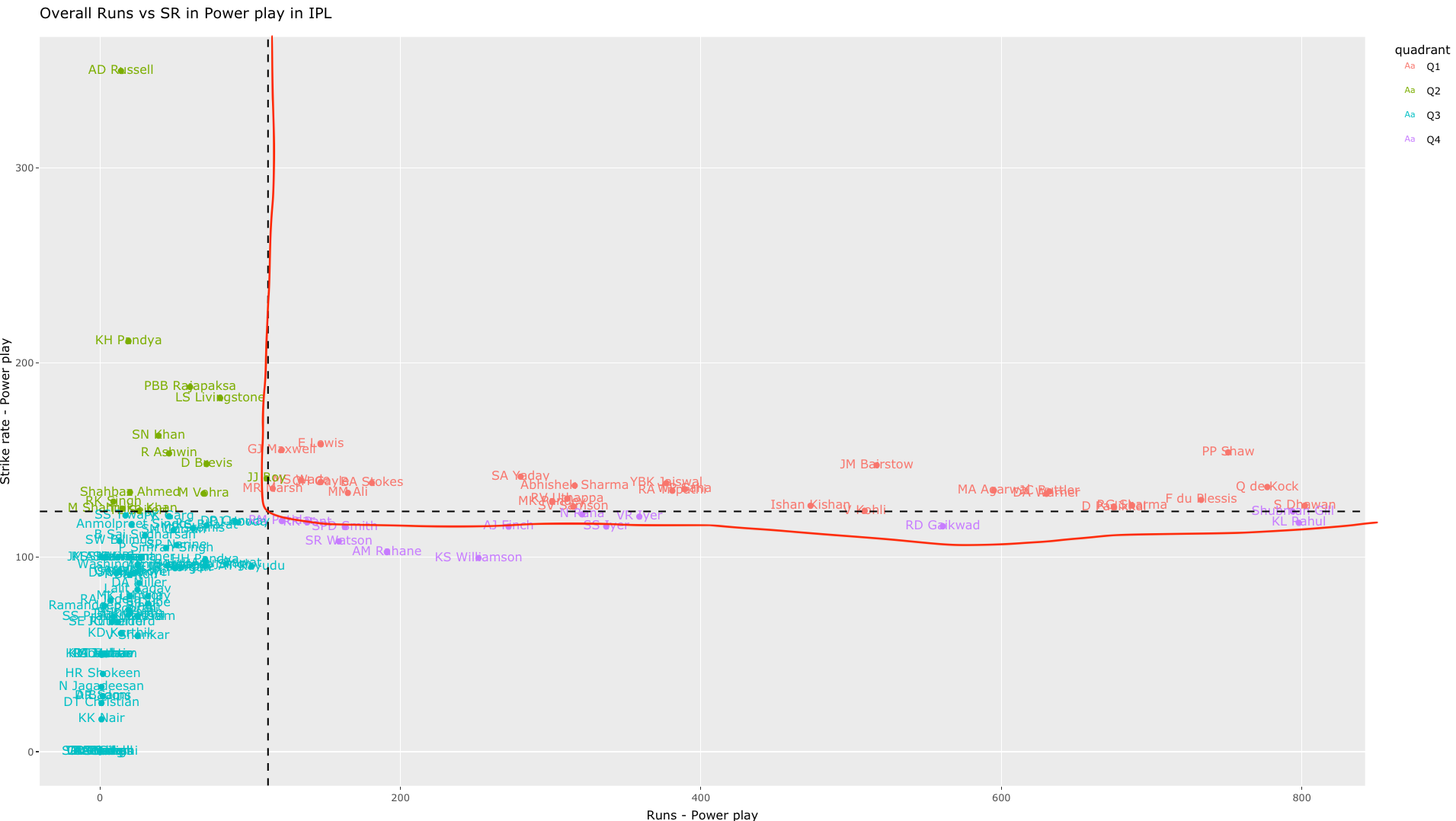

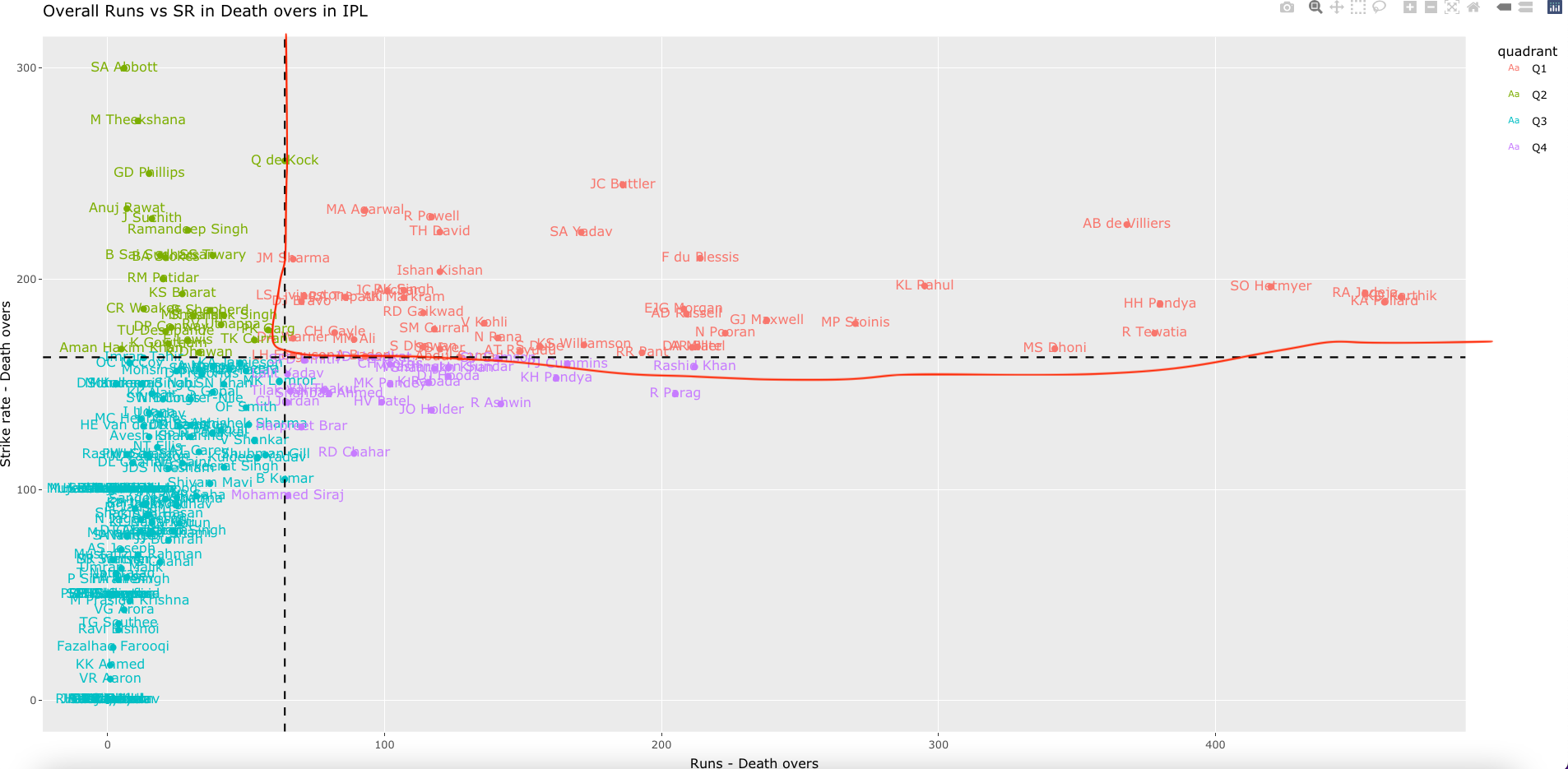

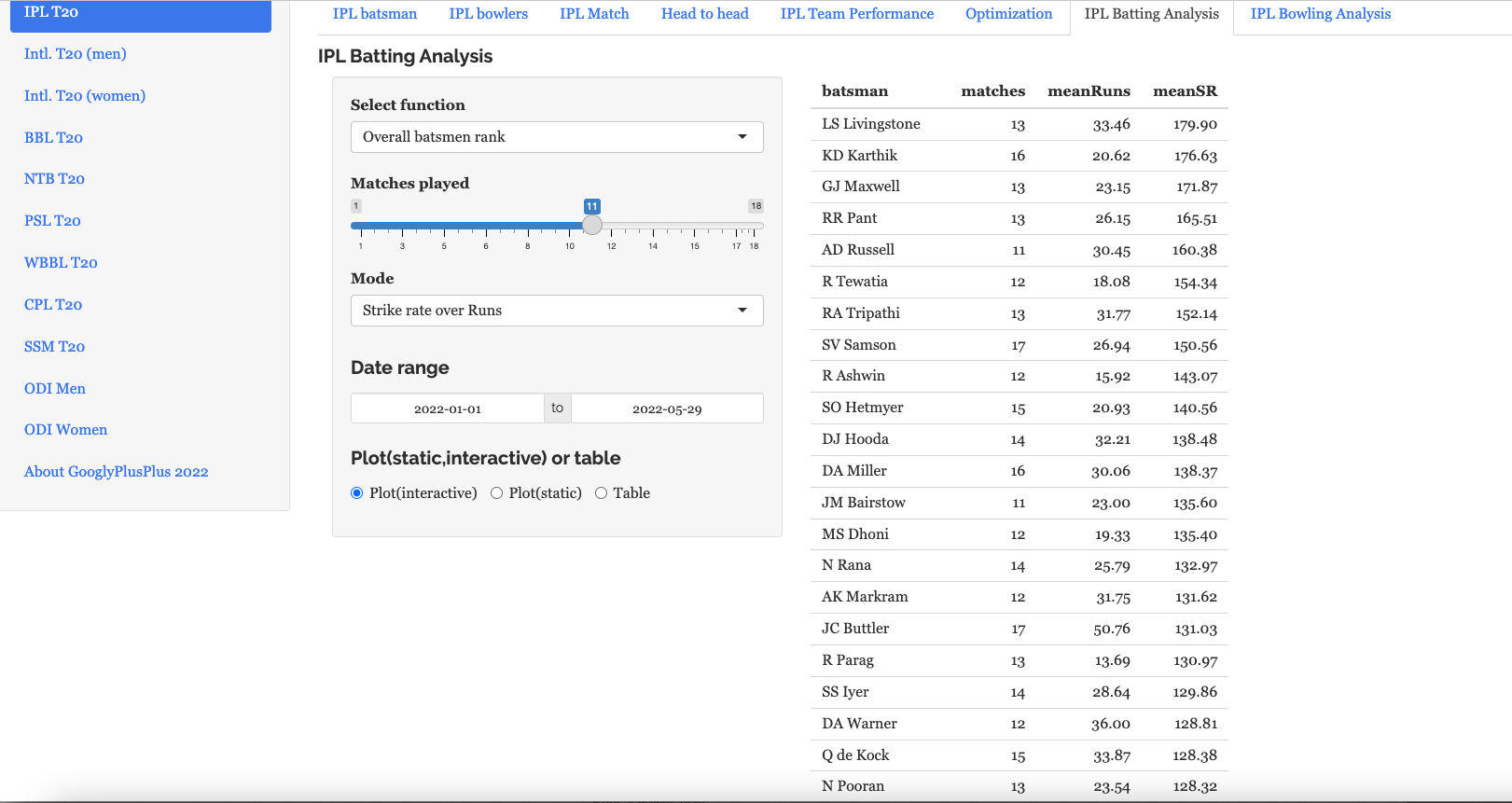

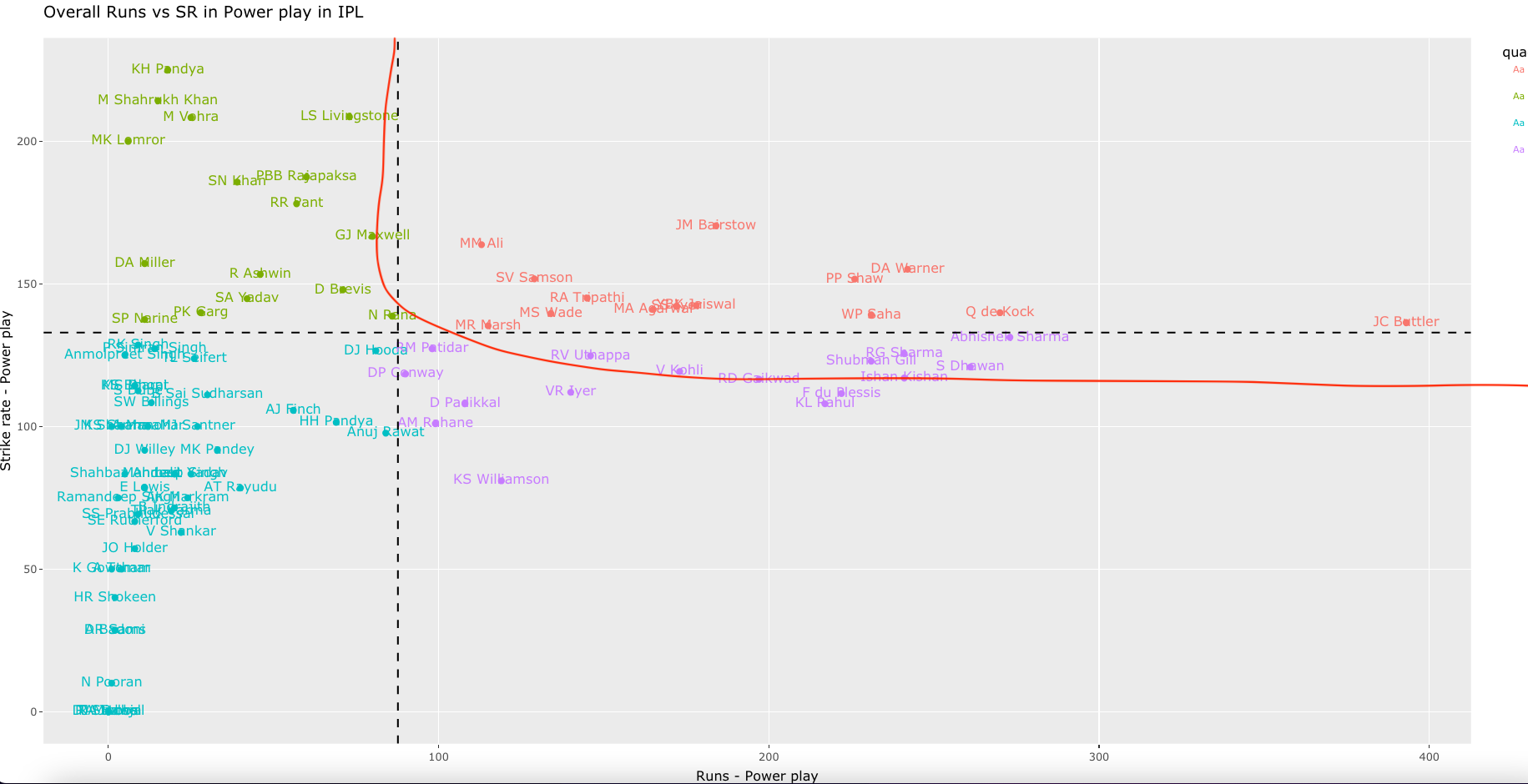

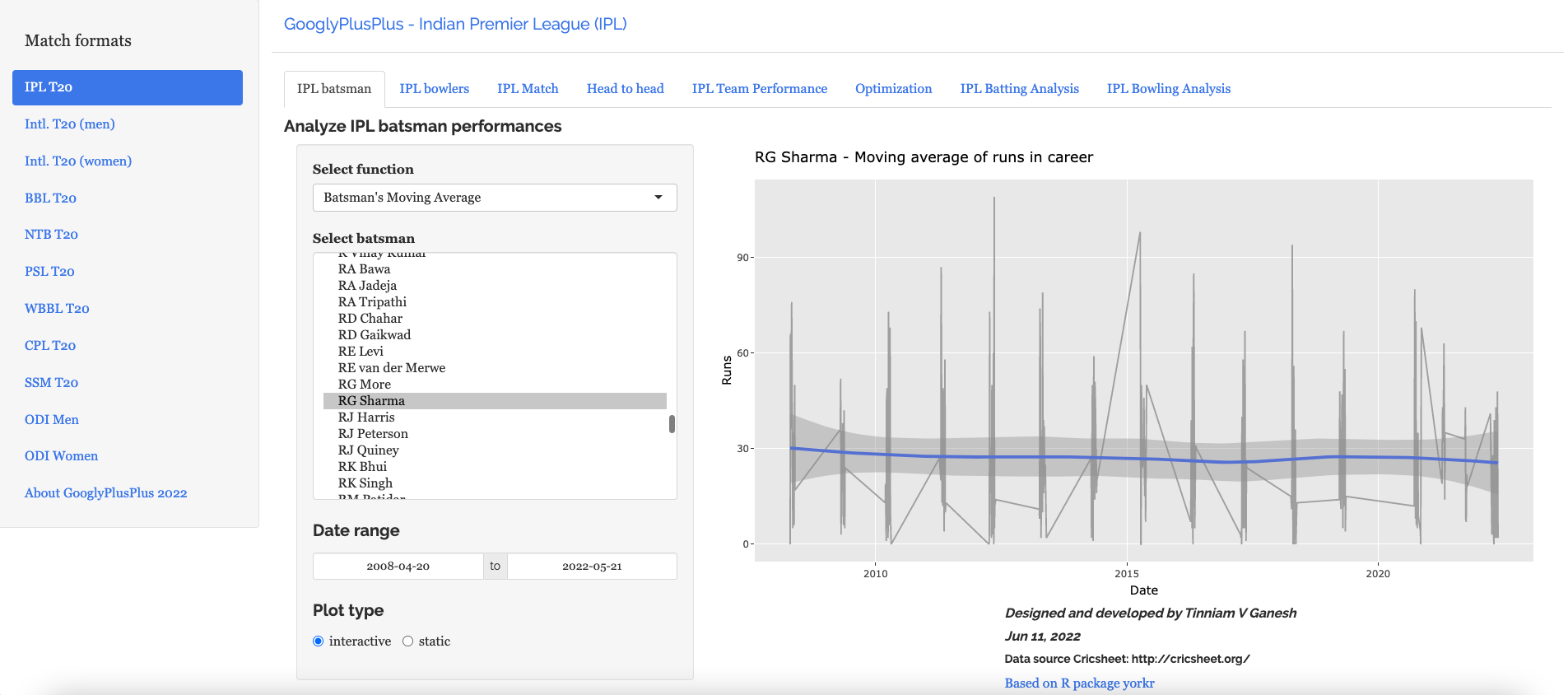
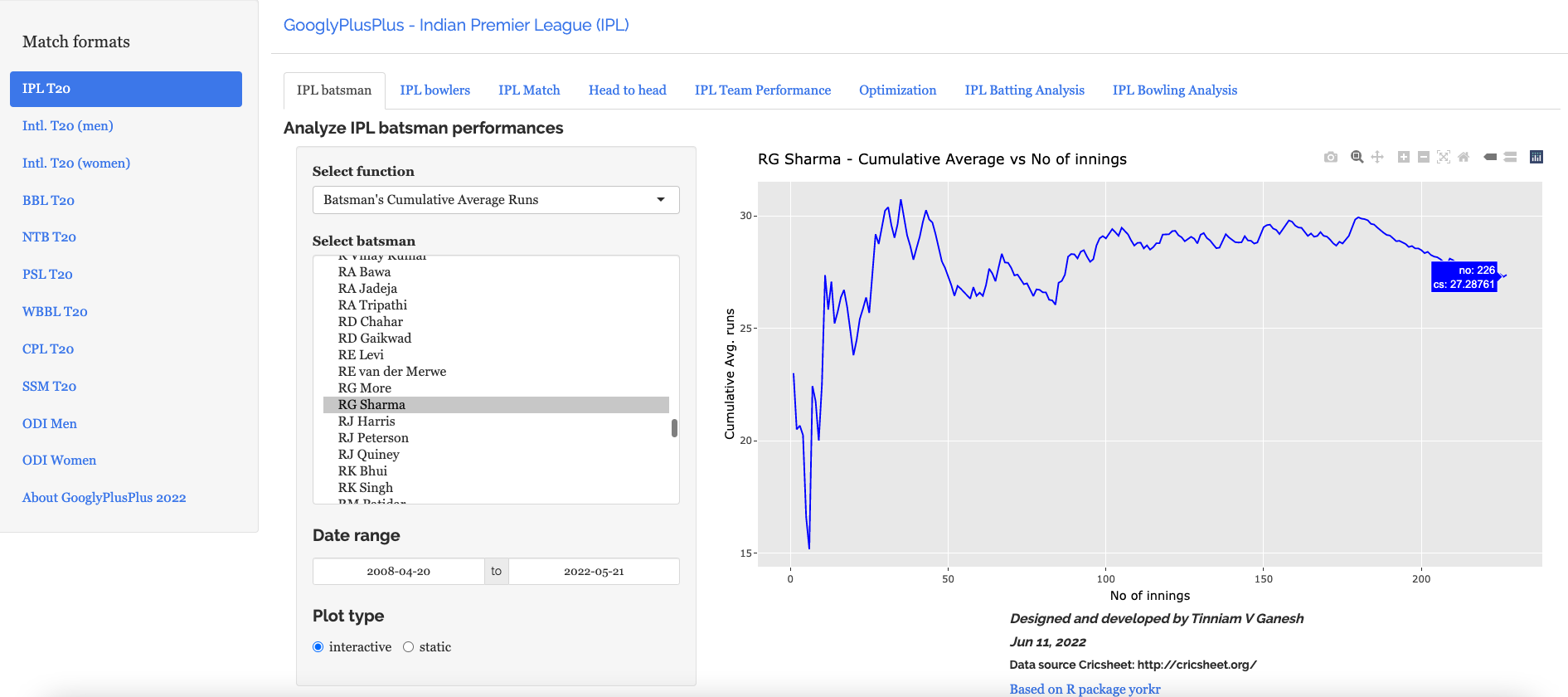

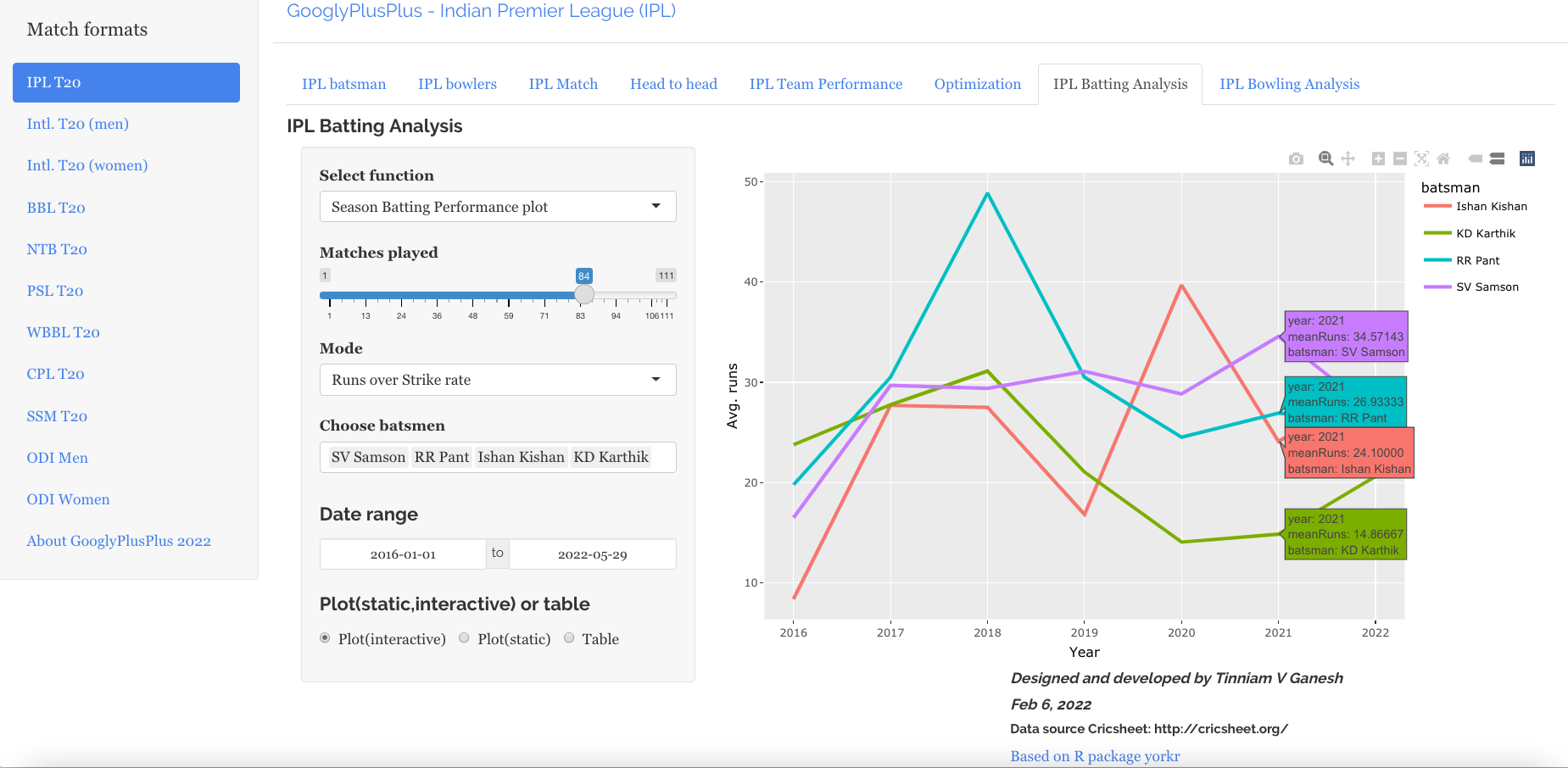

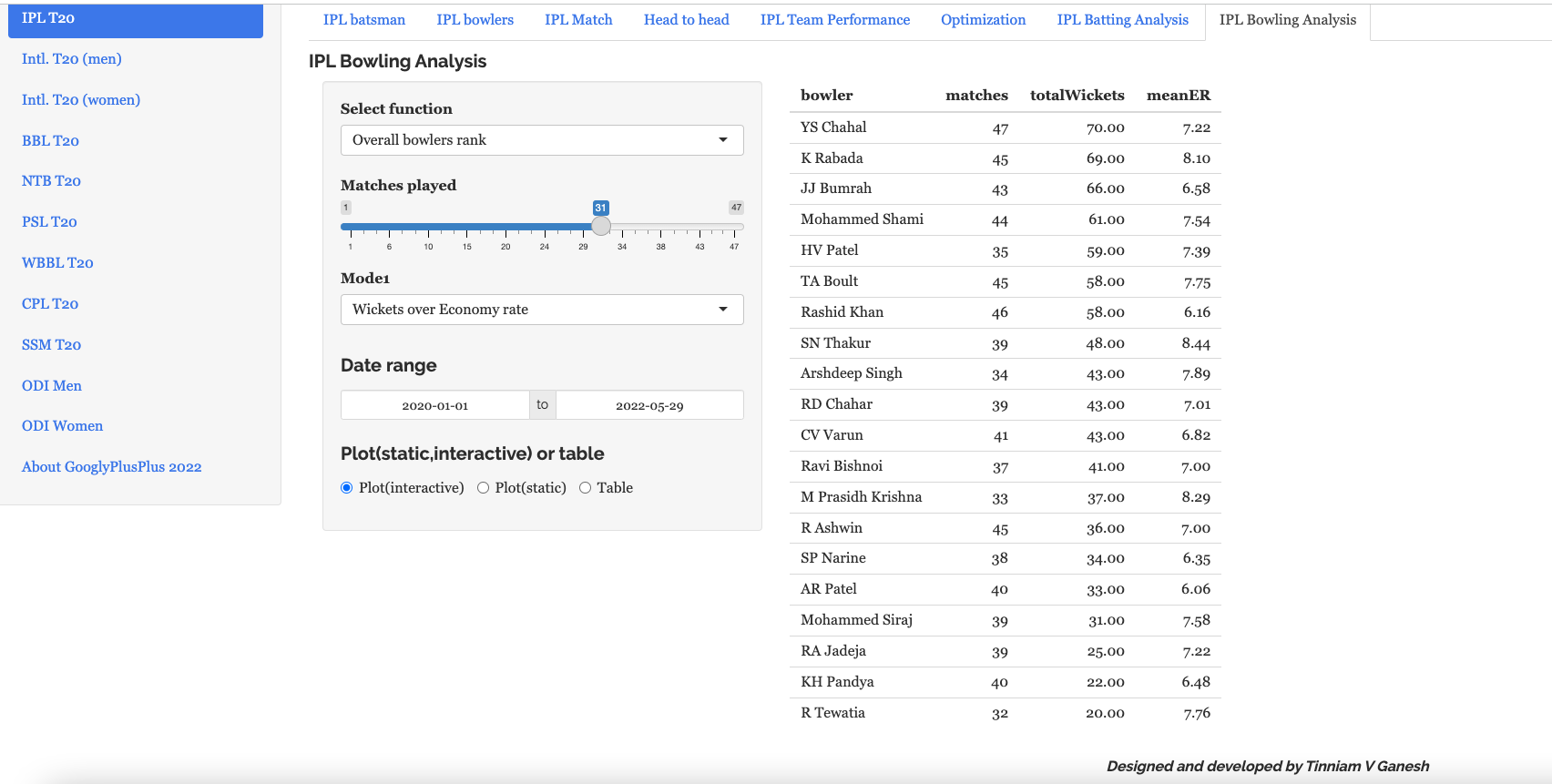


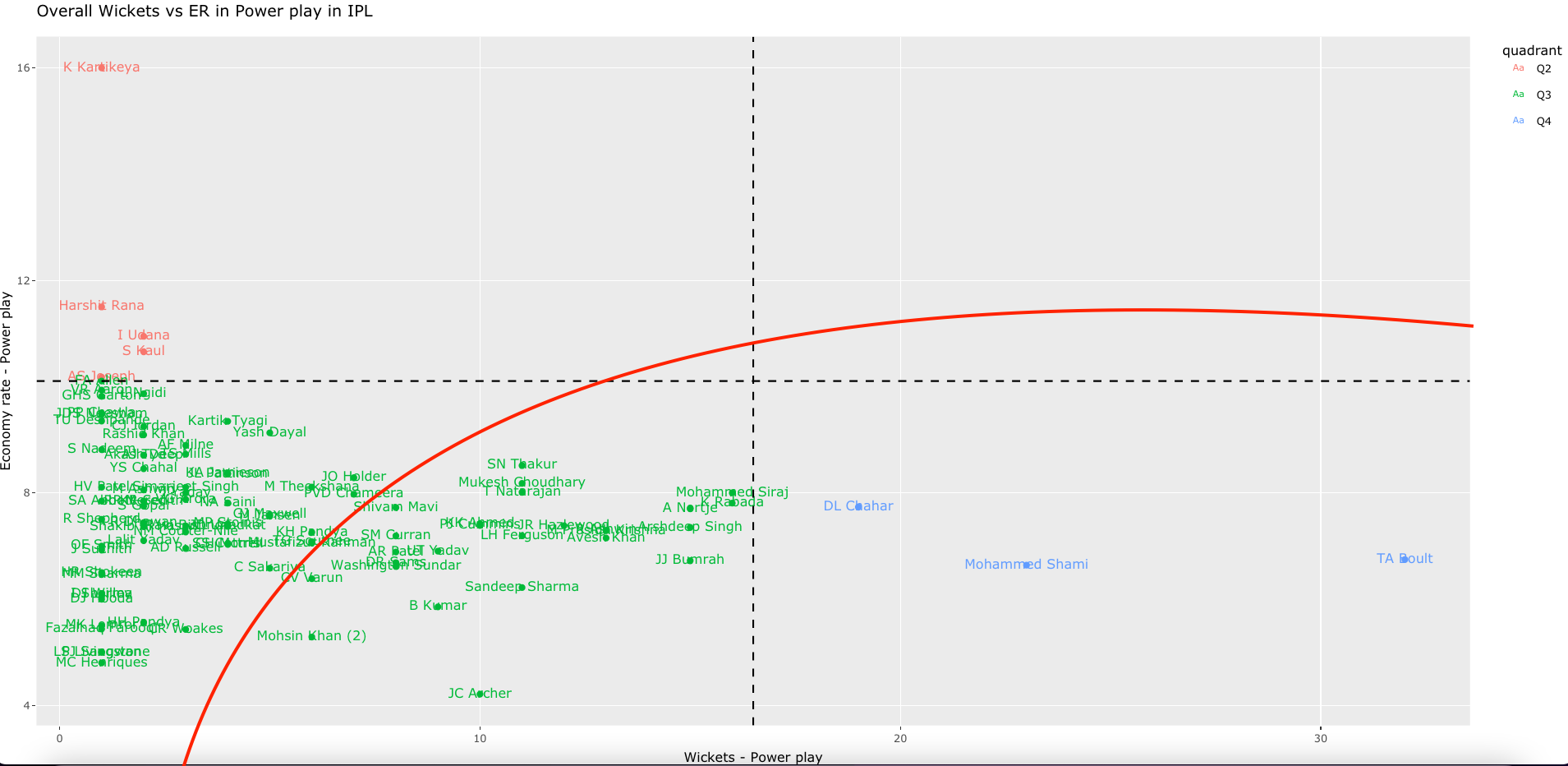
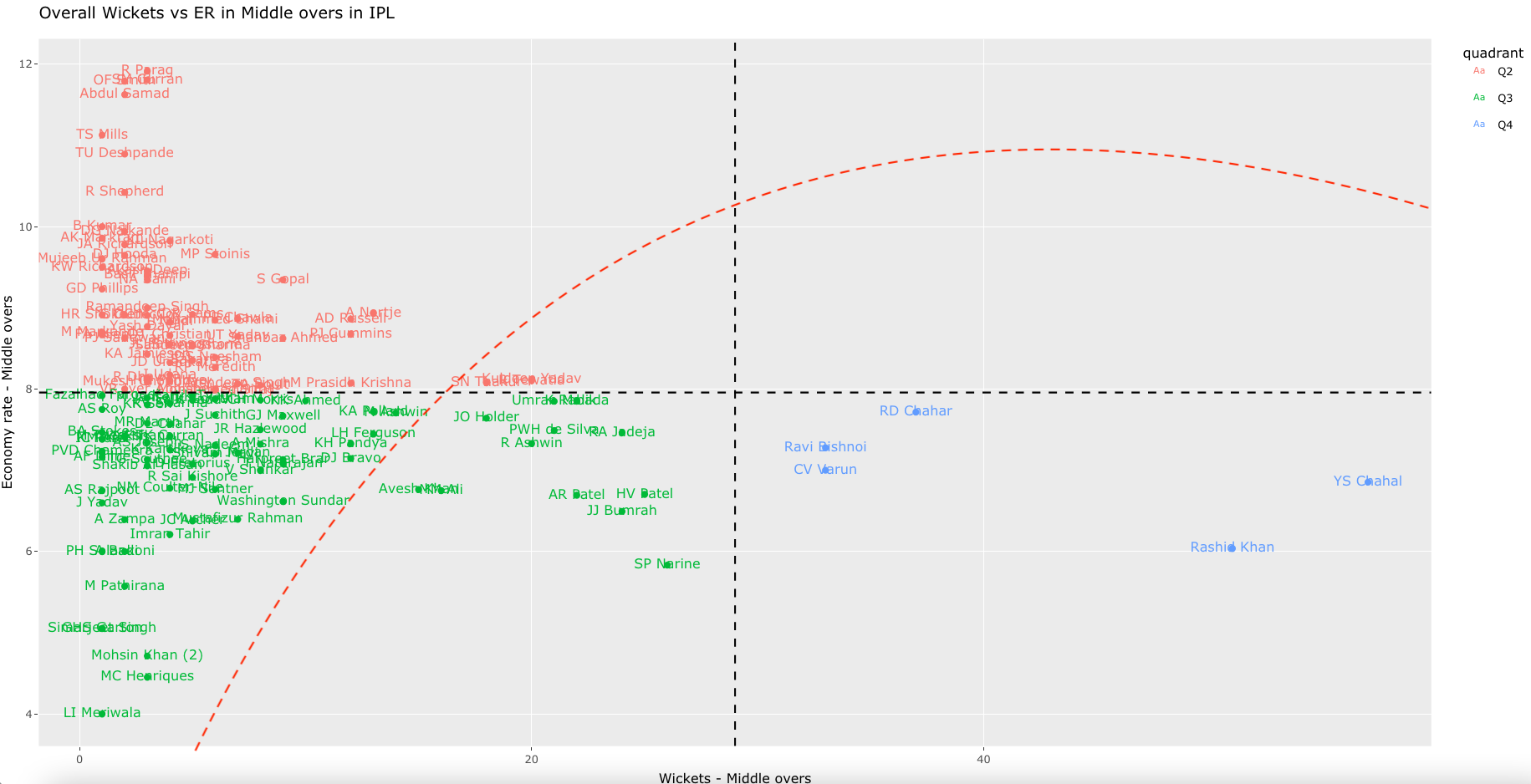
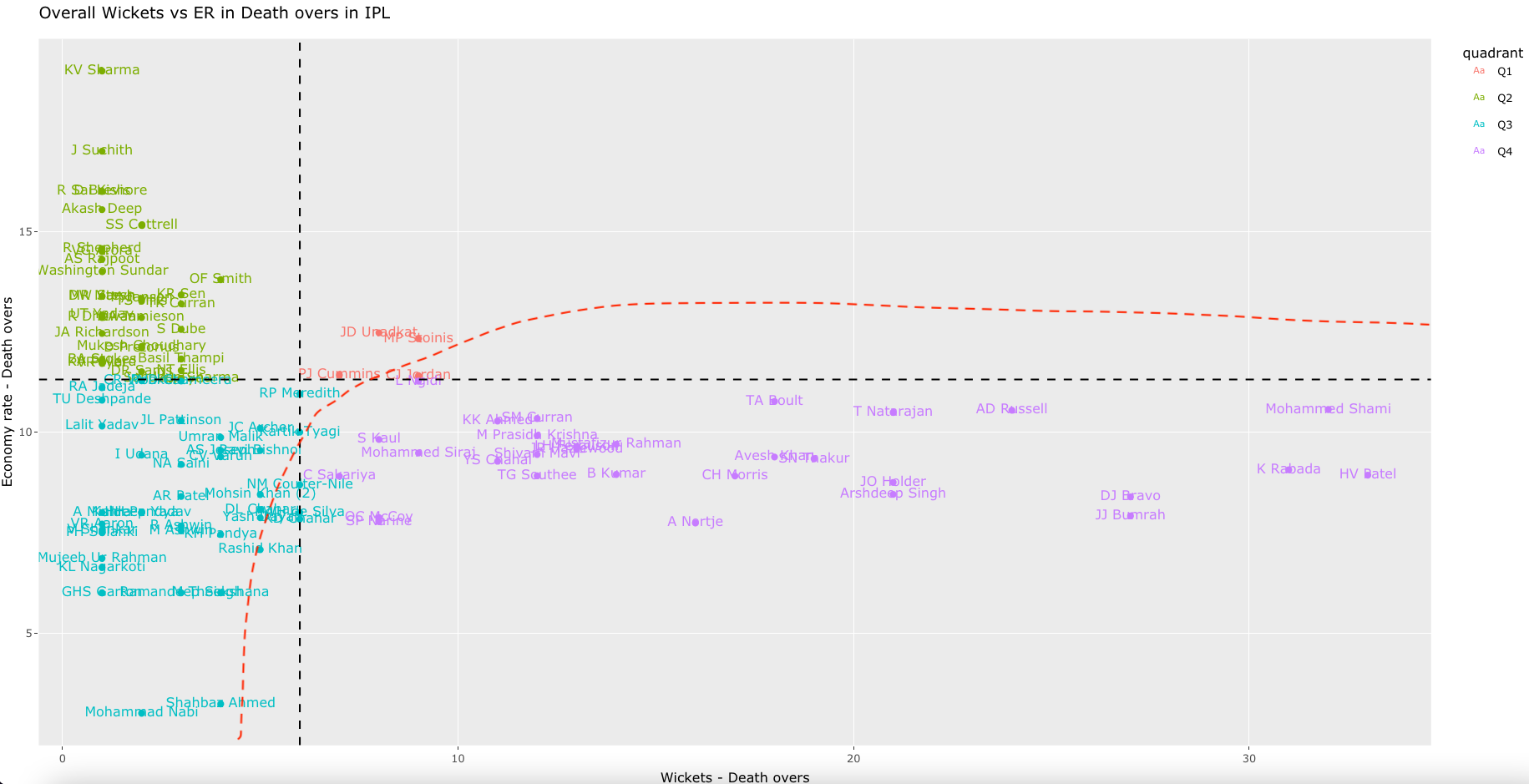
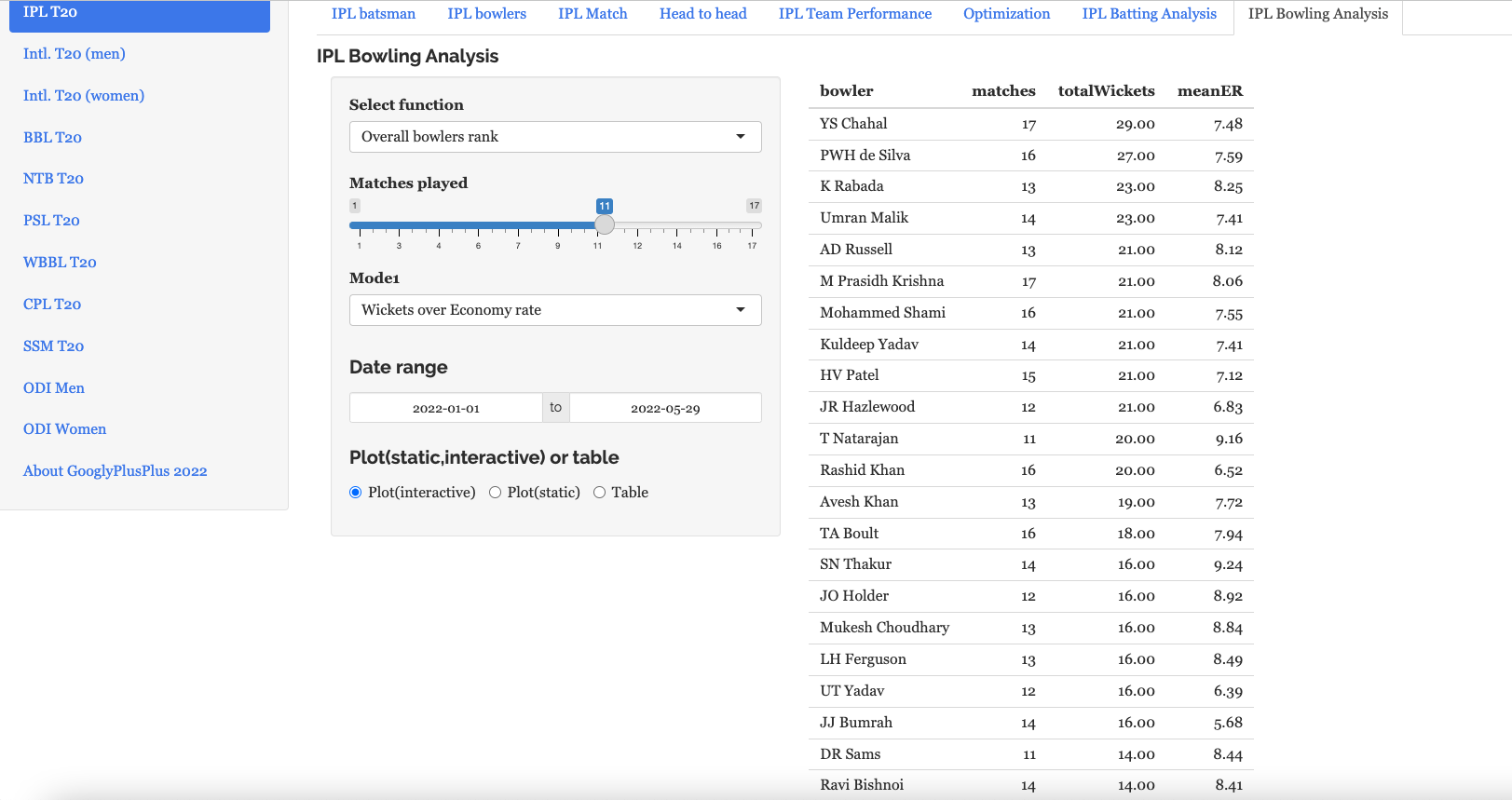
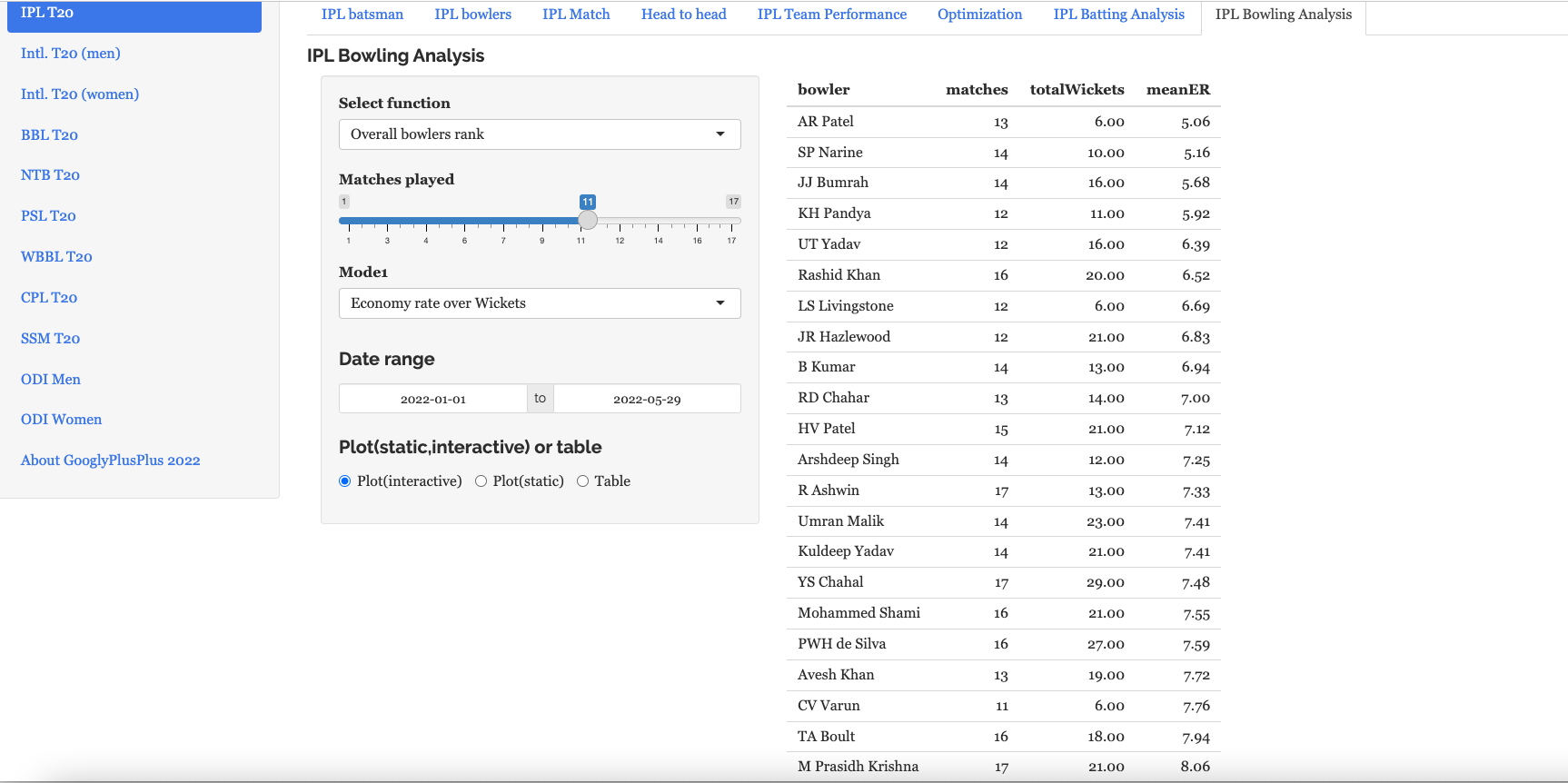
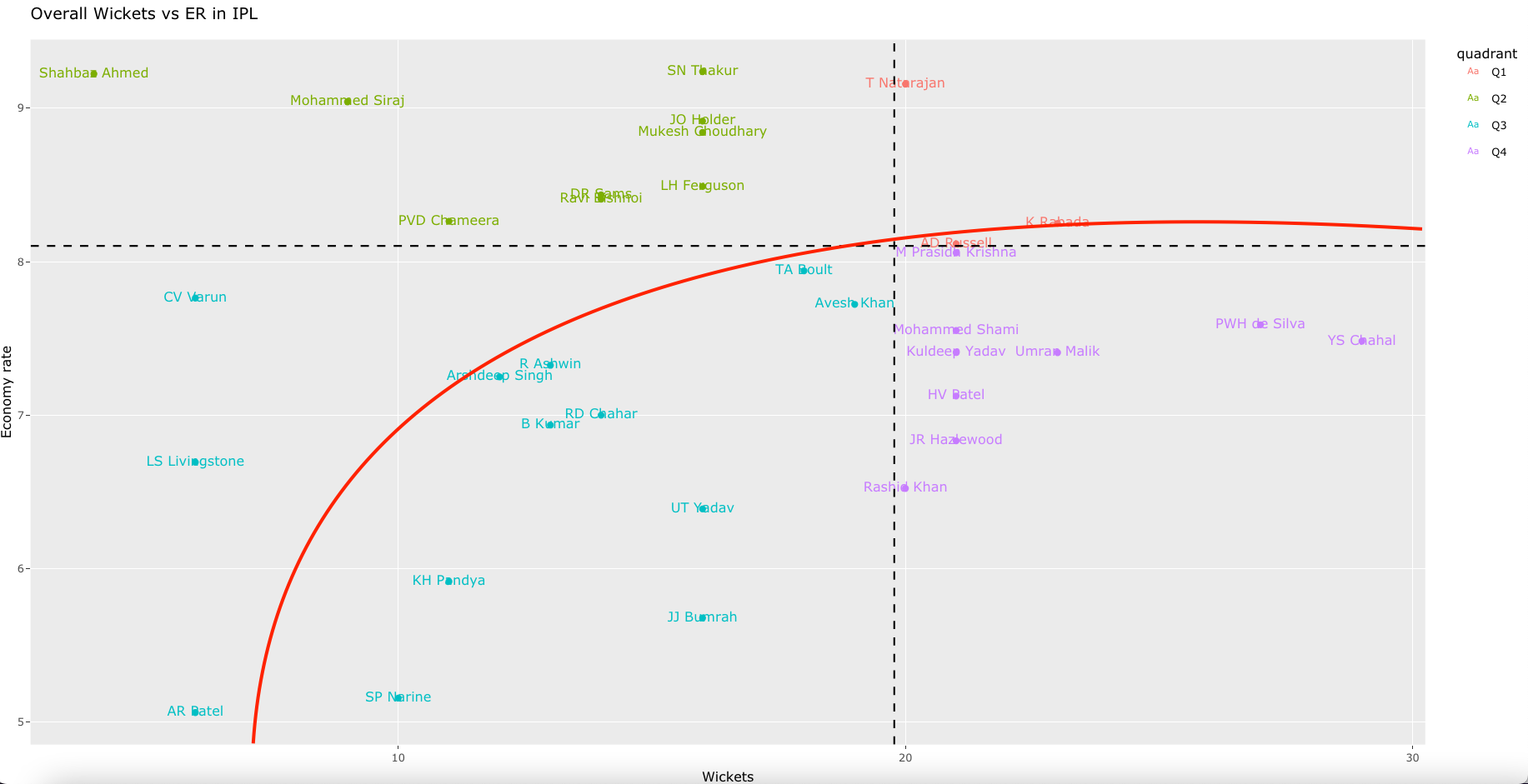
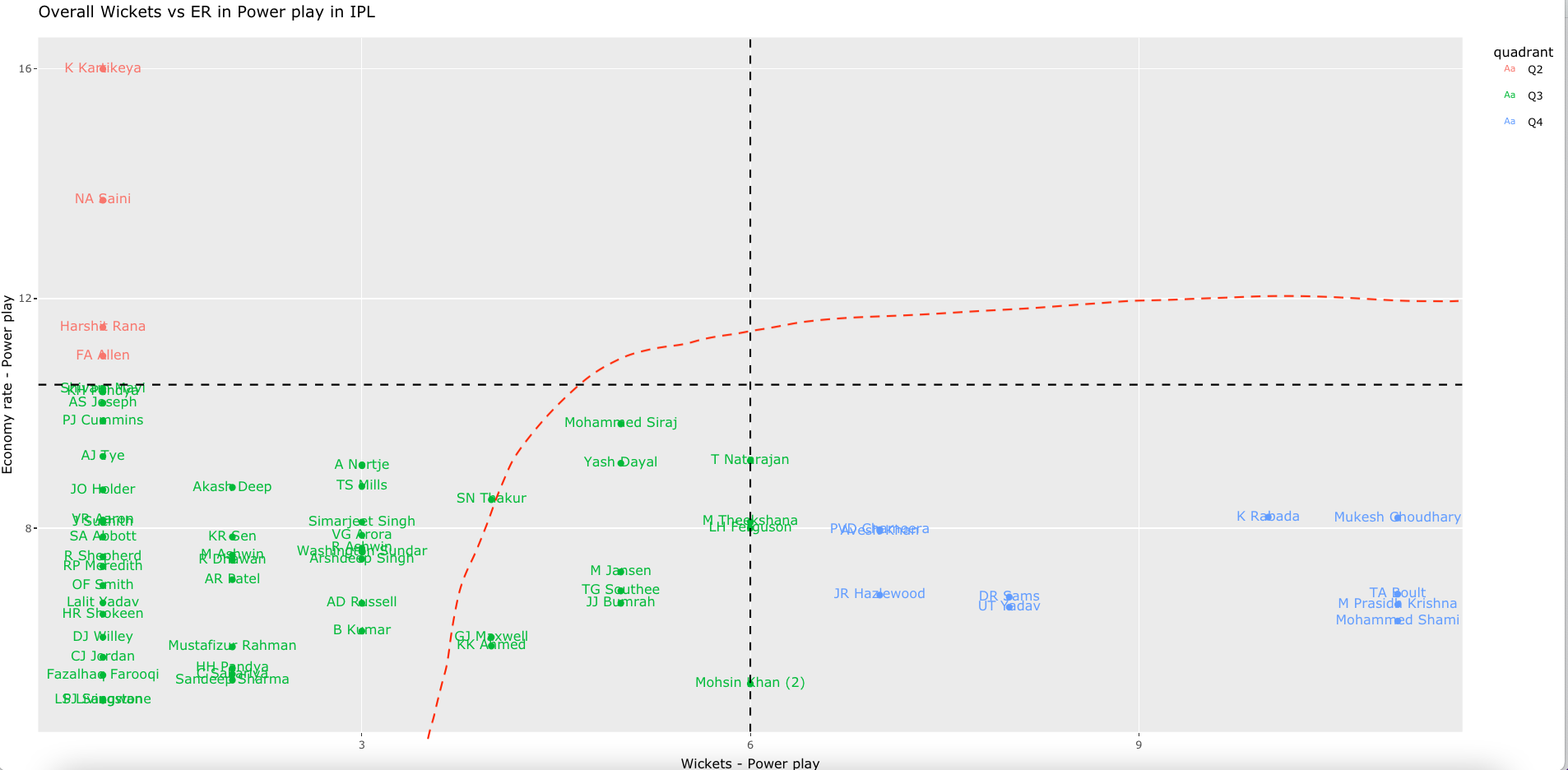
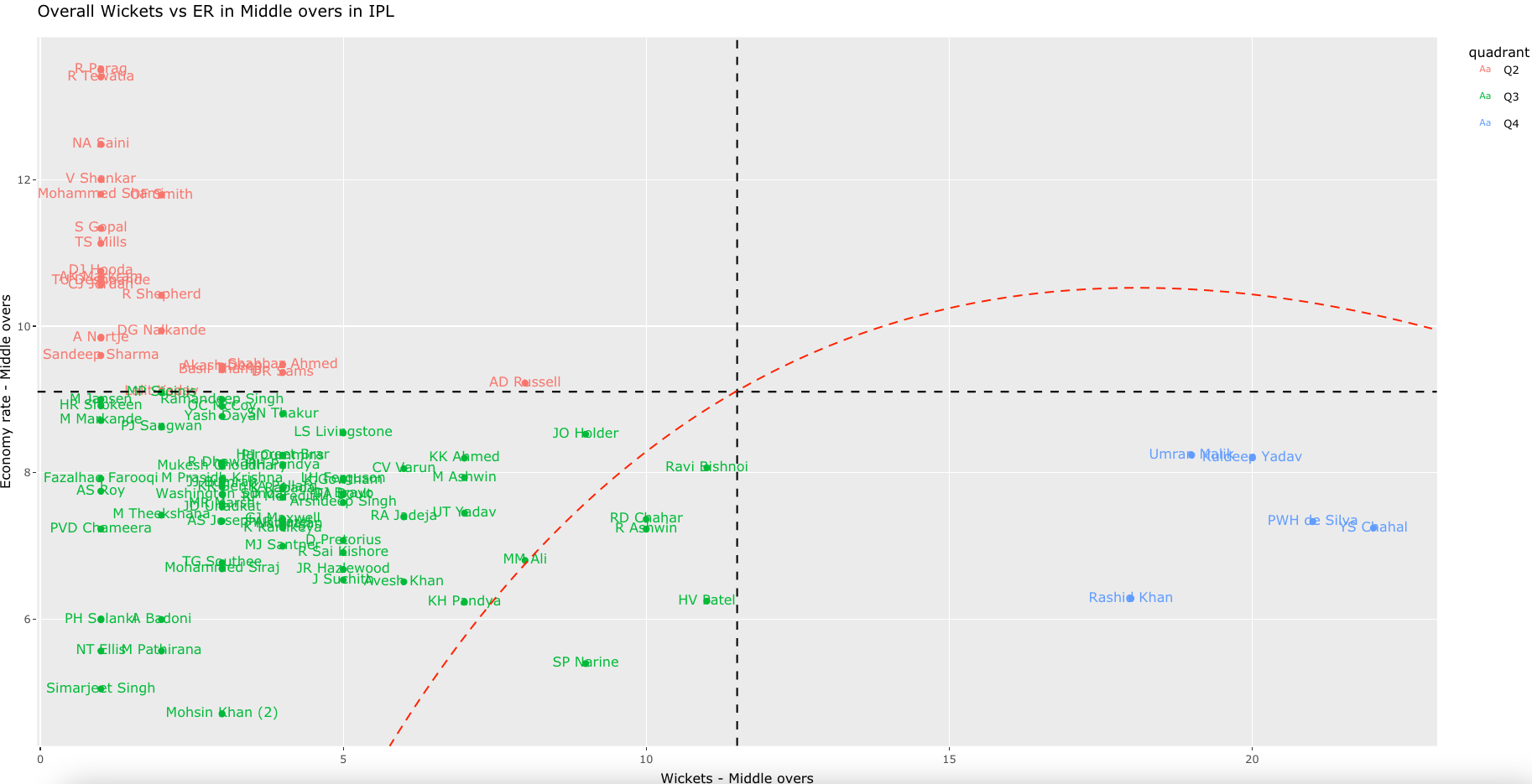
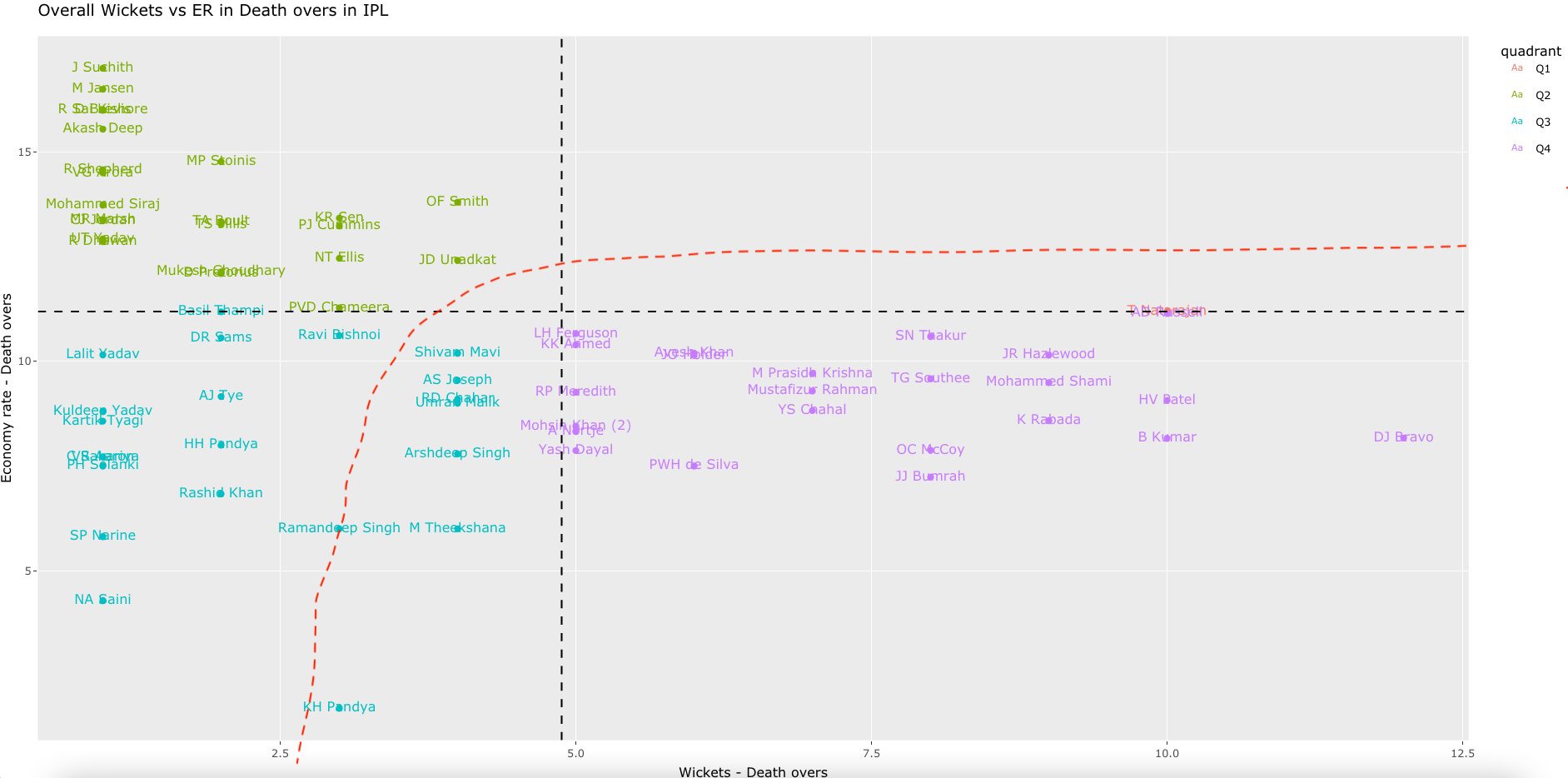
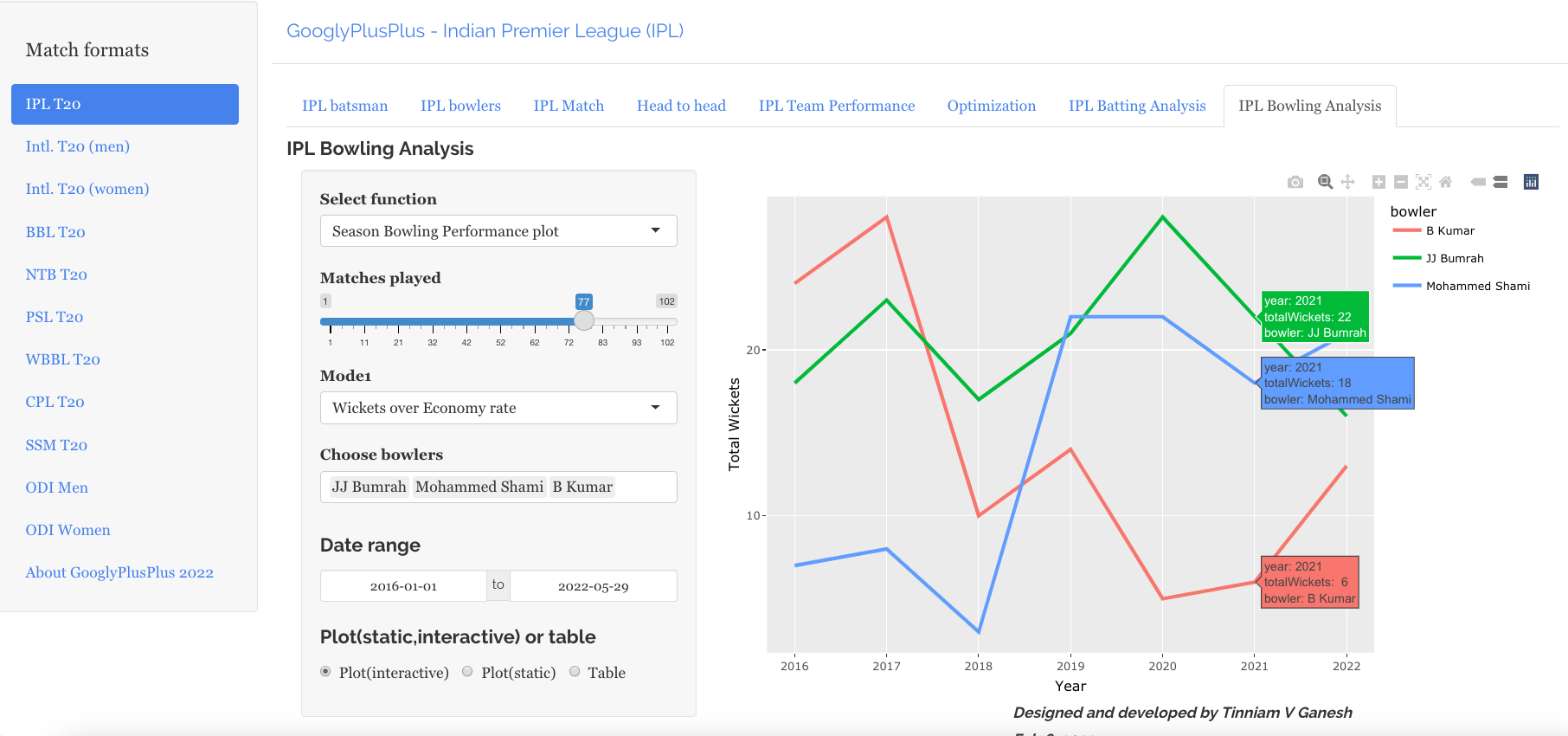
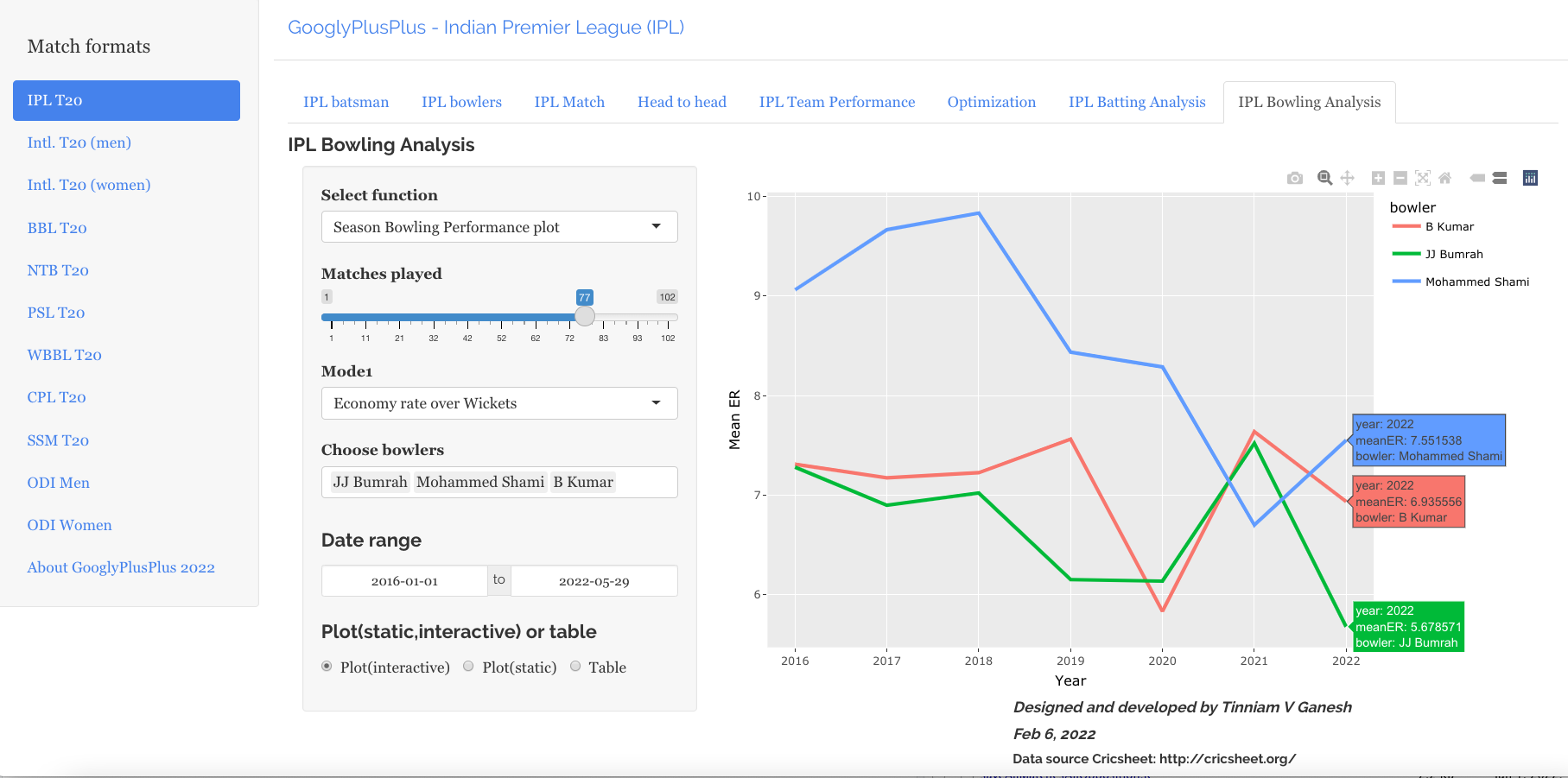
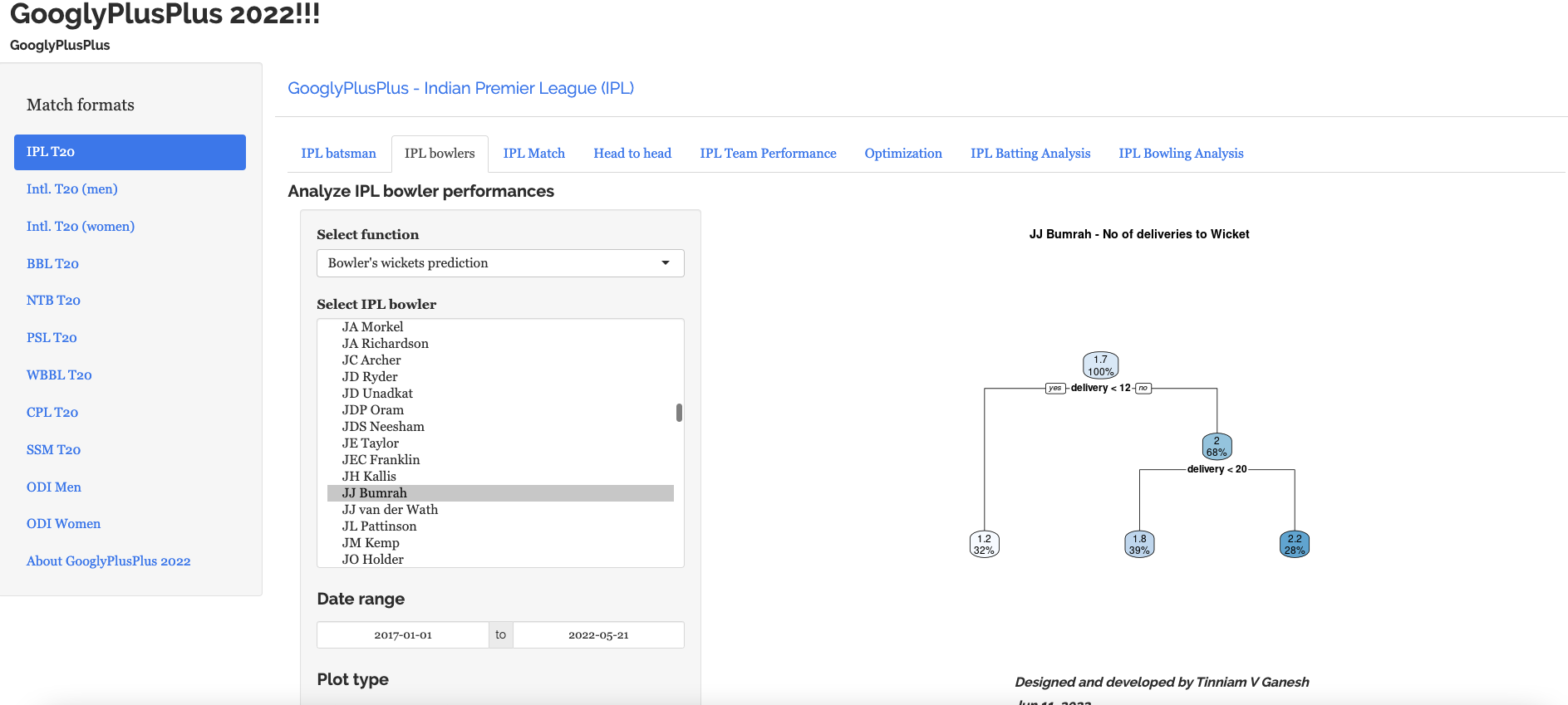

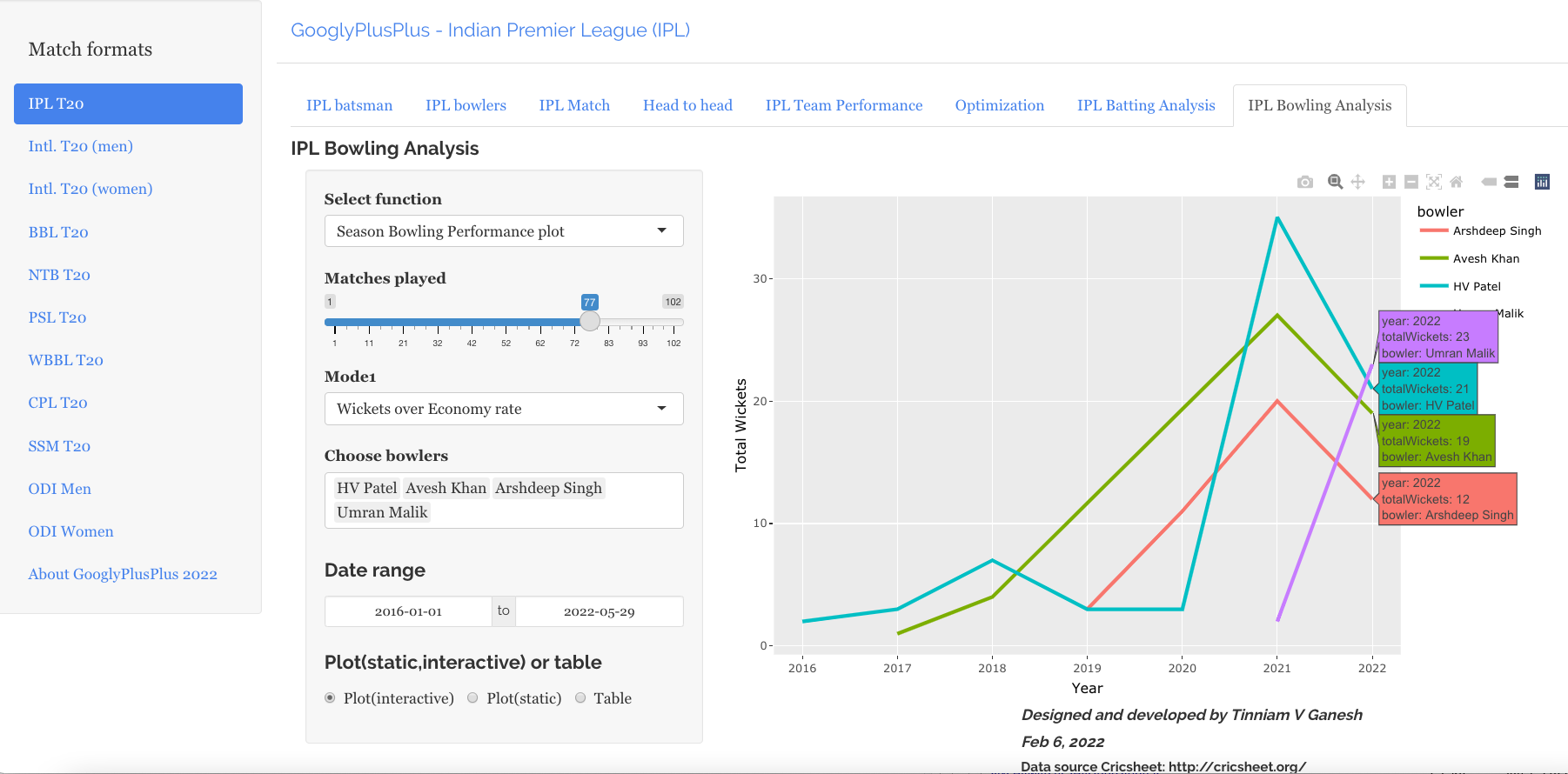
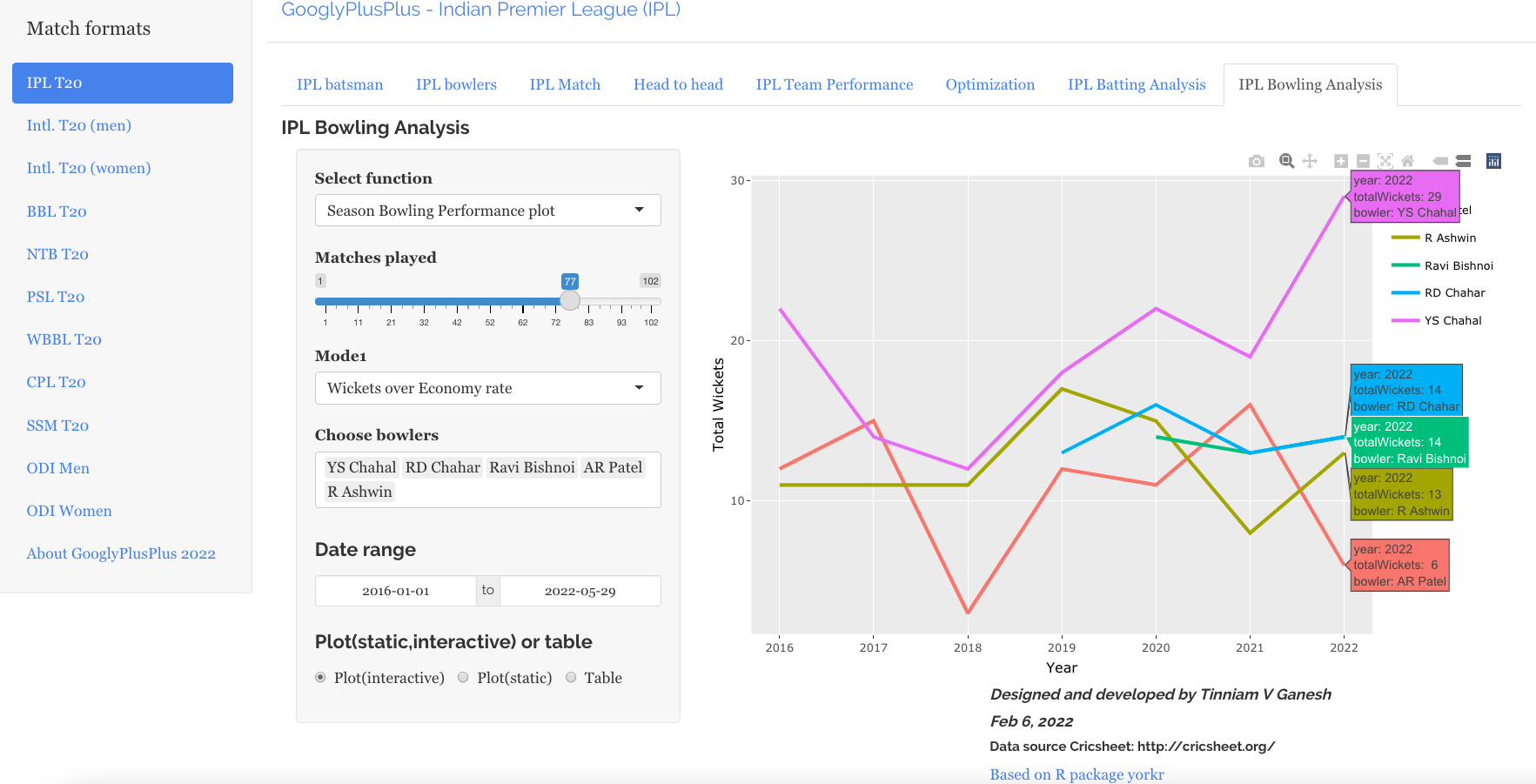
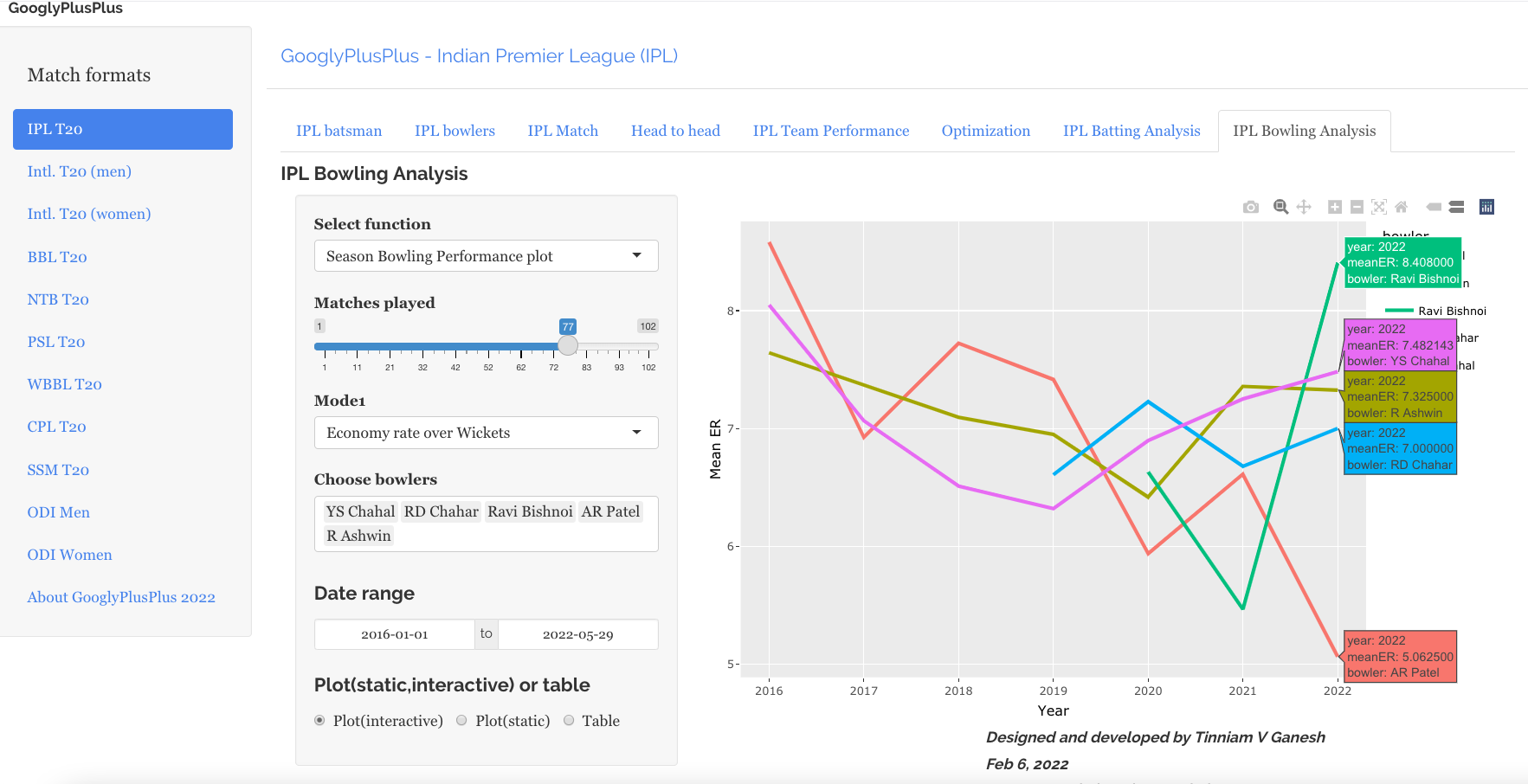

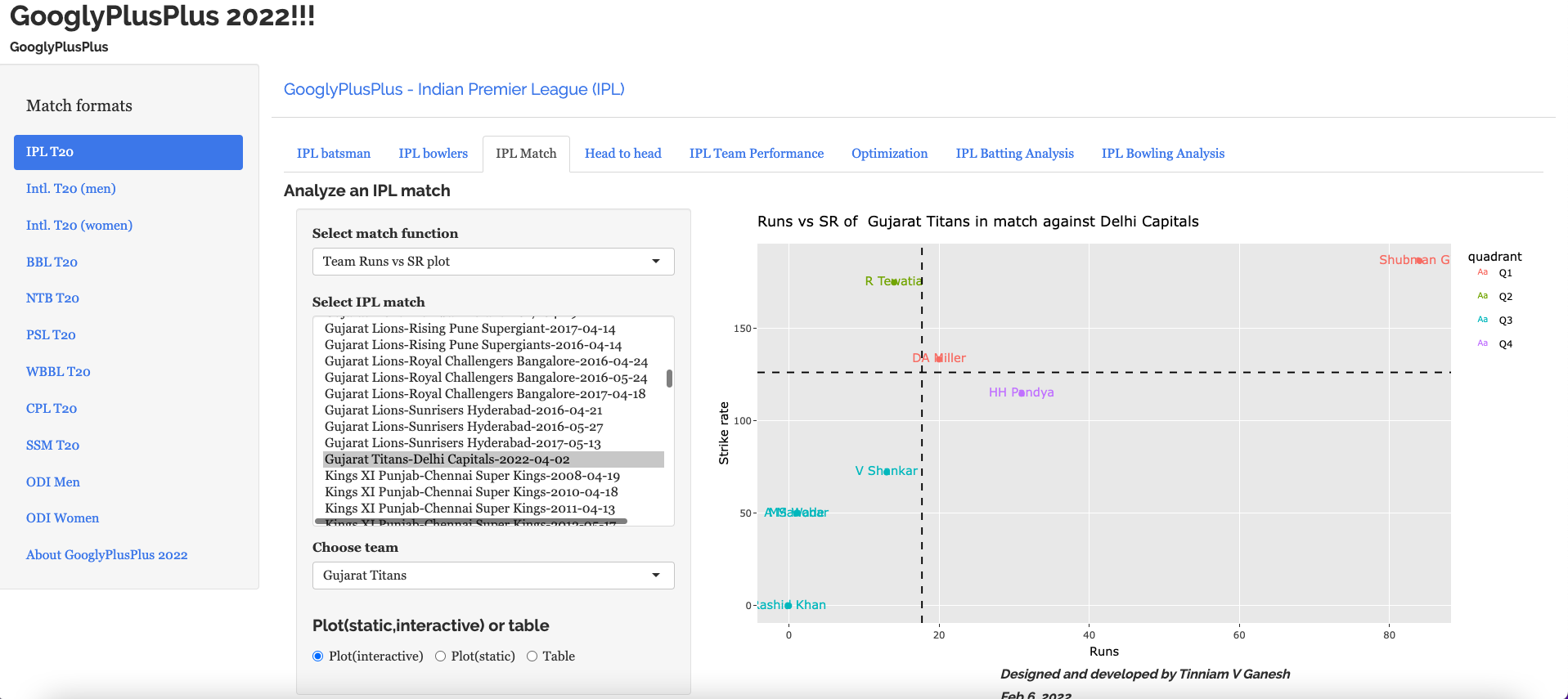
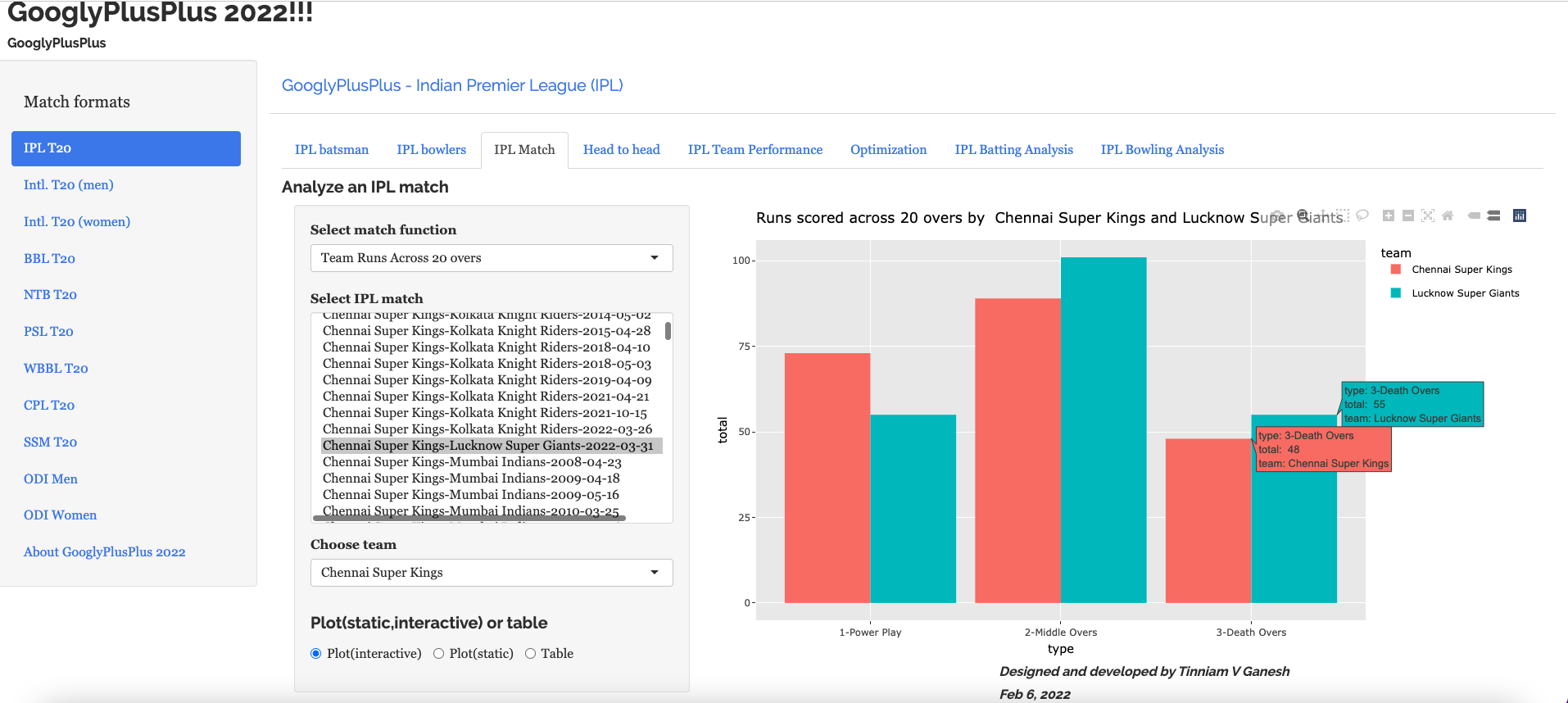
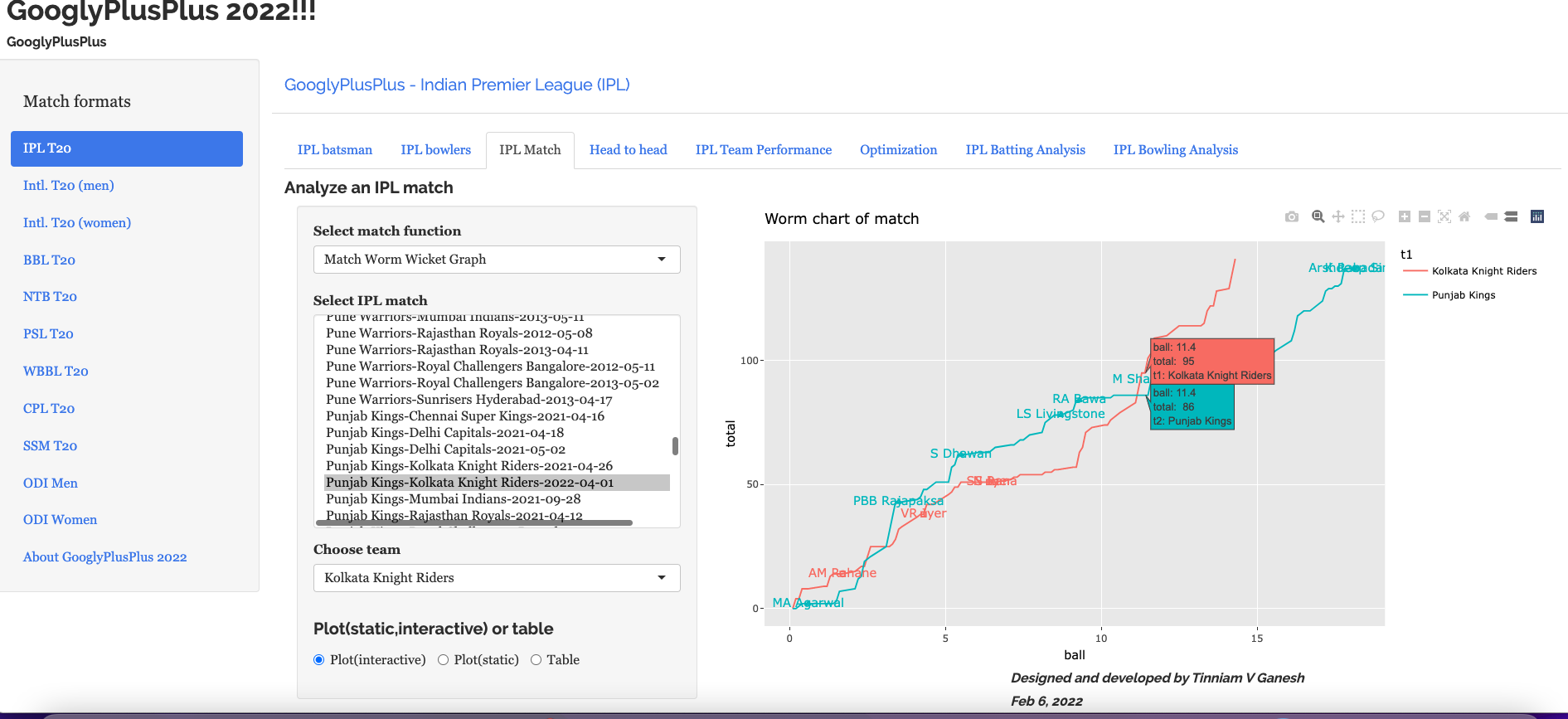
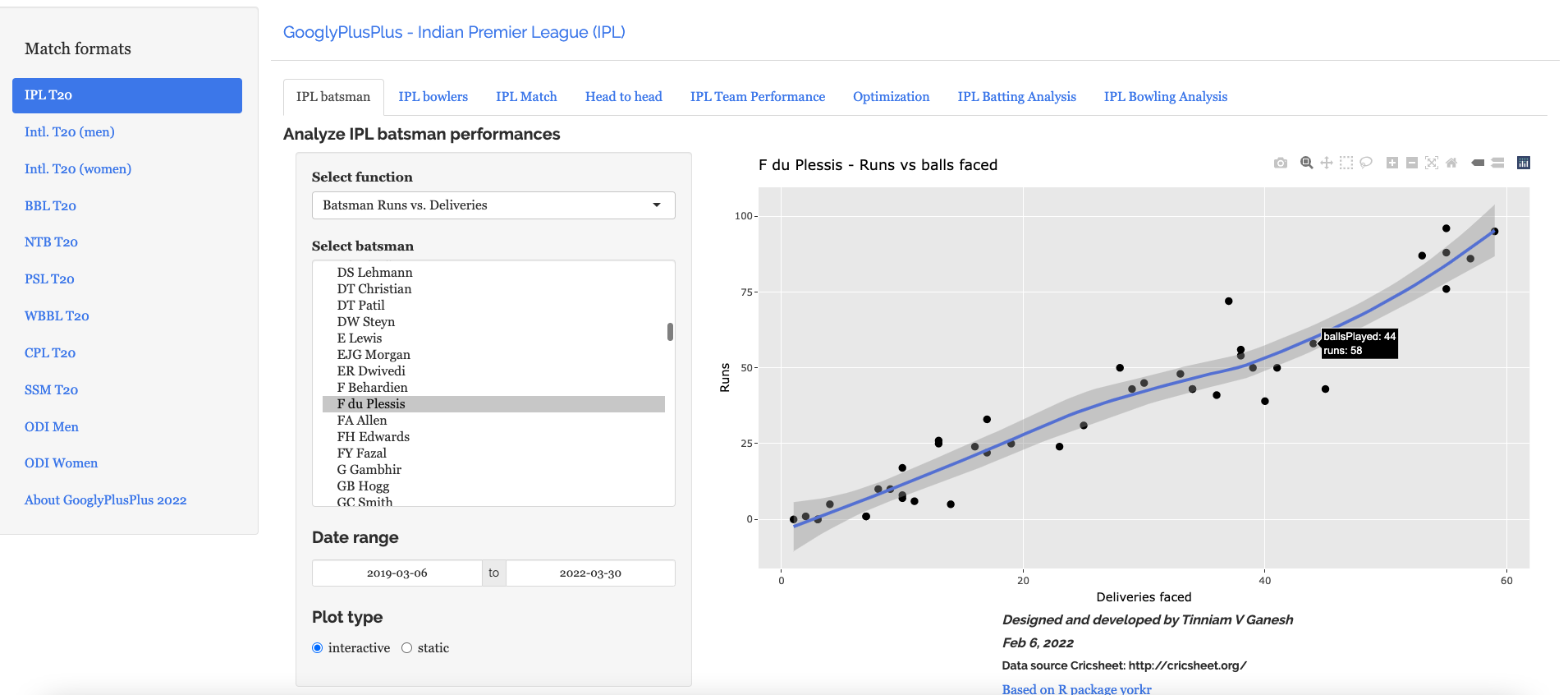
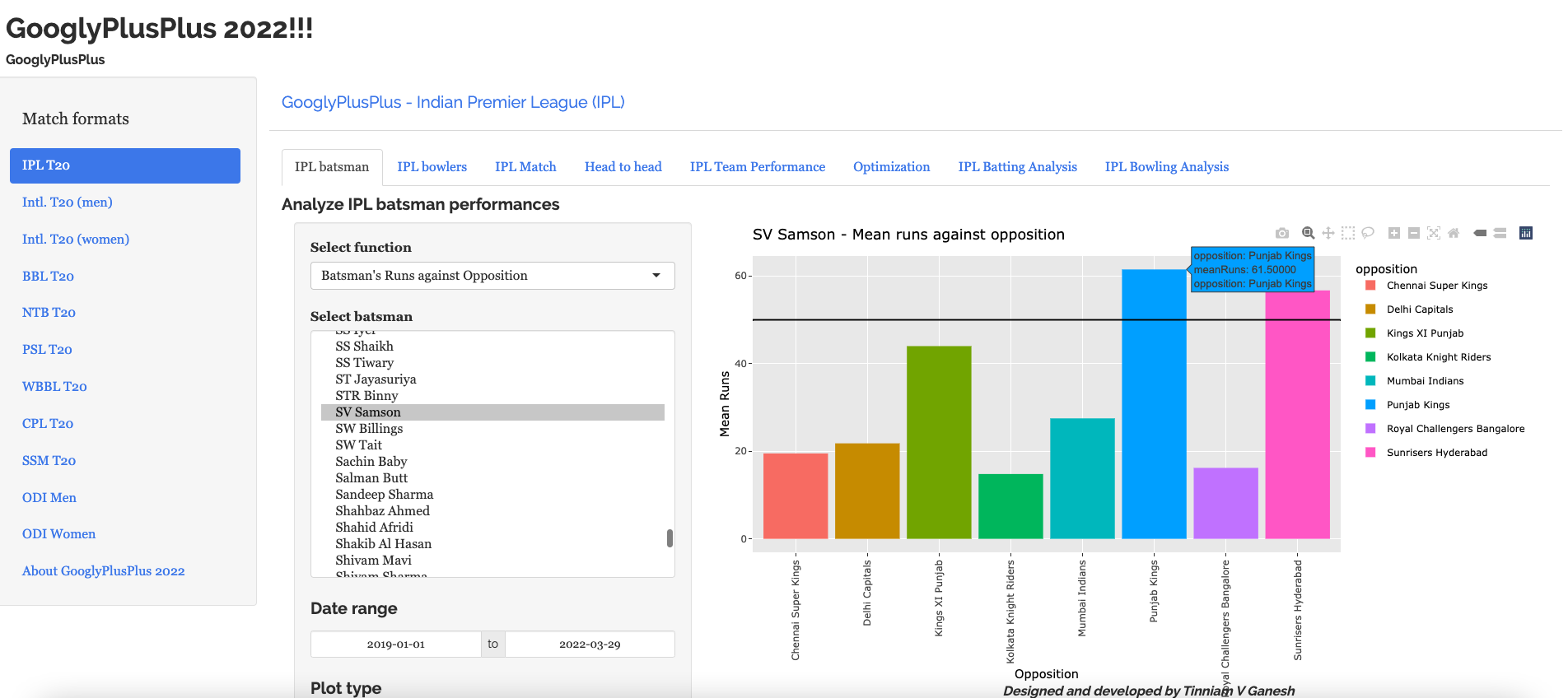
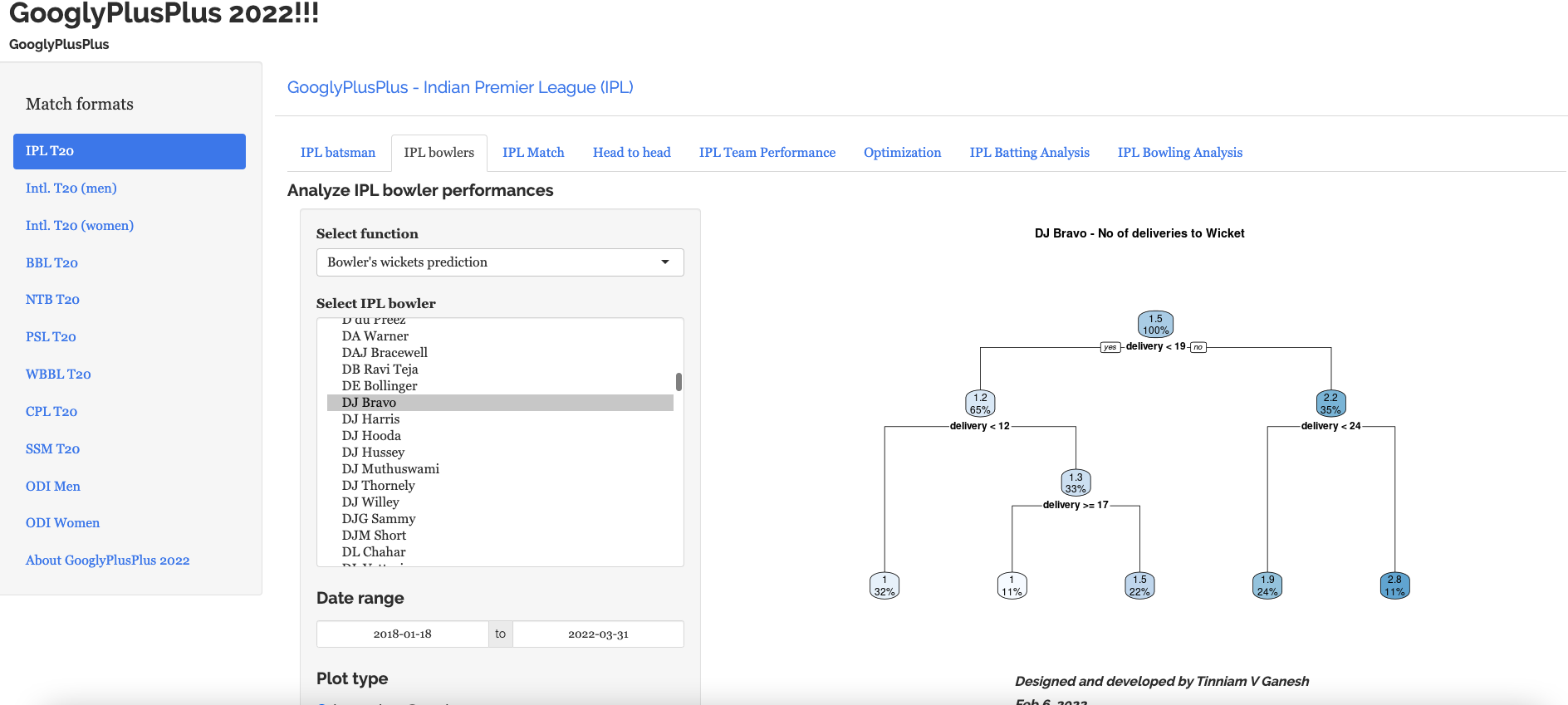

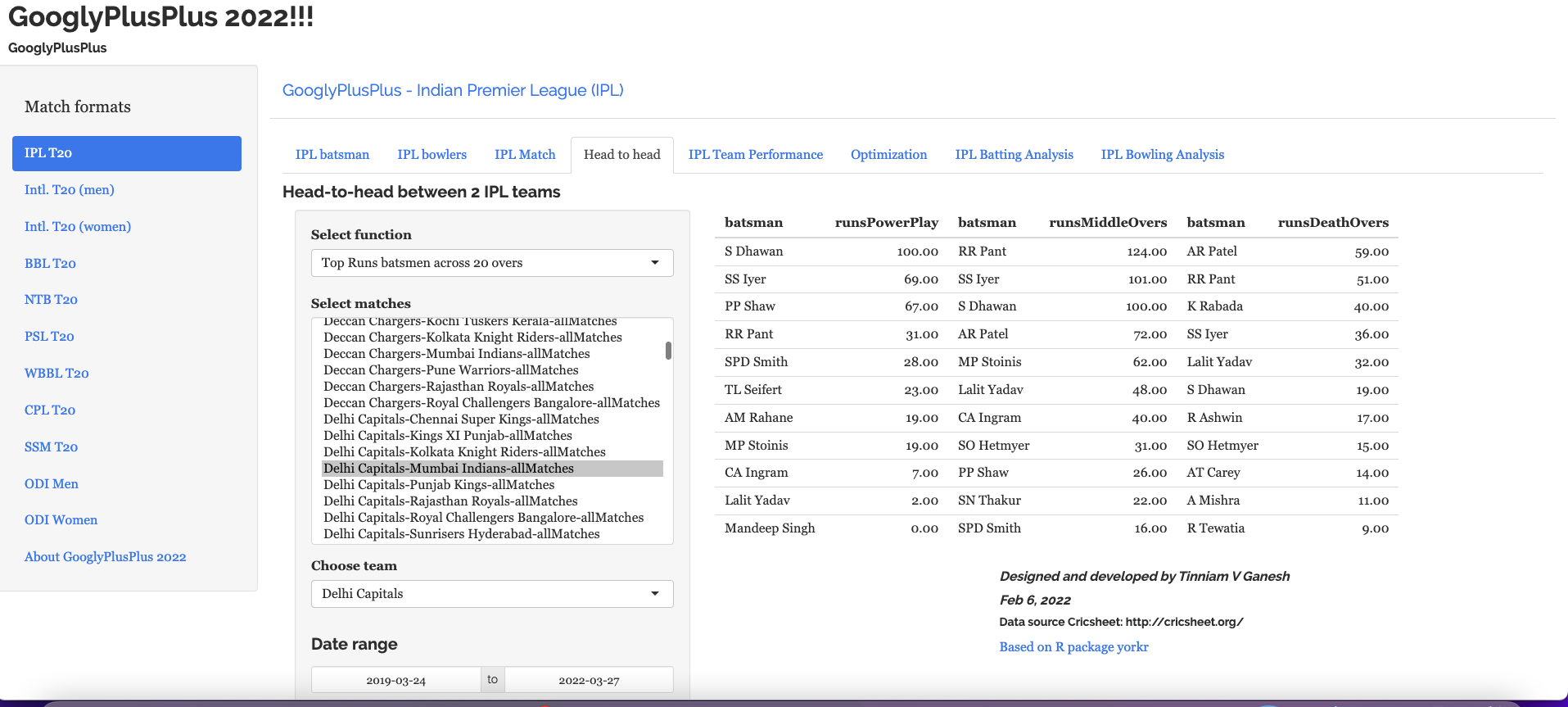
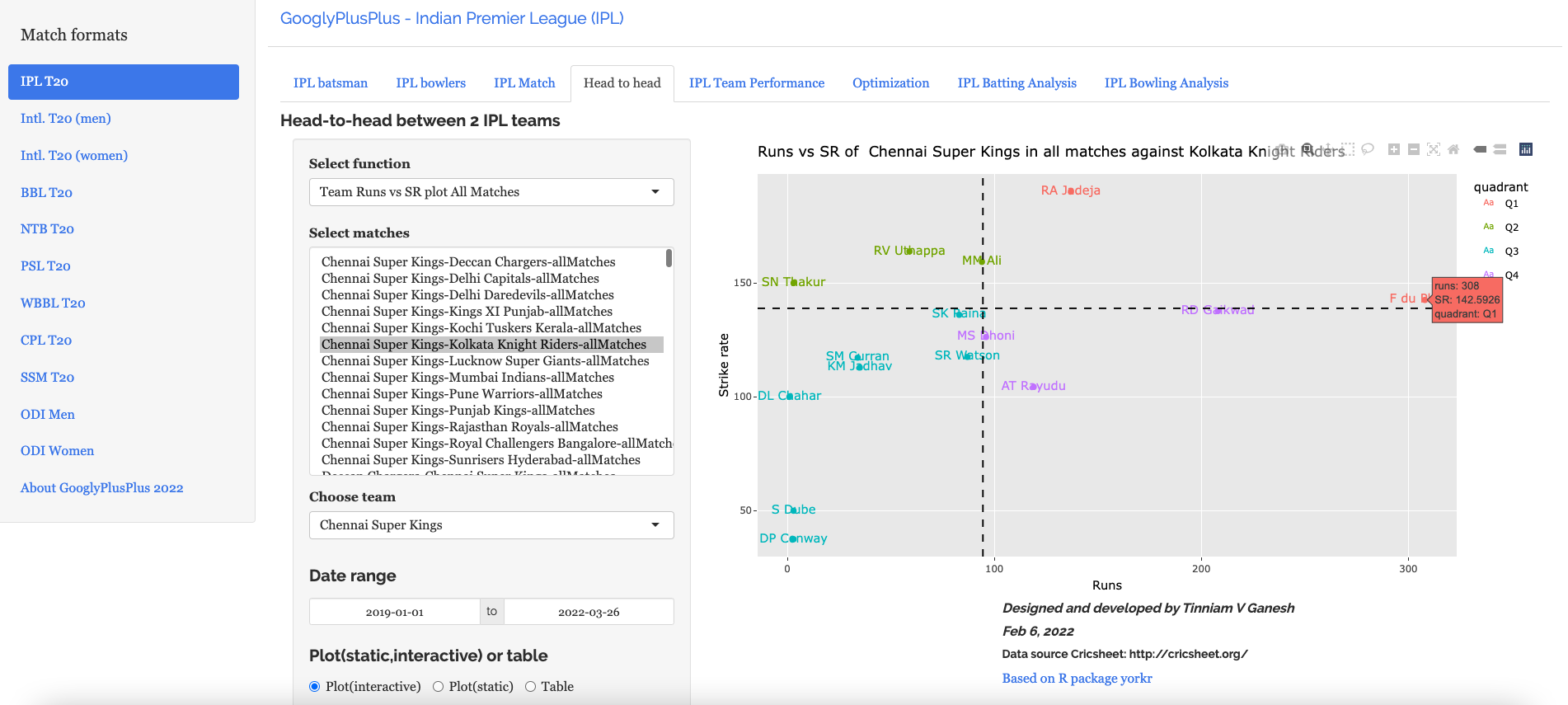
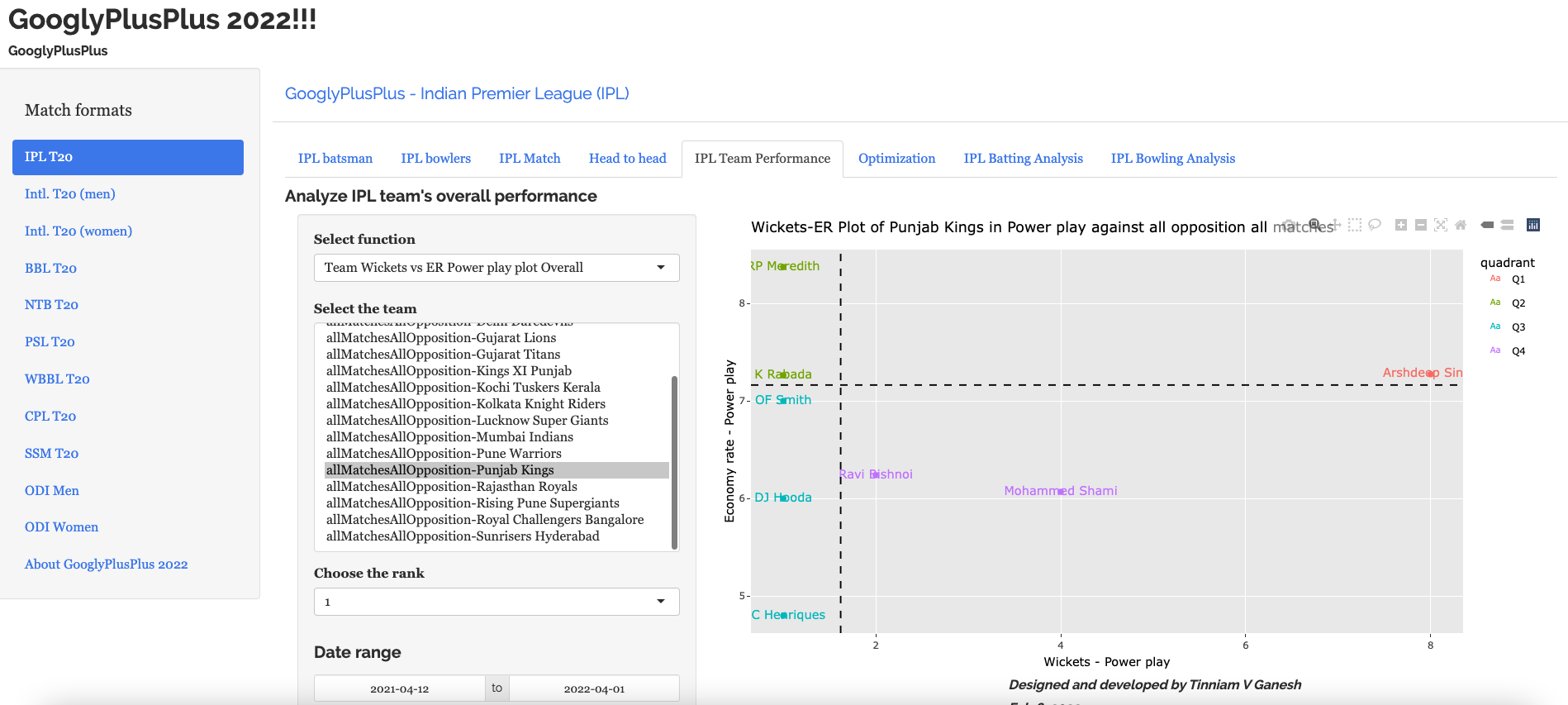
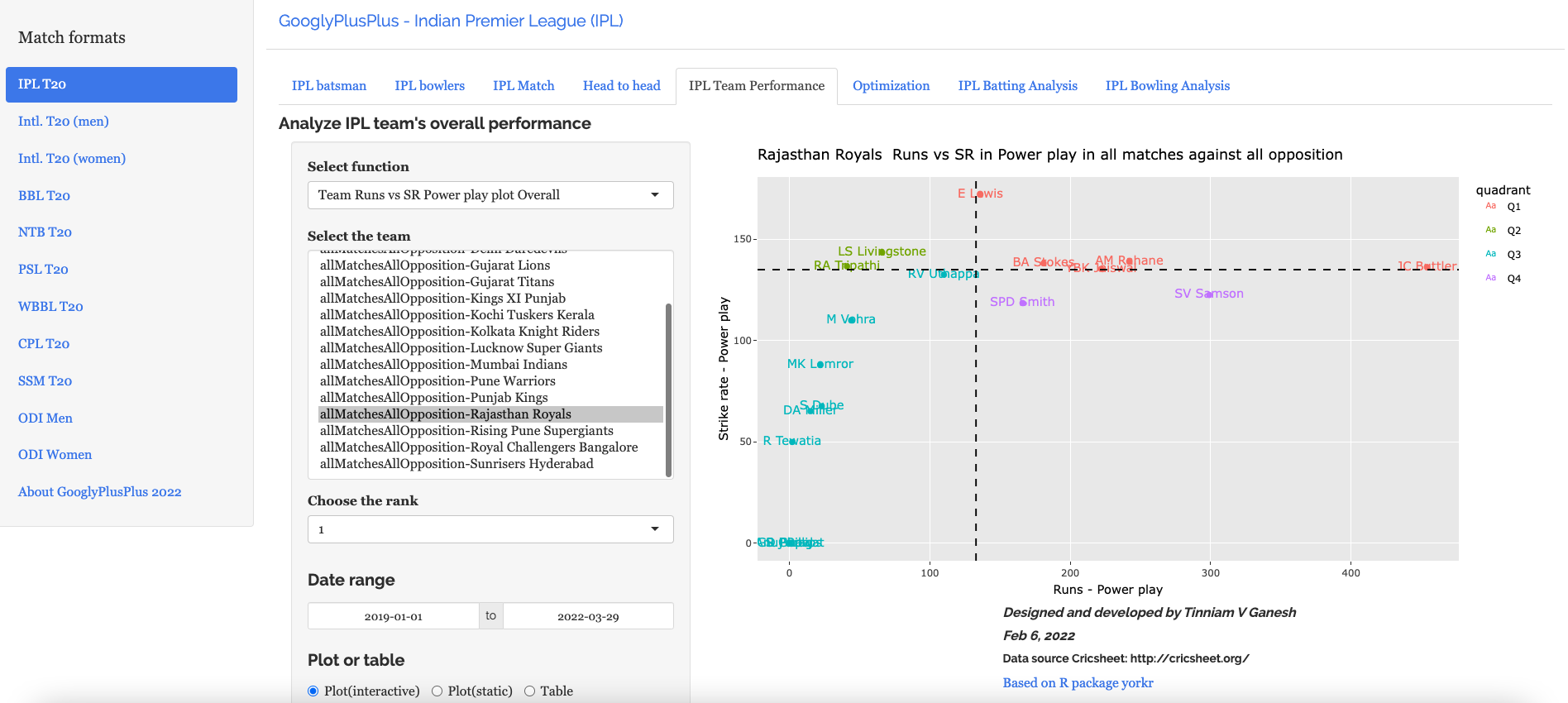
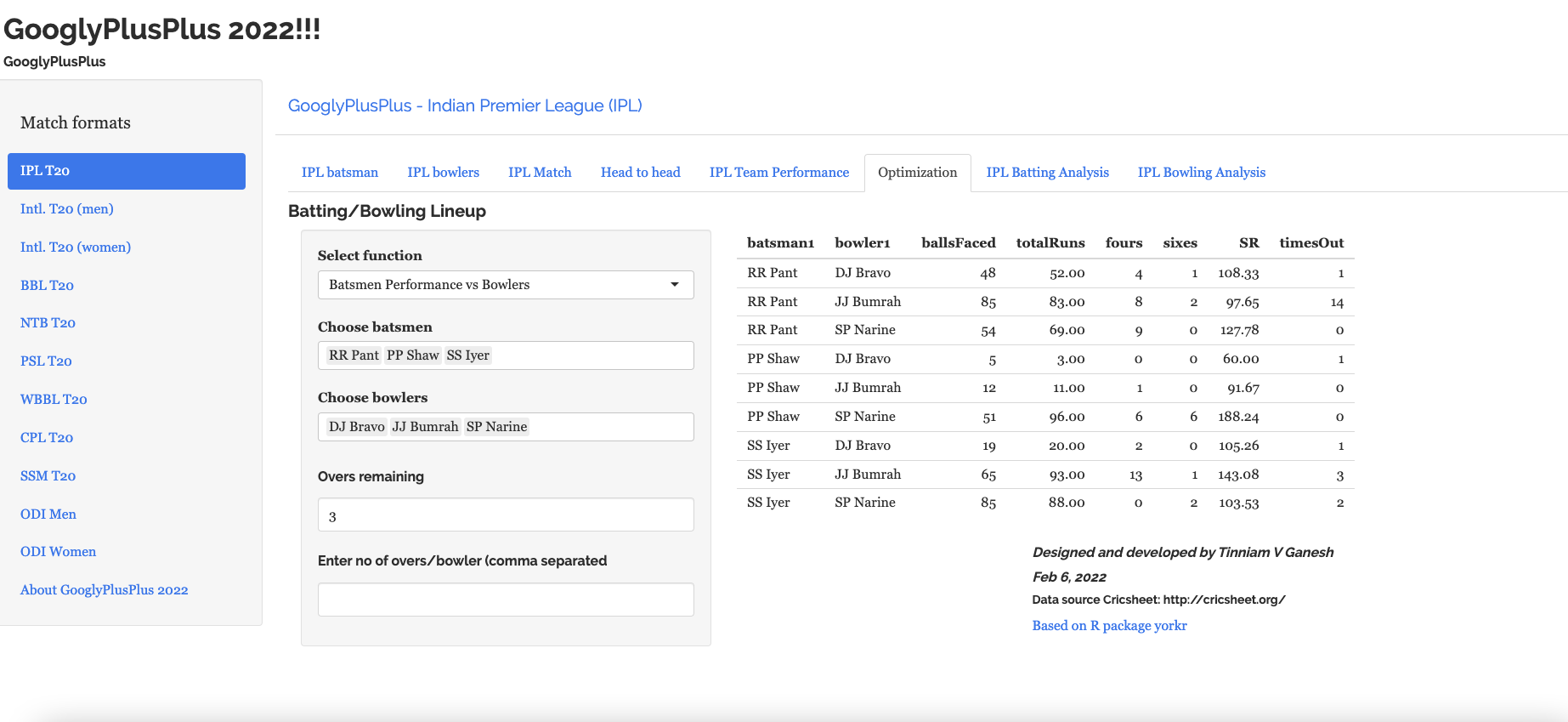


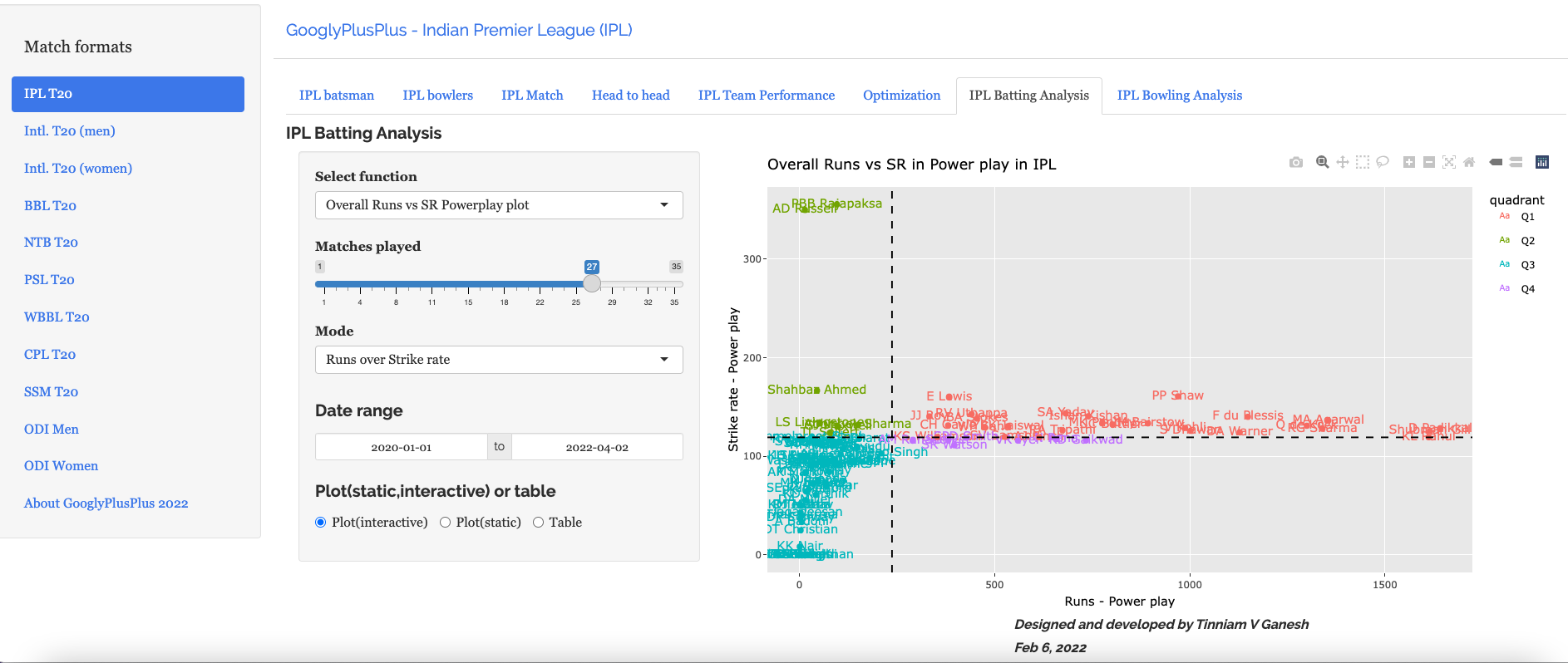




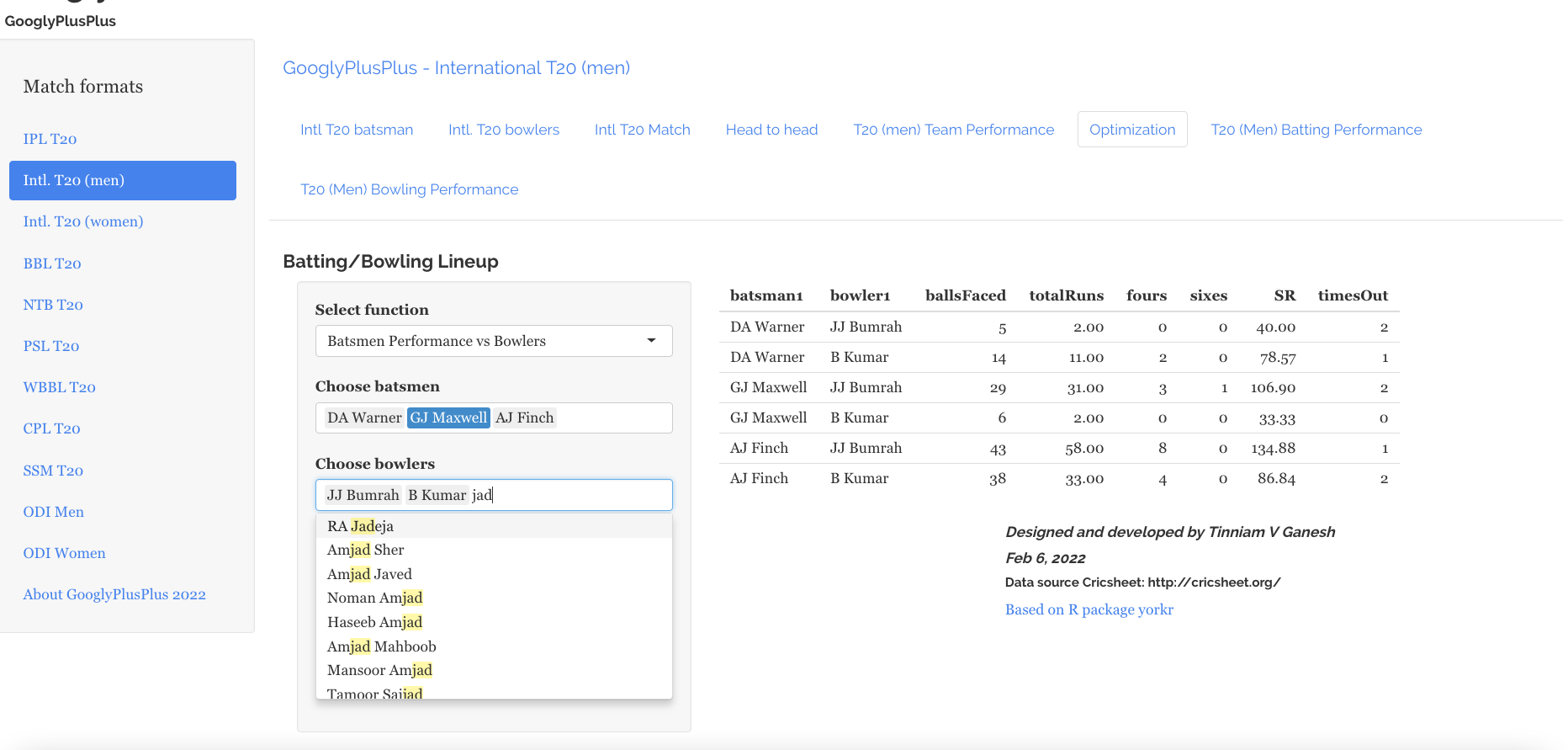
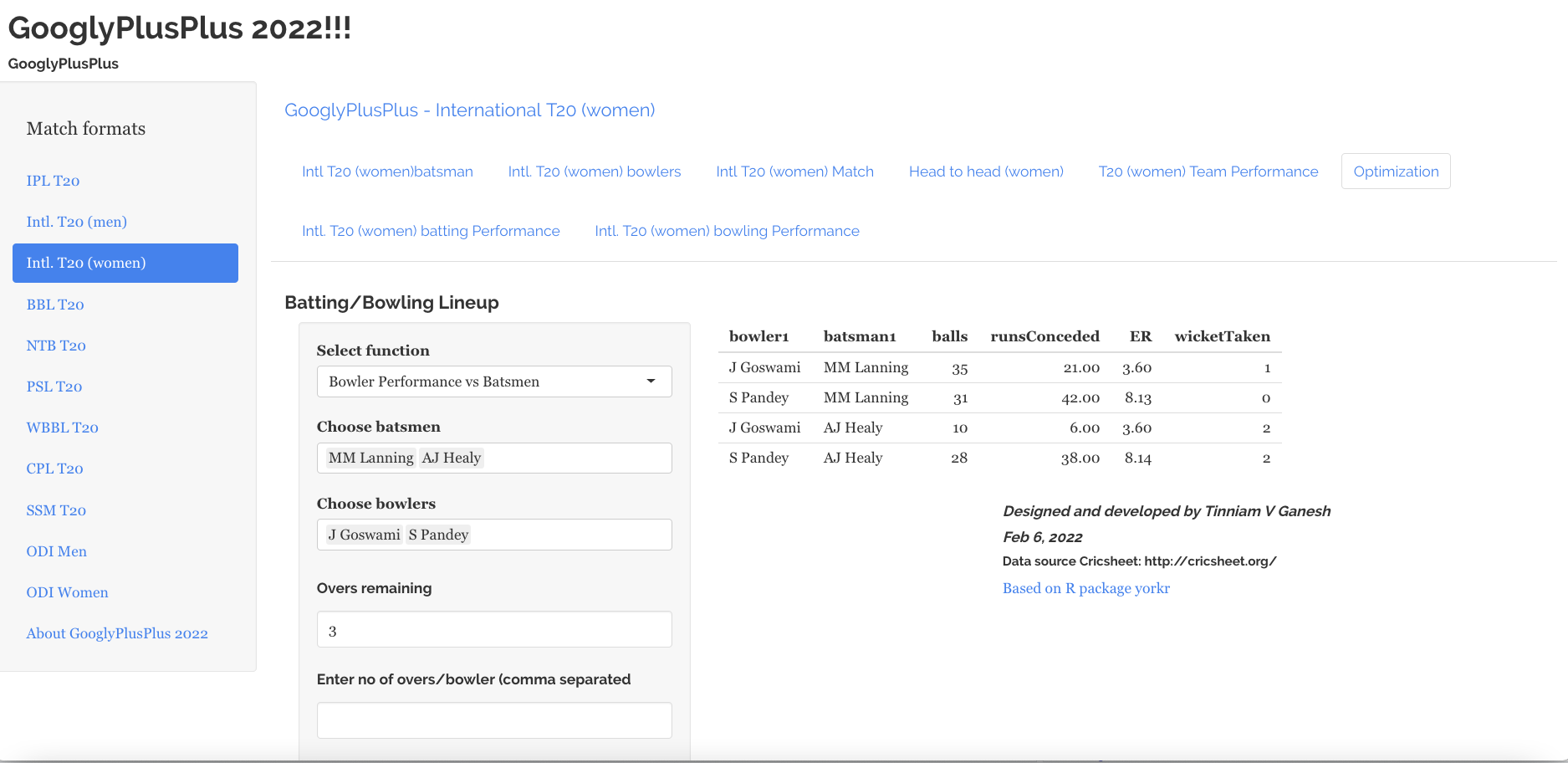
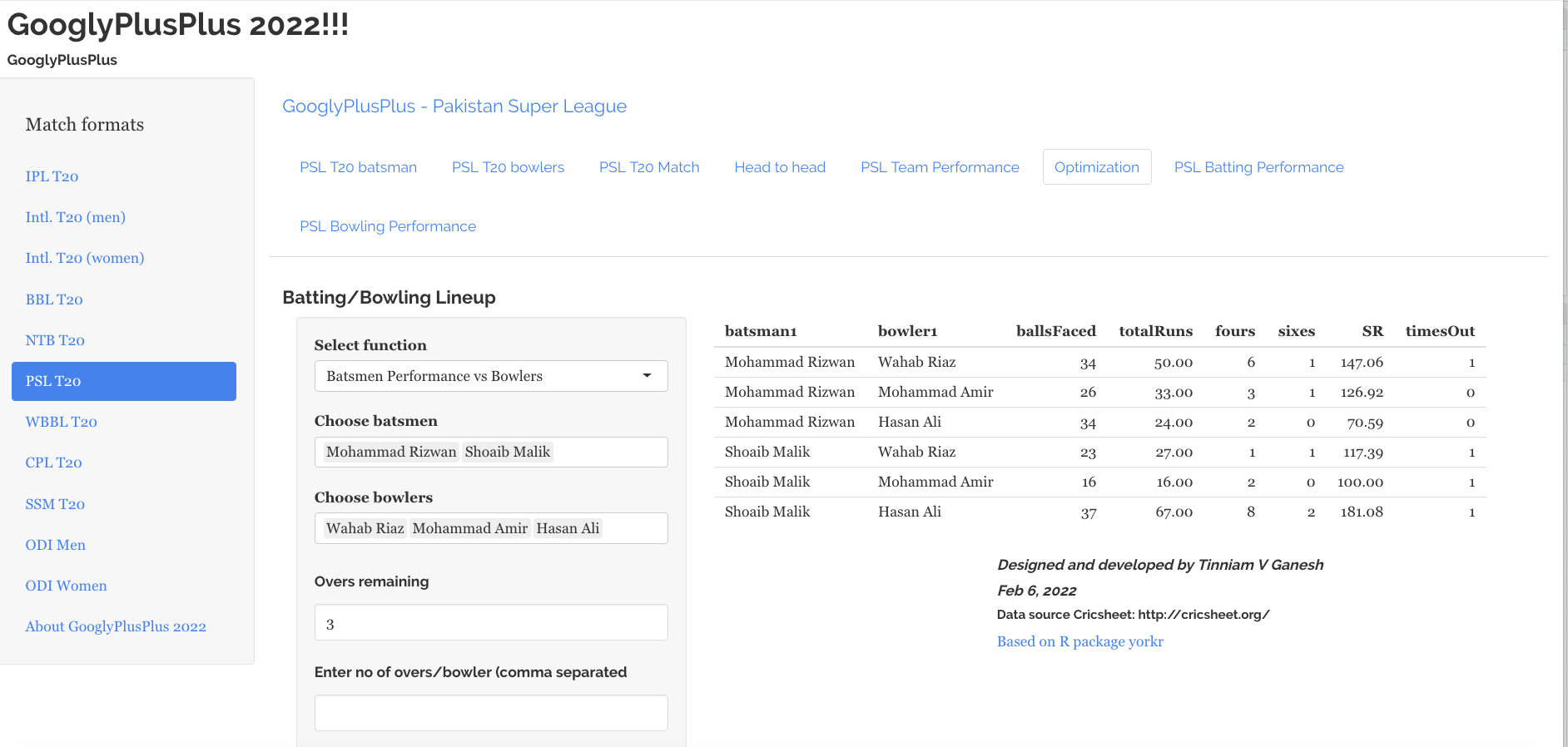
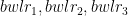
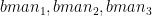
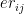 be the Economy Rate of the jth bowler to the ith batsman. Also if remaining overs for the bowlers are
be the Economy Rate of the jth bowler to the ith batsman. Also if remaining overs for the bowlers are 

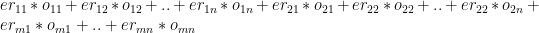

 is the number of overs remaining for the jth bowler against ‘k’ batsmen
is the number of overs remaining for the jth bowler against ‘k’ batsmen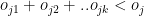
 or
or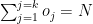
 be the Strike Rate of the ith batsman to the jth bowler
be the Strike Rate of the ith batsman to the jth bowler