This post is result of my dissatisfaction with the awkward and contrived gait of my Robot Walker in my earlier post “Simulating a Robot Walker” in Android. The movements seemed to be a little too contrived for my comfort so I decided to make a robot which has far more natural movements.
This post is result of my dissatisfaction with the awkward and contrived gait of my Robot Walker in my earlier post “Simulating a Robot Walker” in Android. The movements seemed to be a little too contrived for my comfort so I decided to make a robot which has far more natural movements.
You can see the clip at Robot Horse on a canter using Android on Youtube
The complete code can be cloned at GitHub RobotHorse
To do this I pondered on what constitutes a walking motion for any living thing. With a little effort it is clear that the following movements occur during walking
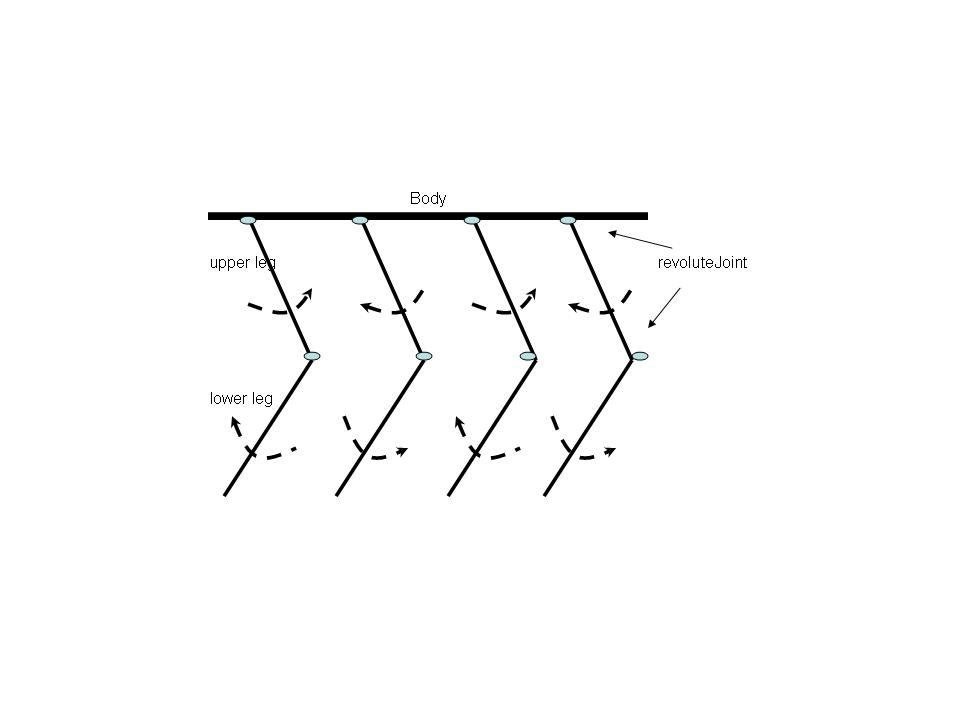
Mechanics of leg movements during walking
- The upper part of the leg swings upward and downward pivoted at the hip.
- The lower part of the leg, pivoted at the knee, swings in the opposite direction to the upper part of the leg. i.e when the upper part swings upward and counter-clockwise, the lower part of the leg swings downward & clockwise which results in the bend at the knees
- When one leg goes up, counterclockwise, the other leg goes down or it swing clockwise and vice versa. See figure below

So with these rules it was easy to make the legs.
Frontal leg (first leg)
The upper part of the leg is connected to the Robot Body through a revoluteJoint with a pivot at the body. The upper leg has a motor and swings between an upper and lower limit
// Create upper leg
upperLeg = new Sprite(x, y, this.mLegTextureRegion, this.getVertexBufferObjectManager());
upperLegBody = PhysicsFactory.createBoxBody(this.mPhysicsWorld, upperLeg, BodyType.DynamicBody, LEG_FIXTURE_DEF);
this.mPhysicsWorld.registerPhysicsConnector(new PhysicsConnector(upperLeg, upperLegBody, true, true));
this.mScene.attachChild(upperLeg);
//Create an anchor/pivot at the body of the robot
Vector2 anchor1 = new Vector2(x/PIXEL_TO_METER_RATIO_DEFAULT,y/PIXEL_TO_METER_RATIO_DEFAULT);
//Attach upper leg to the body using a revolute joint with a motor
final RevoluteJointDef rJointDef = new RevoluteJointDef();
rJointDef.initialize(upperLegBody, robotBody, anchor1);
rJointDef.enableMotor = true;
rJointDef.enableLimit = true;
rJoint = (RevoluteJoint) this.mPhysicsWorld.createJoint(rJointDef);
rJoint.setMotorSpeed(4);
rJoint.setMaxMotorTorque(15);
//Set upper and lower limits for the swing of the leg
rJoint.setLimits((float)(0 * (Math.PI)/180), (float)(30 * (Math.PI)/180));
//Fire a periodic timer
new IntervalTimer(secs,rJoint);
The lower leg pivoted to the bottom of the upper leg through a revoluteJoint swings in the opposite direction of the upper leg between the reverse angle limts. By the way, I had tried every possible joint between the lower & the upper leg (distanceJoint, weldJoint,prismaticJoint) but the revoluteJoint is clearly the best.
// Create lower leg
lowerLeg= new Sprite(x, (y+50), this.mLegTextureRegion, this.getVertexBufferObjectManager());
lowerLegBody = PhysicsFactory.createBoxBody(this.mPhysicsWorld, lowerLeg, BodyType.DynamicBody, LEG_FIXTURE_DEF);
this.mPhysicsWorld.registerPhysicsConnector(new PhysicsConnector(lowerLeg, lowerLegBody, true, true));
this.mScene.attachChild(lowerLeg);
Vector2 anchor2 = new Vector2(x/PIXEL_TO_METER_RATIO_DEFAULT, (y+50)/PIXEL_TO_METER_RATIO_DEFAULT);
//Create a revoluteJoint between upper & lower leg
final RevoluteJointDef rJointDef1 = new RevoluteJointDef();
rJointDef1.initialize(lowerLegBody, upperLegBody, anchor2);
// The lower leg swings in opposite direction to upper leg
rJointDef1.enableMotor = true;
rJointDef1.enableLimit = true;
rJoint1 = (RevoluteJoint) this.mPhysicsWorld.createJoint(rJointDef1);
rJoint1.setMotorSpeed(-4);
rJoint.setMaxMotorTorque(15);
//Set upper and lower limits for the swing of the leg
// Set appropriate limits for lower leg
rJoint1.setLimits((float)(-30 * (Math.PI)/180), (float)(0 * (Math.PI)/180));
new IntervalTimer(secs,rJoint1);
Rear Leg (alternate leg)
Every alternate leg moves in the converse direction as the previous leg
//Create the alternative leg
publicvoid createAltLeg(float x, float y, int secs ){
// Create upper part of leg
upperLeg = new Sprite(x, y, this.mLegTextureRegion, this.getVertexBufferObjectManager());
upperLegBody = PhysicsFactory.createBoxBody(this.mPhysicsWorld, upperLeg, BodyType.DynamicBody, LEG_FIXTURE_DEF);
this.mPhysicsWorld.registerPhysicsConnector(new PhysicsConnector(upperLeg, upperLegBody, true, true));
this.mScene.attachChild(upperLeg);
//Create an anchor/pivot at the body of the robot
Vector2 anchor1 = new Vector2(x/PIXEL_TO_METER_RATIO_DEFAULT,y/PIXEL_TO_METER_RATIO_DEFAULT);
//Attach upper leg to the body using a revolute joint with a motor
final RevoluteJointDef rJointDef = new RevoluteJointDef();
rJointDef.initialize(upperLegBody, robotBody, anchor1);
rJointDef.enableMotor = true;
rJointDef.enableLimit = true;
rJoint = (RevoluteJoint) this.mPhysicsWorld.createJoint(rJointDef);
// This leg swings in the opposite direction of the previous leg
rJoint.setMotorSpeed(-4);
rJoint.setMaxMotorTorque(15);
//Set upper and lower limits for the swing of the leg
rJoint.setLimits((float)(0 * (Math.PI)/180), (float)(30 * (Math.PI)/180));
new IntervalTimer(secs,rJoint);
// Create lower leg
lowerLeg= new Sprite(x, (y+50), this.mLegTextureRegion, this.getVertexBufferObjectManager());
lowerLegBody = PhysicsFactory.createBoxBody(this.mPhysicsWorld, lowerLeg, BodyType.DynamicBody, LEG_FIXTURE_DEF);
this.mPhysicsWorld.registerPhysicsConnector(new PhysicsConnector(lowerLeg, lowerLegBody, true, true));
this.mScene.attachChild(lowerLeg);
Vector2 anchor2 = new Vector2(x/PIXEL_TO_METER_RATIO_DEFAULT, (y+50)/PIXEL_TO_METER_RATIO_DEFAULT);
//Create a revoluteJoint between upper & lower leg
final RevoluteJointDef rJointDef1 = new RevoluteJointDef();
rJointDef1.initialize(lowerLegBody, upperLegBody, anchor2);
rJointDef1.enableMotor = true;
rJointDef1.enableLimit = true;
rJoint1 = (RevoluteJoint) this.mPhysicsWorld.createJoint(rJointDef1);
//The lower part of the leg has the opposite swing to the upper part
rJoint1.setMotorSpeed(4);
rJoint.setMaxMotorTorque(15);
//Set appropriate upper and lower limits for the swing of the leg
rJoint1.setLimits((float)(-30 * (Math.PI)/180), (float)(0 * (Math.PI)/180));
// Fire a periodic timer
new IntervalTimer(secs,rJoint1);
I attached a horse’s head to the body using a WeldJoint
//Create the horse and attach the head using a Weld Joint
horse = new Sprite(140, 320, this.mHorseTextureRegion, this.getVertexBufferObjectManager());
horseBody = PhysicsFactory.createBoxBody(this.mPhysicsWorld, horse, BodyType.DynamicBody, HORSE_FIXTURE_DEF);
this.mPhysicsWorld.registerPhysicsConnector(new PhysicsConnector(horse, horseBody, true, true));
this.mScene.attachChild(horse);
Vector2 anchor = new Vector2(140/PIXEL_TO_METER_RATIO_DEFAULT, 320/PIXEL_TO_METER_RATIO_DEFAULT);
final WeldJointDef weldJointDef = new WeldJointDef();
weldJointDef.initialize(horseBody, robotBody, anchor);
this.mPhysicsWorld.createJoint(weldJointDef);
So now I had a horse that was ready to trot or canter around.
You can see the clip at Robot Horse on a canter using Android
The complete code can be cloned at GitHub RobotHorse
Some issues
Here are some issues with the above code
- The horse is quite unstable. If I move the phone vertically, the horse tends to tip backwards. The above clip was recorded with the phone lying on a table
- The motor speeds, torque and the masses of the different objects have to be adjusted very carefully. If the horse’s head or the body is too heavy the legs buckle under the weight
- Sometimes when I start the simulation the horse seems to bounce off the floor
I have carefully adjusted the mass, friction, motor speeds etc very carefully. Feel free to play around with them.
Comments & suggestions are welcome.
Find me on Google+