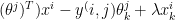In my last post ‘GooglyPlusPlus now with Win Probability Analysis for all T20 matches‘ I had discussed the performance of my ML models, created with and without player embeddings, in computing the Win Probability of T20 matches. With batsman & bowler embeddings I got much better performance than without the embeddings
glmnet – Accuracy – 0.73
Random Forest (RF) – Accuracy – 0.92
While the Random Forest gave excellent accuracy, it was bulky and also took an unusually long time to predict the Win Probability of a single T20 match. The above 2 ML models were built using R’s Tidymodels. glmnet was fast, but I wanted to see if I could create a ML model that was better, lighter and faster. I had initially tried to use Tensorflow, Keras in Python but then abandoned it, since I did not know how to port the Deep Learning model to R and use in my app GooglyPlusPlus.
But later, since I was stuck with a bulky Random Forest model, I decided to again explore options for saving the Keras Deep Learning model and loading it in R. I found out that saving the model as .h5, we can load it in R and use it for predictions. Hence, I rebuilt a Deep Learning model using Keras, Python with player embeddings and I got excellent performance. The DL model was light and had an accuracy 0.8639 with an ROC_AUC of 0.964 which was great!
GooglyPlusPlus uses data from Cricsheet and is based on my R package yorkr
You can try out this latest version of GooglyPlusPlus at gpp2023-1
Here are the steps
A. Build a Keras Deep Learning model
a. Import necessary packages
import pandas as pd
import numpy as np
from zipfile import ZipFile
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import regularizers
from pathlib import Path
import matplotlib.pyplot as plt
b, Upload the data of all 9 T20 leagues (BBL, CPL, IPL, T20 (men) , T20(women), NTB, CPL, SSM, WBB)
# Read all T20 leagues
df1=pd.read_csv('t20.csv')
print("Shape of dataframe=",df1.shape)
# Create training and test data set
train_dataset = df1.sample(frac=0.8,random_state=0)
test_dataset = df1.drop(train_dataset.index)
train_dataset1 = train_dataset[['batsmanIdx','bowlerIdx','ballNum','ballsRemaining','runs','runRate','numWickets','runsMomentum','perfIndex']]
test_dataset1 = test_dataset[['batsmanIdx','bowlerIdx','ballNum','ballsRemaining','runs','runRate','numWickets','runsMomentum','perfIndex']]
train_dataset1
# Set the target data
train_labels = train_dataset.pop('isWinner')
test_labels = test_dataset.pop('isWinner')
train_dataset1
a=train_dataset1.describe()
stats=a.transpose
a
c. Create a Deep Learning ML model using batsman & bowler embeddings
This was a huge success for me to be able to create the Deep Learning model in Python and use it in my Shiny app GooglyPlusPlus. The Deep Learning Keras model is light-weight and extremely fast.
The Deep Learning model has now been integrated into GooglyPlusPlus. Now you can check the Win Probability using both a) glmnet (Logistic Regression with lasso regularisation) b) Keras Deep Learning model with dropouts as regularisation
In addition I have created 2 features based on Win Probability (WP)
i) Win Probability (Side-by-side– Plot(interactive) : With this functionality the 1st and 2nd innings will be side-by-side. When the 1st innings is played by team 1, the Win Probability of team 2 = 100 – WP (team1). Similarly, when the 2nd innings is being played by team 2, the Win Probability of team1 = 100 – WP (team 2)
ii) Win Probability (Overlapping) – Plot (static): With this functionality the Win Probabilities of both team1(1st innings) & team 2 (2nd innings) are displayed overlapping, so that we can see how the probabilities vary ball-by-ball.
Note: Since the same UI is used for all match functions I had to re-use the Plot(interactive) and Plot(static) radio buttons for Win Probability (Side-by-side) and Win Probability(Overlapping) respectively
Here are screenshots using both ML models with both functionality for some random matches
B) ICC T20 Men World Cup – Netherland-South Africa- 2022-11-06
i) Match Worm wicket chart
ii) Win Probability with LR (Side-by-Side- Plot(interactive))
iii) Win Probability LR (Overlapping- Plot(static))
iv) Win Probability Deep Learning (Side-by-side – Plot(interactive)
In the 213th ball of the innings South Africa was slightly ahead of Netherlands. After that they crashed and burned!
v) Win Probability Deep Learning (Overlapping – Plot (static)
It can be seen that in the 94th ball of both innings South Africa was ahead of Netherlands before the eventual slump.
C) Intl. T20 (Women) India – New Zealand – 2020 – 02 – 27
Here is an interesting match between India and New Zealand T20 Women’s teams. NZ successfully chased the India’s total in a wildly swinging fortunes. See the charts below
i) Match Worm Wicket chart
ii) Win Probability with LR (Side-by-side – Plot (interactive)
iii) Win Probability with LR (Overlapping – Plot (static)
iv) Win Probability with DL model (Side-by-side – Plot (interactive))
v) Win Probability with DL model (Overlapping – Plot (static))
The above functionality in plotting the Win Probability using LR or DL with both options (Side-by-side or Overlapping) is available for all 9 T20 leagues currently supported by GooglyPlusPlus.
Often times before crucial matches, or in general, we would like to know the performance of a batsman against a bowler or vice-versa, but we may not have the data. We generally have data where different batsmen would have faced different sets of bowlers with certain performance data like ballsFaced, totalRuns, fours, sixes, strike rate and timesOut. Similarly different bowlers would have performance figures(deliveries, runsConceded, economyRate and wicketTaken) against different sets of batsmen. We will never have the data for all batsmen against all bowlers. However, it would be good estimate the performance of batsmen against a bowler, even though we do not have the performance data. This could be done using collaborative filtering which identifies and computes based on the similarity between batsmen vs bowlers & bowlers vs batsmen.
This post shows an approach whereby we can estimate a batsman’s performance against bowlers even though the batsman may not have faced those bowlers, based on his/her performance against other bowlers. It also estimates the performance of bowlers against batsmen using the same approach. This is based on the recommender algorithm which is used to recommend products to customers based on their rating on other products.
This idea came to me while generating the performance of batsmen vs bowlers & vice-versa for 2 IPL teams in this IPL 2022 with my Shiny app GooglyPlusPlus in the optimization tab, I found that there were some batsmen for which there was no data against certain bowlers, probably because they are playing for the first time in their team or because they were new (see picture below)
In the picture above there is no data for Dewald Brevis against Jasprit Bumrah and YS Chahal. Wouldn’t be great to estimate the performance of Brevis against Bumrah or vice-versa? Can we estimate this performance?
While pondering on this problem, I realized that this problem formulation is similar to the problem formulation for the famous Netflix movie recommendation problem, in which user’s ratings for certain movies are known and based on these ratings, the recommender engine can generate ratings for movies not yet seen.
This post estimates a player’s (batsman/bowler) using the recommender engine This post is based on R package recommenderlab
You can download this R Markdown file and the associated data and perform the analysis yourself using any other recommender engine from Github at playerPerformanceEstimation
Problem statement
In the table below we see a set of bowlers vs a set of batsmen and the number of times the bowlers got these batsmen out. By knowing the performance of the bowlers against some of the batsmen we can use collaborative filter to determine the missing values. This is done using the recommender engine.
The Recommender Engine works as follows. Let us say that there are feature vectors , and for the 3 bowlers which identify the characteristics of these bowlers (“fast”, “lateral drift through the air”, “movement off the pitch”). Let each batsman be identified by parameter vectors , and so on
For e.g. consider the following table
Then by assuming an initial estimate for the parameter vector and the feature vector xx we can formulate this as an optimization problem which tries to minimize the error for This can work very well as the algorithm can determine features which cannot be captured. So for e.g. some particular bowler may have very impressive figures. This could be due to some aspect of the bowling which cannot be captured by the data for e.g. let’s say the bowler uses the ‘scrambled seam’ when he is most effective, with a slightly different arc to the flight. Though the algorithm cannot identify the feature as we know it, but the ML algorithm should pick up intricacies which cannot be captured in data.
Hence the algorithm can be quite effective.
Note: The recommender lab performance is not very good and the Mean Square Error is quite high. Also, the ROC and AUC curves show that not in aLL cases the algorithm is doing a clean job of separating the True positives (TPR) from the False Positives (FPR)
Note: This is similar to the recommendation problem
The collaborative optimization object can be considered as a minimization of both and the features x and can be written as
J(, }= 1/2
The collaborative filtering algorithm can be summarized as follows
Initialize , … and the set of features be ,, … , to small random values
Minimize J(, … ,, , … ,) using gradient descent. For every j=1,2, …, i= 1,2,..,
:= – ( ) –
&
:= – (
Hence for a batsman with parameters and a bowler with (learned) features x, predict the “times out” for the player where the value is not known using
The above derivation for the recommender problem is taken from Machine Learning by Prof Andrew Ng at Coursera from the lecture Collaborative filtering
There are 2 main types of Collaborative Filtering(CF) approaches
User based Collaborative Filtering User-based CF is a memory-based algorithm which tries to mimics word-of-mouth by analyzing rating data from many individuals. The assumption is that users with similar preferences will rate items similarly.
Item based Collaborative Filtering Item-based CF is a model-based approach which produces recommendations based on the relationship between items inferred from the rating matrix. The assumption behind this approach is that users will prefer items that are similar to other items they like.
1a. A note on ROC and Precision-Recall curves
A small note on interpreting ROC & Precision-Recall curves in the post below
ROC Curve: The ROC curve plots the True Positive Rate (TPR) against the False Positive Rate (FPR). Ideally the TPR should increase faster than the FPR and the AUC (area under the curve) should be close to 1
Precision-Recall: The precision-recall curve shows the tradeoff between precision and recall for different threshold. A high area under the curve represents both high recall and high precision, where high precision relates to a low false positive rate, and high recall relates to a low false negative rate
Helper functions for the RMarkdown notebook are created
eval – Gives details of RMSE, MSE and MAE of ML algorithm
evalRecomMethods – Evaluates different recommender methods and plot the ROC and Precision-Recall curves
# This function returns the error for the chosen algorithm and also predicts the estimates
# for the given data
eval <- function(data, train1, k1,given1,goodRating1,recomType1="UBCF"){
set.seed(2022)
e<- evaluationScheme(data,
method = "split",
train = train1,
k = k1,
given = given1,
goodRating = goodRating1)
r1 <- Recommender(getData(e, "train"), recomType1)
print(r1)
p1 <- predict(r1, getData(e, "known"), type="ratings")
print(p1)
error = calcPredictionAccuracy(p1, getData(e, "unknown"))
print(error)
p2 <- predict(r1, data, type="ratingMatrix")
p2
}
# This function will evaluate the different recommender algorithms and plot the AUC and ROC curves
evalRecomMethods <- function(data,k1,given1,goodRating1){
set.seed(2022)
e<- evaluationScheme(data,
method = "cross",
k = k1,
given = given1,
goodRating = goodRating1)
models_to_evaluate <- list(
`IBCF Cosinus` = list(name = "IBCF",
param = list(method = "cosine")),
`IBCF Pearson` = list(name = "IBCF",
param = list(method = "pearson")),
`UBCF Cosinus` = list(name = "UBCF",
param = list(method = "cosine")),
`UBCF Pearson` = list(name = "UBCF",
param = list(method = "pearson")),
`Zufälliger Vorschlag` = list(name = "RANDOM", param=NULL)
)
n_recommendations <- c(1, 5, seq(10, 100, 10))
list_results <- evaluate(x = e,
method = models_to_evaluate,
n = n_recommendations)
plot(list_results, annotate=c(1,3), legend="bottomright")
plot(list_results, "prec/rec", annotate=3, legend="topleft")
}
3. Batsman performance estimation
The section below regenerates the performance for batsmen based on incomplete data for the different fields in the data frame namely balls faced, fours, sixes, strike rate, times out. The recommender lab allows one to test several different algorithms all at once namely
User based – Cosine similarity method, Pearson similarity
Item based – Cosine similarity method, Pearson similarity
Popular
Random
SVD and a few others
3a. Batting dataframe
head(df)
## batsman1 bowler1 ballsFaced totalRuns fours sixes SR timesOut
## 1 A Badoni A Mishra 0 0 0 0 NaN 0
## 2 A Badoni A Nortje 0 0 0 0 NaN 0
## 3 A Badoni A Zampa 0 0 0 0 NaN 0
## 4 A Badoni Abdul Samad 0 0 0 0 NaN 0
## 5 A Badoni Abhishek Sharma 0 0 0 0 NaN 0
## 6 A Badoni AD Russell 0 0 0 0 NaN 0
3b Data set and data preparation
For this analysis the data from Cricsheet has been processed using my R package yorkr to obtain the following 2 data sets – batsmenVsBowler – This dataset will contain the performance of the batsmen against the bowler and will capture a) ballsFaced b) totalRuns c) Fours d) Sixes e) SR f) timesOut – bowlerVsBatsmen – This data set will contain the performance of the bowler against the difference batsmen and will include a) deliveries b) runsConceded c) EconomyRate d) wicketsTaken
Obviously many rows/columns will be empty
This is a large data set and hence I have filtered for the period > Jan 2020 and < Dec 2022 which gives 2 datasets a) batsmanVsBowler20_22.rdata b) bowlerVsBatsman20_22.rdata
I also have 2 other datasets of all batsmen and bowlers in these 2 dataset in the files c) all-batsmen20_22.rds d) all-bowlers20_22.rds
## A Mishra A Nortje A Zampa Abdul Samad Abhishek Sharma
## A Badoni NA NA NA NA NA
## A Manohar NA NA NA NA NA
## A Nortje NA NA NA NA NA
## AB de Villiers NA 4 3 NA NA
## Abdul Samad NA NA NA NA NA
## Abhishek Sharma NA NA NA NA NA
## AD Russell 1 NA NA NA NA
## AF Milne NA NA NA NA NA
## AJ Finch NA NA NA NA 3
## AJ Tye NA NA NA NA NA
## AD Russell AF Milne AJ Tye AK Markram Akash Deep
## A Badoni NA NA NA NA NA
## A Manohar NA NA NA NA NA
## A Nortje NA NA NA NA NA
## AB de Villiers 3 NA 3 NA NA
## Abdul Samad NA NA NA NA NA
## Abhishek Sharma NA NA NA NA NA
## AD Russell NA NA 6 NA NA
## AF Milne NA NA NA NA NA
## AJ Finch NA NA NA NA NA
## AJ Tye NA NA NA NA NA
The dots below represent data for which there is no performance data. These cells need to be estimated by the algorithm
set.seed(2022)
r <- as(df8,"realRatingMatrix")
getRatingMatrix(r)[1:15,1:15]
## 15 x 15 sparse Matrix of class "dgCMatrix"
## [[ suppressing 15 column names 'A Mishra', 'A Nortje', 'A Zampa' ... ]]
The data frame of the batsman vs bowlers from the period 2020 -2022 is read as a dataframe. To remove rows with very low number of ratings(timesOut, SR, Fours, Sixes etc), the rows are filtered so that there are at least more 10 values in the row. For the player estimation the dataframe is converted into a wide-format as a matrix (m x n) of batsman x bowler with each of the columns of the dataframe i.e. timesOut, SR, fours or sixes. These different matrices can be considered as a rating matrix for estimation.
A similar approach is taken for estimating bowler performance. Here a wide form matrix (m x n) of bowler x batsman is created for each of the columns of deliveries, runsConceded, ER, wicketsTaken
5. Batsman’s times Out
The code below estimates the number of times the batsmen would lose his/her wicket to the bowler. As discussed in the algorithm above, the recommendation engine will make an initial estimate features for the bowler and an initial estimate for the parameter vector for the batsmen. Then using gradient descent the recommender engine will determine the feature and parameter values such that the over Mean Squared Error is minimum
From the plot for the different algorithms it can be seen that UBCF performs the best. However the AUC & ROC curves are not optimal and the AUC> 0.5
df3 <- select(df, batsman1,bowler1,timesOut)
df6 <- xtabs(timesOut ~ ., df3)
df7 <- as.data.frame.matrix(df6)
df8 <- data.matrix(df7)
df8[df8 == 0] <- NA
r <- as(df8,"realRatingMatrix")
# Filter only rows where the row count is > 10
r0=r[(rowCounts(r) > 10),]
getRatingMatrix(r0)[1:10,1:10]
## 10 x 10 sparse Matrix of class "dgCMatrix"
## [[ suppressing 10 column names 'A Mishra', 'A Nortje', 'A Zampa' ... ]]
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.000 3.000 3.000 3.463 4.000 21.000
# Evaluate the different plotting methods
evalRecomMethods(r0[1:dim(r0)[1]],k1=5,given=7,goodRating1=median(getRatings(r0)))
#Evaluate the error
a=eval(r0[1:dim(r0)[1]],0.8,k1=5,given1=7,goodRating1=median(getRatings(r0)),"UBCF")
## Recommender of type 'UBCF' for 'realRatingMatrix'
## learned using 70 users.
## 18 x 145 rating matrix of class 'realRatingMatrix' with 1755 ratings.
## RMSE MSE MAE
## 2.069027 4.280872 1.496388
b=round(as(a,"matrix")[1:10,1:10])
c <- as(b,"realRatingMatrix")
m=as(c,"data.frame")
names(m) =c("batsman","bowler","TimesOut")
6. Batsman’s Strike rate
This section deals with the Strike rate of batsmen versus bowlers and estimates the values for those where the data is incomplete using UBCF method.
Even here all the algorithms do not perform too efficiently. I did try out a few variations but could not lower the error (suggestions welcome!!)
## Recommender of type 'UBCF' for 'realRatingMatrix'
## learned using 105 users.
## 27 x 145 rating matrix of class 'realRatingMatrix' with 3220 ratings.
## RMSE MSE MAE
## 77.71979 6040.36508 58.58484
b=round(as(a,"matrix")[1:10,1:10])
c <- as(b,"realRatingMatrix")
n=as(c,"data.frame")
names(n) =c("batsman","bowler","SR")
7. Batsman’s Sixes
The snippet of code estimes the sixes of the batsman against bowlers. The ROC and AUC curve for UBCF looks a lot better here, as it significantly greater than 0.5
## Recommender of type 'UBCF' for 'realRatingMatrix'
## learned using 52 users.
## 14 x 145 rating matrix of class 'realRatingMatrix' with 1634 ratings.
## RMSE MSE MAE
## 3.529922 12.460350 2.532122
b=round(as(a,"matrix")[1:10,1:10])
c <- as(b,"realRatingMatrix")
o=as(c,"data.frame")
names(o) =c("batsman","bowler","Sixes")
## Recommender of type 'UBCF' for 'realRatingMatrix'
## learned using 67 users.
## 17 x 145 rating matrix of class 'realRatingMatrix' with 2083 ratings.
## RMSE MSE MAE
## 5.486661 30.103447 4.060990
b=round(as(a,"matrix")[1:10,1:10])
c <- as(b,"realRatingMatrix")
p=as(c,"data.frame")
names(p) =c("batsman","bowler","Fours")
9. Batsman’s Total Runs
The code below estimates the total runs that would have scored by the batsman against different bowlers
## Recommender of type 'UBCF' for 'realRatingMatrix'
## learned using 105 users.
## 27 x 145 rating matrix of class 'realRatingMatrix' with 3256 ratings.
## RMSE MSE MAE
## 41.50985 1723.06788 29.52958
b=round(as(a,"matrix")[1:10,1:10])
c <- as(b,"realRatingMatrix")
q=as(c,"data.frame")
names(q) =c("batsman","bowler","TotalRuns")
10. Batsman’s Balls Faced
The snippet estimates the balls faced by batsmen versus bowlers
## Recommender of type 'UBCF' for 'realRatingMatrix'
## learned using 112 users.
## 28 x 145 rating matrix of class 'realRatingMatrix' with 3378 ratings.
## RMSE MSE MAE
## 33.91251 1150.05835 23.39439
b=round(as(a,"matrix")[1:10,1:10])
c <- as(b,"realRatingMatrix")
r=as(c,"data.frame")
names(r) =c("batsman","bowler","BallsFaced")
11. Generate the Batsmen Performance Estimate
This code generates the estimated dataframe with known and ‘predicted’ values
## batsman bowler BallsFaced TotalRuns Fours Sixes SR TimesOut
## 1 AB de Villiers A Mishra 94 124 7 5 144 5
## 2 AB de Villiers A Nortje 26 42 4 3 148 3
## 3 AB de Villiers A Zampa 28 42 5 7 106 4
## 4 AB de Villiers Abhishek Sharma 22 28 0 10 136 5
## 5 AB de Villiers AD Russell 70 135 14 12 207 4
## 6 AB de Villiers AF Milne 31 45 6 6 130 3
12. Bowler analysis
Just like the batsman performance estimation we can consider the bowler’s performances also for estimation. Consider the following table
As in the batsman analysis, for every batsman a set of features like (“strong backfoot player”, “360 degree player”,“Power hitter”) can be estimated with a set of initial values. Also every bowler will have an associated parameter vector θθ. Different bowlers will have performance data for different set of batsmen. Based on the initial estimate of the features and the parameters, gradient descent can be used to minimize actual values {for e.g. wicketsTaken(ratings)}.
load("recom_data/bowlerVsBatsman20_22.rdata")
12a. Bowler dataframe
Inspecting the bowler dataframe
head(df2)
## bowler1 batsman1 balls runsConceded ER wicketTaken
## 1 A Mishra A Badoni 0 0 0.000000 0
## 2 A Mishra A Manohar 0 0 0.000000 0
## 3 A Mishra A Nortje 0 0 0.000000 0
## 4 A Mishra AB de Villiers 63 61 5.809524 0
## 5 A Mishra Abdul Samad 0 0 0.000000 0
## 6 A Mishra Abhishek Sharma 2 3 9.000000 0
## Recommender of type 'UBCF' for 'realRatingMatrix'
## learned using 96 users.
## 24 x 195 rating matrix of class 'realRatingMatrix' with 3954 ratings.
## RMSE MSE MAE
## 30.72284 943.89294 19.89204
b=round(as(a,"matrix")[1:10,1:10])
c <- as(b,"realRatingMatrix")
s=as(c,"data.frame")
names(s) =c("bowler","batsman","BallsBowled")
14. Runs conceded by bowler
This section estimates the runs conceded by the bowler. The UBCF Cosinus algorithm performs the best with TPR increasing fastewr than FPR
## Recommender of type 'UBCF' for 'realRatingMatrix'
## learned using 95 users.
## 24 x 195 rating matrix of class 'realRatingMatrix' with 3820 ratings.
## RMSE MSE MAE
## 43.16674 1863.36749 30.32709
b=round(as(a,"matrix")[1:10,1:10])
c <- as(b,"realRatingMatrix")
t=as(c,"data.frame")
names(t) =c("bowler","batsman","RunsConceded")
15. Economy Rate of the bowler
This section computes the economy rate of the bowler. The performance is not all that good
## Recommender of type 'UBCF' for 'realRatingMatrix'
## learned using 95 users.
## 24 x 195 rating matrix of class 'realRatingMatrix' with 3839 ratings.
## RMSE MSE MAE
## 4.380680 19.190356 3.316556
b=round(as(a,"matrix")[1:10,1:10])
c <- as(b,"realRatingMatrix")
u=as(c,"data.frame")
names(u) =c("bowler","batsman","EconomyRate")
16. Wickets Taken by bowler
The code below computes the wickets taken by the bowler versus different batsmen
## Recommender of type 'UBCF' for 'realRatingMatrix'
## learned using 64 users.
## 16 x 195 rating matrix of class 'realRatingMatrix' with 1908 ratings.
## RMSE MSE MAE
## 2.672677 7.143203 1.956934
b=round(as(a,"matrix")[1:10,1:10])
c <- as(b,"realRatingMatrix")
v=as(c,"data.frame")
names(v) =c("bowler","batsman","WicketTaken")
17. Generate the Bowler Performance estmiate
The entire dataframe is regenerated with known and ‘predicted’ values
## bowler batsman BallsBowled RunsConceded EconomyRate WicketTaken
## 1 A Mishra AB de Villiers 102 144 8 4
## 2 A Mishra Abdul Samad 13 20 7 4
## 3 A Mishra Abhishek Sharma 14 26 8 2
## 4 A Mishra AD Russell 47 85 9 3
## 5 A Mishra AJ Finch 45 61 11 4
## 6 A Mishra AJ Tye 14 20 5 4
18. Conclusion
This post showed an approach for performing the Batsmen Performance Estimate & Bowler Performance Estimate. The performance of the recommender engine could have been better. In any case, I think this approach will work for player estimation provided the recommender algorithm is able to achieve a high degree of accuracy. This will be a good way to estimate as the algorithm will be able to determine features and nuances of batsmen and bowlers which cannot be captured by data.
My book ‘Practical Machine Learning with R and Python: Second Edition – Machine Learning in stereo’ is now available in both paperback ($10.99) and kindle ($7.99/Rs449) versions. In this book I implement some of the most common, but important Machine Learning algorithms in R and equivalent Python code. This is almost like listening to parallel channels of music in stereo!
1. Practical machine with R and Python: Third Edition – Machine Learning in Stereo(Paperback-$12.99)
2. Practical machine with R and Python Third Edition – Machine Learning in Stereo(Kindle- $8.99/Rs449)
This book is ideal both for beginners and the experts in R and/or Python. Those starting their journey into datascience and ML will find the first 3 chapters useful, as they touch upon the most important programming constructs in R and Python and also deal with equivalent statements in R and Python. Those who are expert in either of the languages, R or Python, will find the equivalent code ideal for brushing up on the other language. And finally,those who are proficient in both languages, can use the R and Python implementations to internalize the ML algorithms better.
Here is a look at the topics covered
Table of Contents
Essential R …………………………………….. 7
Essential Python for Datascience ……………….. 54
R vs Python ……………………………………. 77
Regression of a continuous variable ………………. 96
Classification and Cross Validation ……………….113
Regression techniques and regularization …………. 134
SVMs, Decision Trees and Validation curves …………175
Splines, GAMs, Random Forests and Boosting …………202
PCA, K-Means and Hierarchical Clustering …………. 234
Pick up your copy today!!
Hope you have a great time learning as I did while implementing these algorithms!
This is the 4th installment of my ‘Practical Machine Learning with R and Python’ series. In this part I discuss classification with Support Vector Machines (SVMs), using both a Linear and a Radial basis kernel, and Decision Trees. Further, a closer look is taken at some of the metrics associated with binary classification, namely accuracy vs precision and recall. I also touch upon Validation curves, Precision-Recall, ROC curves and AUC with equivalent code in R and Python
Check out my compact and minimal book “Practical Machine Learning with R and Python:Third edition- Machine Learning in stereo” available in Amazon in paperback($12.99) and kindle($8.99) versions. My book includes implementations of key ML algorithms and associated measures and metrics. The book is ideal for anybody who is familiar with the concepts and would like a quick reference to the different ML algorithms that can be applied to problems and how to select the best model. Pick your copy today!!
Support Vector Machines (SVM) are another useful Machine Learning model that can be used for both regression and classification problems. SVMs used in classification, compute the hyperplane, that separates the 2 classes with the maximum margin. To do this the features may be transformed into a larger multi-dimensional feature space. SVMs can be used with different kernels namely linear, polynomial or radial basis to determine the best fitting model for a given classification problem.
In the 2nd part of this series Practical Machine Learning with R and Python – Part 2, I had mentioned the various metrics that are used in classification ML problems namely Accuracy, Precision, Recall and F1 score. Accuracy gives the fraction of data that were correctly classified as belonging to the +ve or -ve class. However ‘accuracy’ in itself is not a good enough measure because it does not take into account the fraction of the data that were incorrectly classified. This issue becomes even more critical in different domains. For e.g a surgeon who would like to detect cancer, would like to err on the side of caution, and classify even a possibly non-cancerous patient as possibly having cancer, rather than mis-classifying a malignancy as benign. Here we would like to increase recall or sensitivity which is given by Recall= TP/(TP+FN) or we try reduce mis-classification by either increasing the (true positives) TP or reducing (false negatives) FN
On the other hand, search algorithms would like to increase precision which tries to reduce the number of irrelevant results in the search result. Precision= TP/(TP+FP). In other words we do not want ‘false positives’ or irrelevant results to come in the search results and there is a need to reduce the false positives.
When we try to increase ‘precision’, we do so at the cost of ‘recall’, and vice-versa. I found this diagram and explanation in Wikipedia very useful Source: Wikipedia
“Consider a brain surgeon tasked with removing a cancerous tumor from a patient’s brain. The surgeon needs to remove all of the tumor cells since any remaining cancer cells will regenerate the tumor. Conversely, the surgeon must not remove healthy brain cells since that would leave the patient with impaired brain function. The surgeon may be more liberal in the area of the brain she removes to ensure she has extracted all the cancer cells. This decision increases recall but reduces precision. On the other hand, the surgeon may be more conservative in the brain she removes to ensure she extracts only cancer cells. This decision increases precision but reduces recall. That is to say, greater recall increases the chances of removing healthy cells (negative outcome) and increases the chances of removing all cancer cells (positive outcome). Greater precision decreases the chances of removing healthy cells (positive outcome) but also decreases the chances of removing all cancer cells (negative outcome).”
# Read data. Data from SKLearncancer<-read.csv("cancer.csv")cancer$target<-as.factor(cancer$target)# Split into training and test setstrain_idx<-trainTestSplit(cancer,trainPercent=75,seed=5)train<-cancer[train_idx, ]test<-cancer[-train_idx, ]# Fit a linear basis kernel. DO not scale the datasvmfit=svm(target~., data=train, kernel="linear",scale=FALSE)ypred=predict(svmfit,test)#Print a confusion matrixconfusionMatrix(ypred,test$target)
The code below creates a SVM with linear basis in Python and also dumps the corresponding classification metrics
import numpy as np
import pandas as pd
import os
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.svm import LinearSVC
from sklearn.datasets import make_classification, make_blobs
from sklearn.metrics import confusion_matrix
from matplotlib.colors import ListedColormap
from sklearn.datasets import load_breast_cancer
# Load the cancer data
(X_cancer, y_cancer) = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = train_test_split(X_cancer, y_cancer,
random_state = 0)
clf = LinearSVC().fit(X_train, y_train)
print('Breast cancer dataset')
print('Accuracy of Linear SVC classifier on training set: {:.2f}'
.format(clf.score(X_train, y_train)))
print('Accuracy of Linear SVC classifier on test set: {:.2f}'
.format(clf.score(X_test, y_test)))
## Breast cancer dataset
## Accuracy of Linear SVC classifier on training set: 0.92
## Accuracy of Linear SVC classifier on test set: 0.94
1.2 Dummy classifier
Often when we perform classification tasks using any ML model namely logistic regression, SVM, neural networks etc. it is very useful to determine how well the ML model performs agains at dummy classifier. A dummy classifier uses some simple computation like frequency of majority class, instead of fitting and ML model. It is essential that our ML model does much better that the dummy classifier. This problem is even more important in imbalanced classes where we have only about 10% of +ve samples. If any ML model we create has a accuracy of about 0.90 then it is evident that our classifier is not doing any better than a dummy classsfier which can just take a majority count of this imbalanced class and also come up with 0.90. We need to be able to do better than that.
In the examples below (1.3a & 1.3b) it can be seen that SVMs with ‘radial basis’ kernel with unnormalized data, for both R and Python, do not perform any better than the dummy classifier.
1.2a Dummy classifier – R code
R does not seem to have an explicit dummy classifier. I created a simple dummy classifier that predicts the majority class. SKlearn in Python also includes other strategies like uniform, stratified etc. but this should be possible to create in R also.
# Create a simple dummy classifier that computes the ratio of the majority class to the totlaDummyClassifierAccuracy<-function(train,test,type="majority"){if(type=="majority"){count<-sum(train$target==1)/dim(train)[1]}count}cancer<-read.csv("cancer.csv")cancer$target<-as.factor(cancer$target)# Create training and test setstrain_idx<-trainTestSplit(cancer,trainPercent=75,seed=5)train<-cancer[train_idx, ]test<-cancer[-train_idx, ]#Dummy classifier majority classacc=DummyClassifierAccuracy(train,test)sprintf("Accuracy is %f",acc)
## [1] "Accuracy is 0.638498"
1.2b Dummy classifier – Python code
This dummy classifier uses the majority class.
import numpy as np
import pandas as pd
import os
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.dummy import DummyClassifier
from sklearn.metrics import confusion_matrix
(X_cancer, y_cancer) = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = train_test_split(X_cancer, y_cancer,
random_state = 0)
# Negative class (0) is most frequent
dummy_majority = DummyClassifier(strategy = 'most_frequent').fit(X_train, y_train)
y_dummy_predictions = dummy_majority.predict(X_test)
print('Dummy classifier accuracy on test set: {:.2f}'
.format(dummy_majority.score(X_test, y_test)))
## Dummy classifier accuracy on test set: 0.63
1.3a – Radial SVM (un-normalized) – R code
SVMs perform better when the data is normalized or scaled. The 2 examples below show that SVM with radial basis kernel does not perform any better than the dummy classifier
## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 0 0
## 1 57 85
##
## Accuracy : 0.5986
## 95% CI : (0.5131, 0.6799)
## No Information Rate : 0.5986
## P-Value [Acc > NIR] : 0.5363
##
## Kappa : 0
## Mcnemar's Test P-Value : 1.195e-13
##
## Sensitivity : 0.0000
## Specificity : 1.0000
## Pos Pred Value : NaN
## Neg Pred Value : 0.5986
## Prevalence : 0.4014
## Detection Rate : 0.0000
## Detection Prevalence : 0.0000
## Balanced Accuracy : 0.5000
##
## 'Positive' Class : 0
##
1.4b – Radial SVM (un-normalized) – Python code
import numpy as np
import pandas as pd
import os
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
# Load the cancer data
(X_cancer, y_cancer) = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = train_test_split(X_cancer, y_cancer,
random_state = 0)
clf = SVC(C=10).fit(X_train, y_train)
print('Breast cancer dataset (unnormalized features)')
print('Accuracy of RBF-kernel SVC on training set: {:.2f}'
.format(clf.score(X_train, y_train)))
print('Accuracy of RBF-kernel SVC on test set: {:.2f}'
.format(clf.score(X_test, y_test)))
## Breast cancer dataset (unnormalized features)
## Accuracy of RBF-kernel SVC on training set: 1.00
## Accuracy of RBF-kernel SVC on test set: 0.63
1.5a – Radial SVM (Normalized) -R Code
The data is scaled (normalized ) before using the SVM model. The SVM model has 2 paramaters a) C – Large C (less regularization), more regularization b) gamma – Small gamma has larger decision boundary with more misclassfication, and larger gamma has tighter decision boundary
The R code below computes the accuracy as the regularization paramater is changed
a<-rbind(C1,as.numeric(trainingAccuracy),as.numeric(testAccuracy))b<-data.frame(t(a))names(b)<-c("C1","trainingAccuracy","testAccuracy")df<-melt(b,id="C1")ggplot(df)+geom_line(aes(x=C1, y=value, colour=variable),size=2)+xlab("C (SVC regularization)value")+ylab("Accuracy")+ggtitle("Training and test accuracy vs C(regularization)")
1.5b – Radial SVM (normalized) – Python
The Radial basis kernel is used on normalized data for a range of ‘C’ values and the result is plotted.
import numpy as np
import pandas as pd
import os
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
# Load the cancer data
(X_cancer, y_cancer) = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = train_test_split(X_cancer, y_cancer,
random_state = 0)
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
print('Breast cancer dataset (normalized with MinMax scaling)')
trainingAccuracy=[]
testAccuracy=[]
for C1 in [.01,.1, 1, 10, 20]:
clf = SVC(C=C1).fit(X_train_scaled, y_train)
acctrain=clf.score(X_train_scaled, y_train)
accTest=clf.score(X_test_scaled, y_test)
trainingAccuracy.append(acctrain)
testAccuracy.append(accTest)
# Create a dataframe
C1=[.01,.1, 1, 10, 20]
trainingAccuracy=pd.DataFrame(trainingAccuracy,index=C1)
testAccuracy=pd.DataFrame(testAccuracy,index=C1)
# Plot training and test R squared as a function of alpha
df=pd.concat([trainingAccuracy,testAccuracy],axis=1)
df.columns=['trainingAccuracy','trainingAccuracy']
fig1=df.plot()
fig1=plt.title('Training and test accuracy vs C (SVC)')
fig1.figure.savefig('fig1.png', bbox_inches='tight')
## Breast cancer dataset (normalized with MinMax scaling)
Output image:
1.6a Validation curve – R code
Sklearn includes code creating validation curves by varying paramaters and computing and plotting accuracy as gamma or C or changd. I did not find this R but I think this is a useful function and so I have created the R equivalent of this.
# The R equivalent of np.logspaceseqLogSpace<-function(start,stop,len){a=seq(log10(10^start),log10(10^stop),length=len)10^a}# Read the data. This is taken the SKlearn cancer datacancer<-read.csv("cancer.csv")cancer$target<-as.factor(cancer$target)set.seed(6)# Create the range of C1 in log spaceparam_range=seqLogSpace(-3,2,20)# Initialize the overall training and test accuracy to NULLoverallTrainAccuracy<-NULLoverallTestAccuracy<-NULL# Loop over the parameter range of Gammafor(iinparam_range){# Set no of foldsnoFolds=5# Create the rows which fall into different folds from 1..noFoldsfolds=sample(1:noFolds, nrow(cancer), replace=TRUE)# Initialize the training and test accuracy of folds to 0trainingAccuracy<-0testAccuracy<-0# Loop through the foldsfor(jin1:noFolds){# The training is all rows for which the row is != j (k-1 folds -> training)train<-cancer[folds!=j,]# The rows which have j as the index become the test settest<-cancer[folds==j,]# Create a SVM model for thissvmfit=svm(target~., data=train, kernel="radial",gamma=i,scale=TRUE)# Add up all the fold accuracy for training and test separately ypredTrain<-predict(svmfit,train)ypredTest=predict(svmfit,test)# Create confusion matrix a<-confusionMatrix(ypredTrain,train$target)b<-confusionMatrix(ypredTest,test$target)# Get the accuracytrainingAccuracy<-trainingAccuracy+a$overall[1]testAccuracy<-testAccuracy+b$overall[1]}# Compute the average of accuracy for K folds for number of features 'i'overallTrainAccuracy=c(overallTrainAccuracy,trainingAccuracy/noFolds)overallTestAccuracy=c(overallTestAccuracy,testAccuracy/noFolds)}#Create a dataframea<-rbind(param_range,as.numeric(overallTrainAccuracy),
as.numeric(overallTestAccuracy))b<-data.frame(t(a))names(b)<-c("C1","trainingAccuracy","testAccuracy")df<-melt(b,id="C1")#Plot in log axisggplot(df)+geom_line(aes(x=C1, y=value, colour=variable),size=2)+xlab("C (SVC regularization)value")+ylab("Accuracy")+ggtitle("Training and test accuracy vs C(regularization)")+scale_x_log10()
1.6b Validation curve – Python
Compute and plot the validation curve as gamma is varied.
import numpy as np
import pandas as pd
import os
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.svm import SVC
from sklearn.model_selection import validation_curve
# Load the cancer data
(X_cancer, y_cancer) = load_breast_cancer(return_X_y = True)
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X_cancer)
# Create a gamma values from 10^-3 to 10^2 with 20 equally spaced intervals
param_range = np.logspace(-3, 2, 20)
# Compute the validation curve
train_scores, test_scores = validation_curve(SVC(), X_scaled, y_cancer,
param_name='gamma',
param_range=param_range, cv=10)
#Plot the figure
fig2=plt.figure()
#Compute the mean
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
fig2=plt.title('Validation Curve with SVM')
fig2=plt.xlabel('$\gamma$ (gamma)')
fig2=plt.ylabel('Score')
fig2=plt.ylim(0.0, 1.1)
lw = 2
fig2=plt.semilogx(param_range, train_scores_mean, label='Training score',
color='darkorange', lw=lw)
fig2=plt.fill_between(param_range, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.2,
color='darkorange', lw=lw)
fig2=plt.semilogx(param_range, test_scores_mean, label='Cross-validation score',
color='navy', lw=lw)
fig2=plt.fill_between(param_range, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.2,
color='navy', lw=lw)
fig2.figure.savefig('fig2.png', bbox_inches='tight')
Output image:
1.7a Validation Curve (Preventing data leakage) – Python code
In this course Applied Machine Learning in Python, the Professor states that when we apply the same data transformation to a entire dataset, it will cause a data leakage. “The proper way to do cross-validation when you need to scale the data is not to scale the entire dataset with a single transform, since this will indirectly leak information into the training data about the whole dataset, including the test data (see the lecture on data leakage later in the course). Instead, scaling/normalizing must be computed and applied for each cross-validation fold separately”
So I apply separate scaling to the training and testing folds and plot. In the lecture the Prof states that this can be done using pipelines.
import numpy as np
import pandas as pd
import os
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.cross_validation import KFold
from sklearn.preprocessing import MinMaxScaler
from sklearn.svm import SVC
# Read the data
(X_cancer, y_cancer) = load_breast_cancer(return_X_y = True)
# Set the parameter range
param_range = np.logspace(-3, 2, 20)
# Set number of folds
folds=5#Initialize
overallTrainAccuracy=[]
overallTestAccuracy=[]
# Loop over the paramater rangefor c in param_range:
trainingAccuracy=0
testAccuracy=0
kf = KFold(len(X_cancer),n_folds=folds)
# Partition into training and test foldsfor train_index, test_index in kf:
# Partition the data acccording the fold indices generated
X_train, X_test = X_cancer[train_index], X_cancer[test_index]
y_train, y_test = y_cancer[train_index], y_cancer[test_index]
# Scale the X_train and X_test
scaler = MinMaxScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Fit a SVC model for each C
clf = SVC(C=c).fit(X_train_scaled, y_train)
#Compute the training and test score
acctrain=clf.score(X_train_scaled, y_train)
accTest=clf.score(X_test_scaled, y_test)
trainingAccuracy += np.sum(acctrain)
testAccuracy += np.sum(accTest)
# Compute the mean training and testing accuracy
overallTrainAccuracy.append(trainingAccuracy/folds)
overallTestAccuracy.append(testAccuracy/folds)
overallTrainAccuracy=pd.DataFrame(overallTrainAccuracy,index=param_range)
overallTestAccuracy=pd.DataFrame(overallTestAccuracy,index=param_range)
# Plot training and test R squared as a function of alpha
df=pd.concat([overallTrainAccuracy,overallTestAccuracy],axis=1)
df.columns=['trainingAccuracy','testAccuracy']
fig3=plt.title('Validation Curve with SVM')
fig3=plt.xlabel('$\gamma$ (gamma)')
fig3=plt.ylabel('Score')
fig3=plt.ylim(0.5, 1.1)
lw = 2
fig3=plt.semilogx(param_range, overallTrainAccuracy, label='Training score',
color='darkorange', lw=lw)
fig3=plt.semilogx(param_range, overallTestAccuracy, label='Cross-validation score',
color='navy', lw=lw)
fig3=plt.legend(loc='best')
fig3.figure.savefig('fig3.png', bbox_inches='tight')
Output image:
1.8 a Decision trees – R code
Decision trees in R can be plotted using RPart package
library(rpart)library(rpart.plot)
rpart=NULL# Create a decision treem<-rpart(Species~.,data=iris)#Plotrpart.plot(m,extra=2,main="Decision Tree - IRIS")
1.8 b Decision trees – Python code
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
from sklearn.model_selection import train_test_split
import graphviz
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state = 3)
clf = DecisionTreeClassifier().fit(X_train, y_train)
print('Accuracy of Decision Tree classifier on training set: {:.2f}'
.format(clf.score(X_train, y_train)))
print('Accuracy of Decision Tree classifier on test set: {:.2f}'
.format(clf.score(X_test, y_test)))
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
graph
## Accuracy of Decision Tree classifier on training set: 1.00
## Accuracy of Decision Tree classifier on test set: 0.97
1.9a Feature importance – R code
I found the following code which had a snippet for feature importance. Sklean has a nice method for this. For some reason the results in R and Python are different. Any thoughts?
set.seed(3)# load the librarylibrary(mlbench)
library(caret)# load the datasetcancer<-read.csv("cancer.csv")cancer$target<-as.factor(cancer$target)# Split as datadata<-cancer[,1:31]target<-cancer[,32]# Train the modelmodel<-train(data, target, method="rf", preProcess="scale", trControl=trainControl(method="cv"))
import numpy as np
import pandas as pd
import os
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
import numpy as np
# Read the data
cancer= load_breast_cancer()
(X_cancer, y_cancer) = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = train_test_split(X_cancer, y_cancer, random_state = 0)
# Use the DecisionTreClassifier
clf = DecisionTreeClassifier(max_depth = 4, min_samples_leaf = 8,
random_state = 0).fit(X_train, y_train)
c_features=len(cancer.feature_names)
print('Breast cancer dataset: decision tree')
print('Accuracy of DT classifier on training set: {:.2f}'
.format(clf.score(X_train, y_train)))
print('Accuracy of DT classifier on test set: {:.2f}'
.format(clf.score(X_test, y_test)))
# Plot the feature importances
fig4=plt.figure(figsize=(10,6),dpi=80)
fig4=plt.barh(range(c_features), clf.feature_importances_)
fig4=plt.xlabel("Feature importance")
fig4=plt.ylabel("Feature name")
fig4=plt.yticks(np.arange(c_features), cancer.feature_names)
fig4=plt.tight_layout()
plt.savefig('fig4.png', bbox_inches='tight')
## Breast cancer dataset: decision tree
## Accuracy of DT classifier on training set: 0.96
## Accuracy of DT classifier on test set: 0.94
Output image:
1.10a Precision-Recall, ROC curves & AUC- R code
I tried several R packages for plotting the Precision and Recall and AUC curve. PRROC seems to work well. The Precision-Recall curves show the tradeoff between precision and recall. The higher the precision, the lower the recall and vice versa.AUC curves that hug the top left corner indicate a high sensitivity,specificity and an excellent accuracy.
# Read the data (this data is from sklearn!)d<-read.csv("digits.csv")digits<-d[2:66]digits$X64<-as.factor(digits$X64)# Split as training and test setstrain_idx<-trainTestSplit(digits,trainPercent=75,seed=5)train<-digits[train_idx, ]test<-digits[-train_idx, ]# Fit a SVM model with linear basis kernel with probabilitiessvmfit=svm(X64~., data=train, kernel="linear",scale=FALSE,probability=TRUE)ypred=predict(svmfit,test,probability=TRUE)head(attr(ypred,"probabilities"))
# Store the probability of 0s and 1sm0<-attr(ypred,"probabilities")[,1]m1<-attr(ypred,"probabilities")[,2]# Create a dataframe of scoresscores<-data.frame(m1,test$X64)# Class 0 is data points of +ve class (in this case, digit 1) and -ve class (digit 0)#Compute Precision Recallpr<-pr.curve(scores.class0=scores[scores$test.X64=="1",]$m1,
scores.class1=scores[scores$test.X64=="0",]$m1,
curve=T)# Plot precision-recall curveplot(pr)
#Plot the ROC curveroc<-roc.curve(m0, m1,curve=TRUE)plot(roc)
In the code below classification probabilities are used to compute and plot precision-recall, roc and AUC
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_digits
from sklearn.svm import LinearSVC
from sklearn.calibration import CalibratedClassifierCV
dataset = load_digits()
X, y = dataset.data, dataset.target
# Make a copy of the target
z= y.copy()
# Replace all non 1's as 0
z[z != 1] = 0
X_train, X_test, y_train, y_test = train_test_split(X, z, random_state=0)
svm = LinearSVC()
# Need to use CalibratedClassifierSVC to redict probabilities for lInearSVC
clf = CalibratedClassifierCV(svm)
clf.fit(X_train, y_train)
y_proba_lr = clf.predict_proba(X_test)
from sklearn.metrics import precision_recall_curve
precision, recall, thresholds = precision_recall_curve(y_test, y_proba_lr[:,1])
closest_zero = np.argmin(np.abs(thresholds))
closest_zero_p = precision[closest_zero]
closest_zero_r = recall[closest_zero]
#plt.figure(figsize=(15,15),dpi=80)
plt.figure()
plt.xlim([0.0, 1.01])
plt.ylim([0.0, 1.01])
plt.plot(precision, recall, label='Precision-Recall Curve')
plt.plot(closest_zero_p, closest_zero_r, 'o', markersize = 12, fillstyle = 'none', c='r', mew=3)
plt.xlabel('Precision', fontsize=16)
plt.ylabel('Recall', fontsize=16)
plt.axes().set_aspect('equal')
plt.savefig('fig7.png', bbox_inches='tight')
output
Note: As with other posts in this series on ‘Practical Machine Learning with R and Python’, this post is based on these 2 MOOC courses
1. Statistical Learning, Prof Trevor Hastie & Prof Robert Tibesherani, Online Stanford
2. Applied Machine Learning in Python Prof Kevyn-Collin Thomson, University Of Michigan, Coursera
Conclusion
This 4th part looked at SVMs with linear and radial basis, decision trees, precision-recall tradeoff, ROC curves and AUC.
Stick around for further updates. I’ll be back!
Comments, suggestions and correction are welcome.
















 ,
, 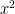 and
and  for the 3 bowlers which identify the characteristics of these bowlers (“fast”, “lateral drift through the air”, “movement off the pitch”). Let each batsman be identified by parameter vectors
for the 3 bowlers which identify the characteristics of these bowlers (“fast”, “lateral drift through the air”, “movement off the pitch”). Let each batsman be identified by parameter vectors  ,
,  and so on
and so on
 and the feature vector xx we can formulate this as an optimization problem which tries to minimize the error for
and the feature vector xx we can formulate this as an optimization problem which tries to minimize the error for  This can work very well as the algorithm can determine features which cannot be captured. So for e.g. some particular bowler may have very impressive figures. This could be due to some aspect of the bowling which cannot be captured by the data for e.g. let’s say the bowler uses the ‘scrambled seam’ when he is most effective, with a slightly different arc to the flight. Though the algorithm cannot identify the feature as we know it, but the ML algorithm should pick up intricacies which cannot be captured in data.
This can work very well as the algorithm can determine features which cannot be captured. So for e.g. some particular bowler may have very impressive figures. This could be due to some aspect of the bowling which cannot be captured by the data for e.g. let’s say the bowler uses the ‘scrambled seam’ when he is most effective, with a slightly different arc to the flight. Though the algorithm cannot identify the feature as we know it, but the ML algorithm should pick up intricacies which cannot be captured in data.
 ,
,  }= 1/2
}= 1/2
 and the set of features be
and the set of features be 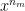 to small random values
to small random values , i= 1,2,..,
, i= 1,2,.., 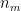
 :=
:=  (
( 
 )
)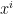 –
– 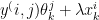
 :=
:=