No computer has ever been designed that is ever aware of what it’s doing; but most of the time, we aren’t either.” Marvin Minksy
“The competent programmer is fully aware of the limited size of his own skull. He therefore approaches his task with full humility, and avoids clever tricks like the plague” Edgser Djikstra
Introduction
In this post, cricpy, the Python avatar of my R package cricketr, learns some new tricks to be able to handle ODI matches. To know more about my R package cricketr see Re-introducing cricketr! : An R package to analyze performances of cricketers
Cricpy uses the statistics info available in ESPN Cricinfo Statsguru. The current version of this package supports only Test cricket
You should be able to install the package using pip install cricpy and use the many functions available in the package. Please mindful of the ESPN Cricinfo Terms of Use
Cricpy can now analyze performances of teams in Test, ODI and T20 cricket see Cricpy adds team analytics to its arsenal!!
This post is also hosted on Rpubs at Int
To know how to use cricpy see Introducing cricpy:A python package to analyze performances of cricketers. To the original version of cricpy, I have added 3 new functions for ODI. The earlier functions work for Test and ODI.
This post is also hosted on Rpubs at Cricpy takes a swing at the ODIs. You can also down the pdf version of this post at cricpy-odi.pdf
You can fork/clone the package at Github cricpy
Note: If you would like to do a similar analysis for a different set of batsman and bowlers, you can clone/download my skeleton cricpy-template from Github (which is the R Markdown file I have used for the analysis below). You will only need to make appropriate changes for the players you are interested in. The functions can be executed in RStudio or in a IPython notebook.
If you are passionate about cricket, and love analyzing cricket performances, then check out my racy book on cricket ‘Cricket analytics with cricketr and cricpy – Analytics harmony with R & Python’! This book discusses and shows how to use my R package ‘cricketr’ and my Python package ‘cricpy’ to analyze batsmen and bowlers in all formats of the game (Test, ODI and T20). The paperback is available on Amazon at $21.99 and the kindle version at $9.99/Rs 449/-. A must read for any cricket lover! Check it out!!
You can download the latest PDF version of the book at ‘Cricket analytics with cricketr and cricpy: Analytics harmony with R and Python-6th edition‘

The cricpy package
The data for a particular player in ODI can be obtained with the getPlayerDataOD() function. To do you will need to go to ESPN CricInfo Player and type in the name of the player for e.g Virat Kohli, Virendar Sehwag, Chris Gayle etc. This will bring up a page which have the profile number for the player e.g. for Virat Kohli this would be http://www.espncricinfo.com/india/content/player/253802.html. Hence, Kohli’s profile is 253802. This can be used to get the data for Virat Kohlis shown below
The cricpy package is a clone of my R package cricketr. The signature of all the python functions are identical with that of its clone ‘cricketr’, with only the necessary variations between Python and R. It may be useful to look at my post R vs Python: Different similarities and similar differences. In fact if you are familar with one of the lanuguages you can look up the package in the other and you will notice the parallel constructs.
You can fork/clone the package at Github cricpy
Note: The charts are self-explanatory and I have not added much of my owy interpretation to it. Do look at the plots closely and check out the performances for yourself.
1 Importing cricpy – Python
# Install the package
# Do a pip install cricpy
# Import cricpy
import cricpy.analytics as ca 2. Invoking functions with Python package crlcpy
import cricpy.analytics as ca
ca.batsman4s("./kohli.csv","Virat Kohli")
![]()

3. Getting help from cricpy – Python
import cricpy.analytics as ca
help(ca.getPlayerDataOD)## Help on function getPlayerDataOD in module cricpy.analytics:
##
## getPlayerDataOD(profile, opposition='', host='', dir='./data', file='player001.csv', type='batting', homeOrAway=[1, 2, 3], result=[1, 2, 3, 5], create=True)
## Get the One day player data from ESPN Cricinfo based on specific inputs and store in a file in a given directory
##
## Description
##
## Get the player data given the profile of the batsman. The allowed inputs are home,away or both and won,lost or draw of matches. The data is stored in a .csv file in a directory specified. This function also returns a data frame of the player
##
## Usage
##
## getPlayerDataOD(profile, opposition="",host="",dir = "../", file = "player001.csv",
## type = "batting", homeOrAway = c(1, 2, 3), result = c(1, 2, 3,5))
## Arguments
##
## profile
## This is the profile number of the player to get data. This can be obtained from http://www.espncricinfo.com/ci/content/player/index.html. Type the name of the player and click search. This will display the details of the player. Make a note of the profile ID. For e.g For Virender Sehwag this turns out to be http://www.espncricinfo.com/india/content/player/35263.html. Hence the profile for Sehwag is 35263
## opposition The numerical value of the opposition country e.g.Australia,India, England etc. The values are Australia:2,Bangladesh:25,Bermuda:12, England:1,Hong Kong:19,India:6,Ireland:29, Netherlands:15,New Zealand:5,Pakistan:7,Scotland:30,South Africa:3,Sri Lanka:8,United Arab Emirates:27, West Indies:4, Zimbabwe:9; Africa XI:405 Note: If no value is entered for opposition then all teams are considered
## host The numerical value of the host country e.g.Australia,India, England etc. The values are Australia:2,Bangladesh:25,England:1,India:6,Ireland:29,Malaysia:16,New Zealand:5,Pakistan:7, Scotland:30,South Africa:3,Sri Lanka:8,United Arab Emirates:27,West Indies:4, Zimbabwe:9 Note: If no value is entered for host then all host countries are considered
## dir
## Name of the directory to store the player data into. If not specified the data is stored in a default directory "../data". Default="../data"
## file
## Name of the file to store the data into for e.g. tendulkar.csv. This can be used for subsequent functions. Default="player001.csv"
## type
## type of data required. This can be "batting" or "bowling"
## homeOrAway
## This is vector with either or all 1,2, 3. 1 is for home 2 is for away, 3 is for neutral venue
## result
## This is a vector that can take values 1,2,3,5. 1 - won match 2- lost match 3-tied 5- no result
## Details
##
## More details can be found in my short video tutorial in Youtube https://www.youtube.com/watch?v=q9uMPFVsXsI
##
## Value
##
## Returns the player's dataframe
##
## Note
##
## Maintainer: Tinniam V Ganesh <tvganesh.85@gmail.com>
##
## Author(s)
##
## Tinniam V Ganesh
##
## References
##
## http://www.espncricinfo.com/ci/content/stats/index.html
## https://gigadom.in/
##
## See Also
##
## getPlayerDataSp getPlayerData
##
## Examples
##
##
## ## Not run:
## # Both home and away. Result = won,lost and drawn
## sehwag =getPlayerDataOD(35263,dir="../cricketr/data", file="sehwag1.csv",
## type="batting", homeOrAway=[1,2],result=[1,2,3,4])
##
## # Only away. Get data only for won and lost innings
## sehwag = getPlayerDataOD(35263,dir="../cricketr/data", file="sehwag2.csv",
## type="batting",homeOrAway=[2],result=[1,2])
##
## # Get bowling data and store in file for future
## malinga = getPlayerData(49758,dir="../cricketr/data",file="malinga1.csv",
## type="bowling")
##
## # Get Dhoni's ODI record in Australia against Australua
## dhoni = getPlayerDataOD(28081,opposition = 2,host=2,dir=".",
## file="dhoniVsAusinAusOD",type="batting")
##
## ## End(Not run)The details below will introduce the different functions that are available in cricpy.
4. Get the ODI player data for a player using the function getPlayerDataOD()
Important Note This needs to be done only once for a player. This function stores the player’s data in the specified CSV file (for e.g. kohli.csv as above) which can then be reused for all other functions). Once we have the data for the players many analyses can be done. This post will use the stored CSV file obtained with a prior getPlayerDataOD for all subsequent analyses
import cricpy.analytics as ca
#sehwag=ca.getPlayerDataOD(35263,dir=".",file="sehwag.csv",type="batting")
#kohli=ca.getPlayerDataOD(253802,dir=".",file="kohli.csv",type="batting")
#jayasuriya=ca.getPlayerDataOD(49209,dir=".",file="jayasuriya.csv",type="batting")
#gayle=ca.getPlayerDataOD(51880,dir=".",file="gayle.csv",type="batting")Included below are some of the functions that can be used for ODI batsmen and bowlers. For this I have chosen, Virat Kohli, ‘the run machine’ who is on-track for breaking many of the Test & ODI records
5 Virat Kohli’s performance – Basic Analyses
The 3 plots below provide the following for Virat Kohli
- Frequency percentage of runs in each run range over the whole career
- Mean Strike Rate for runs scored in the given range
- A histogram of runs frequency percentages in runs ranges
import cricpy.analytics as ca
import matplotlib.pyplot as plt
ca.batsmanRunsFreqPerf("./kohli.csv","Virat Kohli")
ca.batsmanMeanStrikeRate("./kohli.csv","Virat Kohli")
ca.batsmanRunsRanges("./kohli.csv","Virat Kohli")
6. More analyses
import cricpy.analytics as ca
ca.batsman4s("./kohli.csv","Virat Kohli")
ca.batsman6s("./kohli.csv","Virat Kohli")
ca.batsmanDismissals("./kohli.csv","Virat Kohli")
ca.batsmanScoringRateODTT("./kohli.csv","Virat Kohli")
7. 3D scatter plot and prediction plane
The plots below show the 3D scatter plot of Kohli’s Runs versus Balls Faced and Minutes at crease. A linear regression plane is then fitted between Runs and Balls Faced + Minutes at crease
import cricpy.analytics as ca
ca.battingPerf3d("./kohli.csv","Virat Kohli")
Average runs at different venues
The plot below gives the average runs scored by Kohli at different grounds. The plot also the number of innings at each ground as a label at x-axis.
import cricpy.analytics as ca
ca.batsmanAvgRunsGround("./kohli.csv","Virat Kohli")
9. Average runs against different opposing teams
This plot computes the average runs scored by Kohli against different countries.
import cricpy.analytics as ca
ca.batsmanAvgRunsOpposition("./kohli.csv","Virat Kohli")
10 . Highest Runs Likelihood
The plot below shows the Runs Likelihood for a batsman. For this the performance of Kohli is plotted as a 3D scatter plot with Runs versus Balls Faced + Minutes at crease. K-Means. The centroids of 3 clusters are computed and plotted. In this plot Kohli’s highest tendencies are computed and plotted using K-Means
import cricpy.analytics as ca
ca.batsmanRunsLikelihood("./kohli.csv","Virat Kohli")
A look at the Top 4 batsman – Kohli, Jayasuriya, Sehwag and Gayle
The following batsmen have been very prolific in ODI cricket and will be used for the analyses
- Virat Kohli: Runs – 10232, Average:59.83 ,Strike rate-92.88
- Sanath Jayasuriya : Runs – 13430, Average:32.36 ,Strike rate-91.2
- Virendar Sehwag :Runs – 8273, Average:35.05 ,Strike rate-104.33
- Chris Gayle : Runs – 9727, Average:37.12 ,Strike rate-85.82
The following plots take a closer at their performances. The box plots show the median the 1st and 3rd quartile of the runs
12. Box Histogram Plot
This plot shows a combined boxplot of the Runs ranges and a histogram of the Runs Frequency
import cricpy.analytics as ca
ca.batsmanPerfBoxHist("./kohli.csv","Virat Kohli")
ca.batsmanPerfBoxHist("./jayasuriya.csv","Sanath jayasuriya")
ca.batsmanPerfBoxHist("./gayle.csv","Chris Gayle")
ca.batsmanPerfBoxHist("./sehwag.csv","Virendar Sehwag")
13 Moving Average of runs in career
Take a look at the Moving Average across the career of the Top 4 (ignore the dip at the end of all plots. Need to check why this is so!). Kohli’s performance has been steadily improving over the years, so has Sehwag. Gayle seems to be on the way down
import cricpy.analytics as ca
ca.batsmanMovingAverage("./kohli.csv","Virat Kohli")
ca.batsmanMovingAverage("./jayasuriya.csv","Sanath jayasuriya")
ca.batsmanMovingAverage("./gayle.csv","Chris Gayle")
ca.batsmanMovingAverage("./sehwag.csv","Virendar Sehwag")
14 Cumulative Average runs of batsman in career
This function provides the cumulative average runs of the batsman over the career. Kohli seems to be getting better with time and reaches a cumulative average of 45+. Sehwag improves with time and reaches around 35+. Chris Gayle drops from 42 to 35
import cricpy.analytics as ca
ca.batsmanCumulativeAverageRuns("./kohli.csv","Virat Kohli")
ca.batsmanCumulativeAverageRuns("./jayasuriya.csv","Sanath jayasuriya")
ca.batsmanCumulativeAverageRuns("./gayle.csv","Chris Gayle")
ca.batsmanCumulativeAverageRuns("./sehwag.csv","Virendar Sehwag")
15 Cumulative Average strike rate of batsman in career
Sehwag has the best strike rate of almost 90. Kohli and Jayasuriya have a cumulative strike rate of 75.
import cricpy.analytics as ca
ca.batsmanCumulativeStrikeRate("./kohli.csv","Virat Kohli")
ca.batsmanCumulativeStrikeRate("./jayasuriya.csv","Sanath jayasuriya")
ca.batsmanCumulativeStrikeRate("./gayle.csv","Chris Gayle")
ca.batsmanCumulativeStrikeRate("./sehwag.csv","Virendar Sehwag")
16 Relative Batsman Cumulative Average Runs
The plot below compares the Relative cumulative average runs of the batsman . It can be seen that Virat Kohli towers above all others in the runs. He is followed by Chris Gayle and then Sehwag
import cricpy.analytics as ca
frames = ["./sehwag.csv","./gayle.csv","./jayasuriya.csv","./kohli.csv"]
names = ["Sehwag","Gayle","Jayasuriya","Kohli"]
ca.relativeBatsmanCumulativeAvgRuns(frames,names)
Relative Batsman Strike Rate
The plot below gives the relative Runs Frequency Percentages for each 10 run bucket. The plot below show Sehwag has the best strike rate, followed by Jayasuriya
import cricpy.analytics as ca
frames = ["./sehwag.csv","./gayle.csv","./jayasuriya.csv","./kohli.csv"]
names = ["Sehwag","Gayle","Jayasuriya","Kohli"]
ca.relativeBatsmanCumulativeStrikeRate(frames,names)
18. 3D plot of Runs vs Balls Faced and Minutes at Crease
The plot is a scatter plot of Runs vs Balls faced and Minutes at Crease. A 3D prediction plane is fitted
import cricpy.analytics as ca
ca.battingPerf3d("./kohli.csv","Virat Kohli")
ca.battingPerf3d("./jayasuriya.csv","Sanath jayasuriya")
ca.battingPerf3d("./gayle.csv","Chris Gayle")
ca.battingPerf3d("./sehwag.csv","Virendar Sehwag")
3D plot of Runs vs Balls Faced and Minutes at Crease
From the plot below it can be seen that Sehwag has more runs by way of 4s than 1’s,2’s or 3s. Gayle and Jayasuriya have large number of 6s
import cricpy.analytics as ca
frames = ["./sehwag.csv","./kohli.csv","./gayle.csv","./jayasuriya.csv"]
names = ["Sehwag","Kohli","Gayle","Jayasuriya"]
ca.batsman4s6s(frames,names)20. Predicting Runs given Balls Faced and Minutes at Crease
A multi-variate regression plane is fitted between Runs and Balls faced +Minutes at crease.
import cricpy.analytics as ca
import numpy as np
import pandas as pd
BF = np.linspace( 10, 400,15)
Mins = np.linspace( 30,600,15)
newDF= pd.DataFrame({'BF':BF,'Mins':Mins})
kohli= ca.batsmanRunsPredict("./kohli.csv",newDF,"Kohli")print(kohli)## BF Mins Runs
## 0 10.000000 30.000000 6.807407
## 1 37.857143 70.714286 36.034833
## 2 65.714286 111.428571 65.262259
## 3 93.571429 152.142857 94.489686
## 4 121.428571 192.857143 123.717112
## 5 149.285714 233.571429 152.944538
## 6 177.142857 274.285714 182.171965
## 7 205.000000 315.000000 211.399391
## 8 232.857143 355.714286 240.626817
## 9 260.714286 396.428571 269.854244
## 10 288.571429 437.142857 299.081670
## 11 316.428571 477.857143 328.309096
## 12 344.285714 518.571429 357.536523
## 13 372.142857 559.285714 386.763949
## 14 400.000000 600.000000 415.991375The fitted model is then used to predict the runs that the batsmen will score for a given Balls faced and Minutes at crease.
21 Analysis of Top Bowlers
The following 4 bowlers have had an excellent career and will be used for the analysis
- Muthiah Muralitharan:Wickets: 534, Average = 23.08, Economy Rate – 3.93
- Wasim Akram : Wickets: 502, Average = 23.52, Economy Rate – 3.89
- Shaun Pollock: Wickets: 393, Average = 24.50, Economy Rate – 3.67
- Javagal Srinath : Wickets:315, Average – 28.08, Economy Rate – 4.44
How do Muralitharan, Akram, Pollock and Srinath compare with one another with respect to wickets taken and the Economy Rate. The next set of plots compute and plot precisely these analyses.
22. Get the bowler’s data
This plot below computes the percentage frequency of number of wickets taken for e.g 1 wicket x%, 2 wickets y% etc and plots them as a continuous line
import cricpy.analytics as ca
#akram=ca.getPlayerDataOD(43547,dir=".",file="akram.csv",type="bowling")
#murali=ca.getPlayerDataOD(49636,dir=".",file="murali.csv",type="bowling")
#pollock=ca.getPlayerDataOD(46774,dir=".",file="pollock.csv",type="bowling")
#srinath=ca.getPlayerDataOD(34105,dir=".",file="srinath.csv",type="bowling")23. Wicket Frequency Plot
This plot below plots the frequency of wickets taken for each of the bowlers
import cricpy.analytics as ca
ca.bowlerWktsFreqPercent("./murali.csv","M Muralitharan")
ca.bowlerWktsFreqPercent("./akram.csv","Wasim Akram")
ca.bowlerWktsFreqPercent("./pollock.csv","Shaun Pollock")
ca.bowlerWktsFreqPercent("./srinath.csv","J Srinath")
24. Wickets Runs plot
The plot below create a box plot showing the 1st and 3rd quartile of runs conceded versus the number of wickets taken. Murali’s median runs for wickets ia around 40 while Akram, Pollock and Srinath it is around 32+ runs. The spread around the median is larger for these 3 bowlers in comparison to Murali
import cricpy.analytics as ca
ca.bowlerWktsRunsPlot("./murali.csv","M Muralitharan")
ca.bowlerWktsRunsPlot("./akram.csv","Wasim Akram")
ca.bowlerWktsRunsPlot("./pollock.csv","Shaun Pollock")
ca.bowlerWktsRunsPlot("./srinath.csv","J Srinath")
25 Average wickets at different venues
The plot gives the average wickets taken by Muralitharan at different venues. McGrath best performances are at Centurion, Lord’s and Port of Spain averaging about 4 wickets. Kapil Dev’s does good at Kingston and Wellington. Anderson averages 4 wickets at Dunedin and Nagpur
import cricpy.analytics as ca
ca.bowlerAvgWktsGround("./murali.csv","M Muralitharan")
ca.bowlerAvgWktsGround("./akram.csv","Wasim Akram")
ca.bowlerAvgWktsGround("./pollock.csv","Shaun Pollock")
ca.bowlerAvgWktsGround("./srinath.csv","J Srinath")
26 Average wickets against different opposition
The plot gives the average wickets taken by Muralitharan against different countries. The x-axis also includes the number of innings against each team
import cricpy.analytics as ca
ca.bowlerAvgWktsOpposition("./murali.csv","M Muralitharan")
ca.bowlerAvgWktsOpposition("./akram.csv","Wasim Akram")
ca.bowlerAvgWktsOpposition("./pollock.csv","Shaun Pollock")
ca.bowlerAvgWktsOpposition("./srinath.csv","J Srinath")
27 Wickets taken moving average
From the plot below it can be see James Anderson has had a solid performance over the years averaging about wickets
import cricpy.analytics as ca
ca.bowlerMovingAverage("./murali.csv","M Muralitharan")
ca.bowlerMovingAverage("./akram.csv","Wasim Akram")
ca.bowlerMovingAverage("./pollock.csv","Shaun Pollock")
ca.bowlerMovingAverage("./srinath.csv","J Srinath")
28 Cumulative average wickets taken
The plots below give the cumulative average wickets taken by the bowlers. Muralitharan has consistently taken wickets at an average of 1.6 wickets per game. Shaun Pollock has an average of 1.5
import cricpy.analytics as ca
ca.bowlerCumulativeAvgWickets("./murali.csv","M Muralitharan")
ca.bowlerCumulativeAvgWickets("./akram.csv","Wasim Akram")
ca.bowlerCumulativeAvgWickets("./pollock.csv","Shaun Pollock")
ca.bowlerCumulativeAvgWickets("./srinath.csv","J Srinath")
29 Cumulative average economy rate
The plots below give the cumulative average economy rate of the bowlers. Pollock is the most economical, followed by Akram and then Murali
import cricpy.analytics as ca
ca.bowlerCumulativeAvgEconRate("./murali.csv","M Muralitharan")
ca.bowlerCumulativeAvgEconRate("./akram.csv","Wasim Akram")
ca.bowlerCumulativeAvgEconRate("./pollock.csv","Shaun Pollock")
ca.bowlerCumulativeAvgEconRate("./srinath.csv","J Srinath")
30 Relative cumulative average economy rate of bowlers
The Relative cumulative economy rate shows that Pollock is the most economical of the 4 bowlers. He is followed by Akram and then Murali
import cricpy.analytics as ca
frames = ["./srinath.csv","./akram.csv","./murali.csv","pollock.csv"]
names = ["J Srinath","Wasim Akram","M Muralitharan", "S Pollock"]
ca.relativeBowlerCumulativeAvgEconRate(frames,names)
31 Relative Economy Rate against wickets taken
Pollock is most economical vs number of wickets taken. Murali has the best figures for 4 wickets taken.
import cricpy.analytics as ca
frames = ["./srinath.csv","./akram.csv","./murali.csv","pollock.csv"]
names = ["J Srinath","Wasim Akram","M Muralitharan", "S Pollock"]
ca.relativeBowlingER(frames,names)
32 Relative cumulative average wickets of bowlers in career
The plot below shows that McGrath has the best overall cumulative average wickets. While the bowlers are neck to neck around 130 innings, you can see Muralitharan is most consistent and leads the pack after 150 innings in the number of wickets taken.
import cricpy.analytics as ca
frames = ["./srinath.csv","./akram.csv","./murali.csv","pollock.csv"]
names = ["J Srinath","Wasim Akram","M Muralitharan", "S Pollock"]
ca.relativeBowlerCumulativeAvgWickets(frames,names)
33. Key Findings
The plots above capture some of the capabilities and features of my cricpy package. Feel free to install the package and try it out. Please do keep in mind ESPN Cricinfo’s Terms of Use.
Here are the main findings from the analysis above
Analysis of Top 4 batsman
The analysis of the Top 4 test batsman Tendulkar, Kallis, Ponting and Sangakkara show the folliwing
- Kohli is a mean run machine and has been consistently piling on runs. Clearly records will lay shattered in days to come for Kohli
- Virendar Sehwag has the best strike rate of the 4, followed by Jayasuriya and then Kohli
- Shaun Pollock is the most economical of the bowlers followed by Wasim Akram
- Muralitharan is the most consistent wicket of the lot.
Important note: Do check out my other posts using cricpy at cricpy-posts
Also see
1. Architecting a cloud based IP Multimedia System (IMS)
2. Exploring Quantum Gate operations with QCSimulator
3. Dabbling with Wiener filter using OpenCV
4. Deep Learning from first principles in Python, R and Octave – Part 5
5. Big Data-2: Move into the big league:Graduate from R to SparkR
6. Singularity
7. Practical Machine Learning with R and Python – Part 4
8. Literacy in India – A deepR dive
9. Modeling a Car in Android
To see all posts click Index of Posts















































































 In this book I implement some of the most common, but important Machine Learning algorithms in R and equivalent Python code.
In this book I implement some of the most common, but important Machine Learning algorithms in R and equivalent Python code.












 , k=1,2,3,..K is a piece-wise cubic polynomial with continuous derivative up to order 2 at each knot. We can write
, k=1,2,3,..K is a piece-wise cubic polynomial with continuous derivative up to order 2 at each knot. We can write  .
. ),
),  are called ‘basis’ functions, where
are called ‘basis’ functions, where  ,
,  ,
,  ,
,  where k=1,2,3… K The 1st and 2nd derivatives of cubic splines are continuous at the knots. Hence splines provide a smooth continuous fit to the data by fitting different splines to different sections of the data
where k=1,2,3… K The 1st and 2nd derivatives of cubic splines are continuous at the knots. Hence splines provide a smooth continuous fit to the data by fitting different splines to different sections of the data








































 ML models have to be searched. This can be shown as follows
ML models have to be searched. This can be shown as follows ways to choose single feature ML models among ‘n’ features,
ways to choose single feature ML models among ‘n’ features,  ways to choose 2 feature models among ‘n’ models and so on, or
ways to choose 2 feature models among ‘n’ models and so on, or


 models to search amongst in Best Fit. For 10 features this is
models to search amongst in Best Fit. For 10 features this is  or ~1000 models and for 40 features this becomes
or ~1000 models and for 40 features this becomes  which almost 1 trillion. Usually there are datasets with 1000 or maybe even 100000 features and Best fit becomes computationally infeasible.
which almost 1 trillion. Usually there are datasets with 1000 or maybe even 100000 features and Best fit becomes computationally infeasible.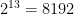 models
models





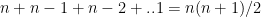 which is of the order of
which is of the order of  . Though forward fit is a sub optimal solution it is far more computationally efficient than best fit
. Though forward fit is a sub optimal solution it is far more computationally efficient than best fit


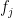 , for e.g., the inclusion of which results in the worst performance in adj Rsquared, or minimum Cp, BIC or some such criteria. At every step 1 feature is dopped. There is no guarantee that the final list of features chosen will be the best among the lot. The computation required for this is of
, for e.g., the inclusion of which results in the worst performance in adj Rsquared, or minimum Cp, BIC or some such criteria. At every step 1 feature is dopped. There is no guarantee that the final list of features chosen will be the best among the lot. The computation required for this is of 



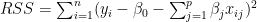

 to
to  significantly shrinks the coefficients. We can draw a vertical line from the x-axis and read the values of the 13 coefficients. Some of them will be close to zero
significantly shrinks the coefficients. We can draw a vertical line from the x-axis and read the values of the 13 coefficients. Some of them will be close to zero






















