GooglyPlusPlus2022 is the new avatar of last year’s GooglyPlusPlus2021. Roughly, about 5 years back I had written a post on Using linear programming to optimize T20 batting and bowling line up. This post has been on the back of my mind for a long time and I decided to pay this post a revisit. This requires computing performance of individual batsmen vs bowlers and vice-versa for performing the optimization. So in this latest incarnation, there are 4 new functions
- batsmanVsBowlerPerf – Performance of batsmen against chosen bowlers
- bowlerVsBatsmanPerf – Performance of bowlers versus specific batsmen
- battingOptimization – Optimizing batting line up based on strike rates ad remaining overs
- bowlingOptimization – Optimizing bowling line up based on economy rates and remaining overs
These 4 functions have been incorporated in all the supported 9 T20 formats namely a. IPL b. Intl. T20(men) c. Intl. T20 (women) d. BBL e. NTB f. PSL g. WBB h. CPL i. SSM
Check out GooglyPlusPlus2022!!
You can clone/fork the code for GooglyPlusPlus2022 from Github from gpp2022-1
With this latest update you can do a myriad of analyses of batsmen, bowlers, teams, matches. This is just-in-time for the IPL Mega-auction!! Do check out these other posts of GooglyPlusPlus for other detailed analysis
- GooglyPlusPlus2021: Towards more picturesque analytics!
- GooglyPlusPlus2021 now with power play, middle and death over analysis
- GooglyPlusPlus2021 adds new bells and whistles!!
- GooglyPlusPlus2021 is now fully interactive!!!
A) Batsman Vs Bowlers – This option computes the performance of individual batsman against individual bowlers
a) IPL Batsmen vs Bowlers
Included below are the performances of Dhoni, Raina and Kohli against Malinga, Ashwin and Bumrah. Note: The last 2 text box input are not required for this.

b) Intl. T20 (men) Batsmen vs Bowlers
Note: You can type the name and choose from the drop down list

B) Bowler vs Batsmen – You can check the performance of specific bowlers against specific batsmen
a) Intl. T20 (women) India vs Australia

b) PSL Bowlers vs Batsmen

C) Strategy for optimizing batting and bowling line up
From the above 2 tabs, it is obvious, that different bowlers have different ER and wicket rate against different batsmen. In other words, the effectiveness of the bowlers varies by batsmen. Conversely, batsmen are more comfortable with certain bowlers versus others and this shows up in different strike rates.
Hence during the death overs, when trying to restrict batsmen to a certain score or on the flip side when the batting side needs to score a target within certain overs, we need to take advantage of the relative effectiveness of bowlers vs batsmen for optimising bowling and aggressiveness of batsmen versus bowlers to quickly reach the target.
This is the approach that is used for bowling and batting optimisation. For optimising bowling, we need to formulate a minimisation problem based on ER rates and for optimising batting, a maximisation strategy is chosen based on SR. ‘Integer programming’ is used to compute during the last set of overs
This latest version includes optimization using “integer programming” based on R package lpSolve.
Here are the 2 formulations
Assume there are 3 bowlers –
and there are 3 batsmen –
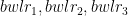
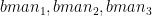
I) LP Formulation for bowling order
Let the economy rate 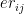
and the total number of overs left to be bowled are


Let the economy rate
Objective function : Minimize –
i.e.
Constraints
Where 
and if the total number of overs remaining to be bowled is N then
The overs that any bowler can bowl is
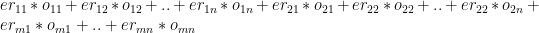

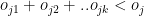
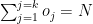
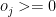
II) LP Formulation for batting lineup
Let the strike rate 
Objective function : Maximize –
i.e.
Constraints
Where
and the total number of overs remaining to be bowled is N then
The overs that any bowler can bowl is


C) Optimized bowling lineup
a) IPL – Optimizing bowling line up
Note: For computing the Optimal bowling lineup, the total number of overs remaining and the number of overs for each bowler have to be entered.

b) PSL – Optimizing batting line up

d) Optimized batting lineup
a) Intl. T20 (men) India vs England

b) Carribean Premier League – Optimizing batting line up

Give GooglyPlusPlus2022 a spin!
You can also check the code here gpp2022-1
Hope you have a good time with GooglyPlusPlus2022!
Also see
- Re-working the Lucy Richardson algorithm in OpenCV
- Deconstructing Convolutional Neural Networks with Tensorflow and Keras
- Deep Learning from first principles in Python, R and Octave – Part 5
- Cricketr adds team analytics to its repertoire!!!
- Practical Machine Learning with R and Python – Part 4
- Cricpy takes a swing at the ODIs
- yorkpy takes a hat-trick, bowls out Intl. T20s, BBL and Natwest T20!!!
- Big Data-4: Webserver log analysis with RDDs, Pyspark, SparkR and SparklyR
- Introducing QCSimulator: A 5-qubit quantum computing simulator in R
To see all posts click Index of posts































































































































































