If one follows the arrow of time from the early 1980s to the present day, the number of programming problems have not only proliferated but have also become more difficult. Fortunately programming in itself has become more manageable with massive increases in computing horsepower, smarter tools and instant availability of information on the internet, typically with the click of a mouse.
Learning to program is no easy task, but can be done with the right mix of attitude, curiosity and interest. Becoming adept at programming, however, is something else. An interesting essay in this context is Peter Norvig’s ‘Teach yourself programming in 10 years’
Back in the 1980s when I wrote my first Fortran program on my college Mainframe, programming was a lengthy exercise, spanning several days.

My first program was to plot a sine wave of characters on a computer printout. Running this program required the following several steps
- Enter the program on a teletype terminal and create a stack of Hollerith (punched) cards
- Submit the stack of cards to the computer center
- The computer center would do a batch execute in the evening on the Mainframe
- God forbid, if your program has a syntax error. If you did find an error, go back to step 1, the next day.
- Assuming everything is fine, the computer center would run your program and your output (printout) would be placed in the appropriate pigeon hole which you would need to pick up the next day.
The whole exercise to write a small-sized program could take anywhere between a couple of days to a whole week.
In the early 1990s things got a little better where one could code, compile, link and execute sitting at one’s desk. However while the programming itself got much simpler than before, certain tasks were still difficult. Till the late 90s programs of any sort had to be written using a regular text editor (vi , emacs etc.) You would then have to go through the process of compiling, linking and executing.
An angry compiler would typically spew forth venom at missing semi-colons, undeclared variables, and uninitialized values. This would happen till you are able to iron out all syntax errors. Then you would link, get undefined symbols and have to include appropriate libraries etc. And then finally you would execute your code, only to have it crash. The process of debugging would then start.
Luckily technology has made life a whole lot easier except for the last step where you could still run into an execution errors . In these days an IDE (Interactive Development Environment) like Eclipse will flag syntax errors, missing definitions/declarations etc. as you write your code. Moreover Eclipse can also indicate which libraries (imports) you would need to include in your package for it to build. The only missing step in IDEs of these days is the ability to predict possible execution errors in your program. I wouldn’t be surprised, if in future, like Microsoft Word, the IDE is able to tell you if a programming construct does not make sense.
So things have gotten a lot easier for the programmer. The following tips for are particularly useful as you progress along in programming
- These days when you are learning a new programming language it is not necessary to know the language from cover to cover by reading a book. In those days when we learnt C it was necessary to know everything from bit structures, macros, pragma etc. The reason being that every syntax or execution error one had to rush to get the textbook and thumb through it for the answer. Not so, in these days of Google. You have the world’s library at your fingertips.
- To get started it is necessary to learn just the most important programming constructs of the language say structure, class, car, cdr besides the usual suspects like loops, conditions and case constructs
- Download and install an IDE for the language. In most case Eclipse will work
- Try to write a simple program and test out your code.
- To do any sort of programming these days you will necessarily need to make 3 friends
- Stackoverflow
- Git & GitHub
- Honing your Googling skills is very important. There are answers to almost any sort of programming problems out there. You would be surprised to know that there are many others who did exactly the same stupid mistake that you did out there. Also googling will take you to interesting tutorials, blogs, articles that discuss different aspects of the programming language and the problem you are trying to solve
- Stackoverflow is really a God send to all programmers. There are so many questions on so many aspects of every programming language on earth there. If you spend time searching Stackoverflow you are bound to find answers, code snippets that you can readily use in your code
- Post your questions in stackoverflow when you don’t find the answers there. You are bound to get quick answers. Thanks to the gamification of Stackoverflow (points, upvotes,badges etc) that has been created on Stackoverflow.
- Git & GitHub: I would suggest that you download and install GitHub for Windows. This will provide you with version control on your desktop. You can modify code while being to switch back to an earlier version with Git. Read up a good tutorial on Git for Windows
- Once you have working code you push it onto GitHub and share with other programmers
Now that you have the basic setup here are few other extremely important tips
- The most important criteria for programming is ‘attitude’. Initially you are bound to get frustrated, angry, irritated etc. But it is necessary to look at the errors that you get with the right attitude. Know that an error is telling you something. Usually the answers to your mistake are in the ‘error message’ itself. Look at it closely and try to understand it. You will learn a lot more when you learn from errors than from copy-pasting from somebody else’s code, even if works right the first time around!
- Make sure you do something different each time. As Einstein said “ If you keep doing the same thing, you will keep getting the same result’
- There are different ways to debug your code. You could use the debugger and single step through the code and keep checking the values of the variables. I personally prefer print statements to localize where things are going wrong. I then try to narrow down the problem to a few lines of code and try to take it apart.
Hopefully the above tips are useful. Programming can be creative activity and will be indispensable in our future.
Above all have fun coding, there are so many possibilities these days!
Also see
1. Programming languages in layman’s language
2. The common alphabet of programming languages
3. The mind of the programmer
4. Programming Zen and now – Some essential tips -2
You may also like
1. A crime map of India in R: Crimes against women
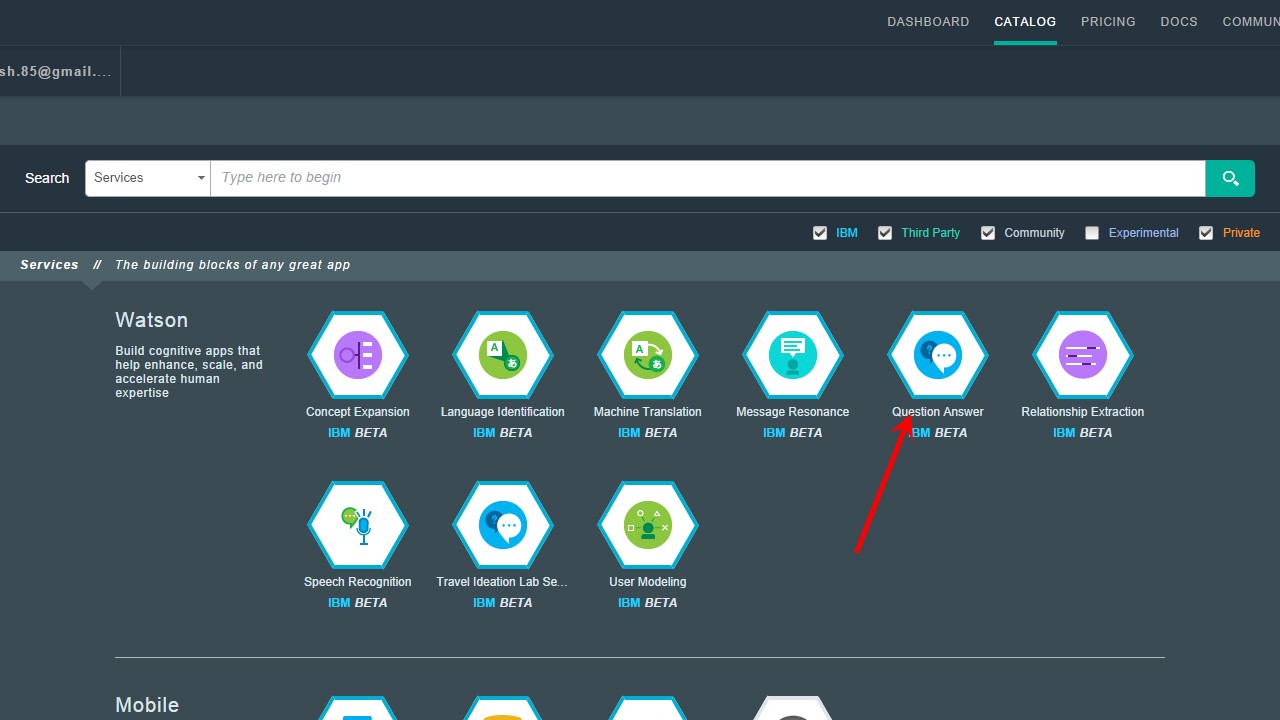
2. What’s up Watson? Using IBM Watson’s QAAPI with Bluemix, NodeExpress – Part 1
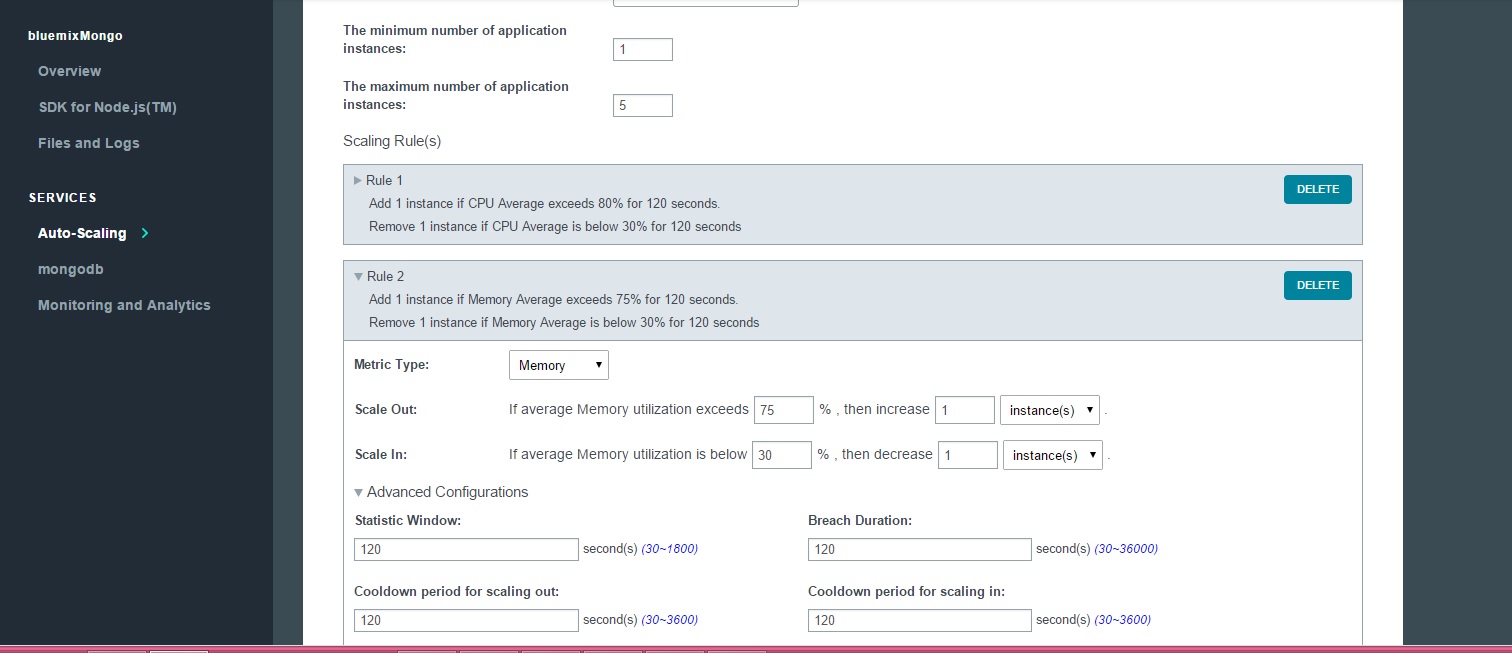
3. Bend it like Bluemix, MongoDB with autoscaling – Part 2
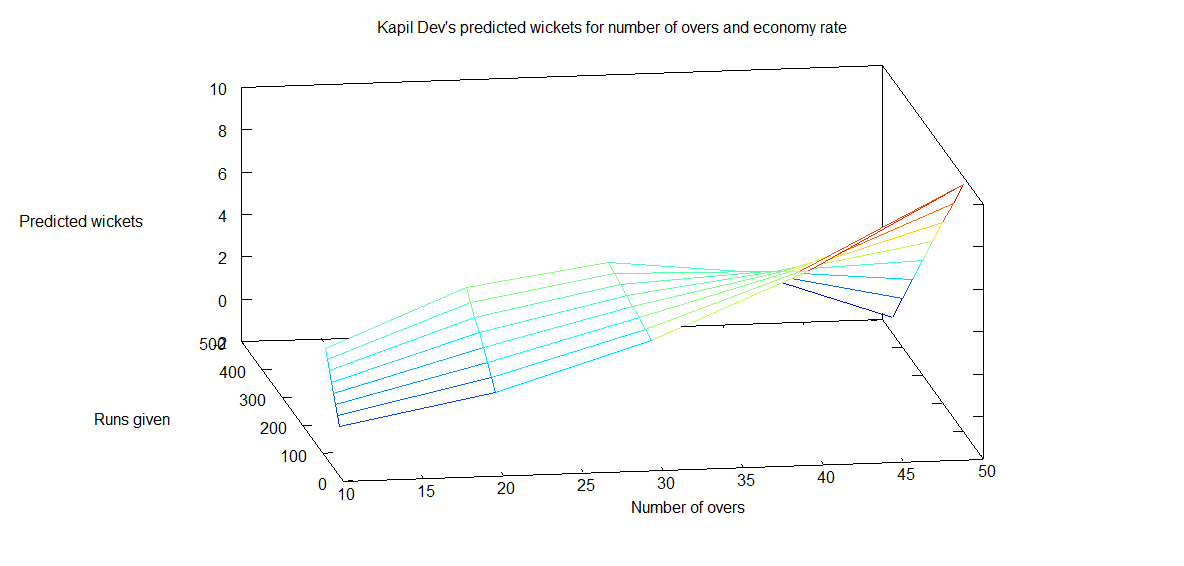
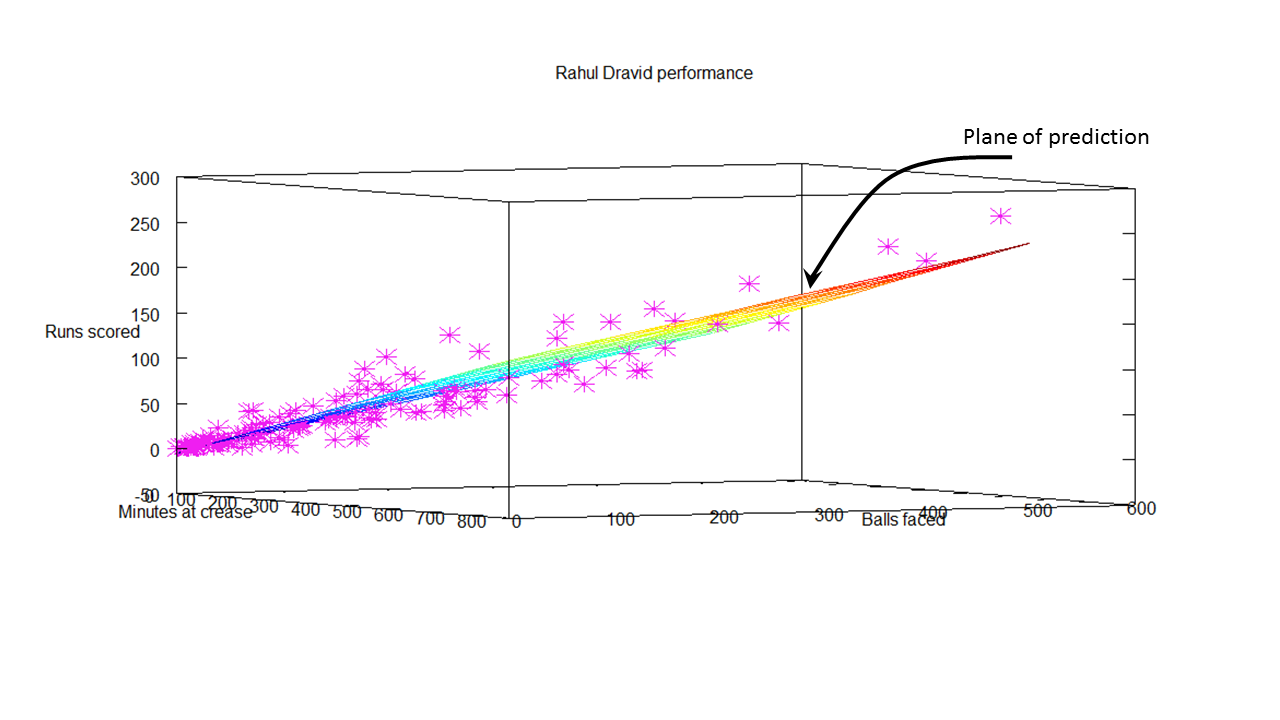
4. Informed choices through Machine Learning : Analyzing Kohli, Tendulkar and Dravid
5. Thinking Web Scale (TWS-3): Map-Reduce – Bring compute to data
6. Deblurring with OpenCV:Weiner filter reloaded
Programming Zen and now – Some essential tips-2