It is that time of the year when there is “a song in the air, the lark’s on the wing, and the snail’s on the the thorn“. Yes, it is the that time of year when the grand gala event of IPL 2022 is underway. So, I managed to wake myself from my Covid-induced slumber, worked up my ‘creaking bones‘ and cranked up the GooglyPlusPlus machinery.
So now, every morning, a scheduled CRON tab entry will automatically download the previous night’s match data from Cricsheet, unzip, process and transform it into the necessary format required by my R package yorkr, and make it available to my Shiny app GooglyPlusPlus. Hence the data is current and you have access to ‘analytics-in-the-now’!.
As you know in 2021, I added a lot of new features to GooglyPlusPlus, new tabs to do even more. analytics – or in other words there is “more GooglyPlusPlus per click!!”. So now, you have the following
- Batsman tab: For detailed analysis of batsmen
- Bowler tab: For detailed analysis of bowlers
- Match tab: Analysis of individual matches, plot of Runs vs SR, Wickets vs ER in power play, middle and death overs
- Head-to-head tab: Detailed analysis of team-vs-team batting/bowling scorecard, batting, bowling performances, performances in power play, middle and death overs
- Team performance tab: Analysis of team-vs-all other teams with batting /bowling scorecard, batting, bowling performances, performances in power play, middle and death overs
- Optimisation tab: Allows one to pit batsmen vs bowlers and vice-versa. This tab also uses integer programming to optimise batting and bowling lineup
- Batting analysis tab: Ranks batsmen using Runs or SR. Also plots performances of batsmen in power play, middle and death overs and plots them in a 4×4 grid
- Bowling analysis tab: Ranks bowlers based on Wickets or ER. Also plots performances of bowlers in power play, middle and death overs and plots them in a 4×4 grid
Also note all these tabs and features are available for all T20 formats namely IPL, Intl. T20 (men, women), BBL, NTB, PSL, CPL, SSM.
Note: All charts are interactive, which means that you can hover, zoom-in, zoom-out, pan etc on the charts
The latest avatar of GooglyPlusPlus2022 is based on my R package yorkr with data from Cricsheet.
Go ahead, give GooglyPlusPlus a try!!!
To know all the new features and how to use them, check out these posts
- Ranking of batsmen, bowlers – GooglyPlusPlus2021 interactively ranks T20 batsmen and bowlers!!!
- Interactive charts – GooglyPlusPlus2021 is now fully interactive!!!
- Detailed batsmen/bowler analytics – GooglyPlusPlus2021 enhanced with drill-down batsman, bowler analytics
- Addition of Date Range picker to charts – GooglyPlusPlus2021 adds new bells and whistles!!
- Analysis of power play, middle and death overs across players, teams – GooglyPlusPlus2021 now with power play, middle and death over analysis
- Analysis based on 4 x 4 grid of players – GooglyPlusPlus2021: Towards more picturesque analytics!
- Optimisation of batsmen/bowlers – GooglyPlusPlus2022 optimizes batting/bowling lineup
Here are some random analysis that can be done by GooglyPlusPlus across the tabs. Note the app will be updated daily and the analytics will be current throughout the season of IPL 2022
A) Match tab
a) GT vs DC – 2 Apr 2022
Runs vs SR – Gujarat Titans

b) CSK vs LSG – 31 Mar 2022
Runs across 20 overs

c) KKR vs PBKS -Match wicket worm chart – 1 Apr 2022

B) Batsmen tab
a) Faf Du Plessis – Runs vs Deliveries

b) Sanju Samson – Runs against opposition

C) Bowler’s tab
a) D J Bravo – No of deliveries to wicket

b) Trent Boult – Wickets at Venues

D) Head-to-head tab
a) DC vs MI – Mar -2019 till date : Batting scorecard

b) CSK vs KKR – Jan 2019 till date : Runs vs SR

E) Team vs All Teams tab
a) Punjab Kings vs all Teams – Wickets vs ER in Power play

b) Rajasthan Royals vs all Teams : Jan 2019 till date : Runs vs SR in Power play

F) Optimisation tab
a) Batsmen vs Bowlers

b) Bowlers vs batsmen

G) Batting analysis
This tab is for ranking batsmen
a) Batsmen rank from 2019 till date (Runs over SR)

b) Overall Runs vs SR (Jan 2020 till date)
Best batsmen in top right quadrant

zooming in on the above (right-most)

H) Bowling analysis tab
a) Best middle over bowlers in IPL (2019 onwards)
The bottom right quadrant are the best bowlers

b) Best bowlers in death overs (bottom-right)

Check out GooglyPlusPlus!!!
Also see
- Deconstructing Convolutional Neural Networks with Tensorflow and Keras
- Deep Learning from first principles in Python, R and Octave – Part 5
- Big Data-4: Webserver log analysis with RDDs, Pyspark, SparkR and SparklyR
- Latency, throughput implications for the Cloud
- Introducing QCSimulator: A 5-qubit quantum computing simulator in R
- Practical Machine Learning with R and Python – Part 3
- Natural language processing: What would Shakespeare say?
- Introducing cricpy:A python package to analyze performances of cricketers
To see all posts click Index of posts





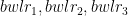
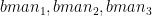
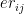 be the Economy Rate of the jth bowler to the ith batsman. Also if remaining overs for the bowlers are
be the Economy Rate of the jth bowler to the ith batsman. Also if remaining overs for the bowlers are 

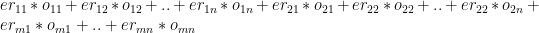

 is the number of overs remaining for the jth bowler against ‘k’ batsmen
is the number of overs remaining for the jth bowler against ‘k’ batsmen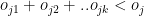
 or
or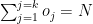
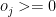
 be the Strike Rate of the ith batsman to the jth bowler
be the Strike Rate of the ith batsman to the jth bowler

















































































































































