There is a voice that doesn’t use words, listen.
When someone beats a rug, the blows are not against the rug, but against the dust in it.
I lost my hat while gazing at the moon, and then I lost my mind.
Rumi
Introduction
After a long hiatus, I am back to my big, bad, blogging ways! In this post I rank T20 players from several different leagues namely
- International T20
- Indian Premier League (IPL) T20
- Big Bash League (BBL) T20
- Natwest Blast (NTB) T20
I have added 8 new functions to my Python Package yorkpy, which will perform the ranking for the above 4 T20 League formats. To know more about my Python package see Pitching yorkpy . short of good length to IPL – Part 1, and the related posts on yorkpy. The code can be easily extended to other leagues which have a the same ‘yaml’ format for the matches. I also fixed some issues which started to crop up, possibly because a few things have changed in the new data.
The new functions are
- rankIntlT20Batting()
- rankIntlT20Batting()
- rankIPLT20Batting()
- rankIPLT20Batting
- rankBBLT20Batting()
- rankBBLT20Batting()
- rankNTBT20Batting()
- rankNTBT20Batting()
The yorkpy package uses data from Cricsheet
You can clone/fork the code for yorkpy at yorkpy
You can download the PDF of the post from Rank T20
yorkpy can be installed with ‘pip install yorkpy‘
1. International T20
The steps to do before ranking for International T20 matches are 1. Download International T20 zip file from Cricsheet Intl T20 2. Unzip the file. This will create a folder with yaml files
import yorkpy.analytics as yka
#yka.convertAllYaml2PandasDataframesT20("../t20s","../data")This above step will convert the yaml files into CSV files. Now do the ranking as below
1a. Ranking of International T20 batsmen
import yorkpy.analytics as yka
intlT20RankBatting=yka.rankIntlT20Batting("C:\\software\\cricket-package\\yorkpyPkg\\data\\data")
intlT20RankBatting.head(15)## matches runs_mean SR_mean
## batsman
## V Kohli 58 38.672414 125.212402
## KS Williamson 42 32.595238 122.884631
## Mohammad Shahzad 52 31.942308 118.212288
## CH Gayle 50 31.140000 111.869984
## BB McCullum 69 29.492754 117.011666
## MM Lanning 48 28.812500 98.582663
## SJ Taylor 44 28.659091 98.684856
## MJ Guptill 68 28.573529 117.673702
## DA Warner 71 28.507042 121.142746
## DPMD Jayawardene 53 27.584906 107.787092
## KC Sangakkara 54 26.407407 106.039838
## JP Duminy 68 26.294118 114.606717
## TM Dilshan 78 26.243590 97.910384
## RG Sharma 65 25.907692 113.056548
## H Masakadza 53 25.566038 99.4538801b. Ranking of International T20 bowlers
import yorkpy.analytics as yka
intlT20RankBowling=yka.rankIntlT20Bowling("C:\\software\\cricket-package\\yorkpyPkg\\data\\data")intlT20RankBowling.head(15)## matches wicket_mean econrate_mean
## bowler
## Umar Gul 58 1.603448 7.637931
## SL Malinga 78 1.500000 7.409188
## Saeed Ajmal 63 1.492063 6.451058
## DW Steyn 46 1.478261 7.014855
## A Shrubsole 45 1.422222 6.294444
## M Morkel 41 1.292683 7.680894
## KMDN Kulasekara 57 1.280702 7.476608
## TG Southee 51 1.274510 8.759804
## SCJ Broad 53 1.264151 inf
## Shakib Al Hasan 58 1.241379 6.836207
## R Ashwin 44 1.204545 7.162879
## Nida Dar 44 1.204545 6.083333
## KH Brunt 44 1.204545 5.982955
## KD Mills 42 1.166667 8.289683
## SR Watson 46 1.152174 8.2463772. Indian Premier League (IPL) T20
The steps to do before ranking for IPL T20 matches are 1. Download IPL T20 zip file from Cricsheet IPL T20 2. Unzip the file. This will create a folder with yaml files
import yorkpy.analytics as yka
#yka.convertAllYaml2PandasDataframesT20("../ipl","../ipldata")This above step will convert the yaml files into CSV files in the /ipldata folder. Now do the ranking as below
2a. Ranking of batsmen in IPL T20
import yorkpy.analytics as yka
IPLT20RankBatting=yka.rankIPLT20Batting("C:\\software\\cricket-package\\yorkpyPkg\\data\\ipldata")
IPLT20RankBatting.head(15)## matches runs_mean SR_mean
## batsman
## DA Warner 129 37.589147 119.917864
## CH Gayle 123 36.723577 125.256818
## SE Marsh 70 36.314286 114.707578
## KL Rahul 59 33.542373 123.424971
## MEK Hussey 60 33.400000 100.439187
## V Kohli 174 32.413793 115.830849
## KS Williamson 42 31.690476 120.443172
## AB de Villiers 143 30.923077 128.967081
## JC Buttler 45 30.800000 132.561154
## AM Rahane 118 30.330508 102.240398
## SR Tendulkar 79 29.949367 101.651959
## F du Plessis 65 29.415385 112.462114
## Q de Kock 51 29.333333 110.973836
## SS Iyer 47 29.170213 102.144222
## G Gambhir 155 28.741935 103.9975582b. Ranking of bowlers in IPL T20
import yorkpy.analytics as yka
IPLT20RankBowling=yka.rankIPLT20Bowling("C:\\software\\cricket-package\\yorkpyPkg\\data\\ipldata")
IPLT20RankBowling.head(15)## matches wicket_mean econrate_mean
## bowler
## SL Malinga 122 1.540984 7.173361
## Imran Tahir 43 1.465116 8.155039
## A Nehra 88 1.375000 7.923295
## MJ McClenaghan 56 1.339286 8.638393
## Rashid Khan 46 1.304348 6.543478
## Sandeep Sharma 79 1.303797 7.860759
## MM Patel 63 1.301587 7.530423
## DJ Bravo 131 1.282443 8.458333
## M Morkel 70 1.257143 7.760714
## SP Narine 109 1.256881 6.747706
## YS Chahal 83 1.228916 8.103659
## R Vinay Kumar 104 1.221154 8.556090
## RP Singh 82 1.219512 8.149390
## CH Morris 52 1.211538 7.854167
## B Kumar 117 1.205128 7.5363253. Natwest T20
The steps to do before ranking for Natwest T20 matches are 1. Download Natwest T20 zip file from Cricsheet NTB T20 2. Unzip the file. This will create a folder with yaml files
import yorkpy.analytics as yka
#yka.convertAllYaml2PandasDataframesT20("../ntb","../ntbdata")This above step will convert the yaml files into CSV files in the /ntbdata folder. Now do the ranking as below
3a. Ranking of NTB batsmen
import yorkpy.analytics as yka
NTBT20RankBatting=yka.rankNTBT20Batting("C:\\software\\cricket-package\\yorkpyPkg\\data\\ntbdata")
NTBT20RankBatting.head(15)## matches runs_mean SR_mean
## batsman
## Babar Azam 13 44.461538 121.268809
## T Banton 13 42.230769 139.376274
## JJ Roy 12 41.250000 142.182147
## DJM Short 12 40.250000 131.182294
## AN Petersen 12 37.916667 132.522727
## IR Bell 13 37.615385 130.104721
## M Klinger 26 35.346154 112.682922
## EJG Morgan 16 35.062500 129.817650
## AJ Finch 19 34.578947 137.093465
## MH Wessels 26 33.884615 116.300969
## S Steel 11 33.545455 140.118207
## DJ Bell-Drummond 21 33.142857 108.566309
## Ashar Zaidi 11 33.000000 178.553331
## DJ Malan 26 33.000000 120.127202
## T Kohler-Cadmore 23 32.956522 112.4930193b. Ranking of NTB bowlers
import yorkpy.analytics as yka
NTBT20RankBowling=yka.rankNTBT20Bowling("C:\\software\\cricket-package\\yorkpyPkg\\data\\ntbdata")
NTBT20RankBowling.head(15)## matches wicket_mean econrate_mean
## bowler
## MW Parkinson 11 2.000000 7.628788
## HF Gurney 23 1.956522 8.831884
## GR Napier 12 1.916667 8.694444
## R Rampaul 19 1.736842 7.131579
## P Coughlin 11 1.727273 8.909091
## AJ Tye 26 1.692308 8.227564
## GC Viljoen 12 1.666667 7.708333
## BAC Howell 21 1.666667 6.857143
## BW Sanderson 12 1.583333 7.902778
## KJ Abbott 14 1.571429 9.398810
## JE Taylor 13 1.538462 9.839744
## JDS Neesham 12 1.500000 10.812500
## MJ Potts 12 1.500000 8.486111
## TT Bresnan 21 1.476190 8.817460
## T van der Gugten 13 1.461538 7.2115384. Big Bash Leagure (BBL) T20
The steps to do before ranking for BBL T20 matches are 1. Download BBL T20 zip file from Cricsheet BBL T20 2. Unzip the file. This will create a folder with yaml files
import yorkpy.analytics as yka
#yka.convertAllYaml2PandasDataframesT20("../bbl","../bbldata")This above step will convert the yaml files into CSV files in the /bbldata folder. Now do the ranking as below
4a. Ranking of BBL batsmen
import yorkpy.analytics as yka
BBLT20RankBatting=yka.rankBBLT20Batting("C:\\software\\cricket-package\\yorkpyPkg\\data\\bbldata")
BBLT20RankBatting.head(15)## matches runs_mean SR_mean
## batsman
## DJM Short 43 40.883721 118.773047
## SE Marsh 47 39.148936 113.616053
## AJ Finch 62 36.306452 120.271231
## AT Carey 37 34.945946 120.125341
## UT Khawaja 41 31.268293 107.355655
## CA Lynn 74 31.162162 121.746578
## MS Wade 46 30.782609 120.310081
## TM Head 45 30.000000 126.769564
## MEK Hussey 23 29.173913 109.492934
## BJ Hodge 29 29.000000 124.438040
## BR Dunk 39 28.230769 106.149913
## AD Hales 31 27.161290 117.678008
## BB McCullum 34 27.058824 115.486392
## GJ Bailey 57 27.000000 121.159220
## MR Marsh 47 26.510638 114.9949094b. Ranking of BBL bowlers
import yorkpy.analytics as yka
BBLT20RankBowling=yka.rankBBLT20Bowling("C:\\software\\cricket-package\\yorkpyPkg\\data\\bbldata")
BBLT20RankBowling.head(15)## matches wicket_mean econrate_mean
## bowler
## Yasir Arafat 15 2.000000 7.587778
## CH Morris 15 1.733333 8.572222
## TK Curran 27 1.629630 8.716049
## TT Bresnan 13 1.615385 8.775641
## JR Hazlewood 18 1.555556 7.361111
## CJ McKay 15 1.533333 8.555556
## DR Sams 36 1.527778 8.581019
## AC McDermott 14 1.500000 9.166667
## JP Faulkner 20 1.500000 8.345833
## SP Narine 12 1.500000 7.395833
## AJ Tye 51 1.490196 8.101307
## M Kelly 21 1.476190 8.908730
## SA Abbott 73 1.438356 8.737443
## B Laughlin 82 1.426829 8.332317
## SW Tait 31 1.419355 8.895161Conclusion
You should be able to now rank players in the above formats as new data is added to Cricsheet. yorkpy can also be used for other leagues which follow the Cricsheet format.
Also see
1. Deep Learning from first principles in Python, R and Octave – Part 5
2. Using Linear Programming (LP) for optimizing bowling change or batting lineup in T20 cricket
3. Using Reinforcement Learning to solve Gridworld
4. Big Data-4: Webserver log analysis with RDDs, Pyspark, SparkR and SparklyR
5. My book ‘Practical Machine Learning in R and Python: Third edition’ on Amazon
6. Deblurring with OpenCV: Weiner filter reloaded
7. Rock N’ Roll with Bluemix, Cloudant & NodeExpress
8. Modeling a Car in Android
To see all posts click Index of posts


 where
where  is the expected return in time t and the discounted expected return
is the expected return in time t and the discounted expected return  in time t+1
in time t+1 at time t, then
at time t, then  is the probability that
is the probability that  = a if
= a if 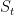 = s.
= s. , is the expected return when starting in s and following
, is the expected return when starting in s and following ![v_{\pi}(s) = E_{\pi}[G_{t} |S_{t}=s] = E_{\pi}[\sum_{k=0}^{k=Inf} \gamma^{k}R_{t+k+1}|S_{t}=s]](https://s0.wp.com/latex.php?latex=v_%7B%5Cpi%7D%28s%29+%3D+E_%7B%5Cpi%7D%5BG_%7Bt%7D+%7CS_%7Bt%7D%3Ds%5D+%3D+E_%7B%5Cpi%7D%5B%5Csum_%7Bk%3D0%7D%5E%7Bk%3DInf%7D+%5Cgamma%5E%7Bk%7DR_%7Bt%2Bk%2B1%7D%7CS_%7Bt%7D%3Ds%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![E_{\pi}[R_{t+1} + \gamma G_{t+1} |S_{t}=s]](https://s0.wp.com/latex.php?latex=E_%7B%5Cpi%7D%5BR_%7Bt%2B1%7D+%2B+%5Cgamma+G_%7Bt%2B1%7D+%7CS_%7Bt%7D%3Ds%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![v_{\pi}(s)=\sum_{a} \pi(a|s) \sum_{s',r} p(s',r|s,a)[r+\gamma*v_{\pi}(s')]](https://s0.wp.com/latex.php?latex=v_%7B%5Cpi%7D%28s%29%3D%5Csum_%7Ba%7D+%5Cpi%28a%7Cs%29+%5Csum_%7Bs%27%2Cr%7D+p%28s%27%2Cr%7Cs%2Ca%29%5Br%2B%5Cgamma%2Av_%7B%5Cpi%7D%28s%27%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![q_{\pi}(s,a)= \sum_{s',r} p(s',r|s,a)[r+\gamma*\pi(a|s)q_{\pi}(s',a')]](https://s0.wp.com/latex.php?latex=q_%7B%5Cpi%7D%28s%2Ca%29%3D+%5Csum_%7Bs%27%2Cr%7D+p%28s%27%2Cr%7Cs%2Ca%29%5Br%2B%5Cgamma%2A%5Cpi%28a%7Cs%29q_%7B%5Cpi%7D%28s%27%2Ca%27%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![v_{*}(s)=max_{a}\sum_{s',r} p(s',r|s,a)[r+\gamma*v_{*}(s')]](https://s0.wp.com/latex.php?latex=v_%7B%2A%7D%28s%29%3Dmax_%7Ba%7D%5Csum_%7Bs%27%2Cr%7D+p%28s%27%2Cr%7Cs%2Ca%29%5Br%2B%5Cgamma%2Av_%7B%2A%7D%28s%27%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![q_{*}(s,a)=\sum_{s',r} p(s',r|s,a)[r+\gamma*max_{a}q_{*}(s',a')]](https://s0.wp.com/latex.php?latex=q_%7B%2A%7D%28s%2Ca%29%3D%5Csum_%7Bs%27%2Cr%7D+p%28s%27%2Cr%7Cs%2Ca%29%5Br%2B%5Cgamma%2Amax_%7Ba%7Dq_%7B%2A%7D%28s%27%2Ca%27%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)








































 Checkout my book ‘Deep Learning from first principles: Second Edition – In vectorized Python, R and Octave’. My book starts with the implementation of a simple 2-layer Neural Network and works its way to a generic L-Layer Deep Learning Network, with all the bells and whistles. The derivations have been discussed in detail. The code has been extensively commented and included in its entirety in the Appendix sections. My book is available on Amazon as
Checkout my book ‘Deep Learning from first principles: Second Edition – In vectorized Python, R and Octave’. My book starts with the implementation of a simple 2-layer Neural Network and works its way to a generic L-Layer Deep Learning Network, with all the bells and whistles. The derivations have been discussed in detail. The code has been extensively commented and included in its entirety in the Appendix sections. My book is available on Amazon as 












































 ‘Cricket analytics with cricketr and cricpy – Analytics harmony with R and Python’ is now available on Amazon in both
‘Cricket analytics with cricketr and cricpy – Analytics harmony with R and Python’ is now available on Amazon in both 




1.1 Read NASA Web server logs
Read the logs files from NASA for the months Jul 95 and Aug 95