This year 2021, we are witnessing a rare spectacle in the cricketing universe, where IPL playoffs are immediately followed by ICC World Cup T20. Cricket pundits have claimed such a phenomenon occurs once in 127 years! Jokes apart, the World cup T20 is underway and as usual GooglyPlusPlus is ready for the action.
GooglyPlusPlus will provide near-real time analytics, by automatically downloading the latest match data daily, processing and organising the match data into appropriate folders so that my R package yorkr can slice and dice the data to provide the pavilion-view analytics.
The charts capture all the breathless, heart-pounding, and nail-biting action in great details in the many tables and plots. Every table and chart tell a story. You just have to ‘read between the lines!’
GooglyPlusPlus2021 will update itself automatically every day, so the data will be current and you can analyse all matches upto the previous day, along with the historical performances of the teams. So make sure you check it everyday.
Note:
- All charts are interactive. To know how to use the interactive charts see my post GooglyPlusPlus2021 is now fully interactive!!!
- The are 5 tabs for each of the formats supported by GooglyPlusPlus2021 which now supports IPL, Intl. T20(men), Intl. T20(women), BBL, NTB, PSL, CPL, SSM, WBB. Besides, it also supports ODI (men) and ODI (women)
- Each of the formats have 5 tabs – Batsman, Bowler, Match, Head-to-head and Overall Performace.
- All T20 formats also include a ranking functionality for the batsmen and bowlers
- You can now perform drill-down analytics for batsmen, bowlers, head-to-head and overall performance based on date-range selector functionality. The ranking tabs also include date range selector granular analysis. For more details see GooglyPlusPlus2021 enhanced with drill-down batsman, bowler analytics
Try out GooglyPlusPlus2021 here GooglyPlusPlus2021!!
You can clone fork the code from Github gpp2021-8
I am including some random screenshots of things that can be done with GooglyPlusPlus2021
A. Papua New Guinea vs Oman (2021-10-17)
a. Batting partnership

B. Match worm chart (New Papua Guinea v Oman)
This was a no contest as Oman cruised to victory

C. Scotland vs Bangladesh (2021-10-17)
a. Scorland upset Bangladesh

b. March worm chart (Scotland vs Bangladesh)
Fortunes see-sawed one way, then another, as can be seen in the match worm chart

C. Netherlands vs Ireland (2021-10-18)
a. Batman vs Bowler

D. Historical performance head-to-head
a. Sri Lanka vs West Indies (2019-2021) – Batting partnerships

b. India vs England (2018 – 2021) – Bowling scorecard

c) Australia vs South Africa – Team wicket opposition

E) Overall performance
a. Pakistan batting scorecard since 2019

a. Win loss of Australia since 2019

F) Batsman Performance
a. PR Stirling’s runs against opposition since 2019

b. KJ Brien’s cumulative average runs since 2019

G. Bowler performance
a. PWH De Silva’s wicket prediction since 2019

b. T Shamsi’s cumulative average wickets since 2019

H. Ranking Intl. T20 batsman since 2019
a. Runs over Strike rate

b. Strike rate over runs

I. Ranking bowlers since 2019
a. Wickets over Economy rate

b. Economy rate over wickets

As mentioned above GooglyPlusPlus2021 will be updated daily automatically, so you won’t miss any analytic action.
Do give GooglyPlusPlus2021 a spin!
Clone/fork the code for the Shiny app from Github gpp2021-8
You may also like
- Natural language processing: What would Shakespeare say?
- Literacy in India – A deepR dive
- Practical Machine Learning with R and Python – Part 5
- Big Data 7: yorkr waltzes with Apache NiFi
- Getting started with Tensorflow, Keras in Python and R
- Deep Learning from first principles in Python, R and Octave – Part 7
- Introducing QCSimulator: A 5-qubit quantum computing simulator in R
- Video presentation on Machine Learning, Data Science, NLP and Big Data – Part 1
To see all post click Index of posts





































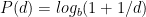







































 Checkout my book ‘Deep Learning from first principles: Second Edition – In vectorized Python, R and Octave’. My book starts with the implementation of a simple 2-layer Neural Network and works its way to a generic L-Layer Deep Learning Network, with all the bells and whistles. The derivations have been discussed in detail. The code has been extensively commented and included in its entirety in the Appendix sections. My book is available on Amazon as
Checkout my book ‘Deep Learning from first principles: Second Edition – In vectorized Python, R and Octave’. My book starts with the implementation of a simple 2-layer Neural Network and works its way to a generic L-Layer Deep Learning Network, with all the bells and whistles. The derivations have been discussed in detail. The code has been extensively commented and included in its entirety in the Appendix sections. My book is available on Amazon as 































































1.1 Read NASA Web server logs
Read the logs files from NASA for the months Jul 95 and Aug 95